MySQL,JDBC, 数据库连接池及XML
数据库
MYSQL数据库
- 数据库(DataBase) 就是存储和管理数据的仓库
- 其本质是一个文件系统, 还是以文件的方式,将数据保存在电脑上
Mac上MYSQL的安装
How to Install MySQL on Mac & Configure MySQL in Terminal
- 查看mysql数据
# 查看mysql安装的目录 $ which mysql $ open 查看到的目录data 目录默认是没有权限查看的,右键get info,修改权限就可以查看
MYSQL常用命令
-
mysql.server start 启动mysql
-
mysql.server stop 停止mysql
-
mysql.server restart 重启mysql
-
mysql.server status 查看mysql是否在运行
- mysql -u 用户名 -p 密码
使用指定用户名和密码登录当前计算机中的MySQL数据库
mysql -uroot -p123456 mysql -h127.0.0.1 -uroot -p123456 -
mysql -h 主机IP -u 用户名 -p 密码 -h 指定IP 方式,进行 登录
- exit 或者 quit 退出
数据库管理系统
-
数据库管理系统 数据库管理系统(DataBase Management System,DBMS):指一种操作和管理维护数据库的大 型软件。
MySQL就是一个 数据库管理系统软件, 安装了Mysql的电脑,我们叫它数据库服务器. -
数据库管理系统的作用 用于建立、使用和维护数据库,对数据库进行统一的管理
-
数据库管理系统、数据库 和表之间的关系 MySQL中管理着很多数据库,在实际开发环境中 一个数据库一般对应了一个的应用,数据库当中保
存着多张表,每一张表对应着不同的业务,表中保存着对应业务的数据。 -
数据库表
- 数据库中以表为组织单位存储数据
- 表类似我们Java中的类,每个字段都有对应的数据类型
- 对应关系如下
类 -----> 表 类中属性 ----> 表中字段 对象 ---> 数据记录
SQL
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统
- 通用语法
- SQL语句可以单行 或者 多行书写,以分号 结尾 ;
- 可以使用空格和缩进来增加语句的可读性。
- MySql中使用SQL不区分大小写,一般关键字大写,数据库名 表名列名 小写。
- 注释方式
# show databases; 单行注释 -- show databases; 单行注释 /* 多行注释 show databases; */
-
数据定义语言DDL 简称DDL(Data Definition Language),用来定义数据库对象:数据库,表,列等
-
create database 数据库名;
-
create database 数据库名 character set 字符集; 创建指定名称的数据库,并且指定字符集(一般都指定utf-8)
-
use 数据库 切换数据库
-
select database(); 查看当前正在使用的数据库
-
show databases; 查看Mysql中 都有哪些数据库
-
show create database 数据库名; 查看一个数据库的定义信息
-
alter database 数据库名 character set 字符集; 数据库的字符集修改操作
-
drop database 数据库名 从MySql中永久的删除某个数据库
-
创建表
-
数据类型
-
int 整型
-
double 浮点型
-
varchar 字符串型,长度可变
- char 字符串类型,长度不可变
-
date 日期类型,给是为 yyyy-MM-dd ,只有年月日,没有时分秒
-
datetime Yyyy-MM-dd HH:mm:ss
-
varchar vs char MySQL中的 char类型与 varchar类型,都对应了 Java中的字符串类型,区别在于:
- char类型是固定长度的: 根据定义的字符串长度分配足够的空间。
- varchar类型是可变长度的: 只使用字符串长度所需的空间
比如: 保存字符串“abc”
x char(10)占用10个字节 y varchar(10)占用3个字节适用场景:
- char类型适合存储 固定长度的字符串,比如 密码 ,性别一类
- varchar类型适合存储 在一定范围内,有长度变化的字符串
-
-
CREATE TABLE 创建一个表格
CREATE TABLE 表名( 字段名称1 字段类型(长度), 字段名称2 字段类型 注意 最后一列不要加逗号 ); -
create table 新表明 like 旧表名 快速创建一个表结构相同的表(复制表结构)
-
-
查看表
-
show tables; 查看当前数据库中的所有表名
-
desc 表名; 查看数据表的结构
-
SHOW CREATE TABLE tableName; 查看创建表的SQL语句
-
-
删除表
-
drop table 表名; 删除表(从数据库中永久删除某一张表)
-
drop table if exists 表名; 判断表是否存在, 存在的话就删除,不存在就不执行删除
-
-
修改表
-
rename table 旧表名 to 新表名 修改表名
-
alter table 表名 character set 字符集 修改表的字符集
-
alter table 表名 add 字段名称 字段类型 向表中添加列, 关键字 ADD
-
alter table 表名 modify 字段名称 字段类型 修改表中列的 数据类型或长度 , 关键字 MODIFY
-
alter table 表名 change 旧列名 新列名 类型(长度); 修改列名称 , 关键字 CHANGE
-
alter table 表名 drop 列名; 删除列 ,关键字 DROP
-
-
-
数据操作语言DML 简称DML(Data Manipulation Language),用来对数据库中表的记录进行更新。
-
插入数据
- insert into 表名 (字段名1,字段名2…) values(字段值1,字段值2…);
- 插入全部字段, 将所有字段名都写出来
INSERT INTO student (sid,sname,age,sex,address) VALUES(1,'孙悟空',20,'男','花果 山'); - 插入全部字段,不写字段名
INSERT INTO student VALUES(2,'孙悟饭',10,'男','地球'); - 插入指定字段的值
INSERT INTO category (cname) VALUES('白骨精');注意⚠️:
- 值与字段必须要对应,个数相同&数据类型相同
- 值的数据大小,必须在字段指定的长度范围内
- varchar char date类型的值必须使用单引号,或者双引号 包裹。
- 如果要插入空值,可以忽略不写,或者插入null
- 如果插入指定字段的值,必须要上写列名
- 插入全部字段, 将所有字段名都写出来
- insert into 表名 (字段名1,字段名2…) values(字段值1,字段值2…);
-
更新数据
-
update 表名 set 列名 = 值, 列名 = 值,… 不带条件的修改
-
update 表名 set 列名 = 值 where 条件表达式:字段名 = 值 带条件的修改
-
-
删除数据
- delete from 表名
删除所有数据
不推荐. 有多少条记录 就执行多少次删除操作. 效率低
-
truncate table 表名 删除整张表的数据
> 推荐. 先删除整张表, 然后再重新创建一张一模一样的表. 效率高 - delete from 表名 where 字段名 = 值 指定条件 删除数据
- delete from 表名
删除所有数据
-
-
数据查询语言DQL 简称DQL(Data Query Language),用来查询数据库中表的记录
- select 列名 from 表名
-- list the datas with a new column name SELECT eid AS '编号', ename as '姓名', sex as '性别', salary as '薪资', hire_date as '入职时间', dept_name as '部门名称' FROM emp; -- list all the dept_name from emp SELECT dept_name FROM emp; -- list all the diffent dept_name from emp without duplication SELECT DISTINCT dept_name FROM emp; -- list ename, and salary, show salary with +1000 SELECT ename,salary+1000 AS SALARY FROM emp; SELECT ename,salary AS SALARY FROM emp; -
