Kudu--分布式数据存储引擎
概述
背景

在 KUDU 之前,大数据主要以两种方式存储:
- 静态数据:以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。这类存储的局限性是数据无 法进行随机的读写。
- 动态数据:以 HBase、Cassandra 作为存储引擎,适用于大数据随机读写场景。这类存储的局限性是批量读取 吞吐量远不如 HDFS,不适用于批量数据分析的场景。
所以现在的企业中,经常会存储两套数据分别用于实时读写与数据分析, 先将数据写入HBase中,再定期通过ETL到Parquet进行数据同步。
但是这样做有很多缺点:
- 用户需要在两套系统间编写和维护复杂的ETL逻辑。结构复杂,维护成本高。
- 时效性较差。因为ETL通常是一个小时、几个小时甚至是一天一次,那么可供分析的数据就需要一个小时至一天 的时间后才进入到可用状态,也就是说从数据到达到可被分析之间是会存在一个较为明显的“空档期”的。
- 更新需求难以满足。在实际情况中可能会有一些对已经写入的数据的更新需求,这种情况往往需要对历史数据 进行更新,而对Parquet这种静态数据集的更新操作,代价是非常昂贵的。
-
存储资源浪费。两套存储系统意味着占用的磁盘资源翻倍了,造成了成本的提升。
- kudu解决的问题
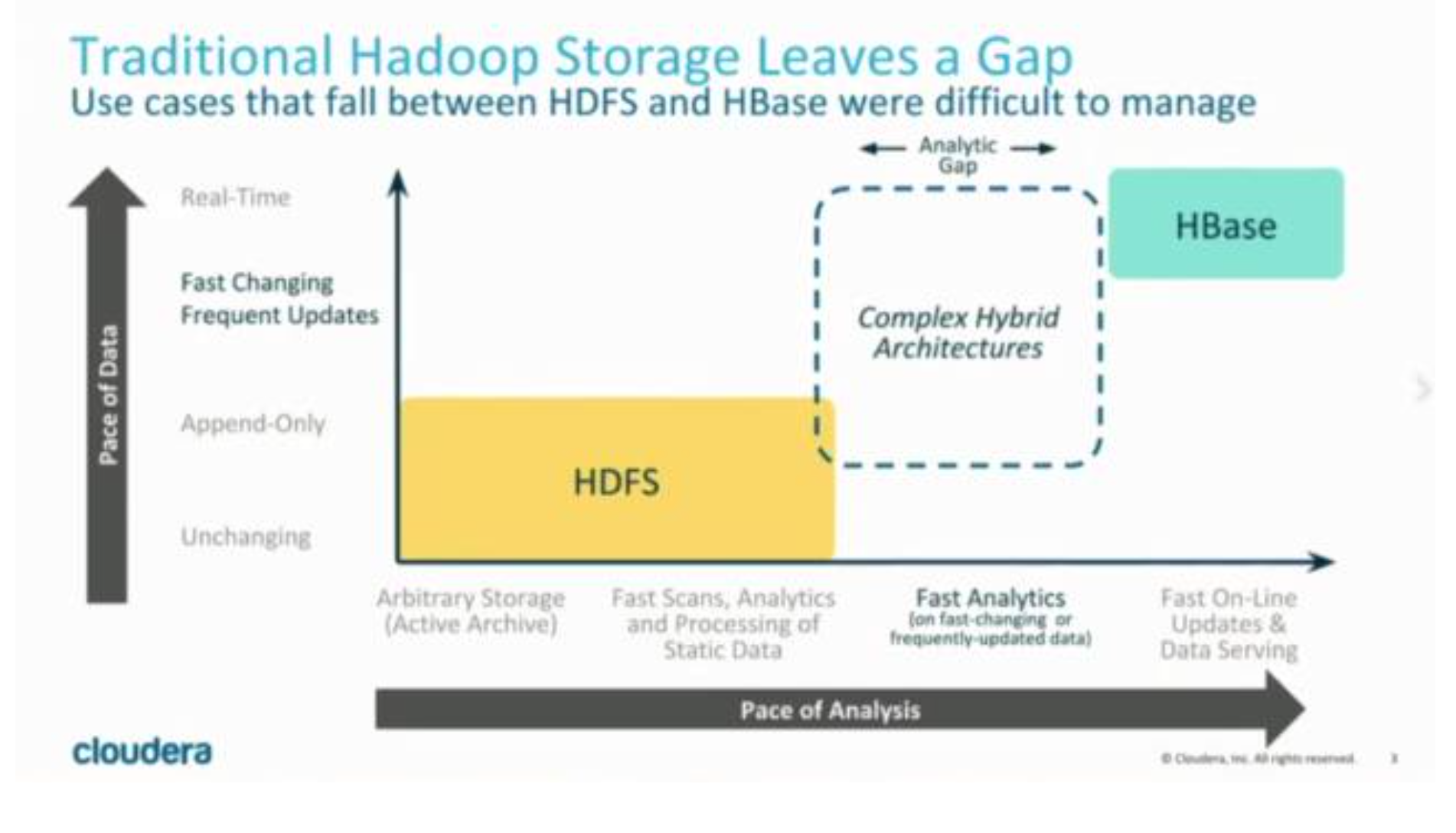 我们知道,基于HDFS的存储技术,比如Parquet,具有高吞吐量连续读取数据的能力;而HBase和Cassandra等技术 适用于低延迟的随机读写场景,那么有没有一种技术可以同时具备这两种优点呢?Kudu提供了一种“happy medium”的选择:
我们知道,基于HDFS的存储技术,比如Parquet,具有高吞吐量连续读取数据的能力;而HBase和Cassandra等技术 适用于低延迟的随机读写场景,那么有没有一种技术可以同时具备这两种优点呢?Kudu提供了一种“happy medium”的选择:
Kudu不但提供了行级的插入、更新、删除API,同时也提供了接近Parquet性能的批量扫描操作。使用同一份存储, 既可以进行随机读写,也可以满足数据分析的要求。
数据模型
KUDU 的数据模型与传统的关系型数据库类似,一个 KUDU 集群由多个表组成,每个表由多个字段组成,一个表必须指定一个由若干个(>=1)字段组成的主键
从用户角度来看,
Kudu是一种存储结构化数据表的存储系统。 在一个Kudu集群中可以定义任意数量的table,每个table都需要预先定义好schema。 每个table的列数是确定的,每一列都需要有名字和类型,每个表中可以把其中一列或多列定义为主键。
这么看来,Kudu更像关系型数据库,而不是像HBase、Cassandra和MongoDB这些NoSQL数据库。不过Kudu目前 还不能像关系型数据一样支持二级索引。 Kudu使用确定的列类型,字段是强类型的,而不是类似于NoSQL 的“everything is byte”。这可以带来两点好处:
- 确定的列类型使Kudu可以进行类型特有的编码,节省空间。
