如何深度学习进行语义分割

当下,语义分割 是计算机视觉领域的一个关键研究点.如上图,语义分割是计算机进行场景理解的一个过程.随着各种从图像中获取信息的应用场景的增加,比如,自动驾驶,人机互动,虚拟现实….所以,使用计算机来解读场景也受到更多的关注.随着深度学习在这几年越来越火,很多语义分割的问题都可以使用基于卷积神经网络的深度模型来解决,它能达到的精度和效率远高于其他方式.
什么是语义分割?
从粗粒预测到细粒度预测,语义分割是必然要经历的过程:
- 一开始是 图片分类, 它可以预测图片的主体组成
- 然后是 目标检测, 它不单可以预测图片的分类,还可以标记出目标在图片中的位置
- 最终, 语义分割 实现了细粒度预测,它可以预测图片上每个像素属于那一类,所以每个像素都可以使用对应分类的颜色进行标记.
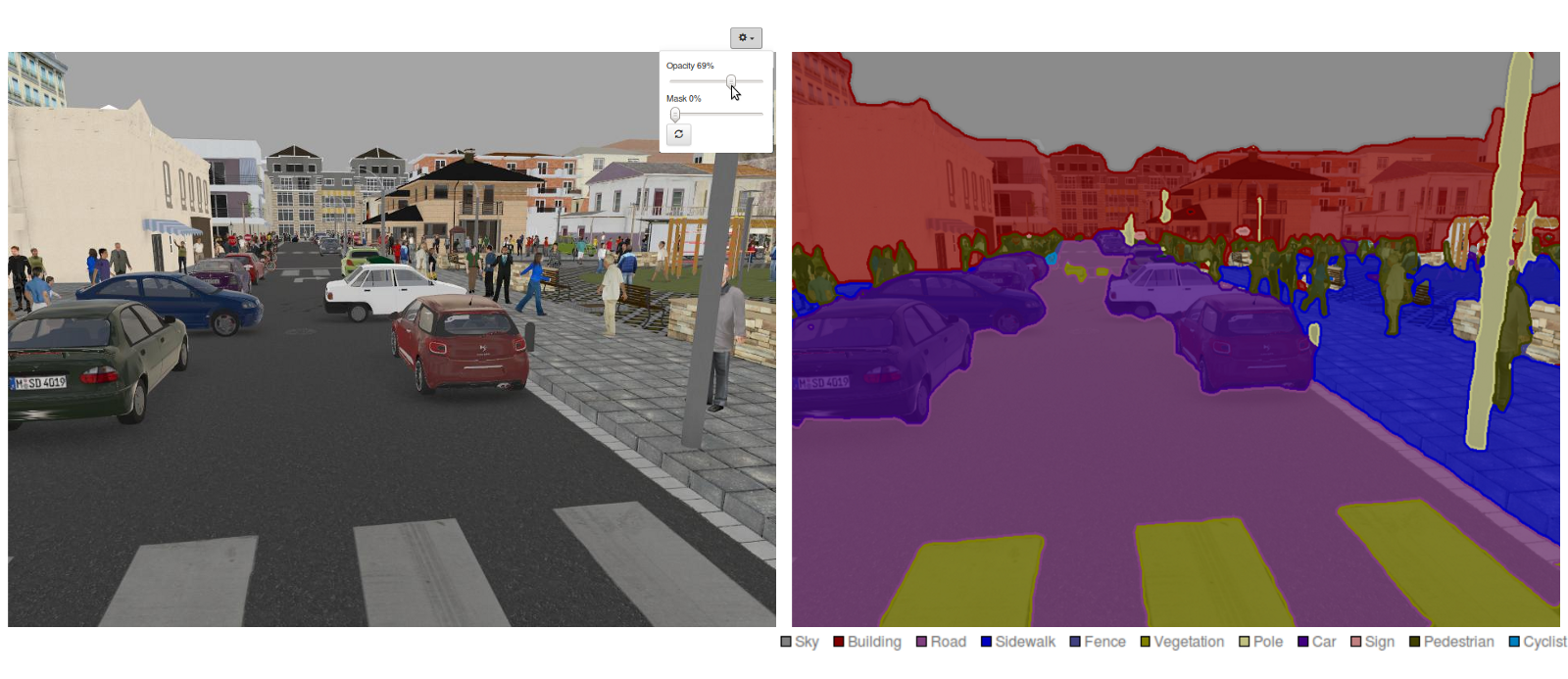
现在有哪些实现语义分割的方式?