select 列名 from 表名 where 条件表达式
-
运算符
-
< <= >= = <> != 大于、小于、大于(小于)等于、不等于
-
BETWEEN …AND… 显示在某一区间的值
例如: 2000-10000之间: Between 2000 and 10000 -
IN(集合) 集合表示多个值,使用逗号分隔,例如: name in (悟空,八戒) in中的每个数据都会作为一次条件,只要满足条件就会显示
-
LIKE ‘%张%’ 模糊查询
通配符:%表示任意长度的字符
通配符: _ 表示一个字符 - IS NULL 查询某一列为NULL的值, 注: 不能写 = NULL
-
-
逻辑运算符
-
And && 多个条件同时成立
-
Or || 多个条件任一成立
-
Not 不成立,取反
-
-
示例代码
# 查询员工姓名为黄蓉的员工信息 SELECT * FROM emp where ename = '黄蓉'; # 查询薪水价格为5000的员工信息 SELECT * FROM emp WHERE salary = 5000; # 查询薪水价格不是5000的所有员工信息 SELECT * FROM emp WHERE salary != 5000; SELECT * FROM emp WHERE salary <> 5000; # 查询薪水价格大于6000元的所有员工信息 SELECT * FROM emp WHERE salary > 6000; # 查询薪水价格在5000到10000之间所有员工信息 SELECT * FROM emp WHERE salary >= 5000 AND salary <= 10000; SELECT * FROM emp WHERE salary BETWEEN 5000 AND 10000; # 查询薪水价格是3600或7200或者20000的所有员工信息 SELECT * FROM emp WHERE salary = 3600 OR salary = 7200 OR salary = 20000; SELECT * FROM emp WHERE salary IN (3600, 7200, 20000); # % 表示匹配任意多个字符串 # _ 表示匹配一个字符 # 查询含有'精'字的所有员工信息 SELECT * FROM emp WHERE ename LIKE '%精%'; # 查询以'孙'开头的所有员工信息 SELECT * FROM emp WHERE ename LIKE '孙%'; # 查询第二个字为'兔'的所有员工信息 SELECT * FROM emp WHERE ename LIKE '_兔%'; # 查询没有部门的员工信息 SELECT * FROM emp WHERE dept_name IS NULL; # 查询有部门的员工信息 SELECT * FROM emp WHERE dept_name IS NOT NULL;
-
- ORDER BY
SELECT 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC / DESC]
-- 默认升序排序 ASC SELECT * FROM emp ORDER BY salary; -- 降序排序 SELECT * FROM emp ORDER BY salary DESC;- 组合排序
-- dual order, if first value equal, order the with second value SELECT * FROM emp ORDER BY salary DESC, eid DESC;
- 组合排序
-
SELECT 聚合函数(字段名) FROM 表名; 之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵
向查询,它是对某一列的值进行计算,然后返回一个单一的值(另外聚合函数会忽略null空值。)-
聚合函数 聚合,纵向统计, count, sum, max, min, avg
-
案例
#1 查询员工的总数 SELECT COUNT(*) AS total_count FROM emp; SELECT COUNT(1) AS total_count FROM emp; -- counting skip null value SELECT COUNT(dept_name) AS total_count FROM emp; #2 查看员工总薪水、最高薪水、最小薪水、薪水的平均值 SELECT SUM(salary) as salary_sum, MAX(salary) as salary_max, MIN(salary) as salary_min, AVG(salary) as salary_avg FROM emp; #3 查询薪水大于4000员工的个数 SELECT count(*) AS '薪水大于4000员工的个数' FROM emp WHERE salary > 4000; -- SELECT * FROM emp WHERE salary > 4000; #4 查询部门为'教学部'的所有员工的个数 SELECT COUNT(*) AS '教学部人数' FROM emp WHERE dept_name = '教学部'; #5 查询部门为'市场部'所有员工的平均薪水 SELECT AVG(salary) AS "'市场部'所有员工的平均薪水" FROM emp WHERE dept_name = '市场部';
-
-
GROUP BY 分组查询指的是使用 GROUP BY 语句,对查询的信息进行分组,相同数据作为一组
- SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];
#1.查询所有部门信息 SELECT dept_name AS '部门信息' FROM emp GROUP BY dept_name; #2.查询每个部门的平均薪资 SELECT dept_name AS '部门', AVG(salary) AS '平均工资' FROM emp GROUP BY dept_name; #3.查询每个部门的平均薪资, 部门名称不能为null SELECT dept_name AS '部门', AVG(salary) AS '平均工资' FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name; #4.查询平均薪资大于6000的部门 SELECT dept_name, AVG(salary) FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name HAVING AVG(salary) > 6000; - WHERE VS HAVING
- where: where 进行分组前的过滤, where 后面不能写 聚合函数
- having: having 是分组后的过滤, having 后面可以写 聚合函数
- SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];
- limit关键字
- limit是限制的意思,用于 限制返回的查询结果的行数 (可以通过limit指定查询多少行数据)
-
limit 语法是 MySql的方言,用来完成分页
- SELECT 字段1,字段2… FROM 表名 LIMIT offset , length;
-- LIMIT # 查询emp表中的前 5条数据 SELECT * FROM emp LIMIT 0, 5; SELECT * FROM emp LIMIT 5; # 查询emp表中 从第4条开始,查询6条 SELECT * FROM emp LIMIT 3, 6; # 分页操作 每页显示3条数据 SELECT * FROM emp LIMIT 0, 3; SELECT * FROM emp LIMIT 3, 3; SELECT * FROM emp LIMIT 6, 3; SELECT * FROM emp LIMIT 9, 3;
- SELECT 字段1,字段2… FROM 表名 LIMIT offset , length;
- 多表查询
- 内连接: inner join , 只获取两张表中 交集部分的数据.