- 可以提供 SQL-like 元数据给其他上层查询工具,比如BI工具。
- KUDU 的使用场景是 OLAP 分析,有一个数据类型对下游的分析工具也更加友好
用户可以使用 Insert,Update和Delete API对表进行写操作。不论使用哪种API,都必须指定主键。但批量的删除和 更新操作需要依赖更高层次的组件(比如Impala、Spark)。Kudu目前还不支持多行事务。 而在读操作方面,Kudu 只提供了Scan操作来获取数据。用户可以通过指定过滤条件来获取自己想要读取的数据,但目前只提供了两种类型 的过滤条件:主键范围和列值与常数的比较。由于Kudu在硬盘中的数据采用列式存储,所以只扫描需要的列将极大 地提高读取性能。
-
一致性模型 Kudu为用户提供了两种一致性模型。默认的一致性模型是snapshot consistency。这种一致性模型保证用户每次读 取出来的都是一个可用的快照,但这种一致性模型只能保证单个client可以看到最新的数据,但不能保证多个client每 次取出的都是最新的数据。
另一种一致性模型external consistency可以在多个client之间保证每次取到的都是最新数据,但是Kudu没有提供默 认的实现,需要用户做一些额外工作。
为了实现external consistency,Kudu提供了两种方式:- 在client之间传播timestamp token。在一个client完成一次写入后,会得到一个timestamp token,然后这个 client把这个token传播到其他client,这样其他client就可以通过token取到最新数据了。不过这个方式的复杂度 很高。
- 通过commit-wait方式,这有些类似于Google的Spanner。但是目前基于NTP的commit-wait方式延迟实在有点 高。不过Kudu相信,随着Spanner的出现,未来几年内基于real-time clock的技术将会逐渐成熟。
Kudu的架构
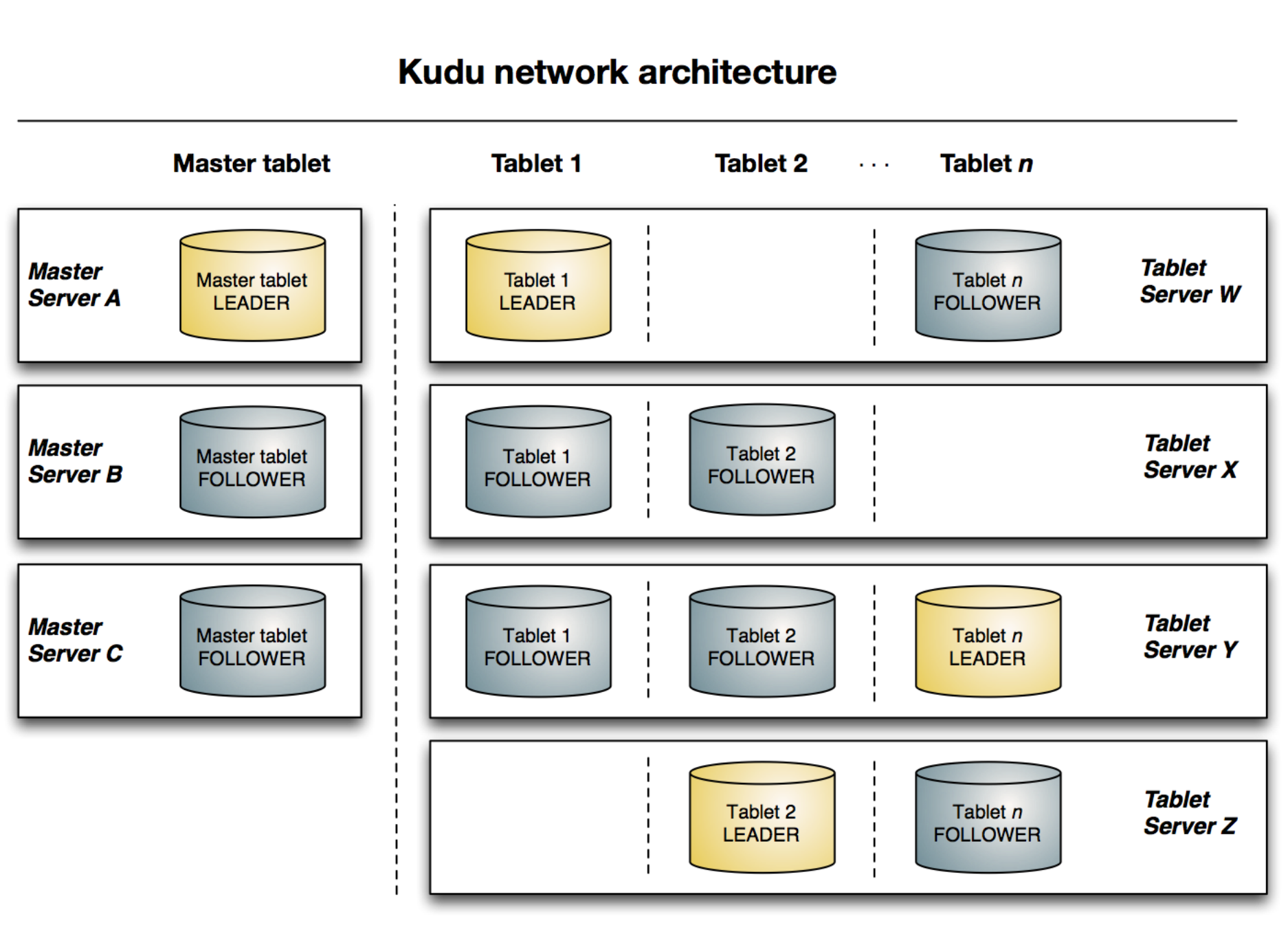
与HDFS和HBase相似,Kudu使用单个的Master节点,用来管理集群的元数据,并且使用任意数量的Tablet Server节点用来存储实际数据。可以部署多个Master节点来提高容错性。
Master
Kudu的master节点负责整个集群的元数据管理和服务协调。它承担着以下功能:
- 作为catalog manager,master节点管理着集群中所有table和tablet的schema及一些其他的元数据。
- 作为cluster coordinator,master节点追踪着所有server节点是否存活,并且当server节点挂掉后协调数据的 重新分布。
-
作为tablet directory,master跟踪每个tablet的位置。
-
Catalog Manager Kudu的master节点会持有一个单tablet的table——catalog table,但是用户是不能直接访问的。master将内部的 catalog信息写入该tablet,并且将整个catalog的信息缓存到内存中。随着现在商用服务器上的内存越来越大,并且 元数据信息占用的空间其实并不大,所以master不容易存在性能瓶颈。catalog table保存了所有table的schema的 版本以及table的状态(创建、运行、删除等)。
