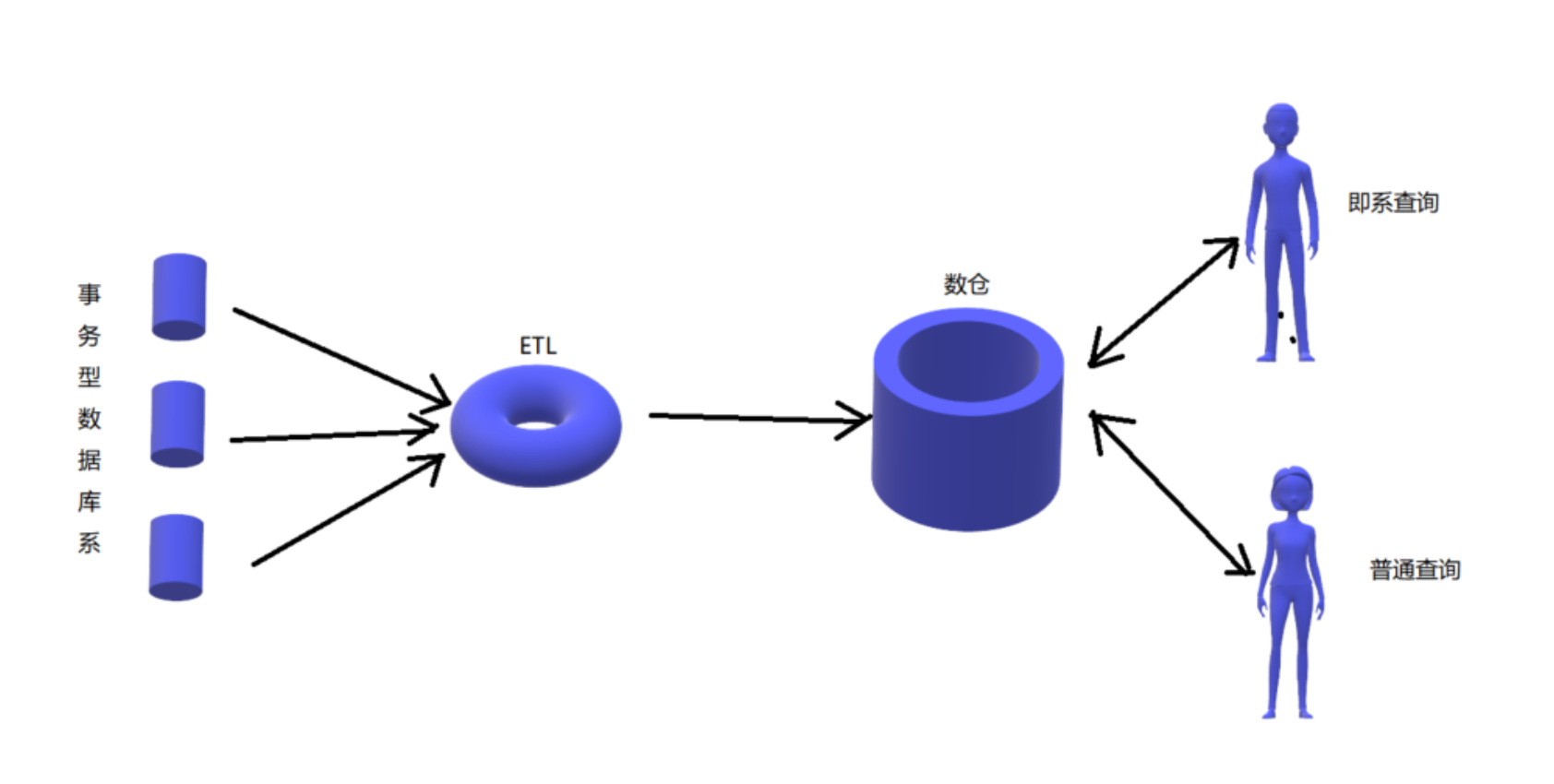
Flink--流(批)式处理框架
Flink 概述
什么是 Flink
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
Flink 特点
Flink 是一个开源的流处理框架,它具有以下特点
- 批流一体:统一批处理、流处理
- 分布式:Flink程序可以运行在多台机器上
- 高性能:处理性能比较高
- 高可用:Flink支持高可用性(HA)
- 准确:Flink可以保证数据处理的准确性
Flink 应用场景
Flink主要应用于流式数据分析场景
-
实时ETL 集成流计算现有的诸多数据通道和SQL灵活的加工能力,对流式数据进行实时清洗、归并和结构化处理;同时,对离线数仓进行有效的补充和优化,并为数据实时传输提供可计算通道。
-
实时报表 实时化采集、加工流式数据存储;实时监控和展现业务、客户各类指标,让数据化运营实时化。
- 如通过分析订单处理系统中的数据获知销售增长率;
- 通过分析运输延迟原因或预测销售量调整库存;
-
监控预警 对系统和用户行为进行实时监测和分析,以便及时发现危险行为,如计算机网络入侵、诈骗预警等
-
在线系统 实时计算各类数据指标,并利用实时结果及时调整在线系统的相关策略,在各类内容投放、智能推送领域有大量的应用,如在客户浏览商品的同时推荐相关商品等
Flink 核心组成及生态发展
-
Flink核心组成
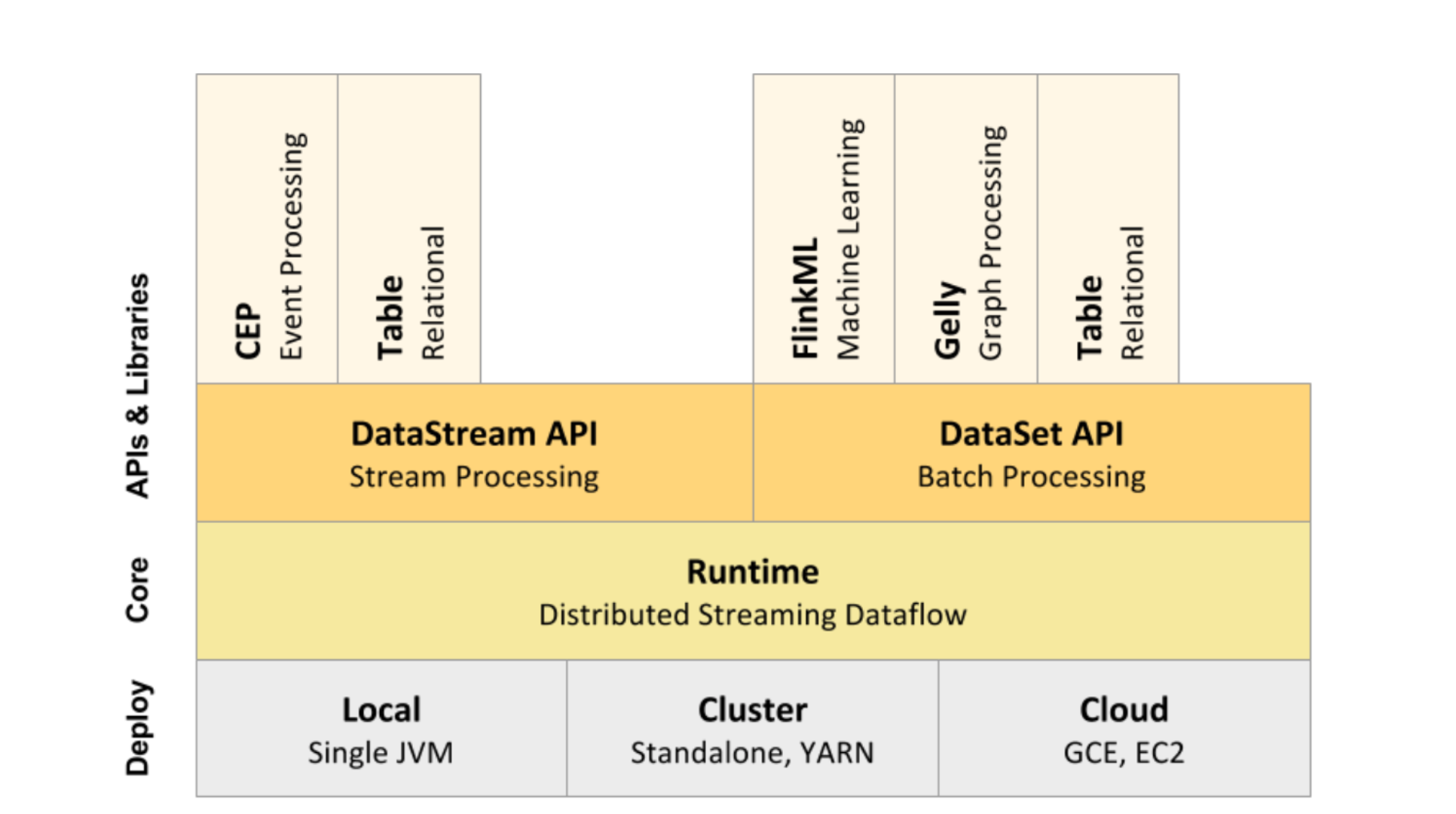
- Deploy层
- 可以启动单个JVM,让Flink以Local模式运行
- Flink也可以以Standalone 集群模式运行,同时也支持Flink ON YARN,Flink应用直接提交到 YARN上面运行
- Flink还可以运行在GCE(谷歌云服务)和EC2(亚马逊云服务)
-
Core层(Runtime) 在Runtime之上提供了两套核心的API,DataStream API(流处理)和 DataSet API(批处理)
- APIs & Libraries层
- CEP流处理
- Table API和SQL
- Flink ML机器学习库
- Gelly图计算
- Deploy层
-
Flink生态发展
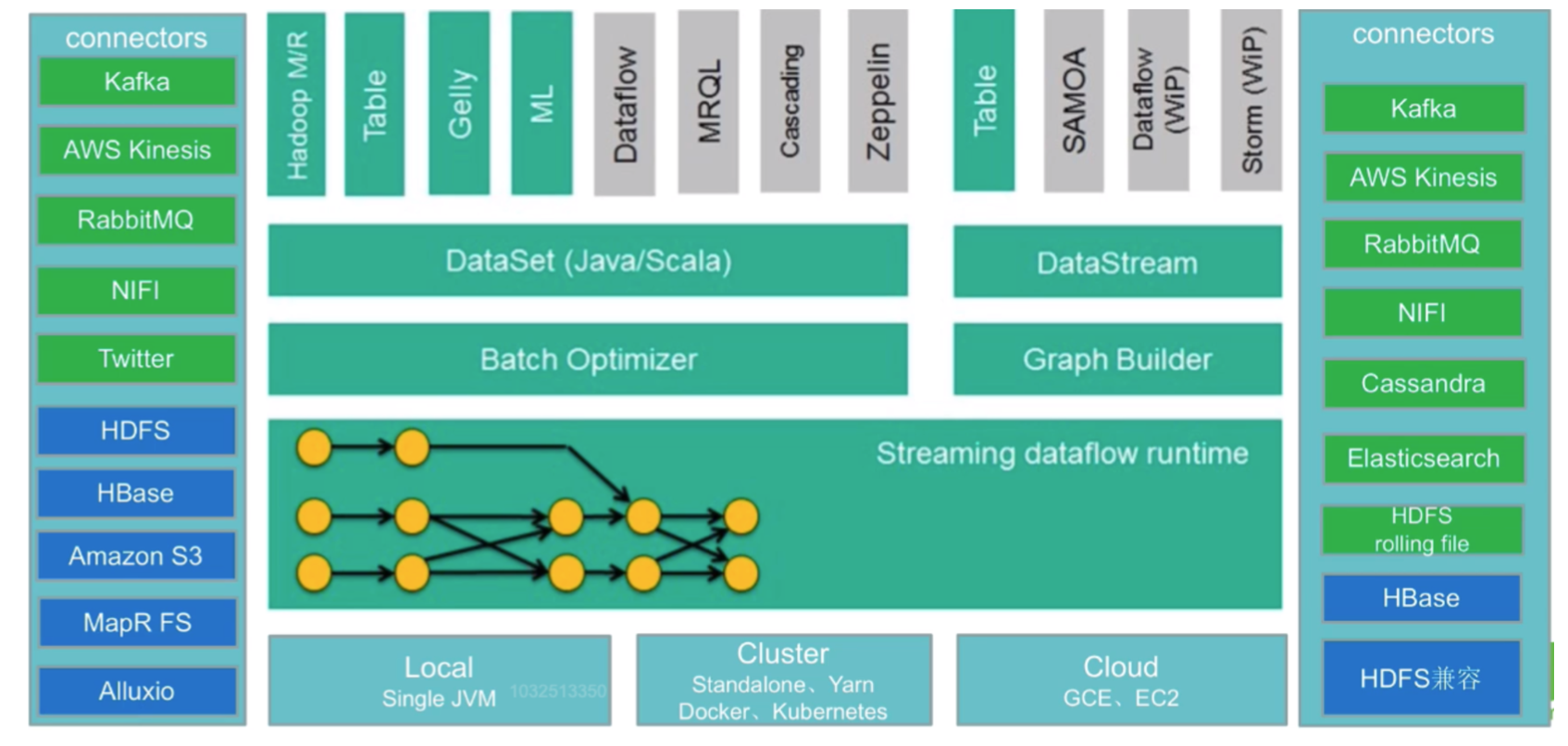
- 中间部分主要内容在上面Flink核心组成中已经提到
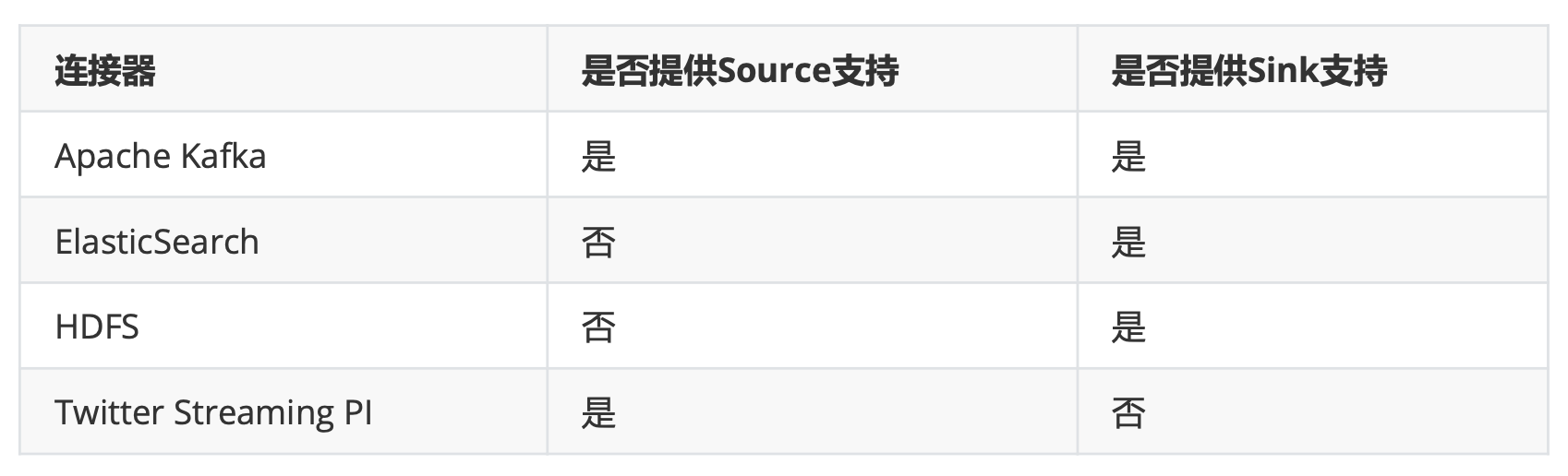
- 输入Connectors(左侧部分)
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队 列)、NIFI(数据管道)、Twitter(API)
批处理方式:包含HDFS(分布式文件系统)、HBase(分布式列式数据库)、Amazon S3(文件 系统)、MapR FS(文件系统)、ALLuxio(基于内存分布式文件系统) - 输出Connectors(右侧部分)
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队 列)、NIFI(数据管道)、Cassandra(NOSQL数据库)、ElasticSearch(全文检索)、HDFS rolling file(滚动文件)
批处理方式:包含HBase(分布式列式数据库)、HDFS(分布式文件系统)
Flink 处理模型:流处理与批处理
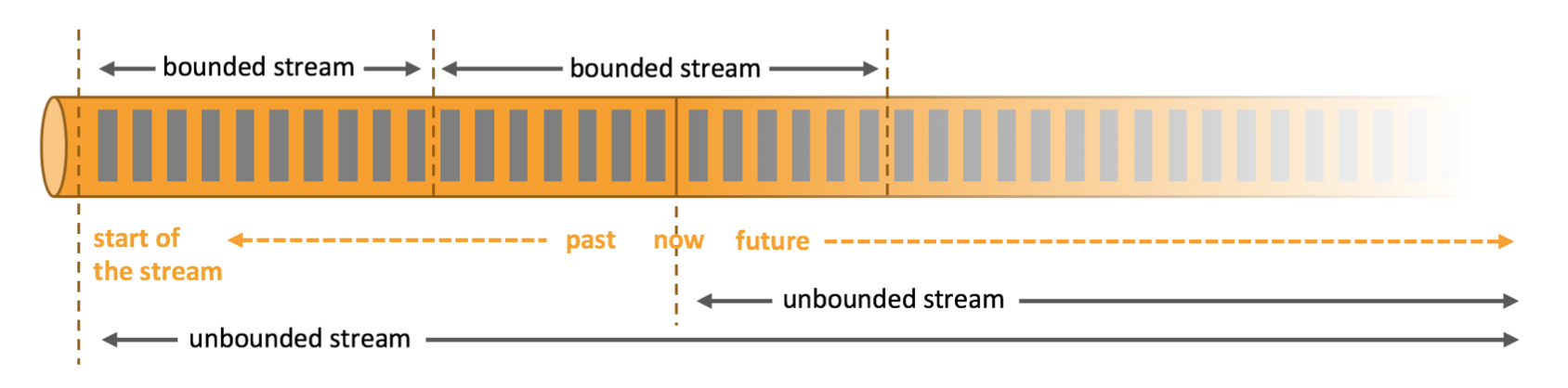
Flink 专注于无限流处理,有限流处理是无限流处理的一种特殊情况
- 无限流处理
- 输入的数据没有尽头,像水流一样源源不断
- 数据处理从当前或者过去的某一个时间点开始,持续不停地进行
- 有限流处理
- 从某一个时间点开始处理数据,然后在另一个时间点结束
- 输入数据可能本身是有限的(即输入数据集并不会随着时间增长),也可能出于分析的目的被人为地设定为有限集(即只分析某一个时间段内的事件)
Flink封装了DataStream API进行流处理,封装了DataSet API进行批处理。 同时,Flink也是一个批流一体的处理引擎,提供了Table API / SQL统一了批处理和流处理
- 有状态的流处理应用
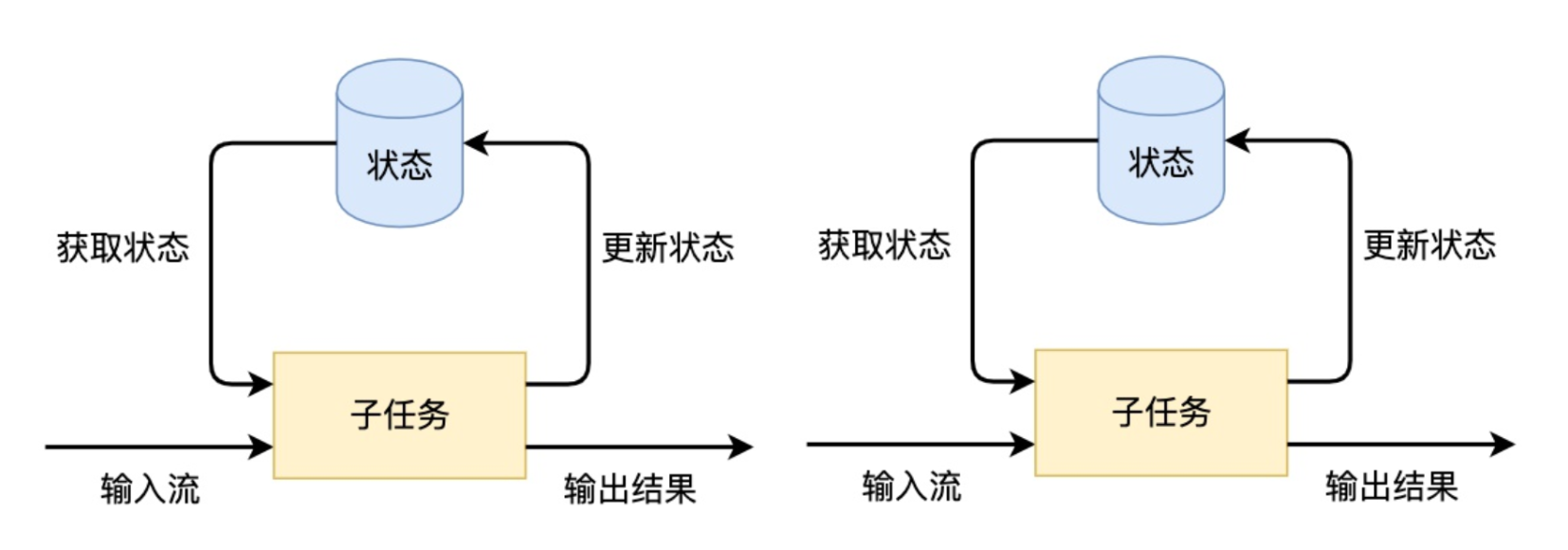 和spark的checkpoint比较
和spark的checkpoint比较
流处理引擎的技术选型
市面上的流处理引擎不止Flink一种,其他的比如Storm、SparkStreaming、Trident等,实际应用 时如何进行选型,给大家一些建议参考
- 流数据要进行状态管理,选择使用Trident、Spark Streaming或者Flink
- 消息投递需要保证At-least-once(至少一次)或者Exactly-once(仅一次)不能选择Storm
- 对于小型独立项目,有低延迟要求,可以选择使用Storm,更简单
- 如果项目已经引入了大框架Spark,实时处理需求可以满足的话,建议直接使用Spark中的Spark Streaming
- 消息投递要满足Exactly-once(仅一次),数据量大、有高吞吐、低延迟要求,要进行状态管理或 窗口统计,建议使用Flink
Flink初体验
相关依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.11.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.11.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.11.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.11.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.11.1</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.1</version>
</dependency>
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.11.1</version>
</dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table</artifactId>
<version>1.11.1</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<!-- Either... -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
<!-- or... -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_2.12</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-orc_2.12</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hbase_2.12</artifactId>
<version>1.10.2</version>
</dependency>
<!-- <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.12</artifactId>
<version>1.10.2</version>
</dependency>-->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.16</version>
</dependency>
<dependency>
<groupId>com.github.housepower</groupId>
<artifactId>clickhouse-native-jdbc</artifactId>
<version>1.6-stable</version>
</dependency>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.5.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
wordCount批处理
- java
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.operators.AggregateOperator; import org.apache.flink.api.java.operators.DataSource; import org.apache.flink.api.java.operators.FlatMapOperator; import org.apache.flink.api.java.operators.UnsortedGrouping; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; import java.util.Arrays; public class WordCountJavaBatch { public static void main(String[] args) throws Exception { String input = "data/input/hello.txt"; String output = "data/output"; // 获取执行环境 ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment(); // 读取文本 DataSource<String> textFile = executionEnvironment.readTextFile(input); // (hello, 1) (word, 1) (hello, 1) FlatMapOperator<String, Tuple2<String, Integer>> wordAndOnes = textFile.flatMap(new SplitClz()); // (hello, 1) (hello, 1) | (word, 1) UnsortedGrouping<Tuple2<String, Integer>> groupWordAndOne = wordAndOnes.groupBy(0); // (hello, 2) (word, 1) AggregateOperator<Tuple2<String, Integer>> out = groupWordAndOne.sum(1); // 按csv格式写出 out.writeAsCsv(output, "\n", ",").setParallelism(1); // flink必须调用execute才会运行 executionEnvironment.execute(); } static class SplitClz implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { Arrays.stream(s.split("\\s+")) .forEach(word -> collector.collect(new Tuple2<>(word, 1)) ); } } } - scala
