LSTM长短期记忆网络
循环神经网络(Recurrent Neural Networks)
人类不会每次都从零开始思考.当你在读这篇文章的时候,你通过前面看过的文字理解每个新出现的词语.你不会忘记前面的所见而重新从零开始思考.你的思维有持续性.
传统的神经网络不能做到这些,这似乎是它的最大局限.例如,想象一下你想分辨电影中每个时间点发生的事情.传统神经网络如何用前一个场景去推导下一个场景,未可知.
循环神经网络为此而生.它是一个环状的网络,这让信息可以续存.

上图中,神经网络单元,A,输入 Xt 输出 ht.环状网络结构让信息从上一个网络单元传到下一个.
这个环让循环神经网络看上去有点神秘.然而,如果你再使仔细琢磨一下,它其实和普通神经网络没有很大的区别.一个循环神经网络可以看作一个相同的网络被复制了n多份,每个网络把信息传递给下一个.想象一下,如果我们把这个环展开:
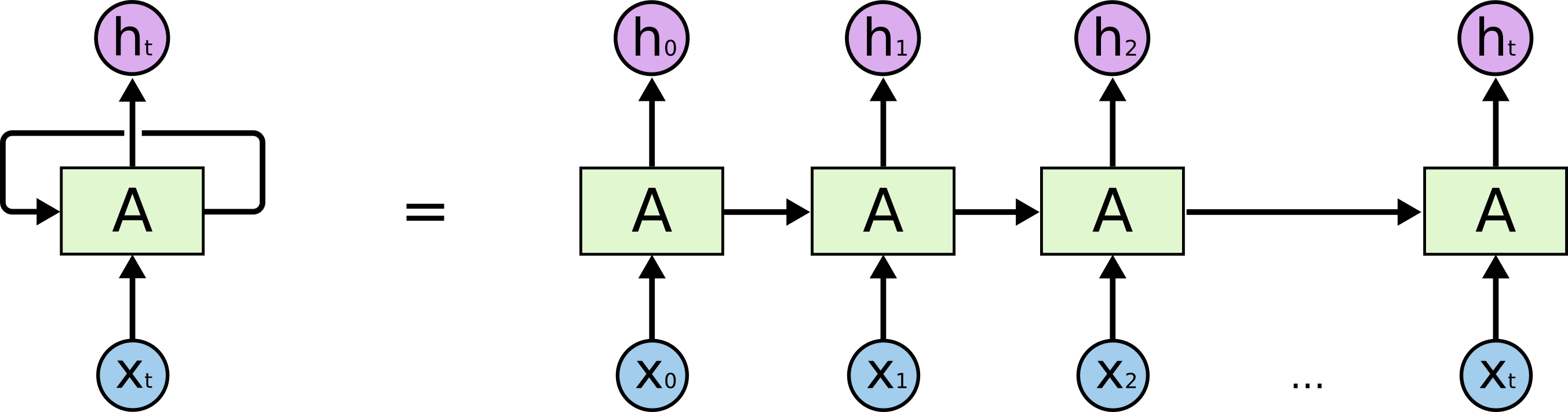
这种链性特征显示出循环神经网络跟序列有紧密关联.它们是神经网络为了处理序列性数据而产生的结构. 这确实挺有用的!过去的几年,把RNN应用到各式各样的问题取得了令人不可置信的成功:语音识别,语言模型,翻译,图片描述…还不断有新的应用出现. 这些成功案例的关键在于使用了“LSTM”,循环神经网络的一种类型,它在处理很多任务时,比标准型效果好非常非常多.几乎所有基于循环神经网络取得的卓越成就都是使用了LSTM.这篇文章将会详细探讨LSTM.
长期依赖的痛点
RNN 的作用在于它可能能够把前面的信息关联到当前任务中,比如使用前面的视频可能有助于理解当前的画面.如果RNN可以做到这些,它们将会极其有用.但是它可以吗?看情况.
有时候,我们只需要观察最近的信息就可以完成当前任务.举个例子,考虑一个语言模型通过前面的几个词预测下一个词.如果我们试图预测“白云飘在 天空”的最后一个词,我们不需要更多上下文 - 很明显下一个词会是 天空.诸如此类,需要预测的信息和关联信息的间隙比较小,RNN可以学会如何使用过去的信息.
