Spark Core & SparkSQL
Spark Core
Spark概述
-
Spark的特点
-
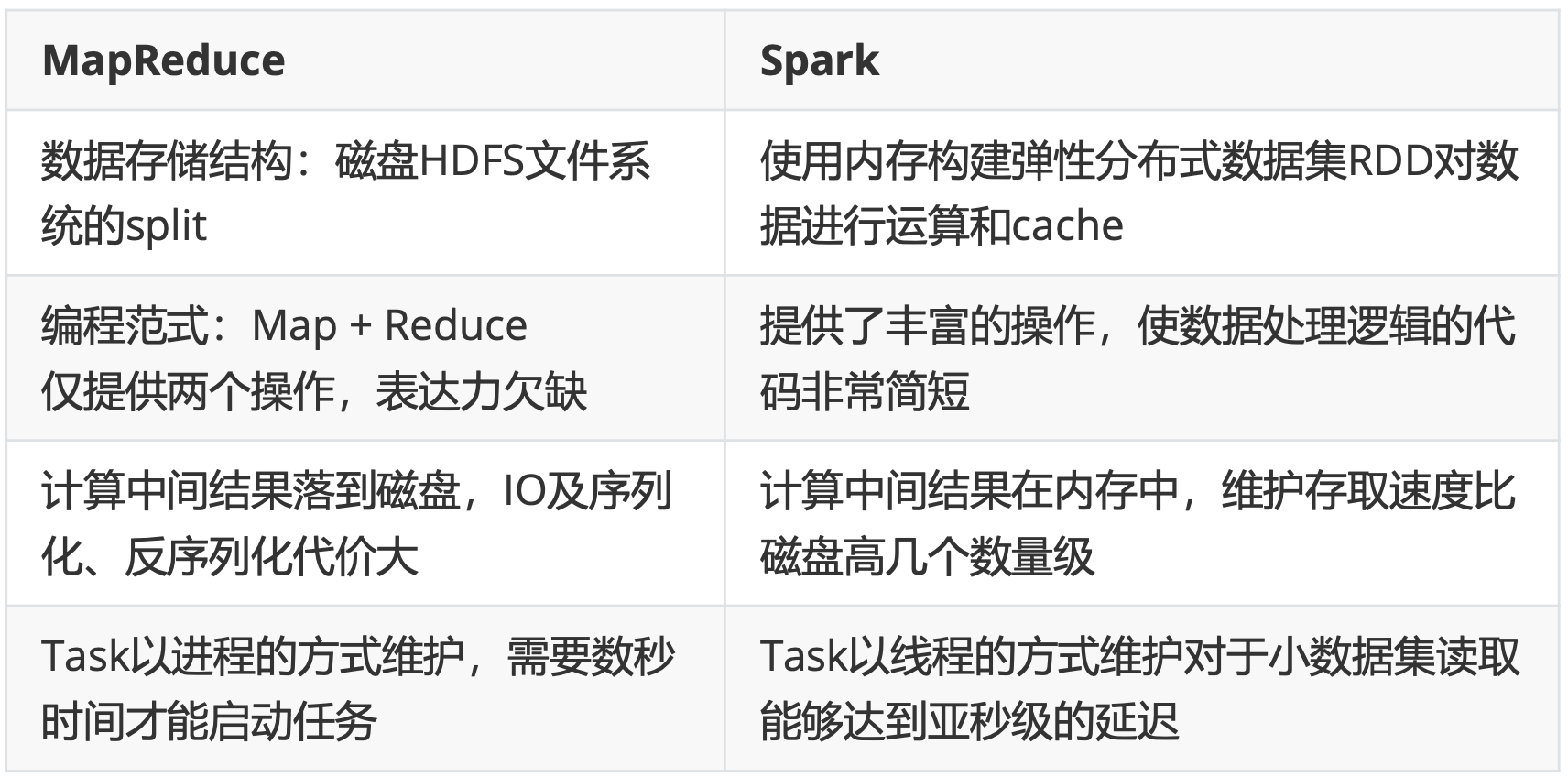
速度快 与 MapReduce 相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流;
-
使用简单 Spark支持 Scala、Java、Python、R的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala 的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法;
-
通用 Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询 (Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算 (GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,企业想用统一的平台去处理遇到的问题,减少开发和 维护的人力成本和部署平台的物力成本;
-
兼容好 Spark可以非常方便地与其他的开源产品进行融合。Spark可以使用 YARN、Mesos作为它的资源管理和调度器;可以处理所有Hadoop支持的数 据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark 也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置 的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
-
-
Spark 与 Hadoop
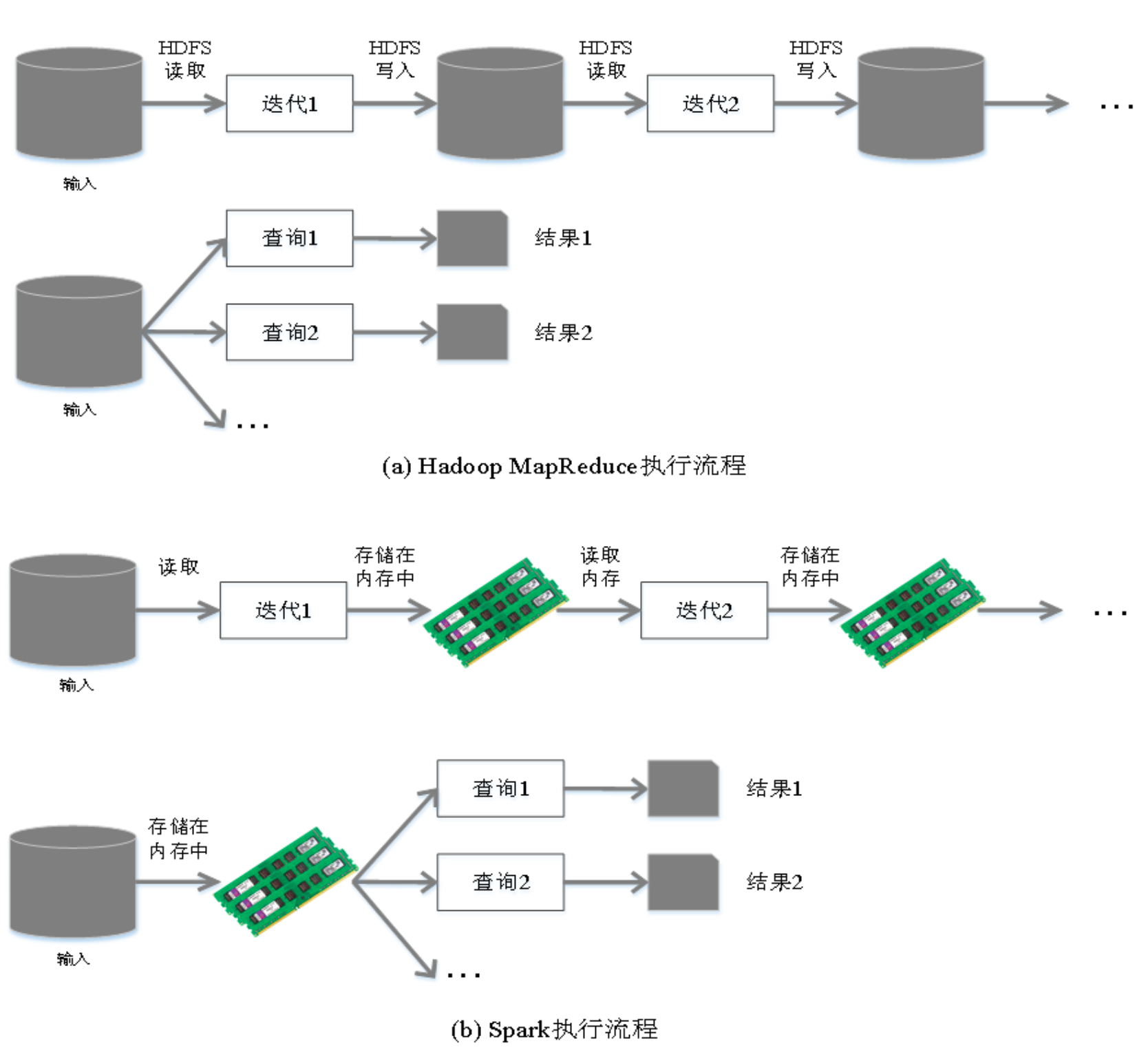 从狭义的角度上看:Hadoop是一个分布式框架,由存储、资源调度、计算三部分组成;
从狭义的角度上看:Hadoop是一个分布式框架,由存储、资源调度、计算三部分组成;
Spark是一个分布式计算引擎,由 Scala 语言编写的计算框架,基于内存的快速、通用、可扩展的大数据分析引擎;
从广义的角度上看,Spark是Hadoop生态中不可或缺的一部分;- MapReduce的不足
- 表达能力有限, 计算模式只有M、R
- 磁盘IO开销大
- 延迟高
- 任务之间的衔接有IO开销
- 在前一个任务执行完成之前,后一个任务无法开始。难以胜任复杂的、多阶段计算任务
-
 Spark在借鉴MapReduce优点的同时,很好地解决了MapReduce所面临的问题。
Spark在借鉴MapReduce优点的同时,很好地解决了MapReduce所面临的问题。备注:Spark的计算模式也属于MapReduce;Spark框架是对MR框架的优化;
- spark 解决的问题
在实际应用中,大数据应用主要包括以下三种类型:
- 批量处理(离线处理):通常时间跨度在数十分钟到数小时之间
- 交互式查询:通常时间跨度在数十秒到数分钟之间
- 流处理(实时处理):通常时间跨度在数百毫秒到数秒之间
当同时存在以上三种场景时,传统的Hadoop框架需要同时部署三种不同的软件。 如:
- MapReduce / Hive 或 Impala / Storm
这样做难免会带来一些问题:
- 不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换
- 不同的软件需要不同的开发和维护团队,带来了较高的使用成本
- 比较难以对同一个集群中的各个系统进行统一的资源协调和分配
Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和 流数据处理:
- Spark的设计遵循“一个软件栈满足不同应用场景”的理念(all in one),逐渐形成了一套完整的生态系统
- 既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等
- Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案
-
Spark 为什么比 MapReduce 快
-
Spark积极使用内存 MR框架中一个Job 只能拥有一个 map task 和一个 reduce task。如果业务处理逻辑复杂,一个map和一个reduce是表达不出来的,这时就需 要将多个 job 组合起来;然而前一个job的计算结果必须写到HDFS,才能交给后一个 job。这样一个复杂的运算,在MR框架中会发生很多次写入、读取操作操作;Spark 框架则可以把多个map reduce task组合在一起连续执行,中间的计算结果不需要落地;
复杂的MR任务:mr + mr + mr + mr +mr …
复杂的Spark任务:mr -> mr -> mr …… -
多进程模型(MR) vs 多线程模型(Spark) MR框架中的的Map Task和Reduce Task是进程级别的,而Spark Task是基于线程模型的。MR框架中的 map task、 reduce task都是 jvm 进程,每次启动都需要重新申请资源,消耗了不必要的时间。 Spark则是通过复用线程池中的线程来减少启动、关闭task所需要的系统开销。
-
- MapReduce的不足
-
系统架构
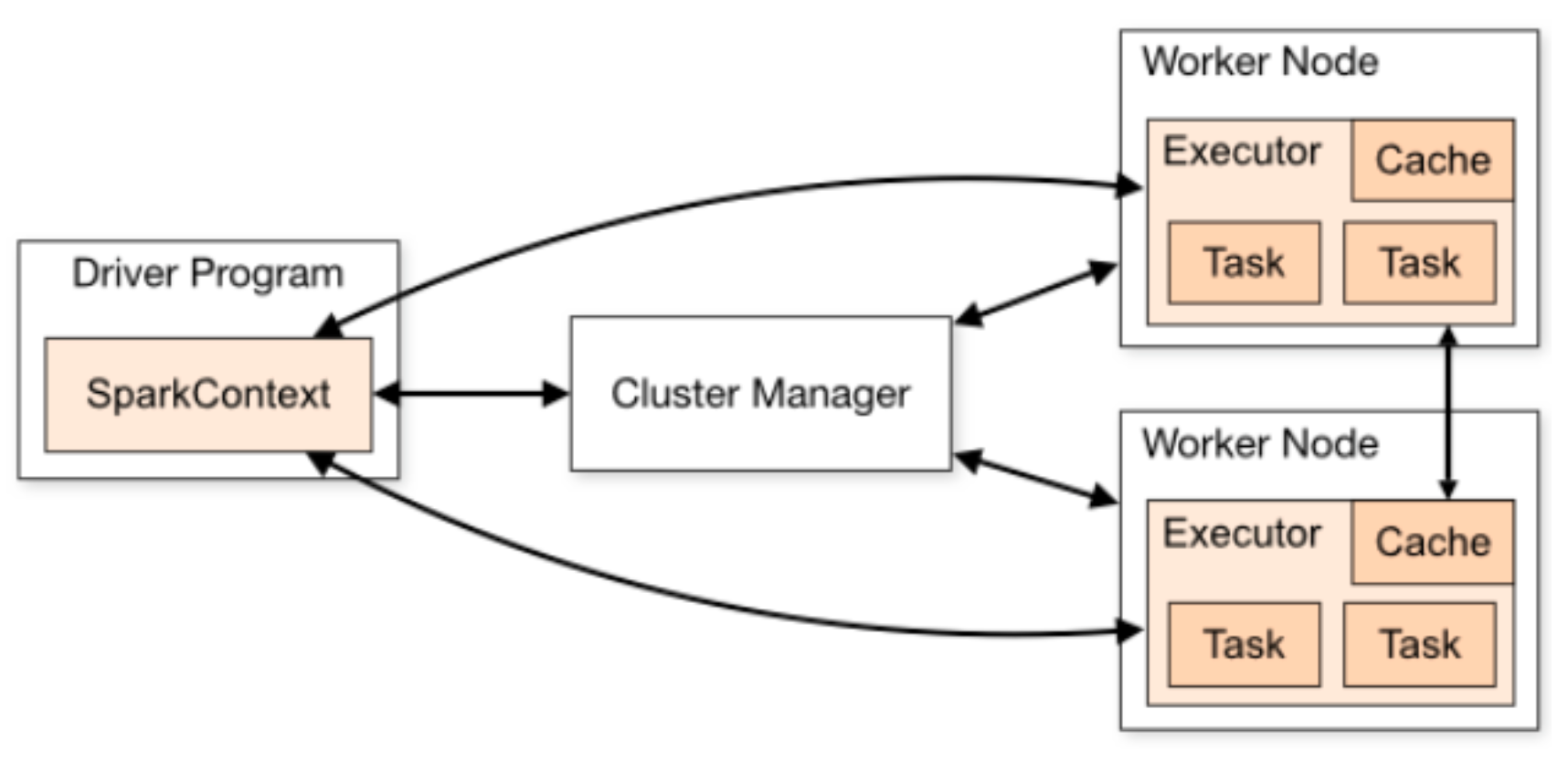 Spark运行架构包括:
Spark运行架构包括:-
Cluster Manager 是集群资源的管理者。Spark支持3种集群部署模式: Standalone、Yarn、Mesos;
-
Worker Node 工作节点,管理本地资源;
-
Driver Program 运行应用的 main() 方法并且创建了 SparkContext。由Cluster Manager分配资源,SparkContext 发送 Task 到 Executor 上执行;
-
Executor 在工作节点上运行,执行 Driver 发送的 Task,并向 Driver 汇报计算结果;
-
-
Spark集群部署模式
- Standalone模式
- 独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源 管理系统。从一定程度上说,该模式是其他两种的基础
- Cluster Manager:Master
- Worker Node:Worker
- 仅支持粗粒度的资源分配方式
- Spark On Yarn模式
- Yarn拥有强大的社区支持,且逐步已经成为大数据集群资源管理系统的标准
- 在国内生产环境中运用最广泛的部署模式
- Spark on yarn 的支持两种模式:
- yarn-cluster:适用于生产环境
- yarn-client:适用于交互、调试,希望立即看到app的输出
- Cluster Manager: ResourceManager
- Worker Node: NodeManager
- 仅支持粗粒度的资源分配方式
- Spark On Mesos模式
- 官方推荐的模式。Spark开发之初就考虑到支持Mesos
- Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然
- Cluster Manager:Mesos Master
- Worker Node:Mesos Slave
- 支持粗粒度、细粒度的资源分配方式
-
粒度模式
-
粗粒度模式(Coarse-grained Mode) 每个应用程序的运行环境由一个Dirver和 若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task。 应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使空闲,最后程序运行结束后,回收这些资源。
-
细粒度模式(Fine-grained Mode) 鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计 算,核心思想是按需分配。
-
- Standalone模式
-
相关术语 http://spark.apache.org/docs/latest/cluster-overview.html
-
Application 用户提交的spark应用程序,由集群中的一个driver 和 许多 executor 组成
-
Application jar 一个包含spark应用程序的jar,jar不应该包含 Spark 或 Hadoop 的 jar,这些jar应该在运行时添加
-
Driver program 运行应用程序的main(),并创建SparkContext(Spark应用程序)
-
Cluster manager 管理集群资源的服务,如standalone,Mesos,Yarn
-
Deploy mode 区分 driver 进程在何处运行。在 Cluster 模式下,在集群内部运行 Driver。 在 Client 模式下,Driver 在集群外部运行
-
Worker node 运行应用程序的工作节点
-
Executor 运行应用程序 Task 和保存数据,每个应用程序都有自己的 executors,并且各个executor相互独立
-
Task executors应用程序的最小运行单元
-
Job 在用户程序中,每次调用Action函数都会产生一个新的job,也就是说每个 Action 生成一个job(A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs.)
-
Stage 一个 job 被分解为多个 stage,每个 stage 是一系列 Task 的集合(Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs.)
-
Spark安装配置
-
Spark安装 官网地址:http://spark.apache.org/ 文档地址:http://spark.apache.org/docs/latest/
下载地址:http://spark.apache.org/downloads.html
下载Spark安装包:https://archive.apache.org/dist/spark/备注:不用安装scala
- 下载软件解压缩,移动到指定位置
cd /opt/lagou/software/ tar zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz mv spark-2.4.5-bin-without-hadoop-scala-2.12/ ../servers/spark-2.4.5/ - 设置环境变量,并使之生效
vim /etc/profile # Spark export SPARK_HOME=/opt/lagou/servers/spark-2.4.5 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin source /etc/profile -
修改配置 文件位置:$SPARK_HOME/conf
修改文件:slaves、spark-defaults.conf、spark-env.sh、log4j.propertiesslaves
centos7-1 centos7-2 centos7-3spark-defaults.conf
spark.master spark://centos7-1:7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://centos7-1:9000/spark-eventlog spark.serializer org.apache.spark.serializer.KryoSerializer spark.driver.memory 512m创建 HDFS 目录:hdfs dfs -mkdir /spark-eventlog
备注:- spark.master。定义master节点,缺省端口号 7077
- spark.eventLog.enabled。开启eventLog
- spark.eventLog.dir。eventLog的存放位置
- spark.serializer。一个高效的序列化器
- spark.driver.memory。定义driver内存的大小(缺省1G)
修改spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_231/ export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2 export HADOOP_CONF_DIR=/opt/lagou/servers/hadoop-2.9.2/etc/hadoop export SPARK_DIST_CLASSPATH=$(/opt/lagou/servers/hadoop-2.9.2/bin/hadoop classpath) export SPARK_MASTER_HOST=centos7-1 export SPARK_MASTER_PORT=7077备注:这里使用的是 spark-2.4.5-bin-without-hadoop,所以要将 Hadoop 相关 jars 的位置告诉Spark
- 将Spark软件分发到集群;修改其他节点上的环境变量
cd /opt/lagou/software/ scp -r spark-2.4.5/ centos7-2:$PWD scp -r spark-2.4.5/ centos7-3:$PWD - 启动集群
cd $SPARK_HOME/sbin ./start-all.sh分别在centos7-1、centos7-2、centos7-3上执行 jps,可以发现:
centos7-1:Master、Worker
centos7-2:Worker
centos7-3:Worker
此时 Spark 运行在 Standalone 模式下。备注:在$HADOOP_HOME/sbin 及 $SPARK_HOME/sbin 下都有 start-all.sh 和 stop-all.sh 文件
在输入 start-all.sh / stop-all.sh 命令时,谁的搜索路径在前面就先执行谁,此时会 产生冲突。
解决方案:
将其中一组命令重命名。如:将 $HADOOP_HOME/sbin 路径下的命令重命名 为:start-all-hadoop.sh / stop-all-hadoop.sh- web界面: http://centos7-1:8080
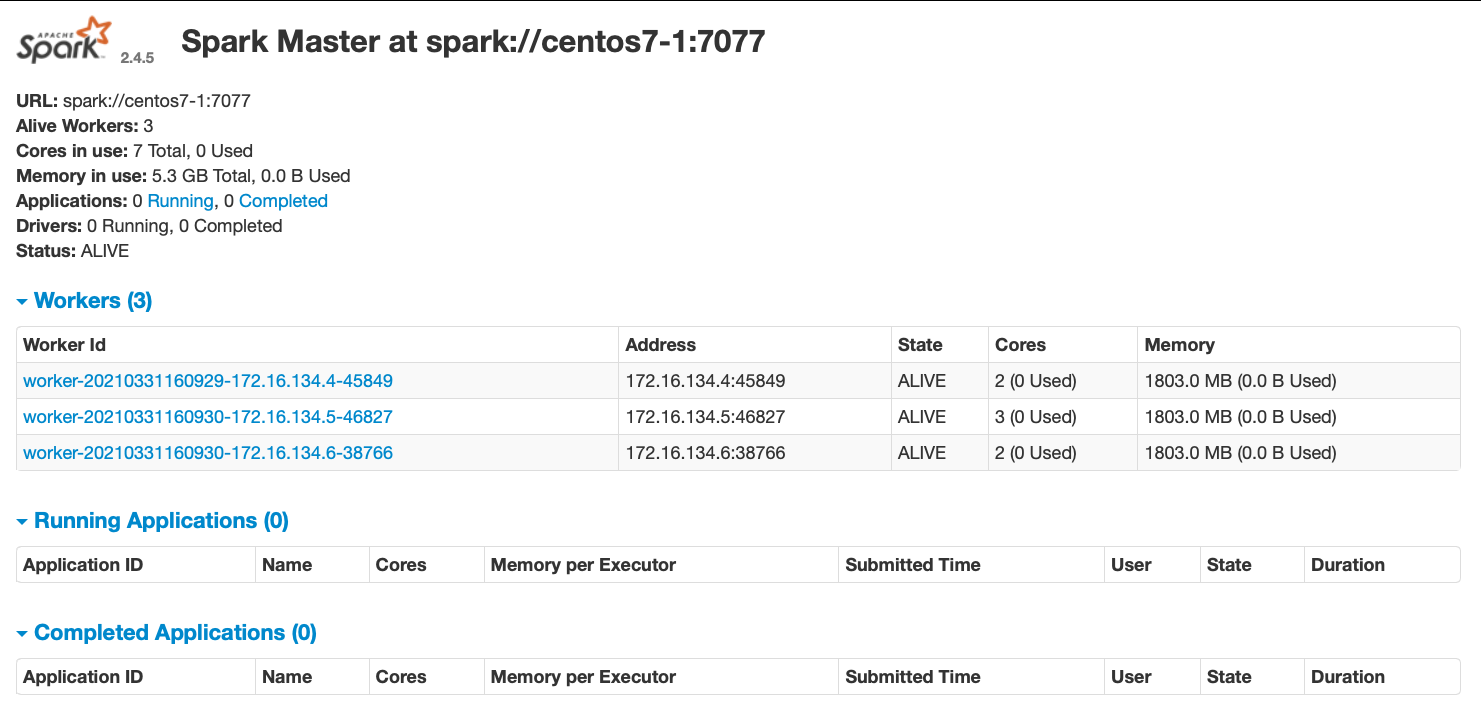
- web界面: http://centos7-1:8080
- 集群测试
# 10个迭代计算pi run-example SparkPi 10 // spark-shell // word count demo, 文件来之hdfs val lines = sc.textFile("/wcinput/wc.txt") lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
- 下载软件解压缩,移动到指定位置
- 部署模式
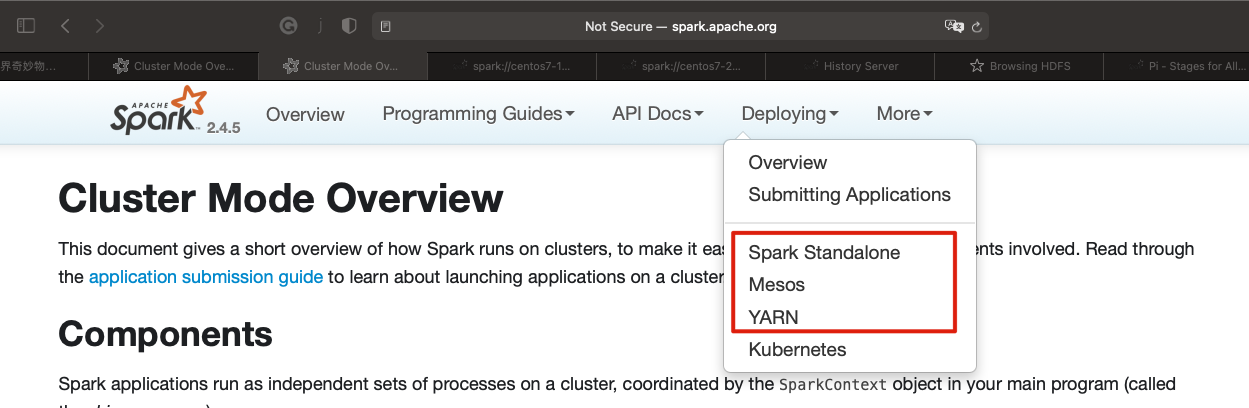 Apache Spark支持多种部署模式:
Apache Spark支持多种部署模式:
- 本地模式。最简单的运行模式,Spark所有进程都运行在一台机器的 JVM 中
- 伪分布式模式。在一台机器中模拟集群运行,相关的进程在同一台机器上(用的非常少)
- 分布式模式。包括:Standalone、Yarn、Mesos
- Standalone:使用Spark自带的资源调度框架
- Yarn:使用 Yarn 资源调度框架
-
Mesos:使用 Mesos 资源调度框架
-
本地模式 本地模式部署在单机,主要用于测试或实验;最简单的运行模式,所有进程都运行在一台机器的 JVM 中;
本地模式用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上有没有问题;
这种模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用。 不用启动Spark的Master、Worker守护进程,也不用启动Hadoop的服务(除非用 到HDFS)。- local:在本地启动一个线程来运行作业;
- local[N]:启动了N个线程;
- local[*]:使用了系统中所有的核;
- local[N,M]:第一个参数表示用到核的个数;第二个参数表示容许作业失败的次数
前面几种模式没有指定M参数,其默认值都是1;
启动 Spark 本地运行模式
spark-shell --master local备注:此时可能有错误。主要原因是配置了日志聚合(即是用来了hdfs,但hdfs服务 关闭了),关闭该选项即可
# spark.eventLog.enabled true # spark.eventLog.dir hdfs://centos7-1:9000/spark-eventlog2、使用 jps 检查,发现一个 SparkSubmit 进程 这个SparkSubmit进程又当爹、又当妈。既是客户提交任务的Client进程、又是
Spark的driver程序、还充当着Spark执行Task的Executor角色。3、执行简单的测试程序
val lines = sc.textFile("file:///root/a.txt") lines.count -
伪分布式 伪分布式模式:在一台机器中模拟集群运行,相关的进程在同一台机器上; 不用启动集群资源管理服务;
- local-cluster[N,cores,memory]
- N模拟集群的 Slave(或worker)节点个数
- cores模拟集群中各个Slave节点上的内核数
- memory模拟集群的各个Slave节点上的内存大小
备注:参数之间没有空格,memory不能加单位
1、启动 Spark 伪分布式模式
spark-shell --master local-cluster[4,2,1024]2、使用 jps 检查,发现1个 SparkSubmit 进程和4个 CoarseGrainedExecutorBackend 进程
SparkSubmit依然充当全能角色,又是Client进程,又是Driver程序,还有资源管理 的作用。
4个CoarseGrainedExecutorBackend,用来并发执行程序的进程。3、执行简单的测试程序
spark-submit --master local-cluster[4,2,1024] --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 10备注:
local-cluster[4,2,1024],参数不要给太大,资源不够
这种模式少用,有Bug, 结束的时候会报错
SPARK-32236 - local-cluster[N,cores,memory]
-
集群模式
-
Standalone模式 参考:http://spark.apache.org/docs/latest/spark-standalone.html
- 分布式部署才能真正体现分布式计算的价值
- 与单机运行的模式不同,这里必须先启动Spark的Master和Worker守护进程; 关闭 yarn 对应的服务
- 不用启动Hadoop服务,除非要使用HDFS的服务
使用jps检查,可以发现:
centos7-1:Master、Worker centos7-2:Worker
centos7-3:Worker-
Standalone 启动脚本 sbin/start-master.sh / sbin/stop-master.sh
sbin/start-slaves.sh / sbin/stop-slaves.sh
sbin/start-slave.sh / sbin/stop-slave.sh
sbin/start-all.sh / sbin/stop-all.shsbin/start-slave.sh : 需要带上master的ip和端口,如
centos7-1:7077 -
运行模式(cluster / client)
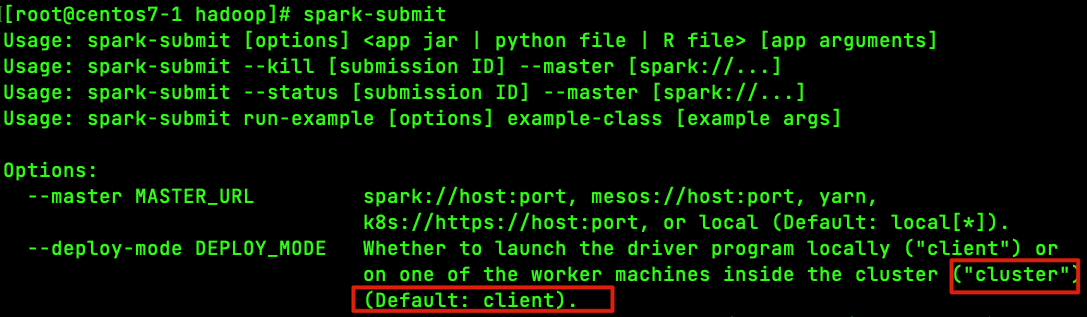
最大的区别:Driver运行在哪里;client是缺省的模式,能看见返回结果,适合调 试;cluster与此相反;- Client模式(缺省)。Driver运行在提交任务的Client,此时可以在Client模式 下,看见应用的返回结果,适合交互、调试
-
Cluster模式。Driver运行在Spark集群中,看不见程序的返回结果,合适生产环境
- Client 模式
spark-submit --class org.apache.spark.examples.SparkPi \ $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 1000再次使用 jps 检查集群中的进程:
- Master进程做为cluster manager,管理集群资源
- Worker 管理节点资源
- SparkSubmit 做为Client端,运行 Driver 程序。Spark Application执行完成, 进程终止
- CoarseGrainedExecutorBackend,运行在Worker上,用来并发执行应用程序
- Cluster 模式
# 提交之后不会输出内容 spark-submit --deploy-mode cluster --class org.apache.spark.examples.SparkPi \ $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 1000 ## 21/03/31 17:40:30 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable # 可以在 /etc/profile 添加下面的配置解决 export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/:$LD_LIBRARY_PATH- SparkSubmit 进程会在应用程序提交给集群之后就退出
- Master会在集群中选择一个 Worker 进程生成一个子进程 DriverWrapper 来启 动 Driver 程序
- Worker节点上会启动 CoarseGrainedExecutorBackend
- DriverWrapper 进程会占用 Worker 进程的一个core(缺省分配1个core,1G内 存)
- 应用程序的结果,会在执行 Driver 程序的节点的 stdout 中输出,而不是打印在 屏幕上
在启动 DriverWrapper 的节点上,进入 $SPARK_HOME/work/,可以看见类似 driver-20200810233021-0000 的目录,这个就是 driver 运行时的日志文件,进入 该目录,会发现:
- jar 文件,这就是移动的计算
- stderr 运行日志
- stdout 输出结果
-
History Server
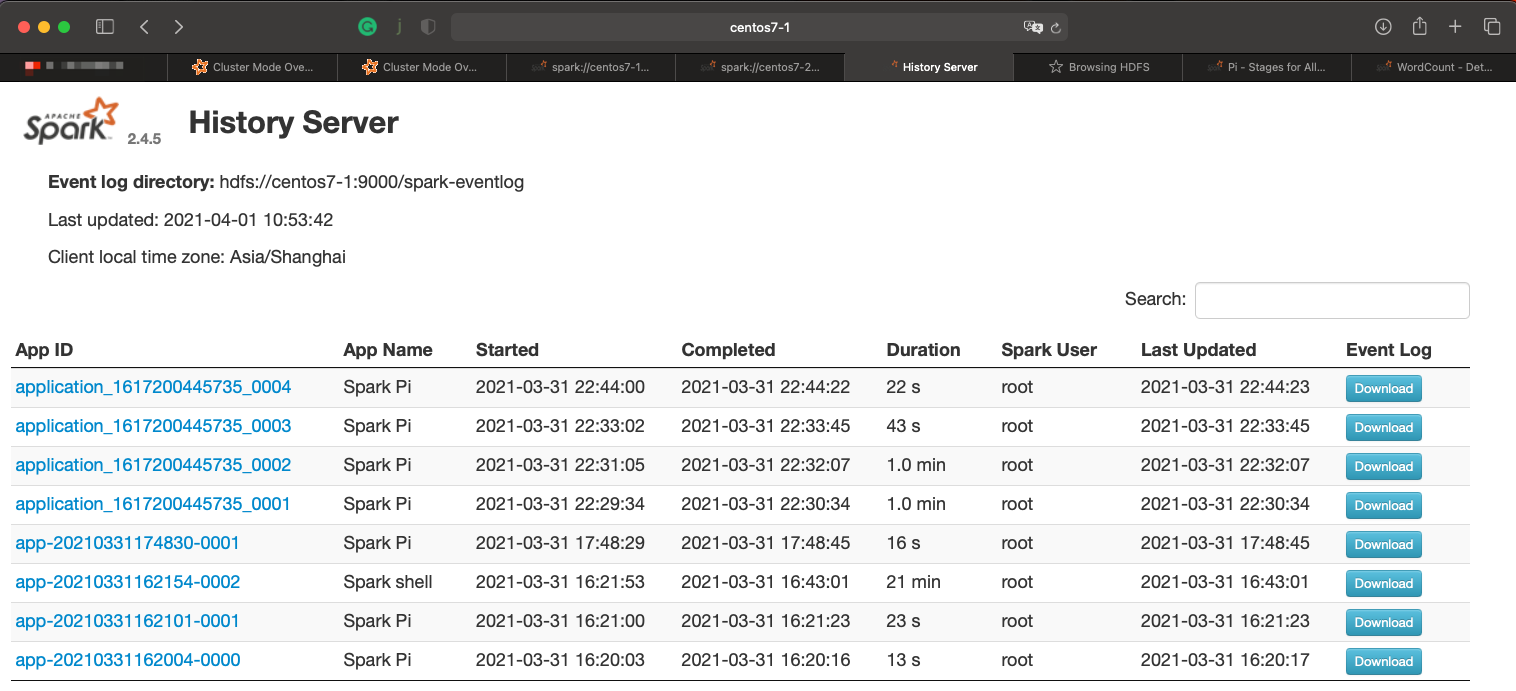 添加如下配置
添加如下配置# spark-defaults.conf # history server spark.eventLog.enabled true spark.eventLog.dir hdfs://centos7-1:9000/spark-eventlog spark.eventLog.compress true # spark-env.sh export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://centos7-1:9000/spark-eventlog"spark.history.retainedApplications。设置缓存Cache中保存的应用程序历史记录的 个数(默认50),如果超过这个值,旧的将被删除;
缓存文件数不表示实际显示的文件总数。只是表示不在缓存中的文件可能需要从硬盘读取,速度稍有差别前提条件:启动hdfs服务(日志写到HDFS)
启动historyserver,使用 jps 检查,可以看见 HistoryServer 进程。如果看见该进程,请检查对应的日志。$SPARK_HOME/sbin/start-history-server.shweb端地址: http://centos7-1:18080/
-
高可用配置 Spark Standalone集群是 Master-Slaves架构的集群模式,和大部分的Master- Slaves结构集群一样,存着Master单点故障的问题。如何解决这个问题,Spark提供了两种方案:
-
基于zookeeper的Standby Master
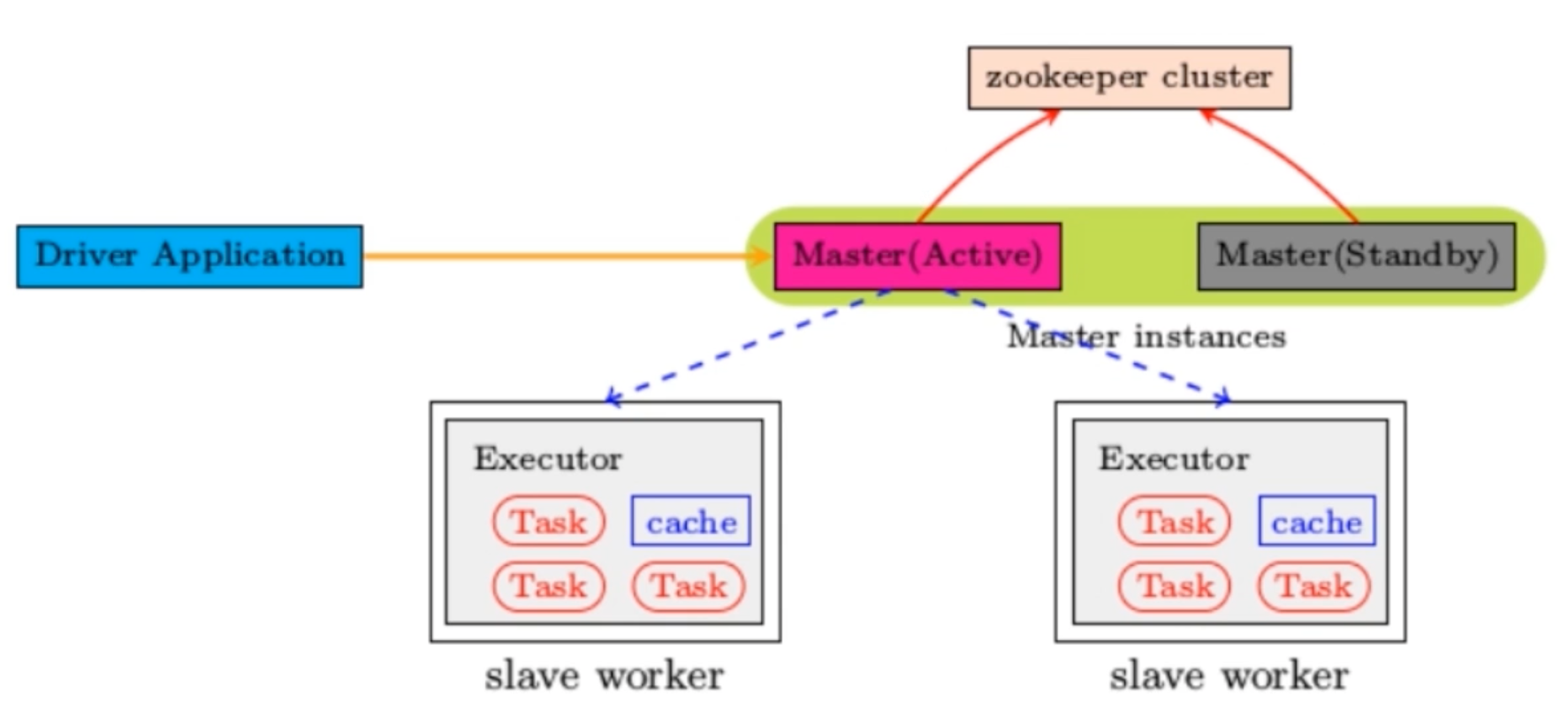 适用于生产模式。将 Spark 集群连接到 Zookeeper,利用 Zookeeper 提供的选举和状态保存的功能,一个 Master 处于 Active 状态,其他 Master 处于Standby状态;
适用于生产模式。将 Spark 集群连接到 Zookeeper,利用 Zookeeper 提供的选举和状态保存的功能,一个 Master 处于 Active 状态,其他 Master 处于Standby状态;
保证在ZK中的元数据主要是集群的信息,包括:Worker,Driver和Application以及 Executors的信息;
如果Active的Master挂掉了,通过选举产生新的 Active 的 Master,然后执行状态恢 复,整个恢复过程可能需要1~2分钟;-
配置步骤 1、安装ZooKeeper,并启动
2、修改 spark-env.sh 文件,并分发到集群中# 注释以下两行!!! # export SPARK_MASTER_HOST=linux121 # export SPARK_MASTER_PORT=7077 # 添加以下内容 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=centos7-1,centos7-2,centos7-3 -Dspark.deploy.zookeeper.dir=/spark"备注:
- spark.deploy.recoveryMode:可选值 Zookeeper、FileSystem、None
- deploy.zookeeper.url:Zookeeper的URL,主机名:端口号(缺省2181)
- deploy.zookeeper.dir:保存集群元数据信息的地址,在ZooKeeper中保存该信息
3、启动 Spark 集群
$SPARK_HOME/sbin/start-all.sh浏览器输入:http://centos7-1:8080/,刚开始 Master 的状态是STANDBY,稍等一会 变为:RECOVERING,最终是:ALIVE
4、在 centos7-2 上启动master
$SPARK_HOME/sbin/start-master.sh进入浏览器输入:http://centos7-2:8080/,此时 Master 的状态为:STANDBY
5、杀到centos7-1上 Master 进程,再观察 centos7-2 上 Master 状态,由 STANDBY => RECOVERING => ALIVE, 这个过程需要1~2分钟
-
-
基于文件系统的单点恢复 (Single-Node Rcovery with Local File System), 主要用于开发或者测试环境。将 Spark Application 和 Worker 的注册信息保存在文 件中,一旦Master发生故障,就可以重新启动Master进程,将系统恢复到之前的状 态
-
- Client 模式
-
Yarn模式 参考:http://spark.apache.org/docs/latest/running-on-yarn.html
需要启动的服务:hdfs服务、yarn服务
需要关闭 Standalone 对应的服务(即集群中的Master、Worker进程),一山不容二 虎!在Yarn模式中,Spark应用程序有两种运行模式:
- yarn-client。Driver程序运行在客户端,适用于交互、调试,希望立即看到app 的输出
- yarn-cluster。Driver程序运行在由RM启动的 AppMaster中,适用于生产环境
-
二者的主要区别:Driver在哪里
- 相关配置
1、关闭 Standalone 模式下对应的服务;开启 hdfs、yarn、historyserver 服务
2、修改 yarn-site.xml 配置
在 $HADOOP_HOME/etc/hadoop/yarn-site.xml 中增加,分发到集群,重启 yarn 服务<property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>备注:
- yarn.nodemanager.pmem-check-enabled。是否启动一个线程检查每个任务 正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true
- yarn.nodemanager.vmem-check-enabled。是否启动一个线程检查每个任务正 使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true
3、修改配置,分发到集群
# spark-env.sh 中这一项必须要有 export HADOOP_CONF_DIR=/opt/lagou/servers/hadoop-2.9.2/etc/hadoop # spark-default.conf(以下是优化) # 与 hadoop historyserver集成 spark.yarn.historyServer.address centos7-1:18080 # 添加(以下是优化) spark.yarn.jars hdfs:///spark-yarn/jars/*.jar # 将 $SPARK_HOME/jars 下的jar包上传到hdfs hdfs dfs -mkdir -p /spark-yarn/jars/ cd $SPARK_HOME/jars hdfs dfs -put * /spark-yarn/jars/ hdfs dfs -ls /spark-yarn/jars/ - 测试
# client spark-submit --master yarn \ --deploy-mode client \ --class org.apache.spark.examples.SparkPi \ $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 2000在提取App节点上可以看见:SparkSubmit、CoarseGrainedExecutorBackend
在集群的其他节点上可以看见:CoarseGrainedExecutorBackend
在提取App节点上可以看见:程序计算的结果(即可以看见计算返回的结果)# cluster spark-submit --master yarn \ --deploy-mode cluster \ --class org.apache.spark.examples.SparkPi \ $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 2000在提取App节点上可以看见:SparkSubmit
在集群的其他节点上可以看见:CoarseGrainedExecutorBackend、
ApplicationMaster(Driver运行在此)
在提取App节点上看不见最终的结果 -
整合HistoryServer服务
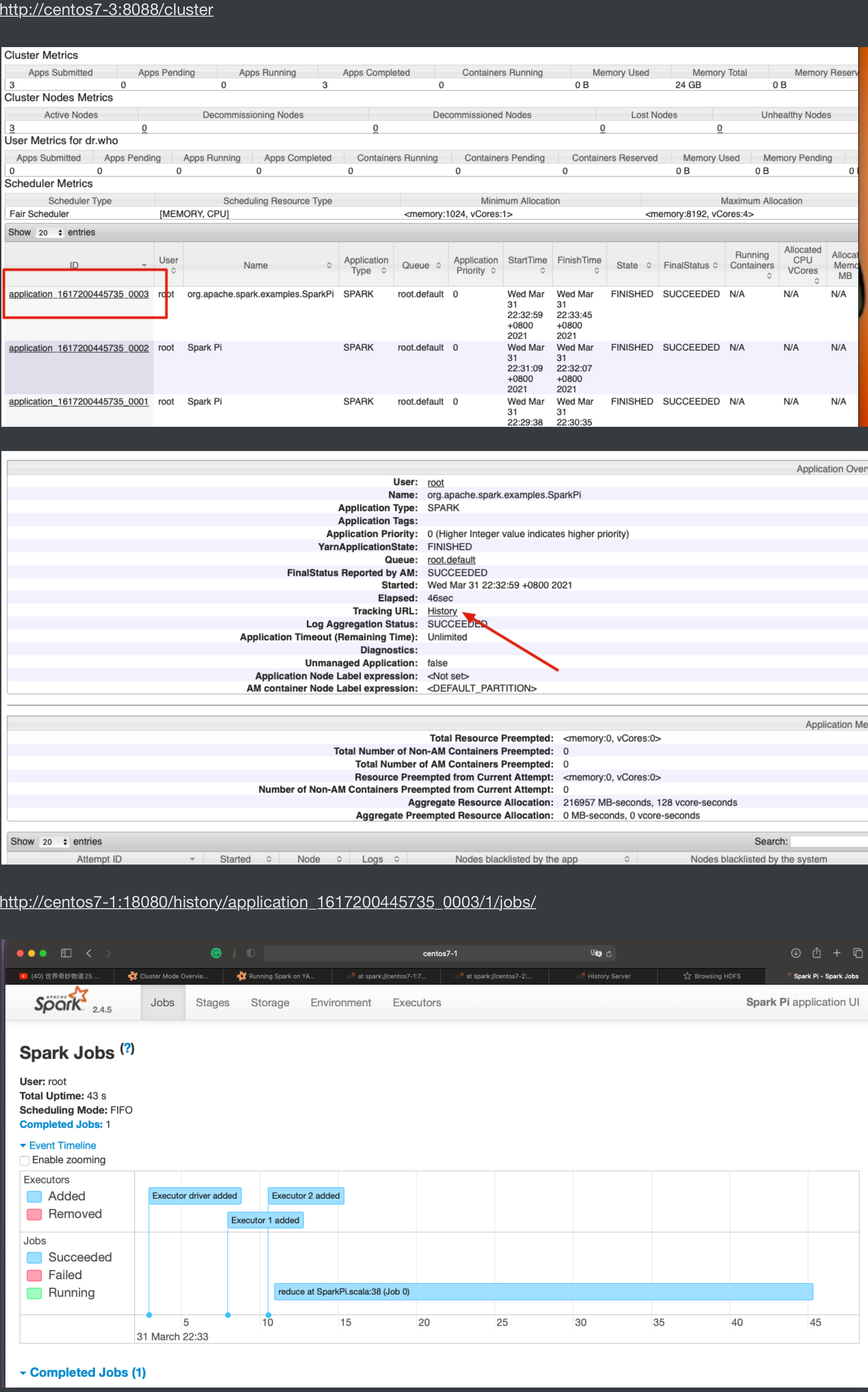 前提:Hadoop的 HDFS、Yarn、HistoryServer 正常;Spark historyserver服务正常;
前提:Hadoop的 HDFS、Yarn、HistoryServer 正常;Spark historyserver服务正常;Hadoop:JobHistoryServer Spark:HistoryServer
1、修改 spark-defaults.conf,并分发到集群
# 修改 spark-defaults.conf spark.master spark://centos7-1:7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://centos7-1:9000/spark-eventlog spark.eventlog.compress true spark.serializer org.apache.spark.serializer.KryoSerializer spark.driver.memory 512m # 与 hadoop historyserver集成 spark.yarn.historyServer.address centos7-1:18080 spark.history.ui.port 180802、重启/启动 spark 历史服务
stop-history-server.sh start-history-server.sh # 启动hadoop的历史服务 mr-jobhistory-daemon.sh start historyserver3、提交任务
spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar \ 1004、Web页面查看日志(图见上)
- 相关配置
-
-
开发环境搭建IDEA 前提:安装scala插件;能读写HDFS文件
- pom.xml
<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <scala.version>2.12.10</scala.version> <spark.version>2.4.5</spark.version> <hadoop.version>2.9.2</hadoop.version> <encoding>UTF-8</encoding> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>${spark.version}</version> </dependency> </dependencies> <build> <pluginManagement> <plugins> <!-- 编译scala的插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> </plugin> <!-- 编译java的插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin </artifactId> <version>3.5.1</version> </plugin> </plugins> </pluginManagement> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <executions> <execution> <phase>compile</phase> <goals> <goal>compile</goal> </goals> </execution> </executions> </plugin> <!-- 打jar插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> </configuration> </execution> </executions> </plugin> </plugins> </build> - 测试代码
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local").setAppName("WordCount") val sc = new SparkContext(conf) // 本地文件 // val lines: RDD[String] = sc.textFile("data/wc.txt") // dfs 全地址 // val lines: RDD[String] = sc.textFile("hdfs://centos7-1:9000/wcinput/wc.txt") // 使用缺省模式的dfs地址,需要在resource中添加core-site.xml val lines: RDD[String] = sc.textFile("/wcinput/wc.txt") lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect().foreach(println) // 留出时间看web界面,因为web界面在执行结束后会自动关闭 // Thread.sleep(1000000) sc.stop() } }备注:core-site.xml;
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://centos7-1:9000</value> </property> </configuration>
- pom.xml
RDD编程
RDD是 Spark 的基石,是实现 Spark 数据处理的核心抽象。
RDD 是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
RDD(Resilient Distributed Dataset)是 Spark 中的核心概念,它是一个容错、 可以并行执行的分布式数据集。
- RDD包含5个特征
- 一个分区的列表
- 一个计算函数compute,对每个分区进行计算
- 对其他RDDs的依赖(宽依赖、窄依赖)列表
- 对key-value RDDs来说,存在一个分区器(Partitioner)【可选的】
- 对每个分区有一个优先位置的列表【可选的】对于一 个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照 “移 动计算不移动数据” 的理念,Spark在任务调度的时候,会尽可能地将计算任务 分配到其所要处理数据块的存储位置。
-
RDD的特点
-
分区
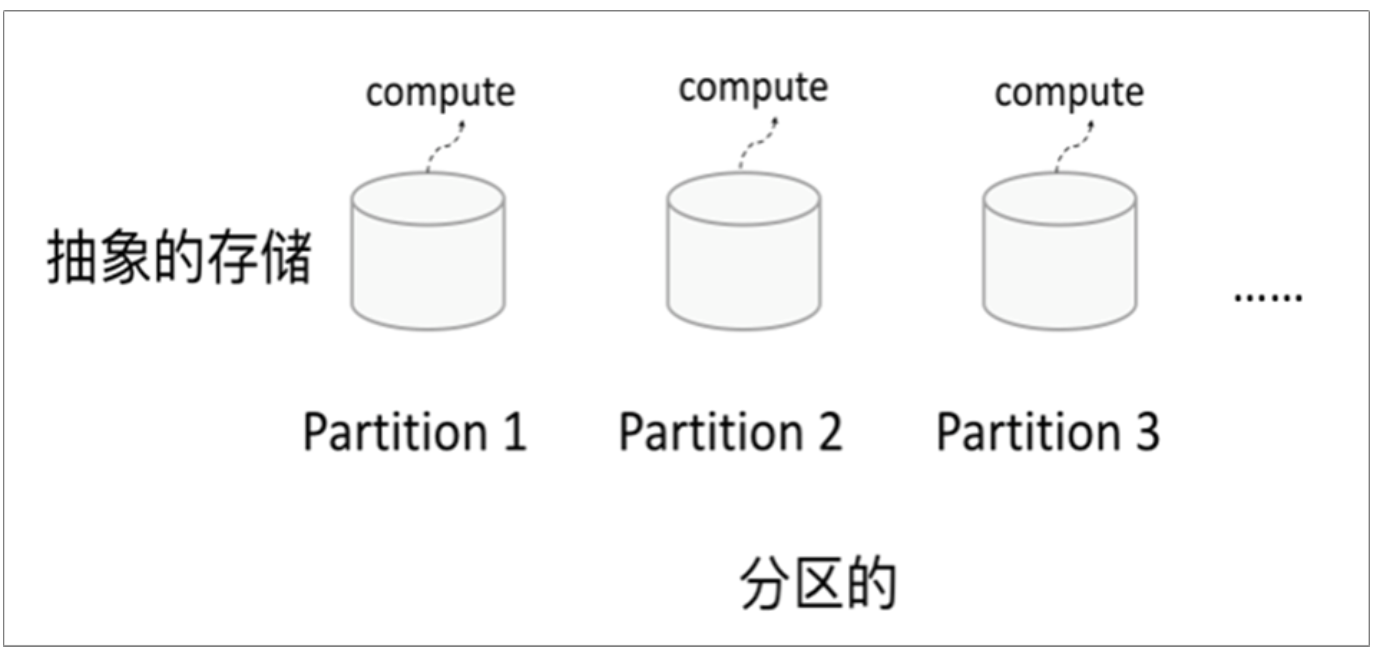 RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个 compute 函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则 compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来, 则compute函数是执行转换逻辑将其他RDD的数据进行转换。
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个 compute 函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则 compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来, 则compute函数是执行转换逻辑将其他RDD的数据进行转换。 -
只读
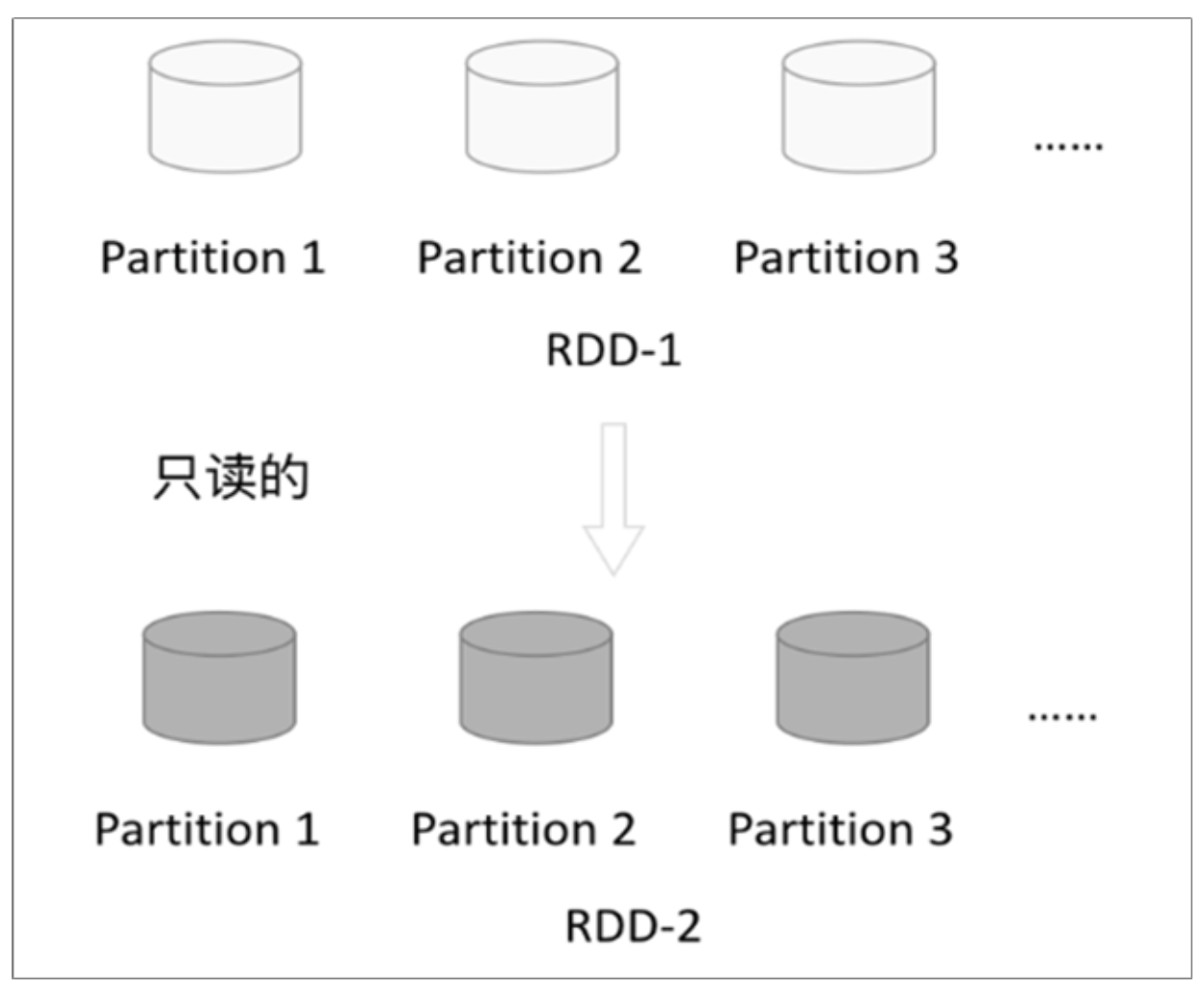 RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD;
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD;
一个RDD转换为另一个RDD,通过丰富的操作算子(map、filter、union、join、 reduceByKey……)实现,不再像MR那样只能写map和reduce了。RDD的操作算子包括两类:
- transformation。用来对RDD进行转化,延迟执行(Lazy);
- action。用来触发RDD的计算;得到相关计算结果或者将RDD保存的文件系统中;
- 依赖
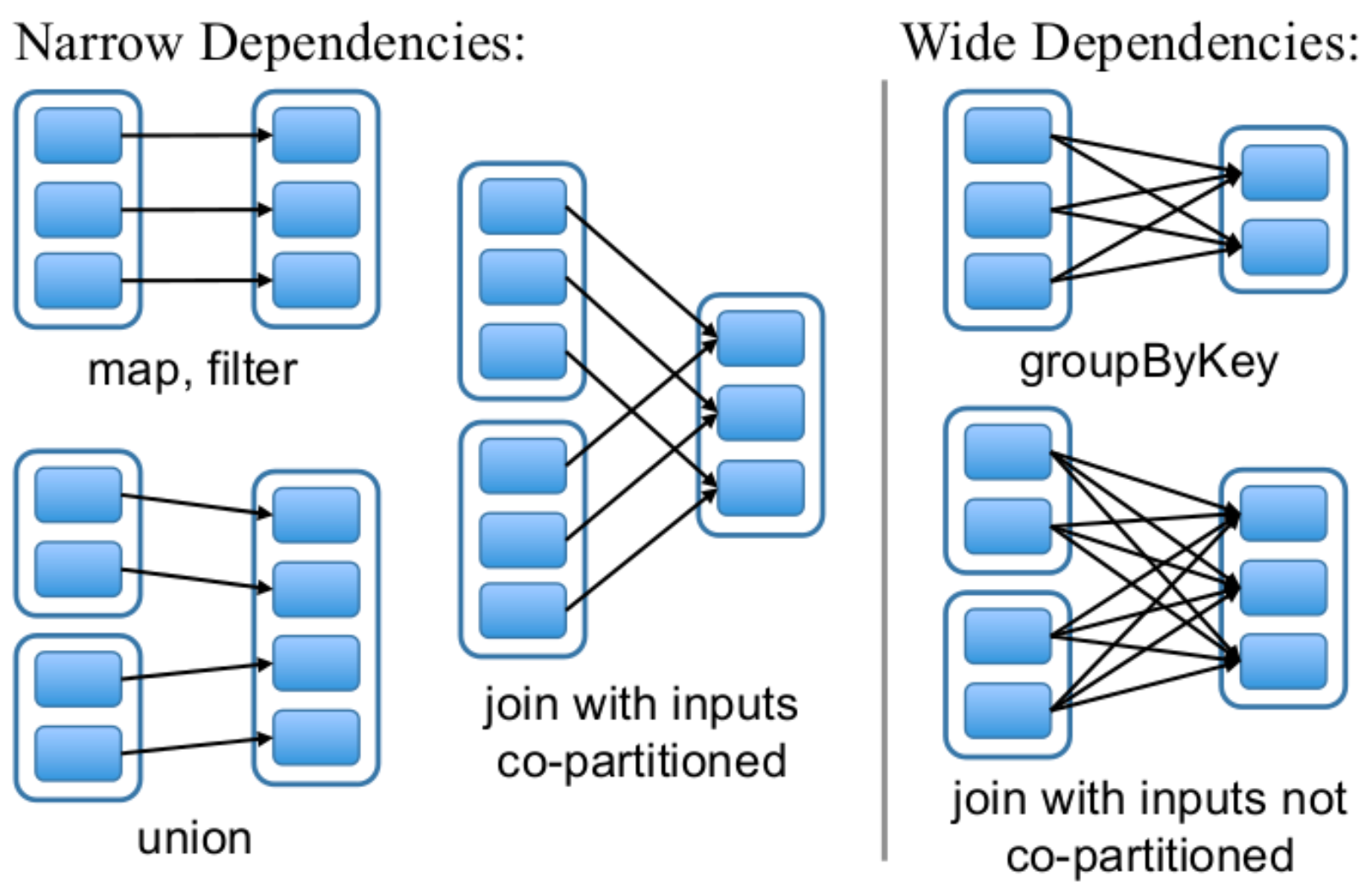 RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系(lineage),也称之为依赖。依赖包括两种:
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系(lineage),也称之为依赖。依赖包括两种:
- 窄依赖。RDDs之间分区是一一对应的(1:1 或 n:1)
- 宽依赖。子RDD每个分区与父RDD的每个分区都有关,是多对多的关系(即 n:m)。有shuffle发生
-
checkpoint 虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。
但是于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。
RDD支持 checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从 checkpoint 处拿到数据。 - 缓存
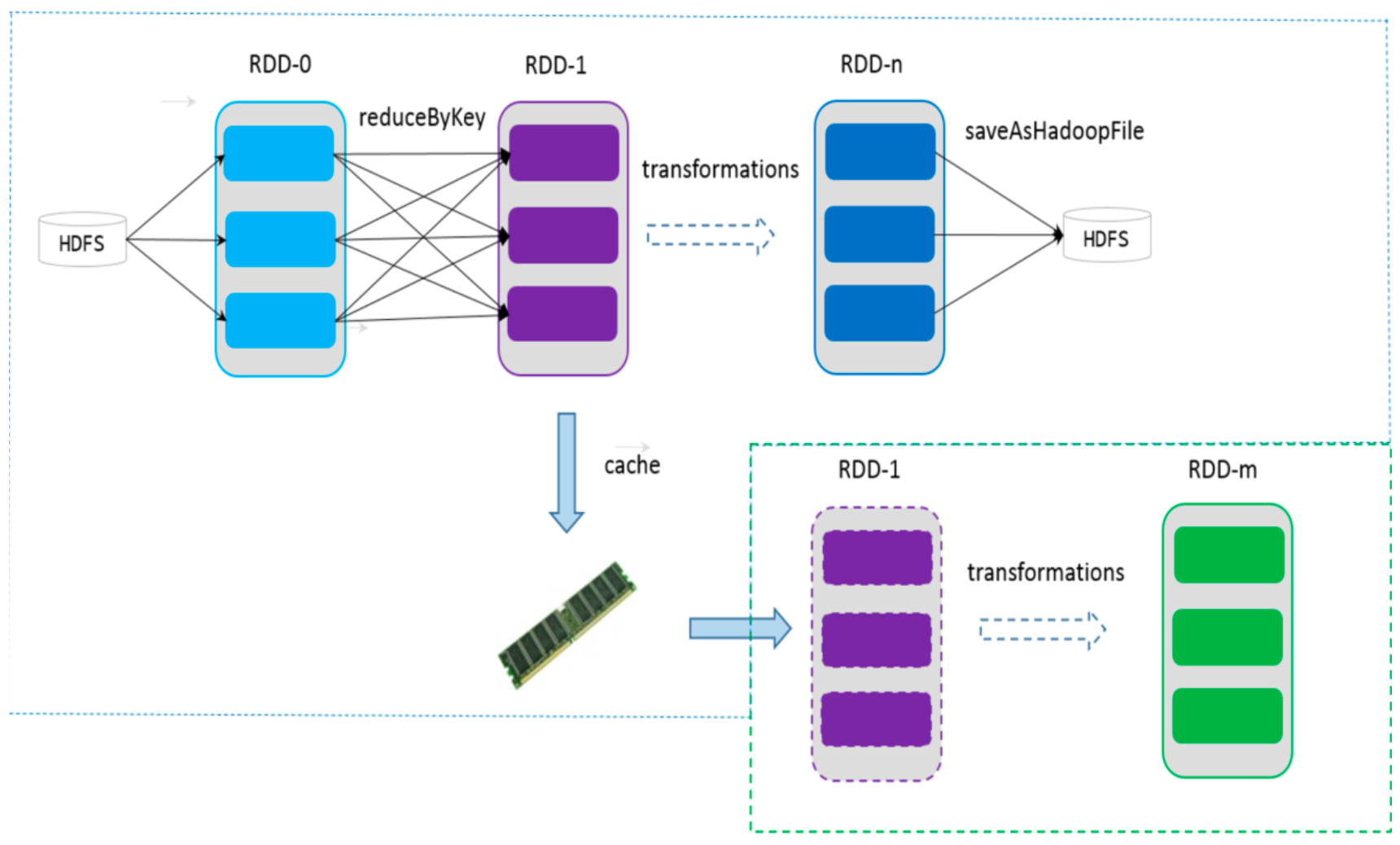 可以控制存储级别(内存、磁盘等)来进行缓存。
可以控制存储级别(内存、磁盘等)来进行缓存。
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。
-
- Spark编程模型
- RDD表示数据对象
- 通过对象上的方法调用来对RDD进行转换
- 最终显示结果 或 将结果输出到外部数据源
- RDD转换算子称为Transformation是Lazy的(延迟执行)
-
只有遇到Action算子,才会执行RDD的转换操作
- Driver & Worker