import org.apache.flink.api.scala._ object WordCountScalaBatch { def main(args: Array[String]): Unit = { val inputPath = "data/input/hello.txt" val output = "data/output.csv" val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment val textFile: DataSet[String] = environment.readTextFile(inputPath) val result: AggregateDataSet[(String, Int)] = textFile.flatMap(_.split("\\s+")).map((_, 1)).groupBy(0).sum(1) result.writeAsCsv(output, "\n", ",").setParallelism(1) environment.execute() } }
wordCount流处理
- java
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Arrays; public class WordCountJavaStream { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> streamSource = environment.socketTextStream("localhost", 7777); SingleOutputStreamOperator<Tuple2<String, Integer>> wordsAndOnes = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { Arrays.stream(s.split("\\s+")) .forEach(word -> collector.collect(new Tuple2<>(word, 1))); } }); KeyedStream<Tuple2<String, Integer>, Tuple> groupedWords = wordsAndOnes.keyBy(0); SingleOutputStreamOperator<Tuple2<String, Integer>> outStream = groupedWords.sum(1); outStream.print(); environment.execute(); } } - scala
import org.apache.flink.streaming.api.scala._ // 处理流式数据 object WordCountScalaStream { def main(args: Array[String]): Unit = { // 使用StreamExecutionEnvironment, 与批处理的运行环境不一样 val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 监听netcat发送的数据 // nc -lp 7777 val streamData: DataStream[String] = environment.socketTextStream("localhost", 7777) // 和批处理的groupBy不同,这里要用keyBy val out: DataStream[(String, Int)] = streamData.flatMap(_.split("\\s+")).map((_, 1)).keyBy(0).sum(1) out.print() environment.execute() } }
Flink体系结构
Flink的重要角色
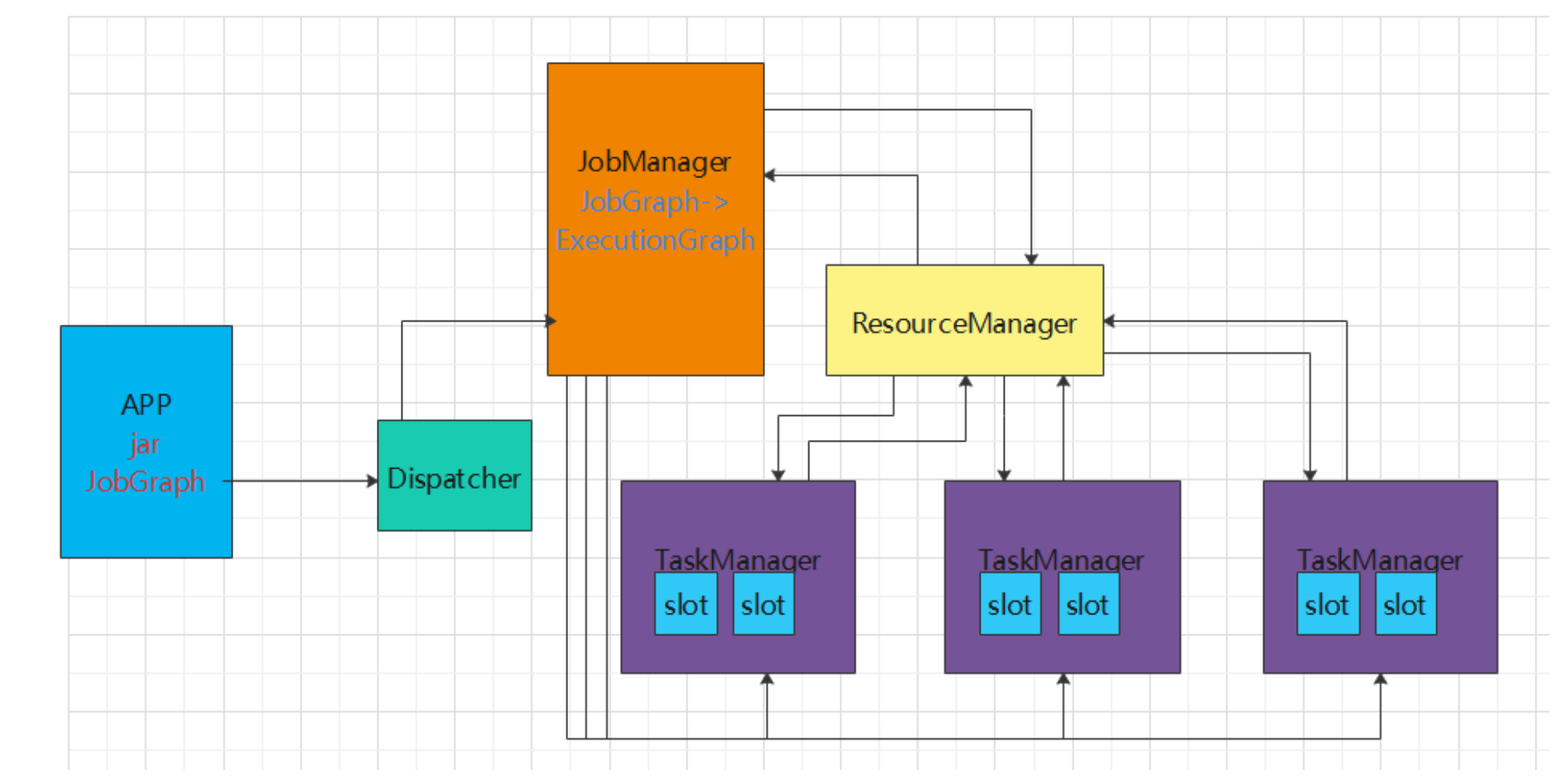
Flink是非常经典的Master/Slave结构实现,JobManager是Master,TaskManager是Slave。
- JobManager处理器(Master)
- 协调分布式执行,它们用来调度task,协调检查点(CheckPoint),协调失败时恢复等
-
Flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。
-
ResourceManager 针对不同的环境和资源提供者,如(YARN,Mesos,Kubernetes或独立部署),Flink提供了不同的ResourceManager
作用:负责管理Flink的处理资源单元—Slot -
Dispatcher 提供一个REST接口来让我们提交需要执行的应用。 一旦一个应用提交执行,Dispatcher会启动一个JobMaster,并将应用转交给他。 Dispatcher还会启动一个webUI来提供有关作业执行信息
注意:某些应用的提交执行的方式,有可能用不到Dispatcher
- App JobManager接收的应用包括jar和JobGraph
-
JobMaster 负责管理一个JobGraph的执行,Flink可以同时运行多个job,每个job都有自己的JobMaster
-
- TaskManager处理器(Slave)
也称之为Worker
- 主要职责是从JobManager处接收任务, 并部署和启动任务, 接收上游的数据并处理
- Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点
- TaskManager在启动的时候会向ResourceManager注册自己的资源信息(Slot的数量等)
Flink运行架构
-
Flink程序结构
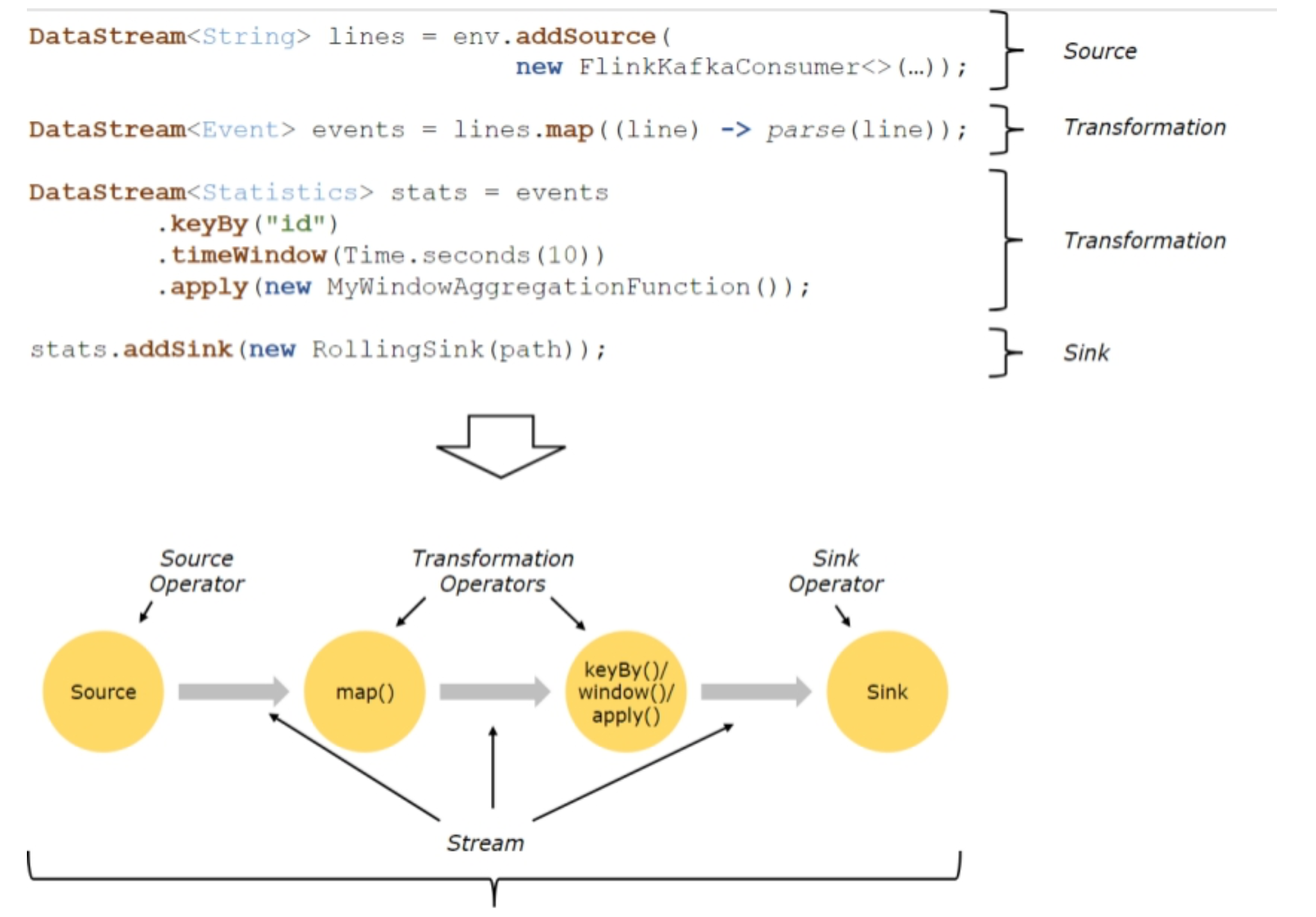 Flink程序的基本构建块是流和转换(请注意,Flink的DataSet API中使用的DataSet也是内部流 )。从概念上讲,流是(可能永无止境的)数据记录流,而转换是将一个或多个流输入,并产生一个或多个输出流。
Flink程序的基本构建块是流和转换(请注意,Flink的DataSet API中使用的DataSet也是内部流 )。从概念上讲,流是(可能永无止境的)数据记录流,而转换是将一个或多个流输入,并产生一个或多个输出流。上图表述了Flink的应用程序结构,有Source(源头)、Transformation(转换)、Sink(接收 器)三个重要组成部分
-
Source 数据源,定义Flink从哪里加载数据,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义 的 source 常见的有 Apache kafka、RabbitMQ 等。
-
Transformation 数据转换的各种操作,也称之为算子,有 Map / FlatMap / Filter / KeyBy / Reduce /
Window等,可以将数据转换计算成你想要的数据。 -
Sink 接收器,Flink 将转换计算后的数据发送的地点 ,定义了结果数据的输出方向,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、HDFS等。
-
- Task和SubTask
- Task 是一个阶段多个功能相同 SubTask 的集合,类似于 Spark 中的 TaskSet。
- SubTask(子任务): SubTask 是 Flink 中任务最小执行单元,是一个 Java 类的实例,这个 Java 类中有属性和方 法,完成具体的计算逻辑
比如一个执行操作map,分布式的场景下会在多个线程中同时执行,每个线程中执行的都叫做一个SubTask
-
Operator chain(操作器链)
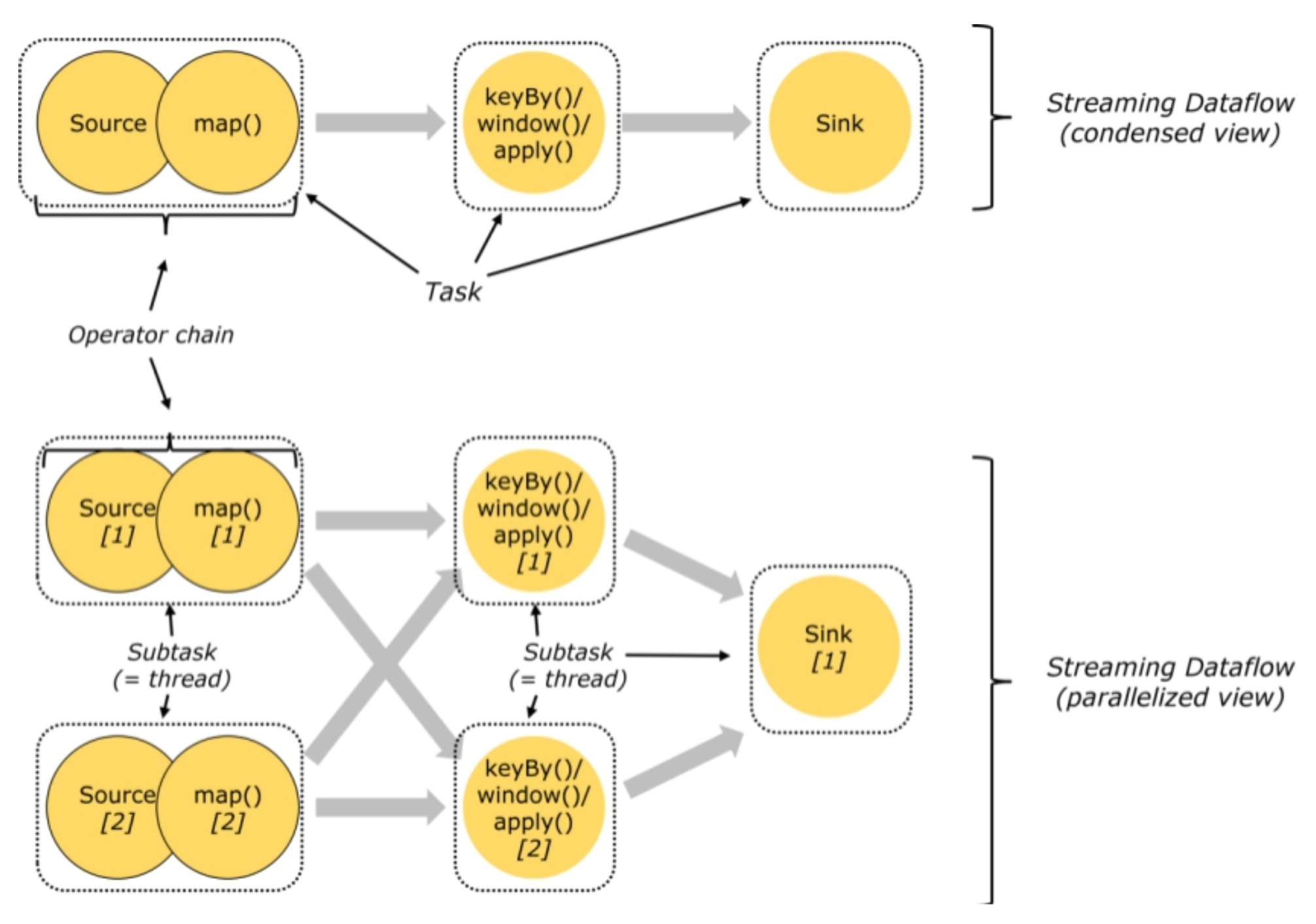 Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进 行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进 行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。 -
Flink中的数据传输 在运行过程中,应用中的任务会持续进行数据交换。
为了有效利用网络资源和提高吞吐量,Flink在处理任务间的数据传输过程中,采用了缓冲区机制。 -
任务槽和槽共享
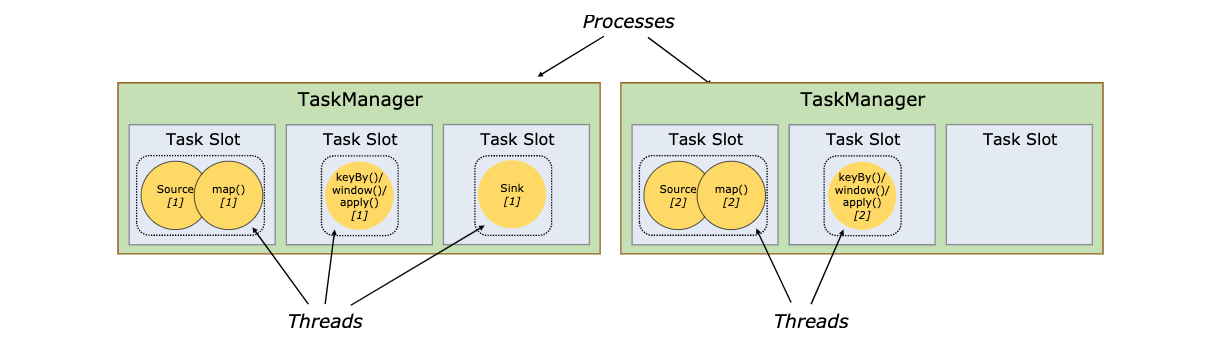 任务槽即task-slot、槽共享即slot sharing
任务槽即task-slot、槽共享即slot sharing每个TaskManager是一个JVM的进程, 可以在不同的线程中执行一个或多个子任务。
为了控制一个worker能接收多少个task。worker通过task slot来进行控制(一个worker至少有一个task slot)- 任务槽
每个task slot表示TaskManager拥有资源的一个固定大小的子集。 一般来说:我们分配槽的个 数都是和CPU的核数相等,比如6核,那么就分配6个槽.
Flink将进程的内存进行了划分到多个Slot中。假设一个TaskManager机器有3个slot,那么每 个slot占有1/3的内存(平分)。
内存被划分到不同的slot之后可以获得如下好处:- TaskManager最多能同时并发执行的任务是可以控制的,那就是3个,因为不能超过slot的数量
- slot有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响
- 槽共享
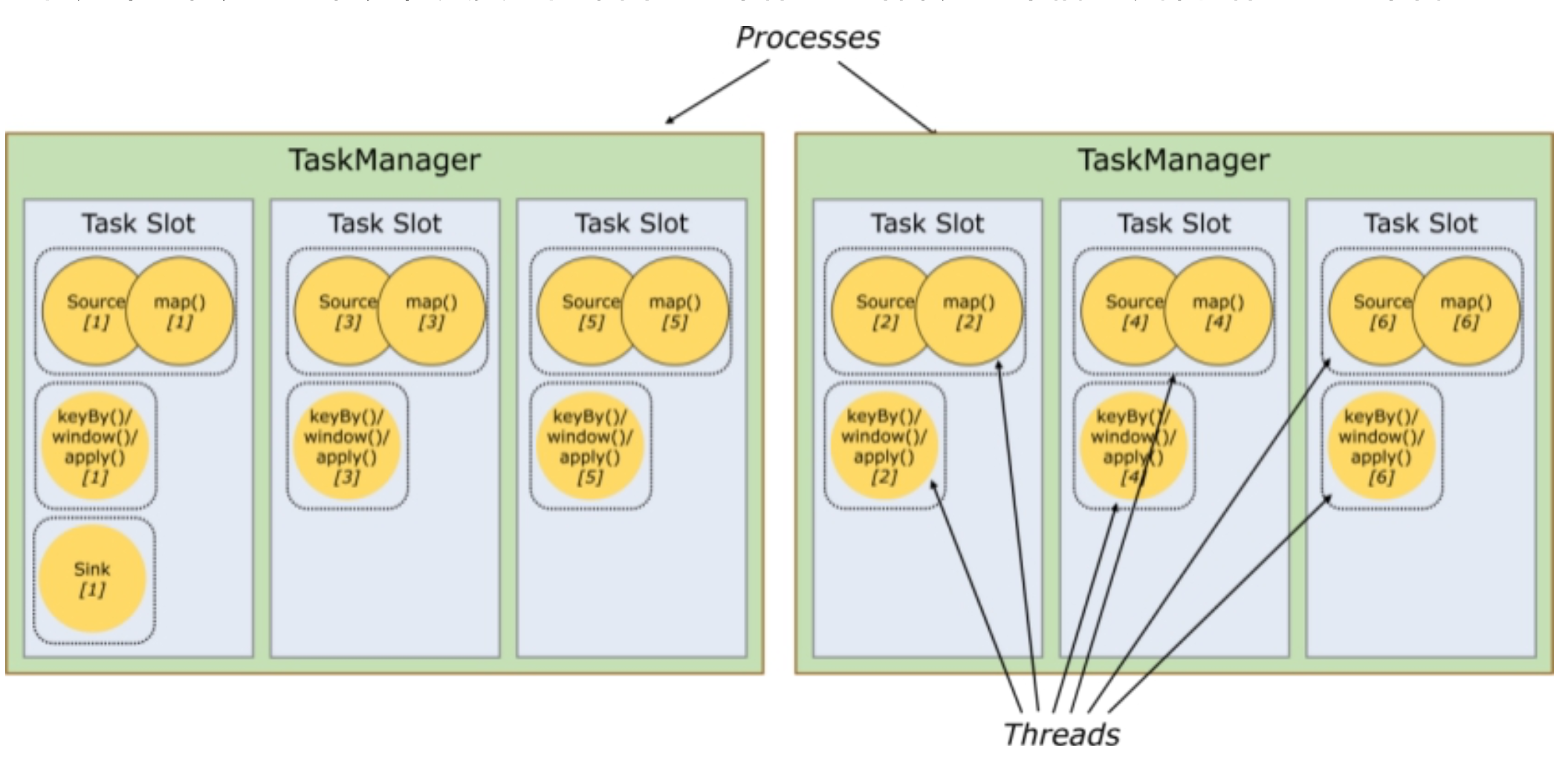 默认情况下,Flink允许子任务subtast(map[1] map[2] keyby[2]keyby[1] ) 共享插槽,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个槽可以保存作业的整个管道。
默认情况下,Flink允许子任务subtast(map[1] map[2] keyby[2]keyby[1] ) 共享插槽,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个槽可以保存作业的整个管道。
- 任务槽
每个task slot表示TaskManager拥有资源的一个固定大小的子集。 一般来说:我们分配槽的个 数都是和CPU的核数相等,比如6核,那么就分配6个槽.
