大数据开发高频面试题
- 1. 给定a,b两个文件,各存放50亿个url,每个url长度为1-255字节,内存限制是4g,让你找出a,b文件共同的url,说明思路和执行方法。
- 2. 二叉树前序、中序、后序遍历方式(递归以及非递归)。
- 3. 求数组所有可能的子数组?
- 4. 给定一个数和一个有序数组,求有序数组的两个数的和满足这个数?(已知这两数存在)
- 5. string、stringbulider、stringbuffer的区别
- 6. ArrayList、LinkedList、Vector区别
- 7. HashMap 时间复杂度?
- 8. 求一个数组的第二大值?
- 9. 有一个1G大小的文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词。
- 10. 现有海量日志数据保存在一个超级大的文件中,该文件无法直接读入内存,要求从中提取某天出访问百度次数最多的那个IP。
- 11. 手写TopN算法,使用spark,scala实现。
- 12. 如何使用redis,或者zookeeper实现分布式锁
- 13. 数组和链表的区别,能否用伪代码实现链表。
- 14. 有了解过哪些机器学习的算法?
- *15. 协同过滤算法的底层实现是什么?
- 16. 快速排序、归并排序、冒泡排序、选择排序(复杂度分别是多少)
- 17. spark-submit几种提交模式的区别是什么?
- 18. spark streming在实时处理时会发生什么故障,如何停止,解决。
- 19. spark工作机制。
- 20. Kafka和sparkStreaming的整合,手动提交的offset调用了什么方法?
- 21. Spark Streaming如何保证数据的防丢失
- 22. spark的checkpoint机制
1. 给定a,b两个文件,各存放50亿个url,每个url长度为1-255字节,内存限制是4g,让你找出a,b文件共同的url,说明思路和执行方法。
思路分析:数据量很大的join,内存有限,设计一个程序解决这个问题 借鉴MapReduce的设计 每个文件的大小为5Gx64=320G,不能一次加载到内存中进行比对
- hash(url)%100对数据分区,存成小文件,每个文件的大小大约300M,这个就可以得到a1,a2,,…a1000; b1,b2,,…b1000. b1中和a相同的url只能在a1中,这样只需要比较俩俩比较1000对300M的文件,就可以求出最终的结果
- 把An加载到内存中,使用HashSet存储,然后掉用contain方法就可以找到Bn中是否有相同的url,有的话就存到结果集里边,有n个结果集的小文件
- 合并n个结果集的小文件,生成最终结果文件
进一步分析,如果允许一定的错误率,可以使用bloom filter来判断A中是否有B
1G = 1000M = 10001000K = 100010001000Byte=1000100010008Bit=80亿bit 4G 大概可以表示320亿bit,将A中的url使用bloom filter映射为这320亿个bit,然后逐个读取b中url检查是否存在,如果是,这url应该是共同url
2. 二叉树前序、中序、后序遍历方式(递归以及非递归)。
前序遍历:根节点,左节点,右节点
中序遍历:左节点,根节点,右节点
后序遍历:左节点,右节点,根节点
递归实现
public class BinaryTree {
int value;
BinaryTree left, right;
}
// 前序遍历
public static void preOrder(BinaryTree root) {
if (root == null) return;
System.out.print(root.value + "\t");
preOrder(root.left);
preOrder(root.right);
}
// 中序遍历
public static void middleOrder(BinaryTree root) {
if (root == null) return;
middleOrder(root.left);
System.out.print(root.value + "\t");
