ZooKeeper--分布式协调组件
Zookeeper简介
Zookeeper是什么?
Zookeeper 是一个分布式协调服务的开源框架。 主要用来解决分布式集群中应用系统的一致性问题, 例如怎样避免同时操作同一数据造成脏读的问题。
-
ZooKeeper 本质上是一个分布式的小文件存储系统。 提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。
-
ZooKeeper 提供给客户端监控存储在zk内部数据的功能,从而可以达到基于数据的集群管理。 诸如: 统一命名服务(dubbo)、分布式配置管理(solr的配置集中管理)、分布式消息队列 (sub/pub)、分布式锁、分布式协调等功能。
zookeeper的架构组成
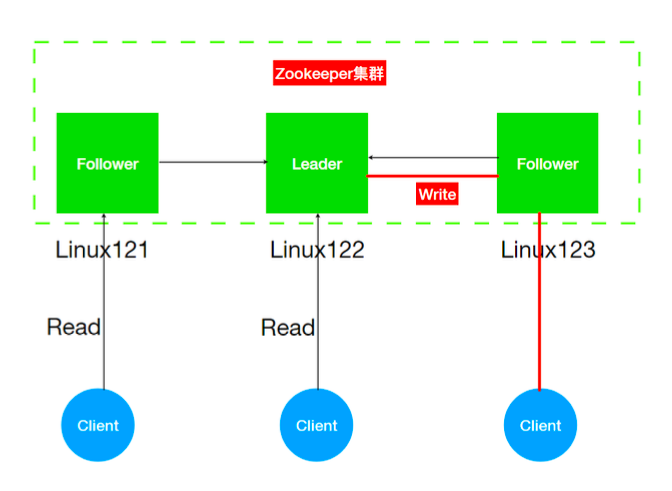
ZK也是Master/slave架构,但是与hadoop不同的是zk集群中的Leader不是指定而来,而是通过选举产 生。
- Leader
- Zookeeper 集群工作的核心角色
- 集群内部各个服务器的调度者。
- 事务请求(写操作) 的唯一调度和处理者,保证集群事务处理的顺序性;对于 create, setData, delete 等有写操作的请求,则需要统一转发给leader 处理, leader 需要决定编号、执 行操作,这个过程称为一个事务。
- Follower
- 处理客户端非事务(读操作) 请求
- 转发事务请求给 Leader
- 参与集群 Leader 选举投票 2n-1台可以做集群投票
- Observer
- 观察者角色,观察 Zookeeper 集群的最新状态变化并将这些状态同步过来,其对于非事务请求可 以进行独立处理,对于事务请求,则会转发给 Leader服务器进行处理。
- 不会参与任何形式的投票只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提升集 群的非事务处理能力。增加了集群增加并发的读请求。
Zookeeper 特点
- Zookeeper:一个领导者(leader:老大),多个跟随者(follower:小弟)组成的集群。
- Leader负责进行投票的发起和决议,更新系统状态(内部原理)
- Follower用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。
- 全局数据一致:每个server保存一份相同的数据副本,Client无论连接到哪个server,数据都是一 致的。
- 更新请求顺序进行(内部原理)
- 数据更新原子性,一次数据更新要么成功,要么失败。
Zookeeper集群模式搭建
Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式。
- 单机模式:Zookeeper只运行在一台服务器上,适合测试环境;
- 伪集群模式:就是在一台服务器上运行多个Zookeeper 实例;
- 集群模式:Zookeeper运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”
1. 下载上传安装包
下载稳定版本的zookeeper : http://zookeeper.apache.org/releases.html
下载完成后,将zookeeper压缩包 zookeeper-3.4.14.tar.gz上传到linux系统/opt/lagou/software 解压 压缩包
tar -zxvf zookeeper-3.4.14.tar.gz -C ../servers/
2. 修改配置文件创建data与log目录
#创建zk存储数据目录
mkdir -p /opt/lagou/servers/zookeeper-3.4.14/data
#创建zk日志文件目录
mkdir -p /opt/lagou/servers/zookeeper-3.4.14/data/logs
#修改zk配置文件
cd /opt/lagou/servers/zookeeper-3.4.14/conf
#文件改名
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
#更新datadir
dataDir=/opt/lagou/servers/zookeeper-3.4.14/data
#增加logdir
dataLogDir=/opt/lagou/servers/zookeeper-3.4.14/data/logs
#增加集群配置 ##server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
server.1=centos7-1:2888:3888
server.2=centos7-2:2888:3888
server.3=centos7-3:2888:3888
#打开注释
#ZK提供了自动清理事务日志和快照文件的功能,这个参数指定了清理频率,单位是小时
autopurge.purgeInterval=1
3. 添加myid配置
在zookeeper的 data 目录下创建一个 myid 文件,内容为1,这个文件就是记录每个服务器的ID
cd /opt/lagou/servers/zookeeper-3.4.14/data
echo 1 > myid