Flink安装和部署
Flink支持多种安装模式
- local(本地):单机模式,一般本地开发调试使用
- StandAlone 独立模式:Flink自带集群,自己管理资源调度,生产环境也会有所应用
- Yarn模式:计算资源统一由Hadoop YARN管理,生产环境应用较多
环境准备工作
- 基础环境
- jdk1.8及以上【配置JAVA_HOME环境变量】
- ssh免密码登录【集群内节点之间免密登录】
- 安装包下载
wget https://archive.apache.org/dist/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.12.tgz
StandAlone模式部署
Step1、Flink安装包上传到centos7-2 对应目录并解压
Step2、修改 flink/conf/flink-conf.yaml 文件
jobmanager.rpc.address: centos7-2
# 一般cpu有多少核就写多少
taskmanager.numberOfTaskSlots: 2
Step3、修改conf/master
vim masters
centos7-2:8081
Step4、修改conf/workers
vim workers
centos7-1
centos7-2
centos7-3
Step5、把修改好配置的flink包分发到centos7-1, centos7-3上
Step6、standalone模式启动
bin目录下执行./start-cluster.sh
Step7、jps进程查看核实
3857 TaskManagerRunner
3411 StandaloneSessionClusterEntrypoint
Step8、查看Flink的web页面 ip:8081/#/overview
Step9、集群模式下运行example测试
./flink run -c WordCount ../examples/streaming/WordCount.jar
# -c 指定程序入口
也可以在web端直接提交jar包
Yarn模式部署
-
启动一个YARN session
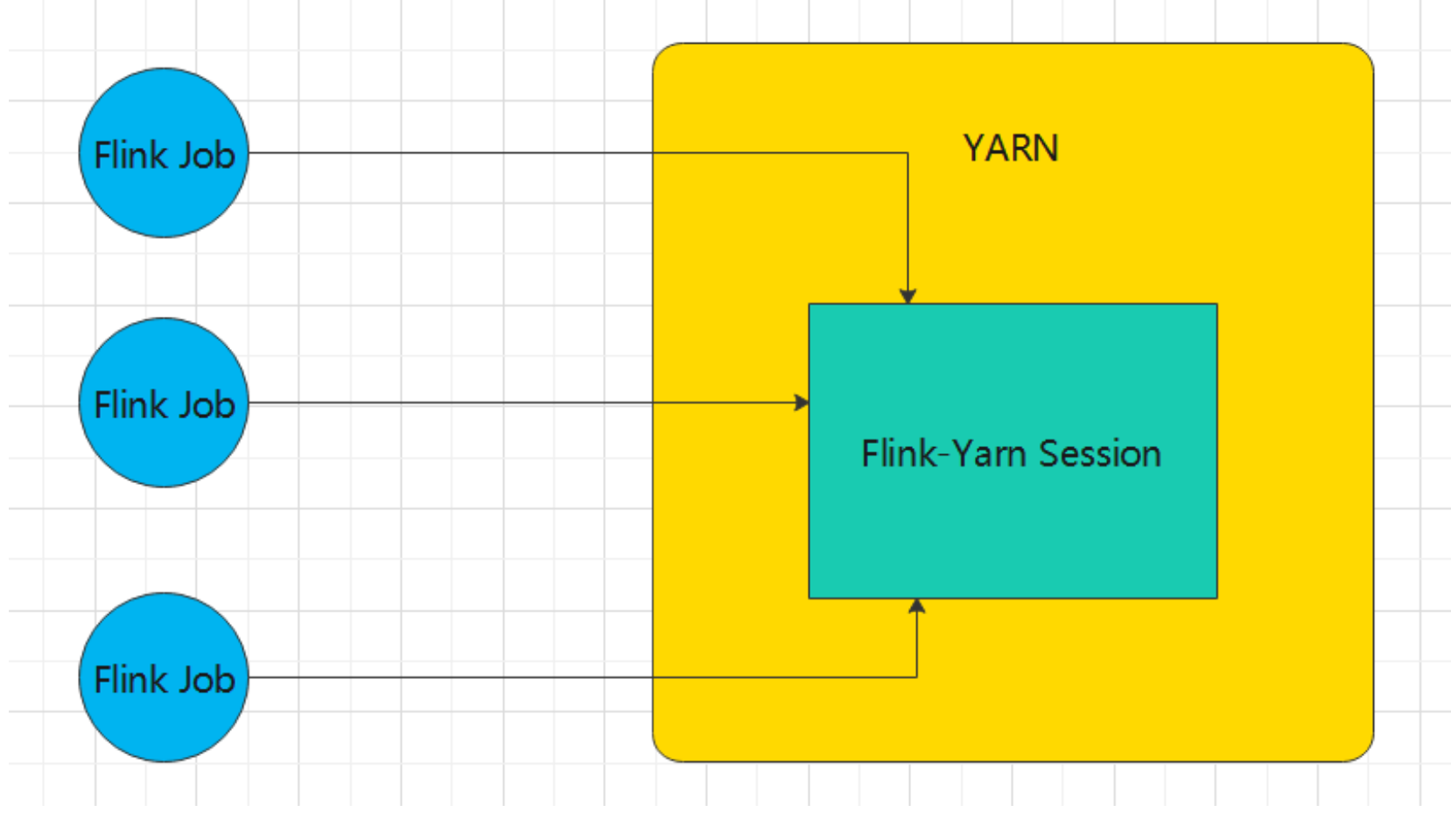 Start a long-running Flink cluster on YARN, 在Yarn上长期启动一个job用来接收Flink的请求,和standalone类似
Start a long-running Flink cluster on YARN, 在Yarn上长期启动一个job用来接收Flink的请求,和standalone类似启动之前需要确认环境变量
vim /etc/profile export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_CLASSPATH=`hadoop classpath`启动yarn session
bin/yarn-session.sh -n 2 -tm 800 -s 1 -d # -n 表示申请2个容器,这里指的就是多少个taskmanager # -s 表示每个TaskManager的slots数量 # -tm 表示每个TaskManager的内存大小 # -d 表示以后台程序方式运行上面命令的意思是,同时向Yarn申请3个container(即便只申请了两个,因为ApplicationMaster(Job Manager)有一个额外的容器)
-n 2: 启动 2 个 Container (TaskManager)
-s 1: 每个 TaskManager 拥有1个 Task Slot
-tm 800: 并且向每个 TaskManager 的 Container 申请 800M 的内存
如果不想让Flink YARN客户端始终运行,那么也可以启动分离的 YARN会话。
该参数被称为-d或–detached。在这种情况下,Flink YARN客户端只会将Flink提交给集群,然后关闭它自己yarn-session.sh(开辟资源) + flink run(提交任务)
- 使用Flink中的yarn-session(yarn客户端),会启动两个必要服务JobManager和TaskManager
- 客户端通过flink run提交作业
- yarn-session会一直启动,不停地接收客户端提交的作业
- 这种方式创建的Flink集群会独占资源。
- 如果有大量的小作业/任务比较小,或者工作时间短,适合使用这种方式,减少资源创建的时间.
-
Run a Flink job on YARN
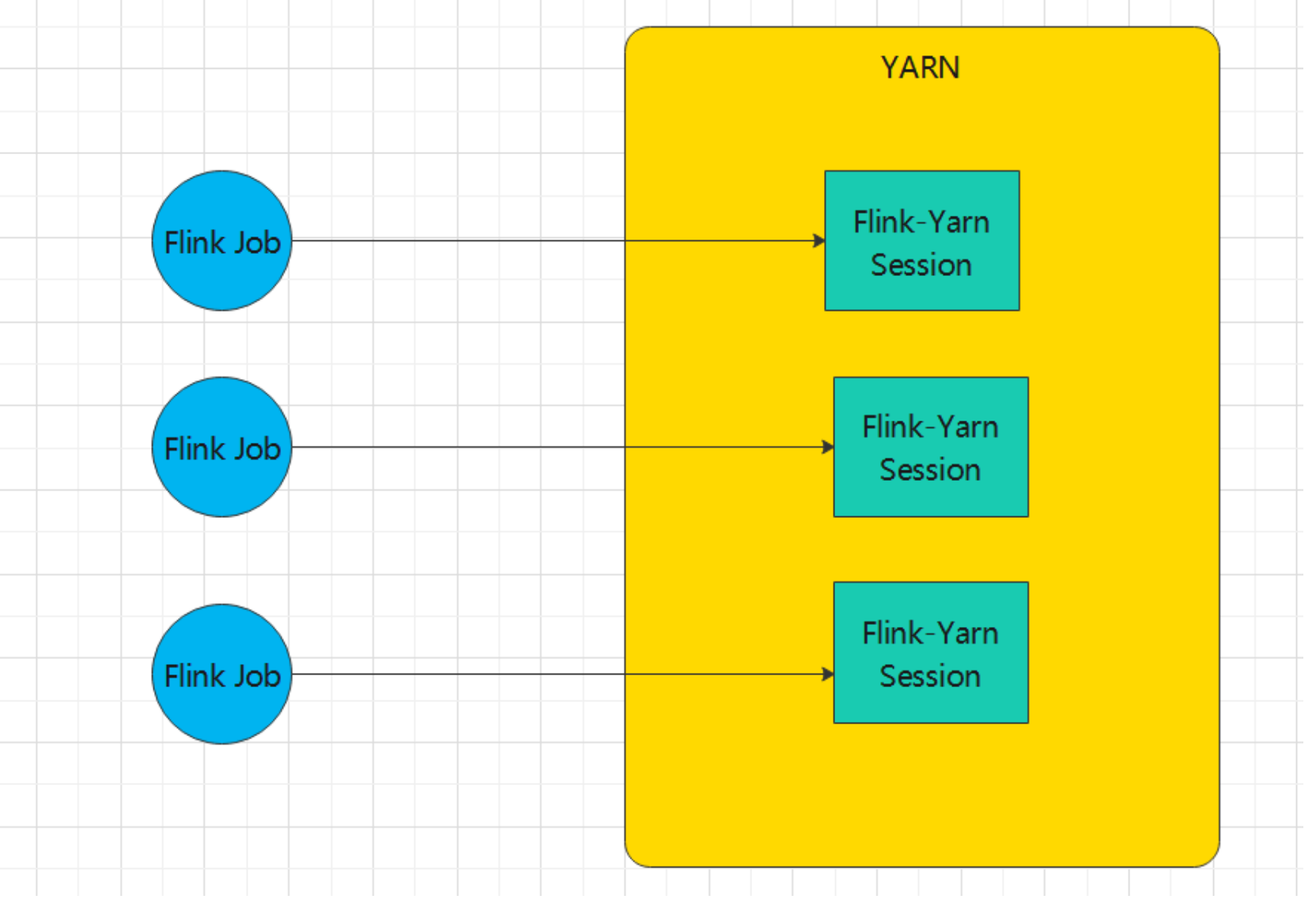 直接在YARN上提交运行Flink作业(Run a Flink job on YARN), 一个flink job 对应一个yarn job
直接在YARN上提交运行Flink作业(Run a Flink job on YARN), 一个flink job 对应一个yarn job启动作业:
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 -c WordCount /export/servers/flink/examples/batch/WordCount.jar # -m jobmanager的地址 # -yn 表示TaskManager的个数 # -yjm 表示job manager可用内存 # -ytm 表示task manager可用内存停止yarn-cluster:
yarn application -kill application_1527077715040_0003 rm -rf /tmp/.yarn-properties-root
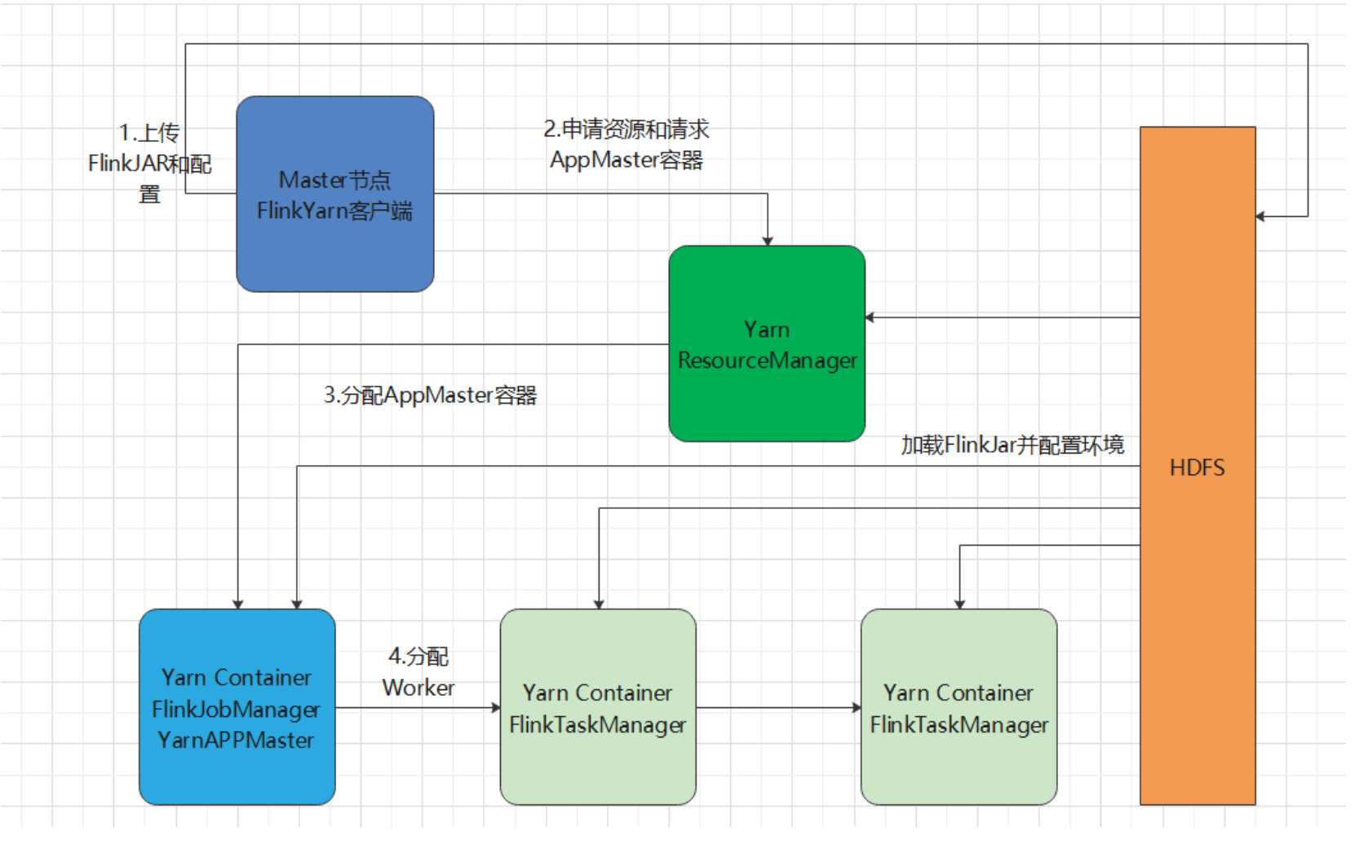
Flink常用API
DataStream
-
DataSource 所有Source都是基于
SourceFunction, 通过StreamExecutionEnvironment的public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function)方法获得.Flink封装了一些常用的source, 用来读取文件, 读取socket, 读取Collection, 读取kafka数据, 可以根据需要自定义source
-
基于文件readTextFile 读取文本文件,文件遵循TextInputFormat逐行读取规则并返回
- hdfs依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-hadoop-compatibility_2.11</artifactId> <version>1.11.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.8.5</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.8.5</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.8.5</version> </dependency> - local, hdfs
String input = "data/input/hello.txt"; String hdfsInput = "hdfs://centos7-1:9000/input/wc.txt"; StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); /** * * @param filePath * The path of the file, as a URI (e.g., "file:///some/local/file" or "hdfs://host:port/file/path") * @param charsetName, default "UTF-8" * The name of the character set used to read the file * @return The data stream that represents the data read from the given file as text lines */ // 本地文件读取 // DataStreamSource<String> data = environment.readTextFile(input); // hdfs文件读取 DataStreamSource<String> data = environment.readTextFile(hdfsInput);
- hdfs依赖
-
基于socket/ socketTextStream 从Socket中读取数据,元素可以通过一个分隔符分开
/** * @param hostname * The host name which a server socket binds * @param port * The port number which a server socket binds. A port number of 0 means that the port number is automatically * allocated. * @return A data stream containing the strings received from the socket */ DataStreamSource<String> streamSource = environment.socketTextStream("centos7-3", 7777); -
基于集合fromCollection 通过Java的Collection集合创建一个数据流,集合中的所有元素必须是相同类型的 如果满足以下条件,Flink将数据类型识别为POJO类型(并允许“按名称”字段引用)
public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); // 集合来自java类型 fromDefinedJavaClass(environment); /** * 8> (Flink,1) * 8> (Spark,1) * 8> (Flink,2) */ // 集合来之自定义类型 fromDefinedClass(environment); /** * 7> People{name='Lucy', age=18} * 5> People{name='April', age=30} */ environment.execute(); } // 使用java类的集合 public static void fromDefinedJavaClass(StreamExecutionEnvironment environment) { // 直接读取单个元素 DataStreamSource<String> data = environment.fromElements("Flink", "Spark", "Flink"); // sentence -> (word, 1) , 按空格切割,并计数 SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = data.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception { for (String word : value.split("\\s+")) { out.collect(new Tuple2<>(word, 1)); } } }); KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>() { @Override public String getKey(Tuple2<String, Integer> value) throws Exception { return value.f0; } }); SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedStream.sum(1); result.print(); } // 使用自定义class public static void fromDefinedClass(StreamExecutionEnvironment environment) { ArrayList<People> groups = new ArrayList<>(); groups.add(new People("April", 30)); groups.add(new People("Angie", 10)); groups.add(new People("Lucy", 18)); DataStreamSource<People> data = environment.fromCollection(groups); SingleOutputStreamOperator<People> filter = data.filter(new FilterFunction<People>() { @Override public boolean filter(People value) throws Exception { return value.age > 15; } }); filter.print(); } static class People{ String name; Integer age; public People(String name, Integer age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } @Override public String toString() { return "People{" + "name='" + name + '\'' + ", age=" + age + '}'; } } -
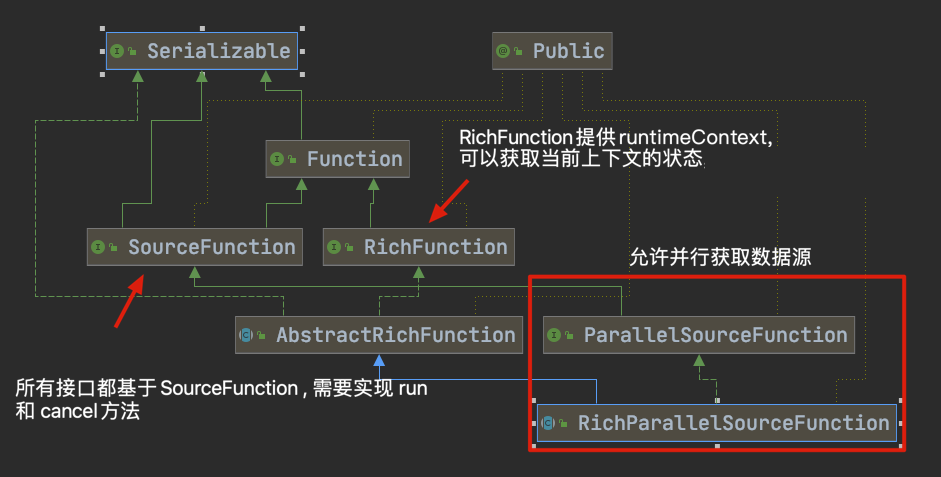
*自定义输入
 可以使用StreamExecutionEnvironment.addSource(sourceFunction)将一个流式数据源加到程序中。
可以使用StreamExecutionEnvironment.addSource(sourceFunction)将一个流式数据源加到程序中。
Flink提供了许多预先实现的源函数,但是也可以编写自己的自定义源,方法是为非并行源implements SourceFunction,或者为并行源 implements ParallelSourceFunction接口,或者extends RichParallelSourceFunction。Flink也提供了一批内置的Connector(连接器),如上表列了几个主要的
- kafka链接器
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.11</artifactId> <version>1.11.1</version> </dependency>StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "animal"; Properties props = new Properties(); props.setProperty("bootstrap.servers", "centos7-3:9092"); FlinkKafkaConsumer<String> stringFlinkKafkaConsumer = new FlinkKafkaConsumer<String>(topic, new SimpleStringSchema(), props); DataStreamSource<String> data = environment.addSource(stringFlinkKafkaConsumer); // sentence -> (word, 1) , 按空格切割,并计数 SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = data.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception { for (String word : value.split("\\s+")) { out.collect(new Tuple2<>(word, 1)); } } }); KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>() { @Override public String getKey(Tuple2<String, Integer> value) throws Exception { return value.f0; } }); SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedStream.sum(1); result.print(); environment.execute();# 后台启动kafka ./kafka-server-start.sh -daemon ../config/server.properties # 创建出题 ./kafka-topics.sh --zookeeper localhost:2181/mykafka --create --topic animal --replication-factor 1 --partitions 1 # 启动生产者 kafka-console-producer.sh --broker-list centos7-3:9092 --topic animal # 启动消费者 kafka-console-consumer.sh --bootstrap-server centos7-3:9092 --topic animal - 自定义类的关系
- kafka链接器
-
-
Transformation
-
类似spark的算子
-
window相关算子
- connect -> coMap
public class ConnectDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(2); DataStreamSource<String> data1 = env.addSource(new SourceFromParallelSource()); DataStreamSource<String> data2 = env.addSource(new SourceFromRichParallelSource()); // 合并连个数据流 ConnectedStreams<String, String> connected = data1.connect(data2); // comap, 合并输出,把并行的数据变成串行的 SingleOutputStreamOperator<String> mappedData = connected.map(new CoMapFunction<String, String, String>() { @Override public String map1(String value) throws Exception { return value + "_map1"; } @Override public String map2(String value) throws Exception { return value + "_map2"; } }); mappedData.print(); /** * 1> 0... from poor_map1 * 2> 0... from poor_map1 * 1> 0... from rich_map2 * 2> 0... from rich_map2 * 2> 1... from poor_map1 * 1> 1... from poor_map1 * 2> 1... from rich_map2 * 1> 1... from rich_map2 * 1> 2... from poor_map1 * 2> 2... from poor_map1 * 1> 2... from rich_map2 * 2> 2... from rich_map2 */ env.execute(); } } - split -> select
public class SplitSelectDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<Integer> data = env.fromElements(1, 2, 3, 4, 5, 6); SplitStream<Integer> splitStream = data.split(new OutputSelector<Integer>() { @Override public Iterable<String> select(Integer value) { // 给每个值加标签, 一个值可以加多个标签 ArrayList<String> output = new ArrayList<>(); if (value % 2 == 0) { output.add("even"); } else { output.add("odd"); } return output; } }); // select 选出包含对应标签的数据 DataStream<Integer> even = splitStream.select("even"); DataStream<Integer> odd = splitStream.select("odd"); DataStream<Integer> all = splitStream.select("odd", "even"); even.print(); /** * 1> 4 * 8> 2 * 2> 6 */ env.execute(); } }
-
-
Sink
-
writeAsText, writeAsCsv
-
print
-
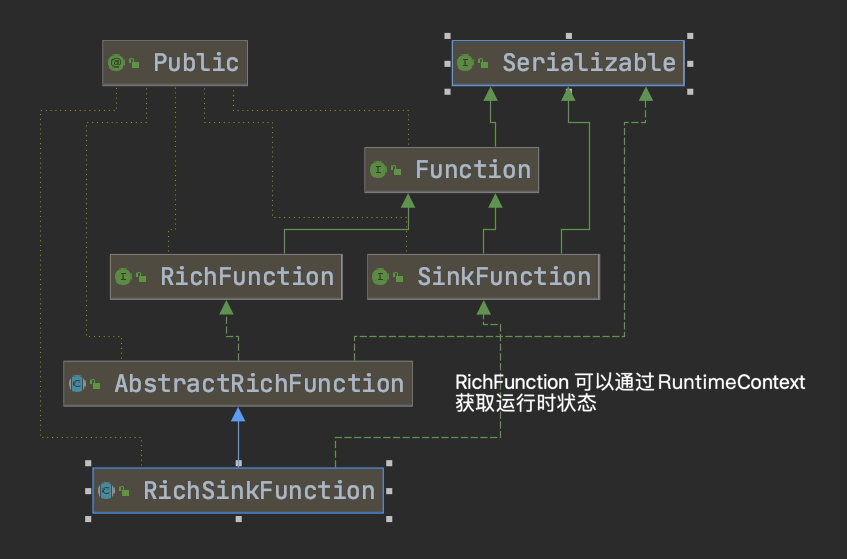
*自定义输出
-
ToRedis 依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-redis_2.11</artifactId> <version>1.1.5</version> </dependency>import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; public class MySinkToRedis { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> data = env.socketTextStream("centos7-3", 7777); SingleOutputStreamOperator<Tuple2<String, String>> m_word = data.map(new MapFunction<String, Tuple2<String, String>>() { @Override public Tuple2<String, String> map(String value) throws Exception { return new Tuple2<>("m_word", value); } }); // 定义redis服务器参数 FlinkJedisPoolConfig.Builder builder = new FlinkJedisPoolConfig.Builder(); builder.setHost("centos7-3"); builder.setPort(6379); FlinkJedisPoolConfig conf = builder.build(); RedisSink redisSink = new RedisSink(conf, new RedisMapper<Tuple2<String, String>>() { // 写入是运行的指令 @Override public RedisCommandDescription getCommandDescription() { return new RedisCommandDescription(RedisCommand.LPUSH); } // 获取写入的key @Override public String getKeyFromData(Tuple2<String, String> data) { return data.f0; } // 获取写入的value @Override public String getValueFromData(Tuple2<String, String> data) { return data.f1; } }); m_word.addSink(redisSink); env.execute(); } } - ToMySQL
