Druid--高性能实时分析数据库
Part 1 Apache Druid简介及架构
Druid概述
1.1 什么是Druid
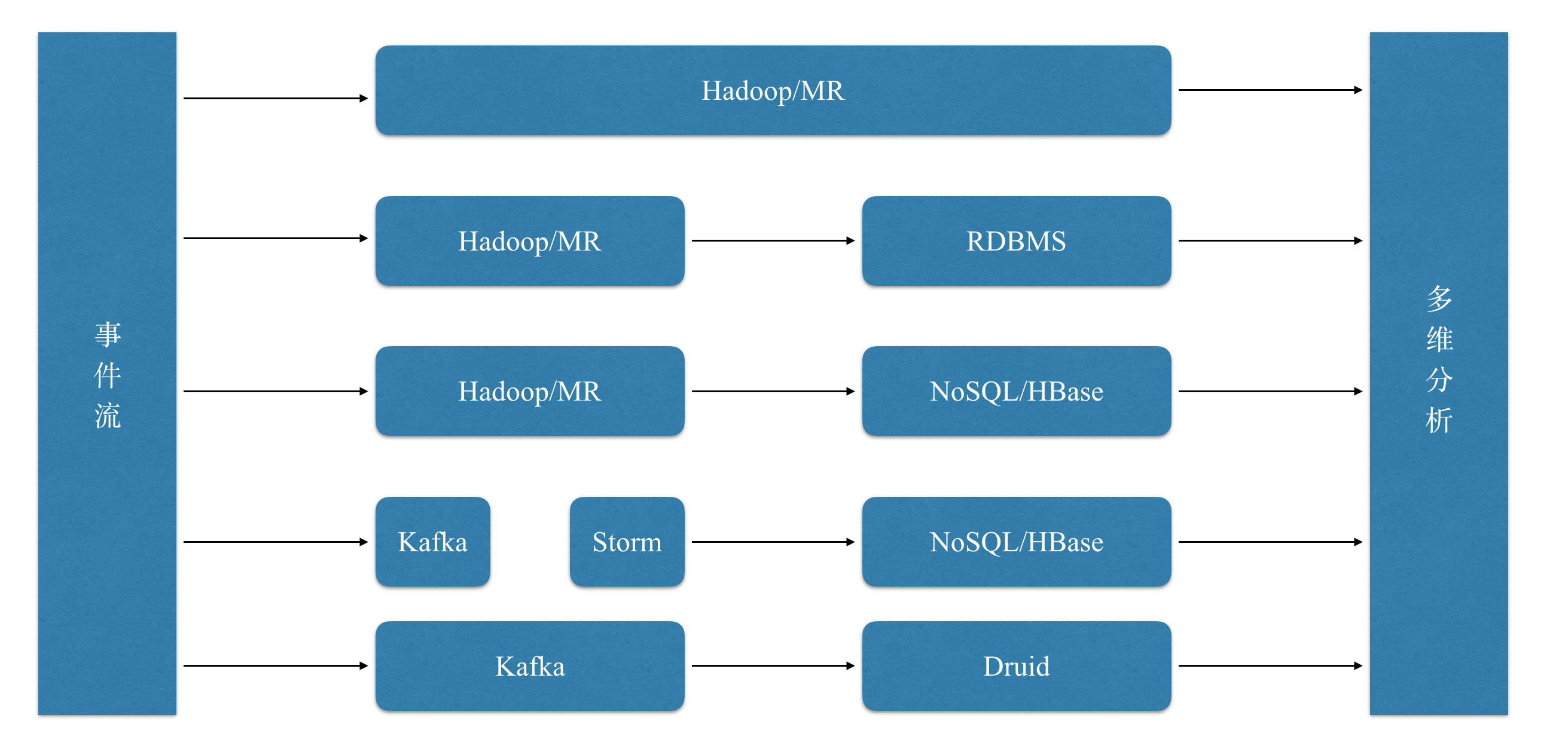
数据分析的基础架构可以分为以下几类:
- 使用Hadoop/Spark进行分析
- 将Hadoop/Spark的结果导入 RDBMS 中提供数据分析
- 将结果保存到容量更大的 NoSQL 数据库中,解决数据分析的存储瓶颈,例如:HBase
- 将数据源进行流式处理,对接流式计算框架(如Storm、Spark、Flink),结果保存到 RDBMS或NoSQL中
- 将数据源进行流式处理,对接分析数据库,例如:Druid
互联网技术的快速增长催生了各类大体量的数据,Hadoop很大的贡献在于帮助企业将他们那些低价值的事件流数据转化为高价值的聚合数据;
Hadoop擅长的是存储和获取大规模数据,它并不提供任何性能上的保证它能多快获取到数据。虽然Hadoop是一个高可用的系统,但在高并发负载下性能会下降;
Hadoop是一个很好的后端、批量处理和数据仓库系统。在一个需要高并发并且保证查询性能和数据可用性的并需要提供产品级别的保证的需求,Hadoop并不能满足。
Druid 是 Metamarkets 公司(一家为在线媒体或广告公司提供数据分析服务的公司)推出的一个分布式内存实时分析系统,用于解决如何在大规模数据集下进行快速的、交互式的查询和分析。
Druid 是一个开源的数据分析引擎工具,为实时和历史数据的次秒级(多于一秒)查询设计。主要应用于对数据的OLAP查询,Druid 提供低延迟(实时)的数据摄取、灵活的数据探索、快速的数据聚合。现有的 Druid 部署已支持扩展到数万亿时间和 PB 级数据。
1.2 与其他OLAP技术对比
| Druid | Kylin | ES | Spark SQL | ClickHouse | |
|---|---|---|---|---|---|
| 数据规模 | 超大 | 超大 | 中等 | 超大 | 中 |
| 查询效率 | 高 | 高 | 中等 | 低 | 高 |
| 并发度 | 高 | 高 | 高 | 低 | 中 |
| 灵活性 | 中 | 低 | 高 | 高 | 高 |
| SQL支持 | 中 | 高 | 中 | 高 | 高 |
SparkSQL / Impala / ClickHouse,支持海量数据,灵活性强,但对响应时间是没有保证的。当数据量和计算复杂度增加后,响应时间会变慢,从秒级到分钟级,甚至小时级都有可能。
搜索引擎架构的系统(Elasticsearch等),在入库时将数据转换为倒排索引。牺牲了灵活性换取很好的性能,在搜索类查询上能做到亚秒级响应,但是对于扫描聚合为主的查询,随着处理数据量的增加,响应时间也会退化到分钟级。
Druid / Kylin,则在入库时对数据进行预聚合,进一步牺牲灵活性换取性能,以实现对超大数据集的秒级响应。
- Kylin 利用 Hadoop/HBase 做计算和存储,使用 SQL 查询,提供 JDBC/ODBC 驱动与常见 BI 工具集成
- Druid 有自己独立的分布式集群,能够实时摄入数据,有自己的查询接口(与BI兼容性较弱),通常多用于实时要求高的场景
目前没有一个OLAP分析引擎能在数据量、灵活程度、性能(吞吐&并发)做到完美,需要基于自己的业务场景进行取舍和选型。
1.3 技术特点
Apache Druid是一个开源的、分布式、实时OLAP分析工具。Druid的核心设计结合了数据仓库、时间序列数据库和搜索系统的思想,适用于多种场景的高性能数据实时分析。Druid将这三个系统中的每个系统的关键特征合并到其接收层、存储格式、查询层和核心体系结构中。
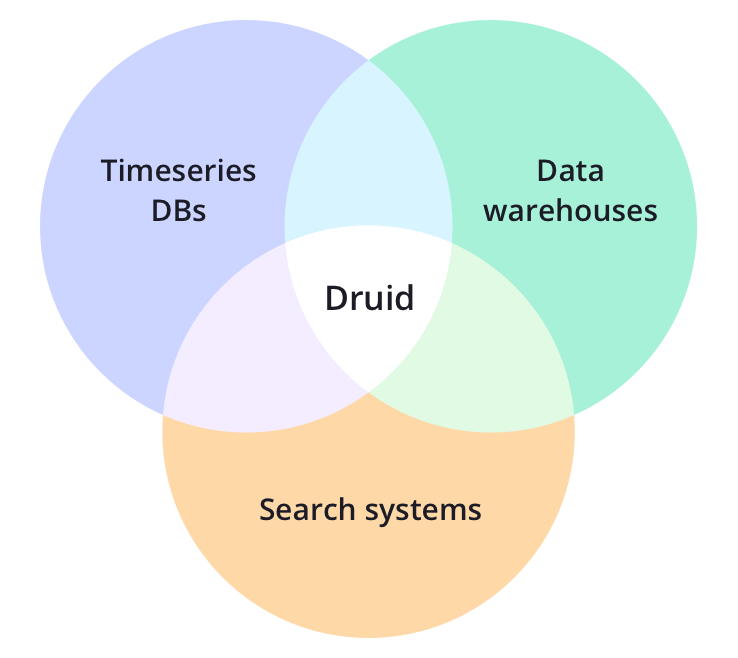
时间序列数据库主要用于处理带时间标签(按照时间的顺序变化)的数据,带时间标签的数据也称为时间序列数据。
时间序列数据主要由电力行业、化工行业等各类型实时监测、检查与分析设备所采集、产生的数据,这些工业数据的典型特点是:产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(常规的实时监测系统均有成千上万的监测点,监测点每秒钟都产生数据,每天产生几十GB的数据量)。
1、主要特点
-
列式存储
Druid 独立的存储和压缩每一列,只需要读取特定查询所需的内容,这可以支持快速扫描、排名和聚合
-
流式和批量摄取(Ingestion)
支持 Apache Kafka、HDFS、AWS S3、stream processors 等现成连接器
-
本地的搜索索引
Druid 为字符串创建倒排索引,以支持快速搜索和排序
-
灵活的 schema
Druid 可以处理变化的 schema 和嵌套数据
-
基于时间优化 partition
Druid 基于时间智能的对数据进行分区,基于时间的查询比传统数据库要快得多
-
支持 SQL
Druid 支持本机的 JSON 语言,还支持基于 HTTP 或者 JDBC 的 SQL
-
水平扩展性
Druid 用于生产环境中,每秒接收数百万个事件,保存多年的数据并提供次秒级查询
-
操作简单
只需要增加或删除服务器即可扩展或缩小规模,Druid 会自动平衡,容错架构通过服务器的故障进行路由
2、集成
Druid是开源大数据技术的补充,包括Apache Kafka,Apache Hadoop,Apache Flink等,通常位于存储或处理层与最终应用之间,充当查询层或数据分析服务。
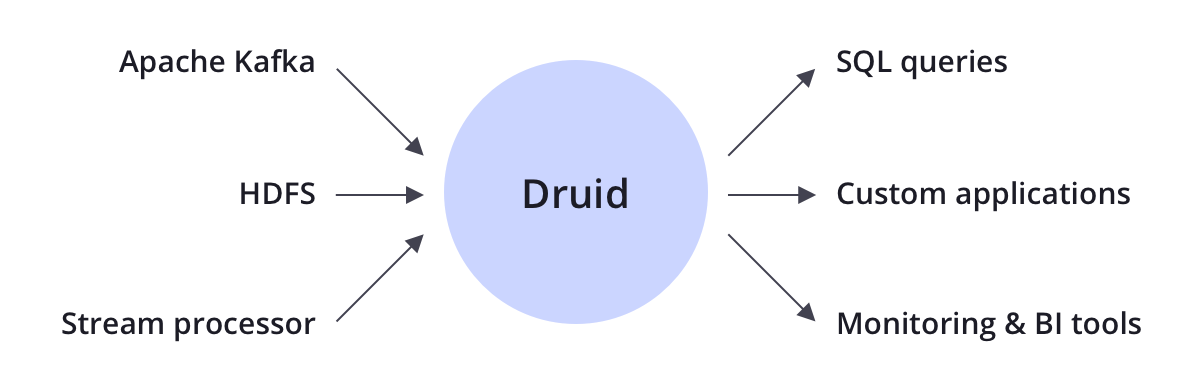
3、Ingestion(摄取)
Druid支持流式传输和批量摄取。Druid连接到数据源,包括:Kafka(用于流数据加载),或分布式文件系统,如HDFS(用于批处理数据加载)。
