ClickHouse--OLAP database
概述
ClickHouse是一个快速开源的OLAP数据库管理系统,它是面向列的,允许使用SQL查询实时生成分析报告。
Clickhouse 发展历史
ROLAP : 传统关系型数据库OLAP,基于MySQL的MyISAM表引擎。
MOLAP :借助物化视图的形式实现数据立方体。预处理的结果存在HBase这类高性能的分布式数据库
HOLAP:R和M的结合体H
ROLAP :ClickHouse
Clickhouse 支持特性剖析
1.真正的面向列的DBMS
2.数据高效压缩
3.磁盘存储的数据
4.多核并行处理
5.在多个服务器上分布式处理
6.SQL语法支持
7.向量化引擎
8.实时数据更新
9.索引
10.适合在线查询
11.支持近似预估计算
12.支持嵌套的数据结构
13.支持数组作为数据类型
14.支持限制查询复杂性以及配额
15.复制数据和对数据完整性的支持
ClickHouse的不完美
Ø 1.不支持事物。
Ø 2.不支持Update/Delete操作。
Ø 3.支持有限操作系统。
ClickHouse应用场景
1.电信行业用于存储数据和统计数据使用。
2.新浪微博用于用户行为数据记录和分析工作。
3.用于广告网络和RTB,电子商务的用户行为分析。
4.信息安全里面的日志分析。
5.检测和遥感信息的挖掘。
6.商业智能。
7.网络游戏以及物联网的数据处理和价值数据分析。
安装
下载地址
官网:https://clickhouse.yandex/
下载地址:http://repo.red-soft.biz/repos/clickhouse/stable/el6/
单机模式
-
上传4个文件到linux服务器 clickhouse-client-20.5.4.40-1.el7.x86_64.rpm
clickhouse-server-20.5.4.40-1.el7.x86_64.rpm
clickhouse-common-static-20.5.4.40-1.el7.x86_64.rpm
clickhouse-server-common-20.5.4.40-1.el7.x86_64.rpm
-
分别安装这4个rpm文件 rpm -ivh ./*.rpm
- 启动ClickServer
# 前台启动: sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml # 后台启动: nohup sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml >null 2>&1 & # 或者 systemctl start clickhouse-server # 启动 service clickhouse-server start # 停止 service clickhouse-server stop # 重启 service clickhouse-server restart - 使用client连接server
clickhouse-client -m - 远程访问
查看端口8123, 累屎下面的结果说明只能本地访问
lsof -i :8123 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME clickhous 653 clickhouse 41u IPv6 32544 0t0 TCP ip6-localhost:8123 (LISTEN) clickhous 653 clickhouse 44u IPv4 32547 0t0 TCP localhost:8123 (LISTEN)vim /etc/clickhouse-server/config.xml # 打开下面的字段 <listen_host>::</listen_host>设置好之后需要重启clickhouse
service clickhouse-server restart再次查看端口8123
lsof -i :8123 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME clickhous 9188 clickhouse 32u IPv6 61573 0t0 TCP *:8123 (LISTEN)
分布式集群安装
-
在所有节点上执行单机安装的步骤
- 三台机器修改配置文件config.xml
vim /etc/clickhouse-server/config.xml # zookeeper标签上面增加: <include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from> - 在三台机器的/etc/clickhouse-server/config.d目录下新建metrika.xml文件
vim metrika.xml添加如下内容:
注意:标签中的内容对应自己的主机名<yandex> <clickhouse_remote_servers> <perftest_3shards_1replicas> <shard> <internal_replication>true</internal_replication> <replica> <host>centos7-1</host> <port>9000</port> </replica> </shard> <shard> <replica> <internal_replication>true</internal_replication> <host>centos7-2</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>centos7-3</host> <port>9000</port> </replica> </shard> </perftest_3shards_1replicas> </clickhouse_remote_servers> <zookeeper-servers> <node index="1"> <host>centos7-1</host> <port>2181</port> </node> <node index="2"> <host>centos7-2</host> <port>2181</port> </node> <node index="3"> <host>centos7-3</host> <port>2181</port> </node> </zookeeper-servers> <macros> <shard>01</shard> <replica>centos7-1</replica> </macros> <networks> <ip>::/0</ip> </networks> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex> - 三台机器启动ClickServer
-
先启动zookeeper集群
-
后台启动
nohup sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml > null 2>&1 &
进入任意一台机器,查看集群配置效果
# 进入客户端 clickhouse-client -m — 查看集群配置 select * from system.clusters; -
数据类型
支持DML, 为了提高性能,较传统数据库而言,clickhouse提供了复合数据类型。 ClickHouse的Upadate和Delete是由Alter变种实现。
整型
固定长度的整型,包括有符号整型或无符号整型。
-
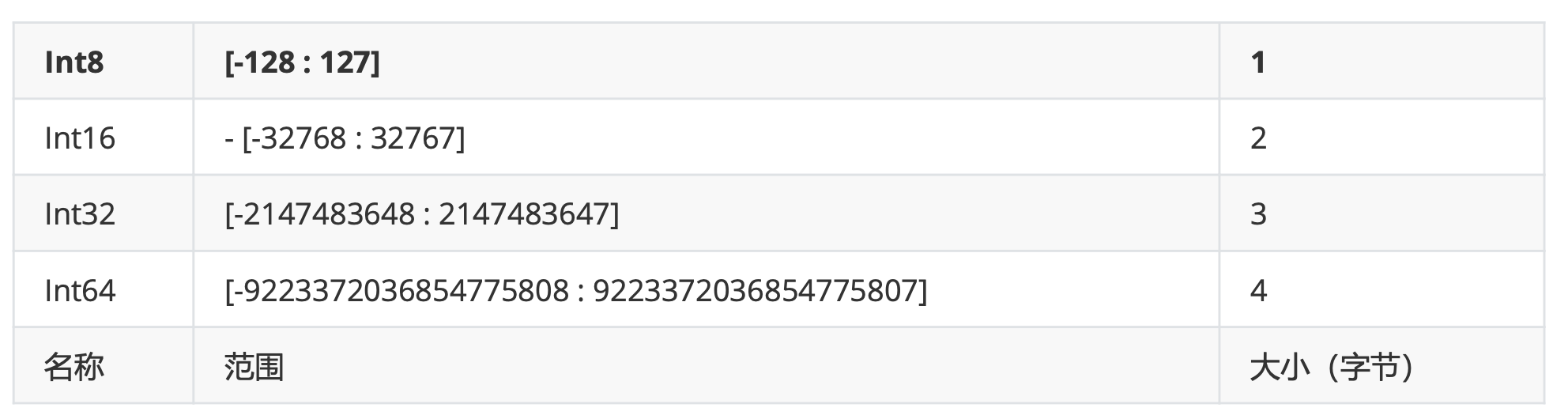
整型范围(-2n-1~2n-1-1)
-
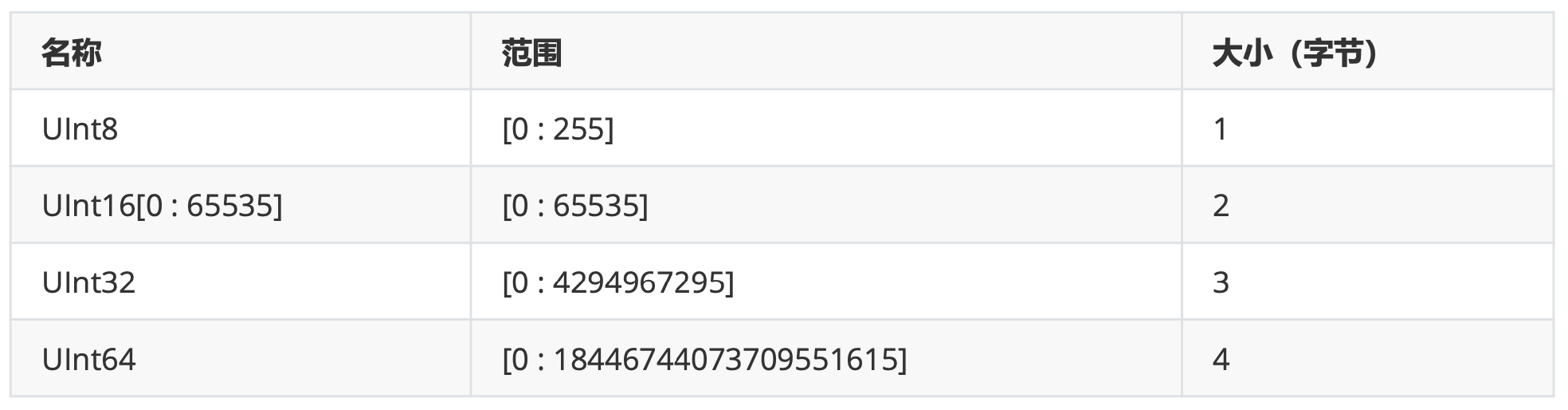
无符号整型范围(0~2n-1)
浮点型

建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。
与标准SQL相比,ClickHouse 支持以下类别的浮点数: Inf-正无穷:
:) select 1/0
┌─divide(1, 0)─┐
│ inf │
└──────────────┘
-Inf-负无穷:
:) select -1/0
┌─divide(1, 0)─┐
│ -inf │
└──────────────┘
NaN-非数字:
:) select 0/0
┌─divide(0, 0)─┐
│ nan │
└──────────────┘
Decimal
如果要求更高精度,可以选择Decimal类型
格式:Decimal(P,S)
P:代表精度,决定总位数(正数部分+小数部分),取值范围0-38
S:代表规模,决定小数位数,取值范围是0-P
ClickHouse对Decimal提供三种简写: Decimal32,Decimal64,Decimal128
- 相加、减精度取大
SELECT toDecimal32(2, 4) + toDecimal32(2, 2) ┌─plus(toDecimal64(2, 4), toDecimal32(2, 2))─┐ │ 4.0000 │ └────────────────────────────────────────────┘ SELECT toDecimal32(4, 4) - toDecimal32(2, 2) ┌─minus(toDecimal32(4, 4), toDecimal32(2, 2))─┐ │ 2.0000 │ └─────────────────────────────────────────────┘ - 相乘精度取和
SELECT toDecimal32(2, 2) * toDecimal32(4, 4) ┌─multiply(toDecimal32(2, 2), toDecimal32(4, 4))─┐ │ 8.000000 │ └────────────────────────────────────────────────┘ - 相除精度取被除数
SELECT toDecimal32(4, 4) / toDecimal32(2, 2) ┌─divide(toDecimal32(4, 4), toDecimal32(2, 2))─┐ │ 2.0000 │ └──────────────────────────────────────────────┘
字符串
clickhouse的字符串需要使用‘’,
“”会被认为是列名
-
String 字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
-
FixedString(N) 固定长度 N 的字符串,N 必须是严格的正自然数。当服务端读取长度小于 N 的字符串时候,通过在字符串末尾添加 空字节来达到 N 字节长度。 当服务端读取长度大于 N 的字符串时候,将返回错误消息。
SELECT toFixedString('abc', 5), LENGTH(toFixedString('abc', 5)) AS LENGTH ┌─toFixedString('abc', 5)─┬─LENGTH─┐ │ abc │ 5 │ └─────────────────────────┴────────┘
UUID
ClickHouse将UUID这种在传统数据库中充当主键的类型直接做成了数据类型
CREATE TABLE UUID_TEST
(
`c1` UUID,
`c2` String )
ENGINE = Memory
insert into UUID_TEST select generateUUIDv4(),'t1';
insert into UUID_TEST(c2) values('t2');
SELECT *
FROM UUID_TEST;
┌───────────────────────────────────c1─┬─c2─┐
│ 00000000-0000-0000-0000-000000000000 │ t2 │
└──────────────────────────────────────┴────┘
┌───────────────────────────────────c1─┬─c2─┐
│ b5098c0b-d824-42b4-9c3c-9317e3ba5fb7 │ t1 │