import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; public class MySinkToMySql { static class Student { String name; Integer age; public Student(String name, Integer age) { this.name = name; this.age = age; } } static class MySQLSink extends RichSinkFunction<Student> { String url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC"; String user = "root"; String password = "h@ckingwithjava11"; Connection connection = null; PreparedStatement preparedStatement = null; @Override public void open(Configuration parameters) throws Exception { // 初始化环境 super.open(parameters); connection = DriverManager.getConnection(url, user, password); preparedStatement = connection.prepareStatement("insert into student (name,age) values(?,?)"); } @Override public void close() throws Exception { // 结束的之后关闭流 super.close(); preparedStatement.close(); connection.close(); } @Override public void invoke(Student value, Context context) throws Exception { // 触发写入, 逐行遍历 preparedStatement.setString(1, value.name); preparedStatement.setInt(2, value.age); preparedStatement.executeUpdate(); } } public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<Student> data = env.fromElements( new Student("April", 20), new Student("Angie", 30), new Student("Yarn", 40) ); // 下沉到MYSQL data.addSink(new MySQLSink()); env.execute(); } } -
ToKafka 依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.11</artifactId> <version>1.11.1</version> </dependency>import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; // socket -> kafka public class MySinkToKafka { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> data = env.socketTextStream("centos7-3", 7777); // 注入到kafka就是生产者 String brokerList = "centos7-3:9092"; String topic = "animal"; FlinkKafkaProducer producer = new FlinkKafkaProducer(brokerList, topic, new SimpleStringSchema()); data.addSink(producer); env.execute(); } } - 自定义类的关系
-
-
DataSet
DataSet批处理的算子和流处理基本一致
-
DataSource
-
基于集合fromCollection
-
基于文件readTextFile
-
-
Transformation
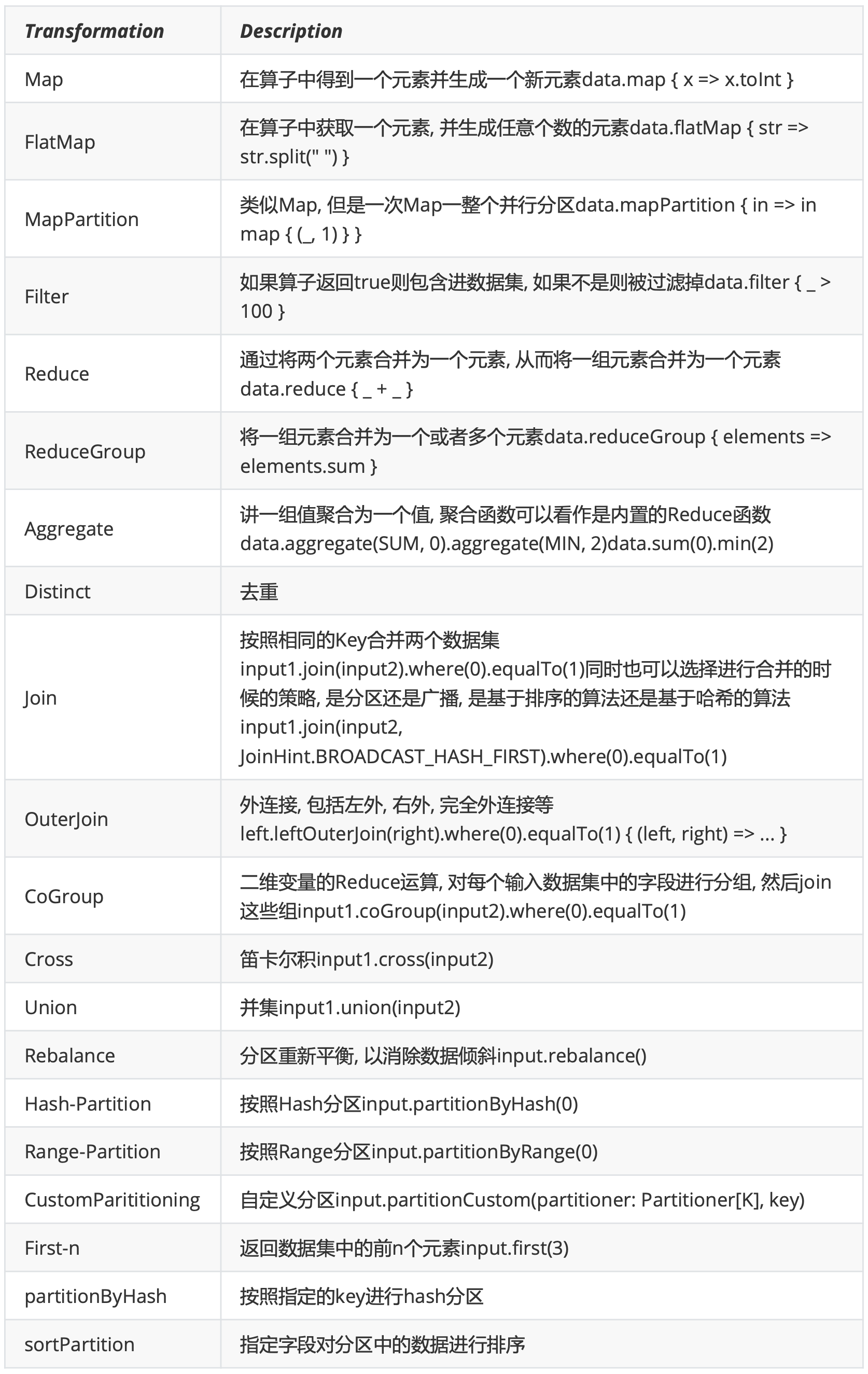 Flink针对DataSet也提供了大量的已经实现的算子,和DataStream计算很类似
Flink针对DataSet也提供了大量的已经实现的算子,和DataStream计算很类似 -
Sink
-
文件输出
-
writeAsText
-
writeAsCsv
-
-
print/printToErr
-
Table API和SQL_API
不论是批处理的DataFrame, 还是流处理的DataSet, 都可以转化成Table, 采用统计的处理方式. Table API and SQL目前尚未完全完善,还在积极的开发中,所以并不是所有的算子操作都可以通 过其实现。
- 用到的依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table</artifactId> <version>1.11.1</version> <type>pom</type> <scope>provided</scope> </dependency> <!-- Either... --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_2.12</artifactId> <version>1.11.1</version> <scope>provided</scope> </dependency> <!-- or... --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala-bridge_2.12</artifactId> <version>1.11.1</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_2.12</artifactId> <version>1.11.1</version> <scope>provided</scope> </dependency> - 案例
import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.SourceFunction; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.types.Row; import static org.apache.flink.table.api.Expressions.$; public class TableApiDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env); DataStreamSource<Tuple2<String, Integer>> data = env.addSource(new SourceFunction<Tuple2<String, Integer>>() { @Override public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception { while (true) { ctx.collect(new Tuple2<>("name", 20)); Thread.sleep(1000); } } @Override public void cancel() { } }); // 创建表, 设置schema Table table = tEnv.fromDataStream(data, $("name"),$("age")); // 选中name Table name = table.select($("name")); /** * The message will be encoded as {@link Tuple2}. The first field is a {@link Boolean} flag, * the second field holds the record of the specified type {@link T}. * * A true {@link Boolean} flag indicates an add message, a false flag indicates a retract message. */ // true 是新增数据, false就更新数据 DataStream<Tuple2<Boolean, Row>> tuple2DataStream = tEnv.toRetractStream(name, Row.class); // 值输出追加的数据 DataStream<Row> rowDataStream = tEnv.toAppendStream(name, Row.class); tuple2DataStream.print(); env.execute(); } }
Flink Window窗口机制
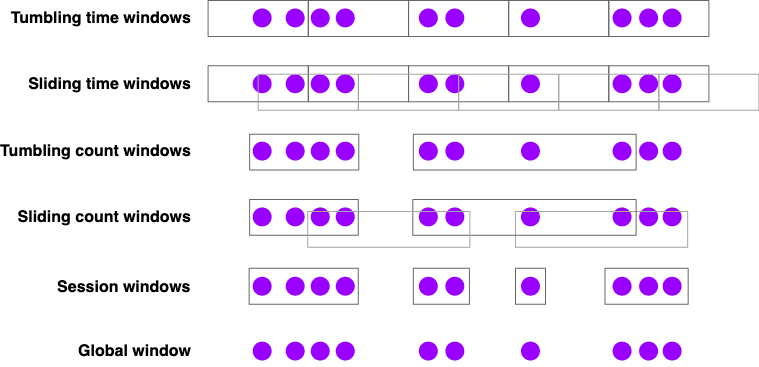
Flink认为Batch是Streaming的一个特例,因此Flink底层引擎是一个流式引擎,在上面实现了流处 理和批处理。而Window就是从Streaming到Batch的桥梁。
通俗讲,Window是用来对一个无限的流设置一个有限的集合,从而在有界的数据集上进行操作的 一种机制。流上的集合由Window来划定范围,比如“计算过去10分钟”或者“最后50个元素的和”。
Window可以由时间(Time Window)(比如每30s)或者数据(Count Window)(如每100个 元素)驱动。DataStream API提供了Time和Count的Window。
Flink要操作窗口,先得将StreamSource 转成WindowedStream
翻滚窗口 (Tumbling Window, 无重叠)
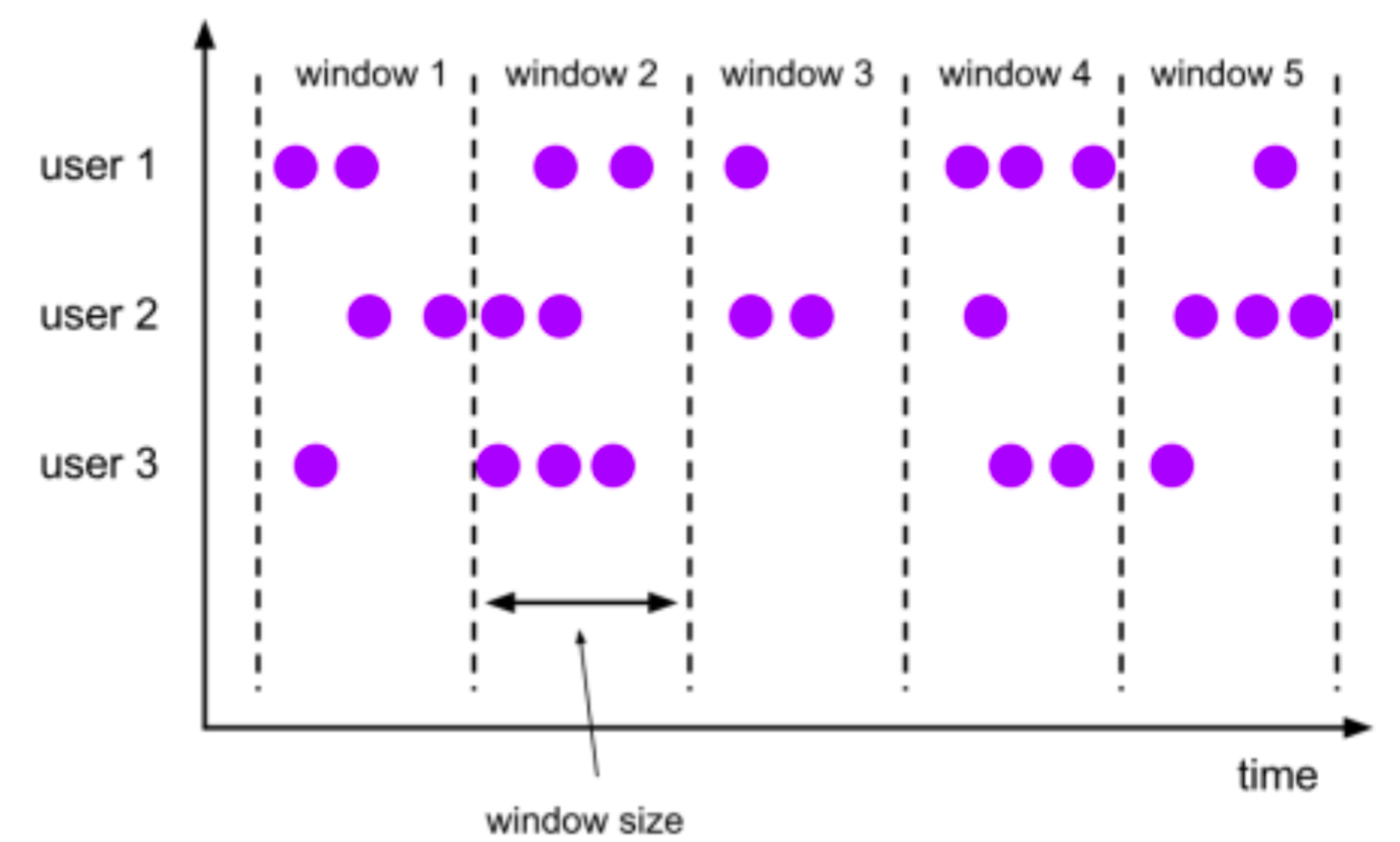
将数据依据固定的窗口长度对数据进行切分
特点:时间对齐,窗口长度固定,没有重叠
-
基于时间驱动 场景:我们需要统计每一分钟中用户购买的商品的总数,需要将用户的行为事件按每一分钟进行切 分,这种切分被成为翻滚时间窗口(Tumbling Time Window)
-
基于事件驱动 场景:当我们想要每100个用户的购买行为作为驱动,那么每当窗口中填满100个”相同”元素了,就 会对窗口进行计算。
滑动窗口 (Sliding Window, 有重叠)
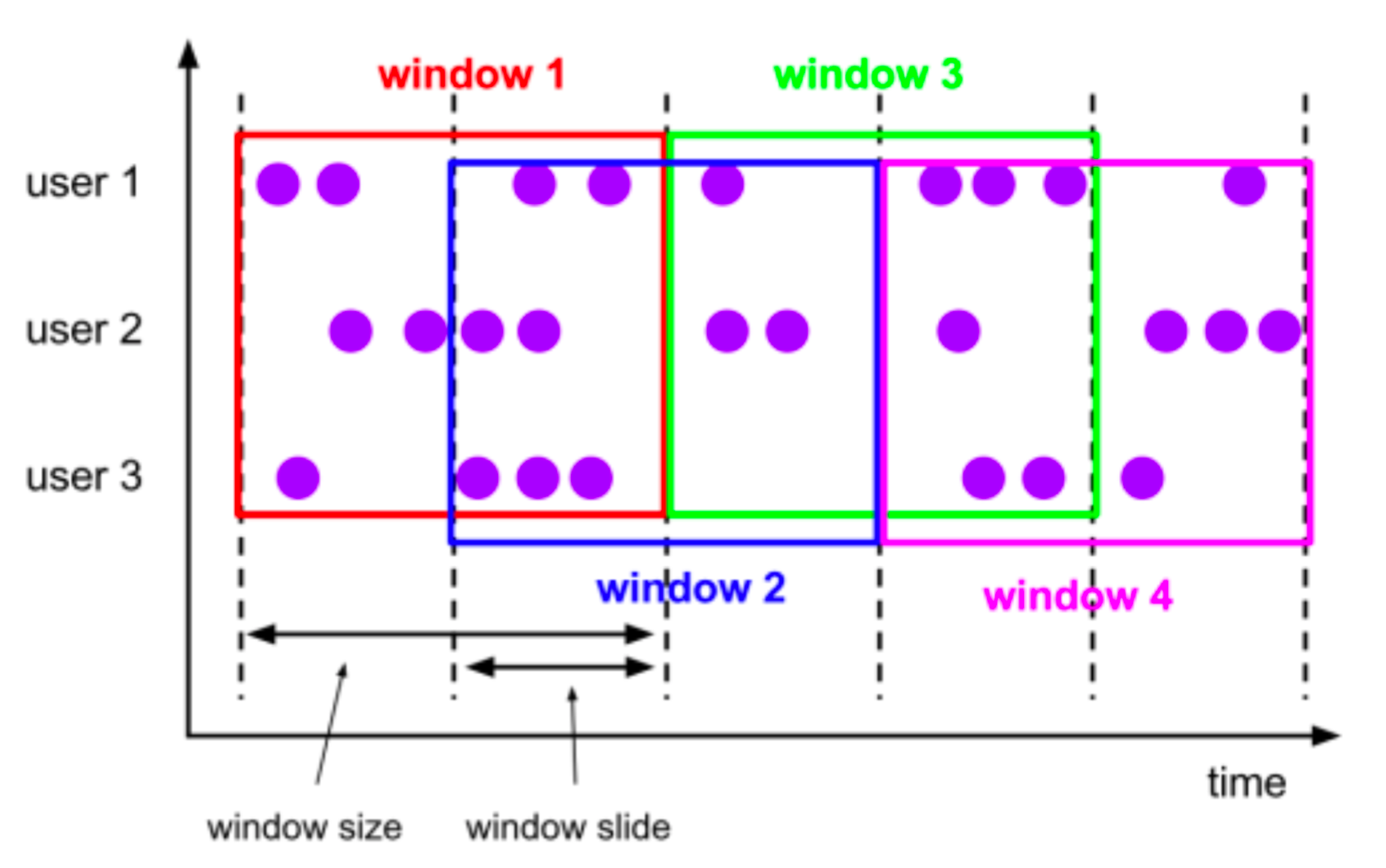
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
特点:窗口长度固定,可以有重叠
-
基于时间的滑动窗口 场景: 我们可以每30秒计算一次最近一分钟用户购买的商品总数
- 示例代码
import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.datastream.WindowedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.SourceFunction; import org.apache.flink.streaming.api.functions.windowing.WindowFunction; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.text.SimpleDateFormat; import java.util.Iterator; import java.util.Random; /** * 时间驱动 */ public class WindowDemo { static SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); public static void main(String[] args) throws Exception { // 1、获取流数据源 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> data = env.addSource(new SourceFunction<String>() { int count = 0; @Override public void run(SourceContext<String> ctx) throws Exception { while (true) { ctx.collect(count + " hao"); count++; Thread.sleep(1000); } } @Override public void cancel() { } }); // 2、获取窗口 SingleOutputStreamOperator<Tuple3<String, String, String>> mapped = data.map(new MapFunction<String, Tuple3<String, String, String>>() { @Override public Tuple3<String, String, String> map(String value) throws Exception { long timeMillis = System.currentTimeMillis(); String dateStr = dateFormat.format(timeMillis); Random random = new Random(); int randomNum = random.nextInt(5); return new Tuple3<>(value, dateStr, String.valueOf(randomNum)); } }); KeyedStream<Tuple3<String, String, String>, String> tuple3StringKeyedStream = mapped.keyBy(value -> value.f0); // WindowedStream<Tuple3<String, String, String>, String, TimeWindow> timeWindow = tuple3StringKeyedStream.timeWindow(Time.seconds(5)); // 滑动窗口 WindowedStream<Tuple3<String, String, String>, String, TimeWindow> timeWindow = tuple3StringKeyedStream.timeWindow(Time.seconds(5), Time.seconds(2)); // 3、操作窗口数据 SingleOutputStreamOperator<String> applyed = timeWindow.apply(new WindowFunction<Tuple3<String, String, String>, String, String, TimeWindow>() { // WindowFunction<IN, OUT, KEY, W extends Window> // apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out) @Override public void apply(String s, TimeWindow window, Iterable<Tuple3<String, String, String>> input, Collector<String> out) throws Exception { Iterator<Tuple3<String, String, String>> iterator = input.iterator(); StringBuilder sb = new StringBuilder(); while (iterator.hasNext()) { Tuple3<String, String, String> next = iterator.next(); sb.append(next.f0 + "..." + next.f1 + "..." + next.f2); } String s1 = s + "..." + dateFormat.format(window.getStart()) + "..." + sb; out.collect(s1); } }); // 4、输出窗口数据 applyed.print(); env.execute(); } }
- 示例代码
-
基于事件的滑动窗口 场景: 每10个 “相同”元素计算一次最近100个元素的总和
- 示例代码
import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.datastream.WindowedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.WindowFunction; import org.apache.flink.streaming.api.windowing.windows.GlobalWindow; import org.apache.flink.util.Collector; import java.text.SimpleDateFormat; import java.util.Iterator; import java.util.Random; /** * 事件驱动 */ public class WindowDemoCount { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> data = env.socketTextStream("localhost", 7777); // 2、获取窗口 SingleOutputStreamOperator<Tuple3<String, String, String>> mapped = data.map(new MapFunction<String, Tuple3<String, String, String>>() { @Override public Tuple3<String, String, String> map(String value) throws Exception { long timeMillis = System.currentTimeMillis(); SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); String dateStr = dateFormat.format(timeMillis); Random random = new Random(); int randomNum = random.nextInt(5); return new Tuple3<>(value, dateStr, String.valueOf(randomNum)); } }); KeyedStream<Tuple3<String, String, String>, String> tuple3StringKeyedStream = mapped.keyBy(value -> value.f0); // 同一个key的数据, 收集够3个才会触发一次窗口事件 // WindowedStream<Tuple3<String, String, String>, String, GlobalWindow> countWindow = tuple3StringKeyedStream.countWindow(3); // 滑动窗口 WindowedStream<Tuple3<String, String, String>, String, GlobalWindow> countWindow = tuple3StringKeyedStream.countWindow(3, 2); // 3、操作窗口数据 SingleOutputStreamOperator<String> applyed = countWindow.apply(new WindowFunction<Tuple3<String, String, String>, String, String, GlobalWindow>() { @Override public void apply(String s, GlobalWindow window, Iterable<Tuple3<String, String, String>> input, Collector<String> out) throws Exception { Iterator<Tuple3<String, String, String>> iterator = input.iterator(); StringBuilder sb = new StringBuilder(); while (iterator.hasNext()) { Tuple3<String, String, String> next = iterator.next(); sb.append(next.f0 + "..." + next.f1 + "..." + next.f2); } String s1 = s + "..." + sb; out.collect(s1); } }); // 4、输出窗口数据 applyed.print(); /** * 4> 1...1...2021-05-26 20:00:25.157...41...2021-05-26 20:00:40.929...21...2021-05-26 20:00:41.344...2 * 2> 2...2...2021-05-26 20:00:25.565...22...2021-05-26 20:00:59.287...02...2021-05-26 20:01:02.307...0 * 3> 3...3...2021-05-26 20:00:25.982...23...2021-05-26 20:01:00.956...43...2021-05-26 20:01:03.033...1 */ env.execute(); } }
- 示例代码
会话窗口 (Session Window, 活动间隙)
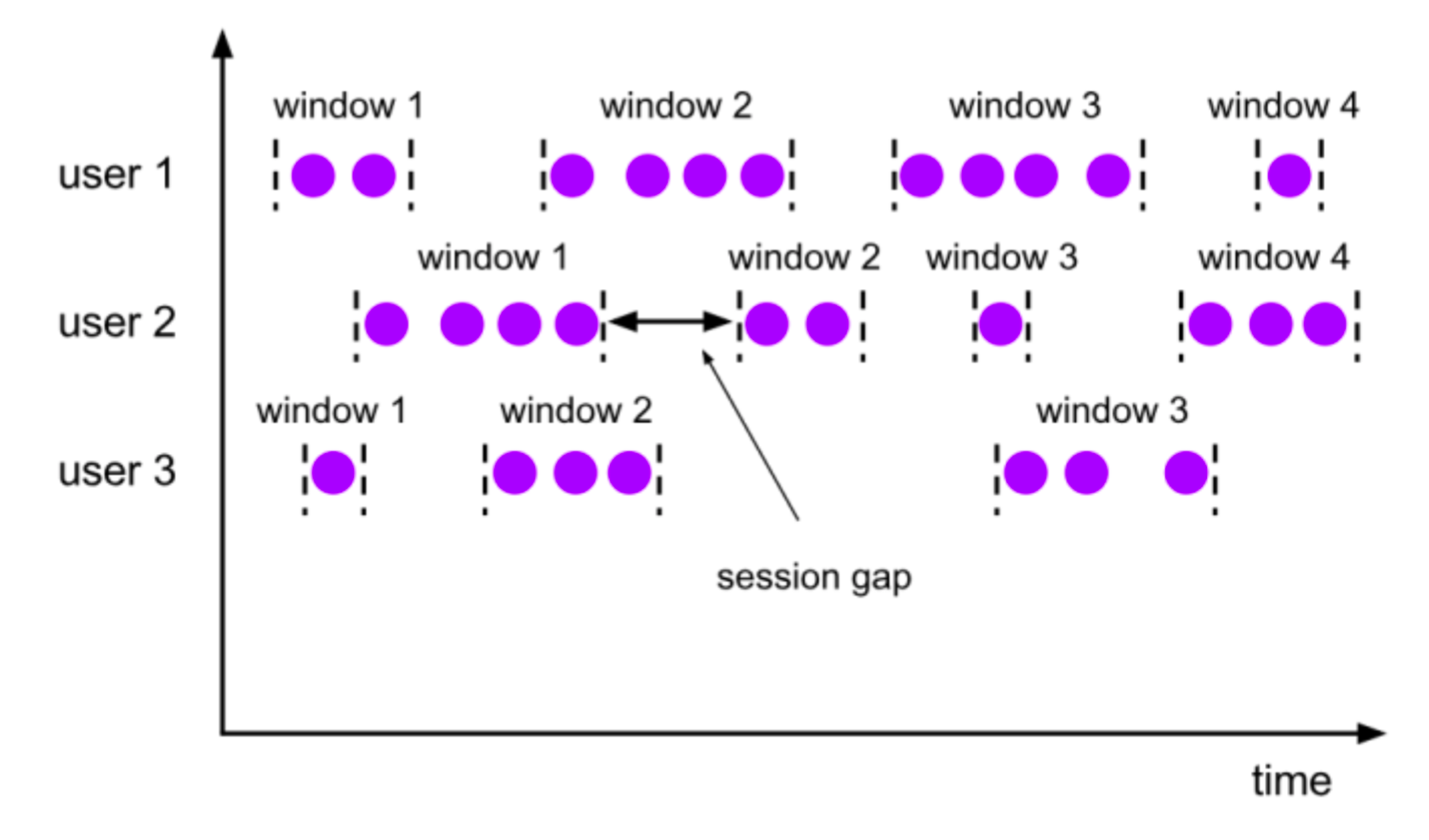
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段 时间没有接收到新数据就会生成新的窗口。
session窗口分配器通过session活动来对元素进行分组,session窗口跟滚动窗口和滑动窗口相比,不 会有重叠和固定的开始时间和结束时间的情况
session窗口在一个固定的时间周期内不再收到元素,即非活动间隔产生,那么这个窗口就会关闭。
一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的长度,当这个非
活跃周期产生,那么当前的session将关闭并且后续的元素将被分配到新的session窗口中去。
特点
会话窗口不重叠,没有固定的开始和结束时间
与翻滚窗口和滑动窗口相反, 当会话窗口在一段时间内没有接收到元素时会关闭会话窗口。
后续的元素将会被分配给新的会话窗口
场景
计算每个用户在活跃期间总共购买的商品数量,如果用户30秒没有活动则视为会话断开
- 示例代码
import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.datastream.WindowedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.WindowFunction; import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; public class WindowDemoSession { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> data = env.socketTextStream("localhost", 7777); KeyedStream<String, String> keyByed = data.map(value -> value).keyBy(value -> value); WindowedStream<String, String, TimeWindow> sessionWindow = keyByed.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))); // key相同,且在session时间内的事件会被视为一个session SingleOutputStreamOperator<String> applyed = sessionWindow.apply(new WindowFunction<String, String, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<String> input, Collector<String> out) throws Exception { StringBuilder stringBuilder = new StringBuilder(); input.forEach(value -> stringBuilder.append(value)); out.collect(stringBuilder.toString()); } }); applyed.print(); env.execute(); } }