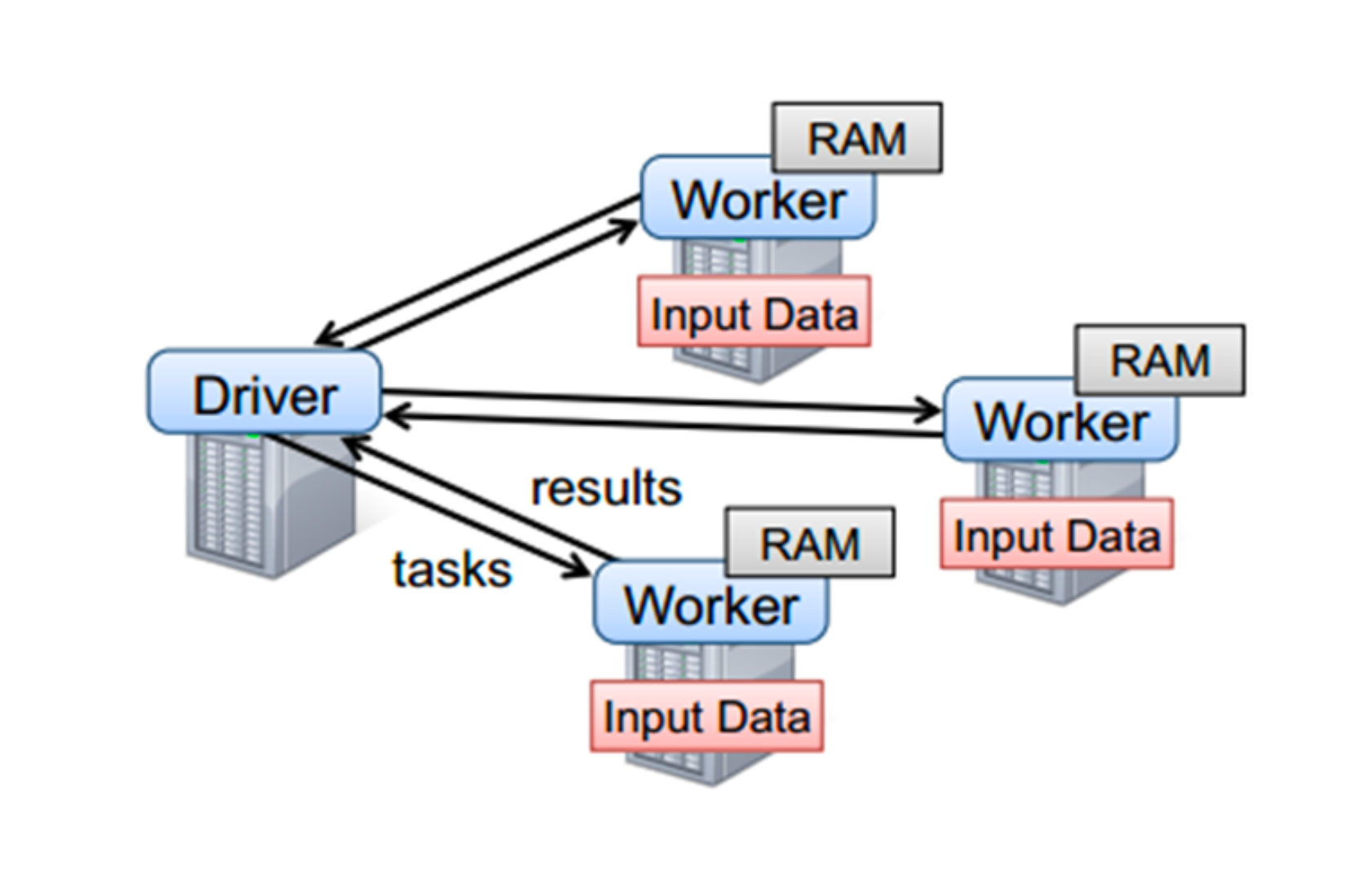 要使用Spark,需要编写 Driver 程序,它被提交到集群运行
要使用Spark,需要编写 Driver 程序,它被提交到集群运行
- Driver中定义了一个或多个 RDD ,并调用 RDD 上的各种算子
- Worker则执行RDD分区计算任务
- Driver & Worker
-
RDD的创建
-
SparkContext SparkContext是编写Spark程序用到的第一个类,是Spark的主要入口点,它负责和 整个集群的交互;
如把Spark集群当作服务端,那么Driver就是客户端,SparkContext 是客户端的核心;
SparkContext是Spark的对外接口,负责向调用者提供 Spark 的各种功能; SparkContext用于连接Spark集群、创建RDD、累加器、广播变量;在 spark-shell 中 SparkContext 已经创建好了,可直接使用;
编写Spark Driver程序第一件事就是:创建SparkContext; -
从集合创建RDD 从集合中创建RDD,主要用于测试。Spark 提供了以下函数:parallelize、 makeRDD、range; 和 makeRDD相比 parallelize 是懒加载,数据会随着源头变
- 从文件系统创建RDD-textFile
用 textFile() 方法来从文件系统中加载数据创建RDD。方法将文件的 URI 作为参数, 这个URI可以是:
- 本地文件系统
- 使用本地文件系统要注意:该文件是不是在所有的节点存在(在Standalone
模式下)
- 使用本地文件系统要注意:该文件是不是在所有的节点存在(在Standalone
- 分布式文件系统HDFS的地址
- Amazon S3的地址
// 从本地文件系统加载数据 val lines = sc.textFile("file:///root/data/wc.txt") // 从分布式文件系统加载数据 val lines = sc.textFile("hdfs://linux121:9000/user/root/data/uaction.dat") val lines = sc.textFile("/user/root/data/uaction.dat") val lines = sc.textFile("data/uaction.dat") - 本地文件系统
- 从RDD创建RDD 本质是将一个RDD转换为另一个RDD, 各种transformation的算子
-
- Transformation
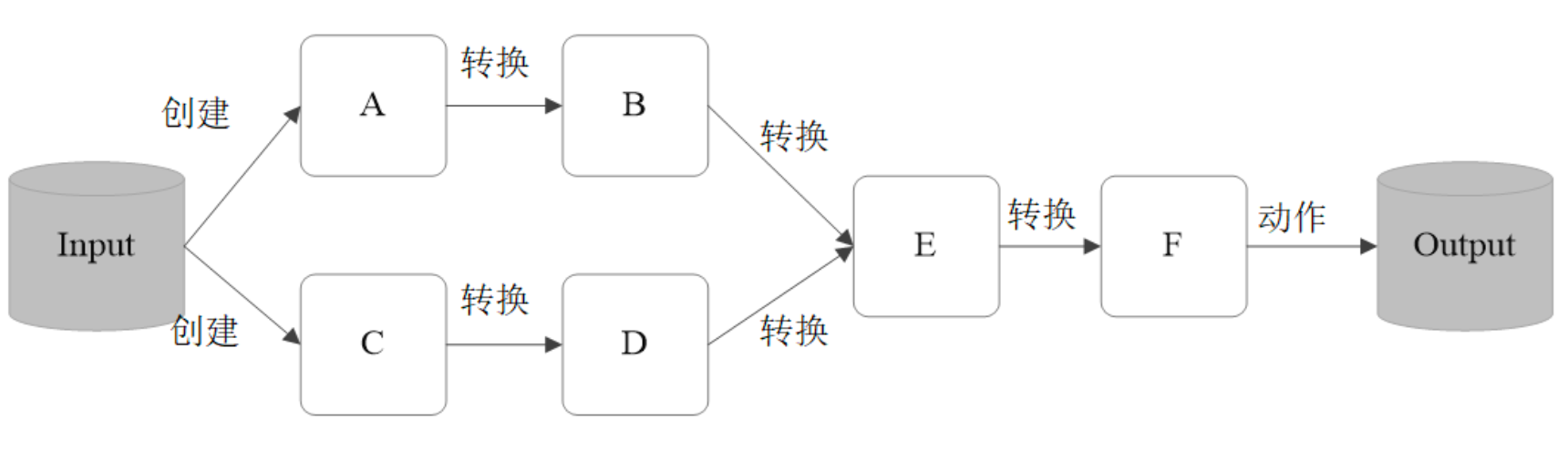 RDD的操作算子分为两类:
RDD的操作算子分为两类:
- Transformation。用来对RDD进行转化,这个操作时延迟执行的(或者说是 Lazy 的);
- Action。用来触发RDD的计算;得到相关计算结果 或者 将结果保存的外部系统 中;
- Transformation:返回一个新的RDD
- Action:返回结果int、double、集合(不会返回新的RDD)
每一次 Transformation 操作都会产生新的RDD,供给下一个“转换”使用;
转换得到的RDD是惰性求值的。也就是说,整个转换过程只是记录了转换的轨迹, 并不会发生真正的计算,只有遇到 Action 操作时,才会发生真正的计算,开始从血 缘关系(lineage)源头开始,进行物理的转换操作;常见的 Transformation 算子: 官方文档:http://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations
-
窄依赖
-
filter(func) 对数据集中的每个元素都使用func,然后返回一个包含使func为true 的元素构成的RDD
-
flatMap(func) 与 map 类似,每个输入元素被映射为0或多个输出元素
-
mapPartitions(func) 和map很像,但是map是将func作用在每个元素上,而 mapPartitions是func作用在整个分区上。假设一个RDD有N个元素,M个分区(N » M),那么map的函数将被调用N次,而mapPartitions中的函数仅被调用M次, 一次处理一个分区中的所有元素
map 与 mapPartitions 的区别
- map:每次处理一条数据
- mapPartitions:每次处理一个分区的数据,分区的数据处理完成后,数据才能 释放,资源不足时容易导致OOM * 最佳实践:当内存资源充足时,建议使用mapPartitions,以提高处理效率
-
mapPartitionsWithIndex(func) 与 mapPartitions 类似,多了分区的索引值的 信息
-
map(func) 对数据集中的每个元素都使用func,然后返回一个新的RDD
-
glom() 将每一个分区形成一个数组,形成新的RDD类型 RDD[Array[T]]
-
sample(withReplacement, fraction, seed) 采样算子。以指定的随机种子 (seed)随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否 放回,true为有放回的抽样,false为无放回的抽样
-
coalesce(numPartitions) 缩减分区数,无shuffle
coalesce 与 repartition 的区别:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { coalesce(numPartitions, shuffle = true) } def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty) (implicit ord: Ordering[T] = null) : RDD[T] = withScope { … }- repartition:增大或减少分区数;有shuffle
- coalesce:一般用于减少分区数(此时无shuffle)
-
union(otherRDD) 求并集,不去重,直接合并数据;得到的RDD分区数为两个RDD分区数之和
- cartesian(otherRDD)
笛卡尔积
- 得到RDD的元素个数为两个RDD元素个数的乘积
- 得到RDD的分区数为:两个RDD分区数的乘积
- 使用该操作会导致数据膨胀,慎用
- zip(otherRDD)
将两个RDD组合成 key-value 形式的RDD,默认两个RDD的
partition数量以及元素数量都相同,否则会抛出异常。
-
-
宽依赖(shuffle) 需要取出数据集中元素和另外一个数集进行比较的是宽依赖,
不需要比较,或直接线性变化的是窄依赖-
groupBy(func) 按照传入函数的返回值进行分组。将key相同的值放入一个迭代器
-
distinct([numTasks])) 对RDD元素去重后,返回一个新的RDD。可传入 numTasks参数改变RDD分区数
-
sortBy(func, [ascending], [numTasks]) 使用 func 对数据进行处理,对处理后 的结果进行排序
-
intersection(otherRDD) 求交集
-
subtract (otherRDD) 求差集,this 的元素减去that中出现的元素
-
repartition(numPartitions) 增加或减少分区数,有shuffle
-
- Action
Action 用来触发RDD的计算,得到相关计算结果;
- Action触发Job。一个Spark程序(Driver程序)包含了多少 Action 算子,那么就 有多少Job;
- 典型的Action算子: collect, count
-
collect() => sc.runJob() => … => dagScheduler.runJob() => 触
发了Job-
collect() / collectAsMap() this method should only be used if the resulting data is expected to be small, as all the data is loaded into the driver’s memory.
数据集小的时候才能调用,不然容易OOM -
stats / count / mean / stdev / max / min 打印所有统计维度数据/计数/平均数/标准差/最大值/最小值
-
foreach(func) / foreachPartition(func) foreach(func) / foreachPartition(func):与map、mapPartitions类似,区别是 foreach 是 Action
-
saveAsTextFile(path) / saveAsSequenceFile(path) / saveAsObjectFile(path) 以文本文件保存/保存成hadoop的SequenceFile/保存成带数据类型的文件
-
reduce(func) / fold(func) / aggregate(func)
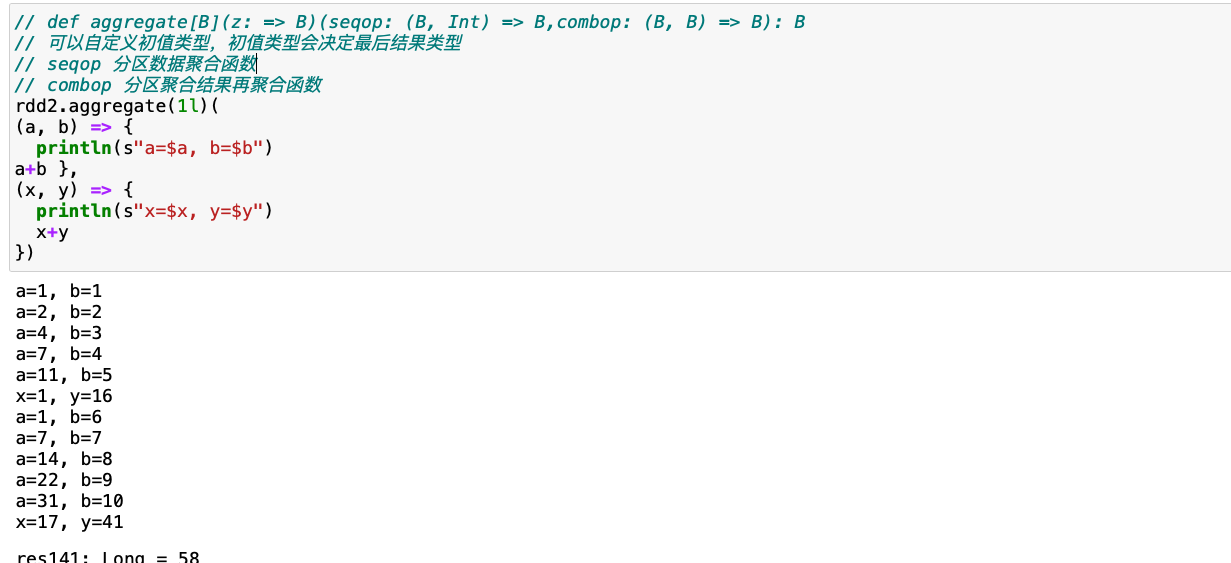 聚合/带初始值的聚合/可以控制聚合阶段的聚合
聚合/带初始值的聚合/可以控制聚合阶段的聚合val rdd2 = sc.range(1, 11) // 求累加和的三种方式 rdd2.reduce(_+_) rdd2.fold(0)(_+_) rdd2.aggregate(0l)(_+_, _+_)- fold的原理
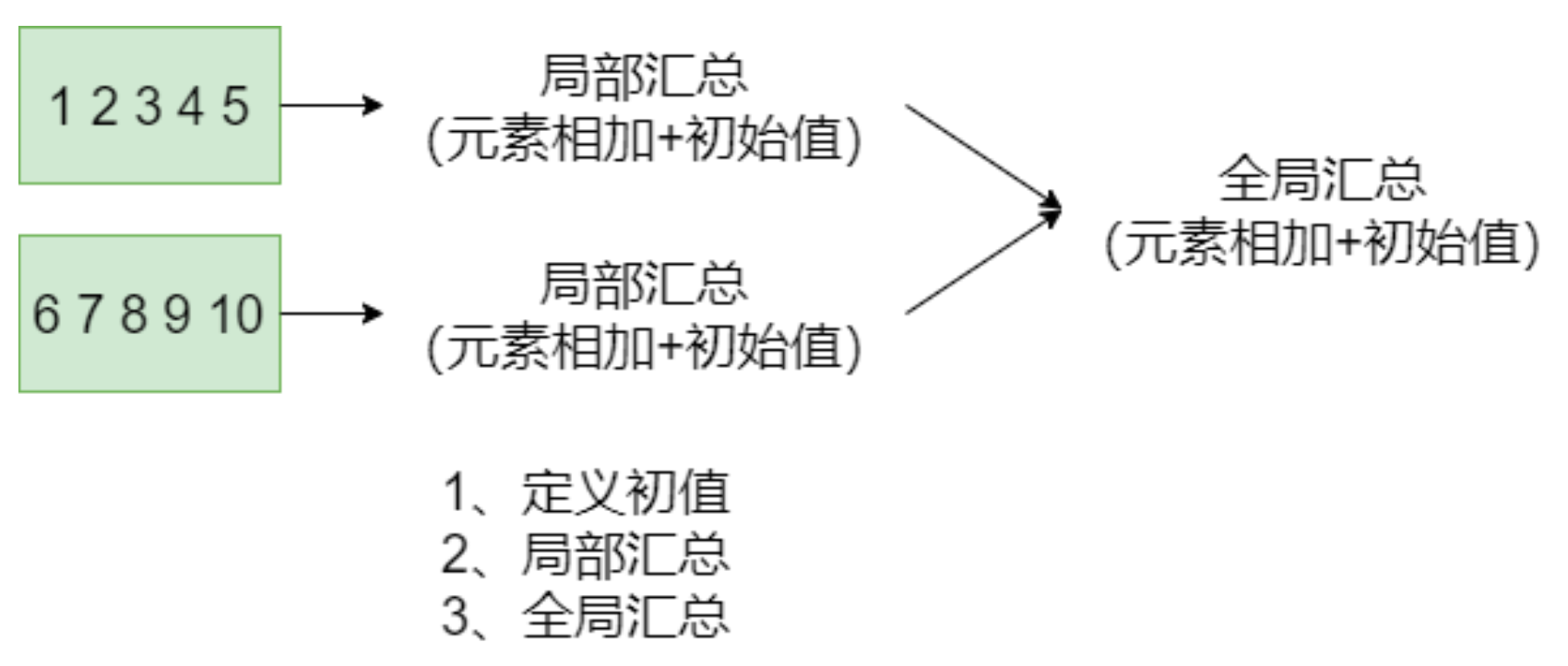
- fold的原理
-
first() / take(n) / top(n) 取第一个元素/取前N个元素/取N极值
-
takeSample(withReplacement, num, [seed]) 返回采样的数据
-
-
Key-Value RDD操作 RDD整体上分为 Value 类型和 Key-Value 类型。
前面介绍的是 Value 类型的RDD的操作,实际使用更多的是 key-value 类型的 RDD,也称为 PairRDD。
Value 类型RDD的操作基本集中在 RDD.scala 中;
key-value 类型的RDD操作集中在 PairRDDFunctions.scala 中;普通RDD大多数算子对 Pair RDD 都是有效的。Pair RDD还有属于自己的 Transformation、Action 算子;
-
创建Pair RDD 数组中的每个单元必须只有两个元素, 如Array[(String, Int)]
val arr = (1 to 10).toArray val arr1 = arr.map(x => (x, x*10, x*100)) // rdd1 不是 Pair RDD val rdd1 = sc.makeRDD(arr1) // rdd2 是 Pair RDD val arr2 = arr.map(x => (x, (x*10, x*100))) val rdd2 = sc.makeRDD(arr2) -
Transformation操作
-
mapValues / flatMapValues / keys / values 这些操作都可以使用 map 操作实 现,是简化操作。
val a = sc.parallelize(List((1,2),(3,4),(5,6))) // 使用 mapValues 更简洁 val b = a.mapValues(x=>1 to x) b.collect // 可使用map实现同样的操作 val b = a.map(x => (x._1, 1 to x._2)) b.collect val b=a.map{case(k,v)=>(k,1tov)} b.collect // flatMapValues 将 value 的值压平 val c = a.flatMapValues(x=>1 to x) c.collect val c = a.mapValues(x=>1 to x).flatMap{case (k, v) => v.map(x=> (k, x))} c.collect c.keys c.values c.map{case (k, v) => k}.collect c.map{case (k, _) => k}.collect c.map{case (_, v) => v}.collect -
subtractByKey 类似于subtract,删掉 RDD 中键与 other RDD 中的键相同的元素
val rdd = sc.makeRDD(Array(("a",1), ("b",2), ("c",3), ("a",5),("d",5))) val other = sc.makeRDD(Array(("a",10), ("b",20), ("c",30))) rdd.subtractByKey(other).collect() // 结果 Array((d,5) -
sortByKey / sortBy sortByKey函数作用于PairRDD,对Key进行排序。在org.apache.spark.rdd.OrderedRDDFunctions 中实现:
sortBy 是通过 sortByKey实现的:
sortBy = keyBy + sortByKeydef sortBy[K]( f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length) (implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope { this.keyBy[K](f) .sortByKey(ascending, numPartitions) .values }val a = sc.parallelize(List("wyp", "iteblog", "com", "397090770", "test")) val b = sc.parallelize (1 to a.count.toInt) val c = a.zip(b) c.sortByKey().collect // Array[(String, Int)] = Array((wyp,1), (test,5), (iteblog,2), (com,3), (397090770,4))备注:sortBy后面需要调用collect才能看到效果,不过直接使用foreach就不排序
-
groupByKey / reduceByKey / foldByKey / aggregateByKey
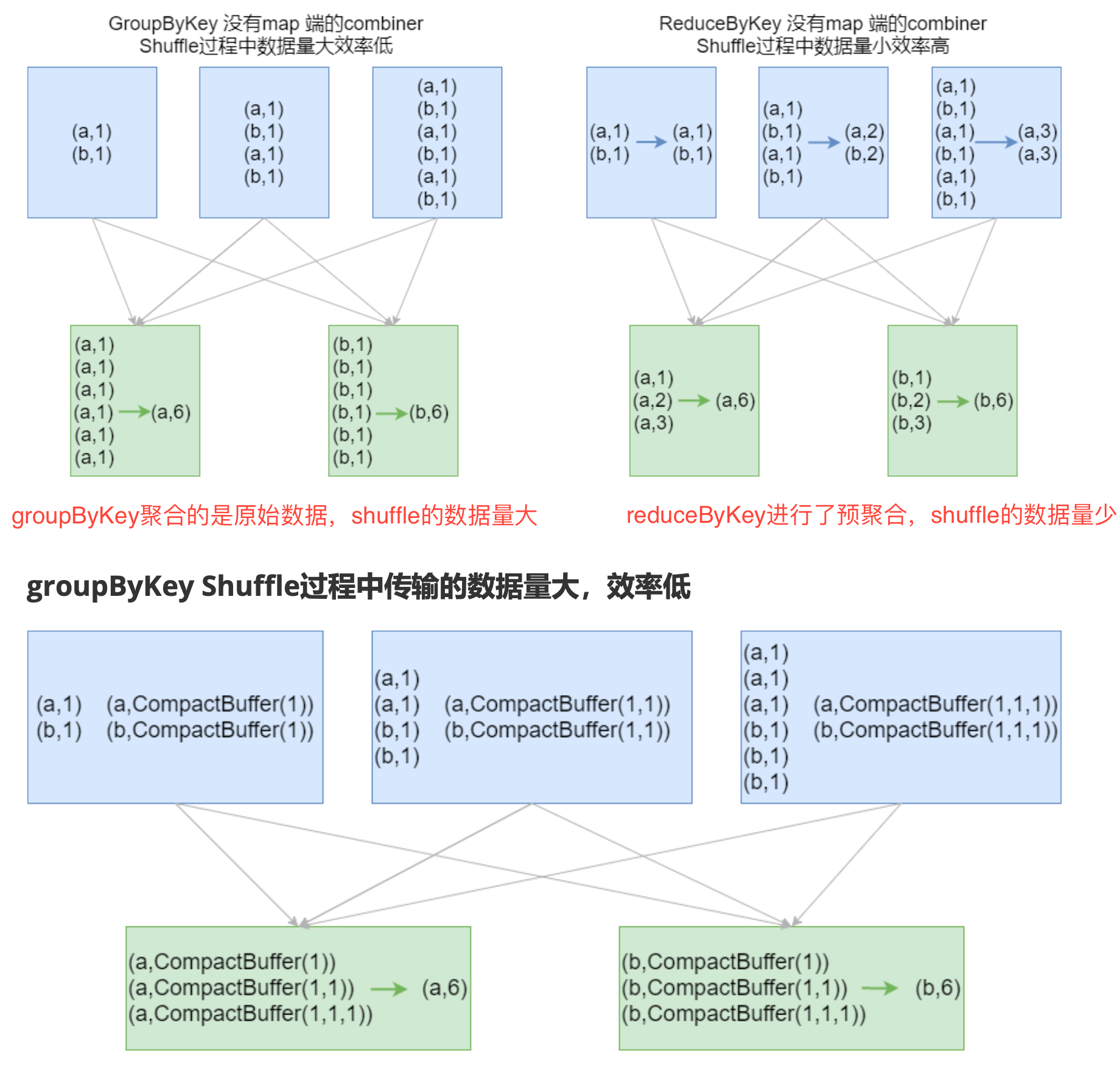 combineByKey(OLD) / combineByKeyWithClassTag (NEW) => 底层实现
combineByKey(OLD) / combineByKeyWithClassTag (NEW) => 底层实现小案例:给定一组数据:(“spark”, 12), (“hadoop”, 26), (“hadoop”, 23), (“spark”, 15), (“scala”, 26), (“spark”, 25), (“spark”, 23), (“hadoop”, 16), (“scala”, 24), (“spark”, 16), 键值对的key表示图书名称,value表示某天图书销量。计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
// groupByKey rdd.groupByKey.mapValues(v=>v.sum.toDouble/v.size).collect rdd.groupByKey.map{case (k, v)=>(k, v.sum.toDouble/v.size)}.collect rdd.groupByKey.map(x =>(x._1, x._2.sum.toDouble/x._2.size)).collect // reduceByKey rdd.mapValues((_, 1)).reduceByKey(((x, y)=>(x._1+y._1, x._2+y._2))).mapValues(x => x._1.toDouble/x._2).collect // foldByKey rdd.mapValues((_, 1)) .foldByKey((0, 0))( (x, y)=>(x._1+y._1, x._2+y._2)) .mapValues(x => x._1.toDouble/x._2).collect // aggregateByKey rdd.mapValues((_, 1)) .aggregateByKey((0, 0))( (x, y)=>(x._1+y._1, x._2+y._2), (a, b)=>(a._1+b._1, a._2+b._2)) .mapValues(x => x._1.toDouble/x._2).collect // 初值(元祖)与RDD元素类型(Int)可以不一致 // (zeroValue: U) 相当于一个缓冲区,._1 用来累计值,._2用来计算 rdd.aggregateByKey((0, 0))( (x, y)=>{println(s"x=$x, y=$y");(x._1+y, x._2+1)}, (a, b)=>{println(s"a=$a, b=$b");(a._1+b._1, a._2+b._2)}) .mapValues(x => x._1.toDouble/x._2).collect // 分区内的合并与分区间的合并,可以采用不同的方式;这种方式是低效的! rdd.aggregateByKey(scala.collection.mutable.ArrayBuffer[Int]())( ((x, y)=> x+=y), ((a, b)=> a++=b)) .mapValues(v => v.sum.toDouble/v.size) .collect // combineByKey(理解就行) rdd.combineByKey( (x: Int) => {println(s"x=$x"); (x,1)}, (x: (Int, Int), y: Int) => {println(s"x=$x, y=$y");(x._1+y,x._2+1)}, (a: (Int, Int), b: (Int, Int)) => {println(s"a=$a, b=$b");(a._1+b._1, a._2+b._2)} ).mapValues(x=>x._1.toDouble/x._2).collect //思路同 mapValues.reduceByKey.mapValues结论:效率相等用最熟悉的方法;groupByKey在一般情况下效率低,尽量少用
-
cogroup / join / leftOuterJoin / rightOuterJoin / fullOuterJoin cogroup:key,value用两个数组聚合
val rdd1 = sc.makeRDD(Array((1,"Spark"), (2,"Hadoop"), (2,"hive"), (3,"Kylin"), (4,"Flink"))) val rdd2 = sc.makeRDD(Array((2,"李四"), (4,"王五"), (5,"赵六"), (6,"冯七"))) val rdd3 = rdd1.cogroup(rdd2) rdd3.foreach(println) /** (4,(CompactBuffer(Flink),CompactBuffer(王五))) (1,(CompactBuffer(Spark),CompactBuffer())) (6,(CompactBuffer(),CompactBuffer(冯七))) (3,(CompactBuffer(Kylin),CompactBuffer())) (5,(CompactBuffer(),CompactBuffer(赵六))) (2,(CompactBuffer(Hadoop, hive),CompactBuffer(李四))) */ rdd1.join(rdd2).foreach(println) /** (4,(Flink,王五)) (2,(Hadoop,李四)) (2,(hive,李四)) */ rdd1.leftOuterJoin(rdd2).foreach(println) /** (4,(Flink,Some(王五))) (1,(Spark,None)) (3,(Kylin,None)) (2,(Hadoop,Some(李四))) (2,(hive,Some(李四))) */ rdd1.rightOuterJoin(rdd2).foreach(println) /** (4,(Some(Flink),王五)) (6,(None,冯七)) (5,(None,赵六)) (2,(Some(Hadoop),李四)) (2,(Some(hive),李四)) */ rdd1.fullOuterJoin(rdd2).foreach(println) /** (4,(Some(Flink),Some(王五))) (1,(Some(Spark),None)) (6,(None,Some(冯七))) (3,(Some(Kylin),None)) (5,(None,Some(赵六))) (2,(Some(Hadoop),Some(李四))) (2,(Some(hive),Some(李四))) */