middleOrder(root.right);
}
// 后序遍历
public static void postOrder(BinaryTree root) {
if (root == null) return;
postOrder(root.left);
postOrder(root.right);
System.out.print(root.value + "\t");
}
非递归实现
public static void preOrder2(BinaryTree root) {
/**
* 对于任一结点P:
* 1)访问结点P,并将结点P入栈;
* 2)判断结点P的左孩子是否为空,若为空,则取栈顶结点并进行出栈操作,并将栈顶结点的右孩子置为当前的结点P,循环至1);若不为空,则将P的左孩子置为当前的结点P;
* 3)直到P为NULL并且栈为空,则遍历结束。
*/
Stack<BinaryTree> s = new Stack<>();
BinaryTree p = root;
while (p != null || !s.isEmpty()) {
while (p != null) {
System.out.print(p.value + "\t");
s.push(p);
p = p.left;
}
if (!s.isEmpty()) {
p = s.pop();
p = p.right;
}
}
}
public static void middleOrder2(BinaryTree root) {
/**
* 对于任一结点P:
* 1)访问结点P,并将结点P入栈;
* 2)判断结点P的左孩子是否为空,若不为空,则入栈操作,直到左孩子为空; 判断栈中是否有元素,有就取出并打印,把当前节点置为取出元素的右节点,循环至1);
* 3)直到P为NULL并且栈为空,则遍历结束。
*/
Stack<BinaryTree> s = new Stack<>();
BinaryTree p = root;
while (p != null || !s.isEmpty()) {
while (p != null) {
s.push(p);
p = p.left;
}
if (!s.isEmpty()) {
p = s.pop();
System.out.print(p.value + "\t");
p = p.right;
}
}
}
public static void postOrder2(BinaryTree root) {
/**
* 要保证根结点在左孩子和右孩子访问之后才能访问,因此对于任一结点P,先将其入栈。
* 如果P不存在左孩子和右孩子,则可以直接访问它;
* 或者P存在左孩子或者右孩子,但是其左孩子和右孩子都已被访问过了,
* 则同样可以直接访问该结点。
* 若非上述两种情况,则将P的右孩子和左孩子依次入栈,这样就保证了每次取栈顶元素
* 的时候,左孩子在右孩子前面被访问,左孩子和右孩子都在根结点前面被访问。
*/
Stack<BinaryTree> s = new Stack<>();
BinaryTree cur;
BinaryTree pre = null;
s.push(root);
while (!s.isEmpty()) {
cur = s.peek();
if ((cur.left==null && cur.right==null)
|| (pre!=null && (pre==cur.left||pre==cur.right))
) {
System.out.print(cur.value + "\t");
s.pop();
pre = cur;
}
else {
if (cur.right != null)
s.push(cur.right);
if (cur.left != null)
s.push(cur.left);
}
}
}
结合项目中使用
先序遍历:在第一次遍历到节点时就执行操作,一般只是想遍历执行操作(或输出结果)可选用先序遍历;
中序遍历:对于二分搜索树,中序遍历的操作顺序(或输出结果顺序)是符合从小到大(或从大到小)顺序的,故要遍历输出排序好的结果需要使用中序遍历
后序遍历:后续遍历的特点是执行操作时,肯定已经遍历过该节点的左右子节点,故适用于要进行破坏性操作的情况,比如删除所有节点
