拉链表
缓慢变化维
缓慢变化维(SCD;Slowly Changing Dimensions)。在现实世界中,维度的属性随着时间的流失发生缓慢的变化(缓慢是相对事实表而言,事实表数据变化的速度比维度表快)。
处理维度表的历史变化信息的问题称为处理缓慢变化维的问题,简称SCD问题。处理缓慢变化维的方法有以下几种常见方式:
- 保留原值
- 直接覆盖
- 增加新属性列
- 快照表
- 拉链表
保留原始值
维度属性值不做更改,保留原始值。
如商品上架售卖时间:一个商品上架售卖后由于其他原因下架,后来又再次上架,此种情况产生了多个商品上架售卖时间。如果业务重点关注的是商品首次上架售卖时间,则采用该方式。
直接覆盖
修改维度属性为最新值,直接覆盖,不保留历史信息。 如商品属于哪个品类:当商品品类发生变化时,直接重写为新品类。
增加新属性列
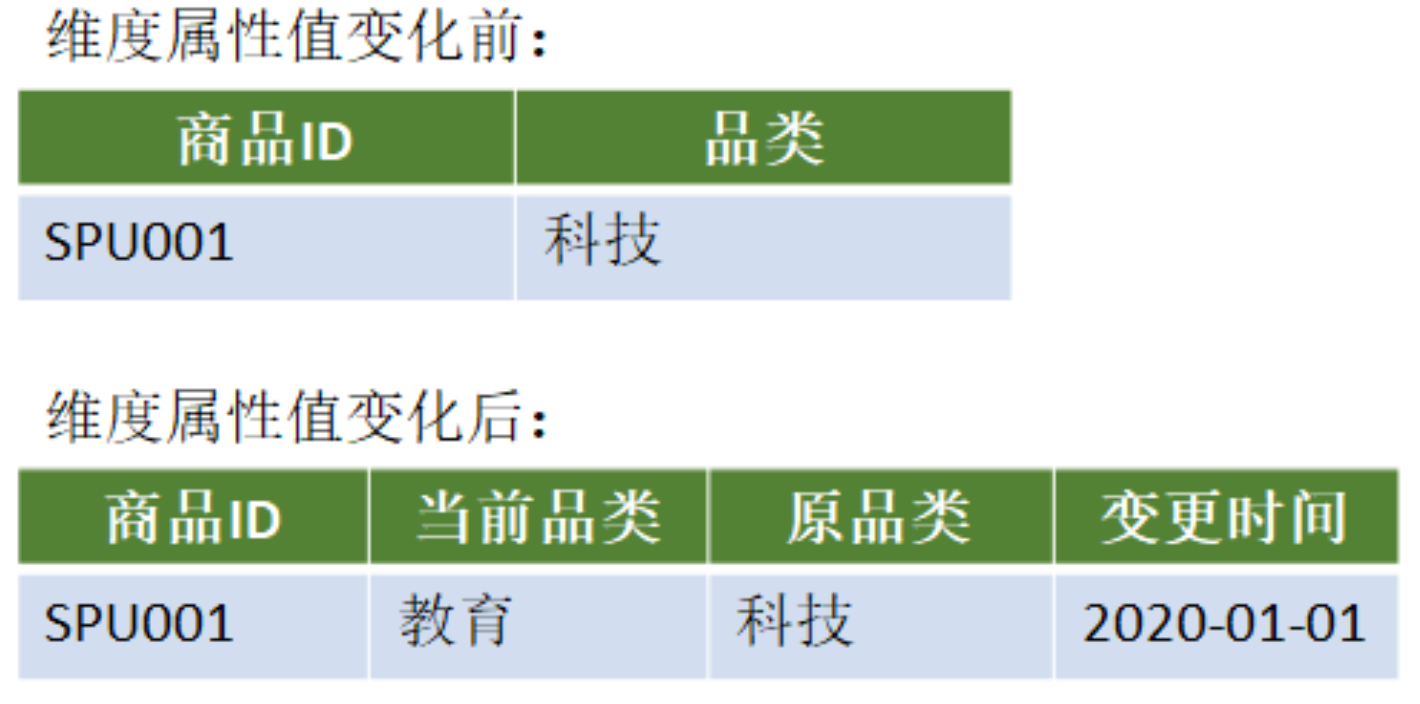
在维度表中增加新的一列,原先属性列存放上一版本的属性值,当前属性列存放当前版本的属性值,还可以增加一列记录变化的时间。
缺点:只能记录最后一次变化的信息。
快照表
每天保留一份全量数据。 简单、高效。缺点是信息重复,浪费磁盘空间。
适用范围:维表不能太大
使用场景多,范围广;一般而言维表都不大。
拉链表
拉链表适合于:表的数据量大,而且数据会发生新增和变化,但是大部分是不变的 (数据发生变化的百分比不大),且是缓慢变化的(如电商中用户信息表中的某些用 户基本属性不可能每天都变化)。主要目的是节省存储空间。
适用场景:
- 表的数据量大
- 表中部分字段会被更新
- 表中记录变量的比例不高
- 需要保留历史信息
周期性事实表
比如订单表,创建之后会有状态变化。
- 只保留一份全量。数据和6月22日的记录一样,如果需要查看6月21日订单001的状态,则无法满足;
- 每天都保留一份全量。在数据仓库中可以在找到所有的历史信息,但数据量大了,而且很多信息都是重复的,会造成较大的存储浪费;
- 使用拉链表保存历史信息,历史拉链表,既能满足保存历史数据的需求,也能节省存储资源。
前提条件:
- 订单表的刷新频率为一天,当天获取前一天的增量数据;
- 如果一个订单在一天内有多次状态变化,只记录最后一个状态的信息;
- 订单状态包括三个:创建、支付、完成;
- 创建时间和修改时间只取到天,如果源订单表中没有状态修改时间,那么抽取增量就比较麻烦,需要有个机制来确保能抽取到每天的增量数据;
拉链表的实现
hive 的实现
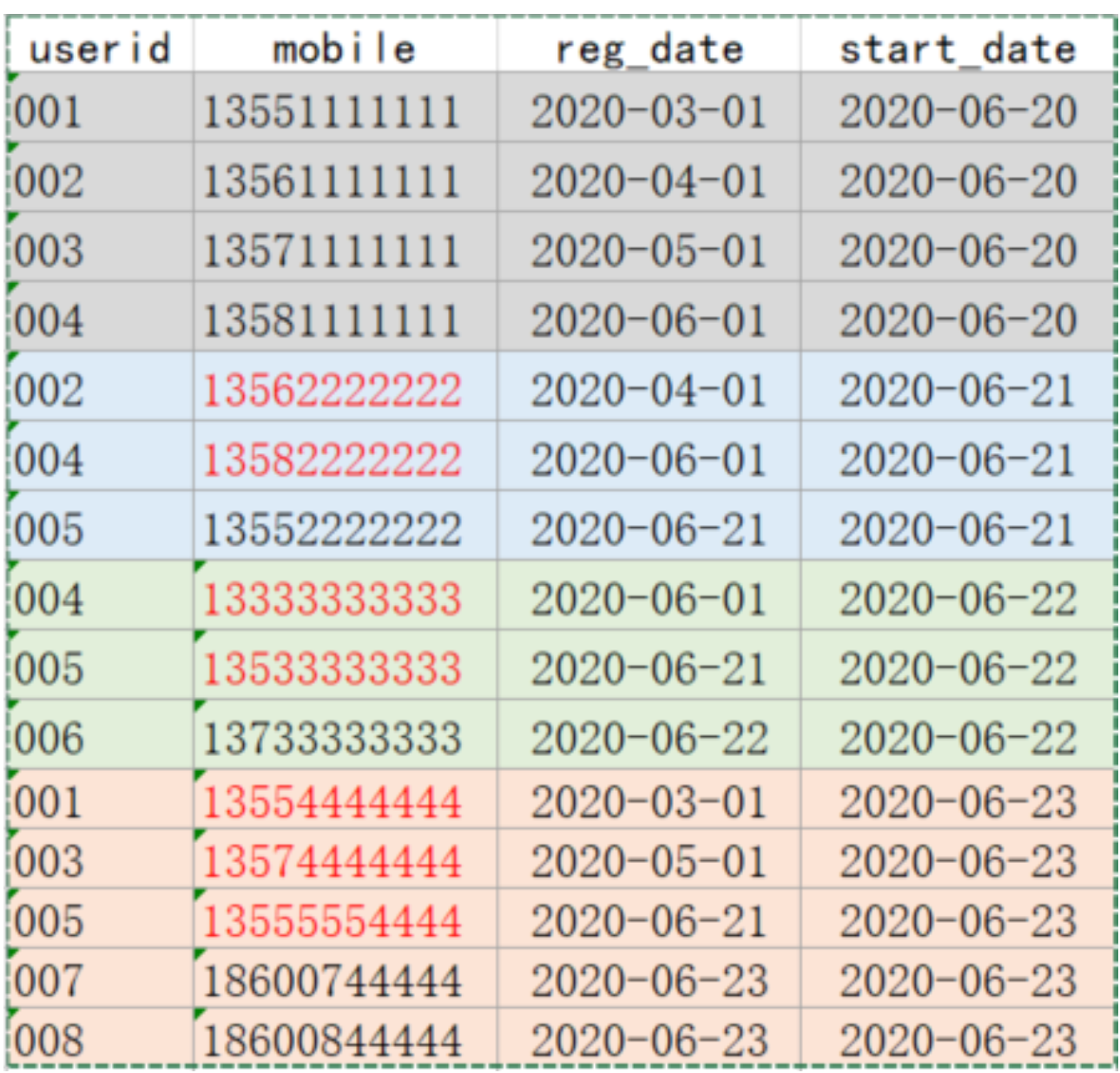
原始数据
实现思路
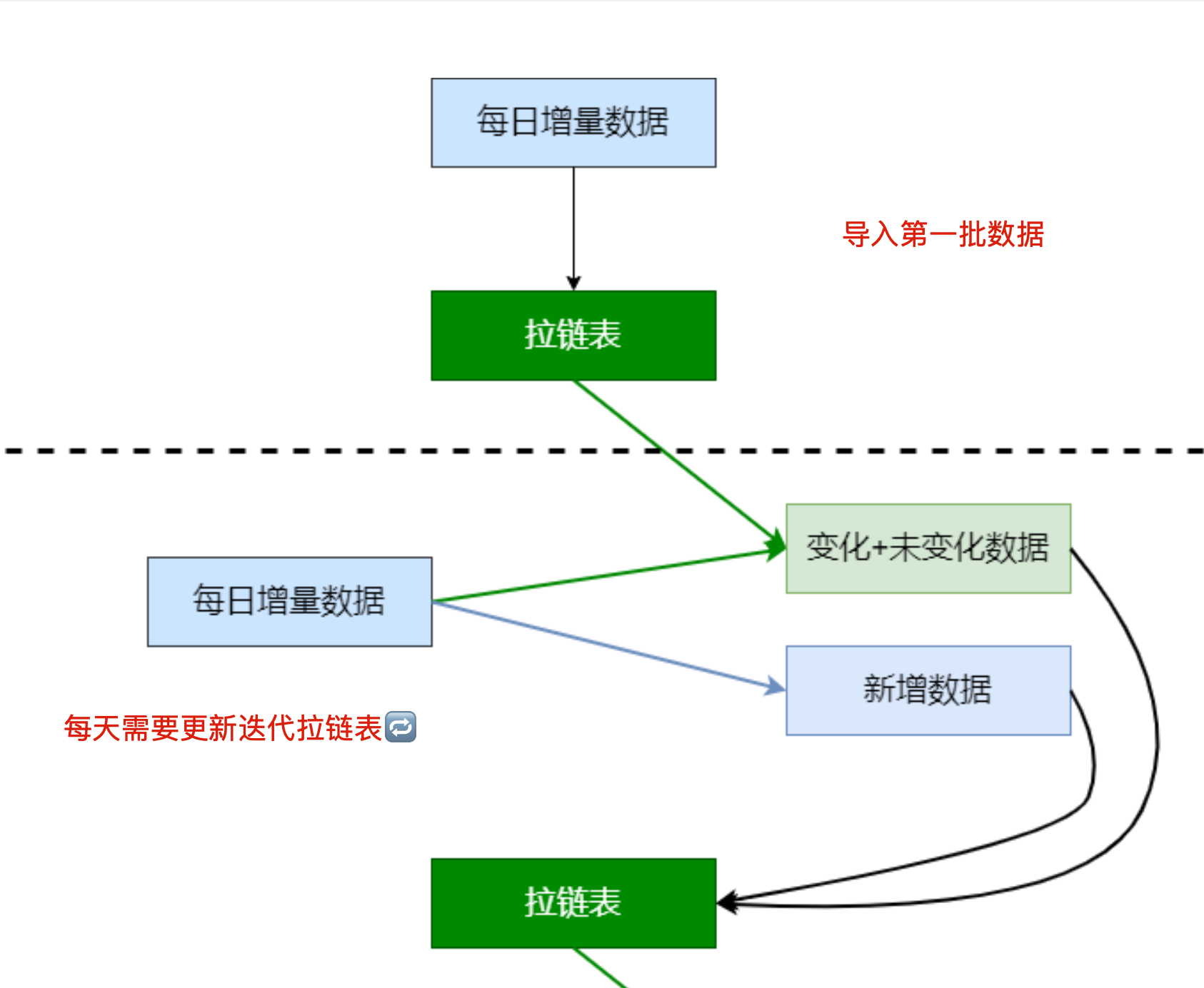
- 初始化数据,生效时间是当天,失效时间永久
- 新增的时候,查看历史表是否有id一样的数据,