语义分割的结构通常分为两部分,一个 编码器 网络,还有一个 解码器 网络:
- 编码器 通常是一个预训练的分类网络,比如VGG/ResNet
- 解码器 的任务是从语义上投射编码器(低像素)识别出的特征到高像素空间来获得像素级的目标分类
与分类任务不同,前者唯一重要的是从深层网络获得最终的预测结果,语义分割不仅需要像素级的分类,还需要投射编码器在不同阶段学到的分类特征到像素空间.不同的实现方式使用的不同的解码器的实现原理各有不同.让我们来探索一下3种主要的方式:
1–基于区域的语义分割
基于区域的方法通常遵循“通过识别来进行分割”的流程,即先提取图片不定大小的区域然后进行解析,进而获得基于区域的分类.在预测的时候,基于区域的预测被转化成像素级别的预测,通常把一个元素标记为包含这个元素的区域中分数最高的那个区域.
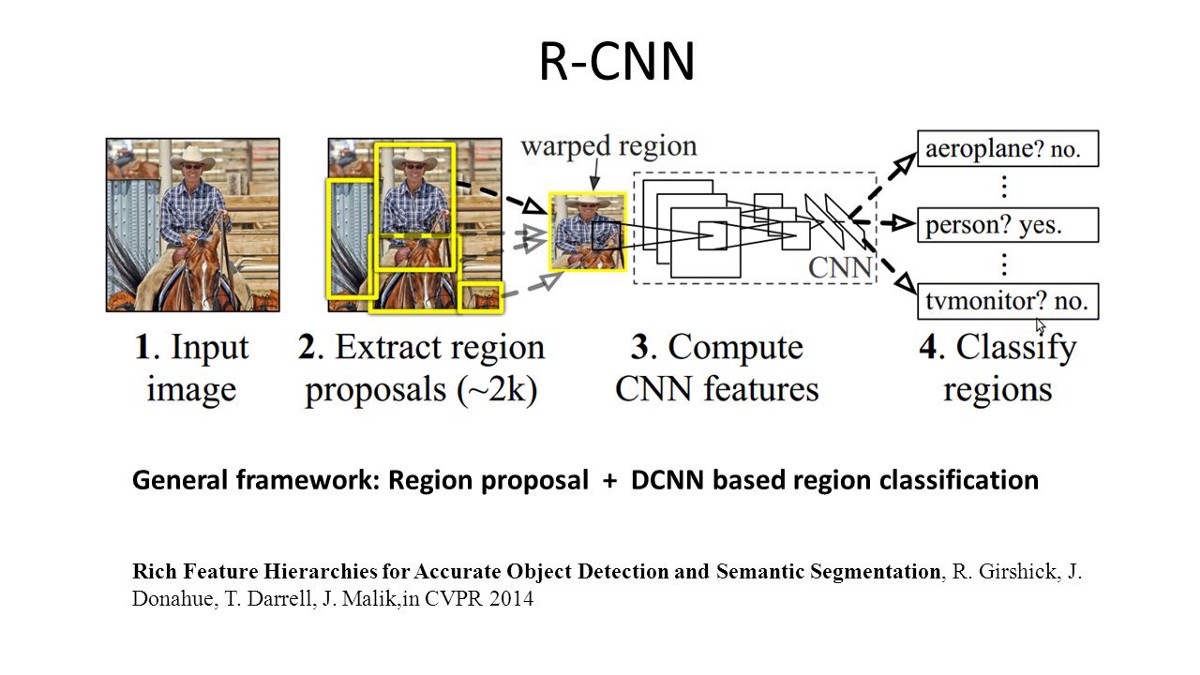
R-CNN(Regions with CNN feature)是基于区域的语义分割的一种方式.它基于目标检测进行语义分割.具体来说,R-CNN先使用选择性搜索来提取大量的目标区域,然后计算每个区域的CNN特征.最终,使用分类用的线性支持向量机算法来对每个区域进行分类.传统的CNN主要用于图片分类,与之相比,R-CNN可以完成更加复杂的任务,比如目标检测和图片分割,甚至成为这两个领域的重要基础.此外,R-CNN可以在所有CNN经典网络的基础上进行搭建,比如AlexNet、VGG、GoogleNet、ResNet.
在图片分割任务中,R-CNN在每个区域中提取两种类型的特征:整个区域的特征还有主体的特征,如果把这两者拼接到一起构成一个区域特征将获得更好的效果.R-CNN由于使用预训练的经典CNN来提取特征,所以有很好的效果.然而,它在分割任务上也有几个缺点:
- 特征与分割任务不兼容
- 特征没有包含足够的空间信息来进行精确的区域预测
- 生成基于分割的局部区域需要不少时间且会影响最终结果
由于以上瓶颈,有了以下升级版的R-CNN, SDS, Hypercolumns, Mask R-CNN.