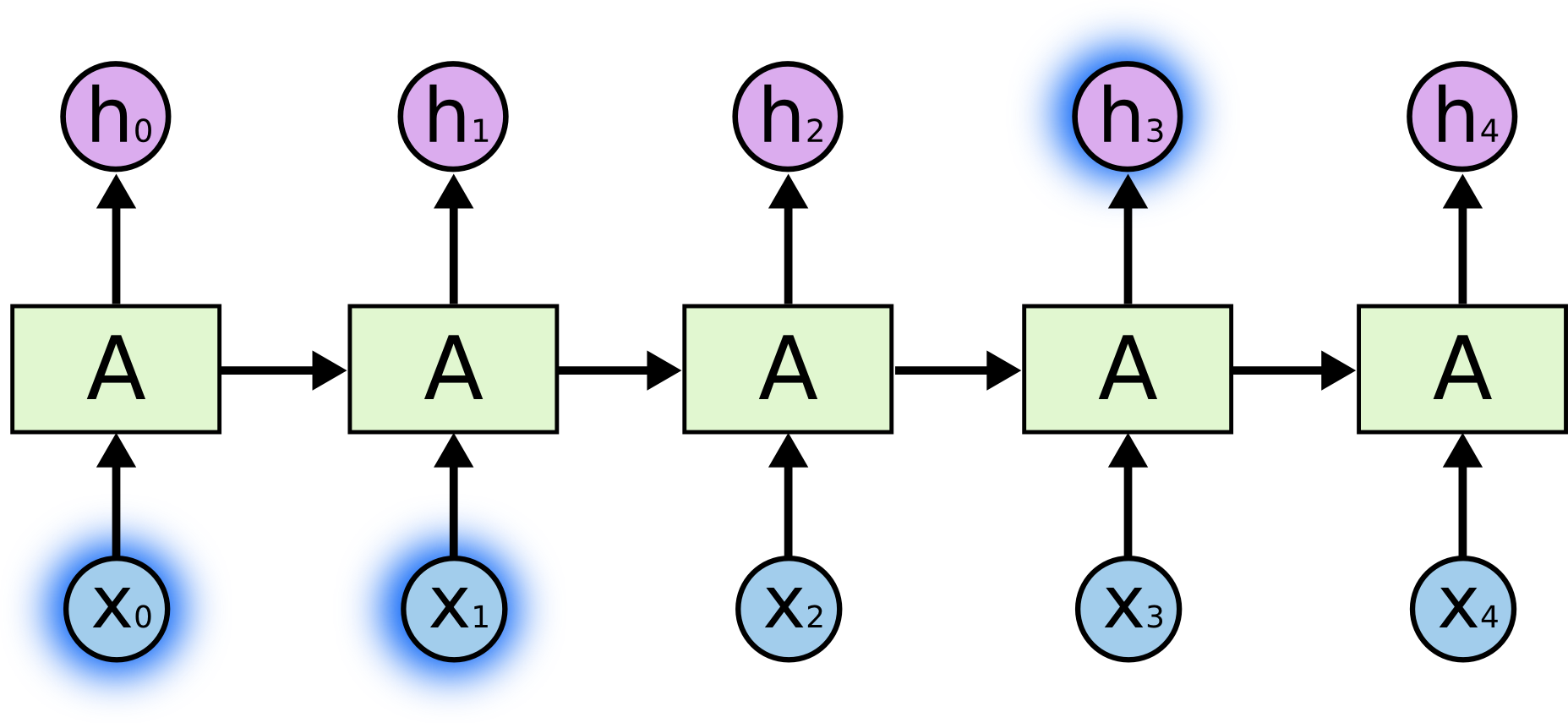
但是别的场景我们可能需要更多的上下文.考虑一下预测这句话的最后一个词,“我在法国长大…我说着流利的 法语.”最靠近的句子可以预测下一个词可能是一种语言,但如果我们想知道是哪种语言,我们需要包含 法国 的段落,这就离得比较远了.完全有这样的可能,我们需要的信息会埋藏在很遥远的上文.