-
-
Action操作
- collectAsMap / countByKey / lookup(key)
collectAsMap: 结果以key->value形式输出,会去重,key相同取最后出现的值
countByKey:计算不同key下面元素的个数
lookup(key): 高效的查找方法,只查找对应分区的数据(如果RDD有分区器的话)
- collectAsMap / countByKey / lookup(key)
collectAsMap: 结果以key->value形式输出,会去重,key相同取最后出现的值
-
-
输入与输出
- 文本文件 textFile(path)/wholeTextFiles(path)/saveAsTextFile(path)
数据读取:textFile(String)。可指定单个文件,支持通配符。
这样对于大量的小文件读取效率并不高,应该使用 wholeTextFilesdef wholeTextFiles(path: String, minPartitions: Int = defaultMinPartitions): RDD[(String, String)])返回值RDD[(String, String)],其中Key是文件的名称,Value是文件的内容 数据保存:saveAsTextFile(String)。指定的输出目录。
-
csv文件 读取 CSV(Comma-Separated Values)/TSV(Tab-Separated Values) 数据和读 取 JSON 数据相似,都需要先把文件当作普通文本文件来读取数据,然后通过将每一 行进行解析实现对CSV的读取。
CSV/TSV 数据的输出也是需要将结构化RDD通过相关的库转换成字符串RDD,然后 使用 Spark 的文本文件 API 写出去。 -
SequenceFile/saveAsSequenceFile SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面 文件(Flat File)。 Spark 有专门用来读取 SequenceFile 的接口。在 SparkContext 中,可以调用:sequenceFile[keyClass, valueClass];
调用 saveAsSequenceFile(path) 保存PairRDD,系统将键和值能够自动转为 Writable类型。
-
json文件 如果 JSON 文件中每一行就是一个JSON记录,那么可以通过将JSON文件当做文本文
件来读取,然后利用相关的JSON库对每一条数据进行JSON解析。 JSON数据的输出主要是通过在输出之前将由结构化数据组成的 RDD 转为字符串
RDD,然后使用 Spark 的文本文件 API 写出去。 json文件的处理使用SparkSQL最为简洁。 -
对象文件 objectFilek,v/saveAsObjectFile 对象文件是将对象序列化后保存的文件,采用Java的序列化机制。
通过 objectFilek,v 接收一个路径,读取对象文件,返回对应的 RDD, 也可以通过调用saveAsObjectFile() 实现对对象文件的输出。因为是序列化所以要指 定类型。 - JDBC
- 文本文件 textFile(path)/wholeTextFiles(path)/saveAsTextFile(path)
数据读取:textFile(String)。可指定单个文件,支持通配符。
-
编程案例
- WordCount - java
- Spark入口点:JavaSparkContext
- Value-RDD:JavaRDD;key-value RDD:JavaPairRDD
- JavaRDD 和 JavaPairRDD转换
- JavaRDD => JavaPairRDD:通过mapToPair函数
- JavaPairRDD => JavaRDD:通过map函数转换
- lambda表达式使用 ->
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import scala.Tuple2; import java.util.Arrays; public class JavaWordCount { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setAppName("javaWordCount").setMaster("local[*]"); JavaSparkContext sc = new JavaSparkContext(conf); sc.setLogLevel("WARN"); JavaRDD<String> lines = sc.textFile("data/wc.txt"); JavaRDD<String> words = lines.flatMap(line -> Arrays.stream(line.split("\\s+")).iterator()); JavaPairRDD<String, Integer> wordMap = words.mapToPair(word -> new Tuple2<>(word, 1)); JavaPairRDD<String, Integer> result = wordMap.reduceByKey((x, y) -> x + y); result.foreach(x -> System.out.println(x)); sc.stop(); } } - WordCount - scala
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { // 1. Create context val conf = new SparkConf() conf.setAppName("wordCount") val sc = new SparkContext(conf) // 设置日志级别 sc.setLogLevel("WARN") // 2. read file val lines: RDD[String] = sc.textFile(args(0)) // 3. RDD transformation val words: RDD[String] = lines.flatMap(line => line.split("\\s+")) val result = words.map(x => (x, 1)).reduceByKey(_ + _) // 4. output result.foreach(println) // 5. stop context sc.stop() // 6. get jar, spark submit // spark-submit --master local[*] --class com.lagou.sparkcore.WordCount original-SparkDemo-1.0-SNAPSHOT.jar /wcinput/* // spark-submit --master yarn --class com.lagou.sparkcore.WordCount original-SparkDemo-1.0-SNAPSHOT.jar /wcinput/* // spark-submit --master spark://centos7-1:7077 --class com.lagou.sparkcore.WordCount original-SparkDemo-1.0-SNAPSHOT.jar /wcinput/* } } -
计算圆周率
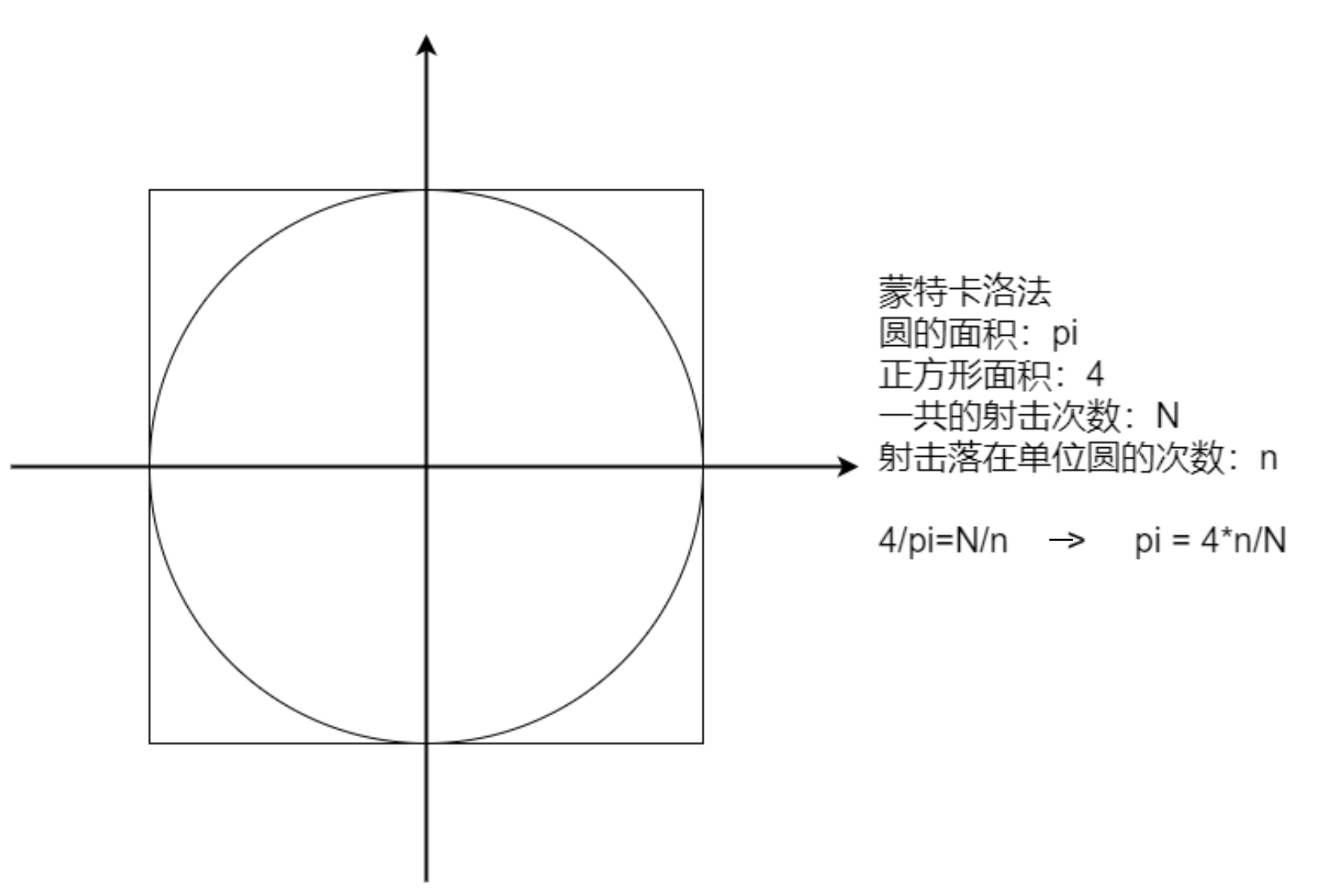
import org.apache.spark.{SparkConf, SparkContext} import scala.math.random object SparkPi { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]") val sc = new SparkContext(conf) // sc.setLogLevel("WARN") // 随机数落在圆内的概率约等于圆的面积 val N = 10000000 val slices = if (args.length > 0) args(0).toInt else 10 val count = sc.makeRDD(1 to N, slices) .map(_ => { val (x, y) = (random, random) if (x * x + y * y <= 1.0) 1 else 0 }).reduce(_ + _) println(s"Pi is roughly ${4.0 * count / N}") sc.stop() } } -
广告数据统计
数据格式:timestamp province city userid adid 时间点 省份 城市 用户 广告
需求:
1、统计每一个省份点击TOP3的广告ID
2、统计每一个省份每一个小时的 TOP3广告IDimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object AdStat { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val lines: RDD[String] = sc.textFile("data/advert.log") // timestamp province adid val rawData = lines.map{line => val words = line.split("\\s+") (words(0), words(1), words(4)) } // 1、统计每一个省份点击TOP3的广告ID val N = 3 rawData.map{case (timeStamp, province, adid) => ((province, adid), 1)} .reduceByKey(_ + _) .map{case ((province, adid), count) => (province, (adid, count))} .groupByKey() .mapValues(v => v.toList.sortWith(_._2>_._2).take(N) // .map(_._1).mkString(",") ) .foreach(println) println("-------------------------") // 2、统计每一个省份每一个小时的 TOP3广告ID rawData.map{case (timeStamp, province, adid) => ((province, getHour(timeStamp), adid), 1)} .reduceByKey(_ + _) .map{case ((province, hour, adid), count) => ((province, hour), (adid, count))} .groupByKey(1) .mapValues(v => v.toList.sortWith(_._2>_._2).take(N) // .map(_._1).mkString(",") ) .foreach(println) sc.stop() } def getHour(timeStamp: String): Int = { import org.joda.time.DateTime val dt = new DateTime(timeStamp.toLong) dt.getHourOfDay } }需要导入解析时间戳的依赖
<dependency> <groupId>joda-time</groupId> <artifactId>joda-time</artifactId> <version>2.9.7</version> </dependency>Joda 类具有不可变性,它们的实例无法被修改。(不可变类的一个优点就是它们是 线程安全的)
在 Spark Core 程序中使用时间日期类型时,不要使用 Java 8 以前的时间日期类型, 线程不安全。 -
找共同好友 原始数据:
100, 200 300 400 500 600
200, 100 300 400
300, 100 200 400 500
400, 100 200 300
500, 100 300
600, 100第一列表示用户,后面的表示该用户的好友
要求:
1、查找两两用户的共同好友
2、最后的结果按前两个id号有序排序import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object FindFriends { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val lines: RDD[String] = sc.textFile("data/fields.dat") val rawData: RDD[(String, List[String])] = lines.map { line => val foo = line.split(",") val bar = foo(1).trim.split("\\s+") (foo(0), bar.toList) } // 1、查找两两用户的共同好友 // 2、最后的结果按前两个id号有序排序 // 方法一 : 笛卡尔积 // “id1 < id2” 去重, 这样才有 a, b -> b, a 的组合 rawData.cartesian(rawData) .filter{ case ((id1, _), (id2, _)) => id1 < id2 } .map { case ((user1, friends1), (user2, friends2)) => ((user1, user2), friends1.intersect(friends2)) } .sortByKey() .collect() .foreach(println) //WARN: 使用sortByKey, sortBy 需要调用collect才能看到排序的效果, println("*" * 30) // 方法二:将数据变形,找到俩俩的好友,再做数据的合并 /** * 100, 200 300 400 500 600 * 200, 100 300 400 * 300, 100 200 400 500 * 400, 100 200 300 * 500, 100 300 * 600, 100 * * 以100为例 * (200 300)有100这个共同好友 * (300 400)有100这个共同好友 * friends.combinations(2) 可以取出数组中所有可能的俩俩组合 * 把变化后的矩阵k,v置换后 合并k,就能获得需要的共同好友 */ rawData.flatMapValues(friends => friends.combinations(2)) .map{case (k, v) => (v.mkString("&"), Set(k))} .reduceByKey(_ | _) .sortByKey() .collect().foreach(println) sc.stop() } } -
Super WordCount 要求:将单词全部转换为小写,去除标点符号,去除停用词;最后按照 count 值降序保存到文件,同时将全部结果保存到MySQL;标点符号和停用词可 以自定义。
import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * 将单词全部转换为小写,去除标点符号,去除停用词;最后按照 count 值降序保存到文件,同时将全部结果保存到MySQL;标点符号和停用词可以自定义。 * 停用词:语言中包含很多功能词。与其他词相比,功能词没有什么实际含义。最普遍 的功能词是[限定词](the、a、an、that、those),介词(on、in、to、from、 over等)、代词、数量词等。 */ object SuperWordCount2 { def main(args: Array[String]): Unit = { val stopWords = "or so this for one be and if or at in on to from by a an the is are were was i we you your he his some any of as can it each".split("\\s+") val punctuation = "[\\(\\)\\.,:;'\\“’”!\\?]" val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val lines = sc.textFile("data/swc.dat").filter(!_.trim.isEmpty) val words: RDD[String] = lines.flatMap { line => line.replaceAll(punctuation, "") //去标点 .toLowerCase //转小写 .split("\\s+") //转单词字符串 .toList } val resultRDD = words.map((_, 1)) .reduceByKey(_ + _) .filter { case (k, _) => !stopWords.contains(k) } //过滤掉停用词 .sortBy(_._2, ascending = false) // 保存文件到本地 resultRDD.saveAsTextFile("data/superWordCount") // 按分区读取数据 resultRDD.foreachPartition(saveToSQL) sc.stop() } def saveToSQL(result: Iterator[(String, Int)]): Unit = { val username = "root" val password = "h@ckingwithjava11" val url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false" var connection: Connection = null var preparedStatement: PreparedStatement = null val sql = "insert into wordcount values (?, ?)" try { connection = DriverManager.getConnection(url, username, password) preparedStatement = connection.prepareStatement(sql) result.foreach { case (word, count) => preparedStatement.setString(1, word) preparedStatement.setInt(2, count) preparedStatement.addBatch() } // 批处理,所有数据用一个事务写入 println(preparedStatement.executeBatch().sum) } catch { case e: Exception => e.printStackTrace() } finally { if (preparedStatement != null) { preparedStatement.clearBatch() preparedStatement.close() } if (connection != null) connection.close() } } }需要导入JDBC的依赖
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency>
- WordCount - java
RDD编程进阶
- 序列化
在实际开发中会自定义一些对RDD的操作,此时需要注意的是:
- 初始化工作是在Driver端进行的
- 实际运行程序是在Executor端进行的
这就涉及到了进程通信,是需要序列化的。凡是在transformation中用到的变量都需要可序列化。
可以简单的认为SparkContext代表Driver。 -
RDD依赖关系
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列
Lineage(血统)记录下来,以便恢复丢失的分区。 RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失