└──────────────────────────────────────┴────┘
枚举类型
包括 Enum8 和 Enum16 类型。Enum 保存 ‘string’= integer 的对应关系。 Enum8 用 ‘String’= Int8 对描述。
Enum16 用 ‘String’= Int16 对描述。
用法演示:
创建一个带有一个枚举 Enum8(‘hello’ = 1, ‘world’ = 2) 类型的列:
CREATE TABLE t_enum
(
x Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog
这个 x 列只能存储类型定义中列出的值:’hello’或’world’。如果尝试保存任何其他值,ClickHouse 抛出异常。
:) INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello’);
:) insert into t_enum values('a')
INSERT INTO t_enum VALUES
Exception on client:
Code: 49. DB::Exception: Unknown element 'a' for type Enum8('hello' = 1, 'world' = 2)
从表中查询数据时,ClickHouse 从 Enum 中输出字符串值。
SELECT *
FROM t_enum
┌─x─────┐
│ hello │
│ world │
│ hello │
└───────┘
如果需要看到对应行的数值,则必须将 Enum 值转换为整数类型。
SELECT CAST(x, 'Int8')
FROM t_enum
┌─CAST(x, 'Int8')─┐
│ 1 │
│ 2 │
│ 1 │
└─────────────────┘
为什么需要枚举类型? 后续对枚举的操作:排序、分组、去重、过滤等,会使用Int类型的Value值
数组
Array(T):由 T 类型元素组成的数组。
T 可以是任意类型,包含数组类型。 但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。例如,不能在 MergeTree 表中存储多维数组。
可以使用array函数来创建数组:
array(T) 也可以使用方号:ClickHouse能够自动推断数据类型 []
创建数组案例:
--数组中可以有不同的数据类型,但是需要相互兼容。
SELECT
[1, 2.] AS x,
toTypeName(x)
┌─x─────┬─toTypeName(array(1, 2.))─┐
│ [1,2] │ Array(Float64) │
└───────┴──────────────────────────┘
:) SELECT array(1, 2) AS x, toTypeName(x);
SELECT
[1, 2] AS x,
toTypeName(x)
┌─x─────┬─toTypeName(array(1, 2))─┐
│ [1,2] │ Array(UInt8) │
└───────┴─────────────────────────┘
如果是声明表字段的时候,需要指明数据类型:
CREATE TABLE Array_test
(
`c1` Array(String)
)
ENGINE = memory
元组
Tuple(T1, T2, …):元组,其中每个元素都有单独的类型。
创建元组的示例:
:) SELECT tuple(1,'a') AS x, toTypeName(x) ;
SELECT
(1, 'a') AS x,
toTypeName(x)
┌─x───────┬─toTypeName(tuple(1, 'a'))─┐
│ (1,'a') │ Tuple(UInt8, String) │
└─────────┴───────────────────────────┘
在定义表字段的时候也需要指明数据类型
Date、DateTime
日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。
Date: yyyy-MM-dd
DateTime: yyyy-MM-dd HH:mm:ss
布尔型
没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
表引擎
表引擎(即表的类型)决定了:
1)数据的存储方式和位置,写到哪里以及从哪里读取数据
2)支持哪些查询以及如何支持。
3)并发数据访问。
4)索引的使用(如果存在)。
5)是否可以执行多线程请求。
6)数据复制参数。
ClickHouse的表引擎有很多,下面介绍其中几种,对其他引擎有兴趣的可以去查阅官方文档:https://clickhouse.yandex/docs/zh/operations/table_engines/
日志
- TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾。该引擎没有并发控制
- 如果同时从表中读取和写入数据,则读取操作将抛出异常;
- 如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。此引擎适用于相对较小的表 (建议最多1,000,000行)。如果有许多小表,则使用此表引擎是适合的,因为它需要打开的文件更少。当拥有大量 小表时,可能会导致性能低下。 不支持索引。
-
Log Log与 TinyLog 的不同之处在于,«标记» 的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移 量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据 访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log 引擎不支持索引。同样,如果写入表失败, 则该表将被破坏,并且从该表读取将返回错误。Log 引擎适用于临时数据,write-once 表以及测试或演示目的。
-
StripeLog StripeLog 引擎将所有列存储在一个文件中。对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐 列写入。
写数据
StripeLog 引擎将所有列存储在一个文件中。对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。
ClickHouse 为每张表写入以下文件:- data.bin — 数据文件。
- index.mrk — 带标记的文件。标记包含了已插入的每个数据块中每列的偏移量。
StripeLog 引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作。
读数据
带标记的文件使得 ClickHouse 可以并行的读取数据。这意味着 SELECT 请求返回行的顺序是不可预测的。使用 ORDER BY 子句对行进行排序。
Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支 持索引。简单查询下有非常非常高的性能表现(超过10G/s)。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概 1 亿行)的场 景。
Merge
Merge 引擎 (不要跟 MergeTree 引擎混淆) 本身不存储数据,但可用于同时从任意多个其他的表中读取数据。 读是自动并行的,不支持写入。读取时,那些被真正读取到数据的表的索引(如果有的话)会被使用。 Merge 引擎的参数:一个数据库名和一个用于匹配表名的正则表达式。
案例:先建t1,t2,t3三个表,然后用 Merge 引擎的 t 表再把它们链接起来。
:)create table t1 (id UInt16, name String) ENGINE=TinyLog;
:)create table t2 (id UInt16, name String) ENGINE=TinyLog;
:)create table t3 (id UInt16, name String) ENGINE=TinyLog;
:)insert into t1(id, name) values (1, 'first');
:)insert into t2(id, name) values (2, 'second');
:)insert into t3(id, name) values (3, 'i am in t3');
:)create table t (id UInt16, name String) ENGINE=Merge(currentDatabase(), '^t');
:) select * from t; ┌─id─┬─name─┐
│ 2│second│ └────┴──────┘ ┌─id─┬─name──┐
│ 1│first│ └────┴───────┘ ┌─id─┬─name───────┐
│ 3 │ i am in t3 │ └────┴────────────┘
MergeTree
https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/
Clickhouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。
MergeTree 引擎系列的基本理念如下。当你有巨量数据要插入到表中,你要高效地一批批写入数据片段,并希望这 些数据片段在后台按照一定规则合并。相比在插入时不断修改(重写)数据进存储,这种策略会高效很多。
- MergeTree的创建方式:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2], ... INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1, INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2 ) ENGINE = MergeTree() ORDER BY expr [PARTITION BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ] [WHERE conditions] [GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ] [SETTINGS name=value, ...]Query Clauses
ENGINE — Name and parameters of the engine. ENGINE = MergeTree(). The MergeTree engine does not have parameters.ORDER BY — The sorting key.
A tuple of column names or arbitrary expressions. Example: ORDER BY (CounterID, EventDate).
ClickHouse uses the sorting key as a primary key if the primary key is not defined obviously by the PRIMARY KEY clause.
Use the ORDER BY tuple() syntax, if you do not need sorting. See Selecting the Primary Key.
PARTITION BY — The partitioning key. Optional.
For partitioning by month, use the toYYYYMM(date_column) expression, where date_column is a column with a date of the type Date. The partition names here have the “YYYYMM” format.