全局窗口GlobalWindow
window实现
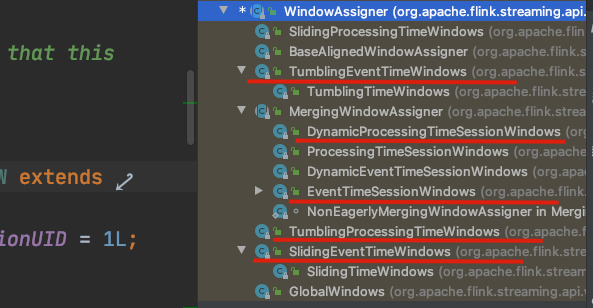
所有windowStream都是通过KeyedStream 如下方法创建的
public <W extends Window> WindowedStream<T, KEY, W> window(WindowAssigner<? super T, W> assigner) {
return new WindowedStream<>(this, assigner);
}
WindowAssigner 是一个抽象类, 用来如何根据时间和key把数据放到不同的窗口
Flink Time
Time
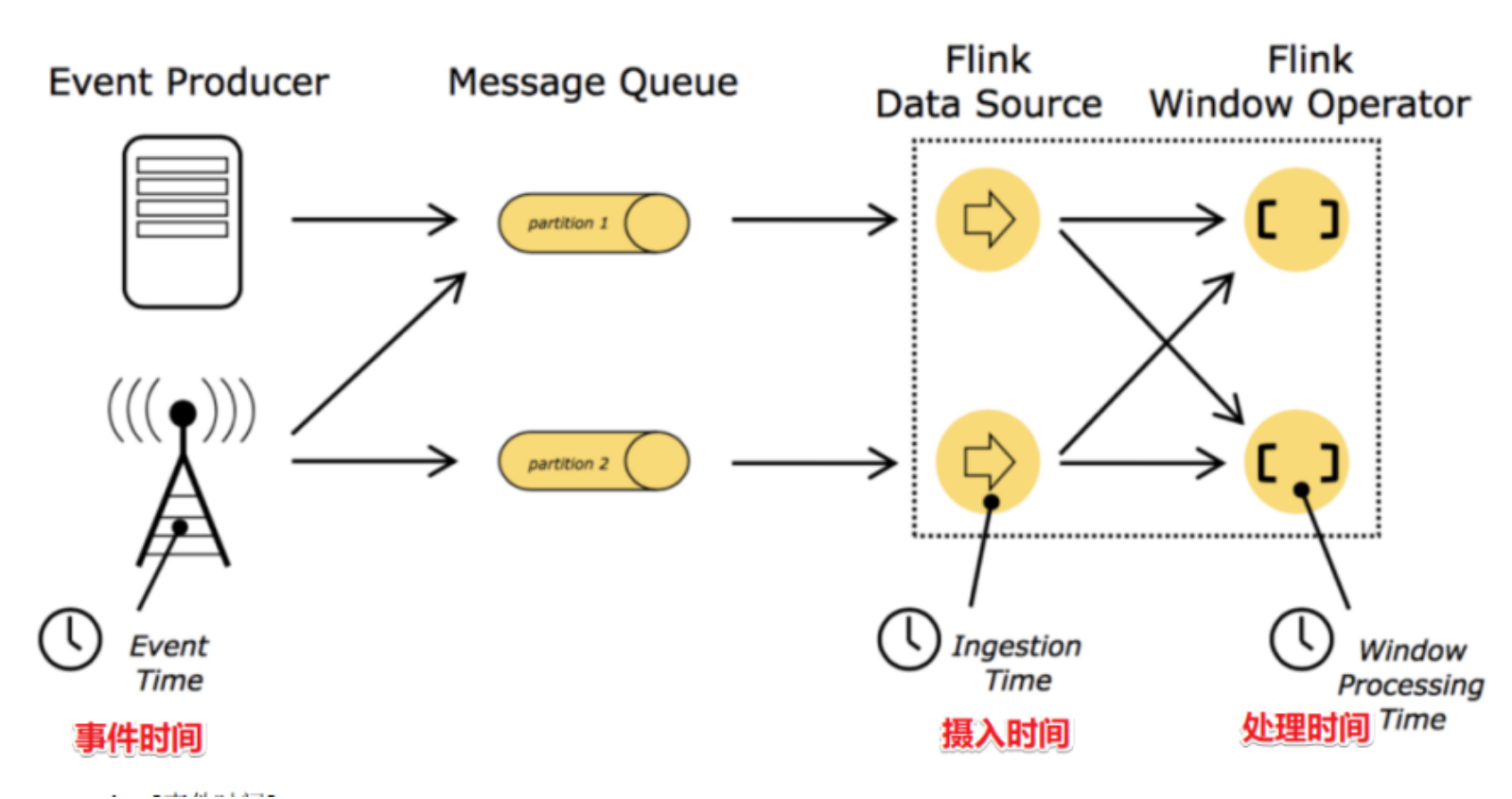
在Flink的流式处理中,会涉及到时间的不同概念
- EventTime[事件时间]: 事件发生的时间,例如:点击网站上的某个链接的时间,每一条日志都会记录自己的生成时间
如果以EventTime为基准来定义时间窗口那将形成EventTimeWindow,要求消息本身就应该携带 EventTime - IngestionTime[摄入时间]: 数据进入Flink的时间,如某个Flink节点的source operator接收到数据的时间,例如:某个source消费到kafka中的数据 如果以IngesingtTime为基准来定义时间窗口那将形成IngestingTimeWindow,以source的systemTime为准
- ProcessingTime[处理时间]: 某个Flink节点执行某个operation的时间,例如:timeWindow处理数据时的系统时间,默认的时间属性就是Processing Time
如果以ProcessingTime基准来定义时间窗口那将形成ProcessingTimeWindow,以operator的 systemTime为准
在Flink的流式处理中,绝大部分的业务都会使用EventTime,一般只在EventTime无法使用时,才会被迫使用ProcessingTime或者IngestionTime。
如果要使用EventTime,那么需要引入EventTime的时间属性,引入方式如下所示:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //设置使用事件时间
Watermark
水印(watermark)就是一个时间戳,Flink可以给数据流添加水印, 可以理解为:收到一条消息后,额外给这个消息添加了一个等待时间,这就是添加水印。
- 水印并不会影响原有Eventtime事件时间
- 当数据流添加水印后,会按照水印时间来触发窗口计算
也就是说watermark水印是用来触发窗口计算的 - 一般会设置水印时间,比事件时间小几秒钟,表示最大允许数据延迟达到多久(即水印时间 = 事件时间 - 允许延迟时间)10:09:57 = 10:10:00 - 3s
-
当接收到的 水印时间 >= 窗口结束时间,则触发计算 如等到一条数据的水印时间为10:10:00 >= 10:10:00 才触发计算,也就是要等到事件时间为10:10:03的数据到来才触发计算
-
示例代码 步骤:
1、获取数据源
2、转化
3、声明水印(watermark)
4、分组聚合,调用window的操作
5、保存处理结果import org.apache.flink.api.common.eventtime.*; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.TimeCharacteristic; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.datastream.WindowedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.WindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.text.SimpleDateFormat; import java.util.ArrayList; import java.util.Collections; import java.util.Iterator; /** * 数据源: * 01,1586489566000 * 01,1586489567000 * 01,1586489568000 * 01,1586489569000 * 01,1586489570000 * 01,1586489571000 * 01,1586489572000 * 01,1586489573000 * 01,1586489574000 * 01,1586489575000 * 01,1586489576000 * 01,1586489577000 * 01,1586489578000 * 01,1586489579000 */ public class WatermarkDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设定使用eventTime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); // 每秒固定生成一个水印 env.getConfig().setAutoWatermarkInterval(1000L); // 并行度 env.setParallelism(1); // 从socket接收数据 DataStreamSource<String> data = env.socketTextStream("localhost", 7777); SingleOutputStreamOperator<Tuple2<String, Long>> maped = data.map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String value) throws Exception { String[] split = value.split(","); return new Tuple2<String, Long>(split[0], Long.valueOf(split[1])); } }); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); // 设置水印 SingleOutputStreamOperator<Tuple2<String, Long>> watermarks = maped.assignTimestampsAndWatermarks(new WatermarkStrategy<Tuple2<String, Long>>() { @Override public WatermarkGenerator<Tuple2<String, Long>> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new WatermarkGenerator<Tuple2<String, Long>>() { private long maxTimeStamp = 0L; private long maxOutOfOrderness = 3000l; @Override public void onEvent(Tuple2<String, Long> event, long eventTimestamp, WatermarkOutput output) { // 记录当前最大eventTime maxTimeStamp = Math.max(maxTimeStamp, event.f1); System.out.println("maxTimeStamp:" + maxTimeStamp + "...format:" + sdf.format(maxTimeStamp)); // 每次收到一条数据就生成水印 // output.emitWatermark(new Watermark(maxTimeStamp - maxOutOfOrderness)); } @Override public void onPeriodicEmit(WatermarkOutput output) { // System.out.println(".....onPeriodicEmit...."); // 周期性的生成水印 output.emitWatermark(new Watermark(maxTimeStamp - maxOutOfOrderness)); } }; } // 设置eventTime的字段 }.withTimestampAssigner((element, recordTimestamp) -> element.f1)); // 数据间隔大的话,建议每收到一条数据生成水印, 数据间隔小且数据量大,建议周期性生成水印 KeyedStream<Tuple2<String, Long>, String> keyed = watermarks.keyBy(value -> value.f0); // 使用eventTime窗口 WindowedStream<Tuple2<String, Long>, String, TimeWindow> windowed = keyed.window(TumblingEventTimeWindows.of(Time.seconds(4))); SingleOutputStreamOperator<String> result = windowed.apply(new WindowFunction<Tuple2<String, Long>, String, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple2<String, Long>> input, Collector<String> out) throws Exception { System.out.println("..." + sdf.format(window.getStart())); String key = s; Iterator<Tuple2<String, Long>> iterator = input.iterator(); ArrayList<Long> list = new ArrayList<>(); while (iterator.hasNext()) { Tuple2<String, Long> next = iterator.next(); list.add(next.f1); } Collections.sort(list); String result = "key:" + key + "..." + "list.size:" + list.size() + "...list.first:" + sdf.format(list.get(0)) + "...list.last:" + sdf.format(list.get(list.size() - 1)) + "...window.start:" + sdf.format(window.getStart()) + "..window.end:" + sdf.format(window.getEnd()); out.collect(result); } }); result.print(); env.execute(); } } - 需要注意的点
1.窗口是左闭右开的,形式为:[window_start_time,window_end_time)。
2.Window的设定基于第一条消息的事件时间,也就是说,Window会一直按照指定的时间间隔进行划分,不论这个Window中有没有数据,EventTime在这个Window期间的数据会进入这个Window。
3.Window会不断产生,属于这个Window范围的数据会被不断加入到Window中,所有未被触发的 Window都会等待触发,只要Window还没触发,属于这个Window范围的数据就会一直被加入到 Window中,直到Window被触发才会停止数据的追加,而当Window触发之后才接受到的属于被触发 Window的数据会被丢弃。(可以用队列记录被丢弃的数据)
4.Window会在以下的条件满足时被触发执行:
(1)在[window_start_time,window_end_time)窗口中有数据存在
(2)watermark时间 >=window_end_time;
5.一般会设置水印时间,比事件时间小几秒钟,表示最大允许数据延迟达到多久
Flink的State
用来保存计算结果或缓存数据。
状态类型
Flink根据是否需要保存中间结果,把计算分为有状态计算和无状态计算
-
无状态计算 独立的
-
有状态计算 依赖之前或之后的事件, 根据数据结构不同,Flink定义了多种state,应用于不同的场景
-
ValueState 即类型为T的单值状态。这个状态与对应的key绑定,是最简单的状态了。它可以通过 update 方法更新状态值,通过 value() 方法获取状态值。
-
ListState 即key上的状态值为一个列表。可以通过 add 方法往列表中附加值;也可以通过 get() 方法返回一个 Iterable
来遍历状态值。 -
ReducingState 这种状态通过用户传入的reduceFunction,每次调用 add 方法添加值的时候, 会调用reduceFunction,最后合并到一个单一的状态值。
-
FoldingState 跟ReducingState有点类似,不过它的状态值类型可以与 add 方法中传入的元素类 型不同(这种状态将会在Flink未来版本中被删除)。
-
MapState 即状态值为一个map。用户通过 put 或 putAll 方法添加元素
-
按key划分
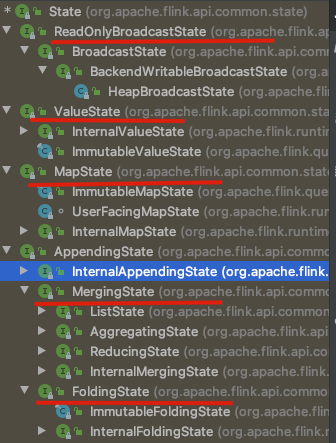
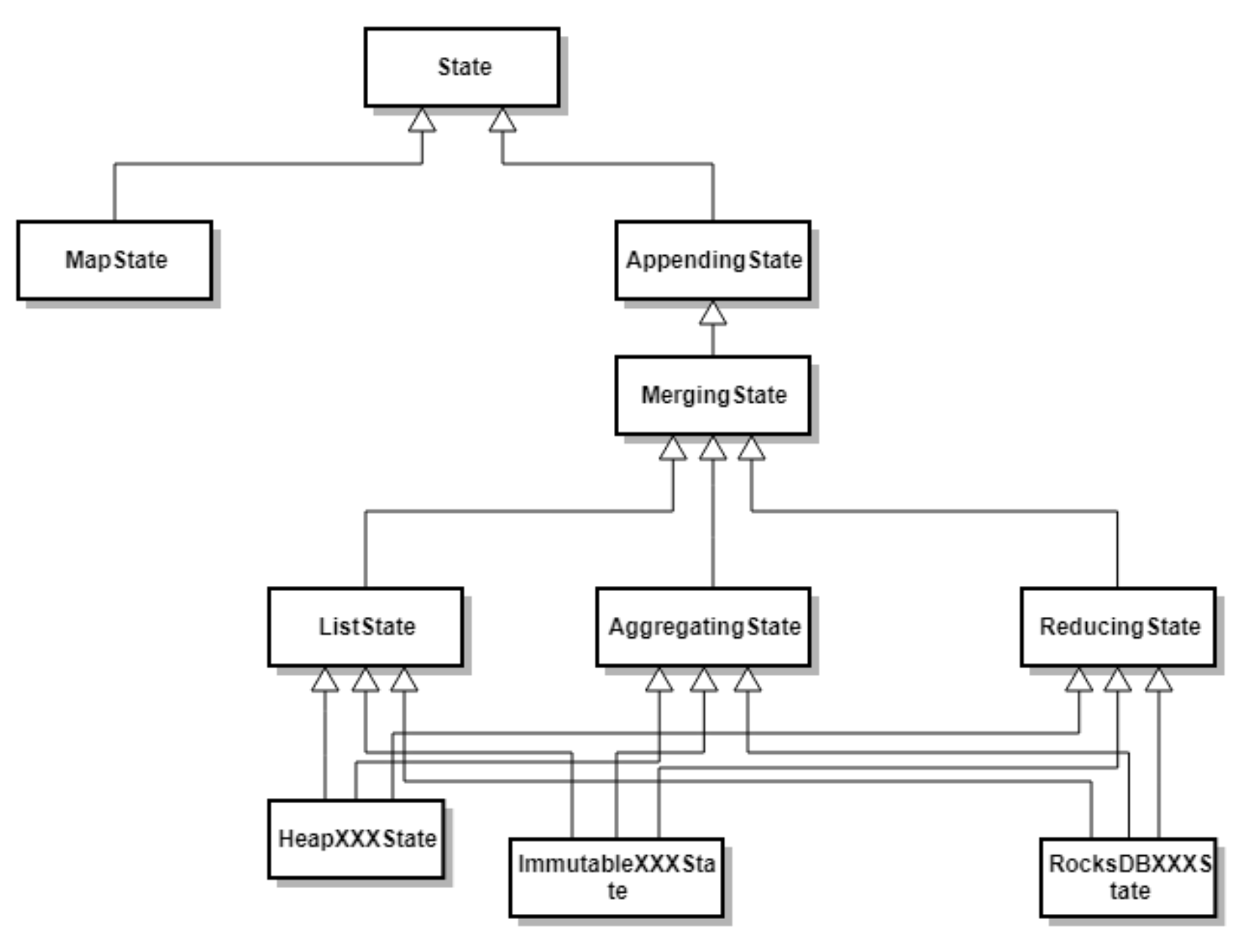 State按照是否有key划分为KeyedState和OperatorState
State按照是否有key划分为KeyedState和OperatorState-
KeyedState
FunctionInitializationContext.getKeyedStateStore()
KeyedStream流上的每一个Key都对应一个State. 表示和Key相关的一种State,只能用于KeydStream类型数据集对应的Functions和 Operators之上。 Keyed State是 Operator State的特例,区别在于 Keyed State 事先按照key对数据集进行了分区,每个 Key State 仅对应ー个 Operator和Key的组合。Keyed State可以通过 Key Groups 进行管理,主要用于 当算子并行度发生变化时,自动重新分布Keyed State数据。在系统运行过程中,一个Keyed算子实例 可能运行一个或者多个Key Groups的keys。-
案例: \\<br> 1、读数据源
2、将数据源根据key分组
3、按照key分组策略,对流式数据调用状态化处理import org.apache.flink.api.common.functions.RichFlatMapFunction; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.api.common.typeinfo.TypeHint; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class MyStateDemo { public static void main(String[] args) throws Exception { // (1,3)(1,5)(1,7)(1,4)(1,2) StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(2000); SingleOutputStreamOperator<Tuple2<Integer, Integer>> data = env.fromElements( new Tuple2<>(1, 3), new Tuple2<>(1, 5), new Tuple2<>(1, 7), new Tuple2<>(1, 4), new Tuple2<>(1, 2) ); KeyedStream<Tuple2<Integer, Integer>, Integer> keyed = data.keyBy(value -> value.f0); SingleOutputStreamOperator<Tuple2<Integer, Integer>> flatmapped = keyed.flatMap(new RichFlatMapFunction<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>() { // 缓存value ValueState<Tuple2<Integer, Integer>> sumState = null; @Override public void open(Configuration parameters) throws Exception { // 定义value state的数据类型, name是存储state的key ValueStateDescriptor<Tuple2<Integer, Integer>> desc = new ValueStateDescriptor<>( "average", TypeInformation.of(new TypeHint<Tuple2<Integer, Integer>>() {}), Tuple2.of(0, 0) ); sumState = getRuntimeContext().getState(desc); super.open(parameters); } @Override public void flatMap(Tuple2<Integer, Integer> value, Collector<Tuple2<Integer, Integer>> out) throws Exception { Tuple2<Integer, Integer> currentSum = sumState.value(); currentSum.f0 += 1; currentSum.f1 += value.f1; sumState.update(currentSum); // 每收到两个数,输出一次它们的平均值 if (currentSum.f0 == 2) { out.collect(new Tuple2<>(value.f0, currentSum.f1 / currentSum.f0)); sumState.clear(); } } }); flatmapped.print(); env.execute(); } }
-
-
OperatorState
FunctionInitializationContext.getOperatorStateStore()
与 Keyed State不同的是, Operator State只和并行的算子实例绑定,和数据元素中的key无关,每个 算子实例中持有所有数据元素中的一部分状态数据。Operator State支持当算子实例并行度发生变化时 自动重新分配状态数据。同时在 Flink中 Keyed State和 Operator State均具有两种形式,其中一种为托管状态( Managed State)形式,由 Flink Runtime中控制和管理状态数据,并将状态数据转换成为内存 Hash tables或 ROCKSDB的对象存储,然后将这些状态数据通过内部的接口持久化到 Checkpoints 中,任务异常时可 以通过这些状态数据恢复任务。另外一种是原生状态(Raw State)形式,由算子自己管理数据结构, 当触发 Checkpoint过程中, Flink并不知道状态数据内部的数据结构,只是将数据转换成bys数据存储 在 Checkpoints中,当从Checkpoints恢复任务时,算子自己再反序列化出状态的数据结构。 Datastream API支持使用 Managed State和 Raw State两种状态形式,在 Flink中推荐用户使用 Managed State管理状态数据,主要原因是 Managed State 能够更好地支持状态数据的重平衡以及更 加完善的内存管理。
- 案例: 使用OperatorState异常恢复
- 设置StreamExecutionEnvironment.enableCheckpointing
- 需要异常恢复的operator实现CheckpointedFunction
StateDemo
import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.functions.RichFlatMapFunction; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.api.common.typeinfo.TypeHint; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class StateDemo { public static void main(String[] args) throws Exception { // (1,3)(1,5)(1,7)(1,4)(1,2) StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置checkpoint env.enableCheckpointing(2000); SingleOutputStreamOperator<Tuple2<Integer, Integer>> data = env.socketTextStream("localhost", 7777).map(new MapFunction<String, Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> map(String value) throws Exception { String[] strings = value.split(","); return new Tuple2<>(Integer.valueOf(strings[0]), Integer.valueOf(strings[1])); } }); KeyedStream<Tuple2<Integer, Integer>, Integer> keyed = data.keyBy(value -> value.f0); SingleOutputStreamOperator<Tuple2<Integer, Integer>> flatmapped = keyed.flatMap(new RichFlatMapFunction<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>() { ValueState<Tuple2<Integer, Integer>> sumState = null; @Override public void open(Configuration parameters) throws Exception { ValueStateDescriptor<Tuple2<Integer, Integer>> desc = new ValueStateDescriptor<>( "average", TypeInformation.of(new TypeHint<Tuple2<Integer, Integer>>() { }), Tuple2.of(0, 0) ); sumState = getRuntimeContext().getState(desc); super.open(parameters); } @Override public void flatMap(Tuple2<Integer, Integer> value, Collector<Tuple2<Integer, Integer>> out) throws Exception { Tuple2<Integer, Integer> currentSum = sumState.value(); currentSum.f0 += 1; currentSum.f1 += value.f1; sumState.update(currentSum); if (currentSum.f0 == 2) { out.collect(new Tuple2<>(value.f0, currentSum.f1 / currentSum.f0)); sumState.clear(); } } }); flatmapped.addSink(new OperatorStateDemo(5)); env.execute(); } }OperatorStateDemo