不幸的是,随着间隙变大,RNN开始无法学习信息之间的关联性.
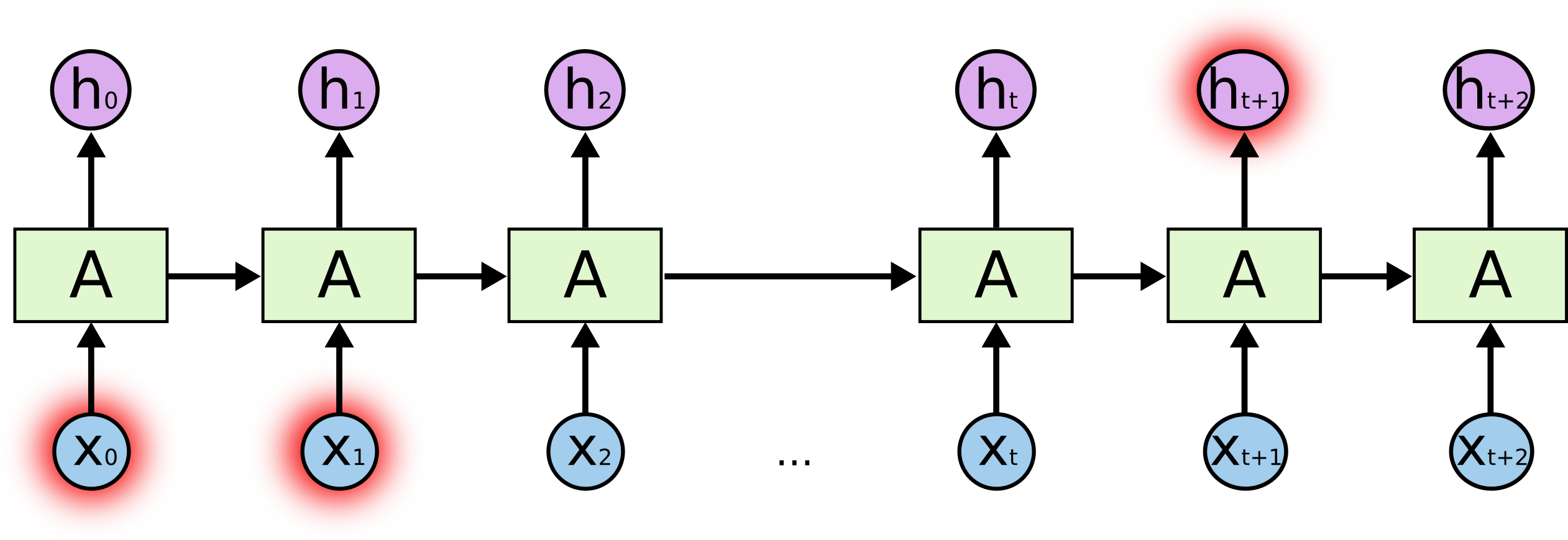
理论上,RNN完全有能耐处理这样的“长期依赖”任务.人类可以很仔细的挑选合适的参数,让它解决这种类型的问题.遗憾的是,事实上,RNN几乎不能习得这一技能.这个问题在这两篇论文Hochreiter (1991) [German] 和 Bengio, et al. (1994)中有深度的剖析,论文里边从比较根本的角度说明它的难点.
值得庆幸的是,LSTM没有这个问题!
长短期记忆网络(Long short term memory networks,LSTM)
长短期记忆网络 - 通常叫做“LSTM” - 是一种特殊类型的RNN,可以学习长期依赖.它由Hochreiter & Schmidhuber (1997)创建, 然后被很多人优化并逐渐流行起来.它处理各式各样的问题都表现很好,现在被广泛使用.
LSTM专门设计来处理长期依赖问题.记住时间间隔比较长的信息实际上是它们的默认行为.
所有循环神经网络都有重复的神经网络模块链.对于标准的RNN,它的重复模块会有一个非常简单结构,比如一个tanh层.