-
Cluster Coordination Kudu集群中的每个tablet server都需要配置master的主机名列表。当集群启动时,tablet server会向master注册, 并发送所有tablet的信息。tablet server第一次向master发送信息时会发送所有tablet的全量信息,后续每次发送则 只会发送增量信息,仅包含新创建、删除或修改的tablet的信息。 作为cluster coordination,master只是集群状态 的观察者。对于tablet server中tablet的副本位置、Raft配置和schema版本等信息的控制和修改由tablet server自身 完成。master只需要下发命令,tablet server执行成功后会自动上报处理的结果。
- Tablet Directory 因为master上缓存了集群的元数据,所以client读写数据的时候,肯定是要通过master才能获取到tablet的位置等信 息。但是如果每次读写都要通过master节点的话,那master就会变成这个集群的性能瓶颈,所以client会在本地缓存 一份它需要访问的tablet的位置信息,这样就不用每次读写都从master中获取。 因为tablet的位置可能也会发生变化 (比如某个tablet server节点crash掉了),所以当tablet的位置发生变化的时候,client会收到相应的通知,然后再 去master上获取一份新的元数据信息。
Table
在数据存储方面,Kudu选择完全由自己实现,而没有借助于已有的开源方案。tablet存储主要想要实现的目标为:
- 快速的列扫描
- 低延迟的随机读写
-
一致性的性能
-
RowSets 在Kudu中,tablet被细分为更小的单元,叫做RowSets。一些RowSet仅存在于内存中,被称为MemRowSets,而另 一些则同时使用内存和硬盘,被称为DiskRowSets。任何一行未被删除的数据都只能存在于一个RowSet中。 无论任 何时候,一个tablet仅有一个MemRowSet用来保存最新插入的数据,并且有一个后台线程会定期把内存中的数据 flush到硬盘上。 当一个MemRowSet被flush到硬盘上以后,一个新的MemRowSet会替代它。而原有的 MemRowSet会变成一到多个DiskRowSet。flush操作是完全同步进行的,在进行flush时,client同样可以进行读写 操作。
- MemRowSet
MemRowSets是一个可以被并发访问并进行过锁优化的B-tree,主要是基于MassTree来设计的,但存在几点不同:
- Kudu并不支持直接删除操作,由于使用了MVCC,所以在Kudu中删除操作其实是插入一条标志着删除的数据, 这样就可以推迟删除操作。
- 类似删除操作,Kudu也不支持原地更新操作。
- 将tree的leaf链接起来,就像B+-tree。这一步关键的操作可以明显地提升scan操作的性能。