Druid在 “索引” 过程中将数据源中的原始数据转换为支持高效读取的优化格式(Segment,段)。
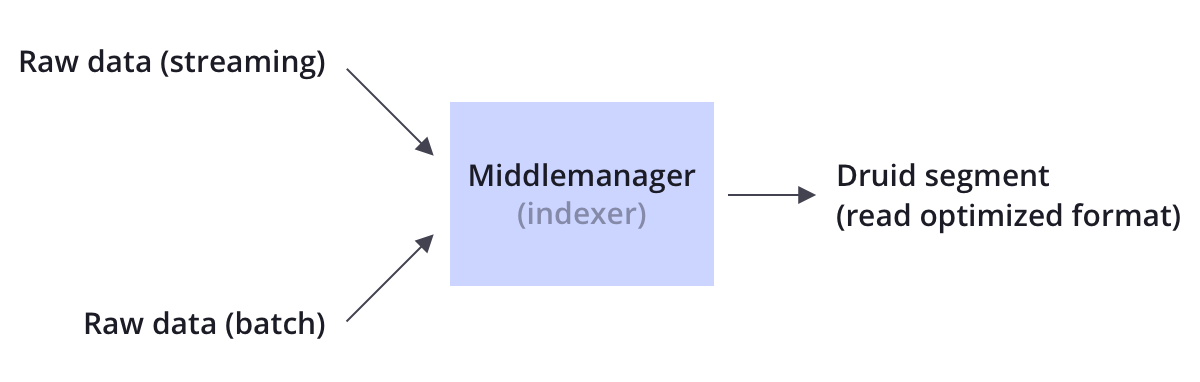
4、存储
Druid的数据存储采用列式存储格式。根据列的类型(字符串,数字等),应用不同的压缩和编码方法,根据列类型构建不同类型的索引。
Druid为字符串列构建倒排索引,以进行快速搜索和过滤。Druid可按时间对数据进行智能分区,以实现面向时间的快速查询。
Druid在摄取数据时对数据进行预聚合,节省大量存储空间。
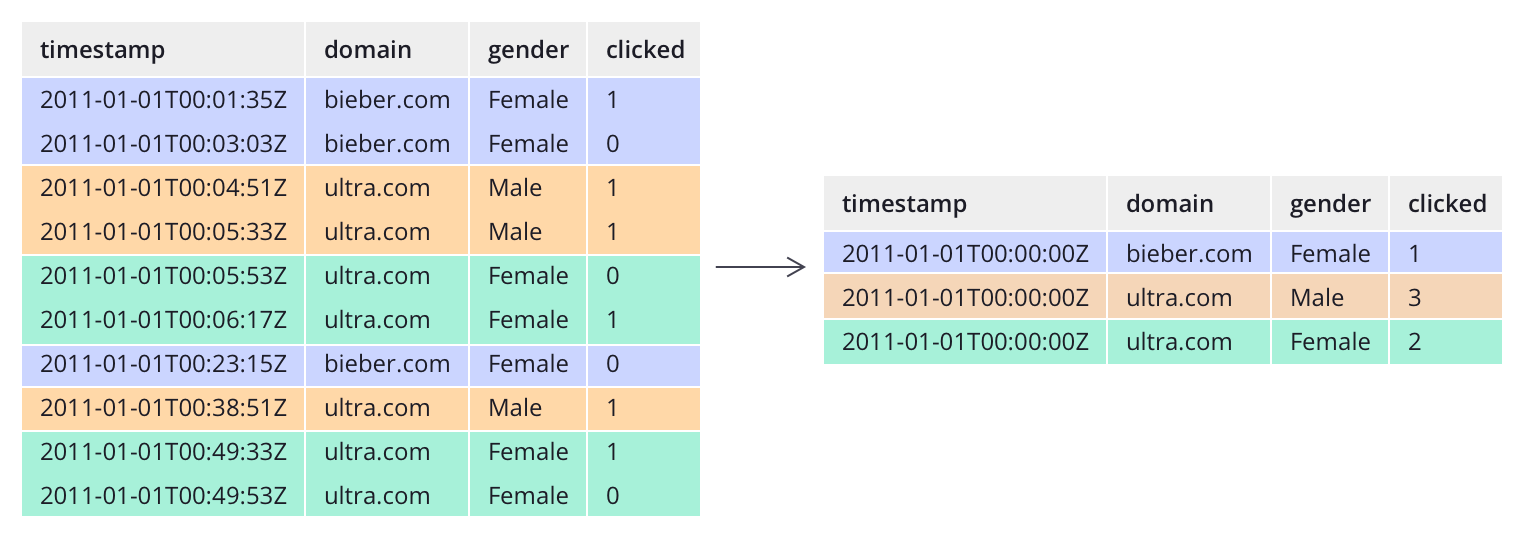
5、查询方式
Druid支持JSON、SQL两种方式查询数据。
1.4 应用场景
Druid擅长的部分
- 对于大部分查询场景可以亚秒级响应
- 事件流实时写入与批量数据导入兼备
- 数据写入前预聚合节省存储空间,提升查询效率
- 水平扩容能力强
是否需要使用Druid
- 处理时间序列事件
- 快速的聚合以及探索式分析
- 近实时分析亚秒级响应
- 存储大量(TB级、PB级)可以预先定义若干维度的事件
- 无单点问题的数据存储
体系架构
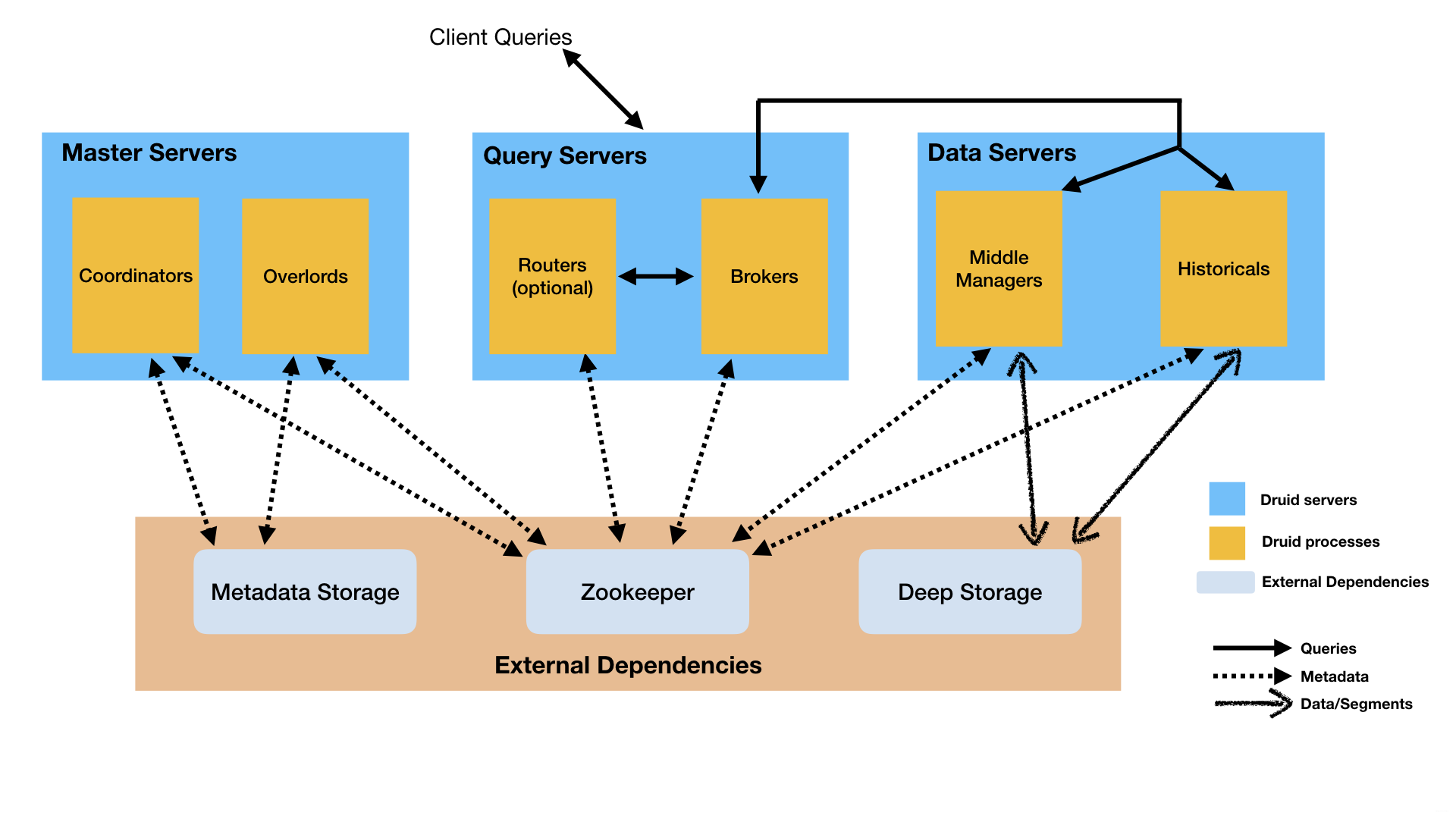
2.1 Druid进程和服务
- Coordinator 进程管理群集上的数据可用性。从metastore中读取Segment的元数据,并决定哪些Segments需要被加载到集群中。使用ZooKeeper查看已经存在的历史节点,了解集群各个节点负载情况。创建一个ZK的条目告诉历史节点加载、删除、或者移动Segments
- Overlord 进程控制数据提取工作负载的分配
- Historical 进程存储可查询数据。提供对Segment的数据查询服务。与ZooKeeper通信,上报节点信息,告知ZK自己拥有哪些Segments。从ZooKeeper中获取执行任务
- MiddleManager 进程负责提取数据
- Broker 进程处理来自外部客户端的查询。负责将查询请求分发到历史节点和实时节点,并聚合这些节点返回的查询结果数据。Broker节点通过zooeeper知道Segment都存放在哪些节点上
- Router 进程是可选的进程,可以将请求路由到Broker、Coordinator、Overlords
根据线程的服务类型分为:
-
Master:Coordinator & Overload 进程,管理数据可用性和数据摄取
-
Data:Historical & MiddleManager,执行提取工作负载并存储所有可查询数据
-
Query:Broker & Router,处理来自外部客户端的查询

2.2 外部依赖
- Deep Storage:深度存储,例如HDFS或者S3。不是用来存储查询数据的。而是作为数据的备份或者进程间数据交换
- Metadata Storage:元数据存储,可以用RDBMS
- ZooKeeper:服务发现、leader选举、服务协调
Part 2 Druid 部署
Druid官网:https://druid.apache.org/
下载 Druid 安装包、并解压缩:
cd /opt/lagou/software
wget http://apache.communilink.net/druid/0.19.0/apache-druid-0.19.0-bin.tar.gz
tar -zxvf apache-druid-0.19.0-bin.tar.gz
查看主目录:
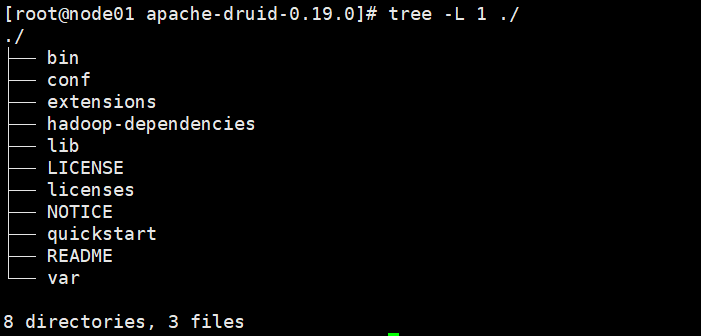
tree -L 1 ./
./
├── bin 运行相关脚本文件
├── conf 生产环境配置文件
├── extensions 各种jar包,第三方扩展
├── hadoop-dependencies hadoop相关依赖
├── lib Druid所有核心软件包
├── LICENSE 许可证
├── licenses
├── NOTICE 对快速入门很有用帮助的文档
├── quickstart 单机测试部署用到的配置及数据
├── README
└── var 启动时生成文件,数据文件在这里了
单服务器部署
单服务器部署的配置文件:
conf/druid/single-server/
├── large
├── medium
├── micro-quickstart
├── nano-quickstart
├── small
└── xlarge
单服务器参考配置:
Nano-Quickstart:1个CPU,4GB RAM
启动命令: bin/start-nano-quickstart
配置目录: conf/druid/single-server/nano-quickstart/*
微型快速入门:4个CPU,16GB RAM
启动命令: bin/start-micro-quickstart
配置目录: conf/druid/single-server/micro-quickstart/*
小型:8 CPU,64GB RAM(〜i3.2xlarge)
启动命令: bin/start-small
配置目录: conf/druid/single-server/small/*
中:16 CPU,128GB RAM(〜i3.4xlarge)
启动命令: bin/start-medium
配置目录: conf/druid/single-server/medium/*
大型:32 CPU,256GB RAM(〜i3.8xlarge)
启动命令: bin/start-large
配置目录: conf/druid/single-server/large/*