3. 求数组所有可能的子数组?
如果子数组是连续的从原来的数组中截取的片段:假设数组长度n,子数组的长度从1到n,每次改变子数组的开始或结尾就会生成一个新的数组,那么子数组的所有组合是等差数列 1…n 的和,(n+1)n/2
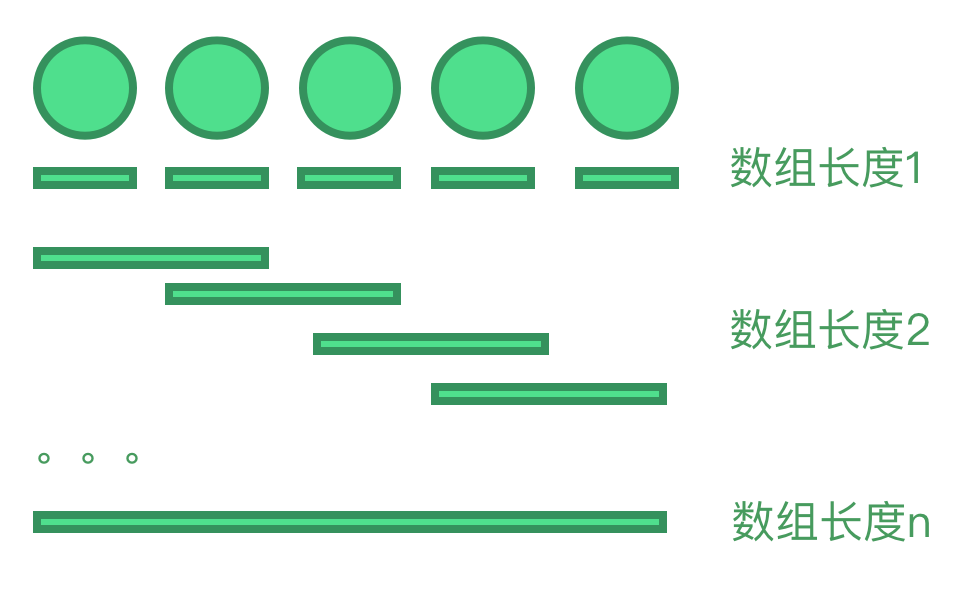
如果子数组不一定连续,只要是数组的子集即可:那就是另外一个故事了,可以用按位对应法
集合A=[a, b, c], 对于任意一个元素,在每个子集中,要么存在,要么不存在。可以用三位数0,1数字来表示数组中的元素是否在子集中,映射方式如下:
(1,1,1)->(a,b,c)
(1,1,0)->(a,b)
(1,0,1)->(a,c)
(1,0,0)->(a)
(0,1,1)->(b,c)
(0,1,0)->(b)
(0,0,1)->(c)
(0,0,0)->@(@表示空集)
故可以用一个整型数00…00~11…11和集合映射。假如数组长度为n,那么可能的子集有2n-1种,减掉的1是空集 结合项目中使用: 在程序中展现所有组合的可能性时,可以使用该算法。
4. 给定一个数和一个有序数组,求有序数组的两个数的和满足这个数?(已知这两数存在)
假设目标和target; 遍历数组,访问过的数据存在
HashSet中,每次遇到一个新的数e,查询一下HashSet中有没有target-e, 如果有就查到需要的结果,如果没有就把e加入HashSet中,继续遍历 另一种思路是,使用双指针,求数组首尾两数的和,如果是目标和,循环结束,如果小于目标和左边指针右移,如果大于目标和右边指针左移,直到找到目标和,或者左指针小于右指针,循环结束
5. string、stringbulider、stringbuffer的区别
- String 是不可变字符串;StringBuilder和StringBuffer都是可变字符串,API相似
- 运行速度: StringBuilder > StringBuffer > String
因为String在对值进行更改时重新创建一个新的对象,原来的对象被当作垃圾进行回收,所以是最慢的- 线程安全: StringBuilder是线程不安全的,StringBuffer是线程安全的。
一个StringBuffer对象被多个线程使用时,因为StringBuffer中很多方法带有synchronized关键字,所以可以保证线程是安全的,但是StringBuilder则没有该关键字。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,单线程的情况建议使用速度较快的StringBuidler
6. ArrayList、LinkedList、Vector区别
它们都是java中的长度可变数组,不过底层实现不一样;ArrayList、LinkedList都是线程不安全的
LinkedList底层是链表,使用的不是连续的存储空间,数据元素的增删复杂度都是O(1), 查询复杂度O(n), 另外,它还提供了List接口没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用;
ArrayList底层是不可变长数组,使用的是连续的存储空间,当数组长度不够时,需要扩容,需要开辟新的空间,并把原来的元素复杂到新的空间,所以数据元素的增删复杂度都是O(n), 按下标查询的复杂度O(1);
Vector是线程安全的,它的底层实现和ArrayList类似,不过很多方法都带有synchronized关键字,因为线程安全所以效率低,单线程时建议使用ArrayList
7. HashMap 时间复杂度?
增删数据的复杂度:O(1)
查询的复杂度:O(1)
理想情况下HashMap的时间复杂度为O(1), 最差的情况是O(n)
TreeMap的时间复杂度为O(logn)
因为对于内存来说,访问任何地址的时间是一样的,即时间极短,相当于可以同时访问到所有的地址。而在时间复杂度为O(1)时,需要很大的内存空间,所以必须要对内存和时间进行取舍
结合项目中使用:
非并发场景使用HashMap,并发场景可以使用HashTable,不过推荐使用ConcurrenthashMap(锁粒度更低、效率更高)
8. 求一个数组的第二大值?