4. 同步zookeeper安装包到所有机器
安装包分发并修改myid的值
rsync-script /opt/lagou/servers/zookeeper-3.4.14
# centos7-2
echo 2 >/opt/lagou/servers/zookeeper-3.4.14/data/myid
# centos7-3
echo 3 >/opt/lagou/servers/zookeeper-3.4.14/data/myid
5. 依次单独启动节点
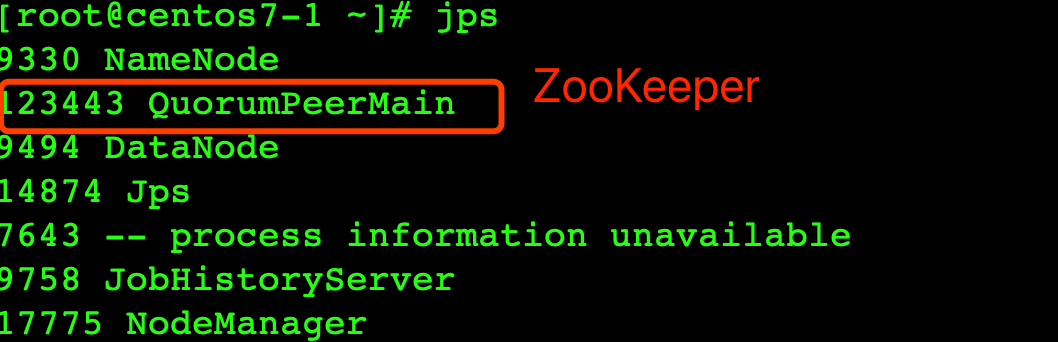
启动命令(三个节点都要执行)
/opt/lagou/servers/zookeeper-3.4.14/bin/zkServer.sh start
# 查看状态
/opt/lagou/servers/zookeeper-3.4.14/bin/zkServer.sh status
# 停止
/opt/lagou/servers/zookeeper-3.4.14/bin/zkServer.sh stop
6. 编写集群启动停止脚本
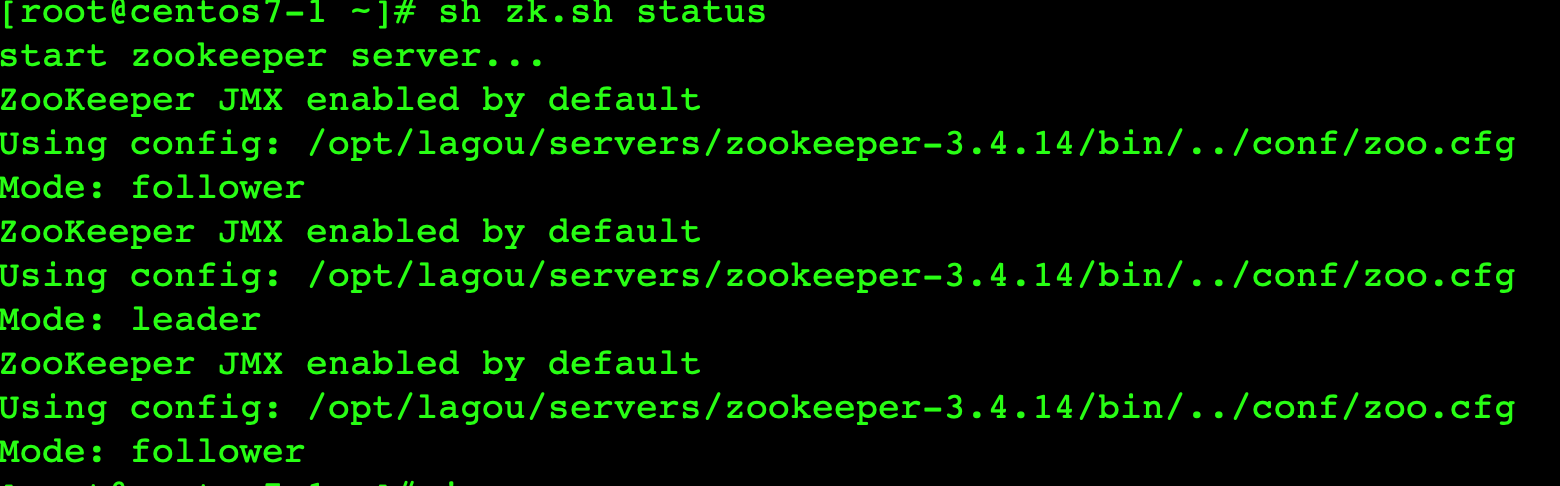
vim zk.sh
#!/bin/sh
echo "start zookeeper server..."
if(($#==0));then
echo "no params";
exit;
fi
hosts="centos7-1 centos7-2 centos7-3"
for host in $hosts
do
ssh $host "source /etc/profile; /opt/lagou/servers/zookeeper-3.4.14/bin/zkServer.sh $1"
done
zk.sh start
zk.sh status
zk.sh stop
Zookeeper数据结构与监听机制
ZooKeeper数据模型Znode
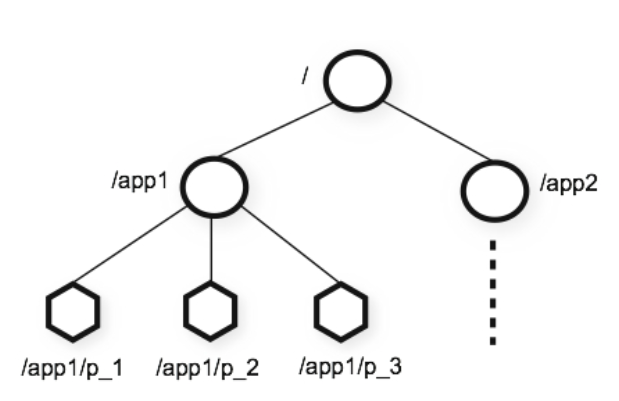
在ZooKeeper中,数据信息被保存在一个个数据节点上,这些节点被称为znode。ZNode 是 Zookeeper 中最小数据单位,在 ZNode 下面又可以再挂 ZNode,这样一层层下去就形成了一个层次化 命名空间 ZNode 树,我们称为 ZNode Tree,它采用了类似文件系统的层级树状结构进行管理。
在 Zookeeper 中,每一个数据节点都是一个 ZNode,上图根目录下有两个节点,分别是:app1 和 app2,其中 app1 下面又有三个子节点,所有ZNode按层次化进行组织,形成这么一颗树,ZNode的节 点路径标识方式和Unix文件系统路径非常相似,都是由一系列使用斜杠(/)进行分割的路径表示,开 发人员可以向这个节点写入数据,也可以在这个节点下面创建子节点
ZNode 的类型
Zookeeper 节点类型可以分为三大类:
持久性节点(Persistent)
临时性节点(Ephemeral)
顺序性节点(Sequential)
在开发中在创建节点的时候通过组合可以生成以下四种节点类型:持久节点、持久顺序节点、临时节点、临时顺序节点。不同类型的节点则会有不同的生命周期
-
持久节点
是Zookeeper中最常见的一种节点类型,所谓持久节点,就是指节点被创建后会一直存在服务器,直到删除操作主动清除 -
持久顺序节点
就是有顺序的持久节点,节点特性和持久节点是一样的,只是额外特性表现在顺序上。 顺序特性实质是在创建节点的时候,会在节点名后面加上一个数字后缀,来表示其顺序。 -
临时节点
就是会被自动清理掉的节点,它的生命周期和客户端会话绑在一起,客户端会话结束,节点会被删除掉。与持久性节点不同的是,临时节点不能创建子节点。 -
临时顺序节点
就是有顺序的临时节点,和持久顺序节点相同,在其创建的时候会在名字后面加上数字后缀。 -
事务ID
在ZooKeeper中,事务是指能够改变ZooKeeper服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新等操作。对于每一个事务请求,ZooKeeper都会为其分配一个全局唯一的事务ID,用 ZXID 来表示,通常是一个 64 位的数字。每一个 ZXID 对应一次 更新操作,从这些ZXID中可以间接地识别出ZooKeeper处理这些更新操作请求的全局顺序
zk中的事务指的是对zk服务器状态改变的操作(create,update data,更新字节点);zk对这些事务操作都会编号,这个编号是自增长的被称为ZXID。
ZNode 的状态信息
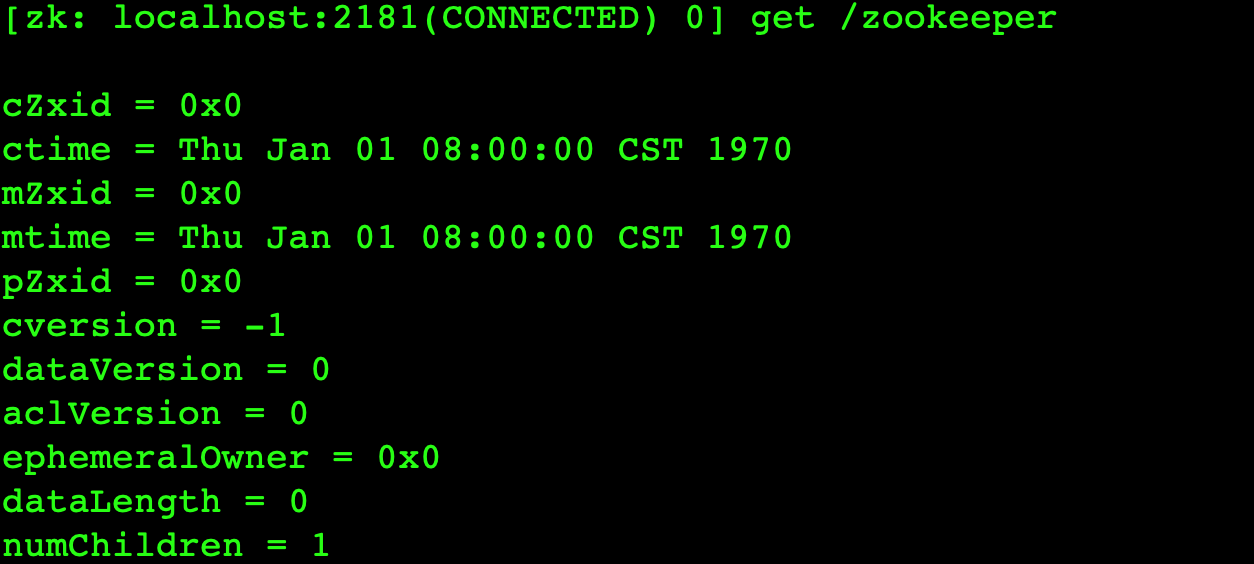
整个 ZNode 节点内容包括两部分:节点数据内容和节点状态信息。数据内容是空,其他的属于状态信息
cZxid 就是 Create ZXID,表示节点被创建时的事务ID。
ctime 就是 Create Time,表示节点创建时间。
mZxid 就是 Modified ZXID,表示节点最后一次被修改时的事务ID。
mtime 就是 Modified Time,表示节点最后一次被修改的时间。
pZxid 表示该节点的子节点列表最后一次被修改时的事务 ID。只有子节点列表变更才会更新 pZxid,子节点内容变更不会更新。
cversion 表示子节点的版本号。