PRIMARY KEY — The primary key if it differs from the sorting key. Optional.
By default the primary key is the same as the sorting key (which is specified by the ORDER BY clause). Thus in most cases it is unnecessary to specify a separate PRIMARY KEY clause.
SAMPLE BY — An expression for sampling. Optional.
If a sampling expression is used, the primary key must contain it. Example: SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID)).
TTL — A list of rules specifying storage duration of rows and defining logic of automatic parts movement between disks and volumes. Optional.
Expression must have one Date or DateTime column as a result. Example:
TTL date + INTERVAL 1 DAYType of the rule DELETE TO DISK ‘xxx’ TO VOLUME ‘xxx’ GROUP BY specifies an action to be done with the part if the expression is satisfied (reaches current time): removal of expired rows, moving a part (if expression is satisfied for all rows in a part) to specified disk (TO DISK ‘xxx’) or to volume (TO VOLUME ‘xxx’), or aggregating values in expired rows. Default type of the rule is removal (DELETE). List of multiple rules can be specified, but there should be no more than one DELETE rule. For more details, see TTL for columns and tables
SETTINGS — Additional parameters that control the behavior of the MergeTree (optional):
index_granularity — Maximum number of data rows between the marks of an index. Default value: 8192. See Data Storage.
index_granularity_bytes — Maximum size of data granules in bytes. Default value: 10Mb. To restrict the granule size only by number of rows, set to 0 (not recommended). See Data Storage.
min_index_granularity_bytes — Min allowed size of data granules in bytes. Default value: 1024b. To provide a safeguard against accidentally creating tables with very low index_granularity_bytes. See Data Storage.
enable_mixed_granularity_parts — Enables or disables transitioning to control the granule size with the index_granularity_bytes setting. Before version 19.11, there was only the index_granularity setting for restricting granule size. The index_granularity_bytes setting improves ClickHouse performance when selecting data from tables with big rows (tens and hundreds of megabytes). If you have tables with big rows, you can enable this setting for the tables to improve the efficiency of SELECT queries.
use_minimalistic_part_header_in_zookeeper — Storage method of the data parts headers in ZooKeeper. If use_minimalistic_part_header_in_zookeeper=1, then ZooKeeper stores less data. For more information, see the setting description in “Server configuration parameters”.
min_merge_bytes_to_use_direct_io — The minimum data volume for merge operation that is required for using direct I/O access to the storage disk. When merging data parts, ClickHouse calculates the total storage volume of all the data to be merged. If the volume exceeds min_merge_bytes_to_use_direct_io bytes, ClickHouse reads and writes the data to the storage disk using the direct I/O interface (O_DIRECT option). If min_merge_bytes_to_use_direct_io = 0, then direct I/O is disabled. Default value: 10 * 1024 * 1024 * 1024 bytes.
merge_with_ttl_timeout — Minimum delay in seconds before repeating a merge with TTL. Default value: 86400 (1 day).
write_final_mark — Enables or disables writing the final index mark at the end of data part (after the last byte). Default value: 1. Don’t turn it off.
merge_max_block_size — Maximum number of rows in block for merge operations. Default value: 8192.
storage_policy — Storage policy. See Using Multiple Block Devices for Data Storage.
min_bytes_for_wide_part, min_rows_for_wide_part — Minimum number of bytes/rows in a data part that can be stored in Wide format. You can set one, both or none of these settings. See Data Storage.
max_parts_in_total — Maximum number of parts in all partitions.
max_compress_block_size — Maximum size of blocks of uncompressed data before compressing for writing to a table. You can also specify this setting in the global settings (see max_compress_block_size setting). The value specified when table is created overrides the global value for this setting.
min_compress_block_size — Minimum size of blocks of uncompressed data required for compression when writing the next mark. You can also specify this setting in the global settings (see min_compress_block_size setting). The value specified when table is created overrides the global value for this setting.
max_partitions_to_read — Limits the maximum number of partitions that can be accessed in one query. You can also specify setting max_partitions_to_read in the global setting. - MergeTree的存储结构
-- mt_table |-- 20180301_20180330_1_100_20 | |-- checksums.txt | |-- columns.txt | |-- date.bin | |-- date.mrk2 | |-- id.bin | |-- id.mrk2 | |-- name.bin | |-- name.mrk2 | `-- primary.idx |-- 20180601_20180629_101_200_20 | |-- checksums.txt | |-- columns.txt | |-- date.bin | |-- date.mrk2 | |-- id.bin | |-- id.mrk2 | |-- name.bin | |-- name.mrk2 | `-- primary.idx |-- detached -- format_version.txtchecksums.txt
二进制的校验文件,保存了余下文件的大小size和size的Hash值,用于快速校验文件的完整和正确性date.bin
压缩格式(默认LZ4)的数据文件,保存了原始数据。以列名.bin命名。date.mrk2
使用了自适应大小的索引间隔,名字为 .mrk2
二进制的列字段标记文件,作用是把稀疏索引.idx文件和存数据的文件.bin联系primary.idx
二进制的一级索引文件,在建表的时候通过OrderBy或者PrimaryKey声明的稀疏索引。 -
数据分区 数据是以分区目录的形式组织的,每个分区独立分开存储。 这种形式,查询数据时,可以有效的跳过无用的数据文件。
-
数据分区的规则 分区键的取值,生成分区ID,分区根据ID决定。根据分区键的数据类型不同,分区ID的生成目前有四种规则:
(1)不指定分区键
(2)使用整形
(3)使用日期类型 toYYYYMM(date) (4)使用其他类型
数据在写入时,会对照分区ID落入对应的分区。 -
分区目录的生成规则 partitionID_MinBlockNum_MaxBlockNum_Level
BlockNum是一个全局整型,从1开始,每当新创建一个分区目录,此数字就累加1。
MinBlockNum:最小数据块编号
MaxBlockNum:最大数据块编号 对于一个新的分区,MinBlockNum和MaxBlockNum的值相同
如:2020_03_1_1_0, 2020_03_2_2_0
Level:合并的层级,即某个分区被合并过得次数。不是全局的,而是针对某一个分区。 -
分区目录的合并过程 MergeTree的分区目录在数据写入过程中被创建。
不同的批次写入数据属于同一分区,也会生成不同的目录,在之后的某个时刻再合并(写入后的10-15分钟),合并 后的旧分区目录默认8分钟后删除。同一个分区的多个目录合并以后的命名规则:
- MinBlockNum:取同一分区中MinBlockNum值最小的
- MaxBlockNum:取同一分区中MaxBlockNum值最大的
- Level:取同一分区最大的Level值加1
-
-
索引 注意:基数太小(即区分度太低)的列不适合做索引列,因 为很可能横跨多个mark的值仍然相同,没有索引的意义了。
-
一级索引 文件:primary.idx
MergeTree的主键使用Primary Key定义,主键定义之后,MergeTree会根据index_granularity间隔(默认8192)为
数据生成一级索引并保存至primary.idx文件中。这种方式是稀疏索引
简化形式:通过order by指代主键-
稀疏索引 primary.idx文件的一级索引采用稀疏索引。
稠密索引:每一行索引标记对应一行具体的数据记录
稀疏索引:每一行索引标记对应一段数据记录(默认索引粒度为8192)稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度快!