- 左外连接: left join , 以左表为基准 ,查询左表的所有数据, 以及与右表有交集的部分
-
右外连接: right join , 以右表为基准,查询右表的所有的数据,以及与左表有交集的部分
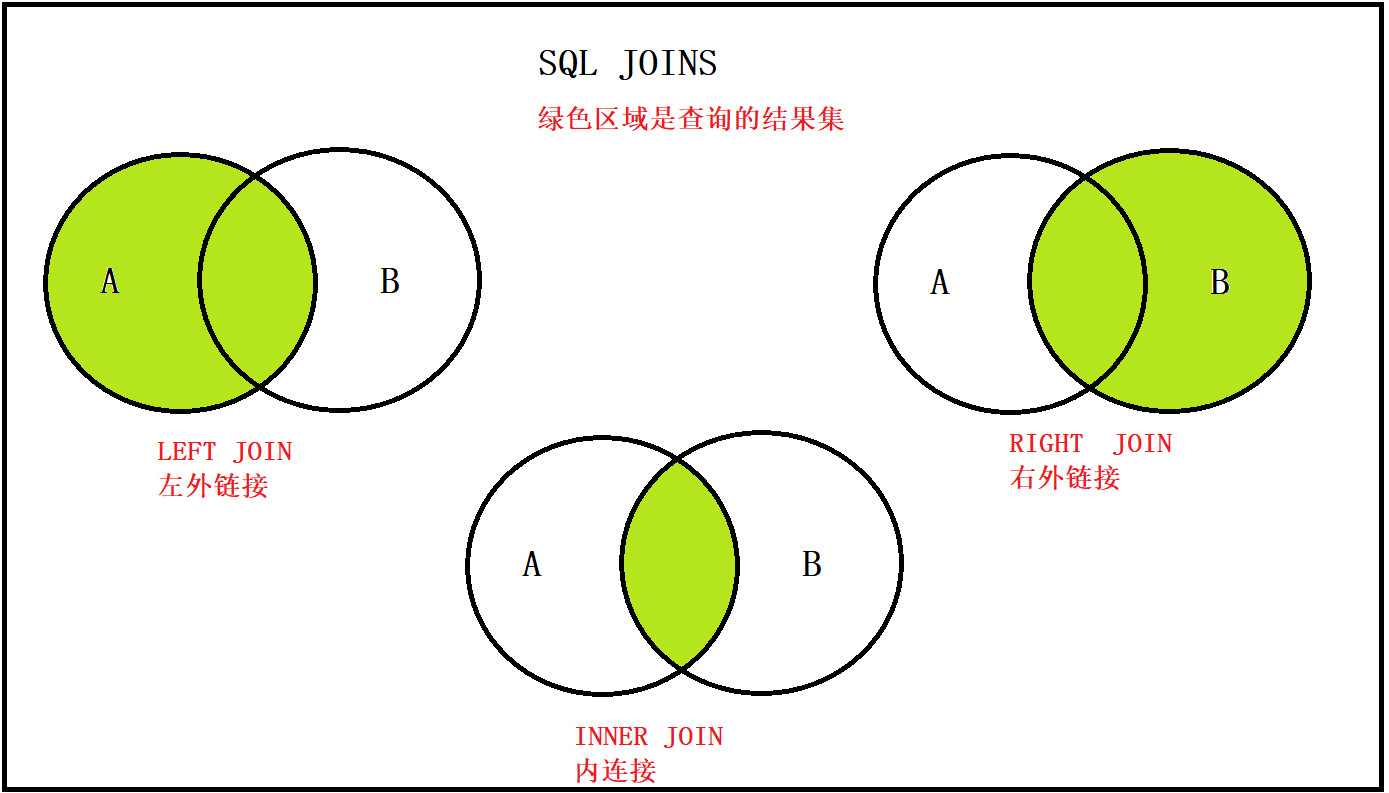
-
SELECT 字段名 FROM 表1, 表2; 交叉连接查询,因为会产生笛卡尔积,所以 基本不会使用
-
内连接查询 通过指定的条件去匹配两张表中的数据, 匹配上就显示,匹配不上就不显示
-
隐式内连接 from子句 后面直接写 多个表名 使用where指定连接条件的 这种连接方式是 隐式内连接. 使用where条件过滤无用的数据
- SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;
-- ------------------------------ -- 隐式内连接 SELECT * FROM products, category WHERE category_id=cid; -- 查询商品表的商品名称 和 价格,以及商品的分类信息 -- 起别名 SELECT p.pname, p.price, c.cname FROM products p, category c WHERE p.category_id=c.cid; -- 查询 格力空调是属于哪一分类下的商品 SELECT p.pname, c.cname FROM products p, category c WHERE p.category_id=c.cid AND p.pname='格力空调';
- SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;
-
显式内连接 使用 inner join …on 这种方式, 就是显式内连接
- SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件
-- 显式内连接 SELECT * FROM products p INNER JOIN category c ON p.category_id=c.cid; SELECT * FROM products p JOIN category c ON p.category_id=c.cid; -- 查询鞋服分类下,价格大于500的商品名称和价格 SELECT p.pname, p.price FROM products p INNER JOIN category c ON p.category_id=c.cid WHERE p.price > 500 AND c.cname='鞋服';
- SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件
-
-
外链接查询
- 左外链接
- 以左表为基准, 匹配右边表中的数据,如果匹配的上,就展示匹配到的数据
-
如果匹配不到, 左表中的数据正常展示, 右边的展示为null.
- SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件
-- LEFT OUTER JOIN /* base on the left table, if there's right table values show them, else show null */ SELECT * FROM category c LEFT JOIN products p ON c.cid=p.category_id; -- 左外连接, 查询每个分类下的商品个数 SELECT c.cname AS 'category', -- 使用COUNT(*),null 也会被算上 COUNT(p.pid) AS 'count' FROM category c LEFT JOIN products p ON c.cid=p.category_id GROUP BY c.cname;
- SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件
- 右外链接
- 以右表为基准,匹配左边表中的数据,如果能匹配到,展示匹配到的数据
-
如果匹配不到,右表中的数据正常展示, 左边展示为null
- SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件
/* base on the right table, if there's left table values show them, else show null */ -- RIGHT JOIN SELECT * FROM products p RIGHT JOIN category c ON c.cid=p.category_id;
- SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件
- 左外链接
-
-
子查询 一条select 查询语句的结果, 作为另一条 select 语句的一部分
特点:
* 子查询必须放在小括号中
* 子查询一般作为父查询的查询条件使用-
where型 子查询 将子查询的结果, 作为父查询的比较条件
- SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
#通过子查询的方式, 查询价格最高的商品信息 SELECT * FROM products WHERE price=(SELECT MAX(price) FROM products); #查询化妆品分类下的 商品名称 商品价格 SELECT cid FROM category c WHERE c.cname='化妆品'; SELECT p.pname, p.price FROM products p WHERE p.category_id=(SELECT cid FROM category c WHERE c.cname='化妆品'); #查询小于平均价格的商品信息 SELECT AVG(price) FROM products; SELECT * FROM products p WHERE p.price<(SELECT AVG(price) FROM products);
- SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
-
from型 子查询 将子查询的结果, 作为 一张表,提供给父层查询使用
- SELECT 查询字段 FROM (子查询)表别名 WHERE 条件;
-- SELECT 查询字段 FROM (子查询)表别名 WHERE 条件; # 查询商品中,价格大于500的商品信息,包括 商品名称 商品价格 商品所属分类名称 SELECT * FROM products WHERE price>500; SELECT p.pname, p.price, c.cname FROM (SELECT * FROM products WHERE price>500) p JOIN category c ON p.category_id=c.cid;
- SELECT 查询字段 FROM (子查询)表别名 WHERE 条件;
-
exists型 子查询 子查询的结果是单列多行, 类似一个数组, 父层查询使用 IN 函数 ,包含子查 询的结果
- SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
-- SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询); # 查询价格小于两千的商品,来自于哪些分类(名称) SELECT DISTINCT category_id FROM products WHERE price<2000; SELECT cname FROM category WHERE cid IN (SELECT DISTINCT category_id FROM products WHERE price<2000); #查询家电类 与 鞋服类下面的全部商品信息 SELECT * FROM category WHERE cname IN ('家电', '鞋服'); SELECT * FROM products WHERE category_id IN (SELECT cid FROM category WHERE cname IN ('家电', '鞋服'));
- SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
-
- select 列名 from 表名
-
数据控制语言DCL 简称DCL(Data Control Language),用来定义数据库的访问权限和安全级别,及创建用户。
MySql默认使用的都是 root 用户,超级管理员,拥有全部的权限。除了root用户以外,我们还可以通 过DCL语言来定义一些权限较小的用户, 分配不同的权限来管理和维护数据库。- 创建用户
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码'; # 主机名: 指定该用户在哪个主机上可以登陆,本地用户可用 localhost 如果想让该用户可以 从任意远程主机登陆,可以使用通配符 % - 用户授权
GRANT 权限 1, 权限 2... ON 数据库名.表名 TO '用户名'@'主机名';权限: 授予用户的权限,如 CREATE、ALTER、SELECT、INSERT、UPDATE 等。 如果要授 予所有的权限则使用 ALL
ON: 用来指定权限针对哪些库和表, 如果是全部使用通配符 .示例代码
-- 指定 table 和 权限 GRANT SELECT, UPDATE ON db4.goods TO 'admin1'@'localhost'; -- 所有数据库 和 权限 GRANT ALL ON *.* TO 'admin2'@'%'; - 查看用户权限
SHOW GRANTS FOR '用户名'@'主机名'; # 示例代码 SHOW GRANTS FOR 'admin1'@'localhost'; - 删除用户
DROP USER '用户名'@'主机名'; - 查询用户