2–基于全卷积网络的语义分割
全卷积网络(FCN)在没有提取目标区域的情况下学习像素到像素的一一映射.FCN网络的结构是经典CNN的延伸.关键是可以把任意大小的图片输入到经典CNN.CNN只能输入固定大小的图片来进行分类预测是由于全链接层是固定的.与此相反,FCN只有卷积层和池化层,这让它可以有能力预测任意大小的输入图片.(图片有最小限制)
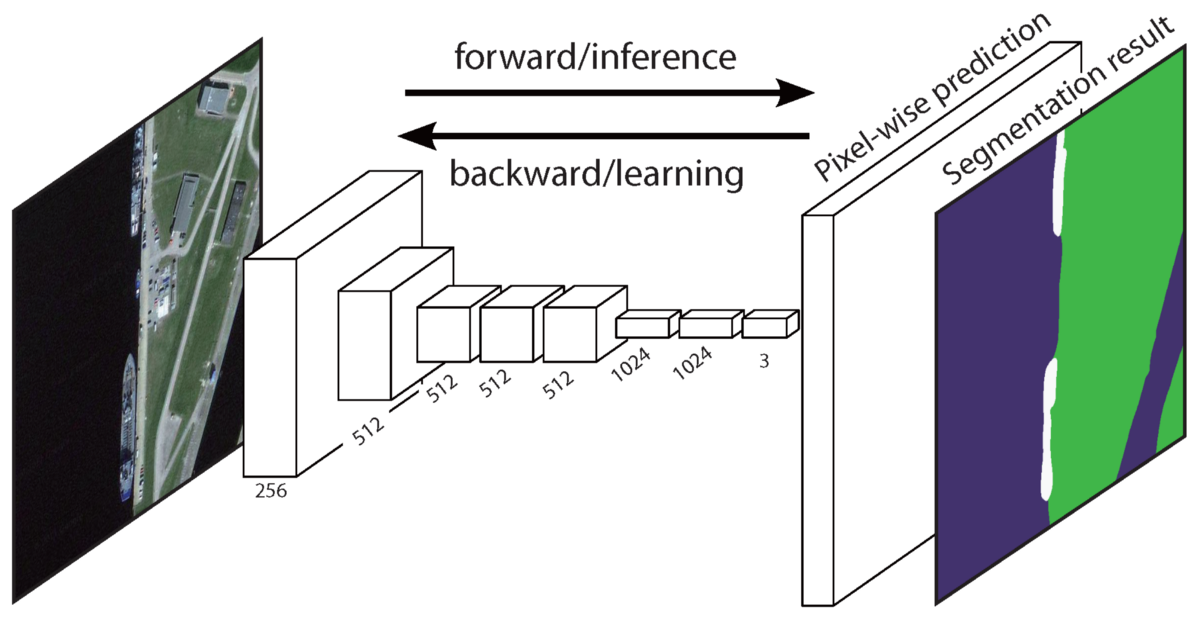 上面这个FCN有个缺点,通过几个卷积层和池化层之后,输出特征图的分辨率变得很小.因此,FCN的直接预测结果通常分辨率很低,进而导致目标边界的模糊.不过有好几种更好的FCN网络结构,可以克服这个缺点,包括 SegNet, DeepLab-CRF, and Dilated Convolutions.
上面这个FCN有个缺点,通过几个卷积层和池化层之后,输出特征图的分辨率变得很小.因此,FCN的直接预测结果通常分辨率很低,进而导致目标边界的模糊.不过有好几种更好的FCN网络结构,可以克服这个缺点,包括 SegNet, DeepLab-CRF, and Dilated Convolutions.
3–弱监督语义分割
大部分语义分割相关的方法都依赖大量有像素级分割遮罩的图片.然而,人工标记这些遮罩需要消耗大量的时间和资源.因而,最近推出了弱监督的实现方式,它的目标在于通过使用有方框标记的图片来实现语义分割.

例如,Boxsup使用方框标记的图片作为监督来训练网络,然后通过迭代来提升用于语义分割的预估遮罩的准确度.Simple Does It把弱监督的局限当作输入标签的噪音,然后通过重复迭代训练来达到降噪的目的.还有Pixel-level Labeling.
使用全卷积网络进行语义分割
这部分,我将手把手教你实现使用全卷积网络(FCN)进行语义分割.我将使用Python3版本的tensorflow,还有其他依赖三方库,比如Numpy和Scipy.当然,你也可以直接查看完整代码.