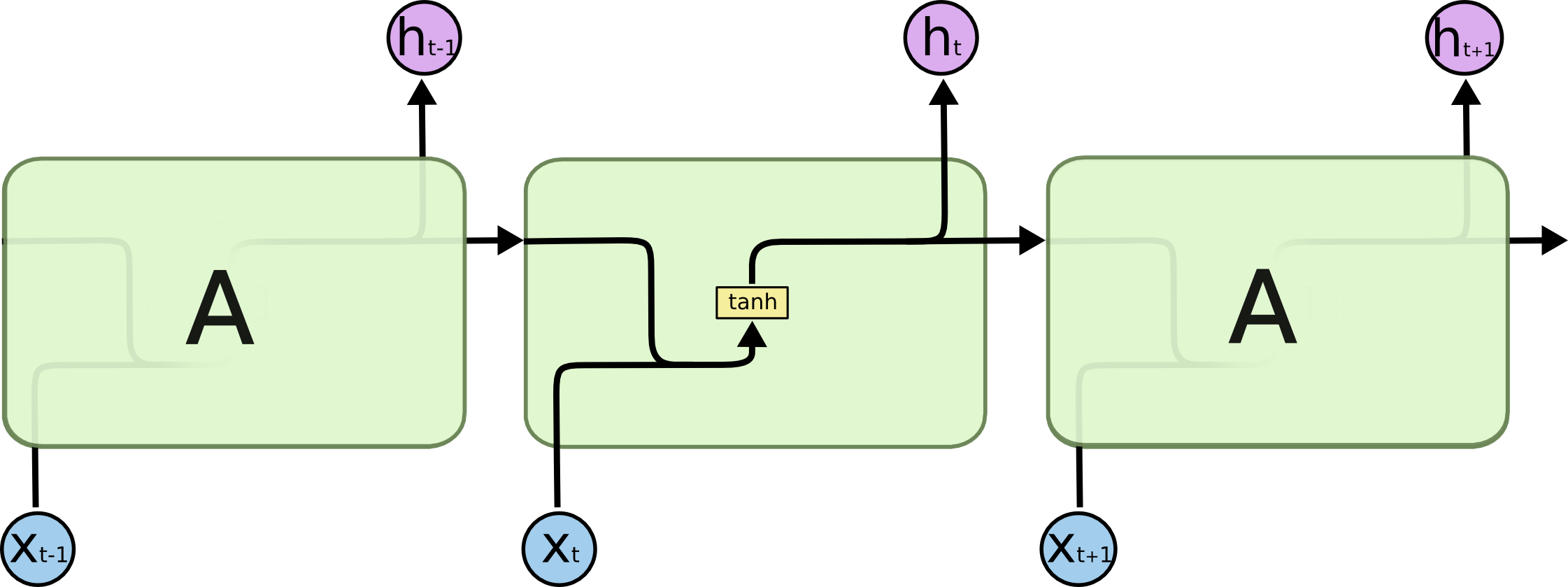
LSTM也有一个链式结构,但是它的重复单元有不同的结构.它有四个神经网络层,用特殊的方式进行交互.