大型X:64 CPU,512GB RAM(〜i3.16xlarge)
启动命令: bin/start-xlarge
配置目录: conf/druid/single-server/xlarge/*
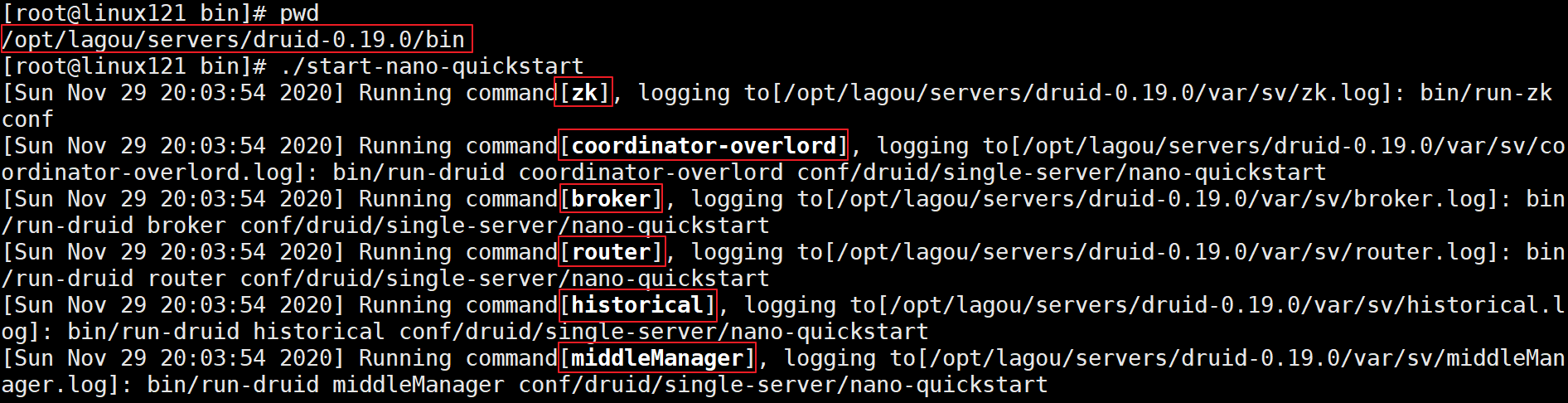
启动Druid:
./bin/start-nano-quickstart start
登录http://wcentos7-1:8888/查看页面
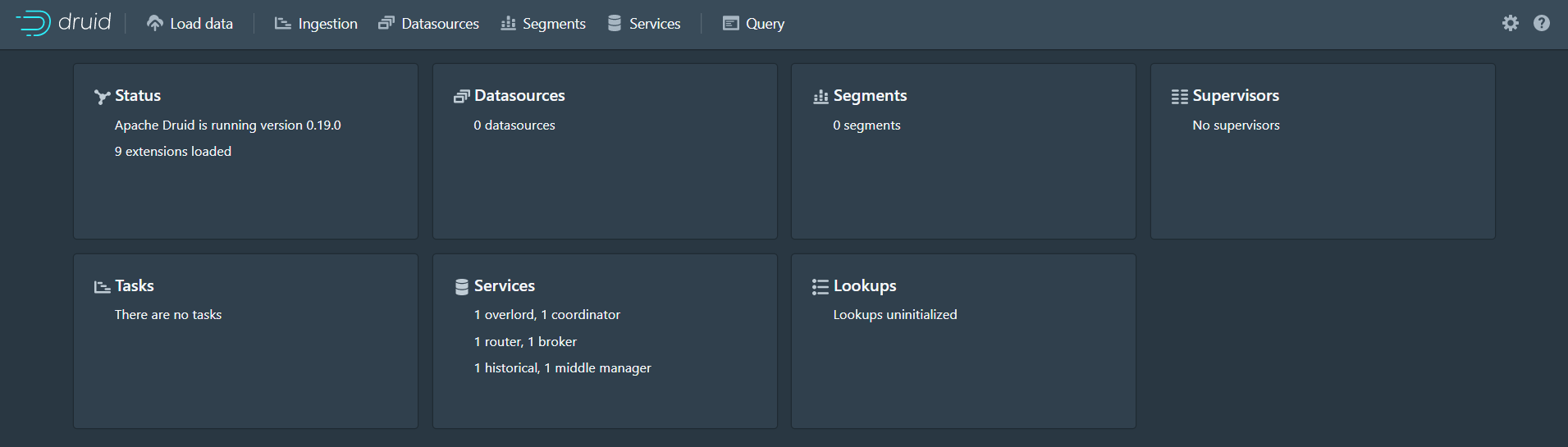
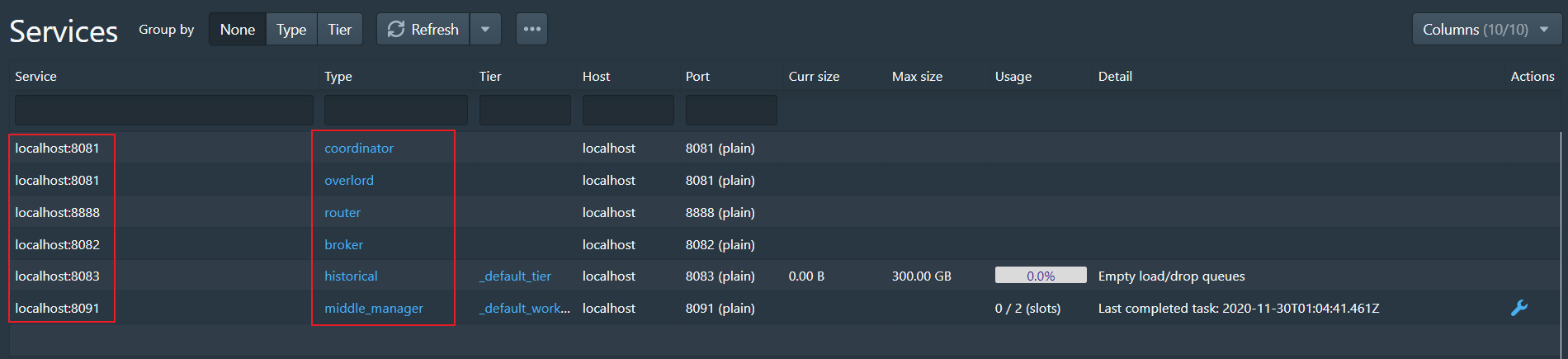
使用jps可以看见启动了很多服务:
官方建议大型系统采用集群模式部署,以实现容错和减少资源争用。
集群部署
1、部署规划
集群部署采用的分配如下:
- 主节点部署 Coordinator 和 Overlord进程
- 数据节点运行 Historical 和 MiddleManager进程
- 查询节点 部署 Broker 和 Router 进程
| 主机 | Druid服务 | 其他服务 |
|---|---|---|
| linux121 | Coordinator、Overlord | Zookeeper、Kafka |
| linux122 | Historical、MiddleManager | Zookeeper、Kafka |
| linux123 | Router、Broker | Zookeeper、Kafka、MySQL |
虚拟机每个节点2core、3G
DeepStorage:Hadoop 2.9.2
2、设置环境变量
vi /etc/profile
# 在文件中增加以下内容
export DRUID_HOME=/opt/lagou/servers/druid-0.19.0
export PATH=$PATH:$DRUID_HOME/bin
3、MySQL中创建相关数据库
使用 root 账号登录MySQL,mysql -uroot -p12345678
CREATE DATABASE druid DEFAULT CHARACTER SET utf8mb4;
CREATE USER 'druid'@'%' IDENTIFIED BY '12345678';
GRANT ALL PRIVILEGES ON druid.* TO 'druid'@'%';
-- ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
set global validate_password_policy=0;
4、配置Druid参数
将hadoop配置文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml链接到 conf/druid/cluster/_common/ 下
cd /opt/lagou/servers/druid-0.19.0/conf/druid/cluster/_common
ln -s $HADOOP_HOME/etc/hadoop/core-site.xml core-site.xml
ln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml hdfs-site.xml
ln -s $HADOOP_HOME/etc/hadoop/yarn-site.xml yarn-site.xml
ln -s $HADOOP_HOME/etc/hadoop/mapred-site.xml mapred-site.xml
将MySQL的驱动程序,链接到 $DRUID_HOME/extensions/mysql-metadata-storage/ 下
ln -s $HIVE_HOME/lib/mysql-connector-java-5.1.46.jar mysql-connector-java-5.1.46.jar
修改配置文件($DRUID_HOME/conf/druid/cluster/_common/common.runtime.properties)
# 增加"mysql-metadata-storage"
druid.extensions.loadList=["mysql-metadata-storage", "druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches"]
# 每台机器写自己的ip或hostname
druid.host=linux121
# 填写zk地址
druid.zk.service.host=linux121:2181,linux122:2181,linux123:2181
druid.zk.paths.base=/druid
# 注释掉前面 derby 的配置
# 增加 mysql 的配置
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://linux123:3306/druid
druid.metadata.storage.connector.user=druid
druid.metadata.storage.connector.password=12345678
# 注释掉local的配置
# 增加HDFS的配置,即使用HDFS作为深度存储
druid.storage.type=hdfs
druid.storage.storageDirectory=/druid/segments
# 注释掉 indexer.logs For local disk的配置
# 增加 indexer.logs For HDFS 的配置
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=/druid/indexing-logs