- 没有实现字典树(trie树),而是只用了单个tree,因为Kudu并不适用于极高的随机读写的场景。
- DiskRowSet 当MemRowSet被flush到硬盘上,就变成了DiskRowSet。当MemRowSet被flush到硬盘的时候,每32M就会形成一 个新的DiskRowSet,这主要是为了保证每个DiskRowSet不会太大,便于后续的增量compaction操作。Kudu通过 将数据分为base data和delta data,来实现数据的更新操作。Kudu会将数据按列存储,数据被切分成多个page,并 使用B-tree进行索引。除了用户写入的数据,Kudu还会将主键索引存入一个列中,并且提供布隆过滤器来进行高效 查找。
- MemRowSet
MemRowSets是一个可以被并发访问并进行过锁优化的B-tree,主要是基于MassTree来设计的,但存在几点不同:
-
Compaction 为了提高查询性能,Kudu会定期进行compaction操作,合并delta data与base data,对标记了删除的数据进行删除,并且会合并一些DiskRowSet。
- 分区
选择分区策略需要理解数据模型和表的预期工作负载:
- 对于写量大的工作负载,重要的是要设计分区,使写分散在各个tablet上,以避免单个tablet超载。
- 对于涉及许多短扫描的工作负载(其中联系远程服务器的开销占主导地位),如果扫描的所有数据都位于同一块 tablet上,则可以提高性能。
没有默认分区 在创建表时,Kudu不提供默认的分区策略。建议预期具有繁重读写工作负载的新表至少拥有与tablet服务器相同的tablet。
和许多分布式存储系统一样,Kudu的table是水平分区的。BigTable只提供了range分区,Cassandra只提供hash分 区,而Kudu同时提供了这两种分区方式,使分区较为灵活。当用户创建一个table时,可以同时指定table的的 partition schema,partition schema会将primary key映射为partition key。一个partition schema包括0到多个 hash-partitioning规则和一个range-partitioning规则。通过灵活地组合各种partition规则,用户可以创造适用于自 己业务场景的分区方式。
安装和运行
环境说明
- os:CentOS Linux release 7.6.1810 (Core)
- hdp-1 hdp-2 hpd-3 三台机器
- hdp-1启动Master
- hdp-1,hdp-2,hdp-3启动tserver
安装ntp服务
每个节点执行:
yum -y install ntp
注释掉以下四行:
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
修改hdp-2 192.168.81.130节点上的配置文件
vi /etc/ntp.conf
加入如下内容