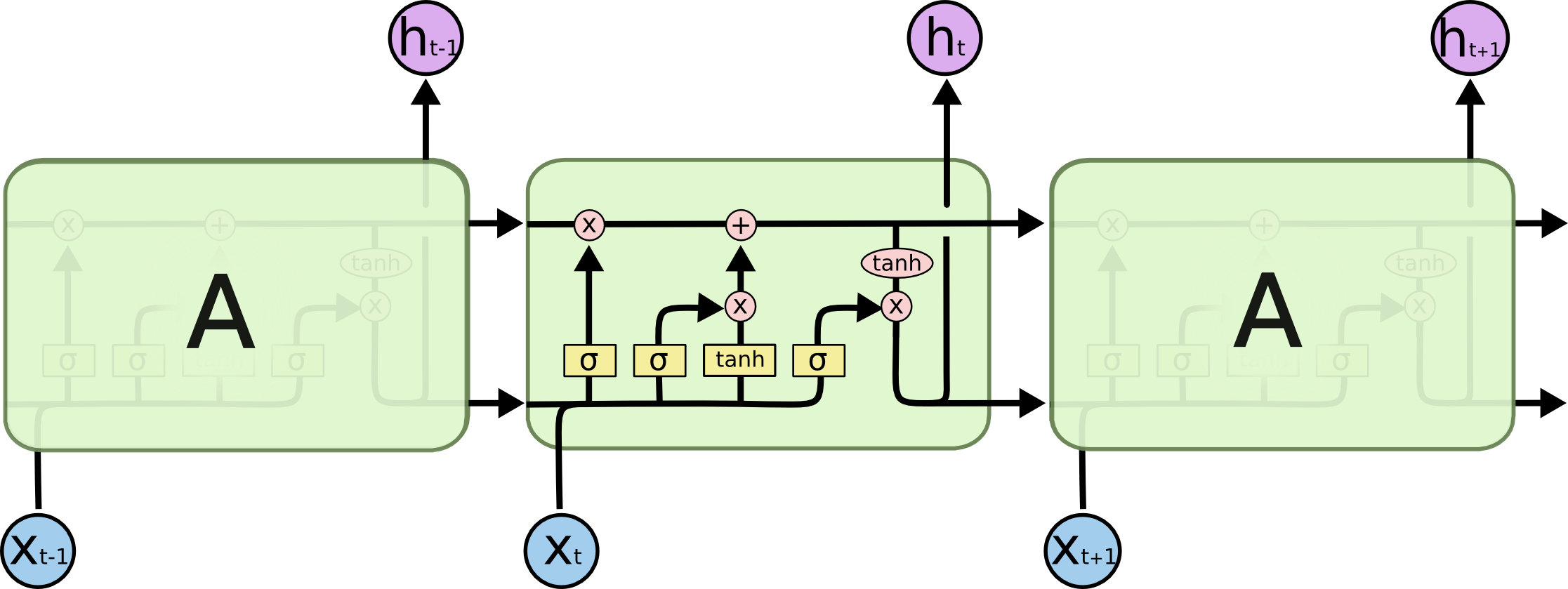
不用担心LSTM里边究竟发生了什么.我们将会一步一步拆解它的结构.现在,让我们先弄清每个标记都代表什么.
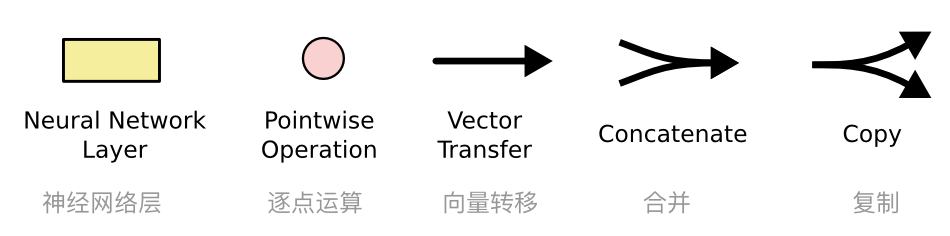
上图中,每条线携带一个完整的向量,从一个节点的输出到其他节点的输入.粉色的圆圈代表逐点运算,比如向量相加,黄色的方块是神经网络层.合并到一起的线代表数据合并,分叉的线代表它的数据被复制,并且复制的数据输出到不同的地方.
LSTM的核心概念
LSTM的关键是单元状态,一条水平的线穿过图示的上方.
单元状态有点像运输带.它笔直的跑完整条链,只有极小的数据变动.很有可能数据仅仅是流过去,而没有什么变动.