-
索引粒度 index_granularity参数,表示索引粒度。新版本中clickhouse提供了自适应索引粒度。 索引粒度在MergeTree引擎中很重要。
-
索引数据的生成规则
 由于稀疏索引,所以MergeTree要间隔index_granularity行数据才会生成一个索引记录,其索引值会根据声明的主键字段获取。
由于稀疏索引,所以MergeTree要间隔index_granularity行数据才会生成一个索引记录,其索引值会根据声明的主键字段获取。 -
索引的查询过程
 MarkRange:一小段数据区间 按照index_granularity的间隔粒度,将一段完整的数据划分成多个小的数据段,小的数据段就是MarkRange, MarkRange与索引编号对应。
MarkRange:一小段数据区间 按照index_granularity的间隔粒度,将一段完整的数据划分成多个小的数据段,小的数据段就是MarkRange, MarkRange与索引编号对应。案例:
共200行数据
index_granularity大小为5
主键ID为Int,取值从0开始
根据索引生成规则,primary.idx文件内容为:
0510 1520 2530 3540 4550 …200共200行数据 / 5 = 40个MarkRange
索引查询 where id = 3
第一步:形成区间格式: [3,3]
第二步:进行交集 [3,3]∩[0,199] 以MarkRange的步长大于8分块,进行剪枝
第三步:合并
MarkRange:(start0,end 20)
-
-
跳数索引
-
granularity和index_granularity的关系 index_granularity定义了数据的粒度 granularity定义了聚合信息汇总的粒度 换言之,granularity定义了一行跳数索 引能够跳过多少个index_granularity区间的数据
-
索引的可用类型
- minmax 存储指定表达式的极值(如果表达式是 tuple ,则存储 tuple 中每个元素的极值),这些信息用于跳 过数据块,类似主键。
- set(max_rows) 存储指定表达式的惟一值(不超过 max_rows 个,max_rows=0 则表示『无限制』)。这些信 息可用于检查 WHERE 表达式是否满足某个数据块。
- ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed) 存储包含数据块 中所有 n 元短语的 布隆过滤器 。只可用在字符串上。 可用于优化 equals , like 和 in 表达式的性能。 n – 短 语长度。 size_of_bloom_filter_in_bytes – 布隆过滤器大小,单位字节。(因为压缩得好,可以指定比较大的 值,如256或512)。 number_of_hash_functions – 布隆过滤器中使用的 hash 函数的个数。 random_seed – hash 函数的随机种子。
- tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed) 跟 ngrambf_v1 类 似,不同于 ngrams 存储字符串指定长度的所有片段。它只存储被非字母数据字符分割的片段。
-
-
-
数据存储 表由按主键排序的数据 片段 组成。
当数据被插入到表中时,会分成数据片段并按主键的字典序排序。例如,主键是 (CounterID, Date) 时,片段中数据 按 CounterID 排序,具有相同 CounterID 的部分按 Date 排序。
不同分区的数据会被分成不同的片段,ClickHouse 在后台合并数据片段以便更高效存储。不会合并来自不同分区的 数据片段。这个合并机制并不保证相同主键的所有行都会合并到同一个数据片段中。ClickHouse 会为每个数据片段创建一个索引文件,索引文件包含每个索引行(『标记』)的主键值。索引行号定义 为 n * index_granularity 。最大的 n 等于总行数除以 index_granularity 的值的整数部分。对于每列,跟主键相同的 索引行处也会写入『标记』。这些『标记』让你可以直接找到数据所在的列。
你可以只用一单一大表并不断地一块块往里面加入数据 – MergeTree 引擎的就是为了这样的场景-
按列存储 在MergeTree中数据按列存储,具体到每个列字段,都拥有一个.bin数据文件,是最终存储数据的文件。 按列存储的 好处: 1、更好的压缩 2、最小化数据扫描范围
MergeTree往.bin文件存数据的步骤:
1、根据OrderBy排序
2、对数据进行压缩
3、数据以压缩数据块的形式写入.bin文件 -
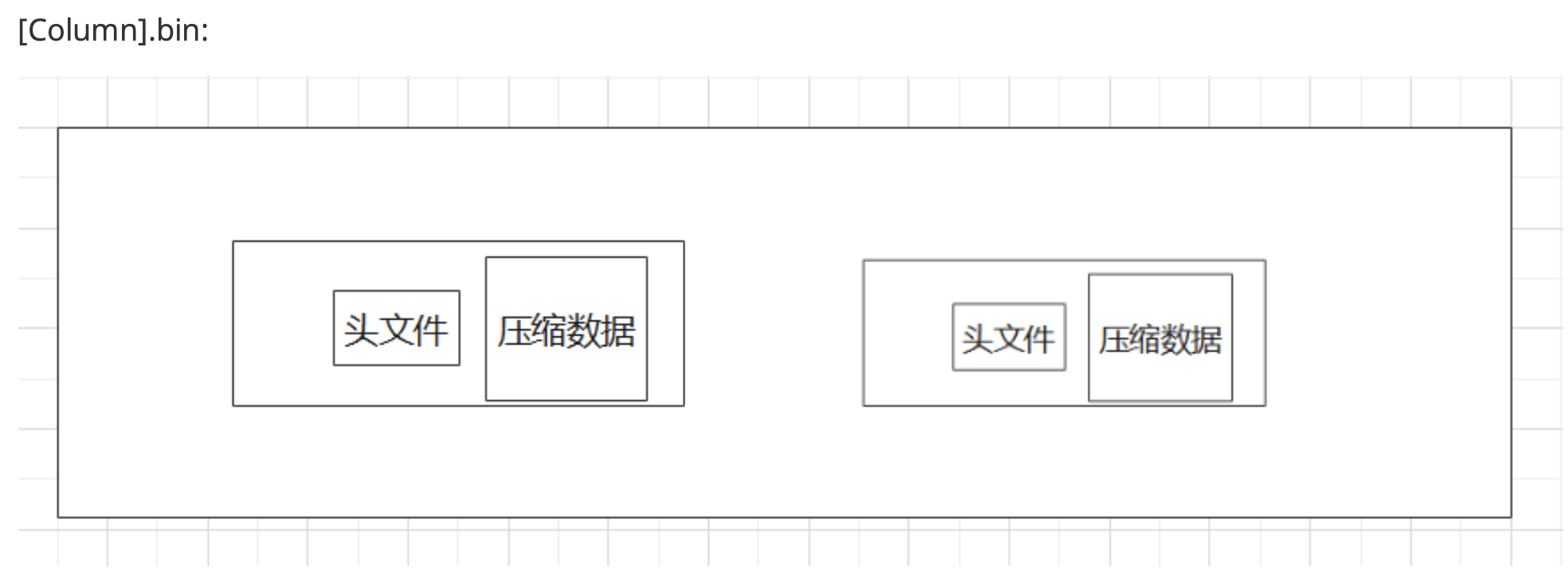
压缩数据块
 CompressionMethod_CompressedSize_UnccompressedSize
CompressionMethod_CompressedSize_UnccompressedSize
一个压缩数据块有两部分组成: 1、头信息 2、压缩数据