排序算法的考察,有两种实现方式,下面是 leetcode1796. 字符串中第二大的数字 的实现
1.使用两个变量来记录最大和第二大值
static public int secondHighest(String s) {
// max 最大元素
// second 缓存max被替换的值
int max = -1;
int second = -1;
for (char c : s.toCharArray()) {
int num = c - '0';
if (num >= 0 && num <= 9) {
if (num > max) {
second = max;
max = num;
} else if (num!=max && num > second) {
second = num;
}
}
}
return second;
}
2.维护一个只有两个元素的最小堆 ,比较通用的方法,如果遇到第三大,第四大,只要改一个参数就够了
// 维护一个只有两个元素的最小堆
static public int secondHighest2(String s) {
PriorityQueue<Integer> queue = new PriorityQueue<>(2);
queue.offer(-1);
for (char c : s.toCharArray()) {
int num = c - '0';
if (num >= 0 && num <= 9) {
if (num > queue.peek() && !queue.contains(num)) {
queue.offer(num);
if (queue.size() > 2) {
queue.poll();
}
}
}
}
return queue.peek();
}
9. 有一个1G大小的文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词。
TopN问题,wordCount -> sort -> take(100) , 参考MR的作业过程
map阶段:遍历文件里的单词,使用hash%5000,把文件分割成5000个小文件,每个文件大小约200k,hash值相同的单词会存到同一个文件,如果有文件大小大于1M,使用其他hash函数,再次分割文件到所有文件的大小都小于1M
reduce阶段:分别读取1200个小文件的数据,加载到内存中,遍历并使用hashmap统计单词出现的频数,快速排序,输出频数top100的(单词,频数)到结果文件
归并排序,合并结果文件的统计结果,找到全局top100的单词
10. 现有海量日志数据保存在一个超级大的文件中,该文件无法直接读入内存,要求从中提取某天出访问百度次数最多的那个IP。
参考MR的作业过程
map: 使用数据流的形式逐行读取日志数据,过滤出某天访问百度的所有ip,hash%n,把ip存到n个小文件中
reduce: 分别处理n个小文件,在文件中ip加载到内存中,遍历并使用hashmap统计ip出现的次数,快速排序,找到当前文件出现次数最多的ip,分别把ip和次数写入到结果文件
读取结果文件中ip和次数数据,找到出现次数最多的ip
11. 手写TopN算法,使用spark,scala实现。
// 假设需要统计的是一个包含很多字符串的rdd, 需要统计出现次数最多的N个单词
val rddwords:RDD[String]
val N
rddwords.map((_, 1))
.reduceByKey(_+_)
.sortBy(-_._2)
.collect()