配置主节点文件(参数大小根据实际情况配置)
$DRUID_HOME/conf/druid/cluster/master/coordinator-overlord/jvm.config
-server
-Xms512m
-Xmx512m
-XX:+ExitOnOutOfMemoryError
-XX:+UseG1GC
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
配置数据节点文件(参数大小根据实际情况配置)
$DRUID_HOME/conf/druid/cluster/data/historical/jvm.config
-server
-Xms512m
-Xmx512m
-XX:MaxDirectMemorySize=1g
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
$DRUID_HOME/conf/druid/cluster/data/historical/runtime.properties
# 修改这一个参数
druid.processing.buffer.sizeBytes=50000000
备注: druid.processing.buffer.sizeBytes 每个查询用于聚合的堆外哈希表的大小
maxDirectMemory= druid.processing.buffer.sizeBytes * (druid.processing.numMergeBuffers + druid.processing.numThreads + 1)
如果 druid.processing.buffer.sizeBytes 太大,那么需要加大maxDirectMemory,否则 historical 服务无法启动
$DRUID_HOME/conf/druid/cluster/data/middleManager/jvm.config
-server
-Xms128m
-Xmx128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
配置查询节点文件(参数大小根据实际情况配置)
$DRUID_HOME/conf/druid/cluster/query/broker/jvm.config
-server
-Xms512m
-Xmx512m
-XX:MaxDirectMemorySize=512m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
$DRUID_HOME/conf/druid/cluster/query/broker/runtime.properties
# 修改这一个参数
druid.processing.buffer.sizeBytes=50000000
备注:
druid.processing.buffer.sizeBytes 每个查询用于聚合的堆外哈希表的大小
maxDirectMemory = druid.processing.buffer.sizeBytes*(druid.processing.numMergeBuffers + druid.processing.numThreads + 1)
如果 druid.processing.buffer.sizeBytes 太大,那么需要加大maxDirectMemory,否则 broker 服务无法启动
$DRUID_HOME/conf/druid/cluster/query/router/jvm.config
-server
-Xms128m
-Xmx128m
-XX:+UseG1GC
-XX:MaxDirectMemorySize=128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
小结:各服务 JVM 内存分配设置如下:
- coordinator-overlord,512m
- historical,512m、堆外1g
- middleManager,128m
- broker,512m、堆外 512m
- router,128m、堆外 128m
5、分发并启动服务
向linux122、linux123分发安装包
scp -r druid-0.19.0/ linux122:$PWD
scp -r druid-0.19.0/ linux123:$PWD
备注:
- 分发后一定要修改 common.runtime.properties 中的 druid.host 为所在节点的ip
- 在linux122、linux123上添加环境变量 $DRUID_HOME
先启动zk的服务:
# linux121
zk.sh start
在主节点(linux121)上启动服务:
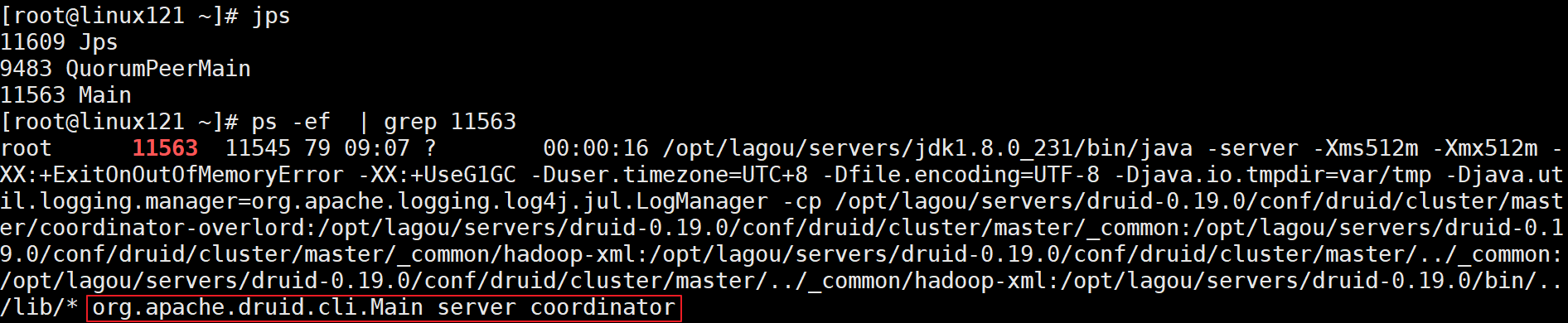
nohup start-cluster-master-no-zk-server &
使用jps检查可看见1个名为Main的后台进程,如下图所示:
在数据节点(linux122)上启动服务:
nohup start-cluster-data-server &
使用jps检查可看见2个名为Main的后台进程,如下图所示:
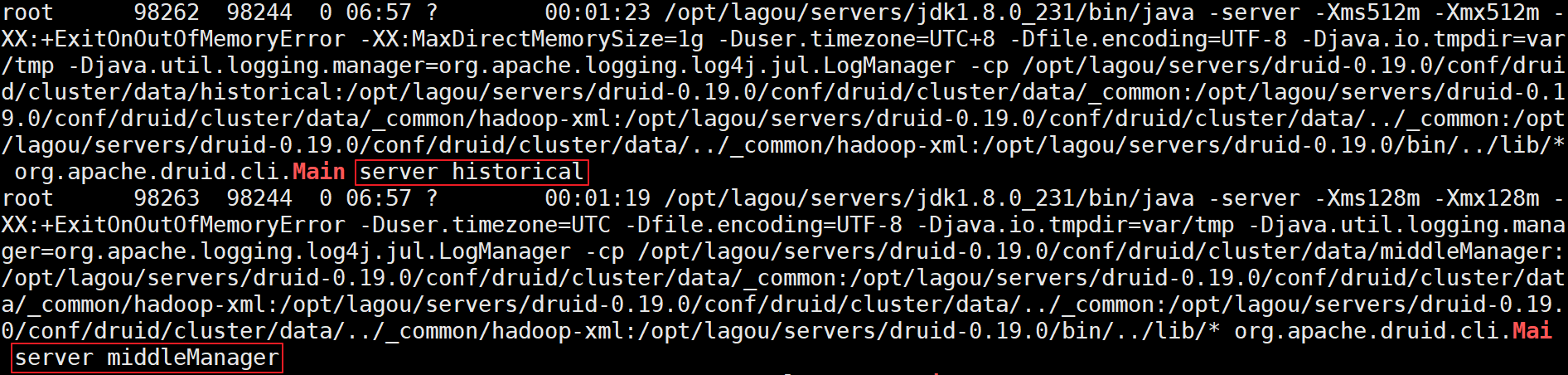
在查询节点(linux123)上启动服务:
nohup start-cluster-query-server &
使用jps检查可看见2个名为Main的后台进程,如下图所示:
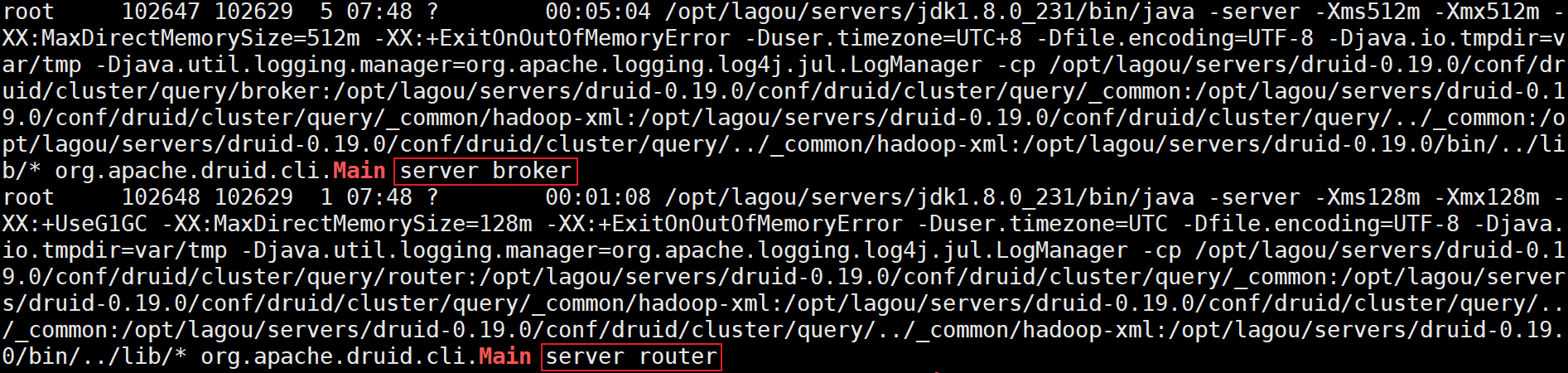
关闭服务:
# 在各个节点运行
cd /opt/lagou/servers/druid-0.19.0/bin