dataVersion 表示内容版本号。
aclVersion 标识acl版本
ephemeralOwner 表示创建该临时节点时的会话 sessionID,如果是持久性节点那么值为 0
dataLength 表示数据长度。
numChildren 表示直系子节点数。
Watcher 机制
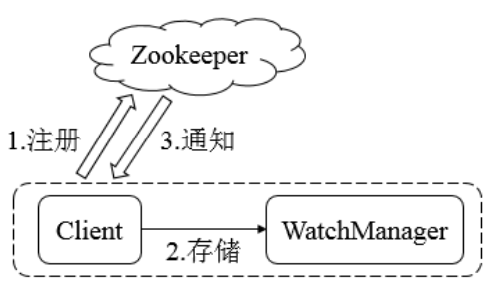
Zookeeper使用Watcher机制实现分布式数据的发布/订阅功能
在 ZooKeeper 中,引入了 Watcher 机制来实现这种分布式的通知功能。ZooKeeper 允许客户端向服 务端注册一个 Watcher 监听,当服务端的一些指定事件触发了这个 Watcher,那么Zk就会向指定客户端发送一个事件通知来实现分布式的通知功能。
Zookeeper的Watcher机制主要包括客户端线程、客户端WatcherManager、Zookeeper服务器三部 分。
具体工作流程为:
- 客户端在向Zookeeper服务器注册的同时,会将Watcher对象存储在客户端的WatcherManager当 中
- 当Zookeeper服务器触发Watcher事件后,会向客户端发送通知
- 客户端线程从WatcherManager中取出对应的Watcher对象来执行回调逻辑
基本使用
ZooKeeper命令行操作
-
启动客户端 在ZooKeeper_home/bin 目录下
./zkcli.sh 连接本地的zookeeper服务器 ./zkCli.sh -server ip:port(2181) 连接指定的服务器 -
help
- create [-s][-e] path data
- 创建节点, -s或-e分别指定节点特性,顺序或临时节点,若不指定,则创建持久节点
- 临时节点在客户端会话结束后,就会自动删除
-
ls path ls命令可以列出Zookeeper指定节点下的所有子节点,但只能查看指定节点下的第一级的所有子节点
-
get path get命令可以获取Zookeeper指定节点的数据内容和属性信息。
-
set path data 使用set命令,可以更新指定节点的数据内容
-
delete path 使用delete命令可以删除Zookeeper上的指定节点, 只能删除空节点
- rmr path 递归删除节点,非空节点也可以删除
开源客户端ZkClient
ZkClient是Github上一个开源的zookeeper客户端,在Zookeeper原生API接口之上进行了包装,是 一个更易用的Zookeeper客户端,同时,zkClient在内部还实现了诸如Session超时重连、Watcher反复 注册等功能
-
- 添加依赖
<dependencies> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.14</version> </dependency> <dependency> <groupId>com.101tec</groupId> <artifactId>zkclient</artifactId> <version>0.2</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> </dependencies> -
- 添加log4j.properties到resources
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 添加log4j.properties到resources
-
- 基本应用
- 初步体验
public class ZkDemo { public static void main(String[] args) { // 创建并链接客户端 ZkClient zkClient = new ZkClient("centos7-1:2181"); System.out.println("zoo keeper client created"); // 创建目录 zkClient.createPersistent("/zk-client/demo", true); // 删除目录 // System.out.println("path created"); // zkClient.delete("/zk-client"); zkClient.deleteRecursive("/zk-client"); System.out.println("path deleted"); } } - 监听节点目录
public class SubscribeChildChange { public static void main(String[] args) throws InterruptedException { ZkClient zkClient = new ZkClient("centos7-2:2181"); // 监听节点及子节点的变化 zkClient.subscribeChildChanges("/lg-client", new IZkChildListener() { public void handleChildChange(String s, List<String> list) throws Exception { System.out.println("path: " + s + " : " + list); } }); zkClient.createPersistent("/lg-client"); Thread.sleep(1000); zkClient.createPersistent("/lg-client/c1"); Thread.sleep(1000); zkClient.createPersistent("/lg-client/c2"); Thread.sleep(1000); zkClient.deleteRecursive("/lg-client/c2"); Thread.sleep(1000); zkClient.deleteRecursive("/lg-client"); Thread.sleep(Long.MAX_VALUE); } } - 监听节点数据
public class SubscribeDataChange { public static void main(String[] args) throws InterruptedException { ZkClient zkClient = new ZkClient("centos7-2:2181"); // 没有序列化的话,读取shell端数据会出错 zkClient.setZkSerializer(new ZkSerializer() { public byte[] serialize(Object o) throws ZkMarshallingError { return ((String)o).getBytes(); } public Object deserialize(byte[] bytes) throws ZkMarshallingError { return new String(bytes); } }); // 监听节点数据的变化 zkClient.subscribeDataChanges("/lg-client", new IZkDataListener() { public void handleDataChange(String s, Object o) throws Exception { System.out.println("path:" + s + " : " + o); } public void handleDataDeleted(String s) throws Exception { System.out.println("handleDataDeleted : " + s); } }); // zkClient.createPersistent("/lg-client"); Thread.sleep(1000); zkClient.writeData("/lg-client", "1234"); Thread.sleep(1000); Object data = zkClient.readData("/lg-client"); System.out.println("read data: " + data); zkClient.deleteRecursive("/lg-client"); Thread.sleep(Long.MAX_VALUE); } }
Zookeeper内部原理
Leader选举
- 选举机制
- 半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
- Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节 点为Leader,其它为Follower,Leader是通过内部的选举机制产生的。
-
集群首次启动
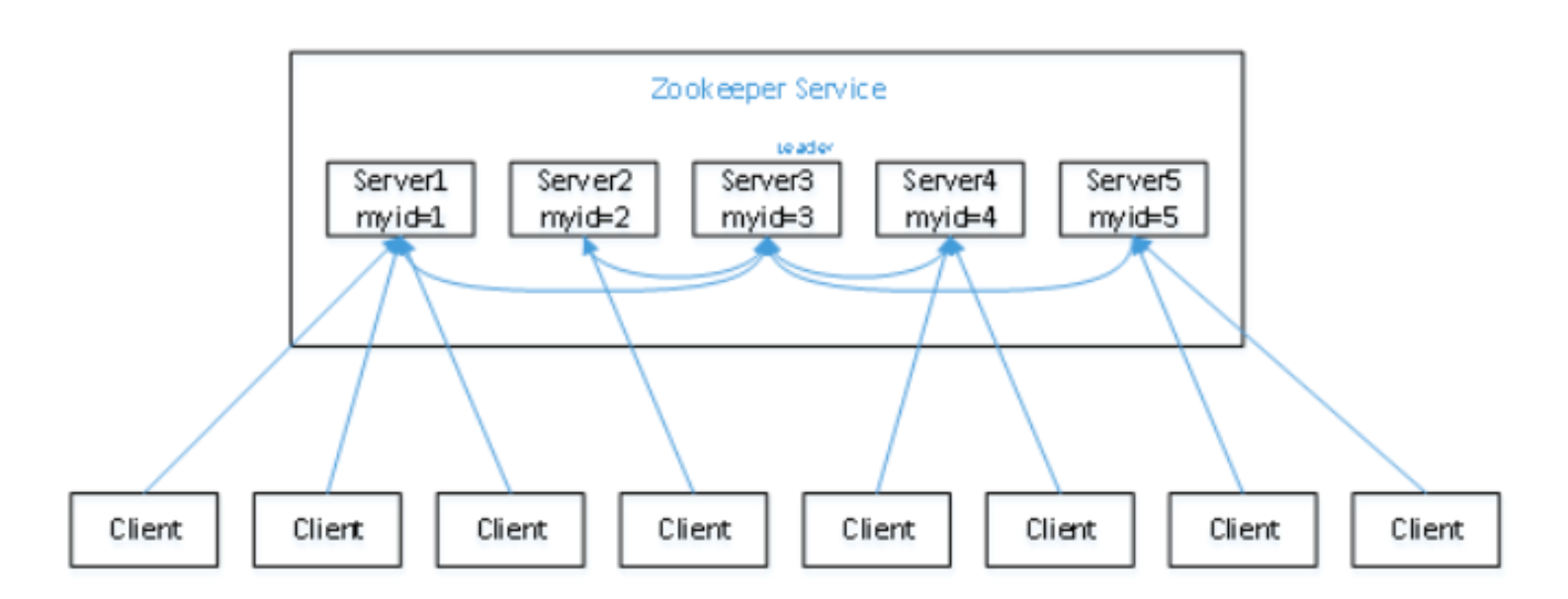 假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历 史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么,
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历 史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么,
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报文没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有 历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个 例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的 是,此时有三台服务器选举了它,所以它成为了这次选举的Leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前 面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样称为follower。 - 集群非首次启动 每个节点在选举时都会参考自身节点的zxid值(事务ID);优先选择zxid值大的节点称为Leader!!
ZAB一致性协议
- 分布式数据一致性问题
为什么会出现分布式数据一致性问题?