-- 查看所有用户 use mysql; SELECT * FROM USER;
- 创建用户
-
SQL约束 对表中的数据进行进一步的限制,从而保证数据的正确性、有效性、完整性.违反约束的不正确数据,将无法插入到表中
-
primary key 主键约束 :不可重复 唯一 非空, 用来表示数据库中的每一条记录
-- PRIMARY KEY, not null and unique -- way 1 CREATE TABLE emp2 ( eid INT PRIMARY KEY, ename VARCHAR(20), sex CHAR(1) ); DESC emp2; DROP TABLE emp2; -- way 2 CREATE TABLE emp2 ( eid INT, ename VARCHAR(20), sex CHAR(1), PRIMARY KEY(eid) ); DESC emp2; DROP TABLE emp2; -- way 3 CREATE TABLE emp3 ( eid INT, ename VARCHAR(20), sex CHAR(1) ); ALTER TABLE emp3 ADD PRIMARY KEY(eid); -- --------------------- DESC emp3; SHOW TABLES; INSERT INTO emp3 VALUES(1, 'haha', 'm'); -- 1062 - Duplicate entry '1' for key 'PRIMARY', Time: 0.000000s INSERT INTO emp3 VALUES(1, 'haha', 'm'); -- 1048 - Column 'eid' cannot be null, Time: 0.000000s INSERT INTO emp3 VALUES(NULL, 'haha', 'm'); INSERT INTO emp3 (eid, ename, sex) VALUES(2, 'haha', 'm'); -- 1364 - Field 'eid' doesn't have a default value, Time: 0.000000s INSERT INTO emp3 (ename, sex) VALUES('yes', 'm'); -- DELETE PRIMARY KEY ALTER TABLE emp3 DROP PRIMARY KEY;-
AUTO_INCREMENT AUTO_INCREMENT 表示自动增长(字段类型必须是整数类型)
-- AUTO_INCREMENT CREATE TABLE emp2 ( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), sex CHAR(1) ); INSERT INTO emp2(ename,sex) VALUES('张三','男'); … SELECT * FROM emp2; DROP TABLE emp2; -- set the start number 100 CREATE TABLE emp2 ( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), sex CHAR(1) )AUTO_INCREMENT=100; INSERT INTO emp2(ename,sex) VALUES('张三','男'); …- DELETE vs TRUNCATE
DELETE: 只是删除表中所有数据,对自增没有影响
TRUNCATE: truncate 是将整个表删除掉,然后创建一个新的表 自增的主键,重新从 1开始
- DELETE vs TRUNCATE
DELETE: 只是删除表中所有数据,对自增没有影响
-
- NOT NULL
某一列不予许为空
字段名 字段类型 not null-- NOT NULL CREATE TABLE emp2 ( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20) NOT NULL, gender CHAR(1) ); -- 1048 - Column 'ename' cannot be null, Time: 0.000000s INSERT INTO emp2 VALUES(NULL, NULL, 'm'); INSERT INTO emp2 VALUES(NULL, 'Hello', 'm'); - UNIQUE
表中的某一列的值不能重复( 对null不做唯一的判断 )
语法:字段名 字段类型 not null-- UNIQUE CREATE TABLE emp3 ( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20) UNIQUE, gender CHAR(1) ); INSERT INTO emp3 VALUES(NULL, 'Hello', 'm'); -- 1062 - Duplicate entry 'Hello' for key 'ename', Time: 0.002000s INSERT INTO emp3 VALUES(NULL, 'Hello', 'm'); INSERT INTO emp3 VALUES(NULL, NULL, 'm'); - DEFAULT
用来指定某列的默认值
语法:字段名 字段类型 DEFAULT 默认值CREATE TABLE emp4 ( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20) UNIQUE, gender CHAR(1) DEFAULT 'F' ); INSERT INTO emp4 (ename) VALUES('Britney'); INSERT INTO emp4 (ename) VALUES('Sara'); INSERT INTO emp4 (ename, gender) VALUES('Sam', 'M'); - FOREIGN KEY
外键约束
- 外键指的是在 从表 中 与 主表 的主键对应的那个字段,比如员工表的 dept_id,就是外键
- 使用外键约束可以让两张表之间产生一个对应关系,从而保证主从表的引用的完整性
- 多表关系中的主表和从表
- 主表: 主键id所在的表, 约束别人的表
-
从表: 外键所在的表多, 被约束的表
- 语法格式
- 新建表是添加外键
[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名) - 已有表添加外键
ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名) REFERENCES 主表(主 键字段名);后添加外键约束时,如果表中有不符合约束的数据,需要删除掉才是添加成功
- 删除外键约束
alter table 从表 drop foreign key 外键约束名称
-- 创建部门表 -- 一方,主表 CREATE TABLE department( id INT PRIMARY KEY AUTO_INCREMENT, dep_name VARCHAR(30), dep_location VARCHAR(30) ); -- 创建员工表 -- 多方 ,从表 CREATE TABLE employee( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), age INT, dept_id INT ); -- 添加2个部门 INSERT INTO department VALUES(NULL, '研发部','广州'),(NULL, '销售部', '深圳'); SELECT * FROM department; -- 添加员工,dep_id表示员工所在的部门 INSERT INTO employee (ename, age, dept_id) VALUES ('张百万', 20, 1); INSERT INTO employee (ename, age, dept_id) VALUES ('赵四', 21, 1); INSERT INTO employee (ename, age, dept_id) VALUES ('广坤', 20, 1); INSERT INTO employee (ename, age, dept_id) VALUES ('小斌', 20, 2); INSERT INTO employee (ename, age, dept_id) VALUES ('艳秋', 22, 2); INSERT INTO employee (ename, age, dept_id) VALUES ('大玲子', 18, 2); SELECT * FROM employee; INSERT INTO employee (ename, age, dept_id) VALUES ('lala', 18, 3); SELECT * FROM employee; DELETE FROM employee WHERE dept_id=3; -- ADD FOREIGN KEY with name ALTER TABLE employee ADD CONSTRAINT emp_dept_kf FOREIGN KEY(dept_id) REFERENCES department(id); -- DELETE FOREIGN KEY with name ALTER TABLE employee DROP FOREIGN KEY emp_dept_kf; DROP TABLE employee; -- add FOREIGN KEY when create table CREATE TABLE employee( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), age INT, dept_id INT, CONSTRAINT emp_dept_kf FOREIGN KEY(dept_id) REFERENCES department(id) ); - 新建表是添加外键
- 注意事项
- 从表外键类型必须与主表主键类型一致 否则创建失败.