./service --down
6、查看界面
使用浏览器查看:http://linux123:8888/
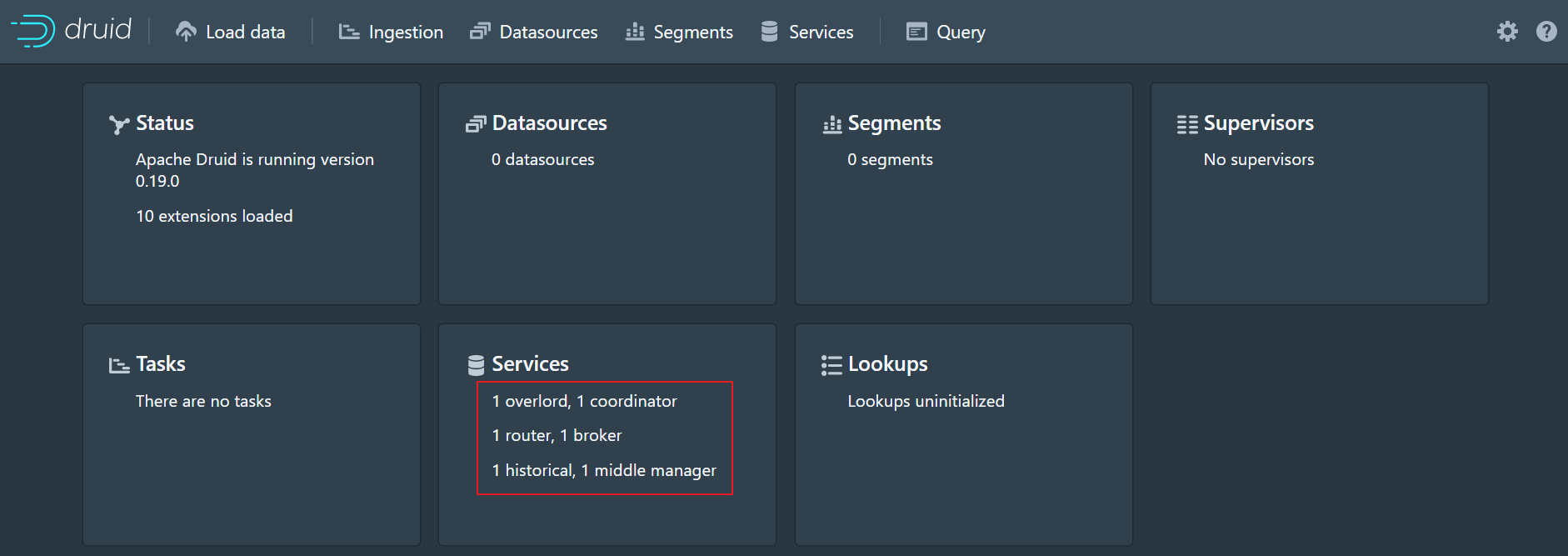
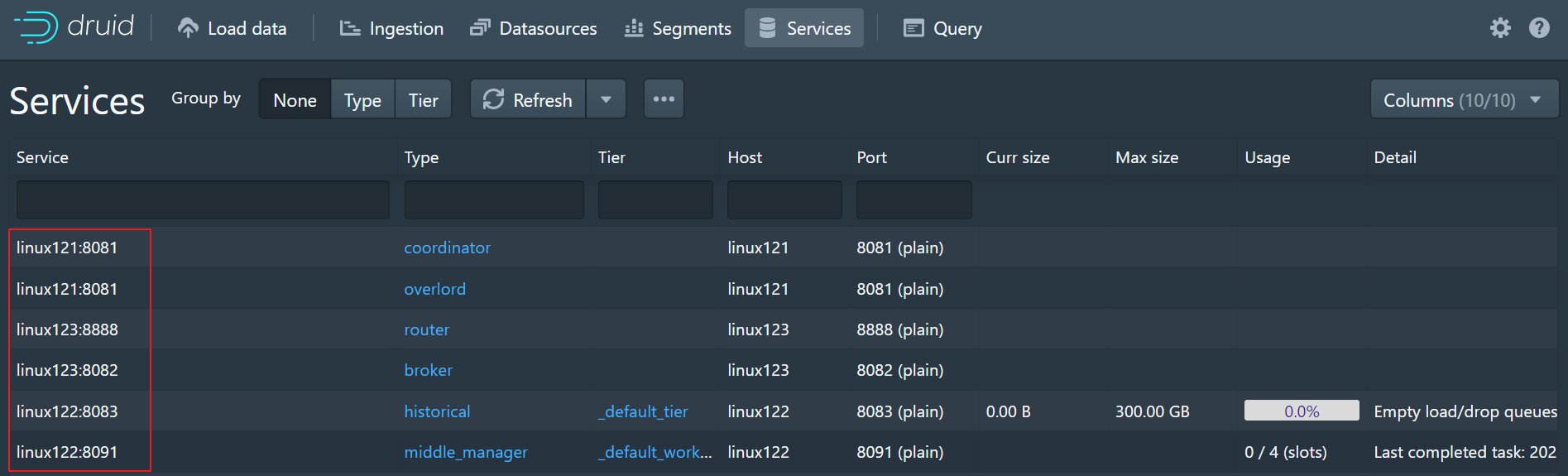
Part 3 Druid入门案例
从Kafka中加载流式数据
1.1 数据及需求说明
Druid典型应用架构

不在Druid中处理复杂的数据转换清洗工作
假设有以下网络流量数据:
ts:时间戳srcip:发送端 IP 地址srcport:发送端端口号dstip:接收端 IP 地址dstport:接收端端口号protocol:协议packets:传输包的数量bytes:传输字节数cost:传输耗费的时间
数据为json格式,通过Kafka传输
每行数据包含:时间戳(ts)、维度列、指标列
维度列:srcip、srcport、dstip、dstport、protocol
指标列:packets、bytes、cost
需要计算的指标:
- 记录的条数:count
- packets:max
- bytes:min
- cost:sum
数据汇总的粒度:分钟
测试数据:
{"ts":"2020-10-01T00:01:35Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666, "dstPort":8888, "protocol": "tcp", "packets":1, "bytes":1000, "cost": 0.1}
{"ts":"2020-10-01T00:01:36Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666, "dstPort":8888, "protocol": "tcp", "packets":2, "bytes":2000, "cost": 0.1}
{"ts":"2020-10-01T00:01:37Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666, "dstPort":8888, "protocol": "tcp", "packets":3, "bytes":3000, "cost": 0.1}
{"ts":"2020-10-01T00:01:38Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666, "dstPort":8888, "protocol": "tcp", "packets":4, "bytes":4000, "cost": 0.1}
{"ts":"2020-10-01T00:02:08Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":5, "bytes":5000, "cost": 0.2}
{"ts":"2020-10-01T00:02:09Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":6, "bytes":6000, "cost": 0.2}
{"ts":"2020-10-01T00:02:10Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":7, "bytes":7000, "cost": 0.2}
{"ts":"2020-10-01T00:02:11Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":8, "bytes":8000, "cost": 0.2}
{"ts":"2020-10-01T00:02:12Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":9, "bytes":9000, "cost": 0.2}
最后执行查询:
select * from tab;
-- 有两个返回值,以下仅为示意
{"ts":"2020-10-01T00:01","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666, "dstPort":8888, "protocol": "tcp", "packets":5, "bytes":1000, "cost": 0.4, "count":4}
{"ts":"2020-10-01T00:02","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":9, "bytes":5000, "cost": 1.0, "count":5}
-- 其他查询
select dstPort, min(packets), max(bytes), sum(count), min(count)
from tab
group by dstPort
1.2 创建Topic发送消息
启动Kafka集群,并创建一个名为 “lagoudruid1” 的 Topic :
-- 创建topic
kafka-topics.sh --create --zookeeper linux121:2181,linux122:2181/kafka1.0 --replication-factor 2 --partitions 6 --topic lagoudruid1
-- 启动生产者
kafka-console-producer.sh --broker-list linux121:9092,linux122:9092 --topic lagoudruid1
备注:–zookeeper linux121:2181,linux122:2181/kafka1.0 => kafka1.0为namespace,请注意自己是否添加了