.take(N)
.foreach(println(_))
// .sortBy(-_._2) 效率较低,可以考虑使用aggregate
rddwords.map((_, 1))
.reduceByKey(_+_)
.aggregate(List(("", -1)))(
(lis, ele) => (ele::lis).sortBy(-_._2).take(N),
(li1, li2) => (li1:::li2).sortBy(-_._2).take(N)
).foreach(println(_))
12. 如何使用redis,或者zookeeper实现分布式锁
多个进程对同一块资源的修改需要使用分布式锁,在项目中,部署了多个tomcat应用,在执行定时任务时就会遇到同一任务可能执行多次的情况,我们可以借助分布式锁,保证在同一时间只有一个tomcat应用执行定时任务。 分布式锁的实现方式有四种:
- 使用redis的setnx()和expire() setnx(key, value) 如果key不存在,设置为当前key的值为value,获取锁成功;如果key存在,直接返回,获取锁失败;任务完成之后需要get(key) 查看key是否还存在,存在就del(key), 释放锁;考虑到redis的弱事务性,一般解锁都使用redis调用lua脚本,来保证事件的原子性;expire()用来设置超时时间,防止某个进程获得锁之后又意外挂了,没有释放锁;
- 使用redis的getset() 此方法使用getset(key, value), 如果返回空,表示获取了分布式锁;如果返回部位空,表示分布式锁已经被其他程序占用;用完之后,同样需要del(key)释放锁
- 使用zookeeper创建临时节点node 使用zookeepr创建节点node,如果创建节点成功,表示获取了此分布式锁;如果创建节点失败,表示此分布式锁已经被其他程序占用(多个程序同时创建一个节点node,只有一个程序能成功)
- 使用zookeeper的创建临时序列节点
利用zk可以创建临时带序号节点的特性来实现一个分布式锁; 锁就是zk指定目录下序号最小的临时节点,多个系统的多个进程都要在此目录下创建临时的顺序节点,因为zk会为我们保证节点的顺序性,所以可以利用节点的顺序进行锁的判断;每个线程都是先创建临时顺序节点,然后获取当前目录下最小的节点,判断最小节点是不是当前节点,如果是那么获取锁成功,如果不是那么获取锁失败;获取失败的进程需要监听当前节点上一个临时顺序节点,当该节点删除的时候(上一个进程执行结束删除或者掉线,zk删除临时节点),这个进程会获取到通知,代表获取到了锁。
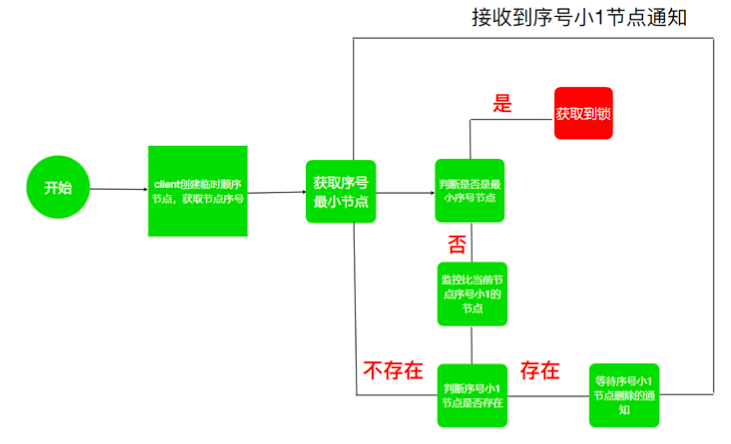
13. 数组和链表的区别,能否用伪代码实现链表。
数组在内存中占用的是连续的存储空间,使用下标访问的时间复杂度是O(1),增删的时间复杂度为O(n), 如果应用需要快速访问数据,很少或不插入和删除元素,应该使用数组。
链表在内存中可以使用非连续的存储空间,每个元素都是通过指针索引到下一个元素,访问第n个元素的时间复杂度是O(n), 增删的时间复杂度为O(1),如果应用需要经常插入和删除元素,就需要使用链表数据结构。
伪代码:定一个链表元素node,它有两个属性,value和next,value存当前元素的值,next指向链表的下一个元素
14. 有了解过哪些机器学习的算法?
开放性问题,知道多少说多少。 有监督算法:决策树,随机森林;非监督算法:KNN(最紧邻),Kmeans
*15. 协同过滤算法的底层实现是什么?