有的话把历史数据的失效时间改为昨天(hive弱支持事务,每次新增都需要覆盖整张表) - 添加新增数据,开始时间当日,结束时间永久
- 每日重复2、3
具体实现
- 建表与数据导入
-- 原数据表 DROP TABLE IF EXISTS test.userinfo; CREATE TABLE test.userinfo( userid STRING COMMENT '用户编号', mobile STRING COMMENT '手机号码', regdate STRING COMMENT '注册日期') COMMENT '用户信息' PARTITIONED BY (dt string) row format delimited fields terminated by ','; -- 拉链表(存放用户历史信息) -- 拉链表不是分区表;多了两个字段start_date、end_date DROP TABLE IF EXISTS test.userhis; CREATE TABLE test.userhis( userid STRING COMMENT '用户编号', mobile STRING COMMENT '手机号码', regdate STRING COMMENT '注册日期', start_date STRING, end_date STRING) COMMENT '用户信息拉链表' row format delimited fields terminated by ','; -- 动态分区数据加载:分区的值是不固定的,由输入数据确定 -- 创建中间表(非分区表) drop table if exists test.tmp1; create table test.tmp1 as select * from test.userinfo; desc formatted test.tmp1; desc formatted test.userinfo; -- tmp1 非分区表,使用系统默认的字段分割符'\001' ALTER table test.tmp1 set serdeproperties("field.delim"=','); -- 加载数据到临时表 load data local inpath '/data/lagoudw/data/userinfo.dat' into table test.tmp1; -- 动态分区非严格模式 set hive.exec.dynamic.partition.mode = nonstrict; -- 动态插入分区表 insert overwrite table test.userinfo partition(dt) select * from test.tmp1; - 更新拉链表数据