1.3 摄取数据
浏览器访问 linux123:8888,点击控制台中的 Load data
1、Start
选择 Apache Kafka ,点击 Connect data
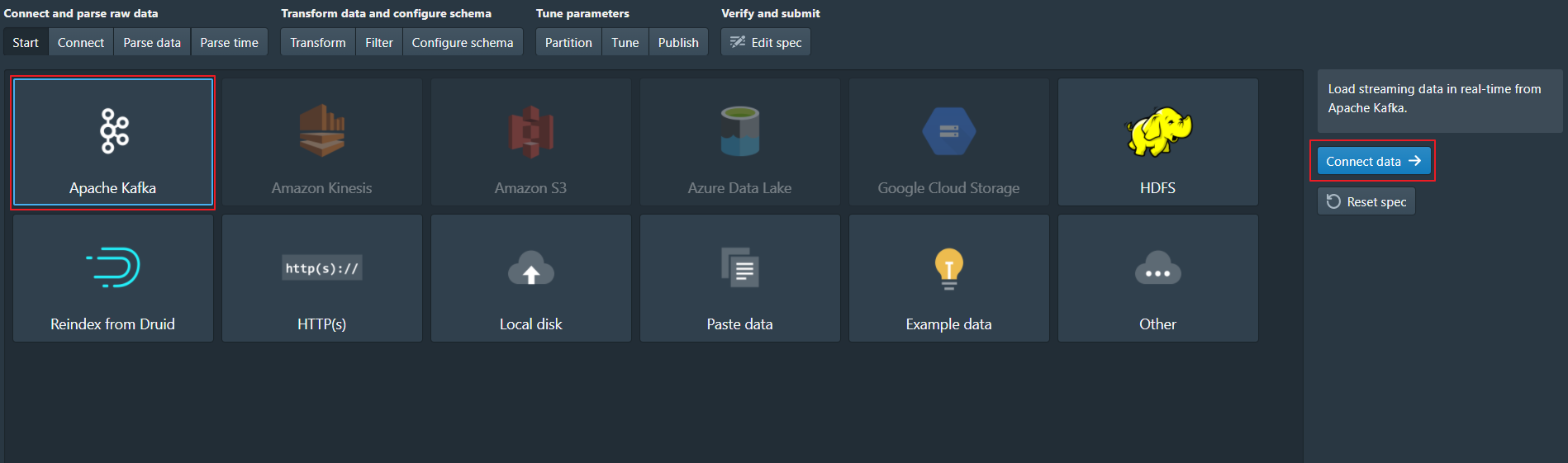
2、Connect
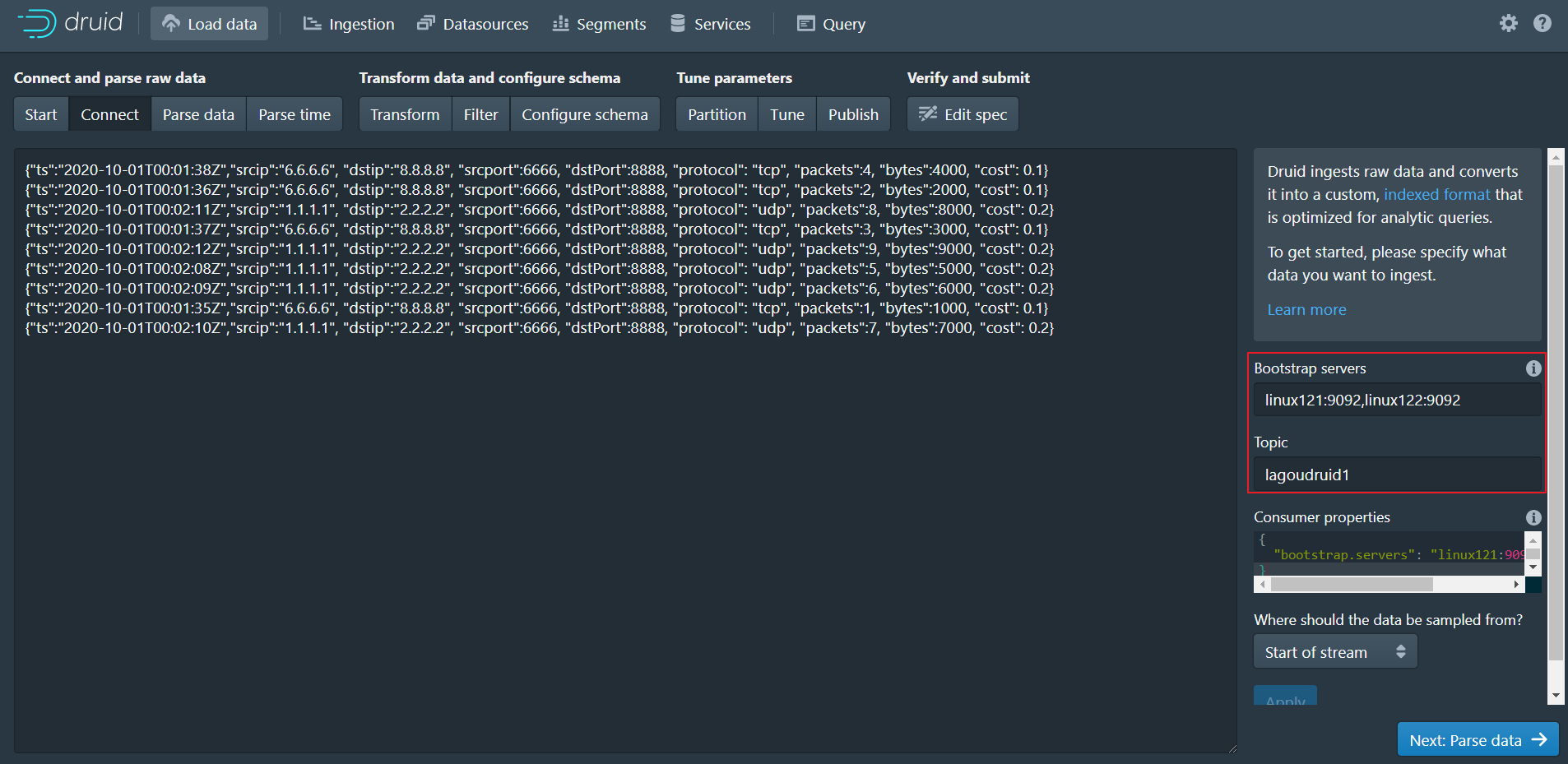
- 在
Bootstrap servers输入linux121:9092,linux122:9092 - 在
Topic输入lagoudruid1 - 点击
Preview确保看到的数据是正确的 - 后点击”Next: Parse data”进入下一步
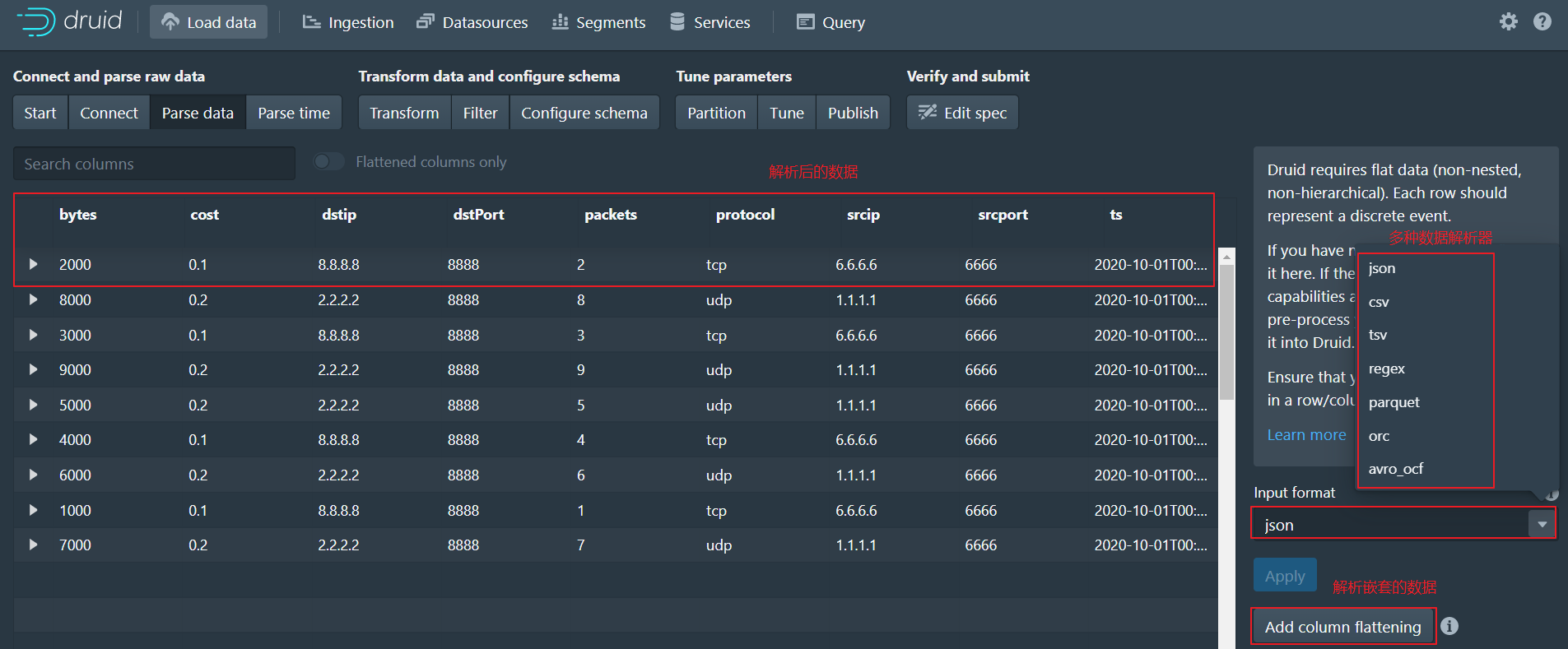
3、Parse data
-
数据加载器将尝试自动为数据确定正确的解析器。可以使用多种解析器解析数据
-
这里使用
json解析器解析数据
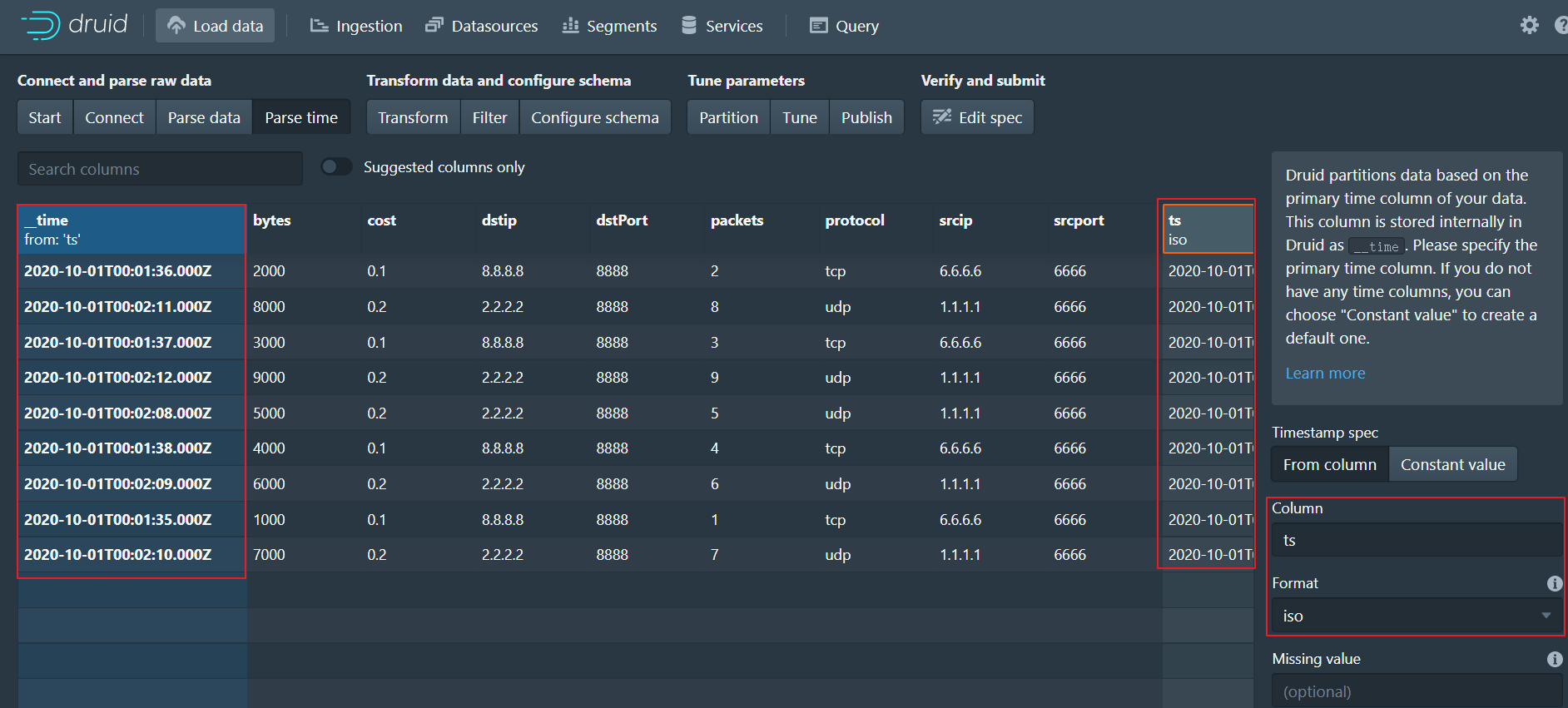
4、Parse time
- 定义数据的主时间列
5、Tranform
- 不建议在Druid中进行复杂的数据转换操作,可考虑将这些操作放在数据预处理
- 这里没有定义数据转换
6、Filter
- 不建议在Druid中进行复杂的数据过滤操作,可考虑将这些操作放在数据预处理
- 这里没有定义数据过滤
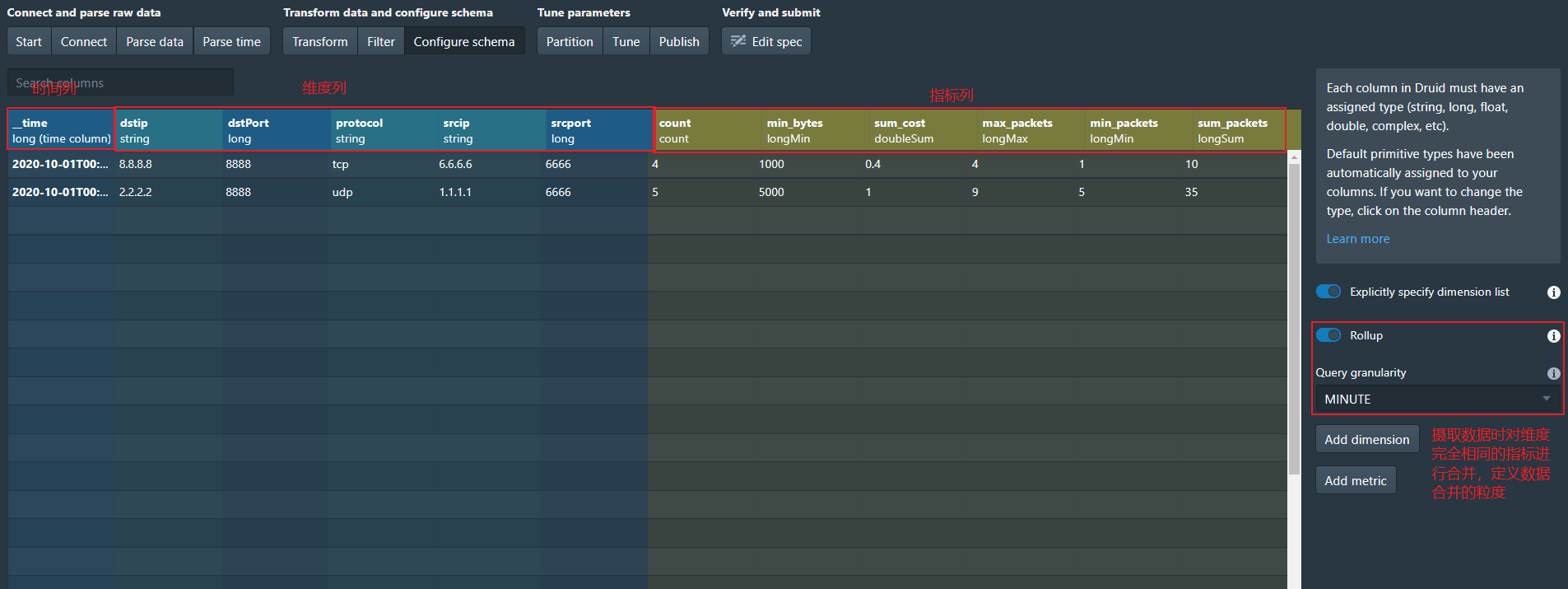
7、configure Schema
- 定义指标列、维度列
- 定义如何在维度列上进行计算
- 定义是否在摄取数据时进行数据的合并(即Rollup),以及Rollup的粒度
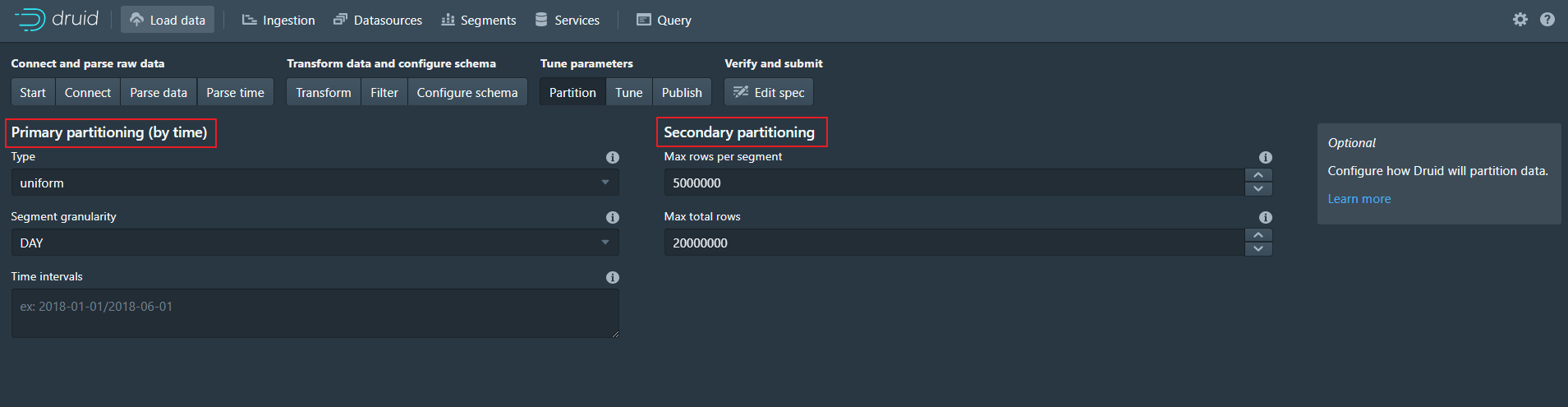
8、Partition
- 定义如何进行数据分区
- Primary partitioning有两种方式
- uniform,以一个固定的时间间隔聚合数据,建议使用这种方式。这里将每天的数据作为一个分区
- arbitrary,尽量保证每个segments大小一致,时间间隔不固定
- Secondary partitioning
- Max rows per segment,每个Segment最大的数据条数
- Max total rows,Segment等待发布的最大数据条数
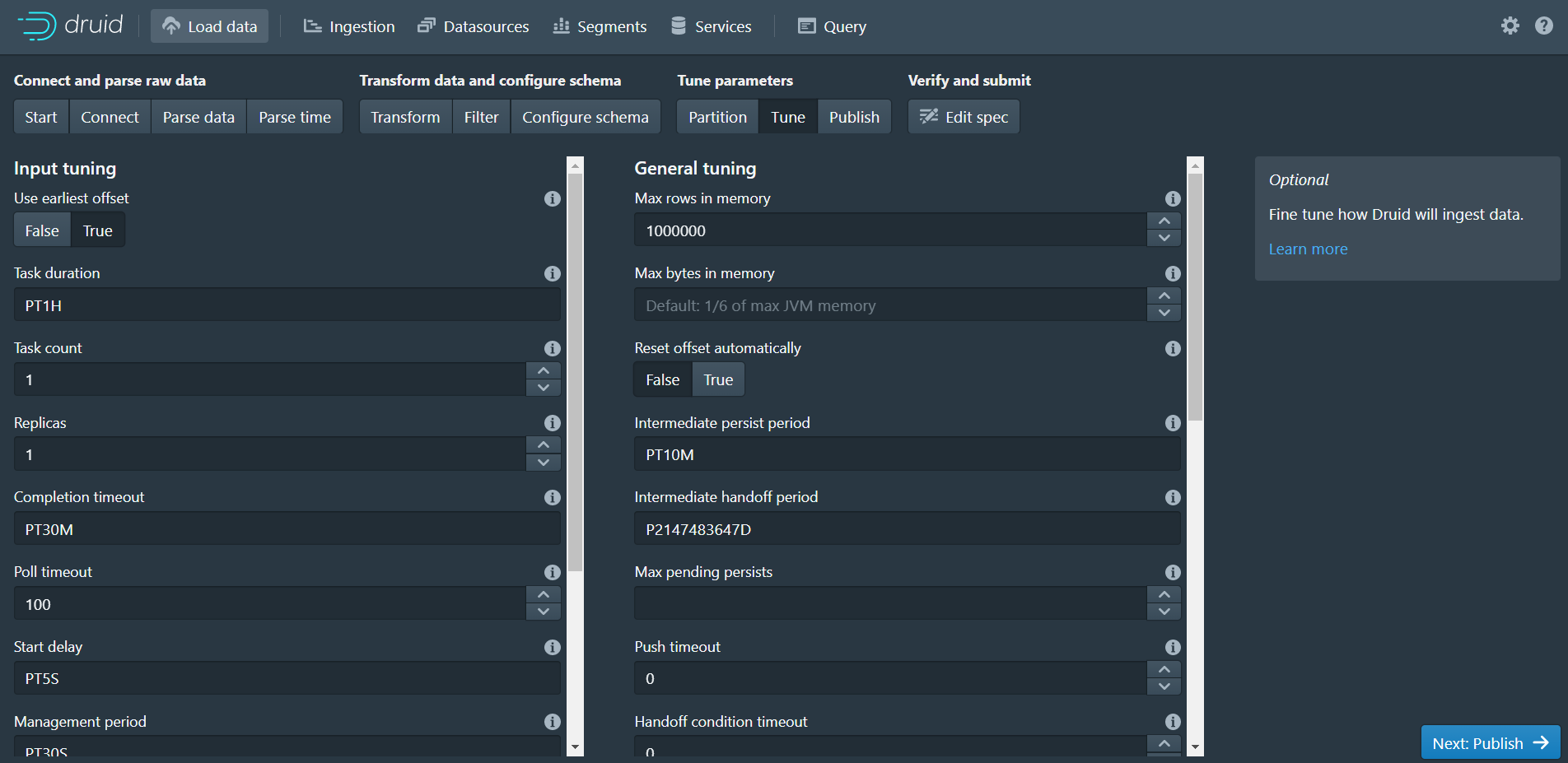
9、Tune
- 定义任务执行和优化的相关参数
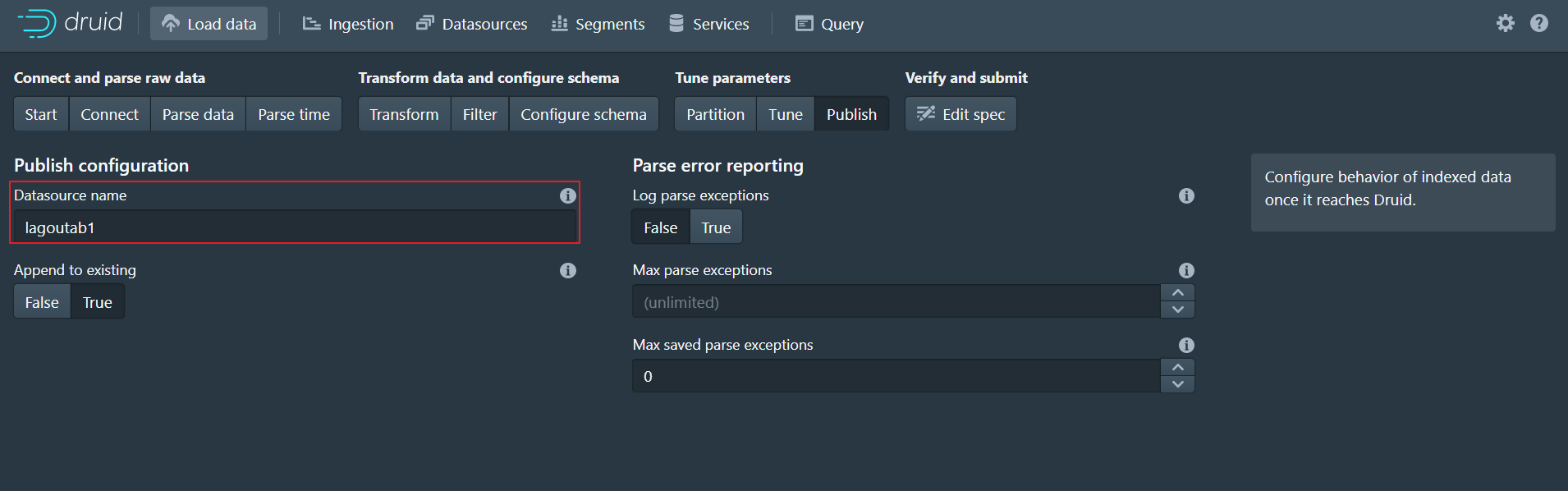
10、Publish
- 定义Datasource的名称
- 定义数据解析失败后采取的动作
11、Edit spec
- json串为数据摄取规范。可返回之前的步骤中进行更改,也可以直接编辑规范,并在前面的步骤中看到它
- 摄取规范定义完成后,单击
Submit将创建一个数据摄取任务
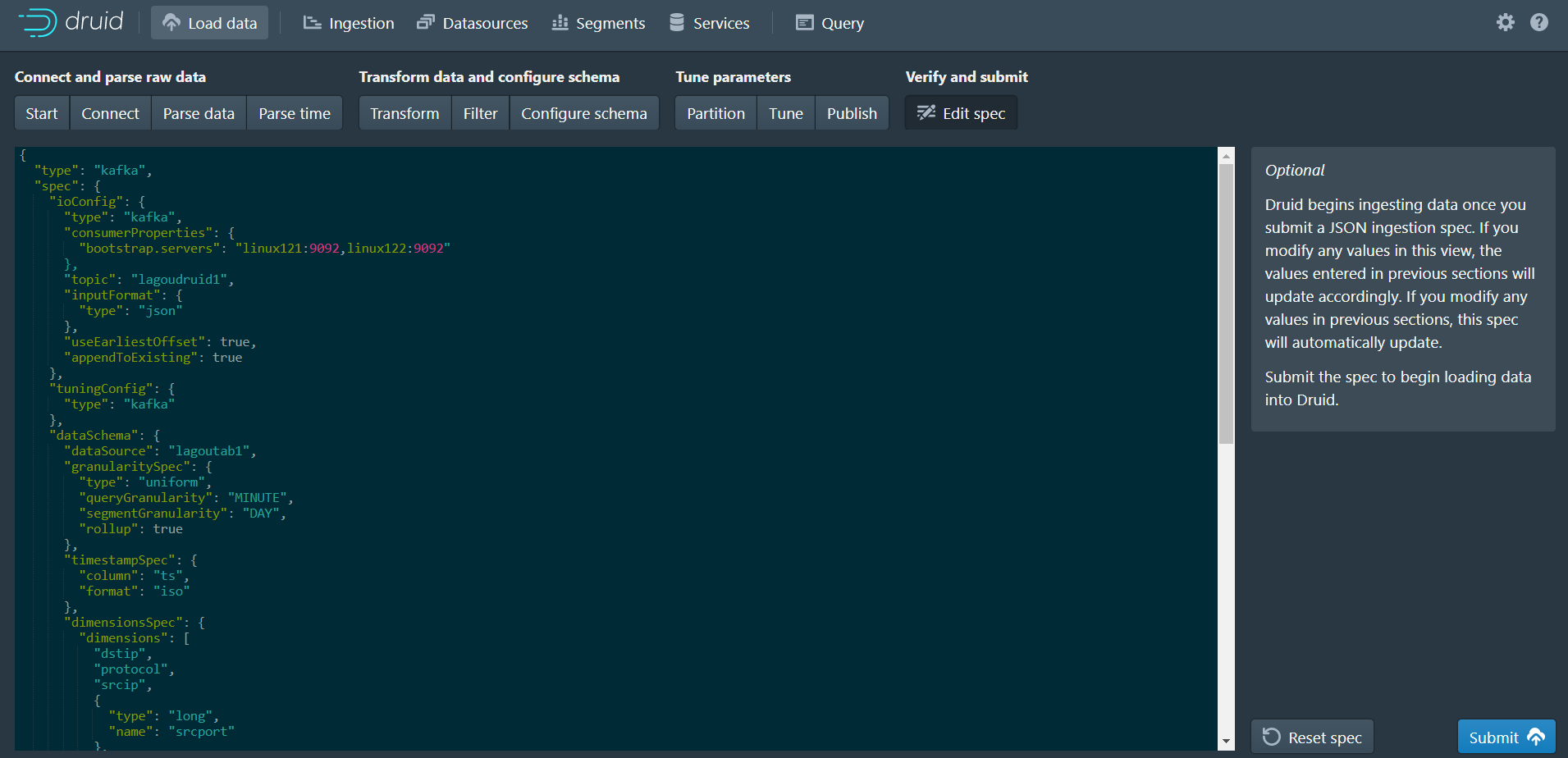
1.4 数据查询
- 数据摄取规范发布后创建 Supervisor
- Supervisor 会启动一个Task,从Kafka中摄取数据
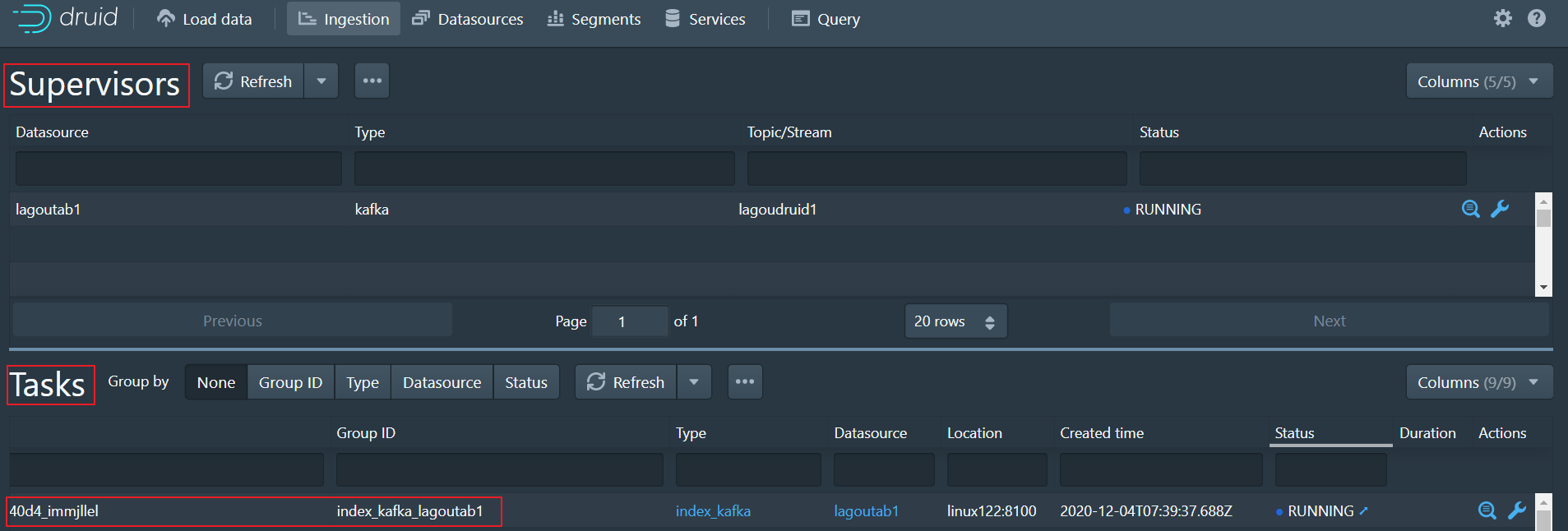
- 等待一小段时间,Datasource被创建,此时可以进行数据的查询
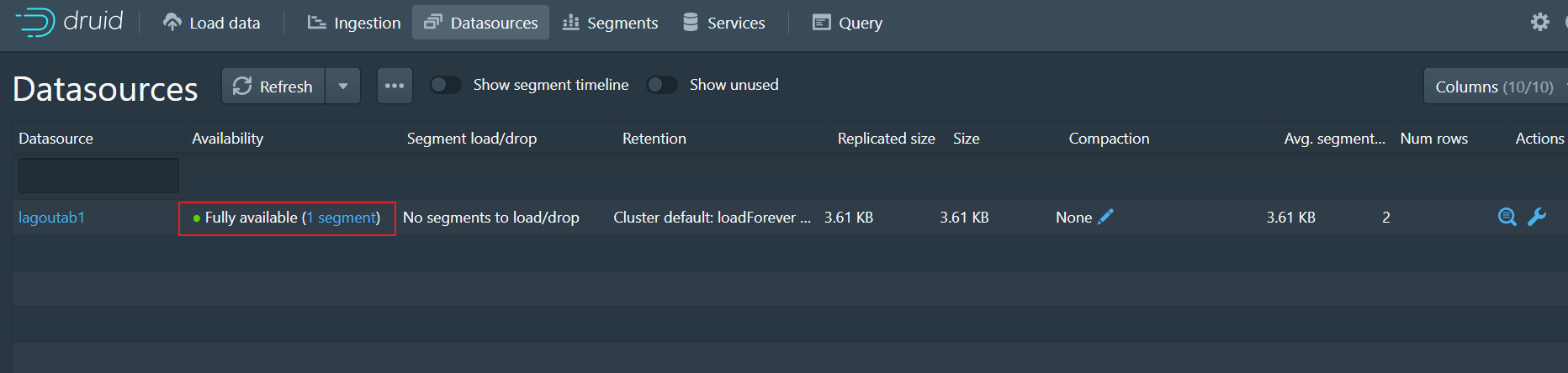
-- 查看全部的数据
select *
from "lagoutab1"
-- 其他查询
select dstPort, min(sum_packets), max(min_bytes), sum("count"), min("count")
from "lagoutab1"
group by dstPort
-- count字段加引号,表示是一个列名(本质是进行转义,否则认为count是一个函数,将报错)
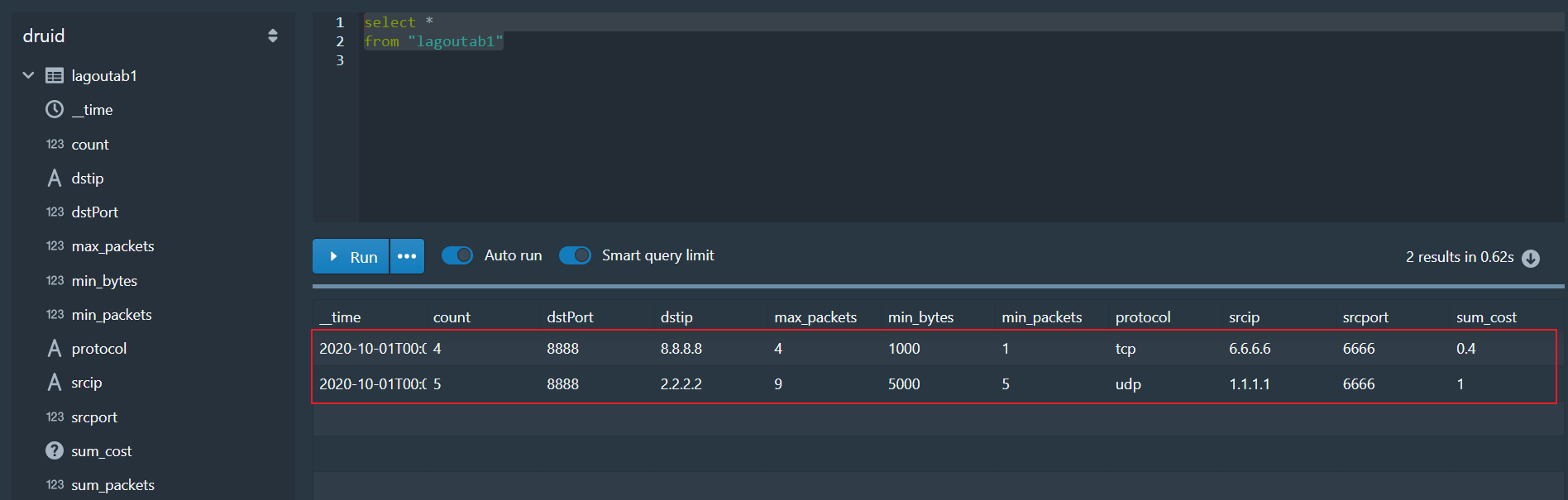
备注:维度相同的数据进行了Rollup
1.5 数据摄取规范
{
"type":"kafka",
"spec":{
"ioConfig":Object{...},
"tuningConfig":Object{...},
"dataSchema":Object{...}
}
}
- dataSchema。指定传入数据的Schema
- ioConfig。指定数据的来源和去向
- tuningConfig。指定各种摄取参数
dataSchema的定义:
Druid摄入数据规范的核心是dataSchema,dataSchema定义了如何解析输入的数据,并将数据存储到Druid中。
"dataSchema":{
"dataSource":"lagoutab1",
"granularitySpec":{
"type":"uniform",
"queryGranularity":"MINUTE",
"segmentGranularity":"DAY",
"rollup":true
},
"timestampSpec":{
"column":"ts",
"format":"iso"
},
"dimensionsSpec":Object{...},
"metricsSpec":Array[6]
}
- dataSource。摄取数据后生成 dataSource 的名称(dataSource是在查询中使用的表)
- granularitySpec。如何创建段和汇总数据
- timestampSpec。设置时间戳的列和格式
- dimensionsSpec。指定数据的维度列
- metricsSpec。指定数据的指标列,以及Rollup时指标列如何计算