这个练习中我们将标注图片中属于马路的像素.我们将使用Kitti Road DataSet作为数据集.

FCN的关键点如下:
- FCN 使用VGG16提取的图片特征进行语义分割
- VGG16 的全链接层被转化成1x1的卷积层.
- 这些低像素语义特征图使用tranposed_convolution进行上取样.
- 跨层链接,通过跨层链接把VGG的池化层和上取样的网络进行叠加,从而获得分辨率更高的预测结果.
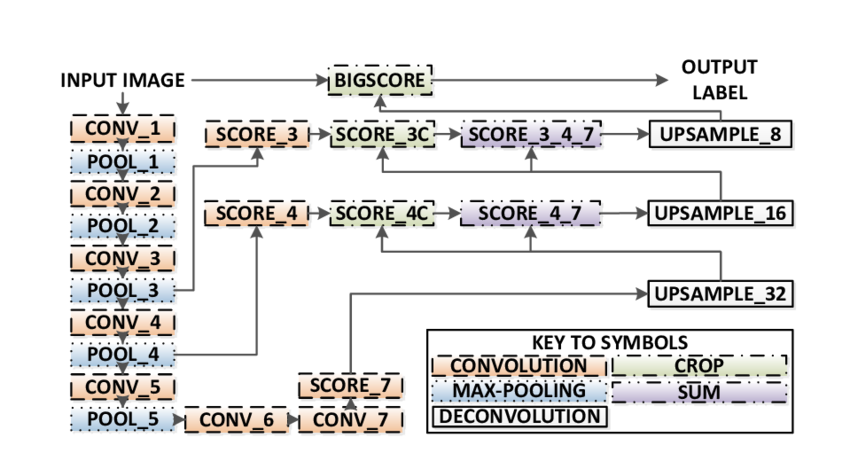
有三种形式的FCN(FCN-32, FCN-16, FCN-8).我们将实现FCN-8,具体步骤如下:
- 编码器: 用一个预训练的 VGG16 作为编码器.解码器从VGG16的layer 7开始.
- FCN Layer-8: 用1x1的卷积层代替VGG16的最后全链接层.
- FCN layer-9: FCN Layer-8被上取样两倍以吻合VGG16 Layer 4的维度.然后,用一个跨层链接把 VGG16 的 Layer 4 和 FCN 的layer 9 链接起来.
- FCN layer-10: FCN Layer-9被上取样两倍以吻合VGG16 Layer 3的维度.然后,用一个跨层链接把 VGG16 的 Layer 3 和 FCN 的layer 10 链接起来.
- FCN layer-11: FCN Layer-10被上取样四倍以吻合输入图片的维度,这样我们才可以得到深度为分类数,大小和原图相同的输出.
FCN-8网络结构图如下
Step 1
加载预训练的 VGG-16 模型到当前Session
def load_vgg(sess, vgg_path):
"""
Load Pretrained VGG Model into TensorFlow.
:param sess: TensorFlow Session
:param vgg_path: Path to vgg folder, containing "variables/" and "saved_model.pb"
:return: Tuple of Tensors from VGG model (image_input, keep_prob, layer3_out, layer4_out, layer7_out)
"""
vgg_tag = 'vgg16'
vgg_input_tensor_name = 'image_input:0'
vgg_keep_prob_tensor_name = 'keep_prob:0'
vgg_layer3_out_tensor_name = 'layer3_out:0'
vgg_layer4_out_tensor_name = 'layer4_out:0'
vgg_layer7_out_tensor_name = 'layer7_out:0'
# load pre-train vgg model to current session
model = tf.saved_model.loader.load(sess, [vgg_tag], vgg_path)
graph = tf.get_default_graph()
image_input = graph.get_tensor_by_name(vgg_input_tensor_name)
keep_prob = graph.get_tensor_by_name(vgg_keep_prob_tensor_name)
layer3_out = graph.get_tensor_by_name(vgg_layer3_out_tensor_name)
layer4_out = graph.get_tensor_by_name(vgg_layer4_out_tensor_name)
layer7_out = graph.get_tensor_by_name(vgg_layer7_out_tensor_name)
return image_input, keep_prob, layer3_out, layer4_out, layer7_out
Step 2
构建FCN网络,我们将使用从VGG-16中获得网络层,作为 编码器,然后对它使用 1x1的卷积层,滤镜数为分类数,再使用 跨层链接 和 上取样 连接上 解码器.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes):
"""
Create the layers for a fully convolutional network. Build skip-layers using the vgg layers.