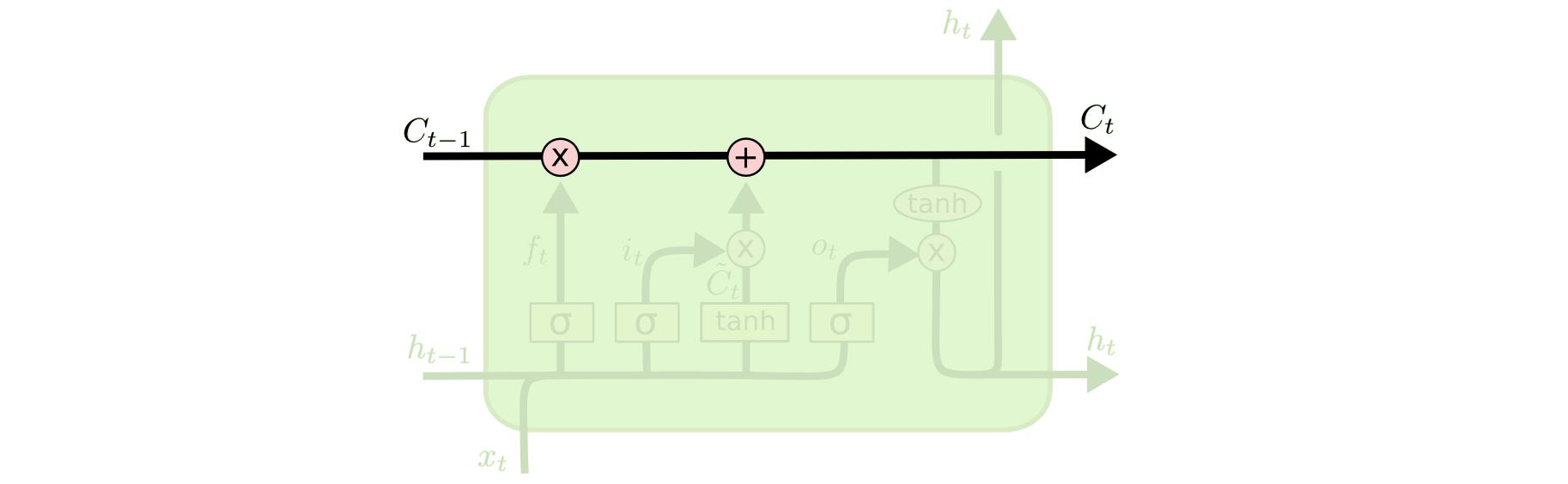 LSTM没有能力删除或添加信息到单元状态,这由它的“门”管理着.
LSTM没有能力删除或添加信息到单元状态,这由它的“门”管理着.
门是一种选择性的让数据通过的方式.它们由一个Sigmoid神经网还有一个逐点乘法运算组成.
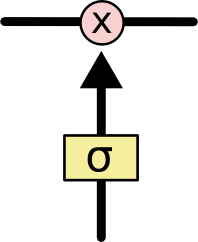
Sigmoid层的输出在0到1之间,表示每个数据应该通过多大比例.0代表“什么都别想通过”,1代表”全部通过!”.
一个LSTM有三个这样的门,用来保护、控制单元状态.
逐步解析LSTM
LSTM第一个需要决定的是什么信息将从单元状态中丢弃.这个决定由一个叫“遗忘门”的Sigmoid层给出.它观察 ht-1 和 Xt,然后针对每个单元状态 Ct-1 输出一个0到1之间的数值. 1代表“完全保留”,0代表“完全丢弃”.
让我们再回到之前的例子,一个语言模型想通过上文预测下一个词语.在这个问题中,单元状态可能包含当前对象的性别,这样它才能使用合适的代词.当我们看到一个新的对象,我们希望遗忘旧对象的性别.