头信息固定使用9位字节表示,1个UInt8(1字节)+2个UInt32(4字节),分别表示压缩算法、压缩后数据大小、压缩前数据大小如:0x821200065536
0x82:是压缩方法
12000:压缩后数据大小
65536:压缩前数据大小clickhouse-compressor –stat命令
$ clickhouse-compressor --stat <./date.bin 2 12显示的数据前面的是压缩的,后面是未压缩的。
如果按照默认8192的索引粒度把数据分成批次,每批次读入数据的规则: 设x为批次数据的大小,
如果单批次获取的数据 x<64k,则继续读下一个批次,找到size>64k则生成下一个数据块 如果单批次数据64k<x<1M则直接生成下一个数据块 如果x>1M,则按照1M切分数据,剩下的数据继续按照上述规则执行。
-
-
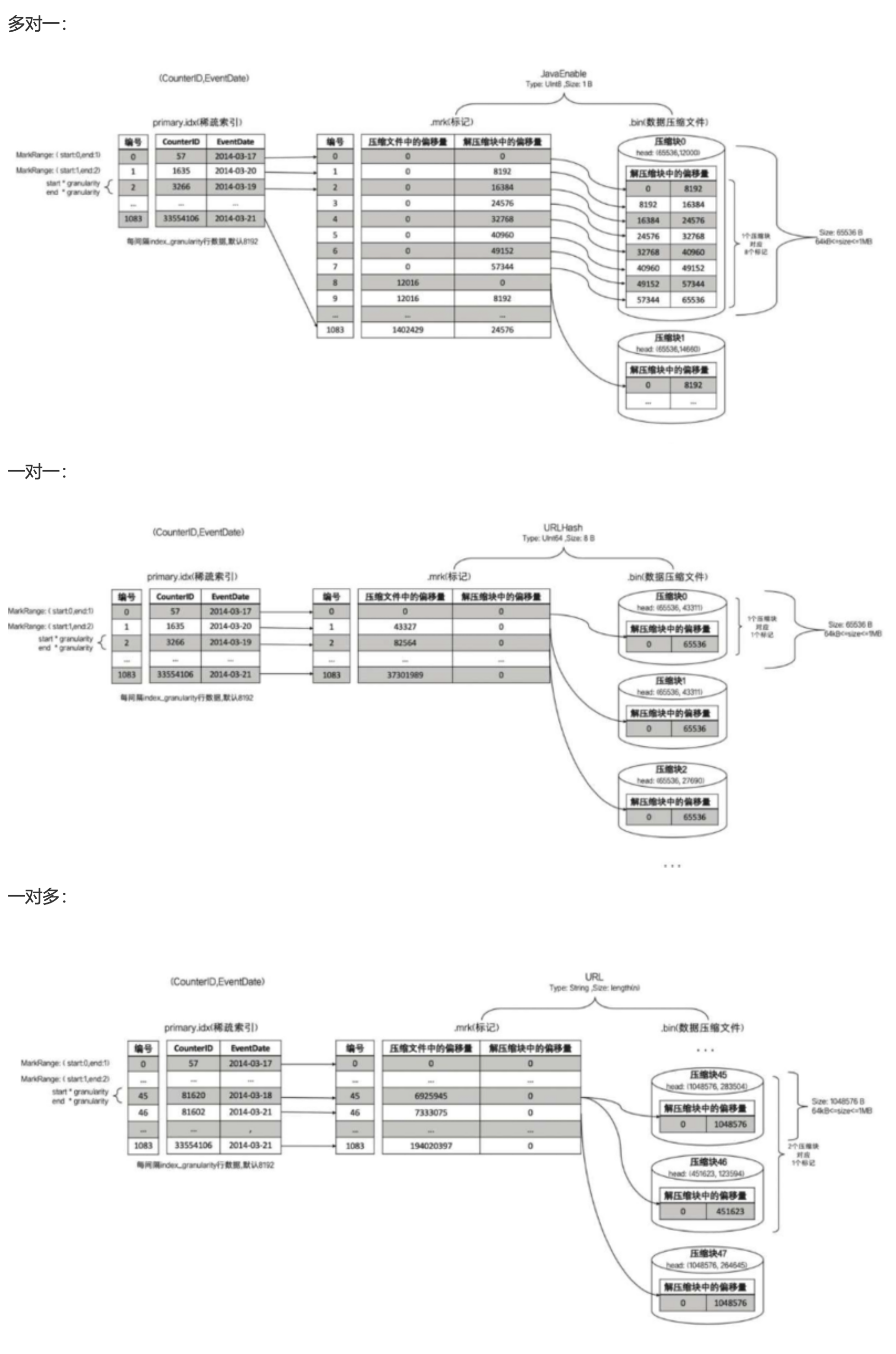
数据标记
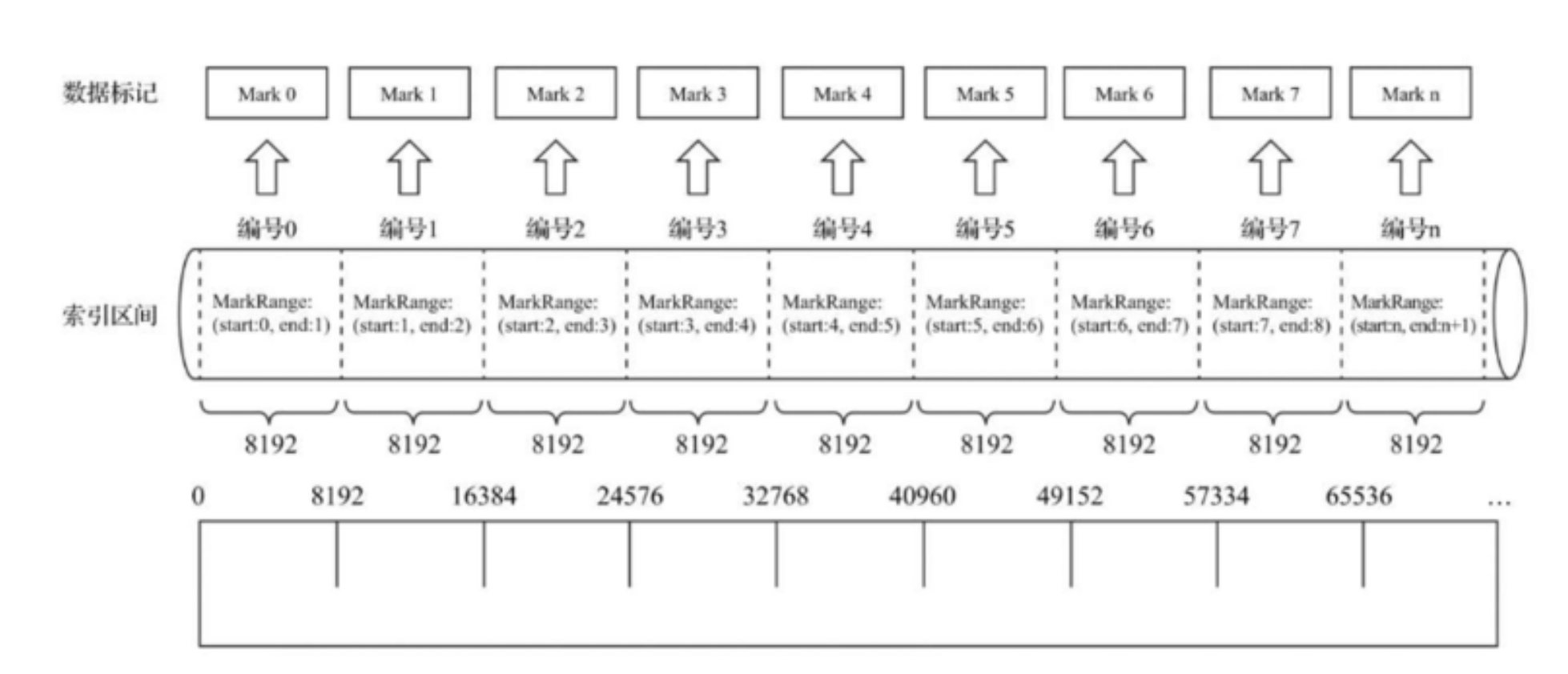 .mrk文件 将以及索引primary.idx和数据文件.bin建立映射关系
.mrk文件 将以及索引primary.idx和数据文件.bin建立映射关系1、数据标记和索引区间是对齐的,根据索引区间的下标编号,就能找到数据标记—索引编号和数据标记数值相同
2、每一个[Column].bin都有一个[Column].mrk与之对应—.mrk文件记录数据在.bin文件中的偏移量.mrk文件内容的生成规则
数据标记和区间是对齐的。均按照index_granularity粒度间隔。可以通过索引区间的下标编号找到对应的数据标记。
每一个列字段的.bin文件都有一个.mrk数据标记文件,用于记录数据在.bin文件中的偏移量信息。 标记数据采用LRU缓存策略加快其取用速度 -
分区、索引、标记和压缩协同
-
写入过程
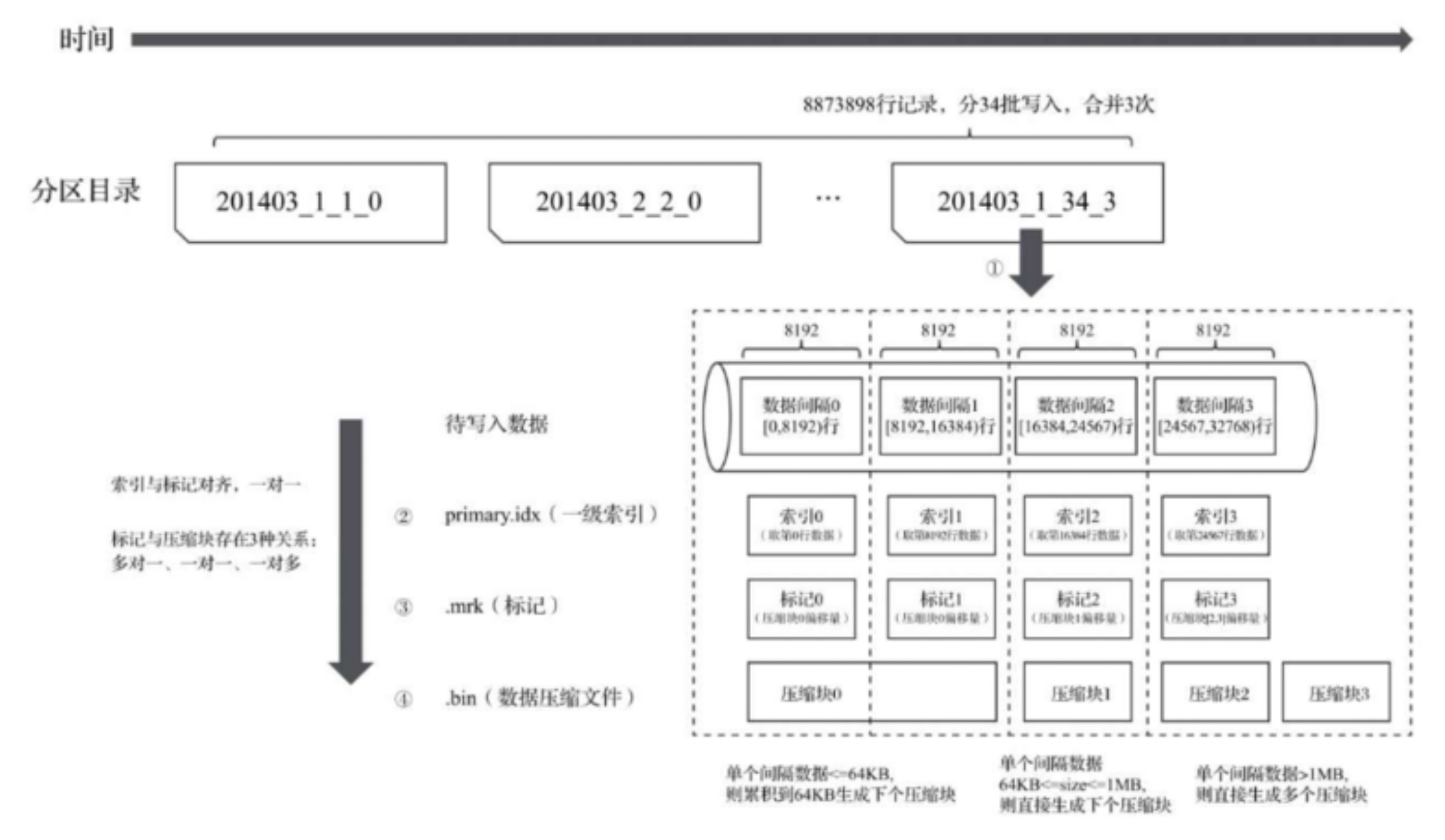 1、生成分区目录
1、生成分区目录
2、合并分区目录
3、生成primary.idx索引文件、每一列的.bin和.mrk文件 -
查询过程
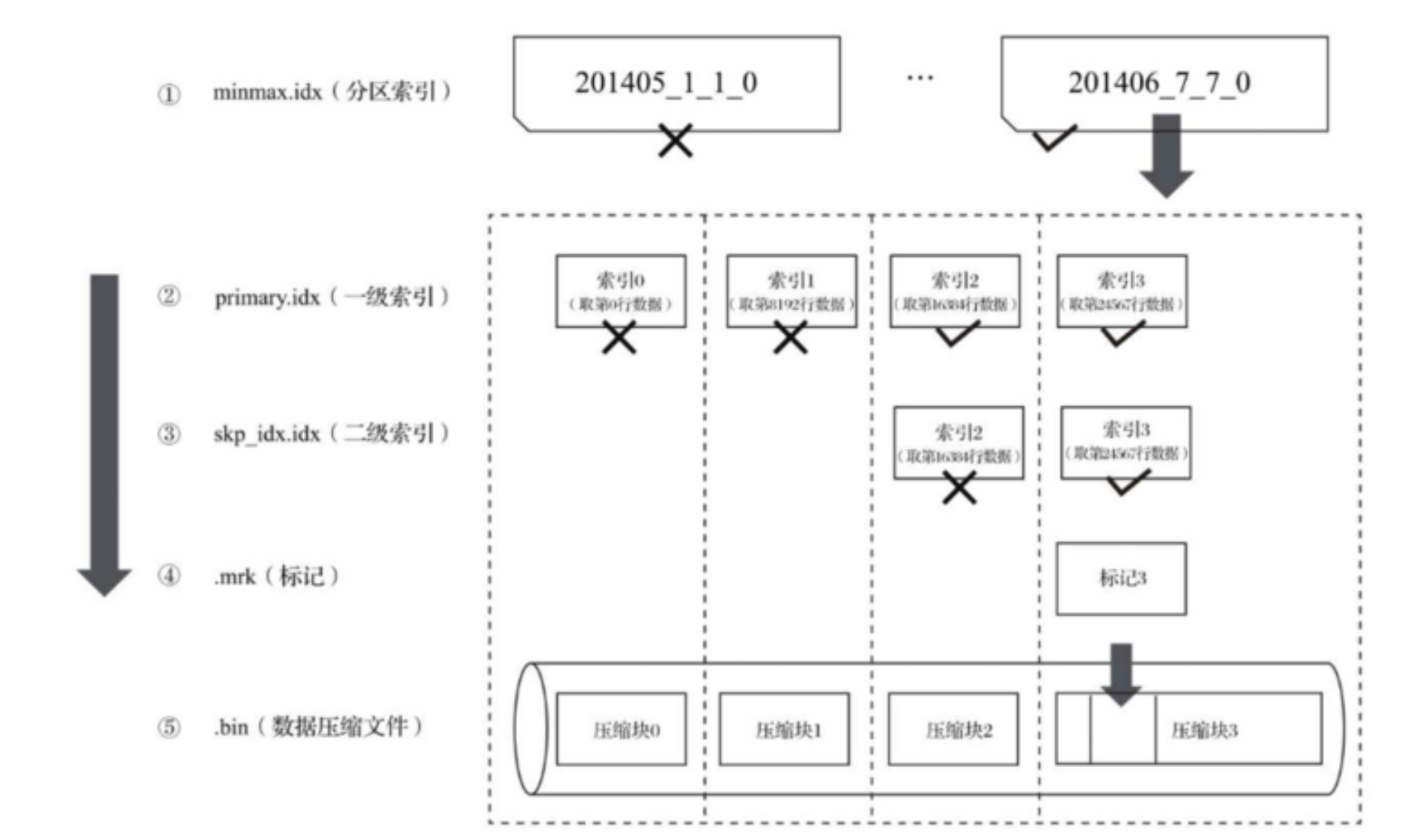 1、根据分区索引缩小查询范围
1、根据分区索引缩小查询范围
2、根据数据标记,缩小查询范围
3、解压压缩块 -
数据标记与压缩数据块的对应关系
-
-
MergTree的TTL TTL:time to live 数据存活时间。TTL既可以设置在表上,也可以设置在列上。TTL指定的时间到期后则删除相应的表或列,如果同时设置了TTL,则根据先过期时间删除相应数据。
用法:
TTL time_col + INTERVAL 3 DAY
表示数据存活时间是time_col时间的3天后
INTERVAL可以设定的时间:SECOND MINUTE HOUR DAY WEEK MONTH QUARTER YEAR- TTL设置在列上
-- mergeTree TTL , time to live create table ttl_table_v1 ( id String, create_time DateTime, code String TTL create_time + INTERVAL 10 SECOND, type UInt8 TTL create_time + INTERVAL 10 SECOND ) engine=MergeTree partition by toYYYYMM(create_time) order by id; desc ttl_table_v1; insert into ttl_table_v1 values('A000',now(),'C1',1),('A000',now()+INTERVAL 10 MINUTE,'C1',1); select * from ttl_table_v1; insert into ttl_table_v1 values('A004',now(),'C3',1); -- 触发ttl数据清除 optimize table ttl_table_v1; - TTL设置在表上
create table tt1_table_v2 ( id String, create_time DateTime, code String TTL create_time + INTERVAL 10 SECOND, type UInt8 ) ENGINE = MergeTree PARTITION BY toYYYYMM(create_time) ORDER BY create_time TTL create_time + INTERVAL 1 DAY;TTL目前没有取消方法
ALTER TABLE tt1_table_v1 MODIFY TTL create_time + INTERVAL + 3 DAY; - TTL文件说明