-- 1、初始化拉链表,导入第一天的数据. insert overwrite table test.userhis select userid, mobile, regdate, dt as start_date, '9999-12-31' as end_date from test.userinfo where dt='$first_date'; -- 2、构建拉链表(userhis), 每日增量数据 -- userinfo(do_date) + userhis => userhis -- userinfo: 新增数据 -- userhis: 历史数据 insert overwrite table test.userhis -- 找出拉链表中需要设置为过期的数据,更新它们 SELECT A.userid, A.mobile, A.regdate, A.start_date, if(B.userid is not null and A.end_date='9999-12-31', date_add('$do_date', -1), A.end_date) end_date from test.userhis A left join (select * from test.userinfo where dt='$do_date') B ON A.userid=B.userid union all -- 当日新增数据 select userid, mobile, regdate, dt as start_date, '9999-12-31' as end_date from test.userinfo where dt='$do_date'; - 拉链表的使用
-- 查看拉链表中最新数据 SELECT * from test.userhis where end_date>="9999-12-31" order by userid; -- 查看拉链表中给定日期数据("2020-06-22") SELECT * from test.userhis where start_date<='2020-06-22' and end_date>="2020-06-22" order by userid; -- 查看拉链表中给定日期数据("2020-06-21") SELECT * from test.userhis where start_date<='2020-06-21' and end_date>="2020-06-21" order by userid; -- 查看拉链表中给定日期数据("2020-06-20") SELECT * from test.userhis where start_date<='2020-06-20' and end_date>="2020-06-20" order by userid; -
拉链表的回滚