# 给192.168.81.0网段,子网掩码为255.255.255.0的局域网机的机器有同步时间的权限
restrict 192.168.81.0 mask 255.255.255.0 notrap nomodify
# prefer代表优先使用此ip做同步
server 192.168.81.130 prefer
# 当所有服务器都不能使用时,使用本机作为同步服务器
server 127.127.1.0
fudge 127.127.1.0 stratum 10
修改192.168.81.129和192.16881.131节点上的配置文件
vi /etc/ntp.conf
加入以下内容
server 192.168.81.130 prefer
server 127.127.1.0
fudge 127.127.1.0 stratum 10
启动NTP服务
service ntpd start
chkconfig ntpd on
检验
检查ntp服务是否成功输入:ntpstat
输出如下则启动成功并且同步已完成
synchronised to local net at stratum 11
time correct to within 11 ms
polling server every 64 s
/etc/init.d/ntpd start 各个节点检查启动成功,否则启动kudu相关服务会报错
时钟同步,kudu对时间要求很精准
ntpdate -u ntp.api.bz
配置Yum的Repository
在使用 yum来安装kudu的时候,由于kudu不是yum的常规组建,直接安装会找不到kudu,所以第一步需要将
kudu的repo文件下载并放置到合适的位置。
- 下载kudu的repo文件 下载repo文件:
wget http://archive.cloudera.com/kudu/redhat/7/x86_64/kudu/cloudera-kudu.repo - 将下载的repo文件放置到/etc/yum.repos.d/目录下
sudo mv cloudera-kudu.repo mv /etc/yum.repos.d/
安装kudu
安装,在每个节点上执行
yum install kudu kudu-master kudu-tserver kudu-client0 kudu-client-devel -y
配置并启动kudu
hdp-2: master hdp-1,hdp-2,hdp-3 slaver 安装完成,在/etc/kudu/conf目录下有两个文件:master.gflagfile和tserver.gflagfile
使用192.168.81.130作为kudu-master,192.168.81.129、192.168.20.130和192.168.81.131作为kudu- tserver节点
所以192.168.81.130节点需要修改master.gflagfile和tserver.gflagfile文件,而192.168.81.129和 192.168.20.131只需要修改tserver.gflagfile文件
修改kudu-master启动配置 hdp-2节点
vi /etc/default/kudu-master
修改以下内容,主要是修改ip:
export FLAGS_rpc_bind_addresses=192.168.81.130:7051
修改每个节点的kudu-tserver启动配置
vi /etc/default/kudu-tserver
修改以下内容,主要是修改ip为当前节点ip
export FLAGS_rpc_bind_addresses=192.168.81.130:7050
master.gflagfile的配置修改
--fromenv=rpc_bind_addresses
--fromenv=log_dir
--fs_wal_dir=/var/lib/kudu/master --fs_data_dirs=/var/lib/kudu/master
-unlock_unsafe_flags=true
-allow_unsafe_replication_factor=true
-default_num_replicas=1 # 此参数可以调整备份数量,默认为3
tserver.gflagfile 的配置修改
# Do not modify these two lines. If you wish to change these variables,
# modify them in /etc/default/kudu-tserver.
--fromenv=rpc_bind_addresses
--fromenv=log_dir
--fs_wal_dir=/var/lib/kudu/tserver
--fs_data_dirs=/var/lib/kudu/tserver
--tserver_master_addrs=hdp-2:7051
-unlock_unsafe_flags=true
-allow_unsafe_replication_factor=true
-default_num_replicas=1
--tserver_master_addrs=192.168.81.130:7051
# 此参数指定master
注意,这里的–tserver_master_addrs指明了集群中master的地址,指向同一个master的tserver形成了一 个kudu集群
创建master.gflagfile和tserver.gflagfile文件中指定的目录,并将所有者更改为kudu,执行如下命令:
mkdir -p /var/lib/kudu/master /var/lib/kudu/tserver
chown -R kudu:kudu /var/lib/kudu/
修改 /etc/security/limits.d/20-nproc.conf 文件,解除kudu用户的线程限制,注意:20可能不同,根据自 己的来修改
vi /etc/security/limits.d/20-nproc.conf
# 加入以下两行内容
kudu soft nproc unlimited
impala soft nproc unlimited
启动kudu
master节点(hdp-2 192.168.81.130)执行:
service kudu-master start
service kudu-tserver start
192.168.81.129和192.168.81.131执行:
service kudu-tserver start
kudu-master启动失败
查看/var/log/kudu/err 发现时间问题,解决方案,重启ntpd
service ntpd restart
然后重启 kudu-master
service kudu-master restart
Web界面 http://master:8050
KuDu常用API
CRUD demo
用到的依赖
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.4.0</version>
</dependency>
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Schema;
import org.apache.kudu.Type;
import org.apache.kudu.client.*;
import java.util.ArrayList;
public class KuduDemo {
public static void main(String[] args) {
String masterAddress = "centos7-1";
KuduClient.KuduClientBuilder kuduClientBuilder = new KuduClient.KuduClientBuilder(masterAddress);
KuduClient client = kuduClientBuilder.build();
// createTable(client);
scanData(client);
}
public static void deleteData(KuduClient client) {
try {
KuduTable kuduTable = client.openTable("student");
KuduSession kuduSession = client.newSession();
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
Delete delete = kuduTable.newDelete();
PartialRow row = delete.getRow();
row.addInt("id", 1);
kuduSession.flush();
kuduSession.apply(delete);
kuduSession.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
public static void updateData(KuduClient client) {
try{
KuduTable kuduTable = client.openTable("student");
KuduSession kuduSession = client.newSession();
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
Update update = kuduTable.newUpdate();
update.getRow().addInt("id", 1);
update.getRow().addString("name", "Angie");
kuduSession.flush();
kuduSession.apply(update);
kuduSession.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
public static void scanData(KuduClient client) {
// kudu查询数据用scanner 思路:
// 1、获取client
// 2、获取Scanner
// 3、从Scanner中循环遍历数据
try {
KuduTable kuduTable = client.openTable("student");
KuduScanner scanner = client.newScannerBuilder(kuduTable).build();
while (scanner.hasMoreRows()) {
for (RowResult result : scanner.nextRows()) {
int id = result.getInt("id");
String name = result.getString("name");
System.out.println("id: "+id + ", name: "+name);
}
}
} catch (KuduException e) {
e.printStackTrace();
}
}
public static void insertData(KuduClient client) {
// 1、获取客户端
// 2、打开一张表
// 3、创建会话
// 4、设置刷新模式
// 5、获取插入实例
// 6、声明带插入数据
// 7、刷入数据
// 8、应用插入实例
// 9、关闭会话
try{
KuduTable kuduTable = client.openTable("student");
KuduSession kuduSession = client.newSession();
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
Insert insert = kuduTable.newInsert();
insert.getRow().addInt("id", 1);
insert.getRow().addString("name", "April");
kuduSession.flush();
kuduSession.apply(insert);
kuduSession.close();
} catch (KuduException e) {
e.printStackTrace();