cat ttl.txt ttl format version: 1 {"columns":[{"name":"code","min":1597839121,"max":1597839721}, {"name":"type","min":1597839121,"max":1597839721}]}SELECT toDateTime(1597839121) AS ttl_min, toDateTime(1597839721) AS ttl_max ┌─────────────ttl_min─┬─────────────ttl_max─┐ │ 2020-08-19 20:12:01 │ 2020-08-19 20:22:01 │ └─────────────────────┴─────────────────────┘SELECT * FROM ttl_table_v1 ┌─id───┬─────────create_time─┬─code─┬─type─┐ │ A000 │ 2020-08-19 20:11:51 │ │ 0 │ │ A000 │ 2020-08-19 20:12:01 │ C1 │ 1 │ └──────┴─────────────────────┴──────┴──────┘一列数据中最小时间:2020-08-19 20:11:51 + INTERVAL的10秒钟 = 2020-08-19 20:12:01 时间 戳:”min”:1597839121
一列数据中最大时间:2020-08-19 20:12:01 + INTERVAL的10秒钟 = 2020-08-19 20:22:01 时间 戳:”max”:1597839721
文件ttl.txt记录的是列字段的过期时间。max - min = 10min
min开始触发删除的时间点,
max最后需要执行删除的时间
- TTL设置在列上
-
MergeTree的存储策略 https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/#table_engine-mergetree-multiple-volumes_configure
-
整体配置: 在/etc/clickhouse-server/config.xml添加配置
<storage_configuration> <!-- 配置文件路径 --> <disks> <disk_hot1> <path> /var/lib/clickhouse/chbase/hotdata1/ </path> </disk_hot1> <disk_hot2> <path> /var/lib/clickhouse/chbase/hotdata2/ </path> </disk_hot2> <disk_cold> <path> /var/lib/clickhouse/chbase/colddata/ </path> </disk_cold> </disks> <!-- 存储策略 --> <policies> <default_jbod> <volumes> <jbod> <disk> disk_hot1 </disk> <disk> disk_hot2 </disk> </jbod> </volumes> <move_factor> 0.2 </move_factor> </default_jbod> <moving_from_hot_to_cold> <volumes> <hot> <disk> disk_hot1 </disk> <max_data_part_size_bytes> 1073741824 </max_data_part_size_bytes> </hot> <cold> <disk> disk_cold </disk> </cold> </volumes> <move_factor> 0.2 </move_factor> </moving_from_hot_to_cold> <moving_from_hot_to_cold_new> <volumes> <hot> <disk> disk_hot2 </disk> <max_data_part_size_bytes> 1048576 </max_data_part_size_bytes> </hot> <cold> <disk> disk_cold </disk> </cold> </volumes> <move_factor> 0.2 </move_factor> </moving_from_hot_to_cold_new> </policies> </storage_configuration>ags:
policy_name_N — Policy name. Policy names must be unique.
volume_name_N — Volume name. Volume names must be unique.
disk — a disk within a volume.
max_data_part_size_bytes — the maximum size of a part that can be stored on any of the volume’s disks.
move_factor — when the amount of available space gets lower than this factor, data automatically start to move on the next volume if any (by default, 0.1).