- 添加数据时, 应该先添加主表中的数据.
- 删除数据时,应该先删除从表中的数据.
-
ON DELETE CASCADE 级联删除: 如果想实现删除主表数据的同时,也删除掉从表数据,可以使用级联删除操作
-- 重新创建添加级联操作 CREATE TABLE employee( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), age INT, dept_id INT, CONSTRAINT emp_dept_fk FOREIGN KEY(dept_id) REFERENCES department(id) -- 添加级联删除 ON DELETE CASCADE ); - 多表设计
/* 多对一, 省份与市 */ use db3; CREATE TABLE province ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(30), description VARCHAR(100) ); CREATE TABLE city ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(30), description VARCHAR(100), pid INT, CONSTRAINT city_province_key FOREIGN KEY(pid) REFERENCES province(id) ); /* 多对多,演员与角色 */ CREATE TABLE actor ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(30) ); CREATE TABLE role ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(30) ); -- 用来记录多对多关系的表 CREATE TABLE arconnector ( id INT PRIMARY KEY AUTO_INCREMENT, aid INT, rid INT, FOREIGN KEY(aid) REFERENCES actor(id), FOREIGN KEY(rid) REFERENCES role(id) ); /* 一对一, 学生和身份证 */ CREATE TABLE idcard ( id INT PRIMARY KEY AUTO_INCREMENT, idNum CHAR(11) ); CREATE TABLE student ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(30), -- 设置外键唯一,这样才会出现一对一 iid INT UNIQUE, FOREIGN KEY(iid) REFERENCES idcard(id) );
-
-
SQL事务 事务是一个整体,由一条或者多条SQL 语句组成,这些SQL语句要么都执行成功,要么都执行失败, 只要有 一条SQL出现异常,整个操作就会回滚,整个业务执行失败
-
回滚:即在事务运行的过程中发生了某种故障,事务不能继续执行,系统将事务中对数据库的所有已完成的操作全部撤销,滚回到事务开始时的状态。(在提交之前执行)
-
手动提交事务
-
start transaction; 或者 BEGIN; 这个语句显式地标记一个事务的起始点。
-
commit; 表示提交事务,即提交事务的所有操作,具体地说,就是将事务中所有对数据库的更新都写到磁盘上的物理数据库中,事务正常结束。
-
rollback; 表示撤销事务,即在事务运行的过程中发生了某种故障,事务不能继续执行,系统将事务中对数据库的所有已完成的操作全部撤销,回滚到事务开始时的状态
-
-
自动提交事务 MySQL 默认每一条 DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,语句 执行完毕 自动提交事务,MySQL 默认开始自动提交事务
关闭环境变量 autocommit,把默认开启的自动提交transaction关掉
mysql> show variables LIKE 'autocommit'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | autocommit | ON | +---------------+-------+ 1 row in set (0.00 sec) mysql> SET autocommit=OFF; Query OK, 0 rows affected (0.00 sec) mysql> show variables LIKE 'autocommit'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | autocommit | OFF | +---------------+-------+ 1 row in set (0.00 sec) -
事务的四大特性ACID
-
原子性 每个事务都是一个整体,不可再拆分,事务中所有的 SQL 语句要么都执行成功, 要么都 失败。
-
一致性 事务在执行前数据库的状态与执行后数据库的状态保持一致。如:转账前2个人的 总金额 是 2000,转账后 2 个人总金额也是 2000.
-
隔离性 事务与事务之间不应该相互影响,执行时保持隔离的状态.
-
数据并发访问 一个数据库可能拥有多个访问客户端,这些客户端都可以并发方式访问数据库. 数据库的相同数据可能被多个事务同时访问,如果不采取隔离措施,就会导致各种问题, 破坏数据的完整性
-
并发可能产生的问题
-
脏读 一个事务读取到了另一个事务中尚未提交的数据
1. 隔离级别是 read uncommitted 2. A、B窗口开始事务 3. B窗口查询数据 4. A窗口修改数据 5. B窗口查询数据,发现改了 6. A窗口rollback 7. B窗口查询到数据又改回去了理想的结果是B只能读到A commit后的结果,通过把隔离级别设置为read committed能解决
-
不可重复读 一个事务中两次读取的数据内容不一致,要求的是在一个事务中多次读取时数据是一致的。这是进行update操作引发的问题
1. 隔离级别是 read committed 或更低 2. A、B窗口开始事务 3. B窗口查询数据 4. A窗口开启事务修改数据,并commit 5. B窗口查询数据,发现改了理想的结果是,B窗口前后查询到数据一致,通过把隔离级别设置为repeatable read可以解决这个问题
-
幻读 一个事务中,某次的select操作得到的结果所表征的数据状态,无法支持后续的业务操作。查询得到的数据状态不准确,导致幻读
1. 隔离级别是 repeatable read 2. A、B窗口开始事务 3. B窗口查询数据 4. A窗口开启事务修改数据,并commit 5. B窗口执行和A窗口修改同一条数据,发现修改之后的结果不准确,或出现错误通过把隔离级别设置为serializable 可以解决这个问题, serializable 串行化可以彻底解决幻读,但是 事务只能排队执行,严重影响效率, 数据库不会使用这种隔离级别
-
-
-
四种隔离级别 不同的隔离级别可以避免不同级别的并发问题
-
read uncommitted 读未提交:会出现所有并发问题
-
Read committed 读已提交:可以避免脏读
-
Repeatable read 可重复读:可以避免脏读,不可重复读
MySQL默认的隔离级别 -
serializable 串行化:可以避免所有并发问题, 给数据库加上线程锁
-
- 查看隔离级别
select @@tx_isolation; -
修改隔离级别 设置事务隔离级别,需要退出 MySQL 再重新登录才能看到隔离级别的变化
/* 设置数据库隔离级别 set global transaction isolation level 级别名称; read uncommitted 读未提交 read committed 读已提交 repeatable read 可重复读 serializable 串行化 */ -- show isolation level SELECT @@tx_isolation; SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-
-
持久性 一旦事务执行成功,对数据库的修改是持久的。就算关机,数据也是要保存下来的.
-
-
-
-
数据库设计
-
数据库三范式 为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据 库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关 系型数据库,必须满足一定的范式
- 第一范式1NF
- 原子性, 做到列不可拆分
- 第一范式是最基本的范式。数据库表里面字段都是单一属性的,不可再分, 如果数据表中每个 字段都是不可再分的最小数据单元,则满足第一范式。
- 第二范式2NF
- 在第一范式的基础上更进一步,目标是确保表中的每列都和主键相关。
- 一张表只能描述一件事.
- 第三范式3NF
- 消除传递依赖
- 表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放
- 第一范式1NF
-
数据库反三范式
- 反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能
-
浪费存储空间,节省查询时间 (以空间换时间)
- 添加冗余字段 设计数据库时,某一个字段属于一张表,但它同时出现在另一个或多个表,且完全等同于它在其本来所属表的意义表示,那么这个字段就是一个冗余字段
-
- 视图
- 视图是一种虚拟表。
- 视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
- 向视图提供数据内容的语句为 SELECT 语句, 可以将视图理解为存储起来的 SELECT 语句.