时,可根据这些信息来重新运算和恢复丢失的数据分区。RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。 依赖有2个作用:其一用来解决数据容错;其二用来划分stage(宽依赖)。
窄依赖:1:1 或 n:1
宽依赖:n:m;意味着有 shuffle查看RDD依赖的方法
toDebugString,dependencies:rdd5.toDebugString /** res18: String = (2) ShuffledRDD[22] at sortByKey at <console>:34 [] +-(2) ShuffledRDD[19] at reduceByKey at <console>:33 [] +-(2) MapPartitionsRDD[18] at map at <console>:32 [] | MapPartitionsRDD[17] at flatMap at <console>:31 [] | /wcinput/wc.txt MapPartitionsRDD[16] at textFile at <console>:30 [] | /wcinput/wc.txt HadoopRDD[15] at textFile at <console>:30 [] */ rdd1.dependencies /** res19: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@a56bd02) */- DAG(Directed Acyclic Graph) 有向无环图
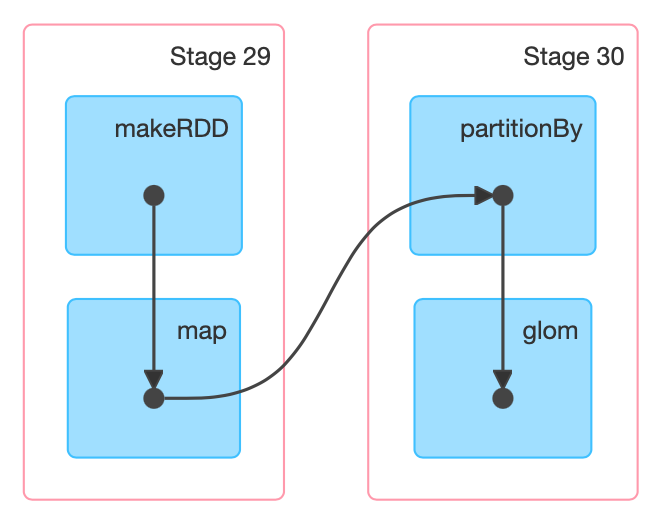
原始的RDD通过一系列的转换就就形成 了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage:- 对于窄依赖,分区的转换处理在Stage中完成计算
- 对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算
- 宽依赖是划分Stage的依据
-
RDD任务流程
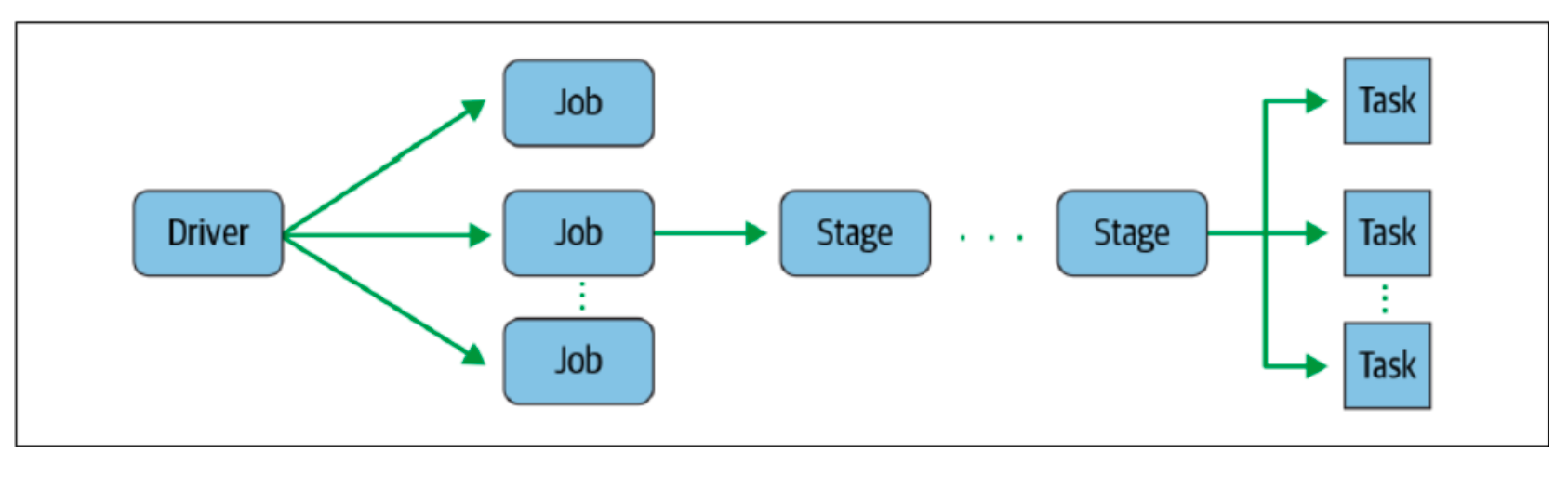 RDD任务切分中间分为:Driver programe、Job、Stage(TaskSet)和Task
RDD任务切分中间分为:Driver programe、Job、Stage(TaskSet)和Task-
Driver program 初始化一个SparkContext即生成一个Spark应用
-
Job 一个Action算子就会生成一个Job
-
Stage 根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽 依赖则划分一个Stage
-
Task Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即 为一个Task; Task是Spark中任务调度的最小单位;每个Stage包含许多Task,这些Task执行 的计算逻辑相同的,计算的数据是不同的
注意:Driver programe->Job->Stage-> Task每一层都是1对n的关系。
task 的数量 = stage * 数据分区数
-
- DAG(Directed Acyclic Graph) 有向无环图
-
RDD持久化/缓存cache
涉及到的算子:persist、cache、unpersist 都是 Transformation缓存是将计算结果写入不同的介质,用户定义可定义存储级别(存储级别定义了缓存存储的介质,目前支持内存、堆外内存、磁盘); 通过缓存,Spark避免了RDD上的重复计算,能够极大地提升计算速度;
-
持久化的好处 RDD持久化或缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键因素;
Spark速度非常快的原因之一,就是在内存中持久化(或缓存)一个数据集。当持久 化一个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此数据集 (或者衍生出的数据集)进行的其他动作(Action)中重用。这使得后续的动作变得 更加迅速;
-
标记为持久化 使用persist()方法对一个RDD标记为持久化。之所以说“标记为持久化”,是因为出现 persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一 个行动操作触发真正计算以后,才会把计算结果进行持久化;
-
什么时候缓存数据 需要对空间和速度进行权衡。一般情况下,如果多个动作需要用 到某个 RDD,而它的计算代价又很高,那么就应该把这个 RDD 缓存起来;
-
缓存可能丢失 缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除。RDD的缓存的容 错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列的转 换,丢失的数据会被重算。RDD的各个Partition是相对独立的,因此只需要计算丢 失的部分即可,并不需要重算全部Partition。
-
缓存的级别
 persist()的参数可以指定持久化级别参数; 使用cache()方法时,会调用persist(MEMORY_ONLY),即:
persist()的参数可以指定持久化级别参数; 使用cache()方法时,会调用persist(MEMORY_ONLY),即:cache() == persist(StorageLevel.Memeory_ONLY)使用unpersist()方法手动地把持久化的RDD从缓存中移除;
cache RDD 以分区为单位;程序执行完毕后,系统会清理cache数据;
-
示例代码
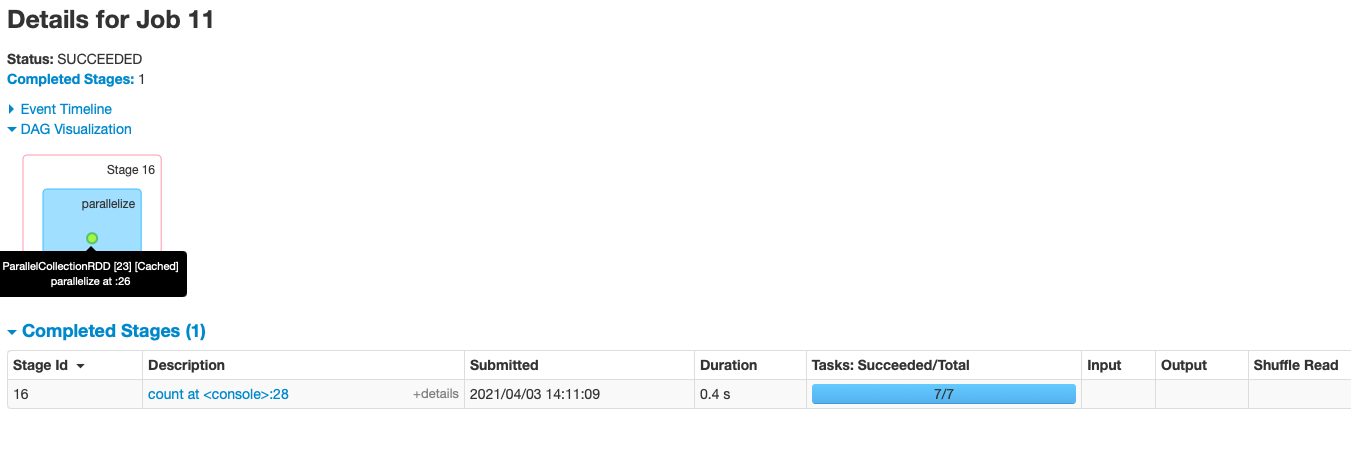 被缓存的RDD的DAG图会有一个绿点;Cache, 会生成多个task
被缓存的RDD的DAG图会有一个绿点;Cache, 会生成多个taskval list = List("Hadoop","Spark","Hive") val rdd = sc.parallelize(list) // 调用persist(MEMORY_ONLY) // 但语句执行到这里,并不会缓存rdd,因为这时rdd还没有被计算生成 rdd.cache() // 第一次Action操作,触发一次真正从头到尾的计算 // 这时才会执行上面的rdd.cache(),将rdd放到缓存中 rdd.count // 第二次Action操作,不需要触发从头到尾的计算 // 只需要重复使用上面缓存中的rdd rdd.collect.mkString(",")
-
-
RDD容错机制Checkpoint 涉及到的算子:checkpoint;也是 Transformation; 与cache类似 checkpoint 也是 lazy 的。
Spark中对于数据的保存除了持久化操作之外,还提供了检查点的机制检查点本质是通过将RDD写入高可靠的磁盘,主要目的是为了容错。检查点通过将 数据写入到HDFS文件系统实现了RDD的检查点功能。
Lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后 有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
-
和cache的比较 cache 和 checkpoint 是有显著区别的,缓存把 RDD 计算出来然后放在内存中,但 是 RDD 的依赖链不能丢掉, 当某个点某个 executor 宕了,上面 cache 的RDD就会 丢掉, 需要通过依赖链重放计算。不同的是,checkpoint 是把 RDD 保存在 HDFS 中,是多副本可靠存储,此时依赖链可以丢掉,所以斩断了依赖链。
-
什么时候用checkpoint 1) DAG中的Lineage过长,如果重算,则开销太大
2) 在宽依赖上做 Checkpoint 获得的收益更大 -
示例代码 备注:checkpoint的文件作业执行完毕后不会被删除
val rdd1 = sc.parallelize(1 to 100000) // 设置checkpoint的存储目录 sc.setCheckpointDir("/tmp/checkpoint") val rdd2 = rdd1.map(_*2) rdd2.cache rdd2.checkpoint // checkpoint是lazy操作 rdd2.isCheckpointed //false // checkpoint之前的rdd依赖关系 rdd2.dependencies(0).rdd // org.apache.spark.rdd.RDD[_] = ParallelCollectionRDD[24] at parallelize at <console>:2 rdd2.dependencies(0).rdd.collect // 执行一次action,触发checkpoint的执行 rdd2.count rdd2.isCheckpointed // true // checkpoint之后的rdd依赖关系 rdd2.dependencies(0).rdd // org.apache.spark.rdd.RDD[_] = ReliableCheckpointRDD[26] at count at <console>:27 //查看RDD所依赖的checkpoint文件 rdd2.getCheckpointFile // Option[String] = Some(hdfs://centos7-1:9000/tmp/checkpoint/badb8947-b8f6-4759-b9ee-981357e179e2/rdd-25)
-
-
RDD的分区 spark.default.parallelism:(默认的并发数)= 2
当配置文件spark-default.conf中没有显示的配置,则按照如下规则取值:本地模式
spark-shell --master local[N] spark.default.parallelism = N spark-shell --master local spark.default.parallelism = 1分布式模式(yarn & standalone)
spark.default.parallelism = max(应用程序持有executor的core总数, 2)经过上面的规则,就能确定了spark.default.parallelism的默认值。如果配置了,则spark.default.parallelism = 配置的值
SparkContext初始化时,同时会生成两个参数,由上面得到的 spark.default.parallelism推导出这两个参数的值
// 从集合中创建RDD的分区数 sc.defaultParallelism = spark.default.parallelism // 从文件中创建RDD的分区数 sc.defaultMinPartitions = min(spark.default.parallelism, 2)-
通过集合创建 简单的说RDD分区数等于cores总数
// 如果创建RDD时没有指定分区数,则rdd的分区数 = sc.defaultParallelism val rdd = sc.parallelize(1 to 100) rdd.getNumPartitions -
通过textFile创建 如果没有指定分区数:
- 本地文件。rdd的分区数 = max(本地文件分片数, sc.defaultMinPartitions)
- HDFS文件。 rdd的分区数 = max(hdfs文件 block 数, sc.defaultMinPartitions)
// 从本地文件系统读取 max(fileSize/32M, defaultMinPartitions) // 328M start0722.big.log val rdd = sc.textFile("file:///data/lagoudw/logs/big/start/start0722.big.log") rdd.getNumPartitions // 11 // hdfs 读取文件 max(block, defaultMinPartitions) // 328M start0722.big.log val rdd = sc.textFile("/test/start0722.big.log") rdd.getNumPartitions // 3备注:
- 本地文件分片数 = 本地文件大小 / 32M 如果读取的是HDFS文件,同时指定的分区数 < hdfs文件的block数,指定的数不生效。但是可以用coalesce改
-
-
RDD分区器 分区器的作用及分类:
在 PairRDD(key,value) 中,很多操作都是基于key的,系统会按照key对数据进行重 组,如groupbykey;
数据重组需要规则,最常见的就是基于 Hash 的分区,此外还有一种复杂的基于抽样 Range 分区方法;-
观察代码 只有Key-Value类型的RDD才可能有分区器,Value类型的RDD分区器的值是 None。
val rdd1 = sc.textFile("/wcinput/wc.txt") rdd1.partitioner // Option[org.apache.spark.Partitioner] = None val rdd2 = rdd1.flatMap(_.split("\\s+")) rdd2.partitioner // Option[org.apache.spark.Partitioner] = None val rdd3 = rdd2.map((_, 1)) rdd3.partitioner // Option[org.apache.spark.Partitioner] = None // pair RDD 没有触发计算的时候没有分区器 val rdd4 = rdd3.reduceByKey(_+_) rdd4.partitioner // Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@2) val rdd5 = rdd4.sortByKey() rdd5.partitioner // Option[org.apache.spark.Partitioner] = Some(org.apache.spark.RangePartitioner@33b81d) -
HashPartitioner
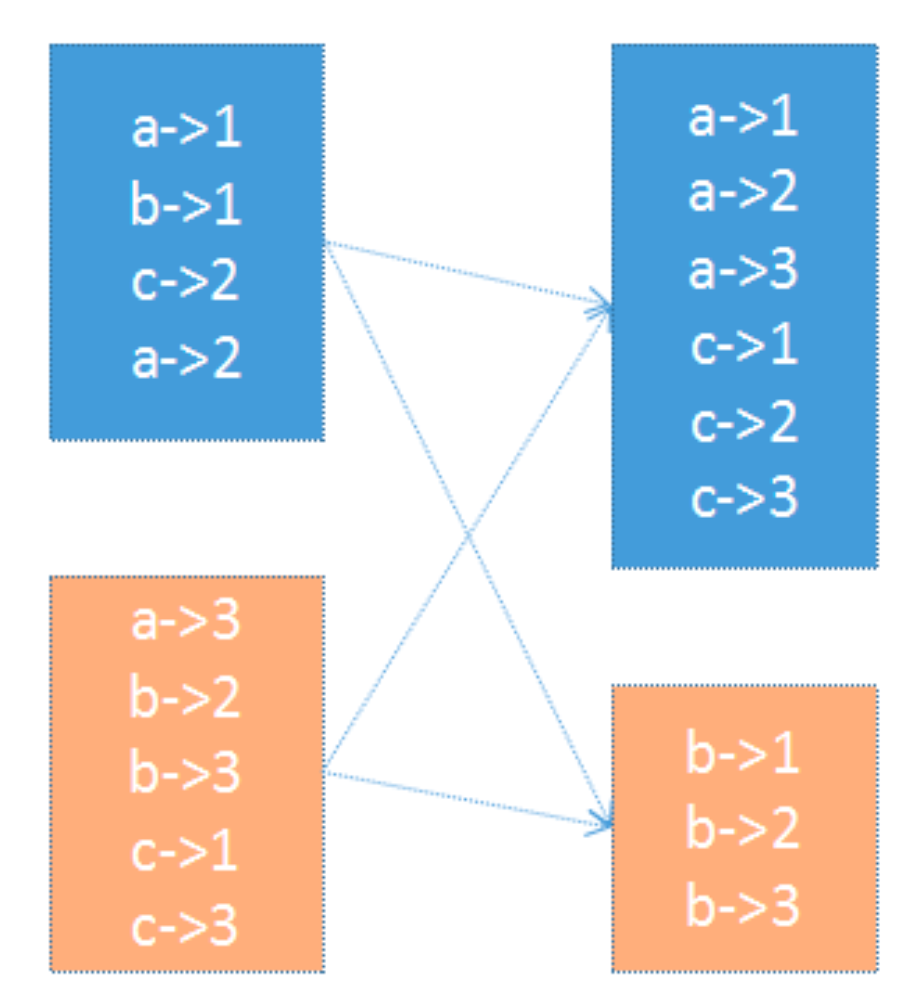 最简单、最常用,也是默认提供的分区器。对于给定的key,计 算其hashCode,并除以分区的个数取余,如果余数小于0,则用 余数+分区的个 数,最后返回的值就是这个key所属的分区ID。该分区方法可以保证key相同的数据 出现在同一个分区中。
最简单、最常用,也是默认提供的分区器。对于给定的key,计 算其hashCode,并除以分区的个数取余,如果余数小于0,则用 余数+分区的个 数,最后返回的值就是这个key所属的分区ID。该分区方法可以保证key相同的数据 出现在同一个分区中。
用户可通过partitionBy主动使用分区器,通过partitions参数指定想要分区的数量。val random = new scala.util.Random val arr = (1 to 100).map(_ => random.nextInt(100)) val rdd1 = sc.makeRDD(arr).map((_, 1)) rdd1.getNumPartitions // 7 // 只是按数组顺序,均匀的把数据分成若干份 rdd1.glom.collect.foreach(x => println(x.toList)) // 主动使用 HashPartitioner val rdd2 = rdd1.partitionBy(new org.apache.spark.HashPartitioner(5)) rdd2.glom.collect.foreach(x => println(x.toList)) // 主动使用 RangePartitioner val rdd3 = rdd1.partitionBy(new org.apache.spark.RangePartitioner(5, rdd1)) rdd3.glom.collect.foreach(x => println(x.toList)) // 每个分区的数据都在不同的区间,只要组内有序,整体就有序 -
RangePartitioner
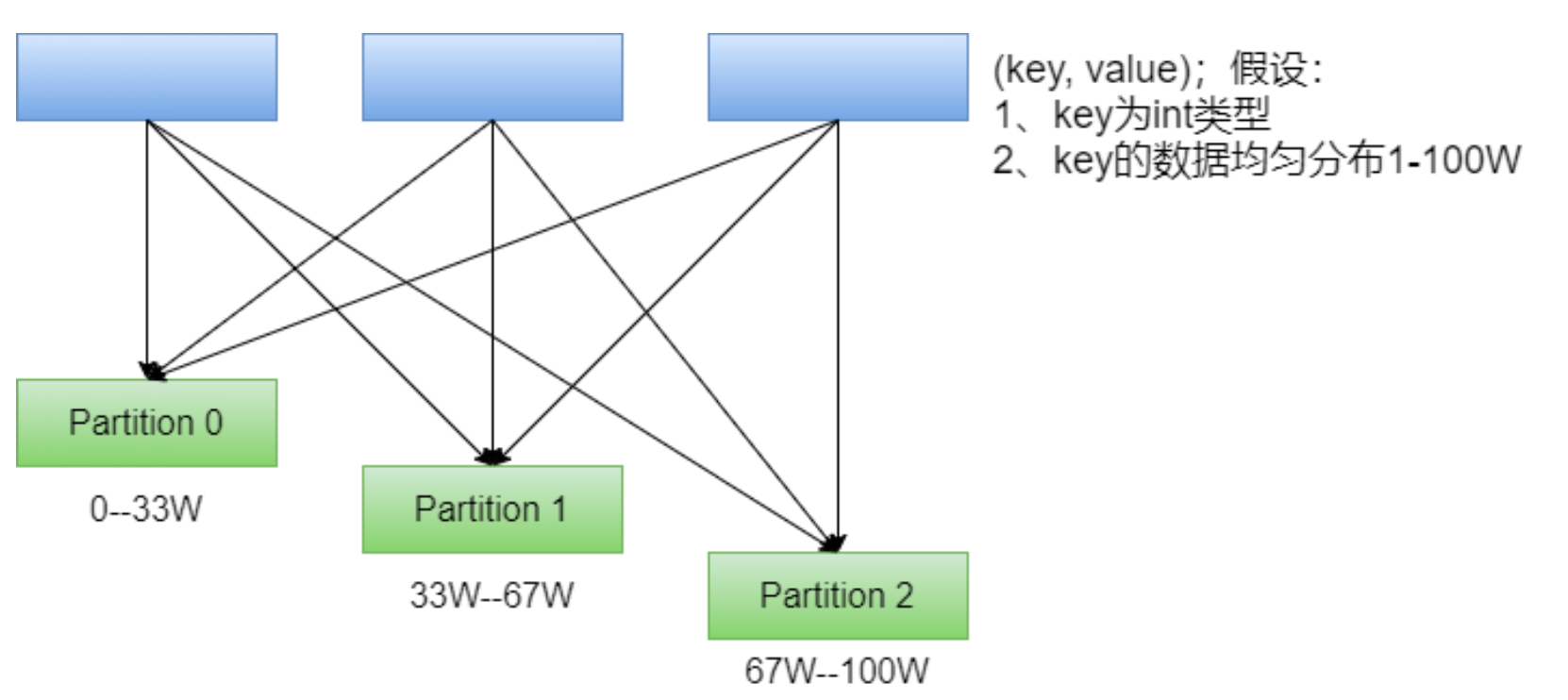 简单的说就是将一定范围内的数映射到某一个分区内。在实现 中,分界的算法尤为重要,用到了水塘抽样算法。sortByKey会使用 RangePartitioner。
简单的说就是将一定范围内的数映射到某一个分区内。在实现 中,分界的算法尤为重要,用到了水塘抽样算法。sortByKey会使用 RangePartitioner。现在的问题:在执行分区之前其实并不知道数据的分布情况,如果想知道数据分区就 需要对数据进行采样;
Spark中RangePartitioner在对数据采样的过程中使用了水塘采样算法。
水塘采样:从包含n个项目的集合S中选取k个样本,其中n为一很大或未知的数量,尤其适用于不能把所有n个项目都存放到主内存的情况;
在采样的过程中执行了collect()操作,引发了Action操作。 -
自定义分区器 Spark允许用户通过自定义的Partitioner对象,灵活的来控制RDD的 分区方式。
实现自定义分区器按以下规则分区:0~1000, 每100一个分区
import org.apache.spark.{Partitioner, SparkConf, SparkContext} // 继承spark的partitioner,并实现分区方法 class MyPartitioner extends Partitioner{ override def numPartitions: Int = 11 override def getPartition(key: Any): Int = key.toString.toInt / 100 } object UserDefinedPartitioner { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getCanonicalName.init) val sc = new SparkContext(conf) sc.setLogLevel("WARN") val random = scala.util.Random val arr = (1 to 100).map(_ => random.nextInt(1000)) val rdd = sc.makeRDD(arr, 10).map((_, 1)) // 打印分区前的数据 rdd.glom().foreach(x => println(x.toList)) println("-"*40) // 打印分区后的数据 val rdd2 = rdd.partitionBy(new MyPartitioner) rdd2.glom().foreach(x => println(x.toList)) sc.stop() } }
-
- 共享变量
有时候需要在多个任务之间共享变量,或者在任务(Task)和Driver Program之间共享变量。为了满足这种需求,Spark提供了两种类型的变量:
- 广播变量(broadcast variables)
-
累加器(accumulators)
广播变量、累加器主要作用是为了优化Spark程序。- 广播变量
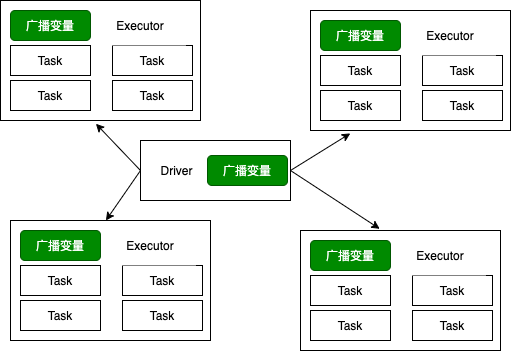 广播变量将变量在节点的 Executor 之间进行共享(由Driver广播出去); 广播变量用来高效分发较大的对象。向所有工作节点(Executor)发送一个较大的只读值,以供一个或多个操作使用。
广播变量将变量在节点的 Executor 之间进行共享(由Driver广播出去); 广播变量用来高效分发较大的对象。向所有工作节点(Executor)发送一个较大的只读值,以供一个或多个操作使用。
使用广播变量的过程如下:- 对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。 任何可序列化的类型都可以这么实现(在 Driver 端)
- 通过 value 属性访问该对象的值(在 Executor 中)
- 变量只会被发到各个 Executor 一次,作为只读值处理
广播变量的相关参数:
- spark.broadcast.blockSize(缺省值:4m)
- spark.broadcast.checksum(缺省值:true)
-
spark.broadcast.compress(缺省值:true)
-
广播变量的运用(Map Side Join)
- 普通的Join操作
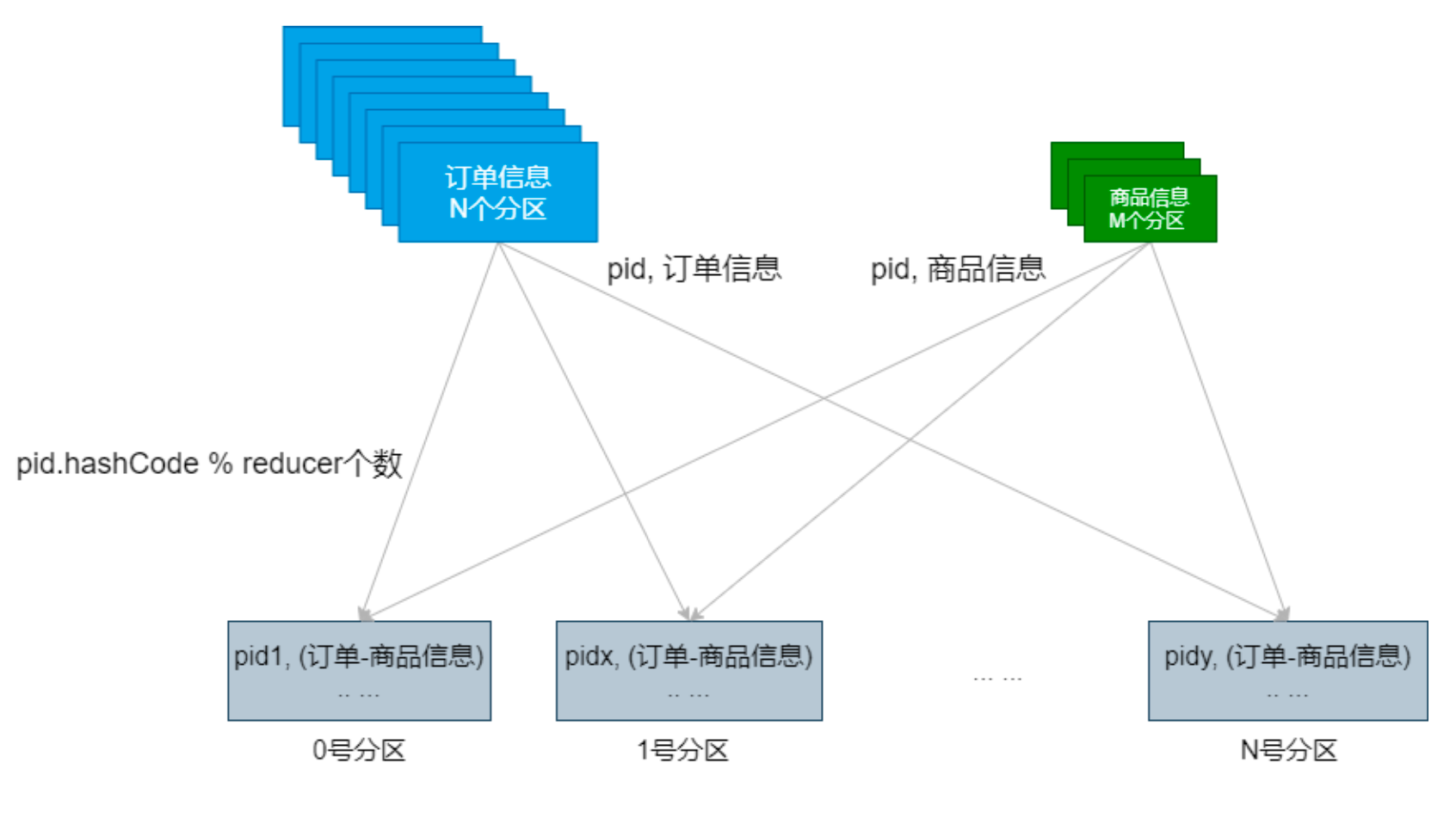