prefer_not_to_merge — Disables merging of data parts on this volume. When this setting is enabled, merging data on this volume is not allowed. This allows controlling how ClickHouse works with slow disks. -
默认策略 19.15之前,只能单路径存储,存储位置为在config.xml配置文件中指定
<!-- Path to data directory, with trailing slash. --> <path>/var/lib/clickhouse/</path>19.15之后,支持多路径存储策略的自定义存储策略,目前有三类策略:
-
JBOD策略 配置方式在config.xml配置文件中指定:
<storage_configuration> <!-- 配置文件路径 --> <disks> <disk_hot1> <path> /var/lib/clickhouse/chbase/hotdata1/ </path> </disk_hot1> <disk_hot2> <path> /var/lib/clickhouse/chbase/hotdata2/ </path> </disk_hot2> <disk_cold> <path> /var/lib/clickhouse/chbase/colddata/ </path> </disk_cold> </disks> <!-- 存储策略 --> <policies> <default_jbod> <volumes> <jbod> <disk> disk_hot1 </disk> <disk> disk_hot2 </disk> </jbod> </volumes> <move_factor> 0.2 </move_factor> </default_jbod> </storage_configuration>配置好之后需要重启才能生效
service clickhouse-server restart查看配置结果
— 磁盘 select name, path, formatReadableSize(free_space) as free, formatReadableSize(total_space) as total, formatReadableSize(keep_free_space) as reserved from system.disks; — 存储策略 select policy_name, volume_name, volume_priority, disks, formatReadableSize(max_data_part_size) max_data_part_size, move_factor from system.storage_policies;建表的时候制定存储策略
CREATE TABLE jbod_table ( EventDate Date, OrderID UInt64, BannerID UInt64, SearchPhrase String ) ENGINE = MergeTree ORDER BY (OrderID, BannerID) PARTITION BY toYYYYMM(EventDate) SETTINGS storage_policy = 'default_jbod'查看数据存到哪个盘上
select name,disk_name from system.parts where table='jbod_table';验证JBOD策略的工作方式,多个磁盘组成了一个磁盘组volume卷,新生成的数据分区,分区目录会按照volume卷中的磁盘定义顺序,轮询写入数据。
-
HOT/COLD策略 热盘ssd放当前最新的数据,达到一定量之后移动到冷盘hhd
<storage_configuration> <!-- 配置文件路径 --> <disks> <disk_hot1> <path> /var/lib/clickhouse/chbase/hotdata1/ </path> </disk_hot1> <disk_hot2> <path> /var/lib/clickhouse/chbase/hotdata2/ </path> </disk_hot2> <disk_cold> <path> /var/lib/clickhouse/chbase/colddata/ </path> </disk_cold> </disks> <!-- 存储策略 --> <policies> <moving_from_hot_to_cold> <volumes> <hot> <disk> disk_hot1 </disk> <max_data_part_size_bytes> 1073741824 </max_data_part_size_bytes> </hot> <cold> <disk> disk_cold </disk> </cold> </volumes> <move_factor> 0.2 </move_factor> </moving_from_hot_to_cold> <moving_from_hot_to_cold_new> <volumes> <hot> <disk> disk_hot2 </disk> <max_data_part_size_bytes> 1048576 </max_data_part_size_bytes> </hot> <cold> <disk> disk_cold </disk> </cold> </volumes> <move_factor> 0.2 </move_factor> </moving_from_hot_to_cold_new> </policies> </storage_configuration>重启服务:service clickhouse-server restart
创建表,测试moving_from_hot_to_cold存储策略:
create table hot_cold_table( id UInt64 )ENGINE=MergeTree() ORDER BY id SETTINGS storage_policy='moving_from_hot_to_cold_new';写入一批500K的数据,生成一个分区目录:
insert into hot_cold_table select rand() from numbers(100000);SELECT name, disk_name FROM system.parts WHERE table = 'hot_cold_table' ┌─name──────┬─disk_name─┐ │ all_1_1_0 │ disk_hot1 │ └───────────┴───────────┘接着写入第二批500k的数据
insert into hot_cold_table select rand() from numbers(100000);SELECT name, disk_name FROM system.parts WHERE table = 'hot_cold_table' ┌─name──────┬─disk_name─┐ │ all_1_1_0 │ disk_hot1 │ │ all_2_2_0 │ disk_hot1 │ └───────────┴───────────┘每一个分区大小为500k, 接下来触发合并:
OPTIMIZE TABLE hot_cold_table_new Ok. 0 rows in set. Elapsed: 0.013 sec. hdp-1 :) select name, disk_name from system.parts where table = 'hot_cold_table_new'; SELECT name, disk_name FROM system.parts WHERE table = 'hot_cold_table_new' ┌─name──────┬─disk_name─┐ │ all_1_1_0 │ disk_hot2 │ │ all_1_2_1 │ disk_cold │ │ all_2_2_0 │ disk_hot2 │ └───────────┴───────────┘查询大小:
SELECT disk_name, formatReadableSize(bytes_on_disk) AS size FROM system.parts WHERE (table = 'hot_cold_table_new') AND (active = 1) ┌─disk_name─┬─size─────┐ │ disk_cold │ 1.01 MiB │ └───────────┴──────────┘
-
MergeTree家族表引擎
-
ReplacingMergeTree https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replacingmergetree/
这个引擎是在 MergeTree 的基础上,添加了“处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除
具有相同主键的重复项。
特点:- 使用ORDER BY排序键作为判断重复的唯一键
- 数据的去重只会在合并的过程中触发
- 以数据分区为单位删除重复数据,不同分区的的重复数据不会被删除
- 找到重复数据的方式依赖数据已经ORDER BY排好序了
- 如果没有ver版本号,则保留重复数据的最后一行
- 如果设置了ver版本号,则保留重复数据中ver版本号最大的数据
格式:
ENGINE [=] ReplacingMergeTree(date-column [, sampling_expression], (primary, key), index_granularity, [ver]) 可以看出他比MergeTree只多了一个ver,这个ver指代版本列。 -
SummingMergeTree https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/summingmergetree/
该引擎继承自 MergeTree。区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相 同聚合数据的条件Key的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果聚合数据的 条件Key的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度,对于不可加 的列,会取一个最先出现的值。
特征:- 用ORDER BY排序键作为聚合数据的条件Key
- 合并分区的时候触发汇总逻辑
- 以数据分区为单位聚合数据,不同分区的数据不会被汇总
- 如果在定义引擎时指定了Columns汇总列(非主键)则SUM汇总这些字段 5. 如果没有指定,则汇总所有非主键的数值类型字段
- SUM汇总相同的聚合Key的数据,依赖ORDER BY排序
- 同一分区的SUM汇总过程中,非汇总字段的数据保留第一行取值
- 支持嵌套结构,但列字段名称必须以Map后缀结束。
SummingMergeTree支持嵌套类型的字段,但列字段名称必须以Map后缀结束。
create table summing_table_nested( id String, nestMap Nested( id UInt32, key UInt32, val UInt64 ), create_time DateTime )ENGINE=SummingMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id; insert into summing_table_nested values('1',[1,2],[10,100],[40,20], '2021-05-08 17:00:00'); insert into summing_table_nested values('1',[1],[20],[60], '2021-05-08 17:00:00'); select * from summing_table_nested; optimize table summing_table_nested; select * from summing_table_nested; -
AggregateMergeTree https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/aggregatingmergetree/
说明: 该引擎继承自 MergeTree,并改变了数据片段的合并逻辑。 ClickHouse 会将相同主键的所有行(在一个数据 片段内)替换为单个存储一系列聚合函数状态的行。 可以使用 AggregatingMergeTree 表来做增量数据统计聚合, 包括物化视图的数据聚合。 引擎需使用 AggregateFunction 类型来处理所有列。 如果要按一组规则来合并减少行 数,则使用 AggregatingMergeTree 是合适的。 对于AggregatingMergeTree不能直接使用insert来查询写入数据。 一般是用insert select。但更常用的是创建物化视图
- 先创建一个MergeTree引擎的基表
CREATE TABLE arr_table_base ( `id` String, `city` String, `code` String, `value` UInt32 ) ENGINE = MergeTree PARTITION BY city ORDER BY (id, city); - 创建一个AggregatingMergeTree的物化视图
create materialized view agg_view engine = AggregatingMergeTree() partition by city order by (id,city) as select id, city, uniqState(code) as code, sumState(value) as value from arr_table_base group by id,city; - 往基表写入数据
insert into table arr_table_base values ('A000','wuhan','code1',1), ('A000','wuhan','code2',200), ('A000','zhuhai','code1',200); - 通过optimize命令手动Merge后查询
optimize table agg_view; -- error result select * from agg_view; id |city |code |value | ----+------+---------+--------+ A000|zhuhai| n | | A000|wuhan | ߙc n | | -- 正确的用法 select id,city,sumMerge(value),uniqMerge(code) from agg_view group by id,city; id |city |sumMerge(value)|uniqMerge(code)| ----+------+---------------+---------------+ A000|zhuhai| 200| 1| A000|wuhan | 201| 2| - 使用场景 可以使用AggregatingMergeTree表来做增量数据统计聚合,包括物化视图的数据聚合。
- 先创建一个MergeTree引擎的基表
-
CollapsingMergeTree https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/collapsingmergetree/
以增代删:
说明: yandex官方给出的介绍是CollapsingMergeTree 会异步的删除(折叠)这些除了特定列 Sign 有 1 和 -1 的值 以外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。该引擎可以显著的降低存储量并提高 SELECT 查询效率。 CollapsingMergeTree引擎有个状态列sign,这个值1为”状态”行,-1为”取消”行,对于数据只关心状态列 为状态的数据,不关心状态列为取消的数据CREATE TABLE cmt_tab( sign Int8, date Date, name String, point String) ENGINE=CollapsingMergeTree(sign) PARTITION BY date ORDER BY (name) SAMPLE BY name; insert into cmt_tab(sign,date,name,point) values (1,'2019-12-13','cctv','100000'); insert into cmt_tab(sign,date,name,point) values (-1,'2019-12-13','cctv','100000'); insert into cmt_tab(sign,date,name,point) values (1,'2019-12-13','hntv','10000'); insert into cmt_tab(sign,date,name,point) values (-1,'2019-12-13','hntv','10000'); insert into cmt_tab(sign,date,name,point) values (1,'2019-12-13','hbtv','11000'); insert into cmt_tab(sign,date,name,point) values (-1,'2019-12-13','hbtv','11000'); insert into cmt_tab(sign,date,name,point) values (1,'2019-12-14','cctv','200000'); insert into cmt_tab(sign,date,name,point) values (1,'2019-12-14','hntv','15000'); insert into cmt_tab(sign,date,name,point) values (1,'2019-12-14','hbtv','16000'); -- 相同分区中order by 的col相同,则 -1 会消除掉一行1的数据, 后插入的1不会被之前的-1消除 select * from cmt_tab; optimize table cmt_tab; select * from cmt_tab;- 使用场景 大数据中对于数据更新很难做到,比如统计一个网站或TV的在用户数,更多场景都是选择用记录每个点的数据,再对 数据进行一定聚合查询。而clickhouse通过CollapsingMergeTree就可以实现,所以使得CollapsingMergeTree大部 分用于OLAP场景
-
VersionedCollapsingMergeTree https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/versionedcollapsingmergetree/
这个引擎和CollapsingMergeTree差不多,只是对CollapsingMergeTree引擎加了一个版本,比如可以适用于非实时 用户在线统计,统计每个节点用户在线业务
集成外部表
HDFS
https://clickhouse.tech/docs/en/engines/table-engines/integrations/hdfs/
This engine provides integration with Apache Hadoop ecosystem by allowing to manage data on HDFS via ClickHouse. This engine is similar
to the File and URL engines, but provides Hadoop-specific features.
