使用 Jupyter notebook 启动 spark-shell
在Jupyter notebook上面运行spark-shell,方便交互式学习API
-
确认本地能够正常启动 spark-shell,(spark, hadoop,java环境已经配好了)
-
能够使用 pip 或 pip3
# 安装依赖, 如果是pip3 记得把python改成 python3 pip install jupyter notebook # 添加启动 spark-scala 的内核 pip install spylon-kernel python -m spylon_kernel
3.启动jupyter notebook
# 如果是root模式需要添加 --allow-root,如果在服务器运行,需要指定ip,不然只能在本机访问
jupyter notebook --allow-root --ip=centos7-1
-
打开终端提示的url
-
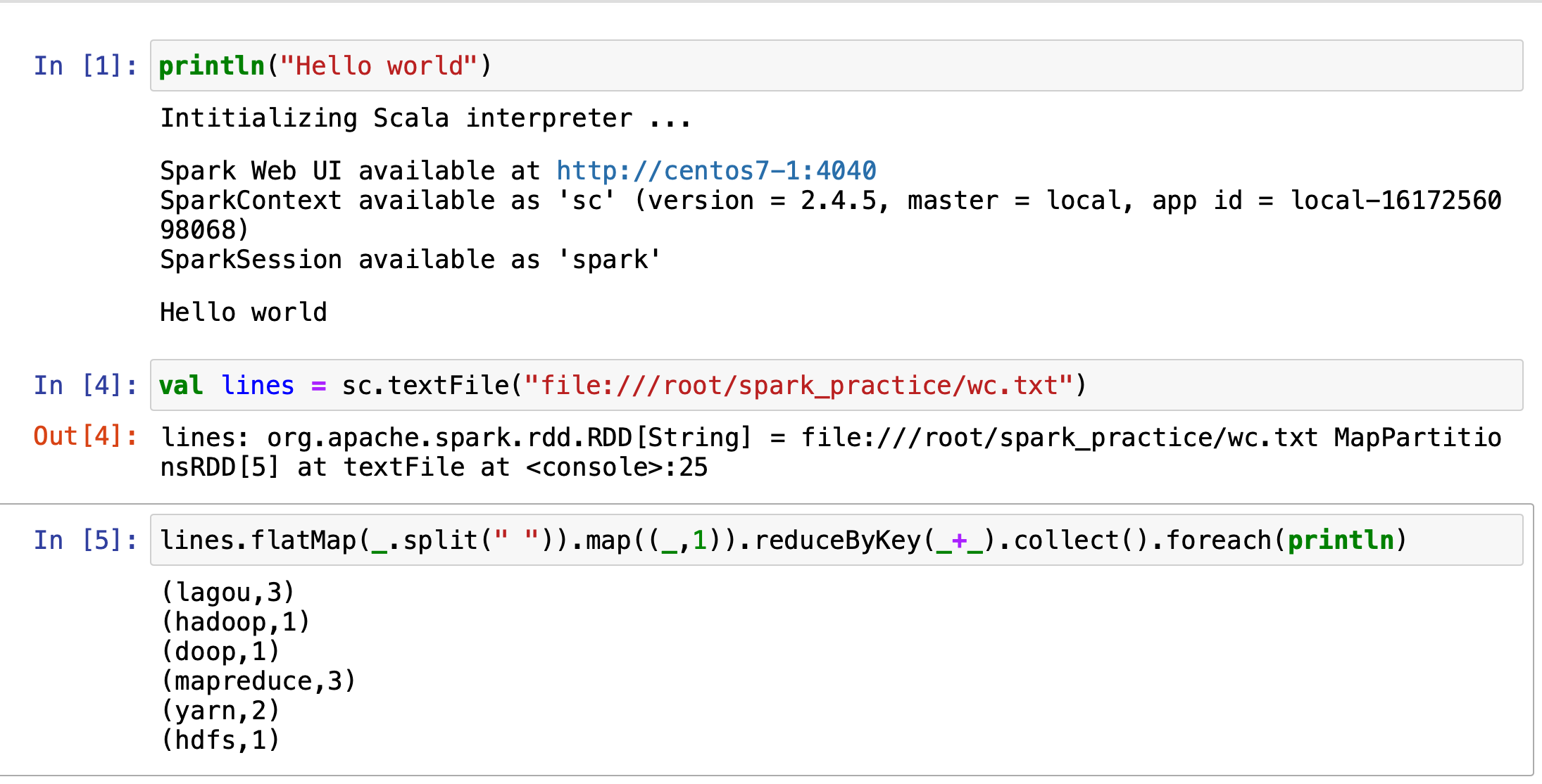
创建一个spylon-kernel的文件
-
如果spark初始化失败,可以查看jupyter notebook打印的错误信息, 根据报错的信息做对应处理
# 修改spark-shell启动的默认参数
vim $SPARK_HOME/conf/spark-defaults.conf
# 使用本地模式运行,学习的时候使用
spark.master local