- 将数据复制到分布式部署的多台机器中,可以消除单点故障,防止系统由于某台(些)机器宕机导致的不可用。
- 通过负载均衡技术,能够让分布在不同地方的数据副本全都对外提供服务。有效提高系统性能。
- 在分布式系统中引入数据复制机制后,多台数据节点之间由于网络等原因很容易产生数据不一致的情况。
-
ZAB协议 ZK就是分布式一致性问题的工业解决方案,paxos是其底层理论算法(晦涩难懂著名),其中zab,raft和 众多开源算法是对paxos的工业级实现。ZK没有完全采用paxos算法,而是使用了一种称为Zookeeper Atomic Broadcast(ZAB,Zookeeper原子消息广播协议)的协议作为其数据一致性的核心算法。
ZAB 协议是为分布式协调服务 Zookeeper 专门设计的一种支持崩溃恢复和原子广播协议。
-
主备模式保证一致性
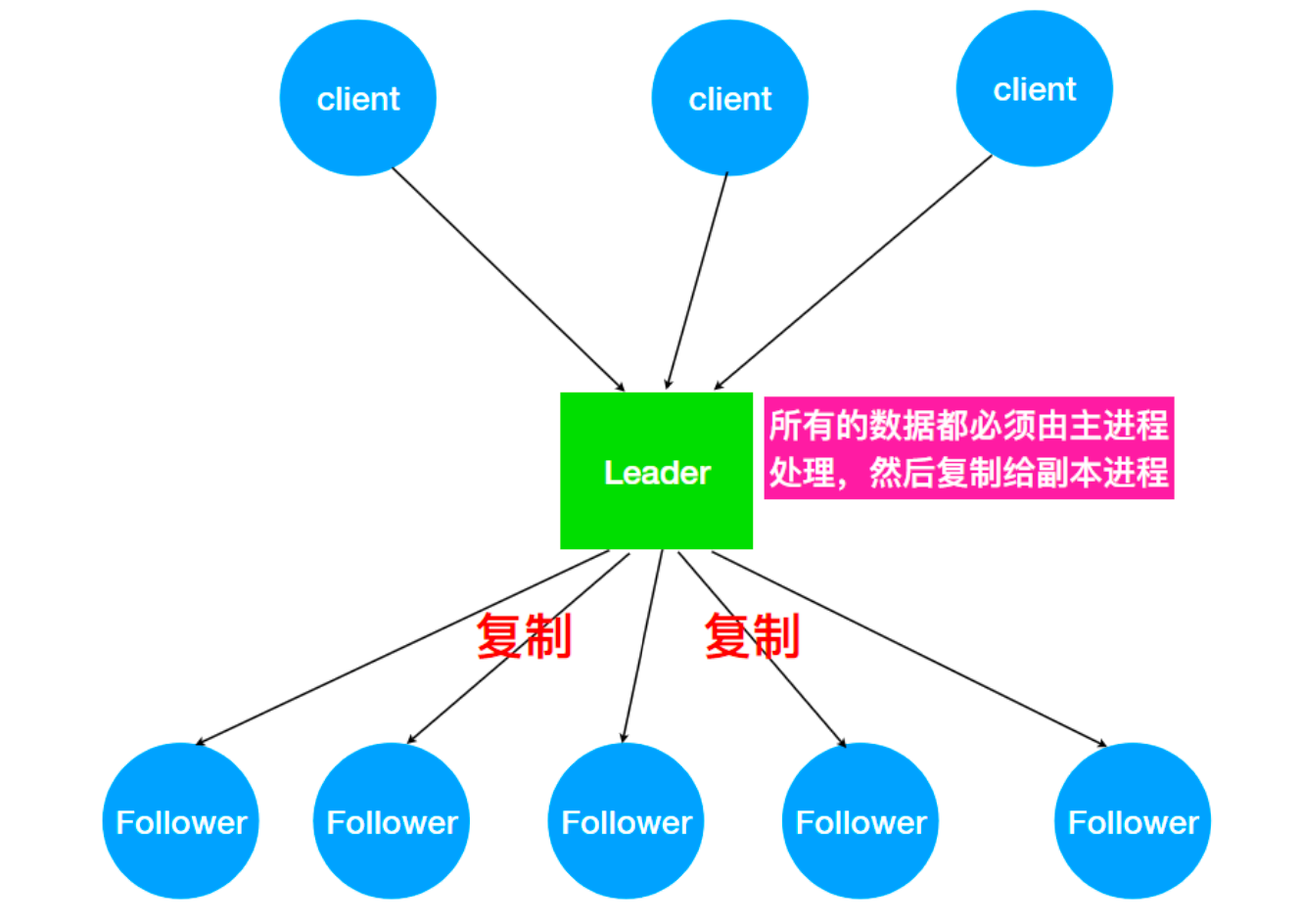 ZK怎么处理集群中的数据?所有客户端写入数据都是写入Leader中,然后,由 Leader 复制到 Follower中。ZAB会将服务器数据的状态变更以事务Proposal的形式广播到所有的副本进程上,ZAB协议能够保证事务操作一个全局的变更序号(ZXID)。
ZK怎么处理集群中的数据?所有客户端写入数据都是写入Leader中,然后,由 Leader 复制到 Follower中。ZAB会将服务器数据的状态变更以事务Proposal的形式广播到所有的副本进程上,ZAB协议能够保证事务操作一个全局的变更序号(ZXID)。 -
广播消息
ZAB 协议的消息广播过程类似于 二阶段提交过程。对于客户端发送的写请求,全部由 Leader 接收, Leader 将请求封装成一个事务 Proposal(提议),将其发送给所有 Follower ,如果收到超过半数反馈 ACK,则执行 Commit 操作(先提交自己,再发送 Commit 给所有 Follower)。- Leader接收到Client请求之后,会将这个请求封装成一个事务,并给这个事务分配一个全局递增的 唯一 ID,称为事务ID(ZXID),ZAB 协议要求保证事务的顺序,因此必须将每一个事务按照 ZXID 进行先后排序然后处理。