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object JoinDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getCanonicalName.init) val sc = new SparkContext(conf) sc.setLogLevel("WARN") // 设置本地文件切分大小 sc.hadoopConfiguration.setLong("fs.local.block.size", 128*1024*1024) val productInfoRDD = sc.textFile("data/lagou_product_info.txt") .map{line => val fields = line.split(";") (fields(0), line) } println(productInfoRDD.getNumPartitions) val orderInfoRDD = sc.textFile("/Volumes/April\\'s\\ Big\\ Disk/Big\\ Data/大数据正式班第四阶段模块二/spark软件及数据/orderinfo.txt") .map{line => val fields = line.split(";") (fields(2), line) } println(orderInfoRDD.getNumPartitions) val resultRDD: RDD[(String, (String, String))] = orderInfoRDD.join(productInfoRDD) println(resultRDD.count()) Thread.sleep(1000000) sc.stop() } }- 运行效率
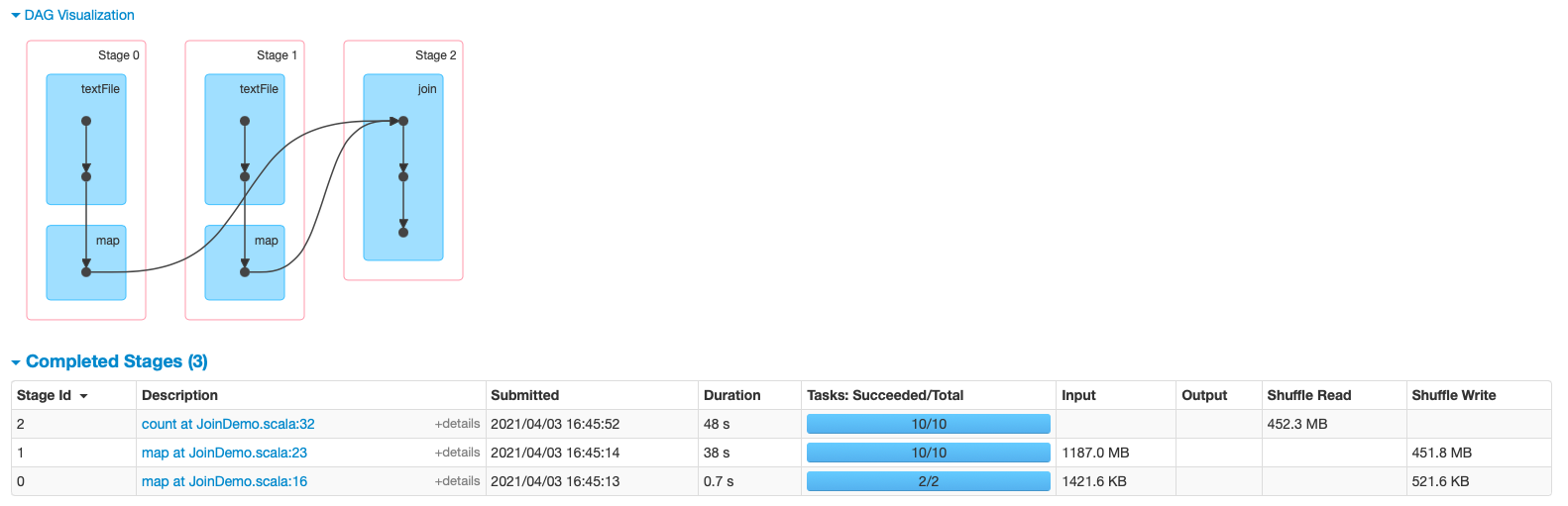
- 运行效率
- Map Side Join
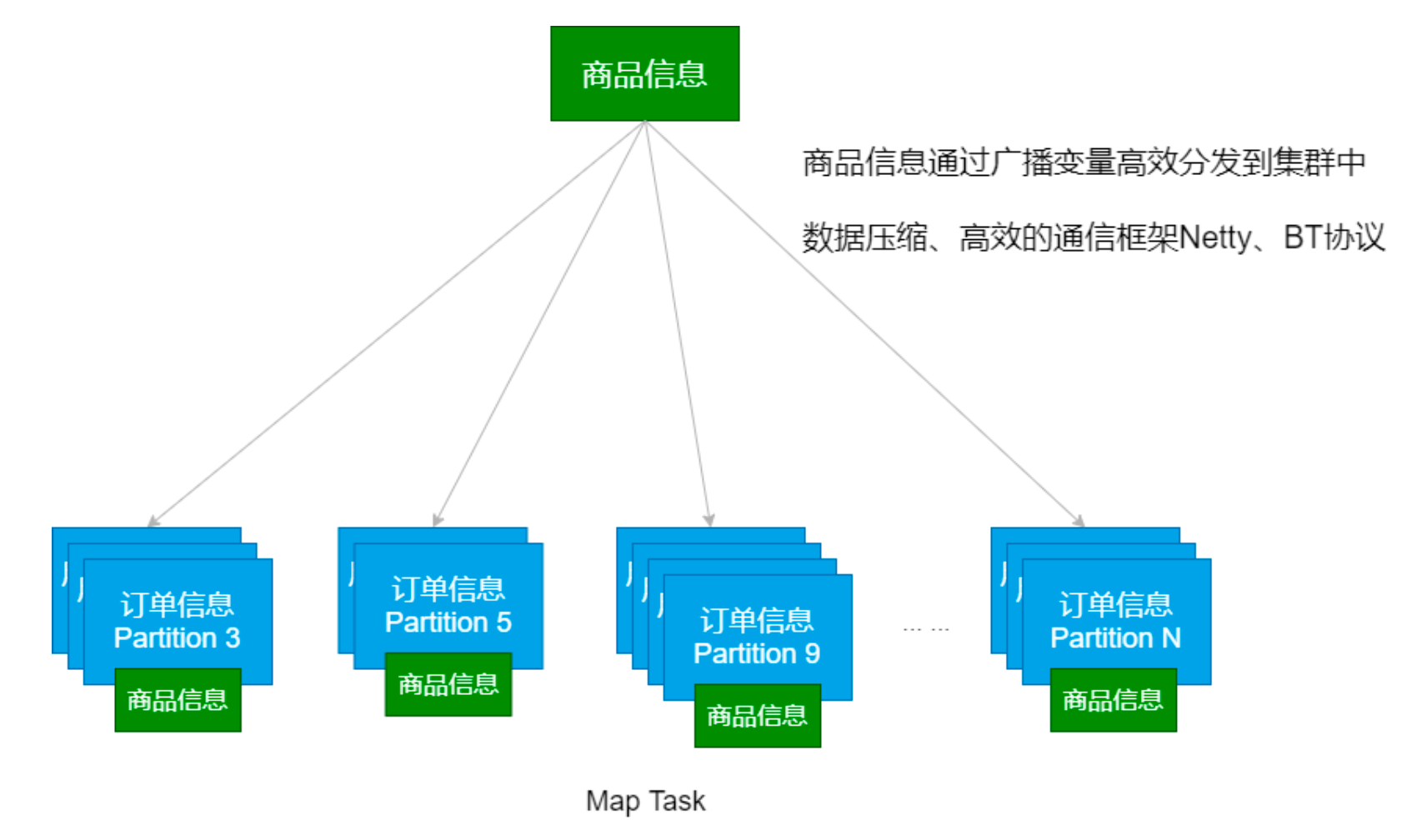
import org.apache.spark.broadcast.Broadcast import org.apache.spark.{SparkConf, SparkContext} object MapJoinDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getCanonicalName.init) val sc = new SparkContext(conf) sc.setLogLevel("WARN") // 设置本地文件切分大小 sc.hadoopConfiguration.setLong("fs.local.block.size", 128*1024*1024) val productInfoRDD = sc.textFile("data/lagou_product_info.txt") .map{line => val fields = line.split(";") (fields(0), line) } val orderInfoRDD = sc.textFile("/Volumes/April\\'s\\ Big\\ Disk/Big\\ Data/大数据正式班第四阶段模块二/spark软件及数据/orderinfo.txt") .map{line => val fields = line.split(";") (fields(2), line) } /** * Broadcast a read-only variable to the cluster, returning a * [[org.apache.spark.broadcast.Broadcast]] object for reading it in distributed functions. * The variable will be sent to each cluster only once. * * @param value to broadcast to the Spark nodes * @return `Broadcast` object, a read-only variable cached on each machine */ // def broadcast[T: ClassTag](value: T): Broadcast[T] = val productInfoBC: Broadcast[collection.Map[String, String]] = sc.broadcast(productInfoRDD.collectAsMap()) val resultRDD = orderInfoRDD .map{case (productId, orderInfo) => val productInfo = productInfoBC.value (productId, (orderInfo, productInfo.getOrElse(productId, null))) } println(resultRDD.count()) Thread.sleep(1000000) sc.stop() } }- 运行效率
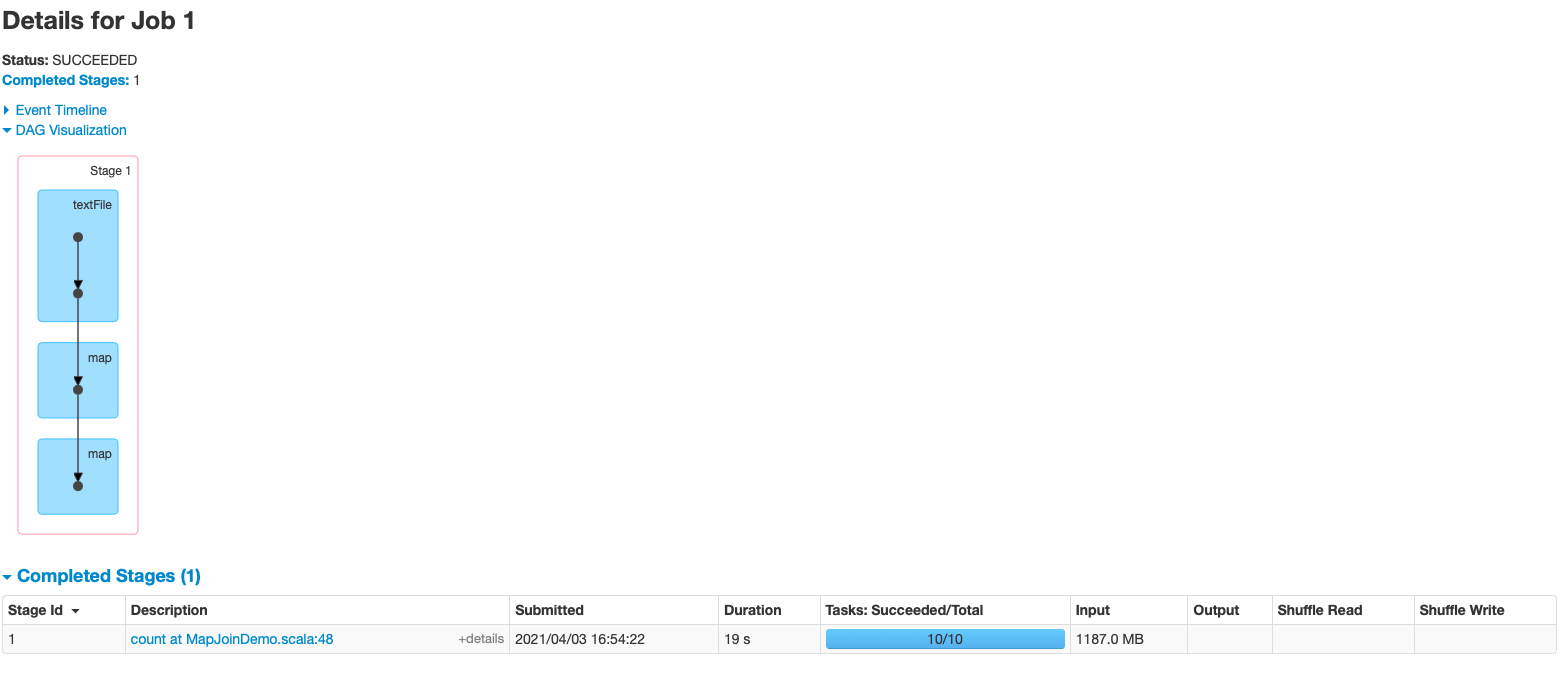
- 运行效率
- 普通的Join操作
-
-
累加器
累加器的作用:可以实现一个变量在不同的 Executor 端能保持状态的累加; 累计器在 Driver 端定义,读取;在 Executor 中完成累加;
累加器也是 lazy 的,需要 Action 触发;Action触发一次,执行一次,触发多次,执行多次;
累加器一个比较经典的应用场景是用来在 Spark Streaming 应用中记录某些事件的 数量;// 统计单词的数量 val data = sc.makeRDD(Seq("hadoop map reduce", "spark mllib")) // 方式1 val count1 = data.flatMap(line => line.split("\\s+")).map(word => 1).reduce(_ + _) // 方式2。错误的方式 var acc=0 data.flatMap(line => line.split("\\s+")).foreach(word => acc += 1) println(acc)Spark内置了三种类型的累加器,分别是:
- LongAccumulator 用来累加整数型
- DoubleAccumulator 用来累加浮点型
- CollectionAccumulator 用来累加集合元素
val rdd = data.map {word => acc1.add(1) acc2.add(word.length) acc3.add(word) word } rdd.count // rdd.collect (acc1.value, acc2.value, acc3.value) // (24,114.0,[hbase, java, spark, scala, java, hive, hello, world, spark, hive, scala, hadoop, hbase, java, java, hive, spark, scala, hello, world, spark, hive, hadoop, scala]) // 每调用一次map就会触发一次,如果一个transform操作,属于多个action,累加器就会调用多次
- 广播变量
- TopN的优化
import org.apache.spark.{SparkConf, SparkContext} import scala.collection.{immutable, mutable} /** * topN 的优化 */ object TopN { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val random = scala.util.Random val data: immutable.Seq[String] = (1 to 50).flatMap { idx => (1 to 2000).map { _ => f"group$idx%2d,${random.nextInt(100000)}" } } val scoreRDD = sc.makeRDD(data, 10) .map{line => val fields = line.split(",") (fields(0), fields(1).toInt) } scoreRDD.cache() val N = 5 // groupByKey scoreRDD .groupByKey() .mapValues{value => value.toList.sorted.takeRight(N).reverse} .sortByKey() .collect() .foreach(println) println("-"*50) // 去掉groupByKey, shuffle的时候只保留需要的TopN scoreRDD.aggregateByKey(List[Int]())( (lst, score) => (score::lst).sorted.takeRight(N), (lst1, lst2) => (lst1:::lst2).sorted.takeRight(N) ) .mapValues(buf => buf.reverse) .sortByKey() .collect() .foreach(println) Thread.sleep(10000000) sc.stop() } }
Spark原理初探
- Standalone模式作业提交
Standalone 模式下有四个重要组成部分,分别是:
- Driver:用户编写的 Spark 应用程序就运行在 Driver 上,由Driver 进程执行
- Master:主要负责资源的调度和分配,并进行集群的监控等职责
- Worker:Worker 运行在集群中的一台服务器上。负责管理该节点上的资源,负 责启动启动节点上的 Executor
- Executor:一个 Worker 上可以运行多个 Executor,Executor通过启动多个线 程(task)对 RDD 的分区进行并行计算
SparkContext 中的三大组件:
- DAGScheduler:负责将DAG划分成若干个Stage
- TaskScheduler:将DAGScheduler提交的 Stage(Taskset)进行优先级排序,再将 task 发送到 Executor
-
SchedulerBackend:定义了许多与Executor事件相关的处理,包括:新的 executor注册进来的时候记录executor的信息,增加全局的资源量(核数);executor 更新状态,若任务完成的话,回收core; 停止executor、remove executor等事件
- 提交步骤
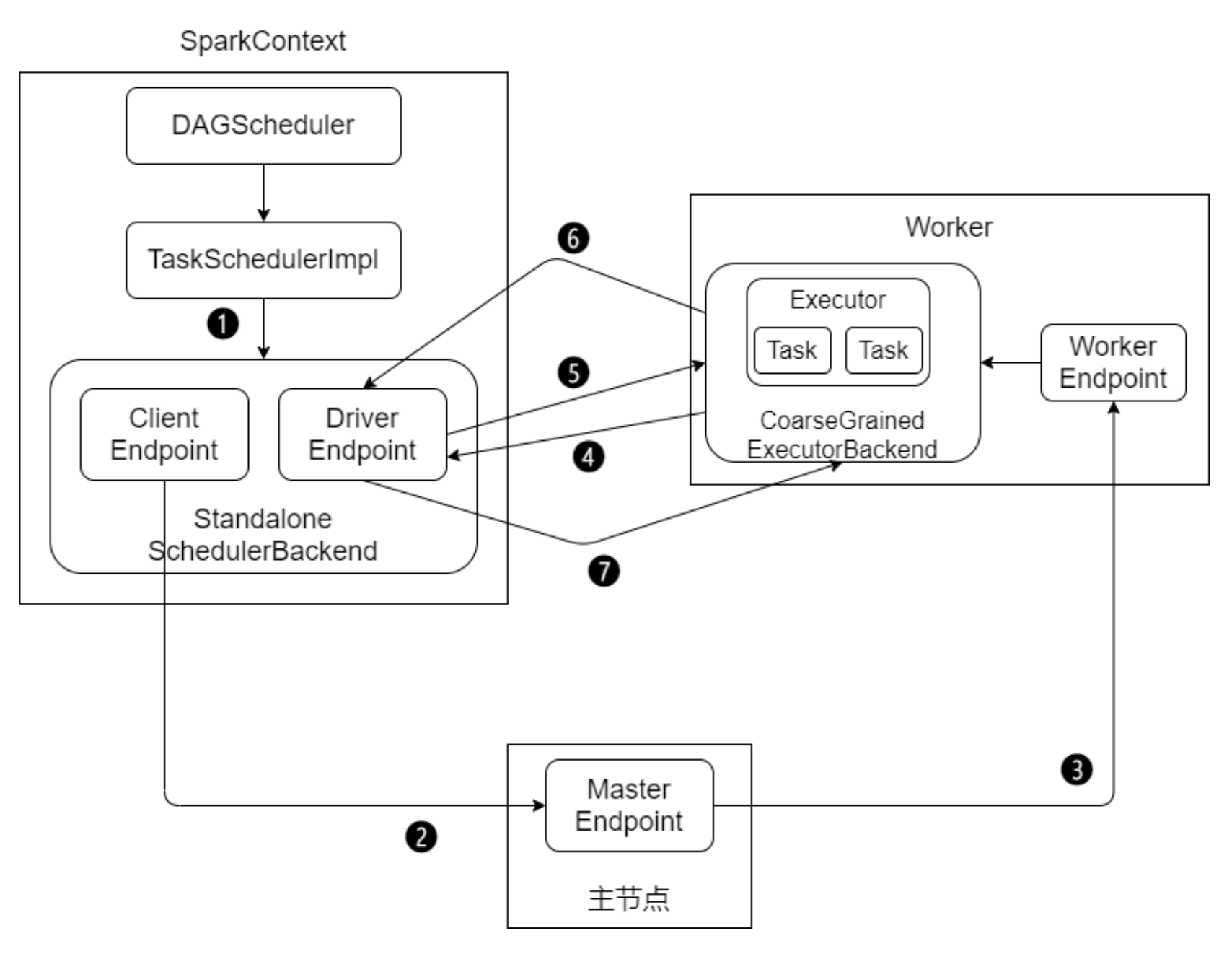 1、启动应用程序,完成SparkContext的初始化
1、启动应用程序,完成SparkContext的初始化
2、Driver向Master注册,申请资源 3、Master检查集群资源状况。若集群资源满足,通知Worker启动Executor 4、Executor启动后向Driver注册(称为反向注册)
5、Driver完成DAG的解析,得到Tasks,然后向Executor发送Task
6、Executor 向Driver汇总任务的执行情况
7、应用程序执行完毕,回收资源
- 提交步骤
-
Shuffle原理 Shuffle是MapReduce计算框架中的一个特殊的阶段,介于Map 和 Reduce 之间。 当Map的输出结果要被Reduce使用时,输出结果需要按key排列,并且分发到 Reducer上去,这个过程就是shuffle。
shuffle涉及到了本地磁盘(非hdfs)的读写和网络的传输,大多数Spark作业的性能 主要就是消耗在了shuffle环节。因此shuffle性能的高低直接影响到了整个程序的运 行效率-
spark shuffle的演变
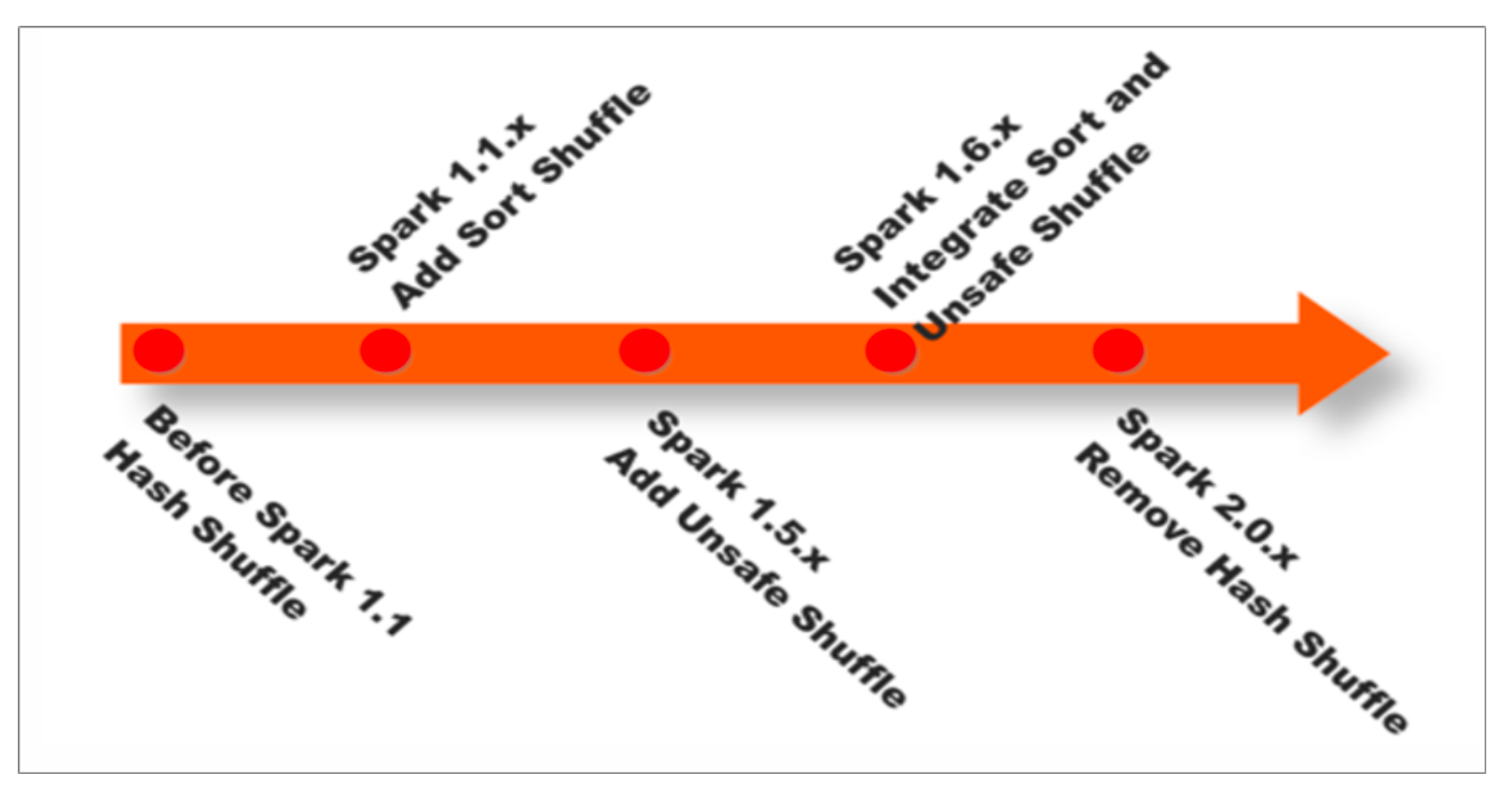 在Spark Shuffle的实现上,经历了Hash、Sort、Tungsten-Sort(堆外内存)三阶段:
在Spark Shuffle的实现上,经历了Hash、Sort、Tungsten-Sort(堆外内存)三阶段:- Hash Base Shuffle V1
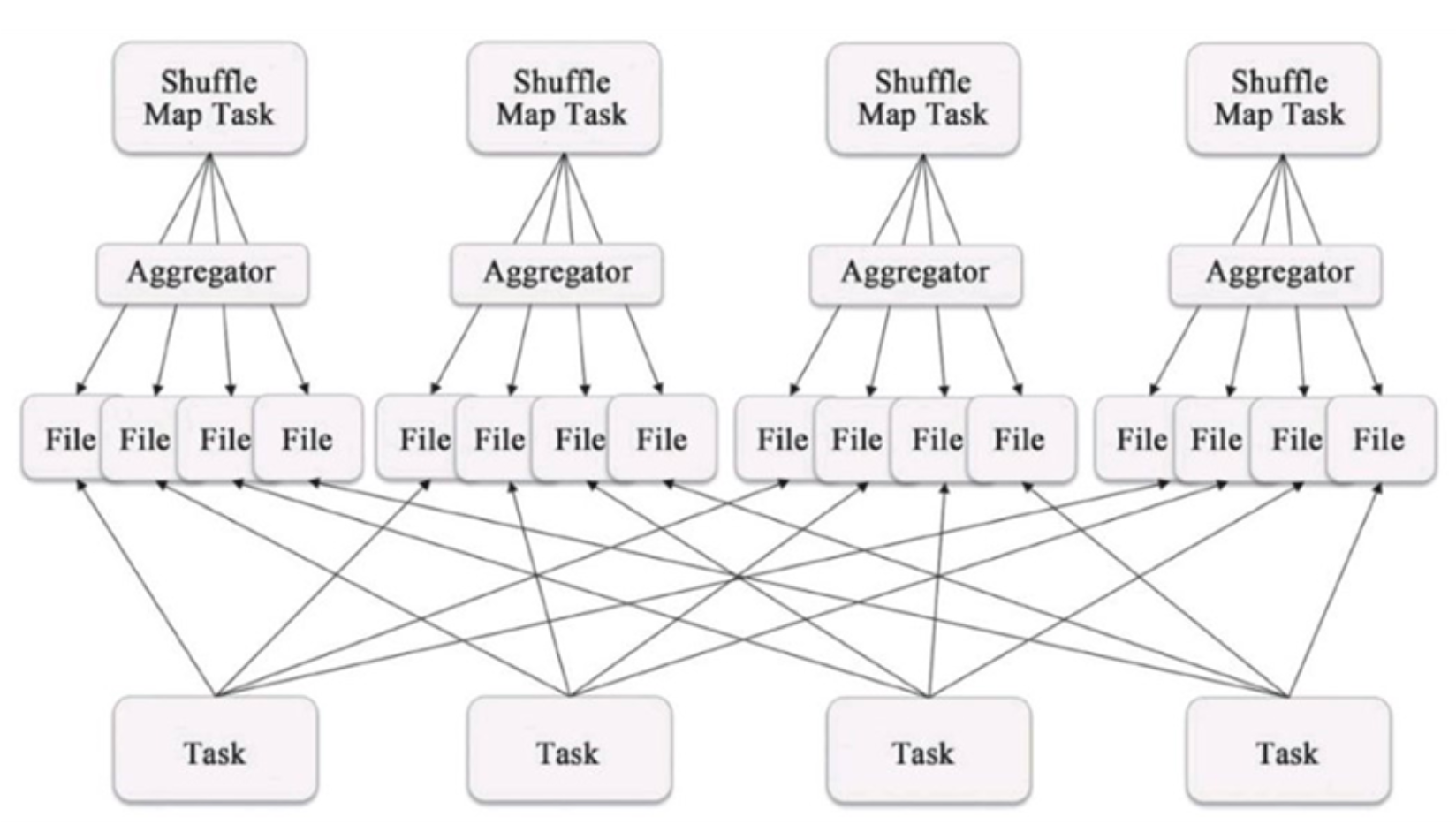
- 每个Shuffle Map Task需要为每个下游的Task创建一个单独的文件
- Shuffle过程中会生成海量的小文件。同时打开过多文件、低效的随机IO
-
Hash Base Shuffle V2
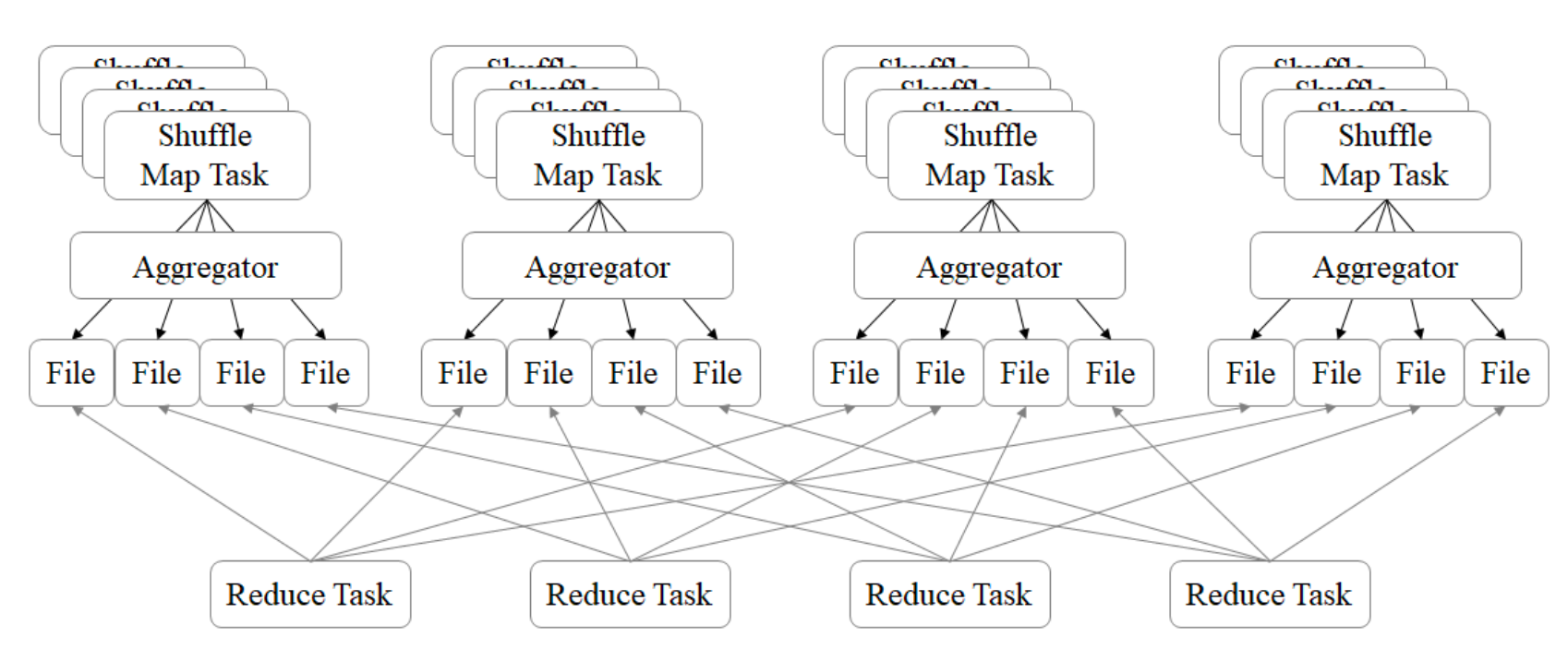 Hash Base Shuffle V2 核心思想:允许不同的task复用同一批磁盘文件,有效将多个 task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升 shuffle write的性能。一定程度上解决了Hash V1中的问题,但不彻底。
Hash Base Shuffle V2 核心思想:允许不同的task复用同一批磁盘文件,有效将多个 task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升 shuffle write的性能。一定程度上解决了Hash V1中的问题,但不彻底。Hash Shuffle 规避了排序,提高了性能;总的来说在Hash Shuffle过程中生成海量 的小文件(Hash Base Shuffle V2生成海量小文件的问题得到了一定程度的缓解)。
- Sort Base Shuffle
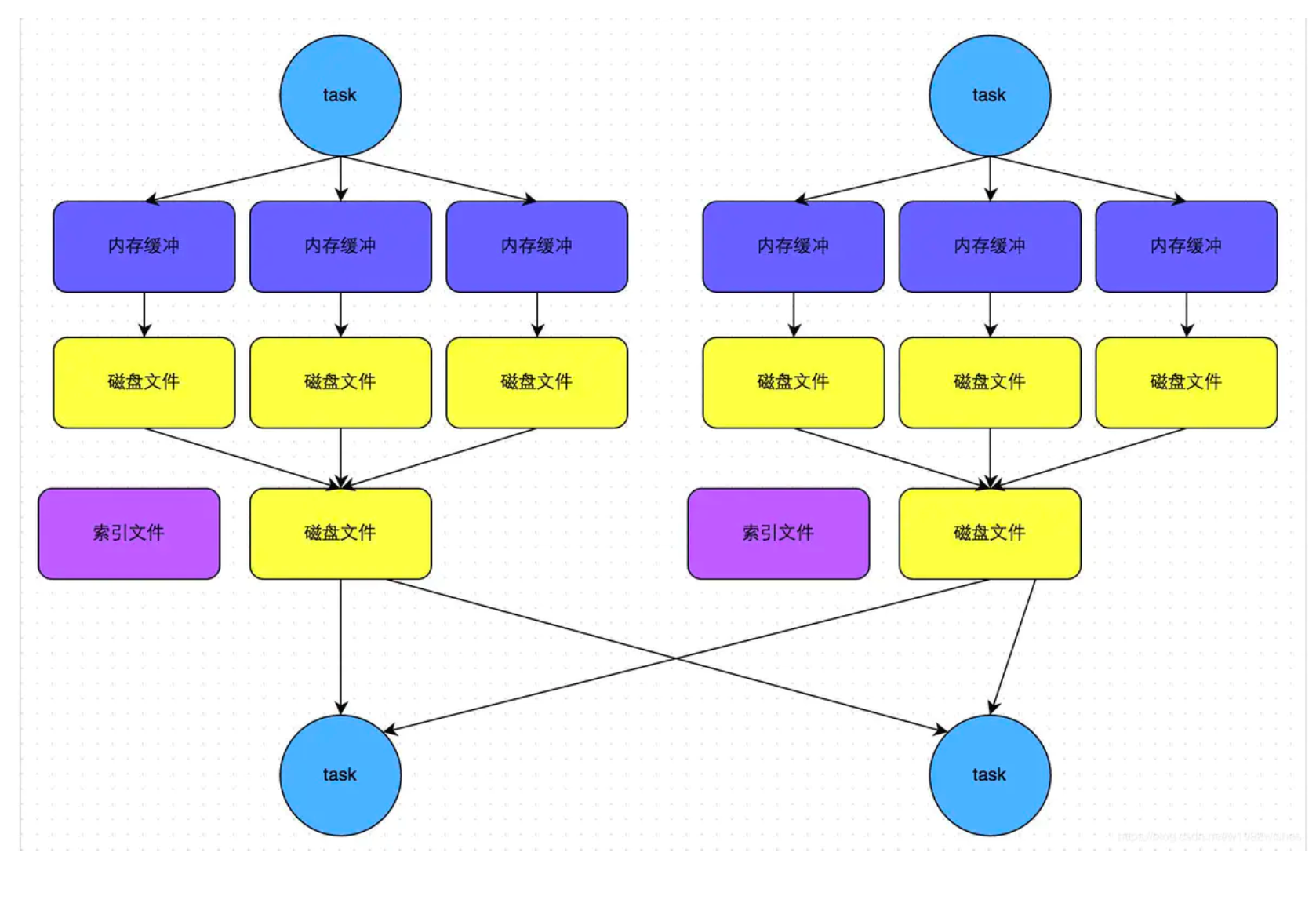 Sort Base Shuffle大大减少了shuffle过程中产生的文件数,提高Shuffle的效率;
Sort Base Shuffle大大减少了shuffle过程中产生的文件数,提高Shuffle的效率;
Spark Shuffle 与 Hadoop Shuffle 从目的、意义、功能上看是类似的,实现(细 节)上有区别。
- Hash Base Shuffle V1
-
-
RDD编程优化
-
RDD复用 避免创建重复的RDD。在开发过程中要注意:对于同一份数据,只应该创建一个 RDD,不要创建多个RDD来代表同一份数据。
- RDD缓存/持久化
- 当多次对同一个RDD执行算子操作时,每一次都会对这个RDD以之前的父RDD 重新计算一次,这种情况是必须要避免的,对同一个RDD的重复计算是对资源的 极大浪费
- 对多次使用的RDD进行持久化,通过持久化将公共RDD的数据缓存到内存/磁盘 中,之后对于公共RDD的计算都会从内存/磁盘中直接获取RDD数据
- RDD的持久化是可以进行序列化的,当内存无法将RDD的数据完整的进行存放的 时候,可以考虑使用序列化的方式减小数据体积,将数据完整存储在内存中
- 巧用 filter
- 尽可能早的执行filter操作,过滤无用数据
- 在filter过滤掉较多数据后,使用 coalesce 对数据进行重分区
-
使用高性能算子
1、避免使用groupByKey,根据场景选择使用高性能的聚合算子 reduceByKey、 aggregateByKey
2、coalesce、repartition,在可能的情况下优先选择没有shuffle的操作
3、foreachPartition 优化输出操作
4、map、mapPartitions,选择合理的选择算子;mapPartitions性能更好,但数据量大时容易导致OOM
5、用 repartitionAndSortWithinPartitions替代 repartition + sort 操作
6、合理使用 cache、persist、checkpoint,选择合理的数据存储级别
7、filter的使用
8、减少对数据源的扫描(算法复杂了) - 设置合理的并行度
- Spark作业中的并行度指各个stage的task的数量
- 设置合理的并行度,让并行度与资源相匹配。简单来说就是在资源允许的前提 下,并行度要设置的尽可能大,达到可以充分利用集群资源。合理的设置并行 度,可以提升整个Spark作业的性能和运行速度
- 广播大变量
- 默认情况下,task中的算子中如果使用了外部变量,每个task都会获取一份变量 的复本,这会造多余的网络传输和内存消耗
- 使用广播变量,只会在每个Executor保存一个副本,Executor的所有task共用此 广播变量,这样就节约了网络及内存资源
-
Spark SQL
Spark SQL概述
Spark SQL(Spark on Hive), 源码在Spark中,支持多种数据源,多种优化技术,扩展性好很多
-
Spark SQL特点
 Spark SQL自从面世以来不仅接过了shark的接力棒,为spark用户提供高性能的SQL on hadoop的解决方案,还为spark带来了通用的高效的,多元一体的结构化的数据 处理能力。
Spark SQL自从面世以来不仅接过了shark的接力棒,为spark用户提供高性能的SQL on hadoop的解决方案,还为spark带来了通用的高效的,多元一体的结构化的数据 处理能力。-
写更少的代码
-
读更少的数据 SparkSQL的表数据在内存中存储不使用原生态的JVM对象存储 方式,而是采用内存列存储
-
提供更好的性能 字节码生成技术、SQL优化
-
-
Spark SQL数据抽象 SparkSQL提供了两个新的抽象,分别是DataFrame和DataSet;
同样的数据都给到这三个数据结构,经过系统的计算逻辑,都得到相同的结果。不同是它们的执行效率和执行方式;
在后期的Spark版本中,DataSet会逐步取代 RDD 和 DataFrame 成为唯一的API接 口。-
DataFrame
 DataFrame的前身是SchemaRDD。Spark1.3更名为DataFrame。不继承RDD,自己实现了RDD的大部分功能。
DataFrame的前身是SchemaRDD。Spark1.3更名为DataFrame。不继承RDD,自己实现了RDD的大部分功能。与RDD类似,DataFrame也是一个分布式数据集:
- DataFrame可以看做分布式 Row 对象的集合,提供了由列组成的详细模式信 息,使其可以得到优化。DataFrame 不仅有比RDD更多的算子,还可以进行执行计划的优化
- DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信 息,即schema
- DataFrame也支持嵌套数据类型(struct、array和map)
- DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友 好,门槛更低
- Dataframe的劣势在于在编译期缺少类型安全检查,导致运行时出错
-
DataSet
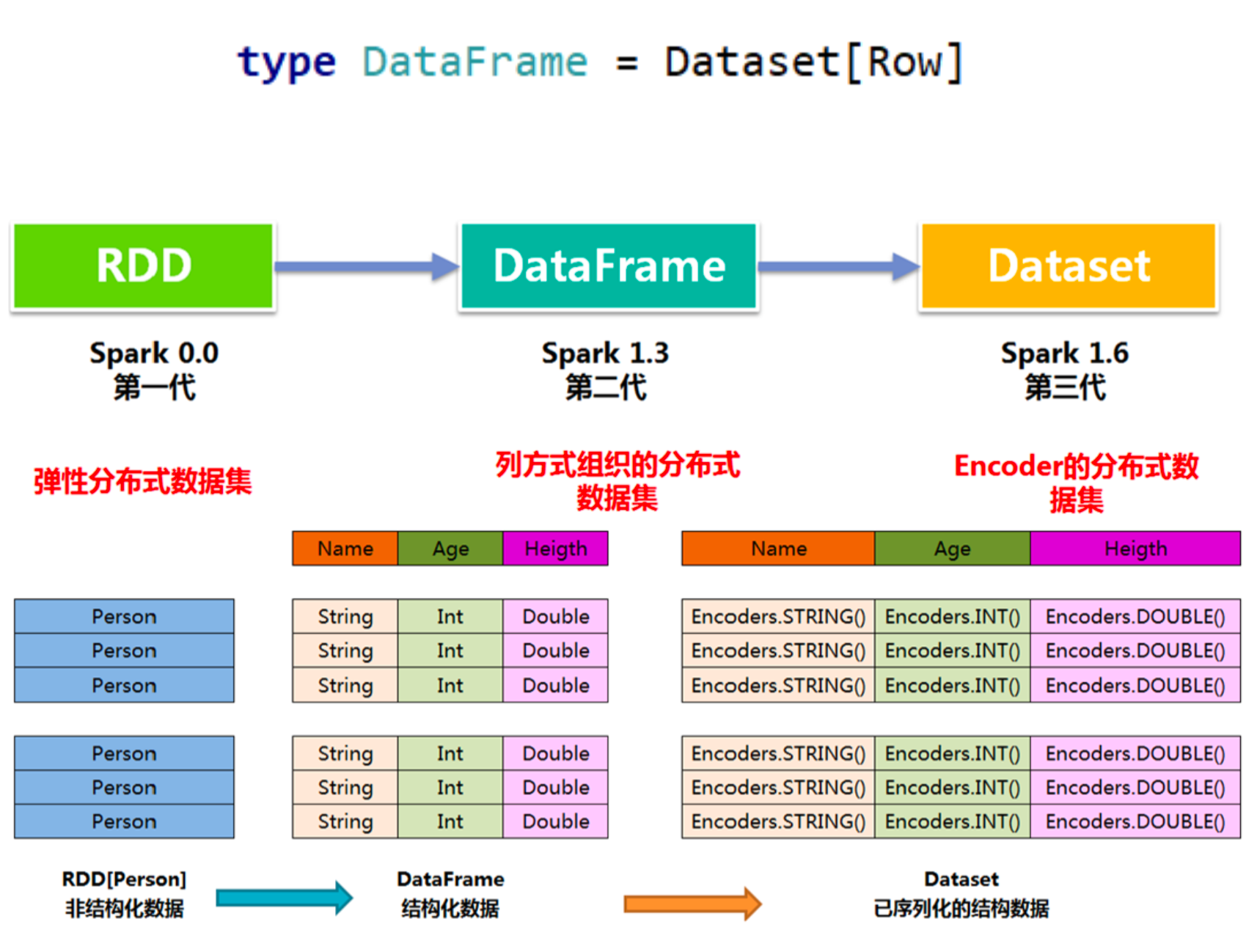 DataSet是在Spark1.6中添加的新的接口;
DataSet是在Spark1.6中添加的新的接口;
与RDD相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表;
与DataFrame相比,保存了类型信息,是强类型的,提供了编译时类型检查;
调用Dataset的方法先会生成逻辑计划,然后Spark的优化器进行优化,最终生成物 理计划,然后提交到集群中运行。
DataSet包含了DataFrame的功能,在Spark2.0中两者得到了一:DataFrame表示 为DataSet[Row],即DataSet的子集。 -
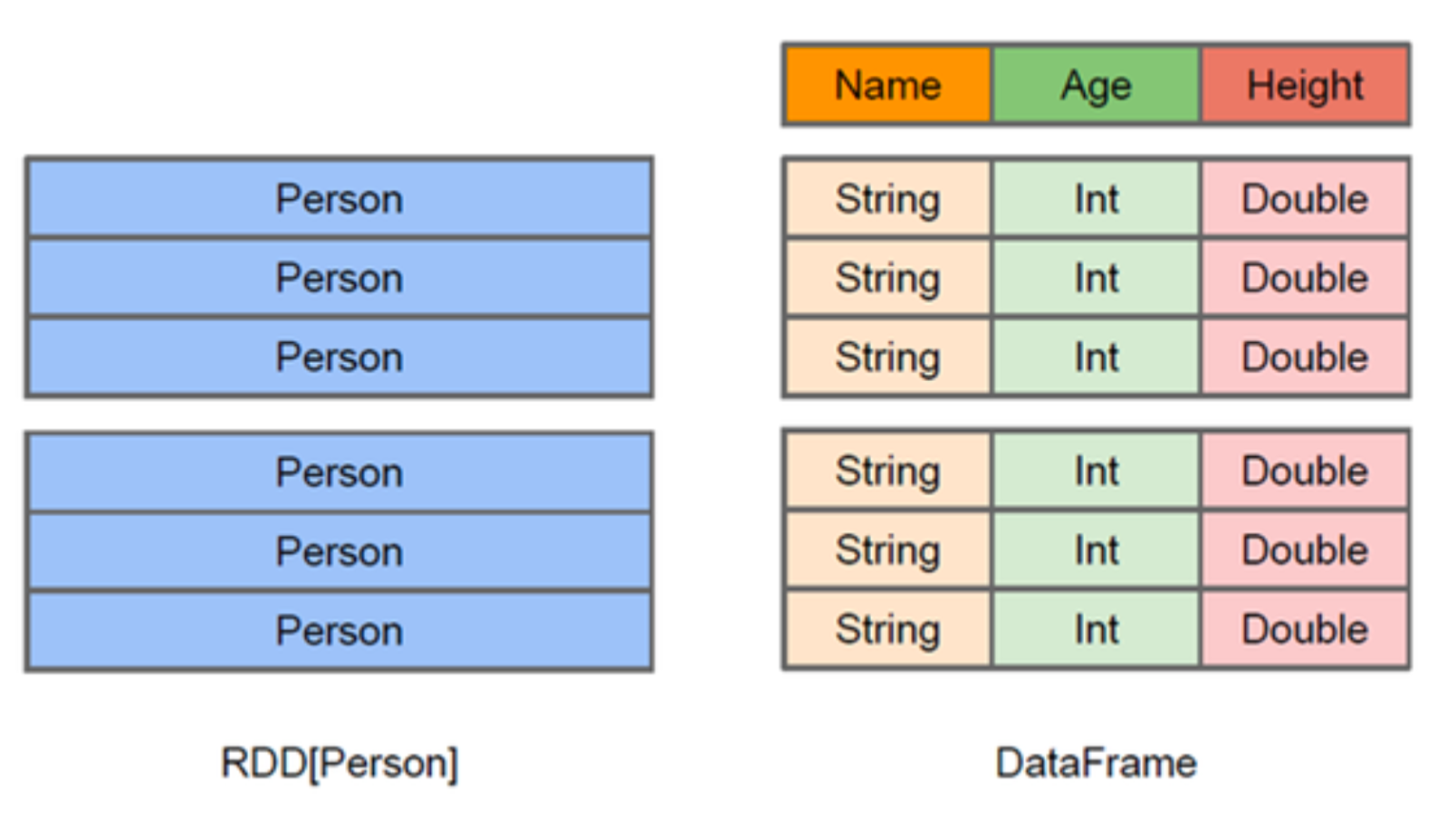
Row & Schema DataFrame = RDD[Row] + Schema;DataFrame 的前身是 SchemaRDD
Row是一个泛化的无类型 JVM objectimport org.apache.spark.sql.Row val row1 = Row(1,"abc", 1.2) // Row 的访问方法 (row1(0),row1(1),row1(2)) // row1: org.apache.spark.sql.Row = [1,abc,1.2] res2: (Any, Any, Any) = (1,abc,1.2) (row1.getInt(0), row1.getString(1), row1.getDouble(2)) //res3: (Int, String, Double) = (1,abc,1.2) (row1.getAs[Int](0), row1.getAs[String](1), row1.getAs[Double](2)) //res4: (Int, String, Double) = (1,abc,1.2)DataFrame(即带有Schema信息的RDD),Spark通过Schema就能够读懂数据。 什么是schema?