-- HDFS
CREATE TABLE hdfs_engine_table (
name String,
value UInt32)
ENGINE=HDFS('hdfs://centos7-1:9000/clickhouse_tabs/test1', 'TSV');
-- 数据会以TSV的形式存在clickhouse_tabs/test1,
-- 注意确保clickhouse有访问clickhouse_tabs的权限 hadoop fs -chown clickhouse:clickhouse /clickhouse_tabs
INSERT INTO hdfs_engine_table VALUES ('one', 1), ('two', 2), ('three', 3);
select * from hdfs_engine_table;
-- Not supported:
-- ALTER and SELECT...SAMPLE operations.
-- Indexes.
-- Replication.
MySQL
https://clickhouse.tech/docs/en/engines/table-engines/integrations/mysql/
-- mysql
create table mysql_table(
`name` String,
`age` Int32
)
ENGINE=MySQL('centos7-3:3306', 'test', 'student','hive','12345678');
insert into mysql_table values('april', 20),('angie', 18);
select * from mysql_table;
-- 不支持update
Kafka
https://clickhouse.tech/docs/en/engines/table-engines/integrations/kafka/
Kafka lets you:
- Publish or subscribe to data flows.
- Organize fault-tolerant storage.
- Process streams as they become available.
-- consumer table
CREATE TABLE queue (
timestamp UInt64,
level String,
message String
) ENGINE = Kafka('centos7-2:9092', 'topic3', 'group1', 'CSV');
-- broker, topic, consumer group, text format
-- result table
CREATE TABLE daily (
day Date,
level String,
total UInt64
) ENGINE = SummingMergeTree(day, (day, level), 8192);
-- 物化视图,创建之后会在后台持续接收kafka消息,并把结果汇总到结果表中
CREATE MATERIALIZED VIEW consumer TO daily
AS SELECT toDate(toDateTime(timestamp)) AS day, level, count() as total
FROM queue GROUP BY day, level;
SELECT level, sum(total) FROM daily GROUP BY level;
-- consumer 的查询结果是当前窗口时间内收到的消息
select * from queue;
-- 1624715352,1,hello
-- 1624715352,1,hello
-- 1624715352,2,hello
-- 1624715352,3,hello
-- 1624715352,4,hello
-- 1624715352,5,hello
-- 1624715352,6,hello
JDBC
https://clickhouse.tech/docs/en/engines/table-engines/integrations/jdbc/
Allows ClickHouse to connect to external databases via JDBC.
To implement the JDBC connection, ClickHouse uses the separate program clickhouse-jdbc-bridge that should run as a daemon.
This engine supports the Nullable data type.
用法和mysql差不多
create table jdbc_table(
`name` String,
`age` Int32
)
ENGINE=JDBC('jdbc:mysql://centos7-3:3306/?user=hive&password=12345678',
'test', 'student');
insert into jdbc_table values('hello', 20);
select * from jdbc_table where age > 15;
副本和分片
副本
zk: 实现多个实例之间的通信。
Data Replication
Replication is only supported for tables in the MergeTree family:
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergeTree
-
ReplicatedGraphiteMergeTree
- 副本的特点
作为数据副本的主要实现载体,ReplicatedMergeTree在设计上有一些显著特点:
- 依赖ZooKeeper:在执行INSERT和ALTER查询的时候,ReplicatedMergeTree需要借助ZooKeeper的分布式协 同能力,以实现多个副本之间的同步。但是在查询副本的时候,并不需要使用ZooKeeper。
- 表级别的副本:副本是在表级别定义的,所以每张表的副本配置都可以按照它的实际需求进行个性化定义,包 括副本的数量,以及副本在集群内的分布位置等。
- 多主架构(Multi Master):可以在任意一个副本上执行INSERT和ALTER查询,它们的效果是相同的。这些操 作会借助ZooKeeper的协同能力被分发至每个副本以本地形式执行。
- Block数据块:在执行INSERT命令写入数据时,会依据max_insert_block_size的大小(默认1048576行)将数 据切分成若干个Block数据块。所以Block数据块是数据写入的基本单元,并且具有写入的原子性和唯一性。
- 原子性:在数据写入时,一个Block块内的数据要么全部写入成功,要么全部失败。
- 唯一性:在写入一个Block数据块的时候,会按照当前Block数据块的数据顺序、数据行和数据大小等指标,计 算Hash信息摘要并记录在案。在此之后,如果某个待写入的Block数据块与先前已被写入的Block数据块拥有相 同的Hash摘要(Block数据块内数据顺序、数据大小和数据行均相同),则该Block数据块会被忽略。这项设计 可以预防由异常原因引起的Block数据块重复写入的问题。
-
zk的配置方式 新建配置文件 /etc/clickhouse-server/config.d/metrika.xml
<yandex> <zookeeper-servers> <node index="1"> <host>hdp-1</host> <port>2181</port> </node> <node index="2"> <host>hdp-2</host> <port>2181</port> </node> <node index="3"> <host>hdp-3</host> <port>2181</port> </node> </zookeeper-servers> </yandex>修改配置文件/etc/clickhouse-server/config.xml
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from> <zookeeper incl="zookeeper-servers" optional="true" /> - 副本的定义形式
CREATE TABLE replicated_sales_5 ( `id` String, `price` Float64, `create_time` DateTime ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/replicated_sales_5', 'centos7-1') PARTITION BY toYYYYMM(create_time) ORDER BY id; -- ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/replicated_sales_5', 'hdp-1') -- 说明: /clickhouse/tables: 约定俗称的路径固定前缀 -- 01:分片编号 -- replicated_sales_5:数据表的名字,建议与物理表名相同 -- centos7-1: 在zk中创建副本的名称,约定俗成使用服务器的名称。 -- CH提供了一张zookeeper的代理表,可用通过SQL语句读取远端ZooKeeper的数据 select * from system.zookeeper where path = '/clickhouse/tables/01/replicated_sales_5'; -- zk对应目录下多了一些管理副本元数据相关的节点 -- ls /clickhouse/tables/01/replicated_sales_5 -- [metadata, temp, mutations, log, leader_election, -- columns, blocks, nonincrement_block_numbers, replicas, quorum, block_numbers]在clickhouse集群的另一台机器定义表结构相同的表, zk节点指定为本机
CREATE TABLE replicated_sales_5 ( `id` String, `price` Float64, `create_time` DateTime ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/replicated_sales_5', 'centos7-2') PARTITION BY toYYYYMM(create_time) ORDER BY id;这样子, 只要有一台机器有数据更新,另一台机器也会同步
ReplicatedMergeTree原理
- 数据结构
[zk: localhost:2181(CONNECTED) 1] ls /clickhouse/tables/01/replicated_sales_5 [metadata, temp, mutations, log, leader_election, columns, blocks, nonincrement_block_numbers, replicas, quorum, block_numbers]元数据
metadata:元数信息: 主键、采样表达式、分区键
columns:列的字段的数据类型、字段名
replicats:副本的名称标志:
leader_election:主副本的选举路径 blocks:hash值(复制数据重复插入)、partition_id
max_insert_block_size: 1048576行 block_numbers:在同一分区下block的顺序
quorum:副本的数据量操作类:
log:log-000000 常规操作
mutations: delete updateEntry:
LogEntry和MutationEntry
分片shard
分布式保存,分区
-
配置文件 /etc/clickhouse-server/config.xml 配置
<remote_servers incl="clickhouse_remote_servers" >/etc/clickhouse-server/config.d/metrika.xml
<yandex> <clickhouse_remote_servers> <!-- 集群的名字 --> <perftest_3shards_1replicas> <shard> <internal_replication>true</internal_replication> <replica> <host>centos7-1</host> <port>9000</port> </replica> </shard> <shard> <replica> <internal_replication>true</internal_replication> <host>centos7-2</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>centos7-3</host> <port>9000</port> </replica> </shard> </perftest_3shards_1replicas> </clickhouse_remote_servers> <zookeeper-servers> <node index="1"> <host>centos7-1</host> <port>2181</port> </node> <node index="2"> <host>centos7-2</host> <port>2181</port> </node> <node index="3"> <host>centos7-3</host> <port>2181</port> </node> </zookeeper-servers> <macros> <!-- 分片编号,每台机器根据实际情况修改 --> <shard>01</shard> <replica>centos7-1</replica> </macros> <networks> <ip>::/0</ip> </networks> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex> -
Distributed用法 Distributed表引擎:
all : 全局查询的
local:真正的保存数据的表分布式引擎,本身不存储数据, 但可以在多个服务器上进行分布式查询。 读是自动并行的。读取时,远程服务器表的
索引(如果有的话)会被使用。
Distributed(cluster_name, database, table [, sharding_key])
参数解析:
cluster_name - 服务器配置文件中的集群名,在/etc/metrika.xml中配置的 database – 数据库名
table – 表名
sharding_key – 数据分片键-- 分布式表 -- Distributed表引擎 create table distributed_all on cluster perftest_3shards_1replicas(id UInt64) engine = Distributed(perftest_3shards_1replicas,'default',distributed_loc,rand()); -- (集群名,在配置文件中配置, databaseName, remote tableName, sharding key) -- on cluster perftest_3shards_1replicas -- perftest_3shards_1replicas需要在/etc/clickhouse-server/config.d/metrika.xml配置 create table distributed_loc on cluster perftest_3shards_1replicas(id UInt64) engine = MergeTree()order by id partition by id; insert into distributed_all values(1); insert into distributed_all values(2); insert into distributed_all values(3); select * from distributed_all; select * from distributed_loc;