- ZK集群为了保证任何事务操作能够有序的顺序执行,只能是 Leader 服务器接受写请求,即使是 Follower 服务器接受到客户端的请求,也会转发到 Leader 服务器进行处理。
-
zk提供的应该是最终一致性的标准。zk所有节点接收写请求之后可以在一定时间内保证所有节点都能看 到该条数据!!
-
1、 发送Proposal到Follower
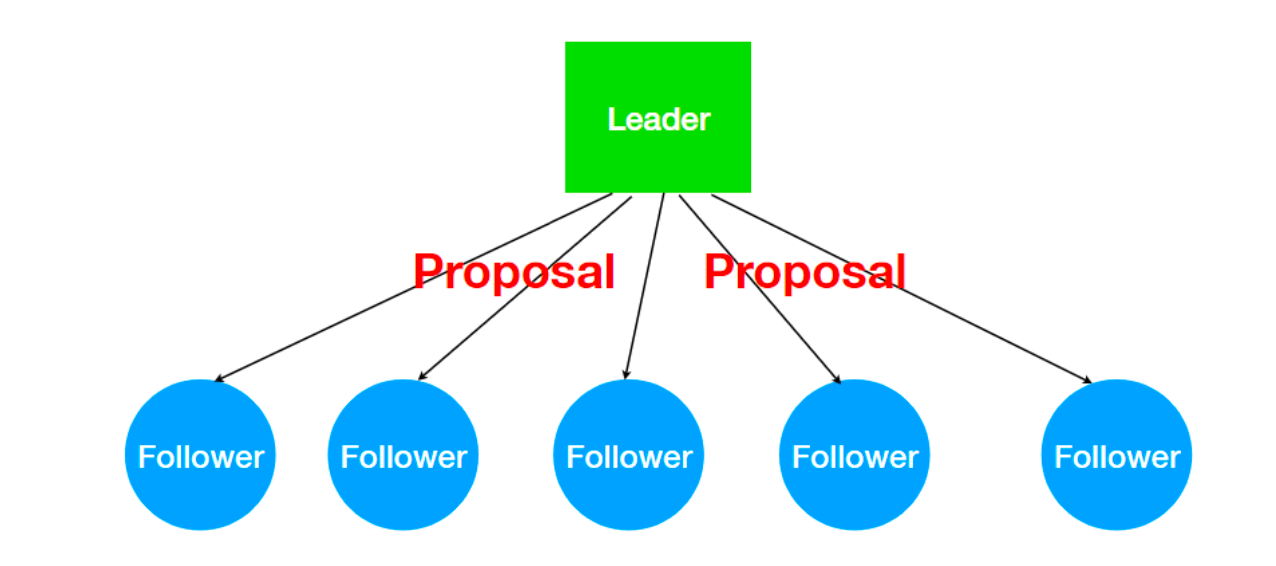
-
2、 Leader接收Follower的ACK
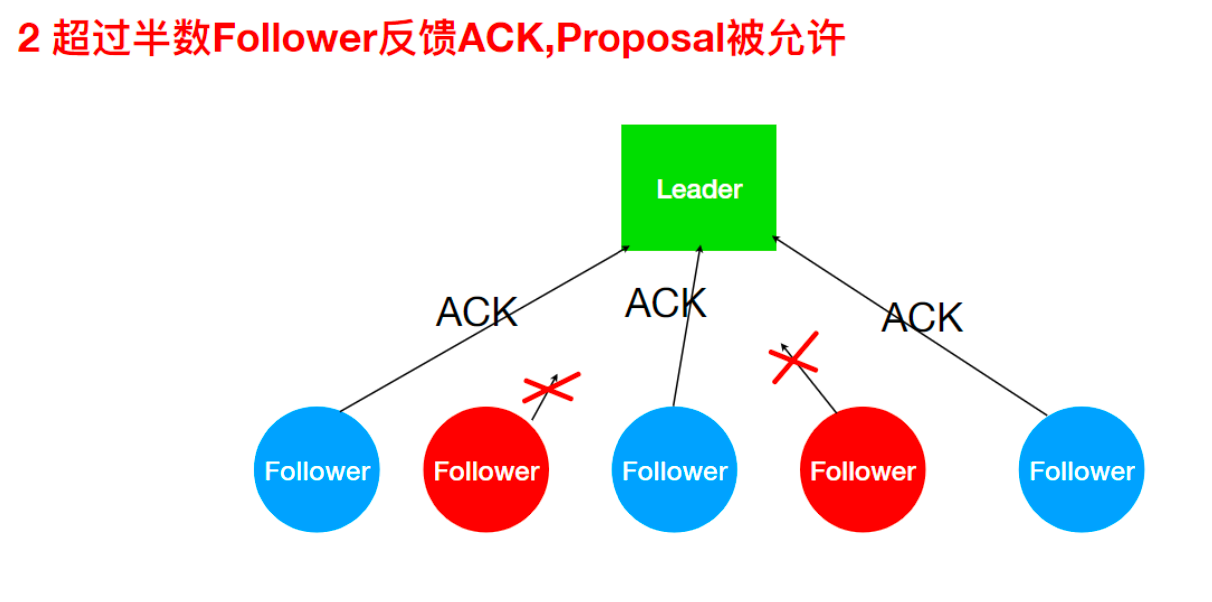
-
3、 超过半数ACK则Commit
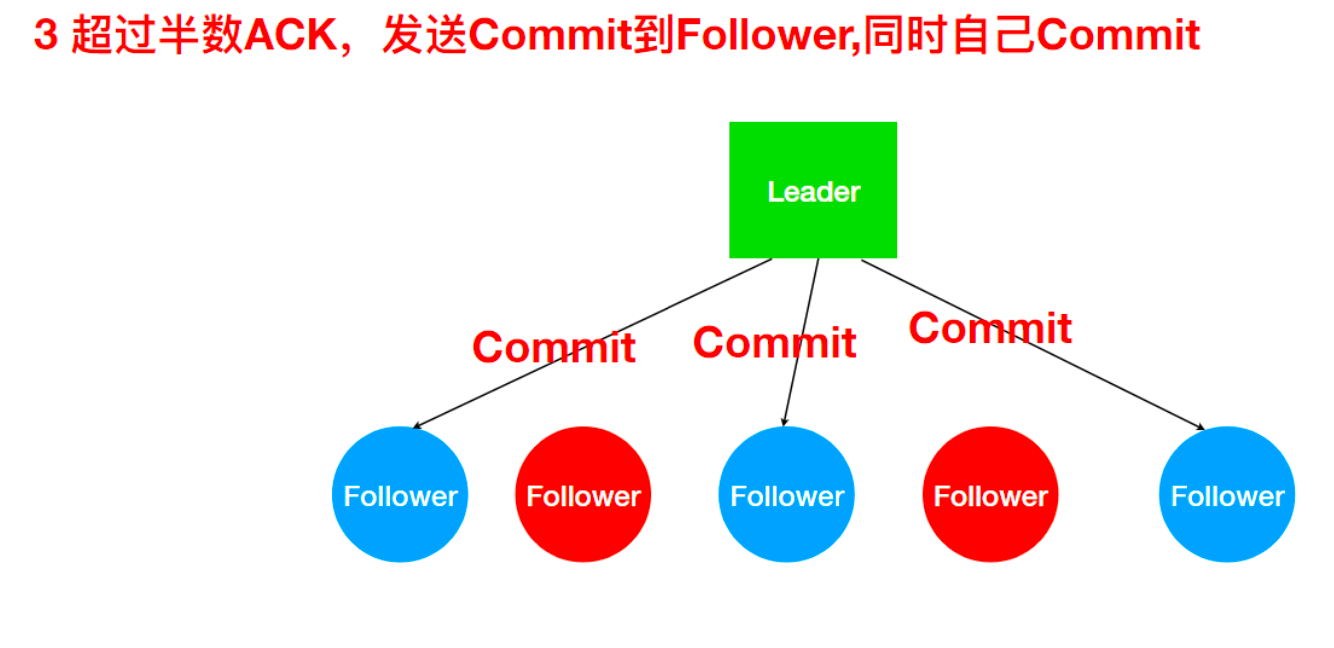 不能正常反馈的Follower恢复正常后会进入数据同步阶段最终与Leader保持一致
不能正常反馈的Follower恢复正常后会进入数据同步阶段最终与Leader保持一致
-
-
Leader 崩溃问题 Leader宕机后,ZK集群无法正常工作,ZAB协议提供了一个高效且可靠的leader选举算法。 Leader宕机后,被选举的新Leader需要解决的问题
- ZAB 协议确保那些已经在 Leader 提交的事务最终会被所有服务器提交。
- ZAB 协议确保丢弃那些只在 Leader 提出/复制,但没有提交的事务。
基于上面的目的,ZAB协议设计了一个选举算法:能够确保已经被Leader提交的事务被集群接受,丢弃 还没有提交的事务。
这个选举算法的关键点:保证选举出的新Leader拥有集群中所有节点最大编号(ZXID)的事务!!