- transformSpec。指定数据的转换规则和过滤规则,这里没有定义
备注:如果没有定义Rollup,在摄取数据时维度和度量之间没有区别
ioConfig的定义:
输入数据的数据源在ioConfig中指定,每个任务类型都有自己的ioConfig,这里从 kafka 获取数据,配置如下:
"ioConfig":{
"type":"kafka",
"consumerProperties":{
"bootstrap.servers":"linux121:9092,linux122:9092"
},
"topic":"lagoudruid1",
"inputFormat":{
"type":"json"
},
"useEarliestOffset":true,
"appendToExisting":true
}
tuningConfig的定义
tuningConfig规范根据摄取任务类型而有所不同。
"tuningConfig":{
"type":"kafka"
}
从HDFS中加载数据
hdfs dfs -cat /data/druidlog.dat
-- druidlog.dat
{"ts":"2020-10-01T00:01:35Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666, "dstPort":8888, "protocol": "tcp", "packets":1, "bytes":1000, "cost": 0.1}
{"ts":"2020-10-01T00:01:36Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666, "dstPort":8888, "protocol": "tcp", "packets":2, "bytes":2000, "cost": 0.1}
{"ts":"2020-10-01T00:01:37Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666, "dstPort":8888, "protocol": "tcp", "packets":3, "bytes":3000, "cost": 0.1}
{"ts":"2020-10-01T00:01:38Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666, "dstPort":8888, "protocol": "tcp", "packets":4, "bytes":4000, "cost": 0.1}
{"ts":"2020-10-01T00:02:08Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":5, "bytes":5000, "cost": 0.2}
{"ts":"2020-10-01T00:02:09Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":6, "bytes":6000, "cost": 0.2}
{"ts":"2020-10-01T00:02:10Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":7, "bytes":7000, "cost": 0.2}
{"ts":"2020-10-01T00:02:11Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":8, "bytes":8000, "cost": 0.2}
{"ts":"2020-10-01T00:02:12Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666, "dstPort":8888, "protocol": "udp", "packets":9, "bytes":9000, "cost": 0.2}
定义数据摄取规范
- HDFS文件,数据格式 json,时间戳 ts
- 不定义Rollup;保留所有的明细数据
- Segment granularity:Day
- DataSource Name:lagoutab2
数据查询
select * from "lagoutab2"
select protocol, count(*) rowcoun, sum(bytes) as bytes, sum(packets) as packets, max(cost) as maxcost
from "lagoutab2"
group by protocol
Part 4 Druid 架构与原理
基础架构
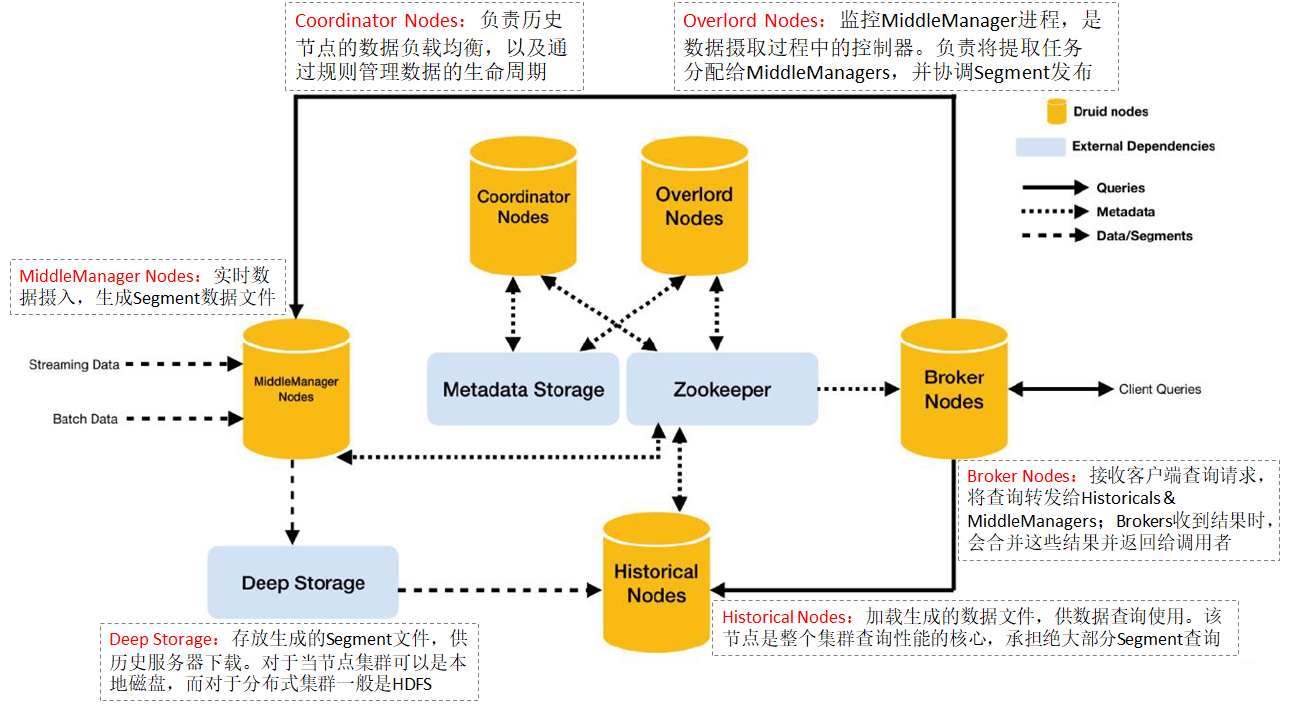
Druid 总体包含以下 6 类节点:
1、Coordinator node:主要负责历史节点的数据负载均衡,以及通过规则管理数据的生命周期。协调节点告诉历史节点加载新数据、卸载过期数据、复制数据、 和为了负载均衡移动数据。
Coordinator 是周期性运行的(由 druid.coordinator.period 配置指定,默认执行间隔为 60s);
Coordinator 需要维护和 ZooKeeper 的连接,以获取集群的信息。Segment 和 Rule 的信息保存在元数据库中,
所以也需要维护与元数据库的连接。
2、Overlord node:进程监视 MiddleManager 进程,并且是Druid 数据摄入的主节点。负责将提取任务分配给 MiddleManagers 并协调 Segement 发布,包括接受、拆解、分配 Task,以及创建 Task 相关的锁,并返回 Task 的状态。