基于用户的CF基于用户的协同过滤,通过用户对不同内容(物品)的行为,来评测用户之间的相似性,找到“邻居”,基于这种相似性做出推荐。这种推荐的本质是,给相似的用户推荐其他用户喜欢的内容,这就是我们经常看到的:和你类似的人还喜欢如下内容。 使用在大数据的推荐中的项目,项目的核心算法。
16. 快速排序、归并排序、冒泡排序、选择排序(复杂度分别是多少)
稳定性:数值相同的元素在排序中不交换位置为稳定反之为不稳定
快速排序: 是不稳定的排序,正常情况时间复杂度O(nlogn), 空间复杂度O(1), 最坏的情况时间复杂度(n2); 最坏情况的例子,每次选用pivot都是第一个元素,需要从小到大排序,数据为[6, 1, 2, 3, 4, 5], 解决方案 是随机取pivot
归并排序: 是稳定的排序,时间复杂度O(nlogn), 空间复杂度O(n)
冒泡排序: 是稳定的排序,时间复杂度O(n2), 空间复杂度O(1)
选择排序: 是不稳定的排序,时间复杂度O(n2), 空间复杂度O(1)
17. spark-submit几种提交模式的区别是什么?
常用的集群模式有standalone-client模式,standalone-cluster模式,yarn-client模式, yarn-cluster模式
standalone模式: 是spark安装包提供的集群模式,不需要安装其他资源管理系统就可以以集群模式运行; 分两种部署模式client,cluster; 调试阶段,希望立即看到app的输出可以使用client模式,但是client模式的driver都在提交app的机器上,如果有多个任务都在一台机器上提交比较考验机器的性能,而且如果提交任务的交互界面被中止,任务运行也会被中止;cluster模式任务提交之后master会在worker节点分配一台机器做driver,这样就可以在一台机器上提交多个任务,而且提交任务后不需要一直和集群保持链接状态,但是有可能找不到提交的jar包,因为driver不一定在哪台机器上,需要确保worker所在的机器有提交的jar包;不过生产阶段一般都使用yarn提交任务
yarn模式: 如果机器上已经安装了yarn那么推荐使用yarn模式,因为可能还有其他服务需要依赖yarn,spark也使用yarn来调度就可以少开一个后台运行的进程;yarn集群的ResourceManager对应StandAlone的Master,yarn集群的NodeManager对应StandAlone的Worker,任务提交的运行流程和standalone基本一致;同样的也有两种部署模式client和cluster,区别就是driver所在的位置不一样,client模式需要保持提交窗口和集群的链接,cluster模式不需要;yarn-cluster和standalone-cluster模式比,还有一个优点就是yarn-cluster会把jar包上传到hdfs,不需要同步jar包到每台机器上
18. spark streming在实时处理时会发生什么故障,如何停止,解决。
- Spark 版本低于 2.3.0 可能会出现 stage停止了
在使用Spark Streaming执行的时候,偶尔会出现Stage停止不动的现象
但是点击任务进去查看任务详情,会发现状态是SUCCESSED的
查看日志,发现日志中出现ERROR和WARN报错:
ERROR LiveListenerBus: Dropping SparkListenerEvent because no remaining room in event queue. This likely means one of the SparkListeners is too slow and cannot keep up with the rate at which tasks are being started by the scheduler. WARN LiveListenerBus: Dropped 1 SparkListenerEvents since …
问题的原因: 当消息队列中的消息数超过其spark.scheduler.listenerbus.eventqueue.size设置的数量(默认10000)时,会将最新的消息移除,这些消息本来是通知任务运行状态的,由于移除了,状态无法得到更新,所以会出现上面描述的现象。补充说明:spark是个分布式系统,不同组件之间的通信,比如状态更新,事件传递使用liveListenerBus完成,eventqueue表示当前活跃的消息队列
解决方案:在spark-submit中添加参数--conf spark.scheduler.listenerbus.eventqueue.size=<大于默认参数的值>, 同时需要给driver分配更多内存- 与Kafka整合是消息无序
修改Kafka的ack参数,当ack=1时,master确认收到消息就算投递成功。ack=0时,发送消息就算成功,高效不准确。ack=all,master和server都要收到消息才算成功。准确不高效。这个需要根据实际场景来权衡