-
Zookeeper应用实践
ZooKeeper是一个典型的发布/订阅模式的分布式数据管理与协调框架,我们可以使用它来进行分布 式数据的发布与订阅。另一方面,通过对ZooKeeper中丰富的数据节点类型进行交叉使用,配合 Watcher事件通知机制,可以非常方便地构建一系列分布式应用中都会涉及的核心功能,如数据发布/订 阅、命名服务、集群管理、Master选举、分布式锁和分布式队列等
Zookeeper的两大特性:
- 客户端如果对Zookeeper的数据节点注册Watcher监听,那么当该数据节点的内容或是其子节点列表发生变更时,Zookeeper服务器就会向订阅的客户端发送变更通知。
- 对在Zookeeper上创建的临时节点,一旦客户端与服务器之间的会话失效,那么临时节点也会被自动删除
利用其两大特性,可以实现集群机器存活监控系统,若监控系统在/clusterServers节点上注册一个 Watcher监听,那么但凡进行动态添加机器的操作,就会在/clusterServers节点下创建一个临时节 点:/clusterServers/[Hostname],这样,监控系统就能够实时监测机器的变动情况。
服务器动态上下线监听
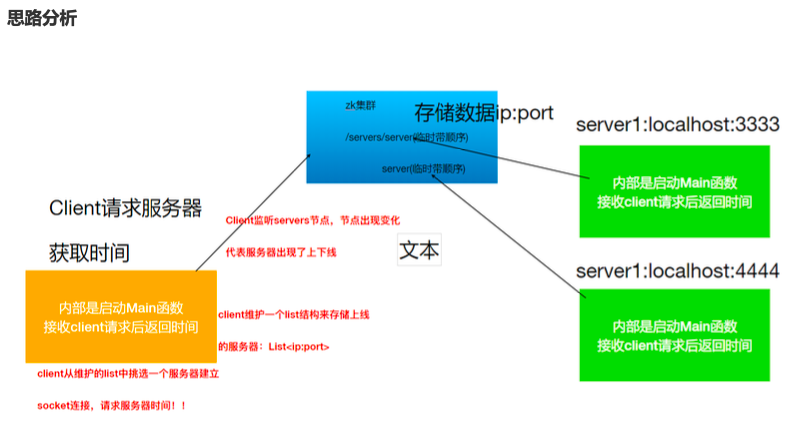
分布式系统中,主节点会有多台,主节点可能因为任何原因出现宕机或者下线,而任意一台客户端都要能实时感知到主节点服务器的上下线。
分布式锁
分布式锁的作用:在整个系统提供一个全局、唯一的锁,在分布式系统中每个系统在进行相关操作的时候需要获取到该锁,才能执行相应操作。
- zk实现分布式锁
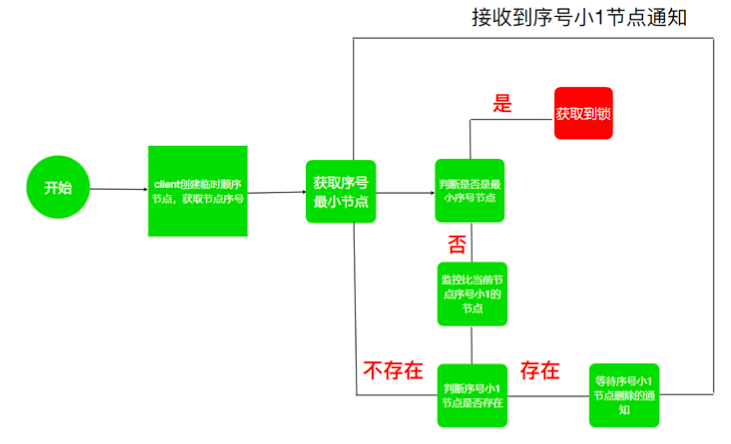
- 利用Zookeeper可以创建临时带序号节点的特性来实现一个分布式锁
- 锁就是zk指定目录下序号最小的临时序列节点,多个系统的多个线程都要在此目录下创建临时的顺 序节点,因为Zk会为我们保证节点的顺序性,所以可以利用节点的顺序进行锁的判断。
- 每个线程都是先创建临时顺序节点,然后获取当前目录下最小的节点(序号),判断最小节点是不是 当前节点,如果是那么获取锁成功,如果不是那么获取锁失败。
- 获取锁失败的线程获取当前节点上一个临时顺序节点,并对此节点进行监听,当该节点删除的时候(上一个线程执行结束删除或者是掉线zk删除临时节点)这个线程会获取到通知,代表获取到了锁。
Hadoop HA
HA 概述
- 所谓HA(High Available),即高可用(7*24小时不中断服务)。
- 实现高可用最关键的策略是消除单点故障。Hadoop-HA严格来说应该分成各个组件的HA机制:
HDFS的HA和YARN的HA。 - Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
- NameNode主要在以下两个方面影响HDFS集群
- NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
- NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述 问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切 换到另外一台机器。
HDFS-HA 工作机制
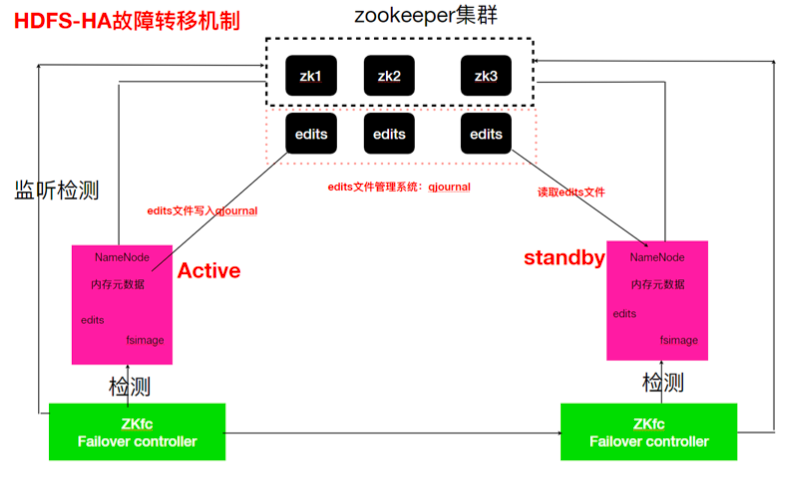
通过双NameNode消除单点故障(Active/Standby)
- HDFS-HA工作要点
- 元数据管理方式需要改变
内存中各自保存一份元数据; Edits日志只有Active状态的NameNode节点可以做写操作; 两个NameNode都可以读取Edits; 共享的Edits放在一个共享存储中管理(qjournal和NFS两个主流实现); - 需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在 NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换 时需要防止brain split现象的发生(集群中出现两个Active的Namenode)。 - 必须保证两个NameNode之间能够ssh无密码登录
- 隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
- 元数据管理方式需要改变
-
配置部署HDFS-HA进行自动故障转移 自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和 ZKFailoverController(ZKFC)进程,ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和 监视客户端故障的高可用服务。HA的自动故障转移依赖于ZooKeeper的以下功能:
-
故障检测 集群中的每个NameNode在ZooKeeper中维护了一个临时会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
-
现役NameNode选择 ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役 NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役 NameNode。
-
-
ZooKeeper的客户端 ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。 每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
-
健康监测 ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时 地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监 测器标识该节点为非健康的。
-
ZooKeeper会话管理 当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode 处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如 果会话终止,锁节点将自动删除。
-
基于ZooKeeper的选择 如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取 该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为 Active。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前的现役 NameNode,然后本地NameNode转换为Active状态。
-
HDFS-HA集群配置
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
- 环境准备
- 修改IP
- 修改主机名及主机名和IP地址的映射
- 关闭防火墙
- ssh免密登录
- 安装JDK,配置环境变量等
-
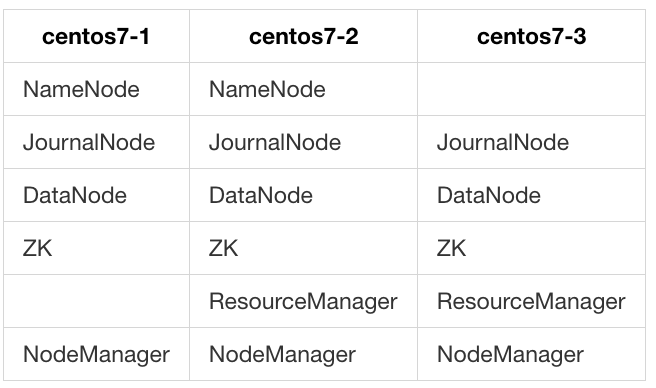
集群规划
- 启动Zookeeper集群
zk.sh start -
配置HDFS-HA集群
- 删除原集群data目录
rm -rf /opt/lagou/servers/ha/hadoop-2.9.2/data - 配置hdfs-site.xml