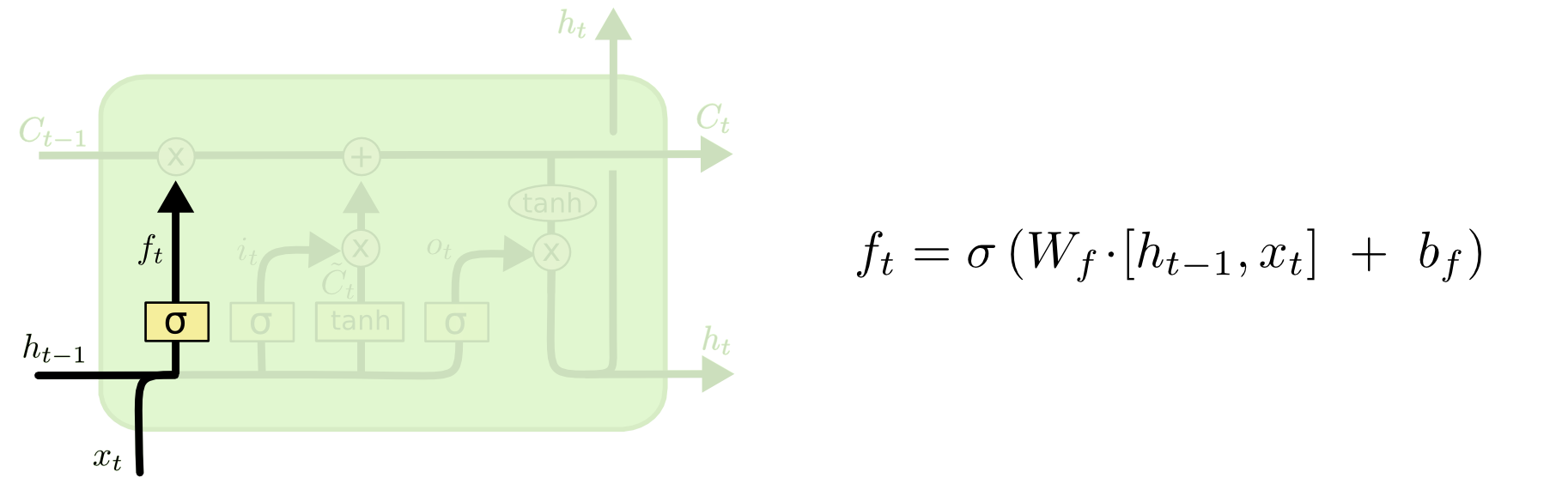
下一步是决定我们将存储什么新信息到单元状态.这可以分成两部分.首先,有一个叫“输入门”的Sigmoid层决定我们需要更新哪些值.其次,一个tanh层生成一个可以加到单元状态的新向量, C~t.下一步,我们将合并这两个向量来更新单元状态.
在我们语言模型的例子中,我们想要把新对象的性别加到单元状态中来取代我们想遗忘的旧状态.
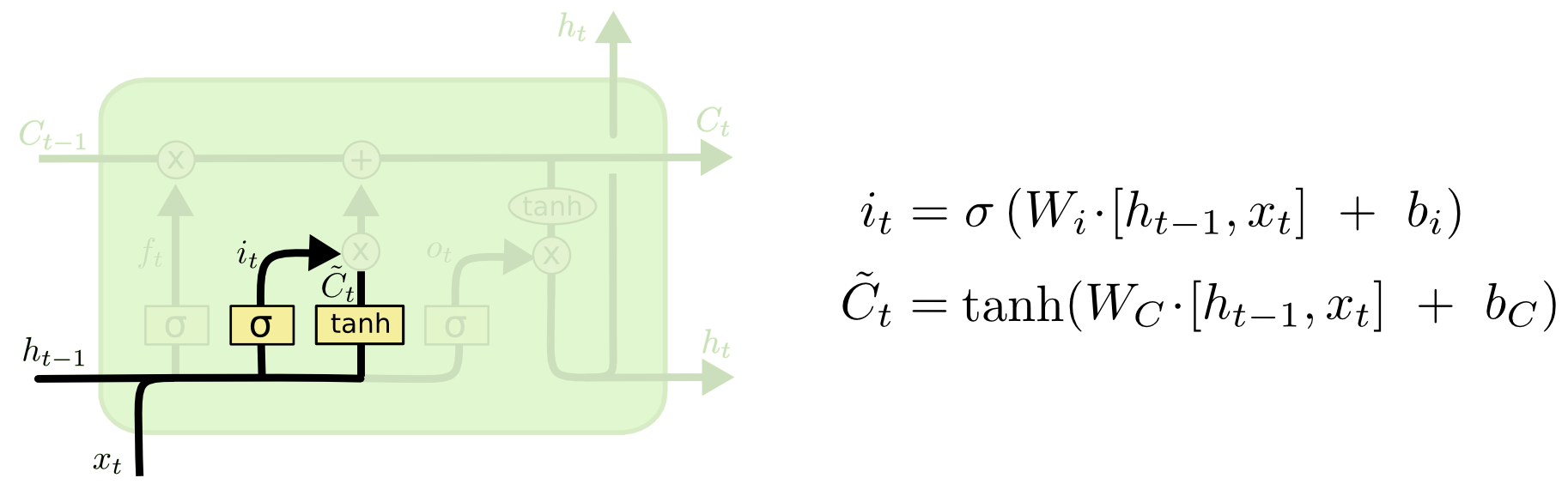
现在是时候把旧单元状态 Ct-1 更新到新单元状态 Ct-1 了.前一步已经决定了要做什么,现在只要执行就好.