import org.apache.flink.api.common.state.ListState; import org.apache.flink.api.common.state.ListStateDescriptor; import org.apache.flink.api.common.typeinfo.TypeHint; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.runtime.state.FunctionInitializationContext; import org.apache.flink.runtime.state.FunctionSnapshotContext; import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction; import org.apache.flink.streaming.api.functions.sink.SinkFunction; import java.util.ArrayList; import java.util.List; public class OperatorStateDemo implements SinkFunction<Tuple2<Integer, Integer>>, CheckpointedFunction { private ListState<Tuple2<Integer, Integer>> operatorState; private List<Tuple2<Integer, Integer>> bufferedElements; private Integer threshold; public OperatorStateDemo(Integer threshold) { this.threshold = threshold; this.bufferedElements = new ArrayList<>(); } /** * 快照状态,每次生成快照都触发 * 可以通过 StreamExecutionEnvironment.enableCheckpointing(2000) * 设置生成快照的周期 * @param context * @throws Exception */ @Override public void snapshotState(FunctionSnapshotContext context) throws Exception { System.out.println("-------------snapshotState--------------"); this.operatorState.clear(); for (Tuple2<Integer, Integer> element : bufferedElements) { this.operatorState.add(element); } } /** * 初始化的时候调用,每个subtask会调用一次,调用次数和并行度有关 * @param context * @throws Exception */ @Override public void initializeState(FunctionInitializationContext context) throws Exception { System.out.println("-----------------initializeState--------------------"); // create a state ListStateDescriptor<Tuple2<Integer, Integer>> operatorDemoDesc = new ListStateDescriptor<>( "operatorDemo", TypeInformation.of(new TypeHint<Tuple2<Integer, Integer>>() { }) ); operatorState = context.getOperatorStateStore().getListState(operatorDemoDesc); // 是否从异常中恢复 if (context.isRestored()) { for (Tuple2<Integer, Integer> element : operatorState.get()) { bufferedElements.add(element); } System.out.println("...context.isRestored"); } } // sinkFunction 的方法,每收到一条数据触发一次 @Override public void invoke(Tuple2<Integer, Integer> value, Context context) throws Exception { bufferedElements.add(value); // 收集threshold个数据之后,再一起输出 if (bufferedElements.size() == threshold) { // do something System.out.println("...out:" + bufferedElements); bufferedElements.clear(); } } }
- 案例: 使用OperatorState异常恢复
-
-
状态描述

State 既然是暴露给用户的,那么就需要有一些属性需要指定:state 名称、val serializer、state type info。在对应的statebackend中,会去调用对应的create方法获取到stateDescriptor中的值。Flink通 过 StateDescriptor 来定义一个状态。这是一个抽象类,内部定义了状态名称、类型、序列化器等基 础信息。与上面的状态对应,从 StateDescriptor 派生了 ValueStateDescriptor ,
ListStateDescriptor 等descriptor
- ValueState getState(ValueStateDescriptor)
- ReducingState getReducingState(ReducingStateDescriptor)
- ListState getListState(ListStateDescriptor)
- FoldingState getFoldingState(FoldingStateDescriptor)
- MapState getMapState(MapStateDescriptor)
广播状态
正常收到的数据只会在一个subtask,在一条线程上处理, 而广播状态会发送到所有subtask,所有线程上, 可以用来做模式匹配
- 案例: 行为模式匹配
- 定义两个输入流, 一个用来接收模式pattern, 一个用来就收动作action
- 缓存收到patterns, 缓存历史action
- 取出patterns和action进行匹配
public class MyPattern { private String firstAction; private String secondAction; … } public class UserAction { private Long userId; private String userAction; … } import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.state.*; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.BroadcastStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction; import org.apache.flink.util.Collector; public class BroadCastDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // DataStreamSource<UserAction> actions = env.fromElements( // new UserAction(1001L, "login"), // new UserAction(1002L, "pay"), // new UserAction(1003L, "car"), // new UserAction(1001L, "logout"), // new UserAction(1002L, "car"), // new UserAction(1003L, "logout") // ); // 广播变量输入之后再输入action数据 SingleOutputStreamOperator<UserAction> actions = env.socketTextStream("localhost", 7777).map(new MapFunction<String, UserAction>() { @Override public UserAction map(String value) throws Exception { String[] split = value.split(","); return new UserAction(Long.valueOf(split[0]), split[1]); } }); KeyedStream<UserAction, Long> keyedActions = actions.keyBy(value -> value.getUserId()); MyPattern pattern1 = new MyPattern("login", "logout"); MyPattern pattern2 = new MyPattern("car", "logout"); // DataStreamSource<MyPattern> patterns = env.fromElements(pattern1,pattern2); //在socket中先输入广播数据 SingleOutputStreamOperator<MyPattern> patterns = env.socketTextStream("localhost", 8888).map(new MapFunction<String, MyPattern>() { @Override public MyPattern map(String value) throws Exception { String[] split = value.split(","); return new MyPattern(split[0], split[1]); } }); // 生成广播流, MapStateDescriptor定义缓存广播state的数据类型 BroadcastStream<MyPattern> bcPatterns = patterns.broadcast(new MapStateDescriptor<>("patterns", Types.POJO(MyPattern.class), Types.VOID)); // 合并keyed stream 和 broadcast stream SingleOutputStreamOperator<Tuple2<Long, MyPattern>> process = keyedActions.connect(bcPatterns).process(new PatternEvaluator()); process.print(); /** * broadcastState...MyPattern{firstAction='car', secondAction='logout'} * broadcastState...MyPattern{firstAction='car', secondAction='logout'} * broadcastState...MyPattern{firstAction='car', secondAction='logout'} * broadcastState...MyPattern{firstAction='car', secondAction='logout'} * broadcastState...MyPattern{firstAction='car', secondAction='logout'} * broadcastState...MyPattern{firstAction='car', secondAction='logout'} * broadcastState...MyPattern{firstAction='car', secondAction='logout'} * broadcastState...MyPattern{firstAction='car', secondAction='logout'} * broadcastState...MyPattern{firstAction='login', secondAction='logout'} * broadcastState...MyPattern{firstAction='login', secondAction='logout'} * broadcastState...MyPattern{firstAction='login', secondAction='logout'} * broadcastState...MyPattern{firstAction='login', secondAction='logout'} * broadcastState...MyPattern{firstAction='login', secondAction='logout'} * broadcastState...MyPattern{firstAction='login', secondAction='logout'} * broadcastState...MyPattern{firstAction='login', secondAction='logout'} * broadcastState...MyPattern{firstAction='login', secondAction='logout'} * processElement...UserAction{userId=1001, userAction='login'} * processElement...UserAction{userId=1002, userAction='pay'} * processElement...UserAction{userId=1003, userAction='car'} * 5> (1001,MyPattern{firstAction='login', secondAction='logout'}) * processElement...UserAction{userId=1001, userAction='logout'} * processElement...UserAction{userId=1002, userAction='car'} * 3> (1003,MyPattern{firstAction='car', secondAction='logout'}) * processElement...UserAction{userId=1003, userAction='logout'} */ env.execute(); } public static class PatternEvaluator extends KeyedBroadcastProcessFunction<Long, UserAction, MyPattern, Tuple2<Long, MyPattern>> { ValueState<String> lastActionState; // 初始化方法 @Override public void open(Configuration parameters) throws Exception { lastActionState = getRuntimeContext().getState(new ValueStateDescriptor<String>("lastAction", Types.STRING)); } // 处理数据流, 模式匹配 @Override public void processElement(UserAction value, ReadOnlyContext ctx, Collector<Tuple2<Long, MyPattern>> out) throws Exception { ReadOnlyBroadcastState<MyPattern, Void> patterns = ctx.getBroadcastState(new MapStateDescriptor<>("patterns", Types.POJO(MyPattern.class), Types.VOID)); String lastAction = lastActionState.value(); if (lastAction != null && value.getUserAction() != null) { MyPattern pat = new MyPattern(lastAction, value.getUserAction()); if (patterns.contains(pat)) { // System.out.println("user:" + value.getUserId() + "....match:" + myPattern); out.collect(new Tuple2<>(ctx.getCurrentKey(), pat)); } } lastActionState.update(value.getUserAction()); System.out.println("processElement..."+value); } // 缓存广播量 @Override public void processBroadcastElement(MyPattern value, Context ctx, Collector<Tuple2<Long, MyPattern>> out) throws Exception { BroadcastState<MyPattern, Void> broadcastState = ctx.getBroadcastState(new MapStateDescriptor<>("patterns", Types.POJO(MyPattern.class), Types.VOID)); broadcastState.put(value, null); System.out.println("broadcastState..."+value); } } }
状态存储
- Memory State Backend
MemoryStateBackend 将工作状态数据保存在 taskmanager 的 java 内存中。key/value 状态和 window 算子使用哈希表存储数值和触发器。进行快照时(checkpointing),生成的快照数据将和 checkpoint ACK 消息一起发送给 jobmanager,jobmanager 将收到的所有快照保存在 java 内存中。 MemoryStateBackend 现在被默认配置成异步的,这样避免阻塞主线程的 pipline 处理。 MemoryStateBackend 的状态存取的速度都非常快,但是不适合在生产环境中使用。这是因为 MemoryStateBackend 有以下限制:
- 每个 state 的默认大小被限制为 5 MB(这个值可以通过 MemoryStateBackend 构造函数设置) * 每个 task 的所有 state 数据 (一个 task 可能包含一个 pipline 中的多个 Operator) 大小不能超过 RPC 系统的帧大小(akka.framesize,默认 10MB)
-
jobmanager 收到的 state 数据总和不能超过 jobmanager 内存
- 适合的场景
- 本地开发和调试
- 状态很小的作业
- 适合的场景
- File System (FS) State Backend
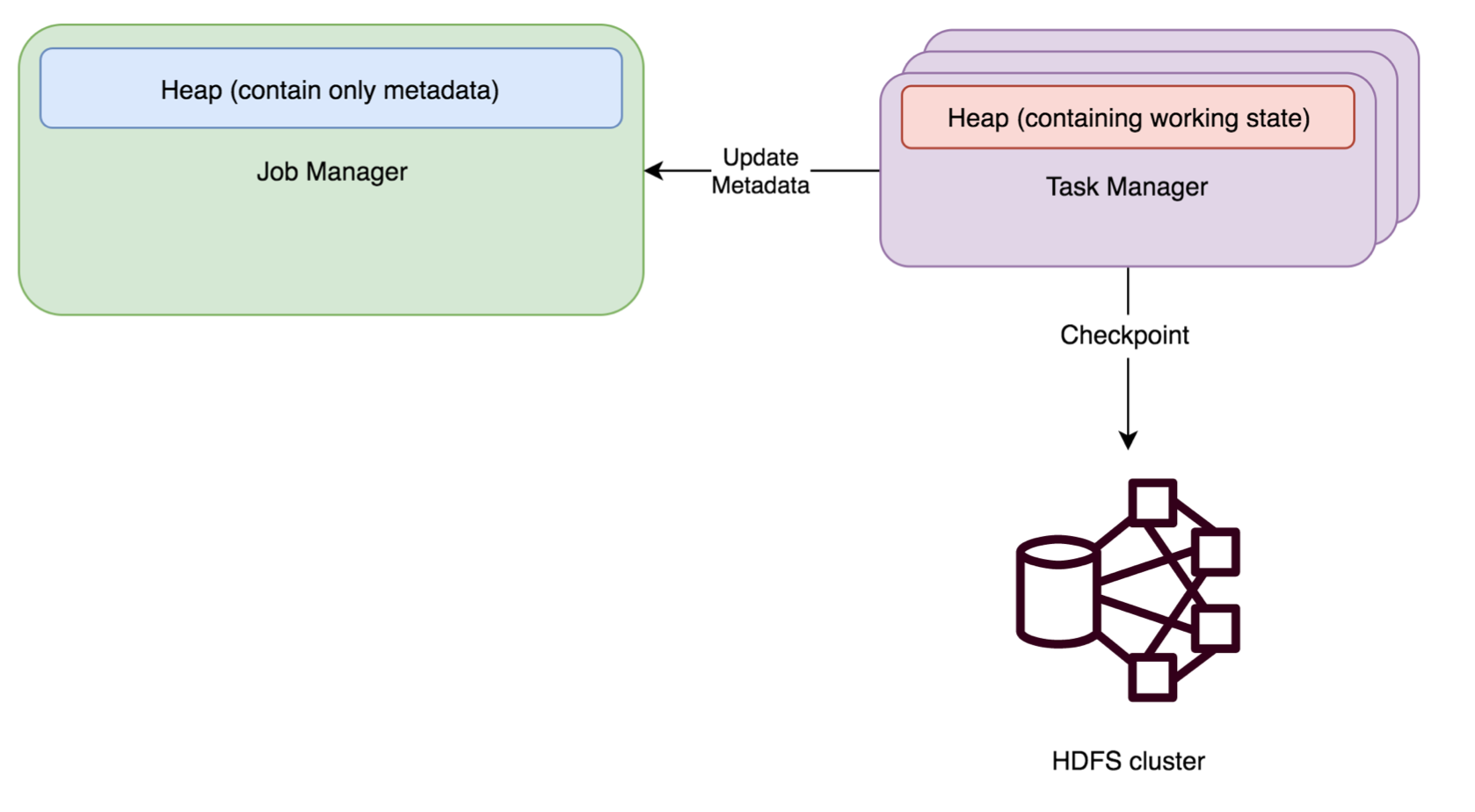 FsStateBackend 需要配置一个 checkpoint 路径,例如“hdfs://namenode:40010/flink/checkpoints” 或者 “file:///data/flink/checkpoints”,我们一般配置为 hdfs 目录
FsStateBackend 需要配置一个 checkpoint 路径,例如“hdfs://namenode:40010/flink/checkpoints” 或者 “file:///data/flink/checkpoints”,我们一般配置为 hdfs 目录
FsStateBackend 将工作状态数据保存在 taskmanager 的 java 内存中。进行快照时,再将快照数据写 入上面配置的路径,然后将写入的文件路径告知 jobmanager。jobmanager 中保存所有状态的元数据 信息(在 HA 模式下,元数据会写入 checkpoint 目录)。
FsStateBackend 默认使用异步方式进行快照,防止阻塞主线程的 pipline 处理。可以通过 FsStateBackend 构造函数取消该模式:new FsStateBackend(path, false);- 适合的场景
- 大状态、长窗口、大键值(键或者值很大)状态的作业
- 适合高可用方案
- 适合的场景
- RocksDB State Backend
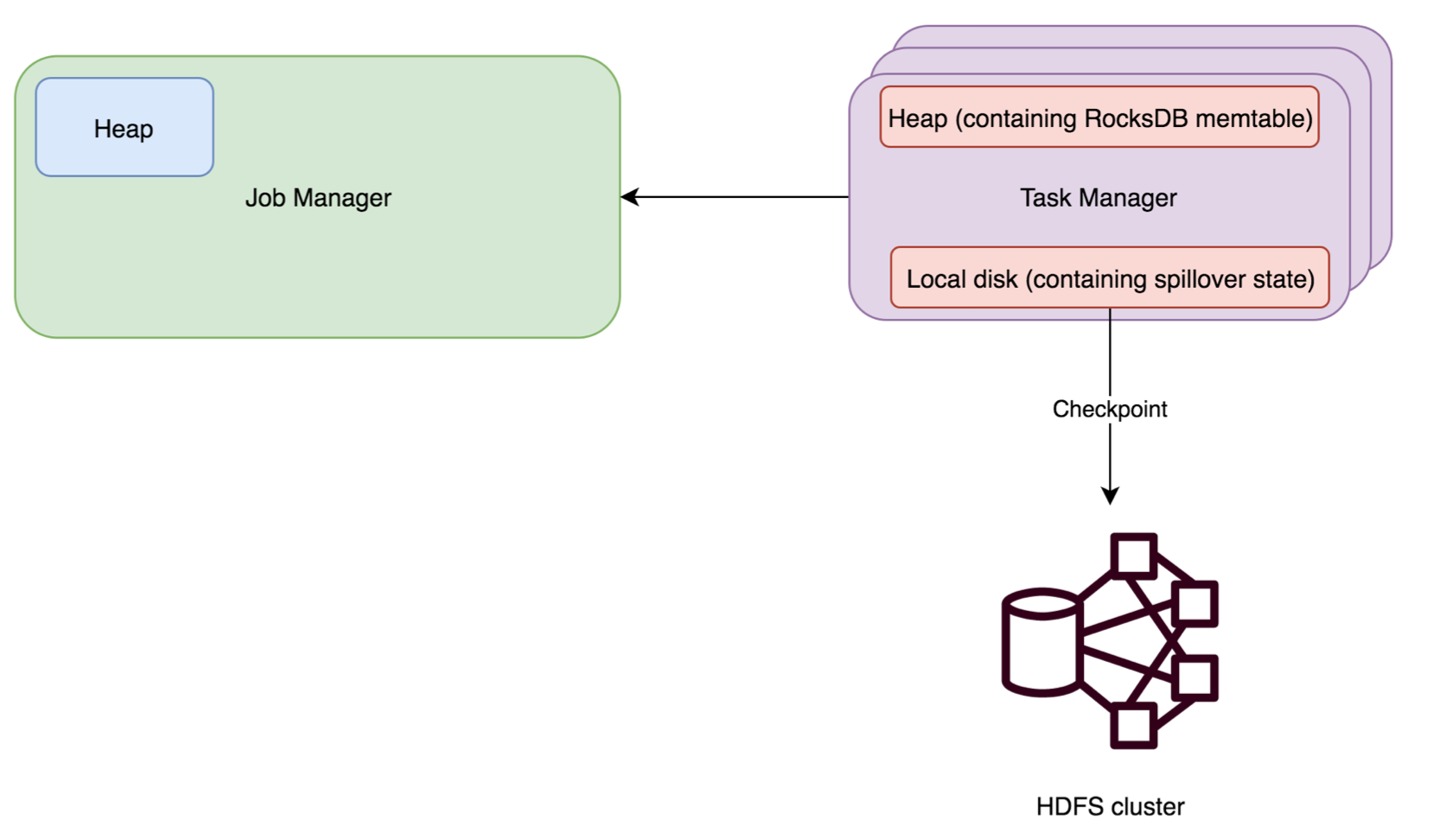 RocksDBStateBackend 也需要配置一个 checkpoint 路径,例如: “hdfs://namenode:40010/flink/checkpoints” 或者 “file:///data/flink/checkpoints”,一般配置为 hdfs 路径。
RocksDBStateBackend 也需要配置一个 checkpoint 路径,例如: “hdfs://namenode:40010/flink/checkpoints” 或者 “file:///data/flink/checkpoints”,一般配置为 hdfs 路径。
RocksDB 是一种可嵌入的持久型的 key-value 存储引擎,提供 ACID 支持。由 Facebook 基于 levelDB 开发,使用 LSM 存储引擎,是内存和磁盘混合存储。
RocksDBStateBackend 将工作状态保存在 taskmanager 的 RocksDB 数据库中;checkpoint 时, RocksDB 中的所有数据会被传输到配置的文件目录,少量元数据信息保存在 jobmanager 内存中( HA 模式下,会保存在 checkpoint 目录)。
RocksDBStateBackend 使用异步方式进行快照。
RocksDBStateBackend 的限制:- 由于 RocksDB 的 JNI bridge API 是基于 byte[] 的,RocksDBStateBackend 支持的每个 key 或者 每个 value 的最大值不超过 2^31 bytes((2GB))。
-
要注意的是,有 merge 操作的状态(例如 ListState),可能会在运行过程中超过 2^31 bytes,导致 程序失败。
- 适用的场景
- 超大状态、超长窗口(天)、大键值状态的作业
- 适合高可用模式
使用 RocksDBStateBackend 时,能够限制状态大小的是 taskmanager 磁盘空间(相对于 FsStateBackend 状态大小限制于 taskmanager 内存 )。这也导致 RocksDBStateBackend 的吞吐比 其他两个要低一些。因为 RocksDB 的状态数据的读写都要经过反序列化/序列化。
RocksDBStateBackend 是目前三者中唯一支持增量 checkpoint 的。
- 适用的场景
并行度的设置
一个Flink程序由多个Operator组成(source、transformation和 sink)。 一个Operator由多个并行的Task(线程)来执行, 一个Operator的并行Task(线程)数目就被称为该Operator(任务)的并行度(Parallel)
并行度可以有如下几种指定方式
Operator Level(算子级别)
一个算子、数据源和sink的并行度可以通过调用 setParallelism()方法来指定
actions.filter(new FilterFunction<UserAction>() {
@Override
public boolean filter(UserAction value) throws Exception {
return false;
}
}).setParallelism(4);
Execution Environment Level(Env级别)
执行环境(任务)的默认并行度可以通过调用setParallelism()方法指定。为了以并行度3来执行所有的算 子、数据源和data sink, 可以通过如下的方式设置执行环境的并行度:
执行环境的并行度可以通过显式设置算子的并行度而被重写
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
Client Level(客户端级别,推荐使用)
并行度可以在客户端将job提交到Flink时设定。 对于CLI客户端,可以通过-p参数指定并行度
./bin/flink run -p 10 WordCount-java.jar
System Level(系统默认级别,尽量不使用)