<property> <name>dfs.nameservices</name> <value>lagoucluster</value> </property> <property> <name>dfs.ha.namenodes.lagoucluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.lagoucluster.nn1</name> <value>centos7-1:9000</value> </property> <property> <name>dfs.namenode.rpc-address.lagoucluster.nn2</name> <value>centos7-2:9000</value> </property> <property> <name>dfs.namenode.http-address.lagoucluster.nn1</name> <value>centos7-1:50070</value> </property> <property> <name>dfs.namenode.http-address.lagoucluster.nn2</name> <value>centos7-2:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://centos7-1:8485;centos7-2:8485;centos7-3:8485/lagou</value> </property> <property> <name>dfs.client.failover.proxy.provider.lagoucluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/journalnode</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>- 配置core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://lagoucluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/lagou/servers/ha/hadoop-2.9.2/data/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>centos7-1:2181,centos7-2:2181,centos7-3:2181</value> </property>- yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--启用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--声明两台resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>centos7-2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>centos7-3</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>centos7-1:2181,centos7-2:2181,centos7-3:2181</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的状态信息存储在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> -
配置core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://lagoucluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/lagou/servers/ha/hadoop-2.9.2/data/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>centos7-1:2181,centos7-2:2181,centos7-3:2181</value> </property> - 拷贝配置好的hadoop环境到其他节点
rsync-script /opt/lagou/servers/ha/hadoop-2.9.2/
- 删除原集群data目录
-
启动HDFS-HA集群
- 启动各个JournalNode节点
/opt/lagou/servers/ha/hadoop-2.9.2/sbin/hadoop-daemon.sh start journalnode - 在[nn1]上,对其进行格式化,并启动
/opt/lagou/servers/ha/hadoop-2.9.2/bin/hdfs namenode -format /opt/lagou/servers/ha/hadoop-2.9.2/sbin/hadoop-daemon.sh start namenode - 在[nn2]上,同步nn1的元数据信息
/opt/lagou/servers/ha/hadoop-2.9.2/bin/hdfs namenode -bootstrapStandby - 在[nn1]上初始化zkfc
/opt/lagou/servers/ha/hadoop-2.9.2/bin/hdfs zkfc -formatZK - 在[nn1]上,启动集群
/opt/lagou/servers/ha/hadoop-2.9.2/sbin/start-dfs.sh
- 启动各个JournalNode节点
YARN-HA配置
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
-
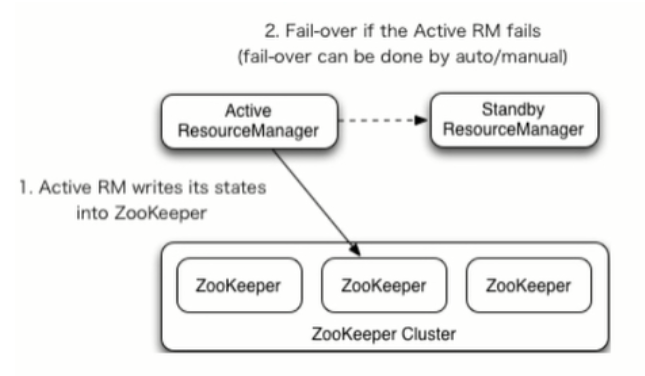
YARN-HA工作机制
-
配置YARN-HA集群
- 环境准备
- 修改IP
- 修改主机名及主机名和IP地址的映射
- 关闭防火墙
- ssh免密登录
- 安装JDK,配置环境变量等
- 配置Zookeeper集群
-
规划集群
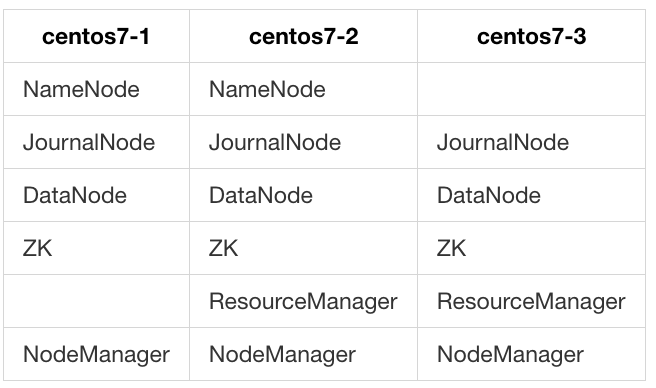
-
具体配置
- yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--启用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--声明两台resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>centos7-2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>centos7-3</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>centos7-1:2181,centos7-2:2181,centos7-3:2181</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的状态信息存储在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> - 同步更新其他节点的配置信息
rsync-script yarn-site.xml - 启动yarn
# 在rm1 /opt/lagou/servers/ha/hadoop-2.9.2/sbin/start-yarn.sh # 在rm2 /opt/lagou/servers/ha/hadoop-2.9.2/sbin/yarn-daemon.sh start resourcemanager
- yarn-site.xml
- 环境准备