我们把旧状态乘以 ft,遗忘我们先前决定要遗忘的.然后我们再加上 it* C~t.这是新的候选值,乘以我们需要缩放的倍率.
在语言模型的例子中,这是我们前面决定要丢弃旧对象的性别,添加新信息的地方.
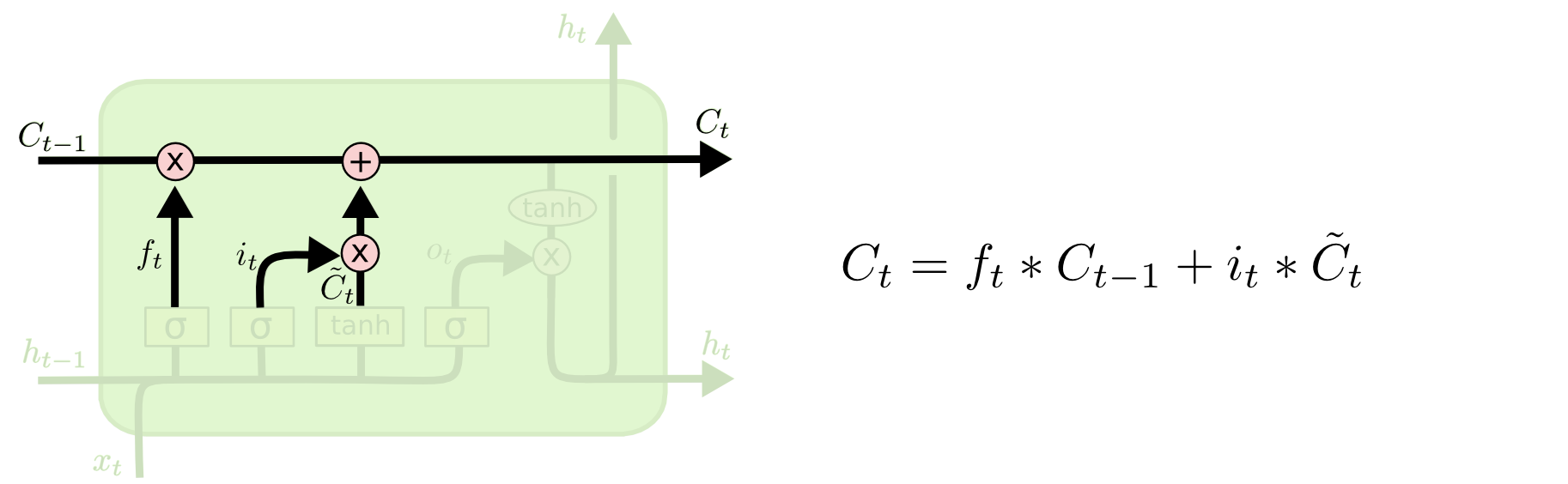
最后,我们需要决定我们需要输出什么.输出由我们的单元状态决定,不过它是一个筛选过的版本.首先,我们生成一个Sigmoid层(输出门)来决定哪一部分单元状态需要输出.然后,我们让单元状态经过 tanh (让值的范围变成 -1 到 1 之间) 然后让它乘以Sigmoid门,这样我们只输出我们决定要输出的那部分.
对于语言模型,由于它只是看到一个对象,后面它可能需要输出动词相关的信息.例如,它可能需要输出这个对象是单数,还是复数,这样我们才知道后面的文字需要使用什么类型的动词.
reference: Understanding LSTM Networks