在系统级可以通过设置flink-conf.yaml文件中的parallelism.default属性来指定所有执行环境的默认并行度
注意事项
1.并行度的优先级:算子级别 > env级别 > Client级别 > 系统默认级别 (越靠前具体的代码并行度的优先 级越高)
2.如果source不可以被并行执行,即使指定了并行度为多个,也不会生效
3.尽可能的规避算子的并行度的设置,因为并行度的改变会造成task的重新划分,带来shuffle问题
4.推荐使用任务提交的时候动态的指定并行度
5.slot是静态的概念,是指taskmanager具有的并发执行能力; parallelism是动态的概念,是指程序运行 时实际使用的并发能力
Flink-Connector (Kafka)
Flink CEP
CEP 即Complex Event Processing - 复杂事件处理,Flink CEP 是在 Flink 中实现的复杂时间处理(CEP) 库。处理事件的规则,被叫做“模式”(Pattern),Flink CEP 提供了 Pattern API,用于对输入流数据进行 复杂事件规则定义,用来提取符合规则的事件序列。
Pattern API 大致分为三种:个体模式,组合模式,模式组。
Flink CEP 应用场景
CEP 在互联网各个行业都有应用,例如金融、物流、电商、智能交通、物联网行业等行业
-
实时监控 在网站的访问日志中寻找那些使用脚本或者工具“爆破”登录的用户;
我们需要在大量的订单交易中发现那些虚假交易(超时未支付)或发现交易活跃用户;
或者在快递运输中发现那些滞留很久没有签收的包裹等。 -
风险控制 比如金融行业可以用来进行风险控制和欺诈识别,从交易信息中寻找那些可能存在的危险交易和非法交易。
-
营销广告 跟踪用户的实时行为,指定对应的推广策略进行推送,提高广告的转化率。
相关概念
-
定义 复合事件处理(Complex Event Processing,CEP)是一种基于动态环境中事件流的分析技术,事件
在这里通常是有意义的状态变化,通过分析事件间的关系,利用过滤、关联、聚合等技术,根据事件间 的时序关系和聚合关系制定检测规则,持续地从事件流中查询出符合要求的事件序列,最终分析得到更 复杂的复合事件。 -
特征
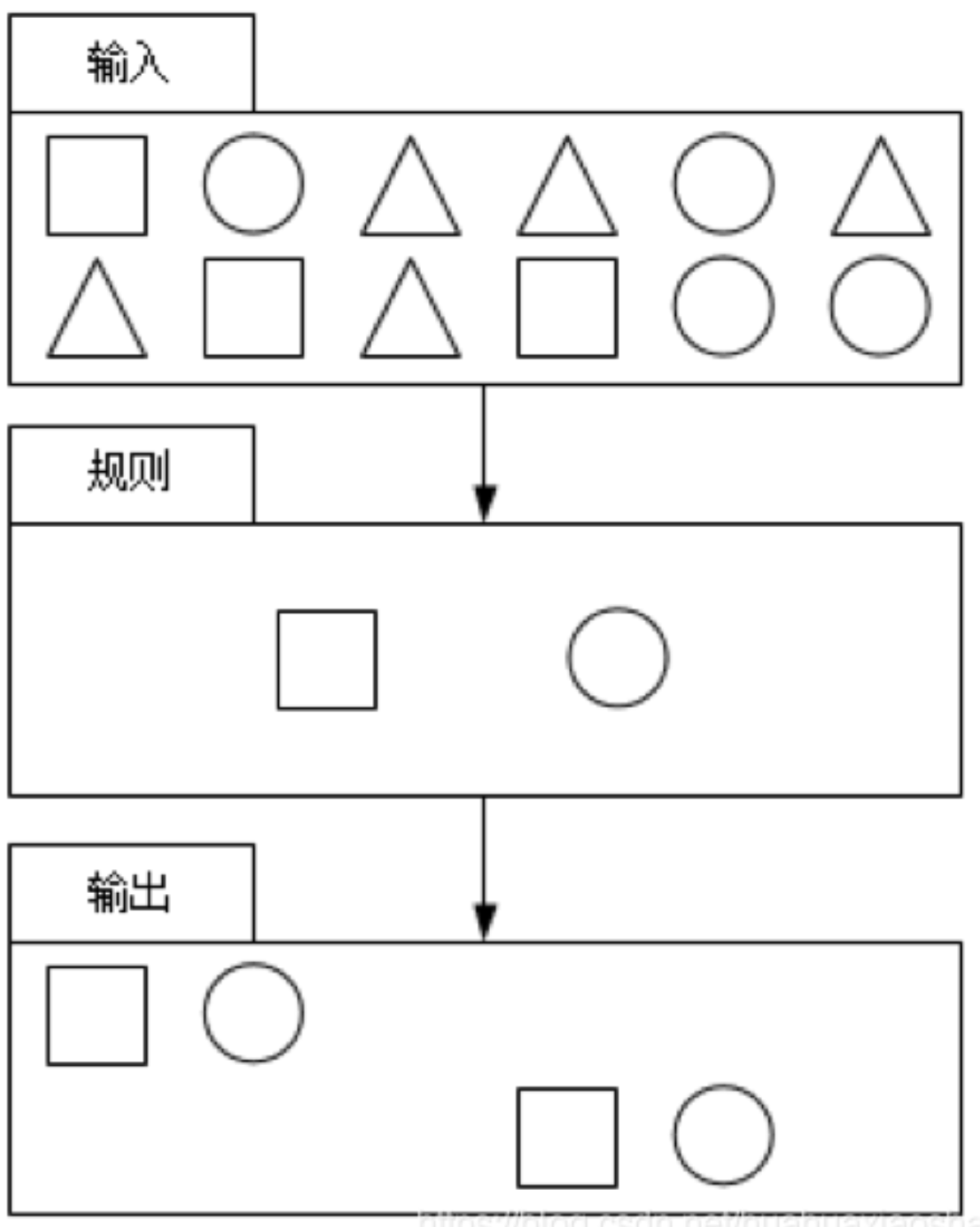 CEP的特征如下:
CEP的特征如下:
目标:从有序的简单事件流中发现一些高阶特征;
输入:一个或多个简单事件构成的事件流;
处理:识别简单事件之间的内在联系,多个符合一定规则的简单事件构成复杂事件;
输出:满足规则的复杂事件。 -
功能 CEP用于分析低延迟、频繁产生的不同来源的事件流。CEP可以帮助在复杂的、不相关的时间流中找
出有意义的模式和复杂的关系,以接近实时或准实时的获得通知或组织一些行为。
CEP支持在流上进行模式匹配,根据模式的条件不同,分为连续的条件或不连续的条件;模式的条件
允许有时间的限制,当条件范围内没有达到满足的条件时,会导致模式匹配超时。
看起来很简单,但是它有很多不同的功能:
1 输入的流数据,尽快产生结果;
2 在2个事件流上,基于时间进行聚合类的计算;
3 提供实时/准实时的警告和通知;
4 在多样的数据源中产生关联分析模式;
5 高吞吐、低延迟的处理
市场上有多种CEP的解决方案,例如Spark、Samza、Beam等,但他们都没有提供专门的库支持。然
而,Flink提供了专门的CEP库。 -
主要组件
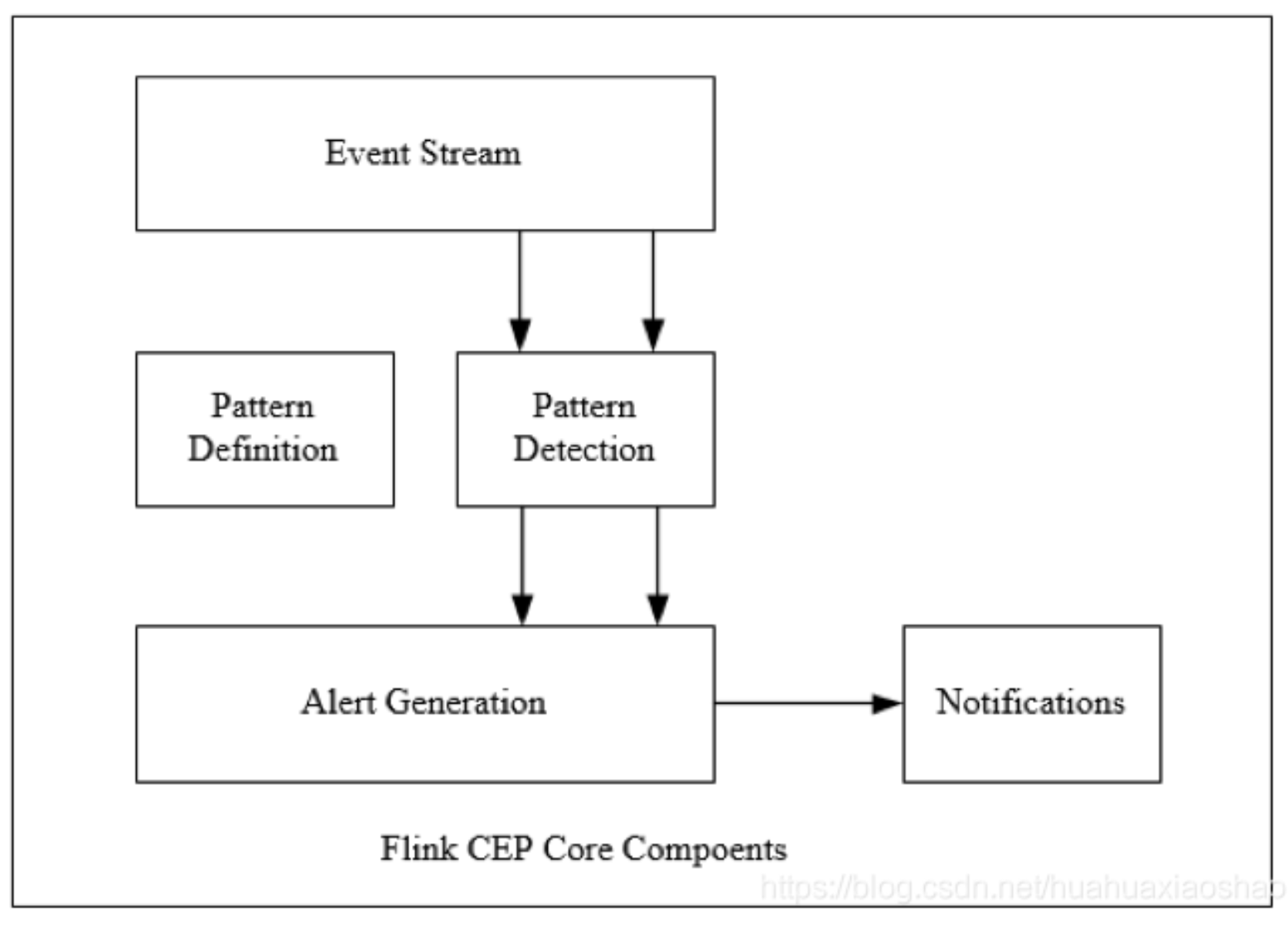 Flink为CEP提供了专门的Flink CEP library,它包含如下组件:Event Stream、Pattern定义、Pattern 检测和生成Alert。
Flink为CEP提供了专门的Flink CEP library,它包含如下组件:Event Stream、Pattern定义、Pattern 检测和生成Alert。
首先,开发人员要在DataStream流上定义出模式条件,之后Flink CEP引擎进行模式检测,必要时生成警告。
Pattern API
处理事件的规则,被叫作模式(Pattern)。
Flink CEP提供了Pattern API用于对输入流数据进行复杂事件规则定义,用来提取符合规则的事件序 列。
模式大致分为三类
-
个体模式(Individual Patterns) 组成复杂规则的每一个单独的模式定义,就是个体模式。
begin("begin").where(…).timesOrMore(5) // 相同事件连续重复出现大于等于5次个体模式包括单例模式和循环模式。单例模式只接收一个事件,而循环模式可以接收多个事件。
-
量词 可以在一个个体模式后追加量词,也就是指定循环次数。
// 匹配出现4次 start.time(4) // 匹配出现0次或4次 start.time(4).optional // 匹配出现2、3或4次 start.time(2,4) // 匹配出现2、3或4次,并且尽可能多地重复匹配 start.time(2,4).greedy // 匹配出现1次或多次 start.oneOrMore // 匹配出现0、2或多次,并且尽可能多地重复匹配 start.timesOrMore(2).optional.greedy -
条件 每个模式都需要指定触发条件,作为模式是否接受事件进入的判断依据。CEP中的个体模式主要通过
调用.where()、.or()和.until()来指定条件。按不同的调用方式,可以分成以下几类:-
简单条件 通过.where()方法对事件中的字段进行判断筛选,决定是否接收该事件
start.where(event=>event.getName.startsWith(“foo”)) -
组合条件 将简单的条件进行合并;or()方法表示或逻辑相连,where的直接组合就相当于与and。
Pattern.where(event => .../*some condition*/).or(event => /*or condition*/) -
终止条件 如果使用了oneOrMore或者oneOrMore.optional,建议使用.until()作为终止条件,以便清理状态。
-
迭代条件 能够对模式之前所有接收的事件进行处理;调用.where((value,ctx) => {…}),可以调用ctx.getEventForPattern(“name”)
-
-
-
组合模式(Combining Patterns,也叫模式序列)
 很多个体模式组合起来,就形成了整个的模式序列。 模式序列必须以一个初始模式开始:
很多个体模式组合起来,就形成了整个的模式序列。 模式序列必须以一个初始模式开始:// 第一个事件是fail,第二个事件还是fail, 窗口时间是5s, 即5s内连续出现两次fail Pattern.<LoginBean>begin("start").where(new IterativeCondition<LoginBean>() { @Override public boolean filter(LoginBean value, Context<LoginBean> ctx) throws Exception { return value.getState().equals("fail"); } }).next("next").where(new IterativeCondition<LoginBean>() { @Override public boolean filter(LoginBean value, Context<LoginBean> ctx) throws Exception { return value.getState().equals("fail"); } }).within(Time.seconds(5));-
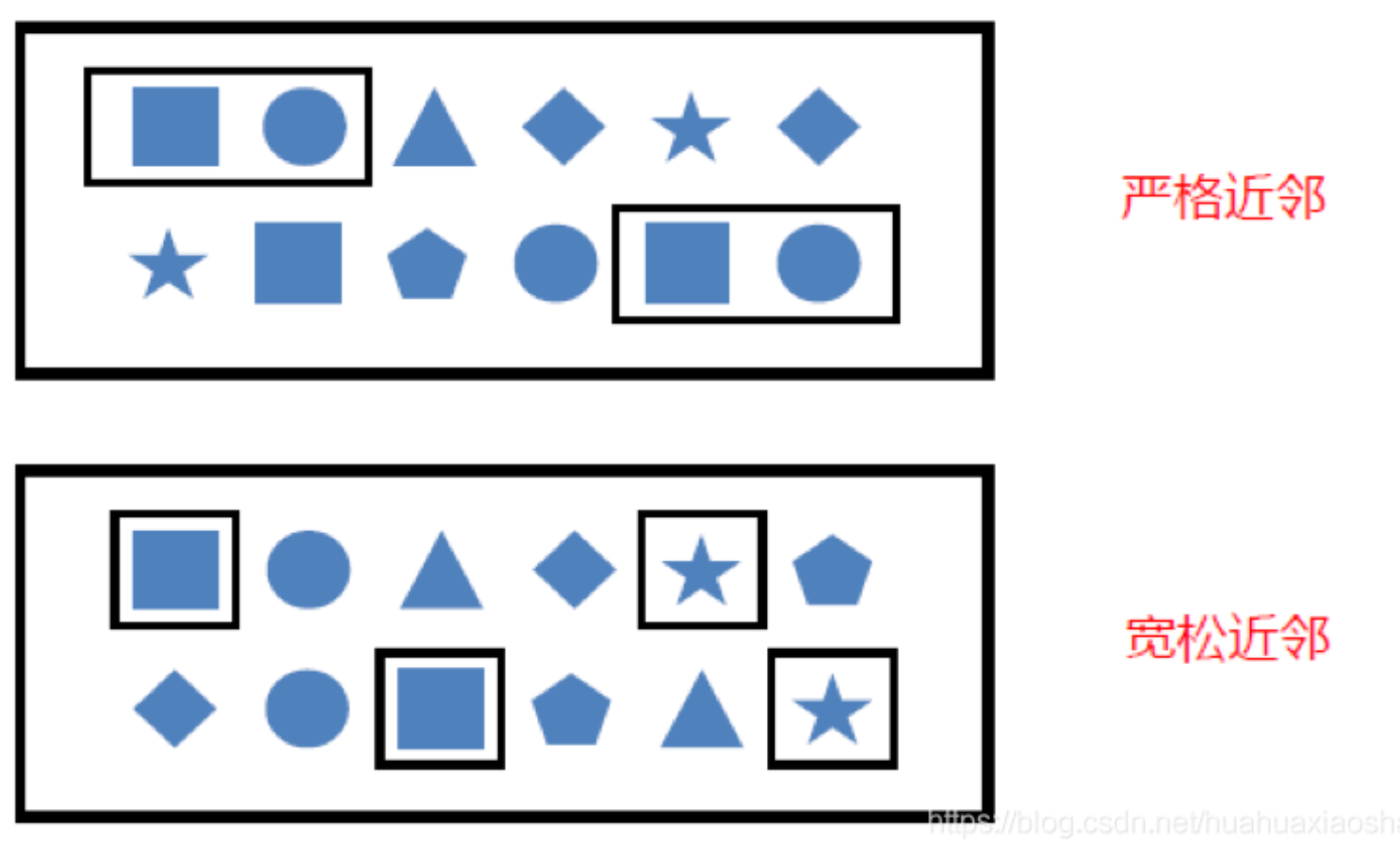
严格近邻 所有事件按照严格的顺序出现,中间没有任何不匹配的事件,由.next()指定。例如对于模式“a next b”,事件序列“a,c,b1,b2”没有匹配。
-
宽松近邻 允许中间出现不匹配的事件,由.followedBy()指定。例如对于模式“a followedBy b”,事件序列 “a,c,b1,b2”匹配为{a,b1}。
-
非确定性宽松近邻 进一步放宽条件,之前已经匹配过的事件也可以再次使用,由.followedByAny()指定。例如对于模式 “a followedByAny b”,事件序列“a,c,b1,b2”匹配为{ab1},{a,b2}。
除了以上模式序列外,还可以定义“不希望出现某种近邻关系”: .notNext():不想让某个事件严格紧邻前一个事件发生。 .notFollowedBy():不想让某个事件在两个事件之间发生。
-
-
模式组(Group of Pattern) 将一个模式序列作为条件嵌套在个体模式里,成为一组模式。
-
模式的检测 指定要查找的模式序列后,就可以将其应用于输入流以检测潜在匹配。调用CEP.pattern(),给定输入流和模式,就能得到一个PatternStream。
val input:DataStream[Event] = ... val pattern:Pattern[Event,_] = ... val patternStream:PatternStream[Event]=CEP.pattern(input,pattern) -
匹配事件的提取 创建PatternStream之后,就可以应用select或者flatSelect方法,从检测到的事件序列中提取事件了。
select()方法需要输入一个select function作为参数,每个成功匹配的事件序列都会调用它。
select()以一个Map[String,Iterable[IN]]来接收匹配到的事件序列,其中key就是每个模式的名称,而 value就是所有接收到的事件的Iterable类型。def selectFn(pattern : Map[String,Iterable[IN]]):OUT={ val startEvent = pattern.get(“start”).get.next val endEvent = pattern.get(“end”).get.next OUT(startEvent, endEvent) }flatSelect通过实现PatternFlatSelectFunction实现与select相似的功能。唯一的区别就是flatSelect方 法可以返回多条记录,它通过一个Collector[OUT]类型的参数来将要输出的数据传递到下游。
-
超时事件的提取 当一个模式通过within关键字定义了检测窗口时间时,部分事件序列可能因为超过窗口长度而被丢 弃;为了能够处理这些超时的部分匹配,select和flatSelect API调用允许指定超时处理程序。
-
注意点
- 所有模式序列必须以.begin()开始;
- 模式序列不能以.notFollowedBy()结束;
- “not”类型的模式不能被optional所修饰;
- 可以为模式指定时间约束,用来要求在多长时间内匹配有效。
next.within(Time.seconds(10))
非确定有限自动机
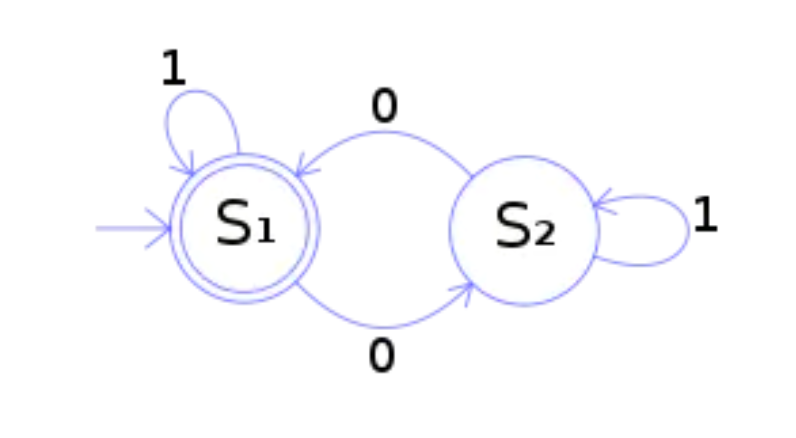
FlinkCEP在运行时会将用户的逻辑转化成这样的一个NFA Graph (nfa对象)
所以有限状态机的工作过程,就是从开始状态,根据不同的输入,自动进行状态转换的过程。
上图中的状态机的功能,是检测二进制数是否含有偶数个 0。从图上可以看出,输入只有 1 和 0 两种。 从 S1 状态开始,只有输入 0 才会转换到 S2 状态,同样 S2 状态下只有输入 0 才会转换到 S1。所以, 二进制数输入完毕,如果满足最终状态,也就是最后停在 S1 状态,那么输入的二进制数就含有偶数个 0。
案例
-
恶意登录检测 需求:找出5秒内,连续登录失败的账号
思路:
1、数据源
2、在数据源上做出watermark
3、在watermark上根据id分组keyby
4、做出模式pattern
5、在数据流上进行模式匹配
6、提取匹配成功的数据import org.apache.flink.api.common.eventtime.*; import org.apache.flink.cep.CEP; import org.apache.flink.cep.PatternStream; import org.apache.flink.cep.functions.PatternProcessFunction; import org.apache.flink.cep.pattern.Pattern; import org.apache.flink.cep.pattern.conditions.IterativeCondition; import org.apache.flink.streaming.api.TimeCharacteristic; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; import java.util.List; import java.util.Map; public class LoginDemo { public static void main(String[] args) throws Exception { /** * 1、数据源 * 2、在数据源上做出watermark * 3、在watermark上根据id分组keyby * 4、做出模式pattern * 5、在数据流上进行模式匹配 * 6、提取匹配成功的数据 */ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); env.setParallelism(1); DataStreamSource<LoginBean> data = env.fromElements( new LoginBean(1L, "fail", 1597905234000L), new LoginBean(1L, "success", 1597905235000L), new LoginBean(2L, "fail", 1597905236000L), new LoginBean(2L, "fail", 1597905237000L), new LoginBean(2L, "fail", 1597905238000L), new LoginBean(3L, "fail", 1597905239000L), new LoginBean(3L, "success", 1597905240000L) ); SingleOutputStreamOperator<LoginBean> watermarks = data.assignTimestampsAndWatermarks(new WatermarkStrategy<LoginBean>() { @Override public WatermarkGenerator<LoginBean> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new WatermarkGenerator<LoginBean>() { long maxTimeStamp = Long.MIN_VALUE; @Override public void onEvent(LoginBean event, long eventTimestamp, WatermarkOutput output) { maxTimeStamp = Math.max(event.getTimestamp(), maxTimeStamp); } long maxOutofOrderness = 500L; @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(maxTimeStamp - maxOutofOrderness)); } }; } }.withTimestampAssigner(((element, recordTimestamp) -> element.getTimestamp()))); KeyedStream<LoginBean, Long> keyed = watermarks.keyBy(value -> value.getId()); // pattern (fail, fail) Pattern<LoginBean, LoginBean> pattern = Pattern.<LoginBean>begin("start").where(new IterativeCondition<LoginBean>() { @Override public boolean filter(LoginBean value, Context<LoginBean> ctx) throws Exception { return value.getState().equals("fail"); } }).next("next").where(new IterativeCondition<LoginBean>() { @Override public boolean filter(LoginBean value, Context<LoginBean> ctx) throws Exception { return value.getState().equals("fail"); } }).within(Time.seconds(5)); PatternStream<LoginBean> patternStream = CEP.pattern(keyed, pattern); SingleOutputStreamOperator<Long> result = patternStream.process(new PatternProcessFunction<LoginBean, Long>() { @Override public void processMatch(Map<String, List<LoginBean>> match, Context ctx, Collector<Long> out) throws Exception { // System.out.println("match---------->" + match); /** * match---------->{start=[LoginBean{id=2, state='fail', * timestamp=1597905237000}], next=[LoginBean{id=2, state='fail', * timestamp=1597905238000}]} */ out.collect(match.get("start").get(0).getId()); } }); result.print(); env.execute(); } } -
检测交易活跃用户 需求:找出24小时内,至少5次有效交易的用户
import org.apache.flink.api.common.eventtime.*; import org.apache.flink.cep.CEP; import org.apache.flink.cep.PatternStream; import org.apache.flink.cep.functions.PatternProcessFunction; import org.apache.flink.cep.pattern.Pattern; import org.apache.flink.cep.pattern.conditions.IterativeCondition; import org.apache.flink.streaming.api.TimeCharacteristic; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; import java.util.List; import java.util.Map; public class DailyActiveUserDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); env.setParallelism(1); DataStreamSource<ActiveUserBean> data = env.fromElements( new ActiveUserBean("100XX", 0.0D, 1597905234000L), new ActiveUserBean("100XX", 100.0D, 1597905235000L), new ActiveUserBean("100XX", 200.0D, 1597905236000L), new ActiveUserBean("100XX", 300.0D, 1597905237000L), new ActiveUserBean("100XX", 400.0D, 1597905238000L), new ActiveUserBean("100XX", 500.0D, 1597905239000L), new ActiveUserBean("101XX", 0.0D, 1597905240000L), new ActiveUserBean("101XX", 100.0D, 1597905241000L) ); SingleOutputStreamOperator<ActiveUserBean> watermarks = data.assignTimestampsAndWatermarks(new WatermarkStrategy<ActiveUserBean>() { @Override public WatermarkGenerator<ActiveUserBean> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new WatermarkGenerator<ActiveUserBean>() { long maxTimeStamp = Long.MIN_VALUE; @Override public void onEvent(ActiveUserBean event, long eventTimestamp, WatermarkOutput output) { maxTimeStamp = Math.max(event.getTimeStamp(), maxTimeStamp); } long maxOutofOrderness = 500L; @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(maxTimeStamp - maxOutofOrderness)); } }; } }.withTimestampAssigner(((element, recordTimestamp) -> element.getTimeStamp()))); KeyedStream<ActiveUserBean, String> keyed = watermarks.keyBy(value -> value.getUid()); // 24 小时以内连续出现5次 Pattern<ActiveUserBean, ActiveUserBean> pattern = Pattern.<ActiveUserBean>begin("begin").where(new IterativeCondition<ActiveUserBean>() { @Override public boolean filter(ActiveUserBean value, Context<ActiveUserBean> ctx) throws Exception { return value.getMoney() > 0; } }).timesOrMore(5) .within(Time.hours(24)); // 生产模式流 PatternStream<ActiveUserBean> patternStream = CEP.pattern(keyed, pattern); // 获取模式匹配的事件s SingleOutputStreamOperator<String> result = patternStream.process(new PatternProcessFunction<ActiveUserBean, String>() { @Override public void processMatch(Map<String, List<ActiveUserBean>> match, Context ctx, Collector<String> out) throws Exception { System.out.println(match); out.collect(match.get("begin").get(0).getUid()); } }); result.print(); env.execute(); } } -
超时未支付 需求:找出下单后10分钟没有支付的订单