- 视图向用户提供基表数据的另一种表现形式
- 作用
- 权限控制时可以使用
- 比如,某几个列可以运行用户查询,其他列不允许,可以开通视图 查询特定的列, 起到权限控制的作用
- 简化复杂的多表查询
- 视图 本身就是一条查询SQL,我们可以将一次复杂的查询 构建成一张视图, 用户只要查询视图 就可以获取想要得到的信息(不需要再编写复杂的SQL)
- 视图主要就是为了简化多表的查询
- 权限控制时可以使用
- 语法
create view 视图名 [column_list] as select语句; view: 表示视图 column_list: 可选参数,表示属性清单,指定视图中各个属性的名称,默认情况下,与SELECT语句中查询 的属性相同 as : 表示视图要执行的操作 select语句: 向视图提供数据内容 # 删除视图 DROP VIEW 视图名 # 显示视图创建信息 SHOW CREATE VIEW 视图名; # 显示视图信息 DESC 视图名;示例代码
-- CREATE A VIEW, A VIEW LIKE A READ ONLY TABLE CREATE VIEW products_category_view AS SELECT * FROM products p LEFT JOIN category c ON p.category_id = c.cid; -- 像表一样使用 SELECT * FROM products_category_view; - 视图与表的区别
- 视图是建立在表的基础上,表存储数据库中的数据,而视图只是做一个数据的展示
- 通过视图不能改变表中数据(一般情况下视图中的数据都是表中的列 经过计算得到的结果,不允许 更新)
- 删除视图,表不受影响,而删除表,视图不再起作用
-
存储过程
- 创建语法
DELIMITER $$ -- 声明语句结束符,可以自定义 一般使用$$ CREATE PROCEDURE 过程名称(IN 参数名 参数类型, …) -- 声明存储过程, 参数可不传 BEGIN -- 开始编写存储过程 -- 要执行的操作 END $$ -- 存储过程结束示例代码
-- create PROCEDURE DELIMITER $$ CREATE PROCEDURE goods_proc() BEGIN select * from goods; END $$ -- 调用存储过程 CALL goods_proc; # 接收一个商品id, 根据id删除数据 DELIMITER $$ -- 传入参数的方式创建 CREATE PROCEDURE delete_product(IN pid INT) BEGIN DELETE FROM goods WHERE gid=pid; END$$ CALL delete_product(2); DELIMITER$$ -- 多个输入参数,可以省略后面的IN CREATE PROCEDURE search_product(IN pid INT, name VARCHAR(20)) BEGIN SELECT * FROM goods WHERE gid=pid AND NAME=name; END$$ CALL search_product(1, '奶茶'); -- 有输入输出的存储过程 DELIMITER$$ CREATE PROCEDURE orders_proc(IN o_oid INT, IN o_gid INT, IN o_price INT, OUT out_num INT) BEGIN INSERT INTO goods VALUES(o_oid, o_gid, o_price); -- 设置变量值 SET @out_num = 1; -- 返回变量值 SELECT @out_num; END$$ CALL orders_proc(1, 2, 50, @out_num); - 优缺点
- 优点:
- 存储过程一旦调试完成后,就可以稳定运行,(前提是,业务需求要相对稳定,没有变化)
- 存储过程减少业务系统与数据库的交互,降低耦合,数据库交互更加快捷(应用服务器,与数据库服务器不在同一个地区)
- 缺点:
- 在互联网行业中,大量使用MySQL,MySQL的存储过程与Oracle的相比较弱,所以较少使用,并且互联网行业需求变化较快也是原因之一
- 尽量在简单的逻辑中使用,存储过程移植十分困难,数据库集群环境,保证各个库之间存储过程变更一致也十分困难。
- 阿里的代码规范里也提出了禁止使用存储过程,存储过程维护起来的确麻烦;
- 优点:
- 创建语法
-
触发器 监视某个表的数据变更,满足条件之后执行触发器中的代码
- 创建语法
delimiter $ -- 将Mysql的结束符号从 ; 改为 $,避免执行出现错误 CREATE TRIGGER Trigger_Name -- 触发器名,在一个数据库中触发器名是唯一的 before/after(insert/update/delete) -- 触发的时机 和 监视的事件 on table_Name -- 触发器所在的表 for each row -- 固定写法 叫做行触发器, 每一行受影响,触发事件都执行 begin -- begin和end之间写触发事件 end $ -- 结束标记示例代码
DELIMITER $ CREATE TRIGGER t1 AFTER INSERT ON orders FOR EACH ROW BEGIN -- UPDATE goods SET num = num - 1 WHERE gid = 4; END $
- 创建语法
MySQL备份&还原
- 命令行备份
mysqldump -u 用户名 -p 密码 数据库 > 文件路径 示例代码 mysqldump -uroot -p123456 db2 > H:/db2.sqlmysqldump 是mysql目录下的一个应用
- 命令行还原
- 创建好database,选中database
- 执行sql脚本
```SQL
source sql文件地址
示例代码
source /Users/april/Desktop/backup/db2.sql
```
MySQL索引
在数据库表中,对字段建立索引可以大大提高查询速度。通过善用这些索引,可以令MySQL的查询和
运行更加高效。
-
索引的类型
-
主键索引 (primary key) 主键是一种唯一性索引,每个表只能有一个主键, 用于标识数据表中的每一 条记录
- 添加方式
# 创建表的时候直接添加主键索引 CREATE TABLE 表名( -- 添加主键 (主键是唯一性索引,不能为null,不能重复,) 字段名 类型 PRIMARY KEY, ); # 修改表结构 添加主键索引 ALTER TABLE 表名 ADD PRIMARY KEY ( 列名 ) - 删除方式
ALTER TABLE 表名 DROP PRIMARY KEY;
- 添加方式
-
唯一索引 (unique) 唯一索引指的是 索引列的所有值都只能出现一次, 必须唯一.
- 添加方式
# 创建表的时候直接添加唯一索引 CREATE TABLE 表名( 列名 类型(长度), -- 添加唯一索引 UNIQUE [索引名称] (列名) ); # 修改表结构 添加唯一索引 ALTER TABLE 表名 ADD UNIQUE [索引名] ( 列名 ) - 删除方式
ALTER TABLE 表名 DROP INDEX 索引名;
- 添加方式
-
普通索引 (index) 最常见的索引,作用就是 加快对数据的访问速度
-
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只 为那些最经常出现在查询条件(WHERE column=)或排序条件(ORDERBY column)中的数据列创建 索引。
- 添加方式
# 创建表的时候直接添加索引 CREATE TABLE 表名( 列名 类型(长度), -- 添加索引 INDEX [索引名称] (列名) ); ALTER TABLE 表名 ADD INDEX [索引名] (列名) - 删除方式
ALTER TABLE 表名 DROP INDEX 索引名;
- 添加方式
-
-
-
索引的优缺点
- 索引的优点
- 大大的提高查询速度
- 可以显著的减少查询中分组和排序的时间。
- 索引的缺点
- 创建索引和维护索引需要时间,而且数据量越大时间越长
- 当对表中的数据进行增加,修改,删除的时候,索引也要同时进行维护,降低了数据的维护速度
- 索引的优点
JDBC
- 定义: JDBC(Java Data Base Connectivity) 是 Java 访问数据库的标准规范.是一种用于执行SQL语句的Java API,可以为 多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。是Java访问数据库的标准规范.