:param vgg_layer3_out: TF Tensor for VGG Layer 3 output
:param vgg_layer4_out: TF Tensor for VGG Layer 4 output
:param vgg_layer7_out: TF Tensor for VGG Layer 7 output
:param num_classes: Number of classes to classify
:return: The Tensor for the last layer of output
"""
layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out
# use a 1*1 conv to extract feature instead of fully connected layer
fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8")
# use step by step upsample conv to get the original size of class mask for image
fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.shape.as_list()[-1],
kernel_size=4, strides=(2, 2), padding="SAME", name="fcn9")
# use skip_connected, so the output will have a higher resolution
fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4")
fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.shape.as_list()[-1],
kernel_size=4, strides=(2, 2), padding="SAME", name="fcn10_conv2d")
fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3")
fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes,
kernel_size=16, strides=(8, 8), padding="SAME", name="fcn11")
return fcn11
Step 3
这一步是优化我们的神经网络,也就是构建损失函数,还有优化器运算符.这里使用交叉墒作为损失函数,Adam作为优化器.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes):
"""
Build the TensorFLow loss and optimizer operations.
:param nn_last_layer: TF Tensor of the last layer in the neural network
:param correct_label: TF Placeholder for the correct label image
:param learning_rate: TF Placeholder for the learning rate
:param num_classes: Number of classes to classify
:return: Tuple of (logits, train_op, cross_entropy_loss)
"""
logits = tf.reshape(nn_last_layer, [-1, num_classes], name="fcn_logits")
correct_label_reshaped = tf.reshape(correct_label, [-1, num_classes])
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped[:])
loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss")
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss_op, name="fcn_train_op")
return logits, train_op, loss_op
Step 4
这一步我们将定义训练函数train_nn
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image,
correct_label, keep_prob, learning_rate):
"""
Train neural network and print out the loss during training.
:param sess: TF Session
:param epochs: Number of epochs
:param batch_size: Batch size
:param get_batches_fn: Function to get batches of training data. Call using get_batches_fn(batch_size)
:param train_op: TF Operation to train the neural network
:param cross_entropy_loss: TF Tensor for the amount of loss
:param input_image: TF Placeholder for input images
:param correct_label: TF Placeholder for label images
:param keep_prob: TF Placeholder for dropout keep probability
:param learning_rate: TF Placeholder for learning rate
"""
for epoch in range(epochs):
total_loss = 0
for X_batch, gt_batch in get_batches_fn(batch_size):
loss, _ = sess.run([cross_entropy_loss, train_op], feed_dict={input_image: X_batch,
correct_label:gt_batch,
keep_prob:FLAGS.DROPOUT,
learning_rate: FLAGS.LEARNING_RATE})
total_loss += loss
print("EPOCH {} ...".format(epoch + 1))
print("Loss = {:.3f}".format(total_loss))
print()
with open(log_file, "a") as f:
f.write("{}:Epoch:{}, Loss:{:.3}\n".format(datetime.now(), epoch+1, total_loss))
Step 5
最后一步,训练网络.在这一步中,我们将加载训练数据,还会调用我们前面构建的所有函数来FCN进行训练.训练完成之后会输出训练结果,把预测的数据保存起来.
def run():
correct_label = tf.placeholder(tf.float32, [None, image_shape[0], image_shape[1], num_classes])
learning_rate = tf.placeholder(tf.float32)
# Download pretrained vgg model
helper.maybe_download_pretrained_vgg(data_dir)
with tf.Session() as sess:
# Path to vgg model
vgg_path = os.path.join(data_dir, 'vgg')
# Create function to get batches
get_batches_fn = helper.gen_batch_function(os.path.join(data_dir, 'data_road/training'), image_shape)
input_image, keep_prob, layer3, layer4, layer7 = load_vgg(sess, vgg_path)
model_output = layers(layer3, layer4, layer7, num_classes)
logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
print("Model bulid successful, starting training")
train_nn(sess, FLAGS.EPOCHS, FLAGS.BATCH_SIZE, get_batches_fn,
train_op, cross_entropy_loss, input_image,
correct_label, keep_prob, learning_rate)
# Save inference data using helper.save_inference_samples
helper.save_inference_samples(output_dir, data_dir, sess, image_shape, logits, keep_prob, input_image)
关于超参,我们选择
epochs=40,
batch_size=16,
num_class=2,
image_shape=(160,576).
训练了dropout=0.1,
dropout=0.25,
dropout=0.5,
dropout=0.75,
keep_prob=1.0.
虽然从losses的平均值来看dropout=0.5的最低,但是从下图可以看出,dropout=0.75预测效果最好.