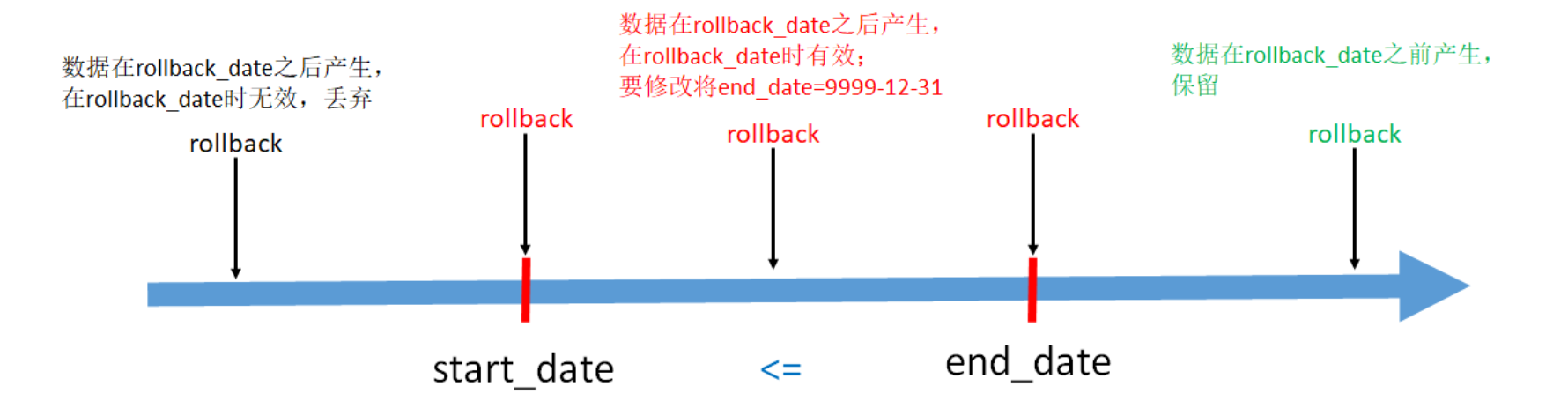 由于种种原因需要将拉链表恢复到 rollback_date 那一天的数据。此时有:
由于种种原因需要将拉链表恢复到 rollback_date 那一天的数据。此时有:- end_date < rollback_date,即结束日期 < 回滚日期。表示该行数据在 rollback_date 之前产生,这些数据需要原样保留
- start_date <= rollback_date <= end_date,即开始日期 <= 回滚日期 <= 结束日 期。这些数据的失效日期在回滚日期之后, 所以需要修改。将end_date 改为 9999-12-31
- rollback_date < start_date, 即回滚日期 < 开始日期, 这部分数据需要删除
-- 1. 忽略回滚日期之后产生的数据 start_date > rollback_date --> when start_date<=rollback_date -- 2. end_date < rollback_date 原封不动, end_date >= rollback_date , end_date = 永久有效(9999-12-31) --> if(end_date < rollback_date, end_date, 9999-12-31) end_date insert overwrite table test.userhis select userid, mobile, regdate, start_date, if(end_date<'$rollback_date', end_date, '9999-12-31') end_date from test.userhis where start_date <= '$rollback_date';- 方案二 保存一段时间的增量数据(userinfo),定期对拉链表做备份(如一个月做一 次备份);如需回滚,直接在备份的拉链表上重跑增量数据。处理简单
- 周期性订单表的实现
- 与维表不同,订单事实表的记录数非常多
- 订单有生命周期;订单的状态不可能永远处于变化之中(订单的生命周期一般在 15天左右)
- 订单是一个拉链表,而且是分区表
- 分区的目的:订单一旦终止,不会重复计算
- 分区的条件:订单创建日期;保证相同的订单在用一个分区
-- 订单事实表(拉链表) DROP TABLE IF EXISTS dwd.dwd_trade_orders; create table dwd.dwd_trade_orders( `orderId` int, ... `createTime` string, `modifiedTime` string, `start_date` string, `end_date` string ) COMMENT '订单事实拉链表' partitioned