import org.apache.flink.api.common.eventtime.*; import org.apache.flink.cep.CEP; import org.apache.flink.cep.PatternSelectFunction; import org.apache.flink.cep.PatternStream; import org.apache.flink.cep.PatternTimeoutFunction; import org.apache.flink.cep.pattern.Pattern; import org.apache.flink.cep.pattern.conditions.IterativeCondition; import org.apache.flink.streaming.api.TimeCharacteristic; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.OutputTag; import java.util.List; import java.util.Map; // 支付超时 public class PayExpiredDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); env.setParallelism(1); DataStreamSource<PayEvent> data = env.fromElements( new PayEvent(1L, "create", 1597905234000L), new PayEvent(1L, "pay", 1597905235000L), new PayEvent(2L, "create", 1597905236000L), new PayEvent(2L, "pay", 1597905237000L), new PayEvent(3L, "create", 1597905239000L) ); SingleOutputStreamOperator<PayEvent> watermarks = data.assignTimestampsAndWatermarks(new WatermarkStrategy<PayEvent>() { @Override public WatermarkGenerator<PayEvent> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new WatermarkGenerator<PayEvent>() { long maxTimeStamp = Long.MIN_VALUE; @Override public void onEvent(PayEvent event, long eventTimestamp, WatermarkOutput output) { maxTimeStamp = Math.max(event.getTimeStamp(), maxTimeStamp); } long maxOutOfOrderness = 500L; @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(maxTimeStamp - maxOutOfOrderness)); } }; } }.withTimestampAssigner((element, recordTimestamp) -> element.getTimeStamp())); KeyedStream<PayEvent, Long> keyed = watermarks.keyBy(value -> value.getId()); // 定义 pattern(create, pay) Pattern<PayEvent, PayEvent> pattern = Pattern.<PayEvent>begin("start").where(new IterativeCondition<PayEvent>() { @Override public boolean filter(PayEvent value, Context<PayEvent> ctx) throws Exception { return value.getState().equals("create"); } }).followedBy("pay").where(new IterativeCondition<PayEvent>() { @Override public boolean filter(PayEvent value, Context<PayEvent> ctx) throws Exception { return value.getState().equals("pay"); } }).within(Time.seconds(600)); // 生成pattern 流 PatternStream<PayEvent> patternStream = CEP.pattern(keyed, pattern); // 声明超时事件的标签, ⚠️这里必须使用匿名内部类{} OutputTag<PayEvent> orderTimeoutOutput = new OutputTag<PayEvent>("orderTimeout"){}; SingleOutputStreamOperator<PayEvent> result = patternStream.select(orderTimeoutOutput, new PatternTimeoutFunction<PayEvent, PayEvent>() { // 获取超时事件 @Override public PayEvent timeout(Map<String, List<PayEvent>> pattern, long timeoutTimestamp) throws Exception { return pattern.get("start").get(0); } }, new PatternSelectFunction<PayEvent, PayEvent>() { // 符合模式的事件 @Override public PayEvent select(Map<String, List<PayEvent>> pattern) throws Exception { System.out.println("select -> " + pattern); return pattern.get("pay").get(0); } }); // 获取超时事件 DataStream<PayEvent> sideOutput = result.getSideOutput(orderTimeoutOutput); sideOutput.print(); env.execute(); } }
FlinkSQL
Table API 和 Flink SQL
Flink 本身是批流统一的处理框架,所以 Table API 和 SQL,就是批流统一的上层处理 API。
Table API 是一套内嵌在 Java 和 Scala 语言中的查询 API,它允许我们以非常直观的方式, 组合来自一些关系运算符的查询(比如 select、filter 和 join)。而对于 Flink SQL,就是直接可 以在代码中写 SQL,来实现一些查询(Query)操作。Flink 的 SQL 支持,基于实现了 SQL 标准的 Apache Calcite(Apache 开源 SQL 解析工具)。
无论输入是批输入还是流式输入,在这两套 API 中,指定的查询都具有相同的语义,得到相同的结果
用到的依赖
<!-- flinktable的基础依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table</artifactId>
<version>1.11.1</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<!-- 桥接器,主要负责 table API 和 DataStream/DataSet API 的连接支持,
按照语言分 java 和 scala。-->
<!-- Either... -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
<!-- or... -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
<!-- 计划器,是 table API 最主要的部分,提供了运行时环境和生 成程序执行计划的 planner;
如果是生产环境,lib 目录下默认已 经有了 planner,就只需要有 bridge 就可以了-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
一般流程
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.$;
public class TableSQLDemo1 {
public static void main(String[] args) throws Exception {
// 1、Flink执行环境env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// BlinkPlanner: 计划器,是 table API 最主要的部分,提供了运行时环境和生 成程序执行计划的 planner;
// 基于 blink 版本的流处理环境(Blink-Streaming-Query)或者,基于 blink 版本的批处理环境(Blink- Batch-Query):
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
// .inBatchMode()
.build();
// 2、用env,做出Table环境tEnv
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
// 3、获取流式数据源
DataStreamSource<Tuple2<String, Integer>> data = env.addSource(new SourceFunction<Tuple2<String, Integer>>() {
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
int num = 0;
while (true) {
ctx.collect(new Tuple2<>("April" + num, num++));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
}
});
// 4、将流式数据源做成Table
// table方式
Table myTable = tEnv.fromDataStream(data, $("name"), $("num"));
// sql 方式
tEnv.createTemporaryView("nameTable", data, $("name"), $("num"));
// 5、对Table中的数据做查询
// 使用table api
// Table selectResult = myTable.select($("name"), $("num"));
// 过滤数据
// Table selectResult = myTable.select($("name"), $("num")).filter($("num").mod(2).isEqual(0));
// 使用sql语句
// Table selectResult = tEnv.sqlQuery("select * from nameTable");
Table selectResult = tEnv.sqlQuery("select * from nameTable where mod(num,2)=0");
// 6、将Table转成数据流:
DataStream<Tuple2<Boolean, Row>> tuple2DataStream = tEnv.toRetractStream(selectResult, Row.class);
tuple2DataStream.print();
env.execute();
}
}
外部链接
-
Connectors

-
FileSystem 连接外部系统在 Catalog 中注册表,直接调用 tableEnv.connect()就可以,里面参数要传 入一个 ConnectorDescriptor,也就是 connector 描述器。对于文件系统的 connector 而言, flink 内部已经提供了,就叫做 FileSystem()。
tEnv.connect(new FileSystem().path("data/input/hello.txt")) .withFormat(new Csv().fieldDelimiter(' ')) .withSchema(new Schema() .field("name", DataTypes.STRING()) .field("action", DataTypes.STRING()) ) .createTemporaryTable("nameTable");完整代码, 从文件中流式读取数据并输出
import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.DataTypes; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.table.descriptors.Csv; import org.apache.flink.table.descriptors.FileSystem; import org.apache.flink.table.descriptors.Schema; import org.apache.flink.types.Row; public class FromFileSystem { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); EnvironmentSettings settings = EnvironmentSettings.newInstance() .useBlinkPlanner() .inStreamingMode() // .inBatchMode() .build(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings); tEnv.connect(new FileSystem().path("data/input/hello.txt")) .withFormat(new Csv().fieldDelimiter(' ')) .withSchema(new Schema() .field("name", DataTypes.STRING()) .field("action", DataTypes.STRING()) ) .createTemporaryTable("nameTable"); String sql = "select * from nameTable"; Table resultTable = tEnv.sqlQuery(sql); DataStream<Tuple2<Boolean, Row>> tuple2DataStream = tEnv.toRetractStream(resultTable, Row.class); tuple2DataStream.print(); env.execute(); } }输出到文件
import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.SourceFunction; import org.apache.flink.table.api.DataTypes; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.table.descriptors.Csv; import org.apache.flink.table.descriptors.FileSystem; import org.apache.flink.table.descriptors.Schema; import static org.apache.flink.table.api.Expressions.$; public class ToFileSystem { public static void main(String[] args) { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); EnvironmentSettings settings = EnvironmentSettings.newInstance() .useBlinkPlanner() .inStreamingMode() // .inBatchMode() .build(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings); DataStreamSource<Tuple2<String, Integer>> data = env.addSource(new SourceFunction<Tuple2<String, Integer>>() { int num = 0; @Override public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception { while (true) { ctx.collect(new Tuple2<>("name"+num, num++)); Thread.sleep(1000); } } @Override public void cancel() { } }); Table nameTable = tEnv.fromDataStream(data, $("name"), $("num")); // 输出到 FileSystem tEnv.connect(new FileSystem().path("data/output2")) .withFormat(new Csv()) .withSchema(new Schema() .field("name", DataTypes.STRING()) .field("num", DataTypes.INT()) ) .createTemporaryTable("tmpTable"); nameTable.executeInsert("tmpTable"); } } -
Kafka
tEnv .connect( new Kafka() .version("universal") .topic("animal2") .property("bootstrap.servers", "centos7-3:9092") .startFromEarliest()) .withFormat(new Csv().fieldDelimiter(',')) .withSchema( new Schema() .field("name", DataTypes.STRING()) .field("age", DataTypes.INT()) ) .createTemporaryTable("animalTable");完整代码, 从kafka读取数据, 过滤后再输出到kafka
import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.DataTypes; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.table.descriptors.Csv; import org.apache.flink.table.descriptors.Kafka; import org.apache.flink.table.descriptors.Schema; import org.apache.flink.types.Row; public class FromKafkaToKafka { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); EnvironmentSettings settings = EnvironmentSettings.newInstance() .useBlinkPlanner() .inStreamingMode() // .inBatchMode() .build(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings); // get data from kafka tEnv .connect( new Kafka() .version("universal") .topic("animal2") .property("bootstrap.servers", "centos7-3:9092") .startFromEarliest()) .withFormat(new Csv().fieldDelimiter(',')) .withSchema( new Schema() .field("name", DataTypes.STRING()) .field("age", DataTypes.INT()) ) .createTemporaryTable("animalTable"); String sql = "select * from animalTable where age>20"; Table table = tEnv.sqlQuery(sql); DataStream<Tuple2<Boolean, Row>> tuple2DataStream = tEnv.toRetractStream(table, Row.class); tuple2DataStream.print(); env.execute(); // sink to kafka // 创建kafka sink, 配置同kafka source tEnv .connect( new Kafka() .version("universal") .topic("animal") .property("bootstrap.servers", "centos7-3:9092")) .withFormat(new Csv().fieldDelimiter(',')) .withSchema( new Schema() .field("name", DataTypes.STRING()) .field("age", DataTypes.INT()) ) .createTemporaryTable("tmpTable"); // 实时插入数据到 某个表 table.executeInsert("tmpTable"); } }
-
-
Formats

查询数据
官网:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/tableApi.html
- Table API
Table selectResult = myTable.select($("name"), $("num")); // 过滤数据 Table selectResult = myTable.select($("name"), $("num")).filter($("num").mod(2).isEqual(0)); - SQL
tEnv.createTemporaryView("userss",data, $("name"), $("age")); String s = "select name,age from userss where mod(age,2)=0"; Table table = tEnv.sqlQuery(s); DataStream<Tuple2<Boolean, Row>> result = tEnv.toRetractStream(table, Row.class);
作业提交

Flink的jar文件并不是Flink集群的可执行文件,需要经过转换之后提交给集群
转换过程:
1、在Flink Client中,通过反射启动jar中的main函数,生成Flink StreamGraph和JobGraph。将 JobGraph提交给Flink集群。
2、Flink集群收到JobGraph后,将JobGraph翻译成ExecutionGraph,然后开始调度执行,启动成功之 后开始消费数据
Flink的核心执行流程就是,把用户的一系列API调用,转化为StreamGraph —> JobGraph —> ExecutionGraph —> 物理执行拓扑(Task DAG)
PipelineExecutor
是Flink Client生成JobGraph之后,将作业提交给集群运行的重要环节
Session模式:AbstractSessionClusterExecutor Per-Job模式:AbstractJobClusterExecutor IDE调试:LocalExecutor
Session模式
作业提交通过: yarn-session.sh脚本 在启动脚本的时候检查是否已经存在已经启动好的Flink-Session模式的集群, 然后在PipelineExecutor中,通过Dispatcher提供的Rest接口提交Flink JobGraph Dispatcher为每一个作业提供一个JobMaser,进入到作业执行阶段
Per-Job模式
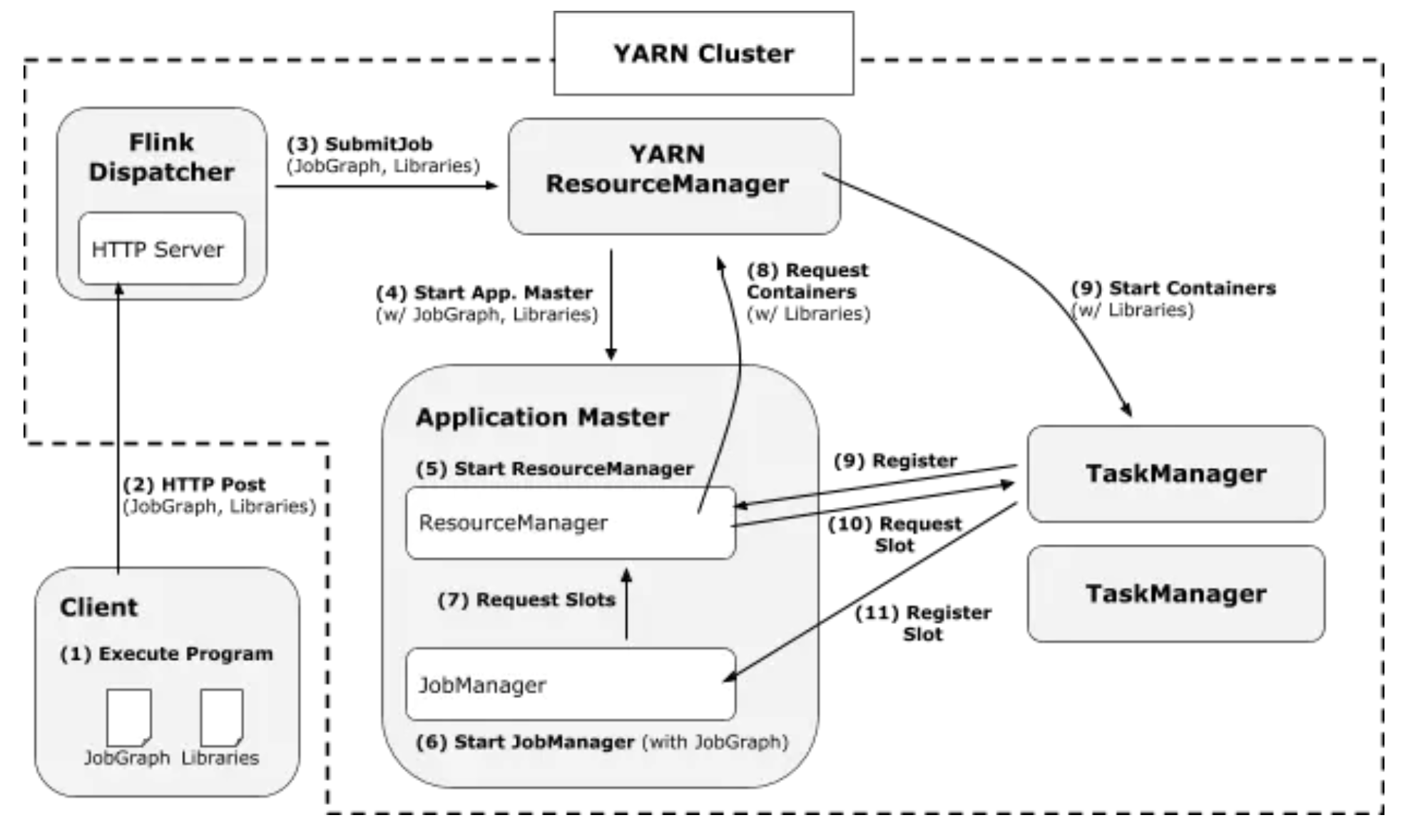
一个作业一个集群,作业之间相互隔离。
在PipelineExecutor执行作业提交的时候,可以创建集群并将JobGraph以及所有需要的文件一起提交给 Yarn集群,在Yarn集群的容器中启动Flink Master(JobManager进程),进行初始化后,从文件系统 中获取JobGraph,交给Dispatcher,之后和Session流程相同。
流程图

详细流程图