} finally {
try {
client.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
public static void deleteTable(KuduClient client) {
try {
client.deleteTable("student");
} catch (KuduException e) {
e.printStackTrace();
} finally {
try {
client.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
public static void createTable(KuduClient client) {
// (1)必须指定表连接到的master节点主机名
// (2)必须定义schema
// (3)必须指定副本数量、分区策略和数量
String tableName = "userTable";
ArrayList<ColumnSchema> columnSchemas = new ArrayList<ColumnSchema>();
ColumnSchema id = new ColumnSchema.ColumnSchemaBuilder("id", Type.STRING).key(true).build();
ColumnSchema name = new ColumnSchema.ColumnSchemaBuilder("name", Type.STRING).key(false).build();
ColumnSchema age = new ColumnSchema.ColumnSchemaBuilder("age", Type.INT32).key(false).build();
columnSchemas.add(id);
columnSchemas.add(name);
columnSchemas.add(age);
Schema schema = new Schema(columnSchemas);
CreateTableOptions options = new CreateTableOptions();
options.setNumReplicas(1);
ArrayList<String> colrule = new ArrayList<String>();
colrule.add("id");
options.addHashPartitions(colrule, 3);
try {
client.createTable(tableName, schema, options);
} catch (KuduException e) {
e.printStackTrace();
} finally {
try {
client.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
}
Flink下沉到KuDu
- 用到的依赖
<dependency> <groupId>org.apache.kudu</groupId> <artifactId>kudu-client</artifactId> <version>1.4.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.11.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.11.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.12</artifactId> <version>1.11.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_2.12</artifactId> <version>1.11.1</version> </dependency> - bean
public class UserInfo { private String numberId; private String name; private Integer age; .... } - MySinkToKudu
import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import org.apache.kudu.client.*; import java.util.Map; public class MySinkToKudu extends RichSinkFunction<Map<String, Object>> { // private final static Logger logger = Logger private KuduClient client; private KuduTable table; private KuduSession session; private String kuduMaster; // table需要提前建好 private String tableName; public MySinkToKudu(String kuduMaster, String tableName) { this.kuduMaster = kuduMaster; this.tableName = tableName; } @Override public void open(Configuration parameters) throws Exception { super.open(parameters); client = new KuduClient.KuduClientBuilder(kuduMaster).build(); table = client.openTable(tableName); session = client.newSession(); session.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH); } public void invoke(Map<String, Object> value, Context context) throws Exception { Insert insert = table.newInsert(); PartialRow row = insert.getRow(); row.addString("id", value.get("id").toString()); row.addString("name", value.get("name").toString()); row.addInt("age", Integer.valueOf(value.get("age").toString())); session.flush(); session.apply(insert); session.close(); } @Override public void close() throws Exception { super.close(); } } - FlinkDemo
import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.HashMap; import java.util.Map; public class FlinkToKuduDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<UserInfo> data = env.fromElements(new UserInfo("001", "Jack", 18), new UserInfo("002", "Rose", 20), new UserInfo("003", "Cris", 22), new UserInfo("004", "Lily", 19), new UserInfo("005", "Lucy", 21), new UserInfo("006", "Json", 24)); SingleOutputStreamOperator<Map<String, Object>> mapped = data.map(new MapFunction<UserInfo, Map<String, Object>>() { public Map<String, Object> map(UserInfo value) throws Exception { HashMap<String, Object> map = new HashMap<String, Object>(); map.put("id", value.getNumberId()); map.put("name", value.getName()); map.put("age", value.getAge()); return map; } }); String masterAddr = "centos7-1"; String tableName = "userTable"; mapped.addSink(new MySinkToKudu(masterAddr, tableName)); env.execute(); } }