DataFrame中提供了详细的数据结构信息,从而使得SparkSQL可以清楚地知道该数 据集中包含哪些列,每列的名称和类型各是什么,DataFrame中的数据结构信息, 即为schema。import org.apache.spark.sql.types._ val schema = (new StructType). add("id", "int", false). add("name", "string", false). add("height", "double", false) /** import org.apache.spark.sql.types._ schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,IntegerType,false), StructField(name,StringType,false), StructField(height,DoubleType,false)) */ -
三者的共性 1、RDD、DataFrame、Dataset都是 Spark 平台下的分布式弹性数据集,为处理海量数据提供便利
2、三者都有许多相同的概念,如分区、持久化、容错等;有许多共同的函数,如map、filter,sortBy等
3、三者都有惰性机制,只有在遇到 Action 算子时,才会开始真正的计算
4、对DataFrame和Dataset进行操作许多操作都需要这个包进行支持,import spark.implicits._ -
三者的区别 DataFrame(DataFrame = RDD[Row] + Schema):
1、与RDD和Dataset不同,DataFrame每一行的类型固定为Row,只有通过解析才 能获取各个字段的值
2、DataFrame与Dataset均支持 SparkSQL 的操作Dataset(Dataset = RDD[case class].toDS):
1、Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同;
2、DataFrame 定义为 Dataset[Row]。每一行的类型是Row,每一行究竟有哪些字 段,各个字段又是什么类型都无从得知,只能用前面提到的getAS方法或者模式匹配 拿出特定字段;
3、Dataset每一行的类型都是一个case class,在自定义了case class之后可以很自由的获得每一行的信息;
-
-
数据类型
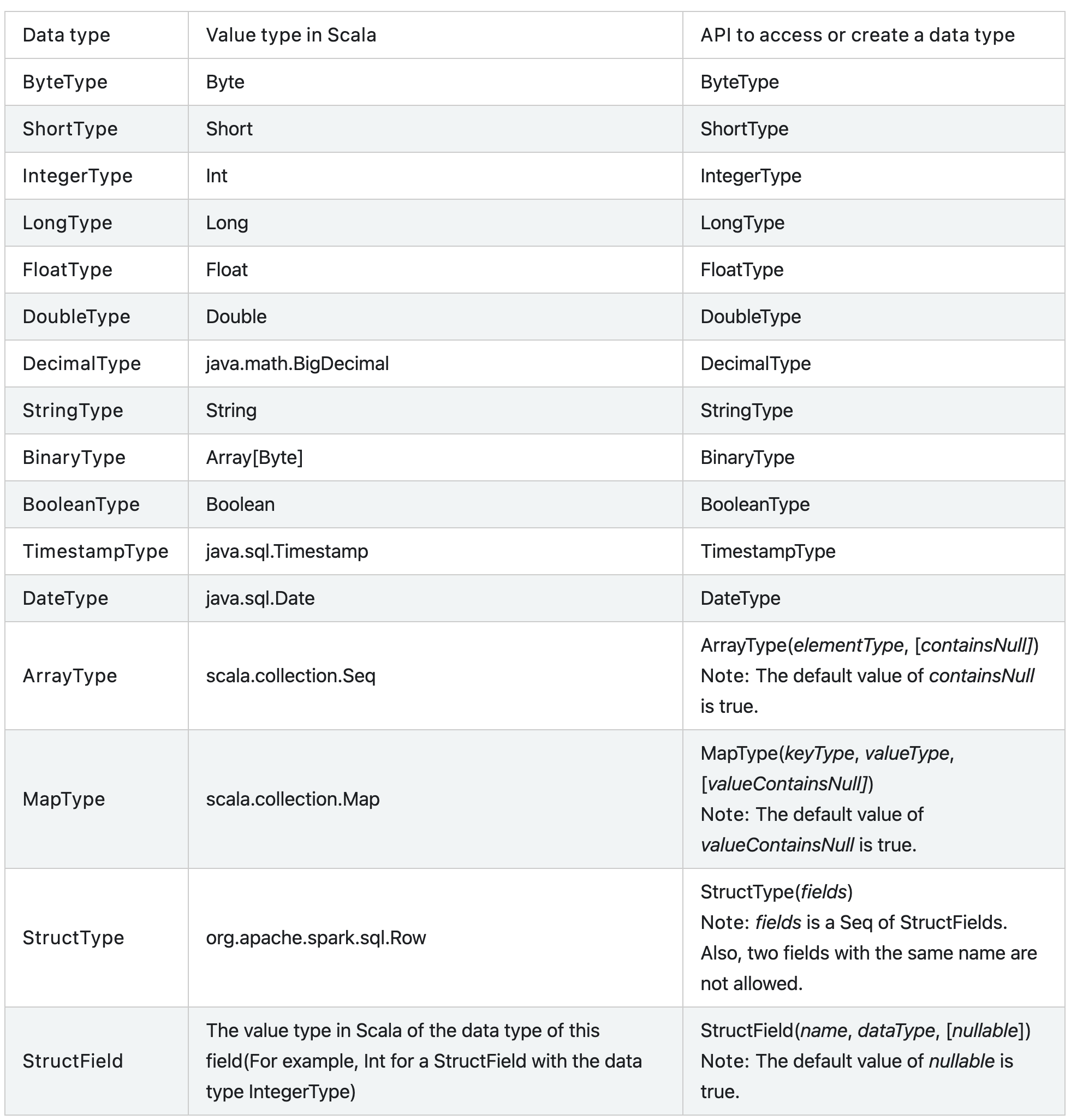 http://spark.apache.org/docs/latest/sql-ref-datatypes.html
http://spark.apache.org/docs/latest/sql-ref-datatypes.html
Spark SQL编程
官方文档:http://spark.apache.org/docs/latest/sql-getting-started.html
- SparkSession
val spark = SparkSession .builder() .appName("Spark SQL basic example") .config("options", "what ever") .master("local[*]") .getOrCreate() val sc = spark.sparkContext sc.setLogLevel("WARN") //Implicit methods available in Scala for converting // * common Scala objects into `DataFrame`s. import spark.implicits._ -
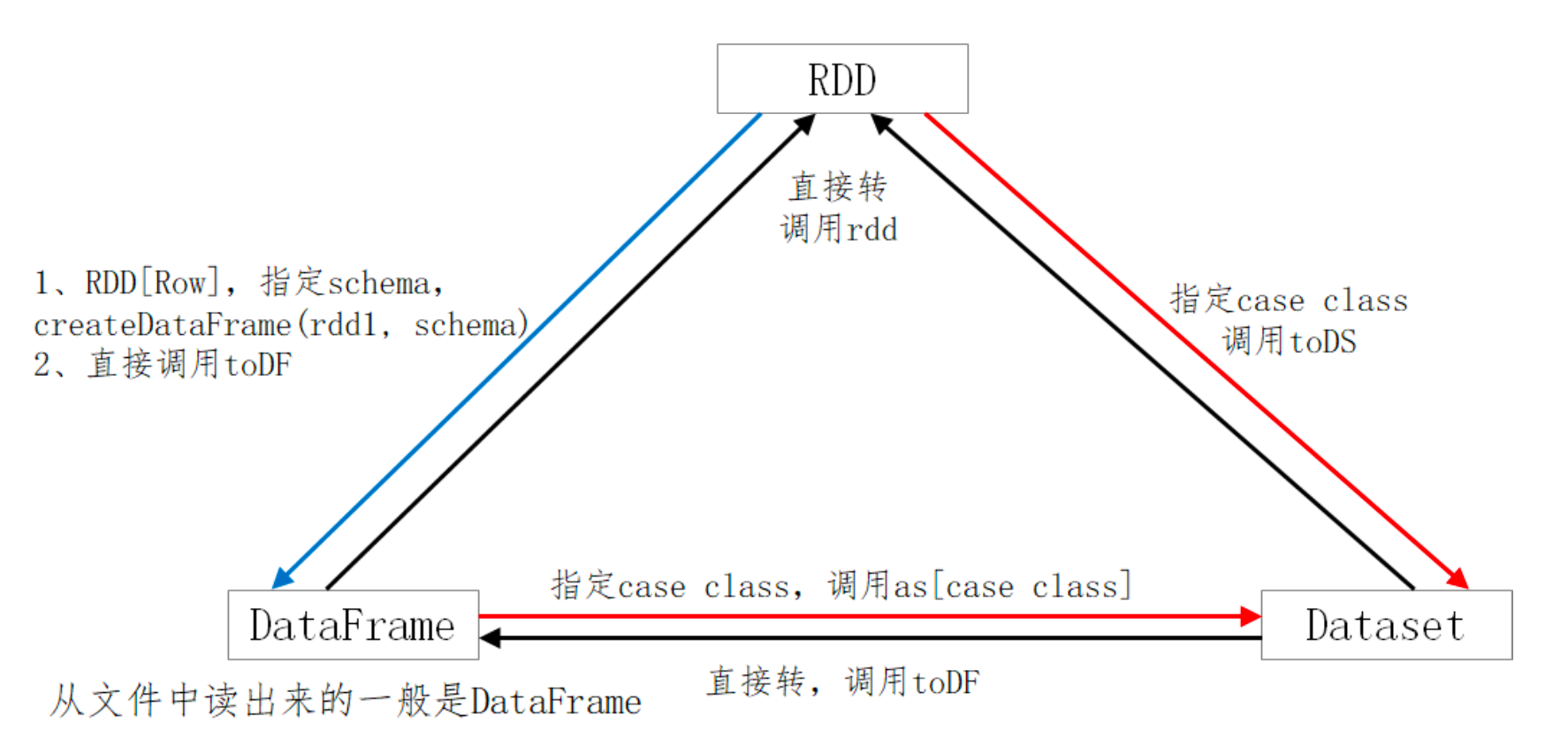
DataFrame & Dataset 的创建 不要刻意区分:DF、DS。DF是一种特殊的DS; ds.transformation => df
Dataset = RDD[case class]
DataFrame = RDD[Row] + Schema-
三者的转换
- 由range生成Dataset
val numDS = spark.range(5, 100, 5) // orderBy 转换操作;desc:function;show:Action numDS.orderBy(desc("id")).show(5) // 统计信息 numDS.describe().show // 显示schema信息 numDS.printSchema // 使用RDD执行同样的操作 numDS.rdd.map(_.toInt).stats // 检查分区数 numDS.rdd.getNumPartitions - 由集合生成Dataset
case class Person(name: String, age: Int, height: Int) // 注意 Seq 中元素的类型 val seq1 = Seq(Person("Jack", 28, 184), Person("Tom", 10, 144), Person("Andy", 16, 165)) val ds1 = spark.createDataset(seq1) // org.apache.spark.sql.Dataset[Person] = [name: string, age: int ... 1 more field] val seq2 = Seq(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165)) val ds2 = spark.createDataset(seq2) // org.apache.spark.sql.Dataset[(String, Int, Int)] = [_1: string, _2: int ... 1 more field] - 由集合生成DataFrame
val lst = List(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165)) val df1 = spark.createDataFrame(lst) .withColumnRenamed("_1", "name1") .withColumnRenamed("_2", "age1") .withColumnRenamed("_3", "height1") // org.apache.spark.sql.DataFrame = [name1: string, age1: int ... 1 more field] // desc是函数,在IDEA中使用是需要导包 import org.apache.spark.sql.functions._ df1.orderBy(desc("age1")).show(10) // 修改整个DF的列名 val df2 = spark.createDataFrame(lst).toDF("name", "age", "height") - RDD 转成 DataFrame
val arr = Array(("Jack", 28, 184), ("Tom", 10, 144), ("Andy",16, 170)) val rdd1 = sc.makeRDD(arr).map(f=>Row(f._1, f._2, f._3)) val schema = StructType( StructField("name", StringType,false) ::StructField("age", IntegerType, false) ::StructField("height", IntegerType, false) ::Nil) // RDD => DataFrame,要指明schema val rddToDF = spark.createDataFrame(rdd1, schema) // RDD[case class] to DF,DS // 反射推断,spark 通过反射从case class的定义得到属性名 case class People(name: String, age: Int, height: Int) val arr = Array(People("Jack", 28, 184), People("Tom", 10, 144), People("Andy",16, 170)) val rdd = sc.makeRDD(arr) val ds2 = rdd.toDS val df2 = rdd.toDF -
RDD转Dataset Dataset = RDD[case class] DataFrame = RDD[Row] + Schema
val ds3 = spark.createDataset(rdd2) ds3.show(10) - 从文件创建DateFrame(以csv文件为例)
val df1 = spark.read.csv(file+"people1.csv") // 指定参数 val df3 = spark.read .options(Map(("header", "true"), ("inferschema", "true"))) .csv(file+"people1.csv") // spark 2.3.0 val schema = "name string, age int, job string" val df4 = spark.read .option("delimiter", ";") .option("header", "true") .schema(schema) .csv(file+"people2.csv")
-
-
Action操作
-
与结构相关 printSchema、explain、columns、dtypes、col
-
与RDD类似的操作 show、collect、collectAsList、head、first、count、take、takeAsList、reduce
-
-
Transformation 操作 select * from tab where … group by … having… order by…
-
与RDD类似的操作 map、filter、flatMap、mapPartitions、sample、 randomSplit、 limit、 distinct、dropDuplicates、describe
-
存储相关 cacheTable、persist、checkpoint、unpersist、cache
备注:Dataset 默认的存储级别是 MEMORY_AND_DISK缓存是懒操作,在需要的环节调用一用(cacheTable…) 在执行action的时候便会触发
-
select相关 列的多种表示、select、selectExpr drop、withColumn、withColumnRenamed、cast(内置函数)
// 列的多种表示方法。使用""、$""、'、col()、ds("") // 注意:不要混用;必要时使用spark.implicitis._;并非每个表示在所有的地方都有效 df1.select($"ename", $"hiredate", $"sal").show df1.select("ename", "hiredate", "sal").show df1.select('ename, 'hiredate, 'sal).show df1.select(col("ename"), col("hiredate"), col("sal")).show df1.select(df1("ename"), df1("hiredate"), df1("sal")).show // 下面的写法无效,其他列的表示法有效 df1.select("ename", "hiredate", "sal"+100).show df1.select("ename", "hiredate", "sal+100").show // 这样写才符合语法 df1.select($"ename", $"hiredate", $"sal"+100).show df1.select('ename, 'hiredate, 'sal+100).show // 可使用expr表达式(expr里面只能使用引号) df1.select(expr("comm+100"), expr("sal+100"), expr("ename")).show df1.selectExpr("ename as name").show df1.selectExpr("power(sal, 2)", "sal").show df1.selectExpr("round(sal, -3) as newsal", "sal","ename").show // drop、withColumn、 withColumnRenamed、casting // drop 删除一个或多个列,得到新的DF df1.drop("mgr") df1.drop("empno", "mgr") // withColumn,修改列值 val df2 = df1.withColumn("sal", $"sal"+1000) df2.show // withColumnRenamed,更改列名 df1.withColumnRenamed("sal", "newsal") // 备注:drop、withColumn、withColumnRenamed返回的是DF // cast,类型转换 df1.selectExpr("cast(empno as string)").printSchema import org.apache.spark.sql.types._ df1.select('empno.cast(StringType)).printSchema // when … otherwise 相当于case… when val df4 = df.select(col("*"), when(col("gender") === "M","Male") .when(col("gender") === "F","Female") .otherwise("Unknown").alias("new_gender")) // 等价于 val df4 = df.select(col("*"), expr("case when gender = 'M' then 'Male' " + "when gender = 'F' then 'Female' " + "else 'Unknown' end").alias("new_gender")) -
where相关 where == filter
// where操作 df1.filter("sal>1000").show df1.filter("sal>1000 and job=='MANAGER'").show // filter操作 df1.where("sal>1000").show df1.where("sal>1000 and job=='MANAGER'").show -
groupBy相关 groupBy、agg、max、min、avg、sum、count(后面5个为内置函数)
// groupBy、max、min、mean、sum、count(与df1.count不同) df1.groupBy("Job").sum("sal").show df1.groupBy("Job").max("sal").show df1.groupBy("Job").min("sal").show df1.groupBy("Job").avg("sal").show df1.groupBy("Job").count.show // 类似having子句 df1.groupBy("Job").avg("sal").where("avg(sal) > 2000").show df1.groupBy("Job").avg("sal").where($"avg(sal)" > 2000).show // agg df1.groupBy("Job").agg("sal"->"max", "sal"->"min", "sal"->"avg", "sal"->"sum", "sal"->"count").show df1.groupBy("deptno").agg("sal"->"max", "sal"->"min", "sal"->"avg", "sal"->"sum", "sal"->"count").show // 这种方式更好理解 df1.groupBy("Job").agg(max("sal"), min("sal"), avg("sal"),sum("sal"), count("sal")).show // 给列取别名 df1.groupBy("Job").agg(max("sal"), min("sal"), avg("sal"), sum("sal"),count("sal")).withColumnRenamed("min(sal)", "min1").show // 给列取别名,最简便 df1.groupBy("Job").agg(max("sal").as("max1"), min("sal").as("min2"), avg("sal").as("avg3"), sum("sal").as("sum4"), count("sal").as("count5")).show -
orderBy相关 orderBy == sort
// orderBy df1.orderBy("sal").show df1.orderBy($"sal").show df1.orderBy($"sal".asc).show // 降序 df1.orderBy(-$"sal").show df1.orderBy(-'sal).show df1.orderBy($"sal".desc).show df1.orderBy(-'deptno, -'sal).show df1.orderBy('sal).show df1.orderBy(col("sal")).show df1.orderBy(df1("sal")).show // sort,以下语句等价 df1.sort("sal").show df1.sort($"sal").show df1.sort($"sal".asc).show df1.sort('sal).show df1.sort(col("sal")).show df1.sort(df1("sal")).show -
join相关
-
集合相关 union==unionAll(过期)、intersect、except
// union、unionAll、intersect、except。集合的交、并、差 val ds3 = ds1.select("name") val ds4 = ds2.select("sname") // union 求并集,不去重 ds3.union(ds4).show // unionAll、union 等价;unionAll过期方法,不建议使用 ds3.unionAll(ds4).show // intersect 求交 ds3.intersect(ds4).show // except 求差 ds3.except(ds4).show -
空值处理 na.fill、na.drop(NaN 和null)
// NaN (Not a Number) math.sqrt(-1.0) math.sqrt(-1.0).isNaN() df1.show // 删除所有列的空值和NaN df1.na.drop.show // 删除某列的空值和NaN df1.na.drop(Array("mgr")).show // 对全部列填充;对指定单列填充;对指定多列填充 df1.na.fill(1000).show df1.na.fill(1000, Array("comm")).show df1.na.fill(Map("mgr"->2000, "comm"->1000)).show // 对指定的值进行替换 df1.na.replace("comm" :: "deptno" :: Nil, Map(0 -> 100, 10 -> 100)).show // 查询空值列或非空值列。isNull、isNotNull为内置函数 df1.filter("comm is null").show df1.filter($"comm".isNull).show df1.filter(col("comm").isNull).show df1.filter("comm is not null").show df1.filter(col("comm").isNotNull).show -
窗口函数 一般情况下窗口函数不用 DSL 处理,直接用SQL更方便 参考源码Window.scala、WindowSpec.scala(主要)
import org.apache.spark.sql.expressions.Window val w1 = Window.partitionBy("cookieid").orderBy("createtime") val w2 = Window.partitionBy("cookieid").orderBy("pv") val w3 = w1.rowsBetween(Window.unboundedPreceding,Window.currentRow) val w4 = w1.rowsBetween(-1, 1) // 聚组函数【用分析函数的数据集】 df.select($"cookieid", $"pv", sum("pv").over(w1).alias("pv1")).show df.select($"cookieid", $"pv", sum("pv").over(w3).alias("pv1")).show df.select($"cookieid", $"pv", sum("pv").over(w4).as("pv1")).show // 排名 df.select($"cookieid", $"pv", rank().over(w2).alias("rank")).show df.select($"cookieid", $"pv", dense_rank().over(w2).alias("denserank")).show df.select($"cookieid", $"pv", row_number().over(w2).alias("rownumber")).show // lag、lead df.select($"cookieid", $"pv", lag("pv", 2).over(w2).alias("rownumber")).show df.select($"cookieid", $"pv", lag("pv", -2).over(w2).alias("rownumber")).show -
内建函数 http://spark.apache.org/docs/latest/api/sql/index.html
-
-
SQL语句 总体而言:SparkSQL与HQL兼容;与HQL相比,SparkSQL更简洁。
createTempView、createOrReplaceTempView、spark.sql(“SQL”)import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} case class Info(id: String, tags: String) object SparkSQLDemo { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("Spark SQL basic example") .config("options", "what ever") .master("local[*]") .getOrCreate() val sc = spark.sparkContext sc.setLogLevel("WARN") //Implicit methods available in Scala for converting // * common Scala objects into `DataFrame`s. import spark.implicits._ val arr = Array("1 1,2,3", "2 2,3", "3 1,2") val rdd = spark.sparkContext.makeRDD(arr).map{line => val fields = line.split("\\s+") Info(fields(0), fields(1)) } val ds: Dataset[Info] = rdd.toDS() ds.createOrReplaceTempView("t1") spark.sql( """ |select id, tag | from t1 | lateral view explode(split(tags, ",")) t2 as tag |""".stripMargin).show spark.sql( """ |select id, explode(split(tags, ",")) tags | from t1 |""".stripMargin).show spark.stop() } } -
输入与输出 SparkSQL内建支持的数据源包括:Parquet、JSON、CSV、Avro、Images、 BinaryFiles(Spark 3.0)。其中Parquet是默认的数据源。
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession} object InputOutputDemo { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("Spark SQL basic example") .config("options", "what ever") .master("local[*]") .getOrCreate() val sc = spark.sparkContext sc.setLogLevel("WARN") //Implicit methods available in Scala for converting // * common Scala objects into `DataFrame`s. import spark.implicits._ val df1 = spark.read.format("parquet").load("data/users.parquet") df1.show() df1.printSchema() spark.sql( """ |create or replace temporary view users |using parquet |options (path "data/sqlParquet") |""".stripMargin) spark.sql("select * from users").show // 写入磁盘 spark.sql("select * from users").write.parquet("data/sqlParquet") // CSV data source does not support array<int> data type spark.sql("select * from users").write.csv("data/csvUsers") spark.sql("select * from users").write.json("data/jsonUsers") df1.write.parquet("data/parquet") // 和上面等价 df1.write.format("parquet") .mode("overwrite") .option("compression", "snappy") .save("data/parquet") // JSON println("*" * 50) val df2 = spark.read.format("json").load("data/emp.json") df2.show() df2.printSchema() spark.sql( """ |create or replace temporary view emp |using json |options(path "data/emp.json") |""".stripMargin) spark.sql("select * from emp").show df2.write .format("json") .mode("overwrite") .save("data/json") println("*" * 20 + "csv" + "*" * 20) val df3 = spark.read .format("csv") .option("header", true) .option("inferschema", true) .load("data/people1.csv") df3.printSchema() df3.show() spark.sql( """ |create or replace temporary view people |using csv |options(path "data/people2.csv", | header "true", | delimiter ";", | inferschema "true") |""".stripMargin) spark.sql("select * from people").show df3.write .format("csv") .mode("overwrite") .option("delimiter", "\t") .save("data/csv") println("*" * 20 + "jdbc" + "*" * 20) val jdbcDF = spark.read .format("jdbc") .option("url", "jdbc:mysql://localhost:3306/test?useSSL=false&useUnicode=true") .option("driver", "com.mysql.jdbc.Driver") .option("dbtable", "student") .option("user", "root") .option("password", "h@ckingwithjava11") .load() jdbcDF.show() jdbcDF.write .format("jdbc") .option("url", "jdbc:mysql://localhost:3306/test?useSSL=false&useUnicode=true") .option("driver", "com.mysql.jdbc.Driver") .option("dbtable", "student_bak") .option("user", "root") .option("password", "h@ckingwithjava11") .mode(SaveMode.Append) .save() spark.stop() } }JDBC备注:如果有中文注意表的字符集,否则会有乱码
- SaveMode.ErrorIfExists(默认)。若表存在,则会直接报异常,数据不能存入 数据库
- SaveMode.Append。若表存在,则追加在该表中;若该表不存在,则会先创建 表,再插入数据
- SaveMode.Overwrite。先将已有的表及其数据全都删除,再重新创建该表,最 后插入新的数据
- SaveMode.Ignore。若表不存在,则创建表并存入数据;若表存在,直接跳过数 据的存储,不会报错
-
UDF & UDAF UDF(User Defined Function),自定义函数。函数的输入、输出都是一条数据记录, 类似于Spark SQL中普通的数学或字符串函数。实现上看就是普通的Scala函数;
UDAF(User Defined Aggregation Funcation),用户自定义聚合函数。函数本身 作用于数据集合,能够在聚合操作的基础上进行自定义操作(多条数据输入,一条数 据输出);类似于在group by之后使用的sum、avg等函数;用Scala编写的UDF与普通的Scala函数几乎没有任何区别,唯一需要多执行的一个步 骤是要在SQLContext注册它。
- UDF