- 说明: JDBC是一组java接口,具体实现由数据库厂商提供SQL驱动实现,就是一个驱动jar包
使用JDBC的准备
- 前往MySQL官网下载对应版本的jar包
- 把jar包添加到项目的依赖Libraries
- 在正在使用Modules中添加新增的lib
开发步骤
-
1.注册驱动
- Class.forName(数据库驱动实现类) 加载和注册数据库驱动,数据库驱动由数据库厂商MySql提供 “com.mysql.jdbc.Driver”
-
2.获得链接
- DriverManager.getConnection
// 通过连接字符串和用户名,密码来获取数据 库连接对象 Connection getConnection(String url, String user, String password)MySql 的url示例:
jdbc:[mysql://localhost:3306/db4?characterEncoding=UTF-8](mysql://localhost:3306/db4?characterEncoding=UTF-8%60)- 第一部分是协议 jdbc,这是固定的; * 第二部分是子协议,就是数据库名称,连接mysql数据库,第二部分当然是mysql了;
-
第三部分是由数据库厂商规定的,我们需要了解每个数据库厂商的要求,mysql的第三部分分别由数据 库服务器的IP地址(localhost)、端口号(3306),以及要使用的 数据库名称 组成。
characterEncoding=UTF-8定义使用的字符集
- DriverManager.getConnection
-
3.获取语句执行平台
-
Statement Connection.createStatement() 创建 SQL语句执行对象
-
Statement 代表一条语句对象,用于发送 SQL 语句给服务器,用于执行静态 SQL 语句并返回它所生成结 果的对象。
-
int executeUpdate(String sql); 执行insert update delete语句.返回int类型,代表受影响的行 数
-
ResultSet executeQuery(String sql); 执行select语句, 返回ResultSet结果集对象
-
-
-
-
- 处理结果集 只有在进行查询操作的时候, 才会处理结果集
-
ResultSet 作用:封装数据库查询的结果集,对结果集进行遍历,取出每一条记录
-
boolean next() 1) 游标向下一行
2) 返回 boolean 类型,如果还有下一条记录,返回 true,否则返回 false -
xxx getXxx( String or int) 1) 通过列名,参数是 String 类型。返回不同的类型
2) 通过列号,参数是整数,从 1 开始。返回不同的类型
-
-
5.释放资源 需要释放的对象:ResultSet 结果集,Statement 语句,Connection 连接
- ResultSet ==> Statement ==> Connection
SQL注入问题
假如使用一条SQL验证登陆用户名和密码是否存在
SELECT * FROM user WHERE username = 'tom' AND PASSWORD = '123';
在java中会使用占位符来接收输入
接收的sql String大概长这样
String sql = String.format("SELECT * FROM user WHERE username='%s' AND PASSWORD='%s'", name, password);
那么如果用户名随便输入一个,
password = “123' OR '1' = ‘1”;
那SQL语句大概就会变成这样
SELECT * FROM user WHERE username = 'tom' AND PASSWORD = '123' OR '1' = '1';
时候JDBC语句查询,返回结果就是true的,这就是SQL注入问题
-
解决方案->预处理对象PreparedStatement
- PreparedStatement
-
PreparedStatement 是 Statement 接口的子接口,继承于父接口中所有的方法。它是一个预编译的 SQL 语 句对象.
-
预编译: 是指SQL 语句被预编译,并存储在 PreparedStatement 对象中。然后可以使用此对象多次高效地执行 该语句。
- Connection -> PreparedStatement prepareStatement(String sql)
指定预编译的 SQL 语句,
SQL 语句中使用占位符 ? 创建一个语句对象,如"SELECT * FROM jdbc_user WHERE username=? AND password=?"; -
int executeUpdate(); 执行insert update delete语句.
-
ResultSet executeQuery(); 执行select语句. 返回结果集对象 Resulset
-
setXxx(占位符的位置, 真实的值)
- Statement vs PreparedStatement
- Statement用于执行静态SQL语句,在执行时,必须指定一个事先准备好的SQL语句。
- PrepareStatement是预编译的SQL语句对象,语句中可以包含动态参数“?”,在执行时可以为“?”动态设置参数值。
- PrepareStatement可以减少编译次数提高数据库性能。
- Connection -> PreparedStatement prepareStatement(String sql)
指定预编译的 SQL 语句,
-
- PreparedStatement
控制事务
-
Connection->void setAutoCommit(boolean autoCommit) 参数是 true 或 false 如果设置为 false,表示关闭自动提交,相 当于开启事务
-
Connection->void commit() 提交事务
-
Connection->void rollback() 回滚事务
DBUtils
使用JDBC我们发现冗余的代码太多了,为了简化开发 我们选择使用 DbUtils
Commons DbUtils是Apache组织提供的一个对JDBC进行简单封装的开源工具类库,使用它能够简化JDBC应用程
序的开发,同时也不会影响程序的性能。
- 使用时导入jar包即可
使用相关知识
-
一张表对应一个类,一列数据对应一个类
-
javabean JavaBean 就是一个类, 开发中通常用于封装数据,有一下特点
- 需要实现 序列化接口, Serializable (暂时可以省略)
- 提供私有字段: private 类型 变量名;
- 提供 getter 和 setter
- 提供 空参构造
QueryRunner
用来调用sql语句的类
-
QueryRunner() 这种方式创建的,需要手动传入connection,并释放资源
-
QueryRunner(DataSource ds) 提供数据源(连接池),DBUtils底层自动维护连接connection
-
update(Connection conn, String sql, Object… params) 用来完成表数据的增加、删除、更新操 作
-
query(Connection conn, String sql, ResultSetHandler
rsh, Object... params) 来完成表 数据的查询操作
ResultSetHandler
- ResultSetHandler是一个接口,可以对查询出来的ResultSet结果集进行处理,达到一些业务上的需求
-
每一种实现类都代表了对查询结果集的一种处理方式
-
ArrayHandler
-
ArrayListHandler
-
BeanHandler
-
BeanListHandler
-
MapHandler
-
MapListHandler
- ScalarHandler
DbUtils
一个工具类,定义了关闭资源与事务处理相关方法.
数据库连接池
- 实际开发中“获得连接”或“释放资源”是非常消耗系统资源的两个过程,为了解决此类性能问题,通常情况我们 采用连接池技术,来共享连接Connection。这样我们就不需要每次都创建连接、释放连接了,这些操作都交 给了连接池.
-
用池来管理Connection,这样可以重复使用Connection。 当使用完Connection后,调用Connection的
close()方法也不会真的关闭Connection,而是把Connection“归还”给池。 - Java为数据库连接池提供了公共的接口:javax.sql.DataSource,各个厂商需要让自己的连接池实现这个接口。
这样应用程序可以方便的切换不同厂商的连接池!