by (dt string) STORED AS PARQUET; -- 这里需要处理动态分区 -- 动态插入分区表的时候,最后一个字段是分区依据,别名对结果没有影响 set hive.exec.dynamic.partition.mode=nonstrict; set hive.exec.dynamic.partition=true; INSERT OVERWRITE TABLE dwd.dwd_trade_orders partition(dt) -- 导入新数据,使用修改时间或创建时间作为开始时间,分区使用开始时间,假设一条订单15天内就会结束更新 select orderId, ... createTime, modifiedTime, case when modifiedtime is not null then from_unixtime(unix_timestamp(modifiedtime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') else from_unixtime(unix_timestamp(createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') end as start_date, '9999-12-31' end_date, from_unixtime(unix_timestamp(createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') dt from ods.ods_trade_orders where dt='$do_date' union all select T1.orderId, ... T1.createTime, T1.modifiedTime, T1.start_date, case when T2.orderId is not null and T1.end_date='9999-12-31' then date_add('$do_date', -1) else T1.end_date end as end_date, T1.dt from (select orderId, ... createTime,modifiedTime, start_date, end_date, dt from dwd.dwd_trade_orders where dt>date_add('$do_date', -15)) T1 --选取15天内的数据,查看是否需要更新状态 left join (select orderId from ods.ods_trade_orders where dt='$do_date') T2 on T1.orderId=T2.orderId;