import org.apache.spark.sql.expressions.UserDefinedFunction import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} // sql 操作常用函数集,比如sum,max,avg import org.apache.spark.sql.functions._ case class Person(name: String, age: Int, height: Int) object UDF { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("Spark SQL basic example") .config("options", "what ever") .master("local[*]") .getOrCreate() val sc = spark.sparkContext sc.setLogLevel("WARN") //Implicit methods available in Scala for converting // * common Scala objects into `DataFrame`s. import spark.implicits._ val data = List(("scala", "author1"), ("spark", "author2"),("hadoop", "author3"), ("hive", "author4"), ("strom", "author5"), ("kafka", "author6")) val df = spark.createDataFrame(data).toDF("title", "author") df.createOrReplaceTempView("books") // 定义函数并注册 def len(bookTitle: String):Int = bookTitle.length spark.udf.register("len", len _) // UDF可以在select语句、where语句等多处使用 spark.sql("select title, author, len(title) as tilLen from books").show spark.sql("select title, author, len(title) as tilLen from books where len(title) > 5").show // UDF可以在DataFrame、Dataset的API中使用 println("*"*40) df.filter("len(title)>5").show() // 如果要在DSL语法中使用$符号包裹字符串表示一个Column,需要用udf方法 来接收函数。这种函数无需注册 println("*"*40) val len2: UserDefinedFunction = udf(len _) df.select($"title", $"author", len2($"author").as("titLen")).show() df.where(len2($"title")>5).show // 不使用UDF println("*"*40) val result: Dataset[(String, String, Int)] = df.map { case Row(title: String, author: String) => (title, author, len(title)) } result.show() spark.stop() } } -
UDAF 普通的UDF不支持数据的聚合运算。如当要对销售数据执行年度同比计算,就需要对 当年和上一年的销量分别求和,然后再利用公式进行计算。此时需要使用UDAF, Spark为所有的UDAF定义了一个父类 UserDefinedAggregateFunction 。要继承这个类
-
类型不安全的UDAF
class TypeUnSafeUDAF extends UserDefinedAggregateFunction { /** * A `StructType` represents data types of input arguments of this aggregate function. */ override def inputSchema: StructType = new StructType() .add("sales", DoubleType) .add("saleDate", StringType) /** * A `StructType` represents data types of values in the aggregation buffer. */ def bufferSchema: StructType = new StructType() .add("2019Sum", DoubleType) .add("2020Sum", DoubleType) /** * The `DataType` of the returned value of this [[UserDefinedAggregateFunction]]. */ def dataType: DataType = DoubleType /** * Returns true if this function is deterministic, i.e. given the same input, * always return the same output. */ def deterministic: Boolean = true /** * Initializes the given aggregation buffer, i.e. the zero value of the aggregation buffer. */ def initialize(buffer: MutableAggregationBuffer): Unit = { buffer.update(0, 0.0) buffer.update(1, 0.0) } /** * Updates the given aggregation buffer `buffer` with new input data from `input`. * * This is called once per input row. */ def update(buffer: MutableAggregationBuffer, input: Row): Unit = { val year = input.getAs[String](1).take(4) year match { case "2019" => buffer.update(0, buffer(0).asInstanceOf[Double] + input.getAs[Double](0)) case "2020" => buffer.update(1, buffer(1).asInstanceOf[Double] + input.getAs[Double](0)) case _ => println(s"Input $input out of bounds") } } /** * Merges two aggregation buffers and stores the updated buffer values back to `buffer1`. * * This is called when we merge two partially aggregated data together. */ def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = { buffer1.update(0, buffer1(0).asInstanceOf[Double]+buffer2.getAs[Double](0)) buffer1.update(1, buffer1(1).asInstanceOf[Double]+buffer2.getAs[Double](1)) } /** * Calculates the final result of this [[UserDefinedAggregateFunction]] based on the given * aggregation buffer. */ def evaluate(buffer: Row): Double = { (buffer.getAs[Double](1) - buffer.getAs[Double](0))/buffer.getAs[Double](0) } } object TypeUnSafeUDAF { def main(args: Array[String]): Unit = { Logger.getLogger("org").setLevel(Level.WARN) val spark = SparkSession .builder() .appName("Spark SQL basic example") .config("options", "what ever") .master("local[*]") .getOrCreate() //Implicit methods available in Scala for converting // * common Scala objects into `DataFrame`s. import spark.implicits._ val sales = Seq( (1, "Widget Co", 1000.00, 0.00, "AZ", "2019-01-02"), (2, "Acme Widgets", 2000.00, 500.00, "CA", "2019-02-01"), (3, "Widgetry", 1000.00, 200.00, "CA", "2020-01-11"), (4, "Widgets R Us", 2000.00, 0.0, "CA", "2020-02-19"), (5, "Ye Olde Widgete", 3000.00, 0.0, "MA", "2020-02-28")) val salesDF = spark.createDataFrame(sales).toDF("id", "name", "sales", "discount", "state", "saleDate") salesDF.createTempView("sales") salesDF.show() val userFunc = new TypeUnSafeUDAF spark.udf.register("userFunc", userFunc) spark.sql("select userFunc(sales, saleDate) from sales").show salesDF.select(userFunc($"sales",$"saleDate")).show() spark.stop() } } -
类型安全的UDAF
import org.apache.log4j.{Level, Logger} import org.apache.spark.sql.{Column, DataFrame, Dataset, Encoder, Encoders, Row, SparkSession, TypedColumn} import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction} import org.apache.spark.sql.types._ case class Sales(id: Int, name: String, sales: Double, discount: Double, state: String, saleDate: String) case class SalesBuffer(var sale2019: Double, var sale2020: Double) class TypeSafeUDAF extends Aggregator[Sales, SalesBuffer, Double] { /** * A zero value for this aggregation. Should satisfy the property that any b + zero = b. */ override def zero: SalesBuffer = SalesBuffer(0, 0) /** * Combine two values to produce a new value. For performance, the function may modify `b` and * return it instead of constructing new object for b. */ override def reduce(b: SalesBuffer, a: Sales): SalesBuffer = { val year = a.saleDate.take(4) year match { case "2019" => b.sale2019 += a.sales case "2020" => b.sale2020 += a.sales case _ => println("error") } b } /** * Merge two intermediate values. */ override def merge(b1: SalesBuffer, b2: SalesBuffer): SalesBuffer = { SalesBuffer(b1.sale2019+b2.sale2019, b2.sale2020+b2.sale2020) } /** * Transform the output of the reduction. */ override def finish(reduction: SalesBuffer): Double = (reduction.sale2020-reduction.sale2019)/reduction.sale2019 /** * Specifies the `Encoder` for the intermediate value type. */ override def bufferEncoder: Encoder[SalesBuffer] = Encoders.product /** * Specifies the `Encoder` for the final output value type. */ override def outputEncoder: Encoder[Double] = Encoders.scalaDouble } object TypeSafeUDAF { def main(args: Array[String]): Unit = { Logger.getLogger("org").setLevel(Level.WARN) val spark = SparkSession .builder() .appName("Spark SQL basic example") .config("options", "what ever") .master("local[*]") .getOrCreate() //Implicit methods available in Scala for converting // * common Scala objects into `DataFrame`s. import spark.implicits._ val sales = Seq( Sales(1, "Widget Co", 1000.00, 0.00, "AZ", "2019-01-02"), Sales(2, "Acme Widgets", 2000.00, 500.00, "CA", "2019-02-01"), Sales(3, "Widgetry", 1000.00, 200.00, "CA", "2020-01-11"), Sales(4, "Widgets R Us", 2000.00, 0.0, "CA", "2020-02-19"), Sales(5, "Ye Olde Widgete", 3000.00, 0.0, "MA", "2020-02-28")) val salesDF: Dataset[Sales] = spark.createDataset(sales) salesDF.show() val column: TypedColumn[Sales, Double] = new TypeSafeUDAF().toColumn.name("rate") salesDF.select(column).show() spark.stop() } }
-
- UDF
-
访问Hive
- 在 pom 文件中增加依赖:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>${spark.version}</version> </dependency> - 在 resources中增加hive-site.xml文件
<configuration> <property> <name>hive.metastore.uris</name> <value>thrift://centos7-3:9083</value> </property> </configuration>备注:最好使用 metastore service 连接Hive;使用直连 metastore 的方式时, SparkSQL程序会修改 Hive 的版本信息;
- 示例代码
import org.apache.spark.sql.{SaveMode, SparkSession} import org.apache.spark.sql.functions._ object HiveDemo { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("HiveDemo") .master("local[*]") .enableHiveSupport() // 设为true时,Spark使用与Hive相同的约定来编写Parquet数据 .config("spark.sql.parquet.writeLegacyFormat", true) .getOrCreate() spark.sparkContext.setLogLevel("WARN") import spark.implicits._ // SQL的方式 spark.sql("show databases").show spark.sql("select * from ods.ods_trade_product_info").show // 链接hive的table,然后用DSL语句 val product_info = spark.table("ods.ods_trade_product_info") println(product_info.count()) product_info.show(5) product_info.filter("price > 50").show product_info.select(max($"price")).show product_info.write.mode(SaveMode.Append).saveAsTable("ods.ods_trade_product_info_bak") spark.table("ods.ods_trade_product_info_bak").show() spark.stop() } }
- 在 pom 文件中增加依赖:
Spark SQL原理
- SparkSQL中的join
数据分析中将两个数据集进行 Join 操作是很常见的场景。在 Spark 的物理计划阶 段,Spark 的 Join Selection 类会根据 Join hints 策略、Join 表的大小、 Join 是等值 Join 还是不等值以及参与 Join 的 key 是否可以排序等条件来选择最终的 Join 策略, 最后 Spark 会利用选择好的 Join 策略执行最终的计算。当前 Spark 一共支持五种 Join 策略:
- Broadcast hash join (BHJ)
- Shuffle hash join(SHJ)
- Shuffle sort merge join (SMJ)
- Shuffle-and-replicate nested loop join,又称笛卡尔积(Cartesian product join)
- Broadcast nested loop join (BNLJ)
其中 BHJ 和 SMJ 这两种 Join 策略是我们运行 Spark 作业最常见的。JoinSelection 会 先根据 Join 的 Key 为等值 Join 来选择 Broadcast hash join、Shuffle hash join 以 及 Shuffle sort merge join 中的一个;如果 Join 的 Key 为不等值 Join 或者没有指定 Join 条件,则会选择 Broadcast nested loop join 或 Shuffle-and-replicate nested loop join。
不同的 Join 策略在执行上效率差别很大,了解每种 Join 策略的执行过程和适用条件 是很有必要的。- Broadcast Hash Join
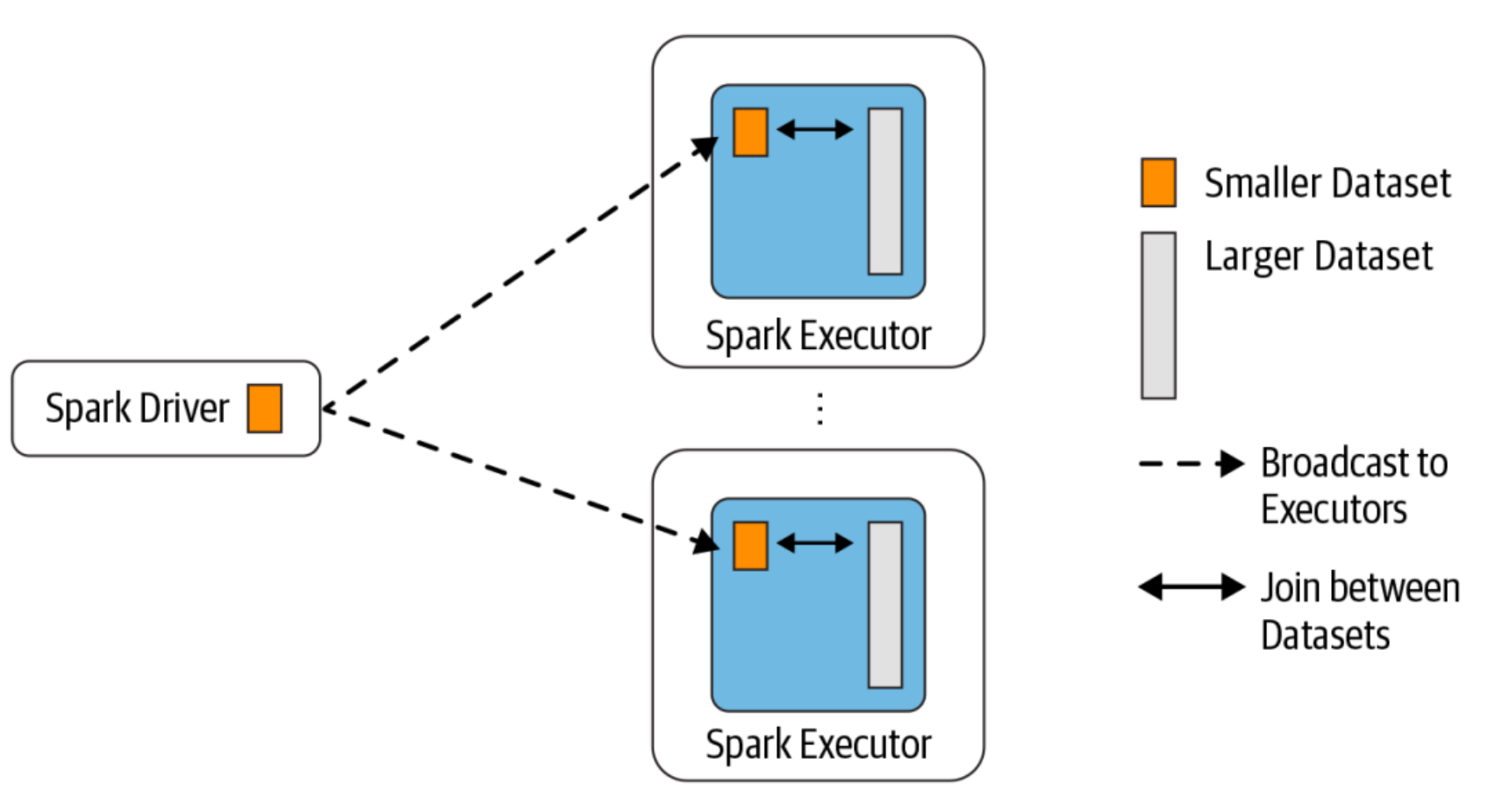 Broadcast Hash Join 的实现是将小表的数据广播到 Spark 所有的 Executor 端,这
Broadcast Hash Join 的实现是将小表的数据广播到 Spark 所有的 Executor 端,这
个广播过程和我们自己去广播数据没什么区别:- 利用 collect 算子将小表的数据从 Executor 端拉到 Driver 端
- 在 Driver 端调用 sparkContext.broadcast 广播到所有 Executor 端
- 在 Executor 端使用广播的数据与大表进行 Join 操作(实际上是执行map操作)
这种 Join 策略避免了 Shuffle 操作。一般而言,Broadcast Hash Join 会比其他 Join 策略执行的要快。
使用这种 Join 策略必须满足以下条件:
- 小表的数据必须很小,可以通过 spark.sql.autoBroadcastJoinThreshold 参数 来配置,默认是 10MB
- 如果内存比较大,可以将阈值适当加大
- 将 spark.sql.autoBroadcastJoinThreshold 参数设置为 -1,可以关闭这种连接 方式
- 只能用于等值 Join,不要求参与 Join 的 keys 可排序
-
Shuffle Hash Join
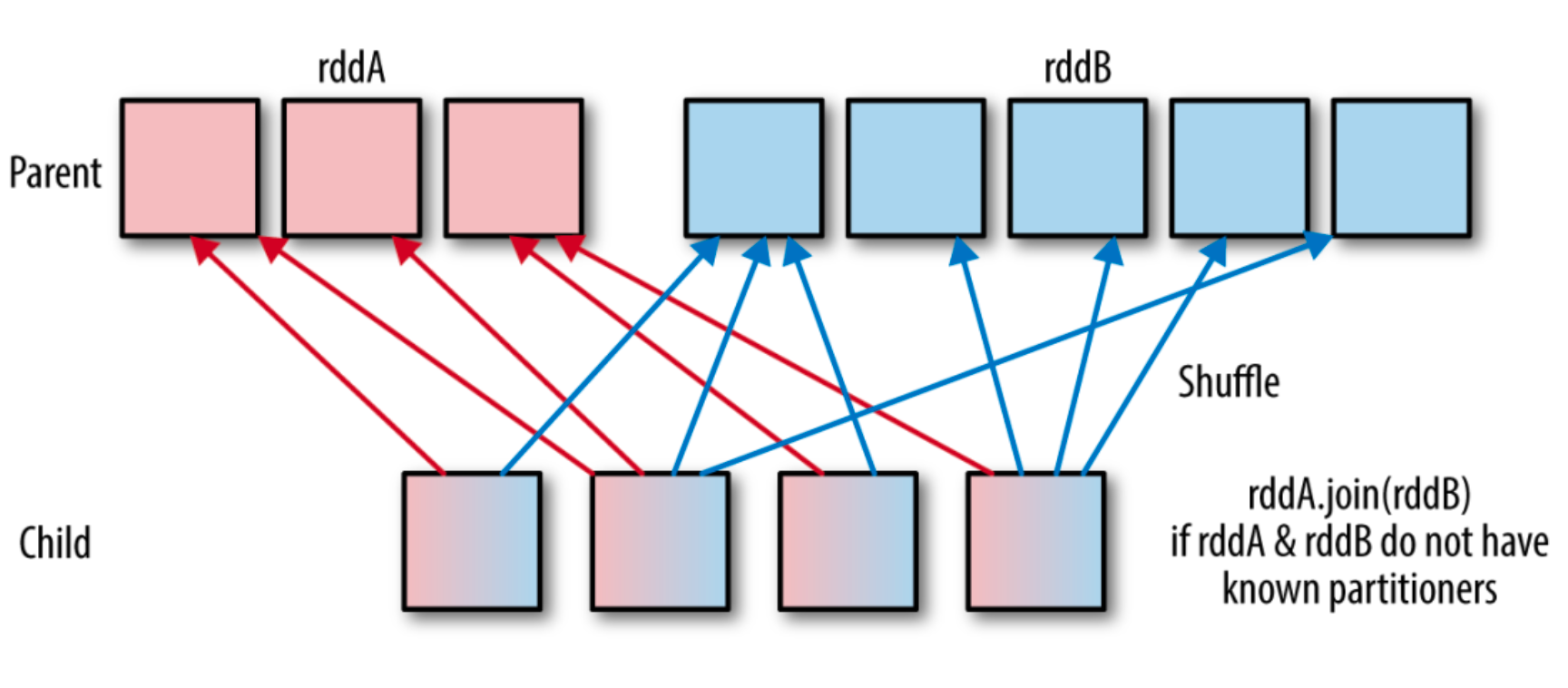 当表中的数据比较大,又不适合使用广播,这个时候就可以考虑使用 Shuffle Hash Join。
当表中的数据比较大,又不适合使用广播,这个时候就可以考虑使用 Shuffle Hash Join。
Shuffle Hash Join 同样是在大表和小表进行 Join 的时候选择的一种策略。它的计算 思想是:把大表和小表按照相同的分区算法和分区数进行分区(根据参与 Join 的 keys 进行分区),这样就保证了 hash 值一样的数据都分发到同一个分区中,然后 在同一个 Executor 中两张表 hash 值一样的分区就可以在本地进行 hash Join 了。
在进行 Join 之前,还会对小表的分区构建 Hash Map。Shuffle hash join 利用了分 治思想,把大问题拆解成小问题去解决。要启用 Shuffle Hash Join 必须满足以下条件:
- 仅支持等值 Join,不要求参与 Join 的 Keys 可排序
- spark.sql.join.preferSortMergeJoin 参数必须设置为 false,参数是从 Spark 2.0.0 版本引入的,默认值为 true,也就是默认情况下选择 Sort Merge Join
- 小表的大小(plan.stats.sizeInBytes)必须小于 spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions(默认值 200)
- 而且小表大小(stats.sizeInBytes)的三倍必须小于等于大表的大小 (stats.sizeInBytes),也就是 a.stats.sizeInBytes * 3 < = b.stats.sizeInBytes
- Shuffle Sort Merge Join
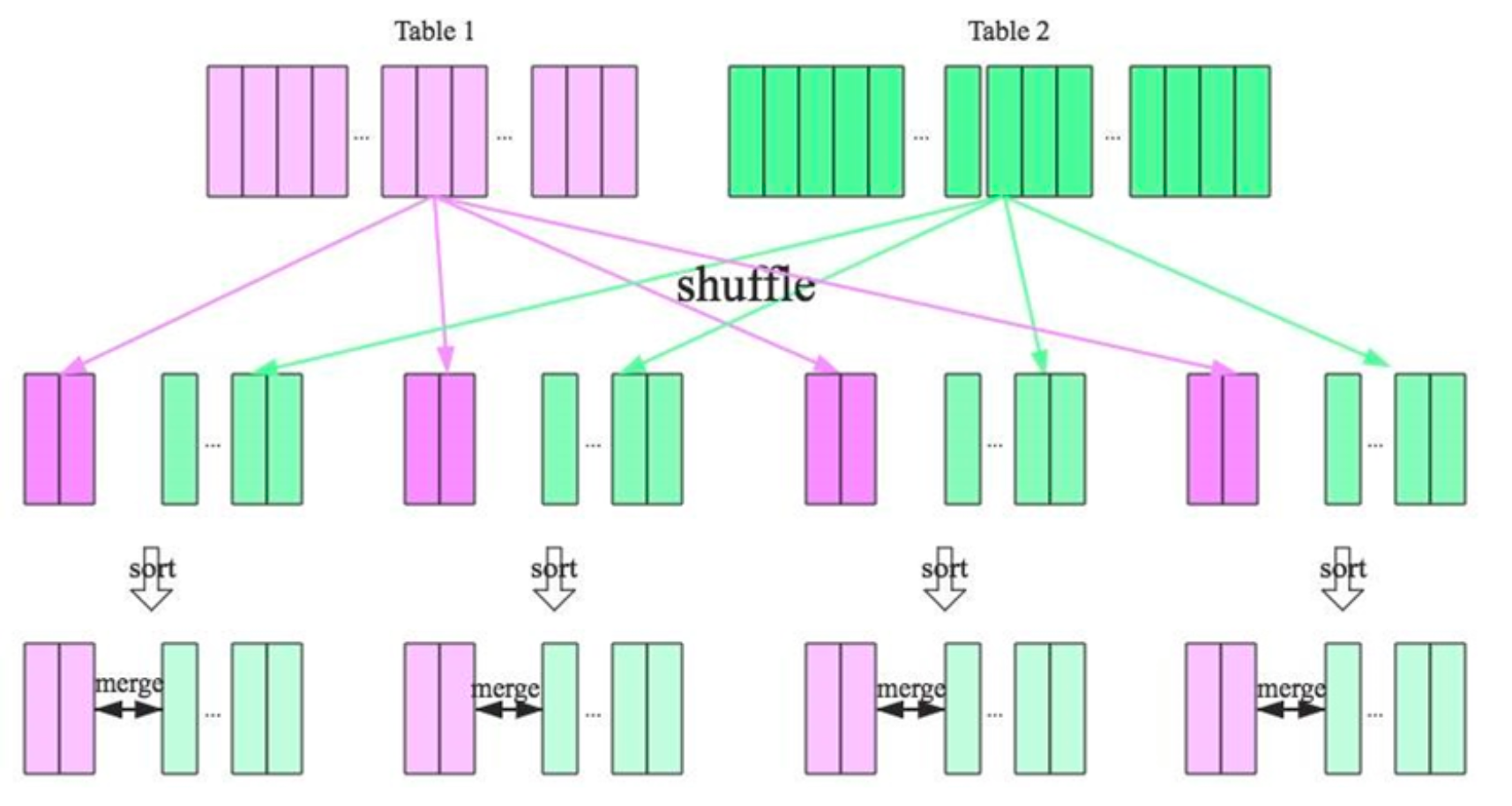 前面两种 Join 策略对表的大小都有条件的,如果参与 Join 的表都很大,这时候就得
前面两种 Join 策略对表的大小都有条件的,如果参与 Join 的表都很大,这时候就得
考虑用 Shuffle Sort Merge Join 了。 Shuffle Sort Merge Join 的实现思想:- 将两张表按照 join key 进行shuffle,保证join key值相同的记录会被分在相应的分区
- 对每个分区内的数据进行排序
- 排序后再对相应的分区内的记录进行连接
无论分区有多大,Sort Merge Join都不用把一侧的数据全部加载到内存中,而是即 用即丢;因为两个序列都有序。从头遍历,碰到key相同的就输出,如果不同,左边 小就继续取左边,反之取右边。从而大大提高了大数据量下sql join的稳定性。
要启用 Shuffle Sort Merge Join 必须满足以下条件:
- 仅支持等值 Join,并且要求参与 Join 的 Keys 可排序
-
Cartesian product join 如果 Spark 中两张参与 Join 的表没指定连接条件,那么会产生 Cartesian product join,这个 Join 得到的结果其实就是两张表行数的乘积。
- Broadcast nested loop join
可以把 Broadcast nested loop join 的执行看做下面的计算:
for record_1 in relation_1: for record_2 in relation_2: # join condition is executed可以看出 Broadcast nested loop join 在某些情况会对某张表重复扫描多次,效率非 常低下。从名字可以看出,这种 join 会根据相关条件对小表进行广播,以减少表的 扫描次数。
Broadcast nested loop join 支持等值和不等值 Join,支持所有的 Join 类型。
- SQL解析过程
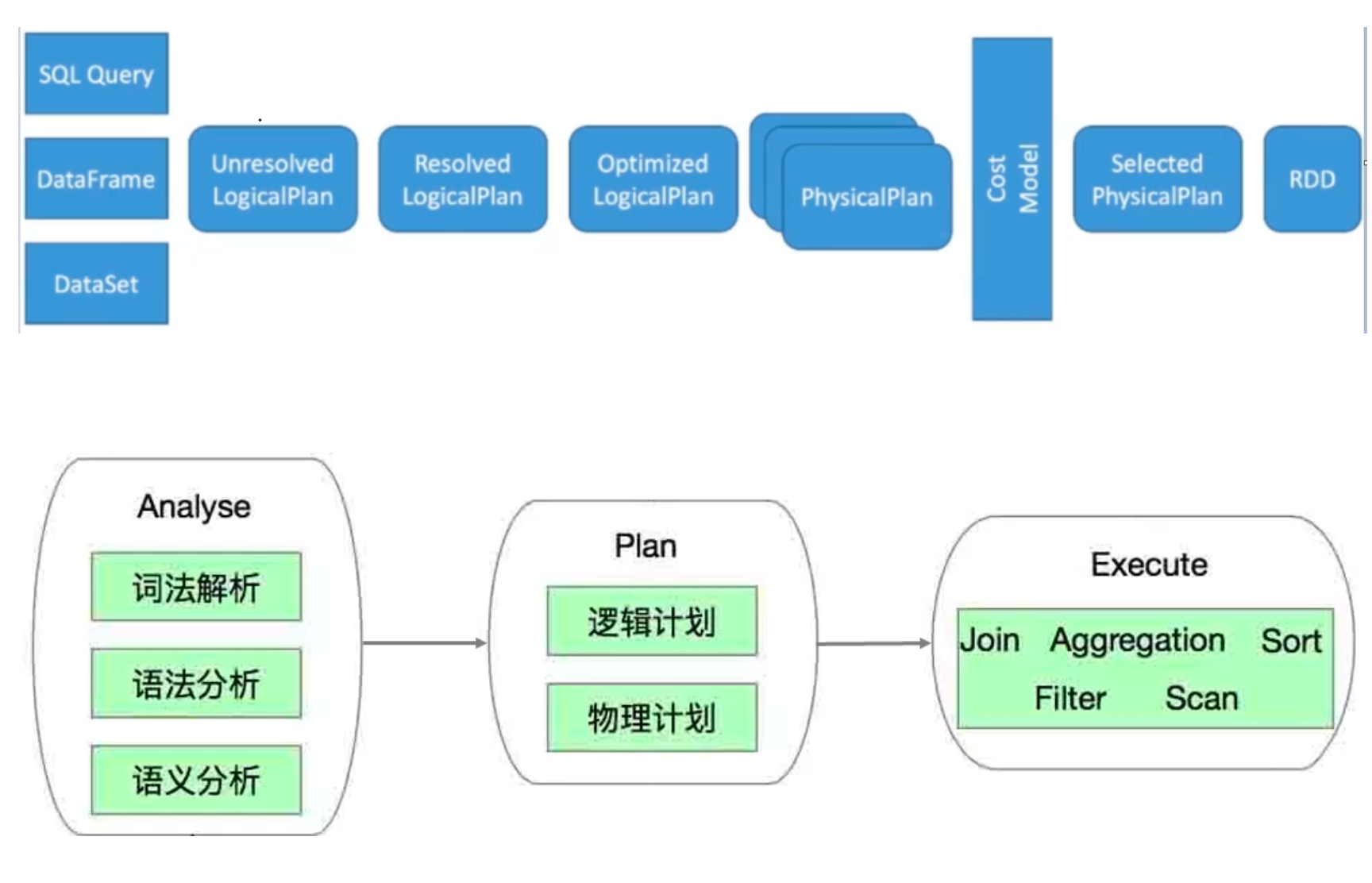 Spark SQL 可以说是 Spark 中的精华部分。原来基于 RDD 构建大数据计算任务,重 心在向 DataSet 转移,原来基于 RDD 写的代码也在迁移。使用 Spark SQL 编码好处 是非常大的,尤其是在性能方面,有很大提升。Spark SQL 中各种内嵌的性能优化比 写 RDD 遵守各种最佳实践更靠谱的,尤其对新手来说。如先 filter 操作再 map 操 作,Spark SQL 中会自动进行谓词下推;Spark SQL中会自动使用 broadcast join 来 广播小表,把 shuffle join 转化为 map join 等等。
Spark SQL 可以说是 Spark 中的精华部分。原来基于 RDD 构建大数据计算任务,重 心在向 DataSet 转移,原来基于 RDD 写的代码也在迁移。使用 Spark SQL 编码好处 是非常大的,尤其是在性能方面,有很大提升。Spark SQL 中各种内嵌的性能优化比 写 RDD 遵守各种最佳实践更靠谱的,尤其对新手来说。如先 filter 操作再 map 操 作,Spark SQL 中会自动进行谓词下推;Spark SQL中会自动使用 broadcast join 来 广播小表,把 shuffle join 转化为 map join 等等。
Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、 执行。Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule)对Tree进行绑 定、优化等处理过程。Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分构成:- Core: 负责处理数据的输入和输出,如获取数据,查询结果输出成DataFrame等
- Catalyst: 负责处理整个查询过程,包括解析、绑定、优化等
- Hive: 负责对Hive数据进行处理
- Hive-ThriftServer: 主要用于对Hive的访问
Spark SQL的代码复杂度是问题的本质复杂度带来的,Spark SQL中的 Catalyst 框架 大部分逻辑是在一个 Tree 类型的数据结构上做各种操作
-
queryExecution
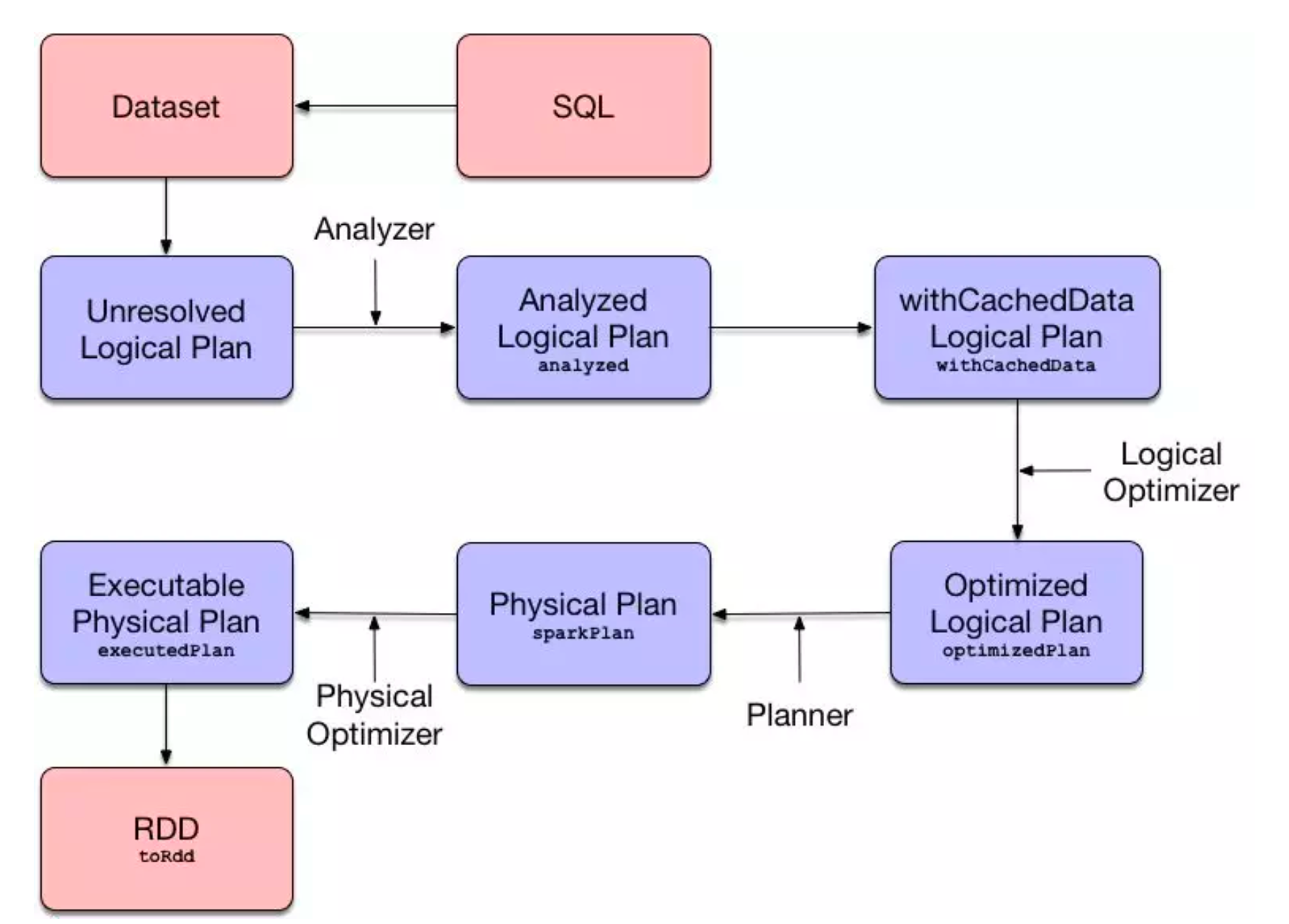 queryExecution 就是整个执行计划的执行引擎,里面有执行过程中各个中间过程变 量,整个执行流程如上
queryExecution 就是整个执行计划的执行引擎,里面有执行过程中各个中间过程变 量,整个执行流程如上可以使用
df.queryExecution来查看执行计划== Parsed Logical Plan == 'Aggregate ['name], [unresolvedalias('sum('v), None), 'name] +- 'SubqueryAlias `tmp` +- 'Project ['stu.id, ((100 + 10) + 'score.score) AS v#26, 'name] +- 'Filter (('stu.id = 'score.id) && ('stu.age >= 11)) +- 'Join Inner :- 'UnresolvedRelation `stu` +- 'UnresolvedRelation `score` == Analyzed Logical Plan == sum(v): bigint, name: string Aggregate [name#8], [sum(cast(v#26 as bigint)) AS sum(v)#28L, name#8] +- SubqueryAlias `tmp` +- Project [id#7, ((100 + 10) + score#22) AS v#26, name#8] +- Filter ((id#7 = id#20) && (age#9 >= 11)) +- Join Inner :- SubqueryAlias `stu` : +- Project [_1#3 AS id#7, _2#4 AS name#8, _3#5 AS age#9] : +- LocalRelation [_1#3, _2#4, _3#5] +- SubqueryAlias `score` +- Project [_1#16 AS id#20, _2#17 AS subject#21, _3#18 AS score#22] +- LocalRelation [_1#16, _2#17, _3#18] == Optimized Logical Plan == Aggregate [name#8], [sum(cast(v#26 as bigint)) AS sum(v)#28L, name#8] +- Project [(110 + score#22) AS v#26, name#8] +- Join Inner, (id#7 = id#20) :- LocalRelation [id#7, name#8] +- LocalRelation [id#20, score#22] == Physical Plan == *(2) HashAggregate(keys=[name#8], functions=[sum(cast(v#26 as bigint))], output=[sum(v)#28L, name#8]) +- Exchange hashpartitioning(name#8, 200) +- *(1) HashAggregate(keys=[name#8], functions=[partial_sum(cast(v#26 as bigint))], output=[name#8, sum#32L]) +- *(1) Project [(110 + score#22) AS v#26, name#8] +- *(1) BroadcastHashJoin [id#7], [id#20], Inner, BuildLeft :- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint))) : +- LocalTableScan [id#7, name#8] +- LocalTableScan [id#20, score#22]