19. spark工作机制。
spark 有多个机制,比如容错机制,shuffle机制,调度机制等。
容错机制: RDD容错: RDD之间的依赖分两种,宽依赖和窄依赖,宽依赖是这父分区可以被多个子分区所用,即多对多的关系,窄依赖是指父分区智能被一个子分区使用,即一对一的关系;当出现某个节点计算错误的时候,会顺着RDD的操作顺序往回走。如果是窄依赖错误,重新计算父RDD分区即可,因为它不依赖其他节点;如果是宽依赖错误,重算代价较高,需要重新计算所有分区上的父RDD。这个时候就需要认为添加检查点来提高容错机制的执行效率,DAG中的血缘关系过长,如果重算开销太大,所以在特定几个宽依赖上做checkPoint是有价值的。
Driver容错:元数据checkpoint,在类似HDFS的容错存储上,保存Streaming计算信息,这种checkpoint用来恢复运行stream应用程序失败的Driver进程
shuffle机制: spark等分布式计算框架中,数据被分成一块一块的分区,分布在集群中各个节点上,每个计算任务一次处理一个分区,当需要对具有某种共同特征的一类数据进行计算时,就需要将集群中的这类数据汇聚到同一个节点。这个按照一定的规制对数据重新分区的过程就是shuffle。Spark的shuffle过程分为Writer和Reader,Writer负责生成中间数据,Reader负责整合中间数据,shuffle过程会根据数据规模选用合适的Writer实现;具体的有hash base shuffle,sort base shuffle;
20. Kafka和sparkStreaming的整合,手动提交的offset调用了什么方法?
手动提交Offset需要处理处理三步操作:
- kakfa config 设置
enable.auto.commit = false- 创建Kafka流的时候需要提交缓存的offset
- 每次读取数据的时候缓存offset到自定义的数据库,比如redis
需用调用的方法
dstream.foreachRDD { (rdd, time) =>
if (!rdd.isEmpty()) {
// 获取offset
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// 保存offset 到 redis
OffsetsWithRedisUtils.saveOffsetsToRedis(offsetRanges, groupId)
}
}
推荐使用MySQL和Redis缓存kafka offset;offset其实也可以自动提交,不过那样不能保证Spark Streaming处理的数据不丢失,自动提交的时候,只要spark streaming 收到kafka的数据就会提交offset,但是如果收到数据后处理过程中服务器挂了,下次在连接上kafka就会跳过没有处理成功那段数据,这是我们不想见到的结果,所以Kafka和Spark Streaming进行整合时,大多数时候需要手动提交offset
21. Spark Streaming如何保证数据的防丢失
在Spark Streaming的生成实践中,要做到数据零丢失,需要满足以下几个先决条件:
- 数据的数据源是可靠的/数据接收器的可靠的
- 应用程序的metadata被application的driver持久化了(checkpointed) 下面分别对这3个条件进行介绍:
- 对于一些输入数据源(比如Kafka),Spark Streaming可以对已经接收的数据进行确认。使用手动管理offset的方式,只有数据处理成功才提交offset,这样如果Spark Streaming突然挂掉,可以继续处理没有处理成功的数据
- 可靠的数据源和接收器可以让我们从接收器挂掉的情况下恢复。但是更棘手的是如果Driver挂掉如何恢复?其中一个方法就是对Driver的metadata进行checkpoint。利用这个特性,Driver可以将应用程序的重要元数据持久化到可靠的存储中,比如HDFS;然后Driver可以利用这些持久化的数据进行恢复
22. spark的checkpoint机制
RDD checkpoint: RDD之间的依赖分两种,宽依赖和窄依赖,宽依赖是这父分区可以被多个子分区所用,即多对多的关系,窄依赖是指父分区智能被一个子分区使用,即一对一的关系;当出现某个节点计算错误的时候,会顺着RDD的操作顺序往回走。如果是窄依赖错误,重新计算父RDD分区即可,因为它不依赖其他节点;如果是宽依赖错误,重算代价较高,需要重新计算所有分区上的父RDD。这个时候就需要认为添加检查点来提高容错机制的执行效率,DAG中的血缘关系过长,如果重算开销太大,所以在特定几个宽依赖上做checkPoint是有价值的。
元数据checkpoint: 在类似HDFS的容错存储上,保存Streaming计算信息,这种checkpoint用来恢复运行stream应用程序失败的Driver进程