DBCP
DBCP也是一个开源的连接池,是Apache成员之一,在企业开发中也比较常见,tomcat内置的连接池。
-
导入jar包
-
编写工具类
-
连接池实现类BasicDataSource
C3P0
C3P0是一个开源的JDBC连接池,支持JDBC3规范和JDBC2的标准扩展。目前使用它的开源项目有Hibernate、
Spring等。
-
导入jar包
-
编写工具类
-
连接池实现类ComboPooledDataSource
-
new ComboPooledDataSource() 使用 默认配置
-
new ComboPooledDataSource(“mysql”); 使用命名配置
-
-
数据库配置文件c3p0-config.xml c3p0-config.xml 文件名不可更改 直接放到src下,也可以放到到资源文件夹中
Druid
Druid(德鲁伊)是阿里巴巴开发的号称为监控而生的数据库连接池,Druid是目前最好的数据库连接池。在功 能、性能、扩展性方面,都超过其他数据库连接池,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行 情况。
-
导入jar包
-
编写工具类
- 连接池实现类 DataSource 多态调用
//1.创建属性集对象 Properties p = new Properties(); //2.加载配置文件 Druid 连接池不能够主动加载配置文件 ,需要指定文件 InputStream inputStream = DruidUtils.class.getClassLoader().getResourceAsStream("druid.properties"); //3. 使用Properties对象的 load方法 从字节流中读取配置信息 p.load(inputStream); / /4. 通过工厂类获取连接池对象 DataSource dataSource = DruidDataSourceFactory.createDataSource(p); - 数据库配置文件druid.properties
常见配置项
-
driverClassName
-
url
-
username
-
password
-
maxActive
-
maxIdle
-
minIdle
-
initialSize
数据库批量处理
- 批处理指的是一次操作中执行多条SQL语句,批处理相比于一次一次执行效率会提高很多。
- 当向数据库中添加大量的数据时,需要用到批处理。
- 如果执行批处理的时候有一条出错,全部倒回
- 注意⚠️:必须在URL后面添加
&rewriteBatchedStatements=true,不然批处理退回到正常的单条语句处理
Statement
-
void addBatch() 将给定的 SQL 命令添加到此 Statement 对象的当前命令列表中。 通过调用方法 executeBatch 可以批量执行此列表中的命令。
-
int[] executeBatch() 每次提交一批命令到数据库中执行,如果所有的命令都成功执行了,
那么返回一个数组,这个数组是说明每条命令所影响的行数
PreparedStatement
-
void addBatch() 将给定的 SQL 命令添加到此 Statement 对象的当前命令列表中。 通过调用方法 executeBatch 可以批量执行此列表中的命令。
-
int[] executeBatch() 每次提交一批命令到数据库中执行,如果所有的命令都成功执行了,
那么返回一个数组,这个数组是说明每条命令所影响的行数
MySql元数据
SQL
-
SHOW STATUS; 查看服务器当前状态
-
SELECT VERSION(); 查看MySQl的版本信息
-
SHOW COLUMNS FROM table_name; 查询表中的详细信息
-
SHOW INDEX FROM table_name; 显示数据表的详细索引信息
-
SHOW DATABASES; 列出所有数据库
-
SHOW TABLES; 显示当前数据库的所有表
-
SELECT DATABASE(); 获取当前的数据库名
JDBC
-
DatabaseMetaData 描述数据库的元数据对象
-
Connection.getMetaData () -> DatabaseMetaData
-
getURL()
-
getUserName()
-
getDatabaseProductName() 获取数据库的产品名称MySQL
-
getDatabaseProductVersion()
-
getDriverName()
-
isReadOnly()
-
-
ResultSetMetaData 描述结果集的元数据对象
-
getColumnCount()
-
getColumnName(int i)
-
getColumnTypeName(int i)
-
XML
XML的作用
-
存储数据 通常,我们在数据库中存储数据。不过,如果希望数据的可移植性更强,我们可以 把数据存储 XML 文件中
-
配置文件 作为各种技术框架的配置文件使用 (最多)
-
在网络中传输 客户端可以使用XML格式向服务器端发送数据,服务器接收到xml格式数据,进行解析
XML语法
- 声明文档格式
<?xml version="1.0" encoding="UTF-8"?>- 文档声明必须为结束;
- 文档声明必写在第一行;
- 元素
<employee eid="3">name</employee>- 不能使用空格,不能使用冒号
- XML 标签名称区分大小写
- XML 必须有且只有一个根元素
- 空元素
<close/>
空元素只有开始标签,而没有结束标签,但元素必须自己闭合
XML约束
可以编写一个文档来约束一个XML文档的书写规范,这称之为XML约束
-
不需要写,能看懂就行
-
DTD DTD(Document Type Definition),文档类型定义,用来约束XML文档。规定XML文档中元素的名称,子元素的名称及顺序,元素的属性等。
- 引入
<!DOCTYPE students SYSTEM "student.dtd">
- 引入
-
Schema
- Schema是新的XML文档约束, 比DTD强大很多,是DTD 替代者;
- Schema本身也是XML文档,但Schema文档的扩展名为xsd,而不是xml。
- Schema 功能更强大,内置多种简单和复杂的数据类型
- Schema 支持命名空间 (一个XML中可以引入多个约束文档)
- 引入
<students xmlns="http://www.lagou.com/xml" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.lagou.com/xml student.xsd" > </students>
XML解析
- DOM
要求解析器把整个XML文档装载到内存,并解析成一个Document对象。
- 优点:元素与元素之间保留结构关系,故可以进行增删改查操作。
- 缺点:XML文档过大,可能出现内存溢出显现。
- SAX
是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。并以事件驱动的方 式进行具体解析,每执行一行,都将触发对应的事件。(了解)
- 优点:占用内存少 处理速度快,可以处理大文件
- 缺点:只能读,逐行后将释放资源。
-
DOM4J解析器 一款非常优秀的解析器 , Dom4j是一个易用的、开源的库,用于XML,XPath和XSLT。 它应用于Java平台,采用了Java集合框架并完全支持DOM,SAX和JAXP。
- 使用
- 导入
dom4j-1.6.1.jar SaxReader reader = new SaxReader()Document document = reader.read(“filepath.xml”)
- 导入
-
SaxReader
- read(…) 加载执行xml文档
-
Document
- getRootElement() 获得根元素
-
Element
-
elements(…) 获得指定名称的所有子元素。可以不指定名称
-
element(…) 获得指定名称的第一个子元素。可以不指定名称
-
getName() 获得当前元素的元素名
-
attributeValue(…) 获得指定属性名的属性值
-
elementText(…) 获得指定名称子元素的文本值
-
getText() 获得当前元素的文本内容
-
- 使用
-
xpath XPath 是一门在 XML 文档中查找信息的语言。 可以是使用xpath查找xml中的内容。
XPath 的好处:由于DOM4J在解析XML时只能一层一层解析,所以当XML文件层数过多时使用会很不方便,结合 XPATH就可以直接获取到某个元素-
使用 导入
jaxen-1.1-beta-6.jar -
常用API
-
Document->selectSingleNode(query): 查找和 XPath 查询匹配的一个节点。
-
Document->selectNodes(query) 得到的是xml根节点下的所有满足 xpath 的节点;
-
Node 节点对象
-
-
query语法
-
/AAA/DDD/BBB 表示一层一层的,AAA下面 DDD下面的BBB
-
//BBB 表示和这个名称相同,表示只要名称是BBB,都得到
-
//* 所有元素
-
BBB[1] , BBB[last()] 第一种表示第一个BBB元素, 第二种表示最后一个BBB元素
-
//BBB[@id] 表示只要BBB元素上面有id属性,都得到
-
//BBB[@id=’b1’] 表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是b1
-
-