3、Historical node:加载生成好的数据文件,以供数据查询。Historical node是整个集群查询性能的核心所在,Historical 会承担绝大部分的 segment 查询。
Historical 进程从 Deep Storage 中下载 Segment,并响应有关这些 Segment 的查询请求(这些请求来自Broker 进程);
Historical 进程不处理写入请求;
Historical 进程采用了无共享架构设计,它知道如何去加载和删除 Segment,以及如何基于 Segment 来响应查询。
即便底层的深度存储无法正常工作,Historical 进程还是能针对其已同步的 Segments,正常提供查询服务。
4、MiddleManager node:及时摄入实时数据,生成 Segment 数据文件。
MiddleManager 进程是执行提交任务的工作节点。MiddleManagers 将任务转发给在不同 JVM 中运行的 Peon 进程。
MiddleManager、Peon、Task 的对应关系是,每个 Peon 进程一次只能运行一个Task 任务,但一个
MiddleManager 却可以管理多个 Peon 进程。
5、Broker node:接收客户端查询请求,并将这些查询转发给 Historicals 和 MiddleManagers。当 Brokers 从这些子查询中收到结果时,它们会合并这些结果并将它们返回给调用者。
Broker节点负责转发Client查询请求的;
Broker通过zookeeper能够知道哪个Segment在哪些节点上,将查询转发给相应节点;
所有节点返回数据后,Broker会将所有节点的数据进行合并,然后返回给Client;
6、Router node(可选的): 负责将请求路由到Broker、Coordinators、Overlords。
Router 进程可以在 Brokers、Overlords 和 Coordinators 进程之上,提供一层统一的 API网关。
Router 进程是可选的,如果集群数据规模已经达到了 TB级别,需要考虑启用(druid.router.managementProxy.enabled=true)。
一旦集群规模达到一定的数量级,那么发生故障的概率就会变得不容忽视,而 Router 支持将请求只发送给健康的节点,
避免请求失败。同时,查询的响应时间和资源消耗,也会随着数据量的增长而变高,而 Router 支持设置查询的优先级和负载均衡策略,避免了大查询造成的队列堆积或查询热点等问题。
Druid 的进程可以被任意部署,为了理解与部署组织方便。这些进程分为了三类:
- Master: Coordinator、Overlord 负责数据可用性和摄取
- Query: Broker and Router,负责处理外部请求
- Data: Historical and MiddleManager,负责实际的Ingestion负载和数据存储
Druid 还包含 3 类外部依赖:
- Deep Storage:存放生成的 Segment 数据文件,并供历史服务器下载, 对于单节点集群可以是本地磁盘,而对于分布式集群一般是 HDFS
Druid使用deep storage来做数据的备份,也作为在Druid进程之间在后台传输数据的一种方式。
当响应查询时,Historical首先从本地磁盘读取预取的段,这也意味着需要在deep storage和加载的数据的Historical中拥有足够的磁盘空间。
- Metadata Storage,存储 Druid 集群的元数据信息,如 Segment 的相关信息,一般使用 MySQL
| 表名 | 作用 |
|---|---|
| druid_dataSource | 存储DataSources,以便 Kafka Index Service查找 |
| druid_pendingSegments | 存储 pending 的 Segments |
| druid_segments | 存储每个 Segments 的metadata 信息 |
| druid_rules | 关于 Segment 的 load / drop 规则 |
| druid_config | 存放运行时的配置信息 |
| druid_tasks | 为Indexing Service 保存 Task 信息 |
| druid_tasklogs | 为Indexing Service 保存 Task 日志 |
| druid_tasklocks | 为Indexing Service 保存 Task 锁 |
| druid_supervisors | 为Indexing Service保存 SuperVisor 信息 |
| druid_audit | 记录配置、Coordinator规则的变化 |
- Zookeeper:为 Druid 集群提供以执行协调服务。如内部服务的监控,协调和领导者选举
Coordinator 节点的 Leader 选举
Historical 节点发布 Segment 的协议
Coordinator 和 Historical 之间 load / drop Segment 的协议
Overlord 节点的 Leader 选举
Overlord 和 MiddleManager 之间的 Task 管理
架构演进
Apache Druid 初始版本架构图 ~ 0.6.0(2012~2013)
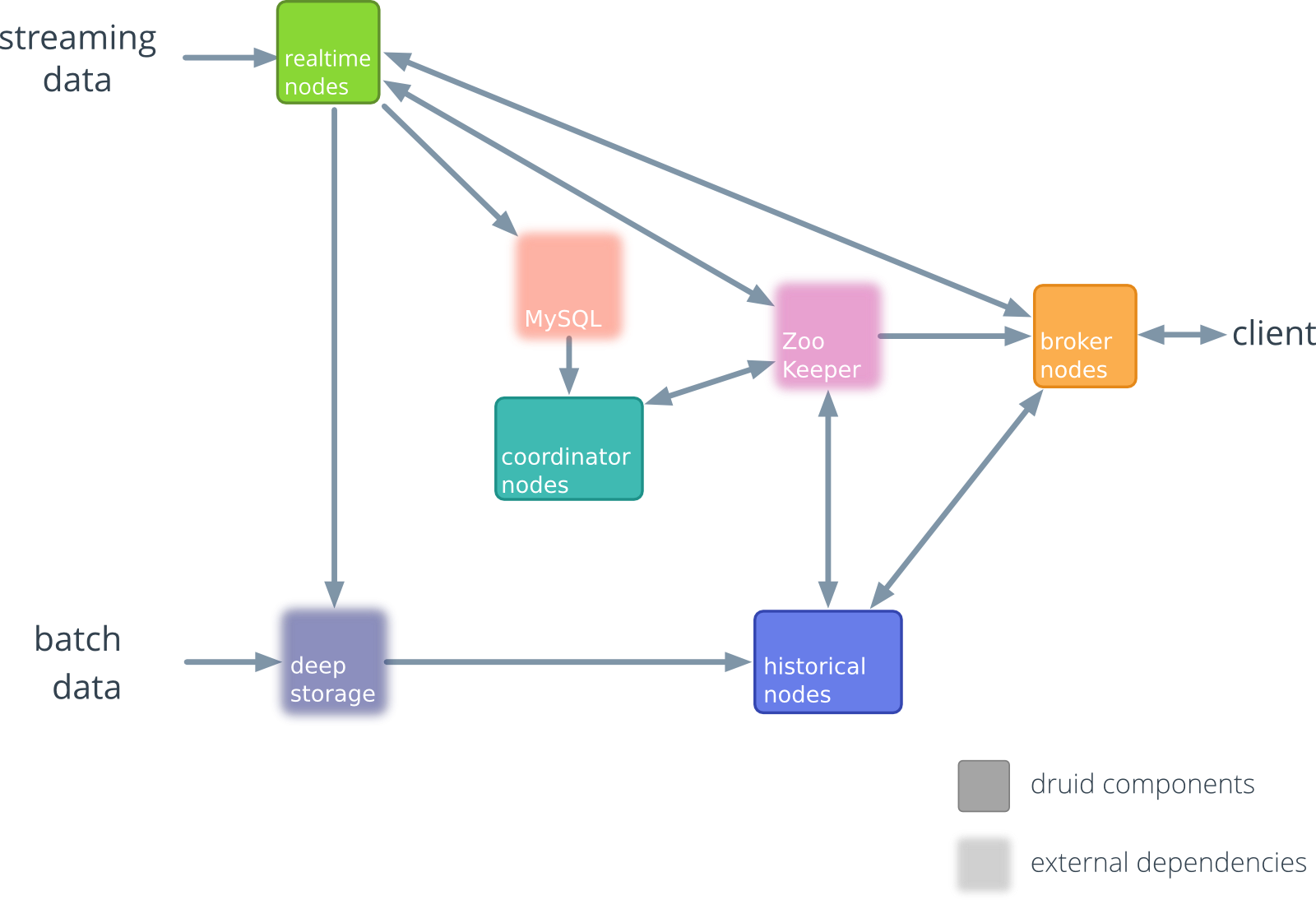
0.7.0 ~ 0.12.0(2013~2018)
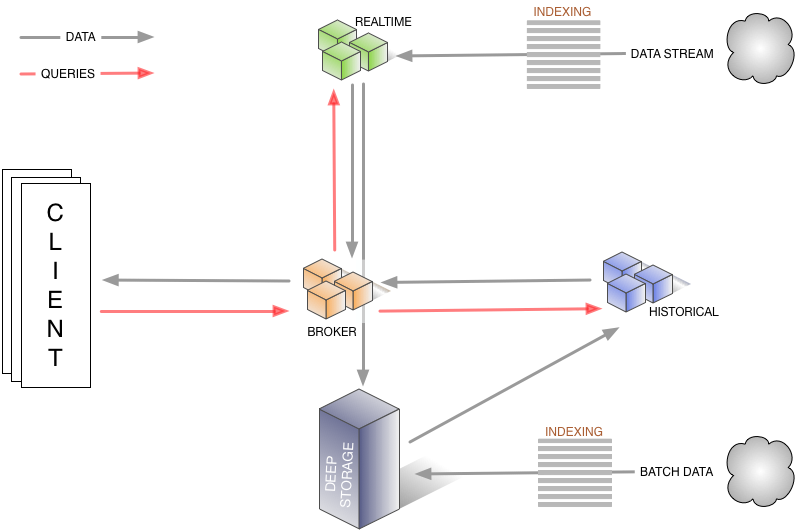
Apache Druid 旧架构图——数据流转
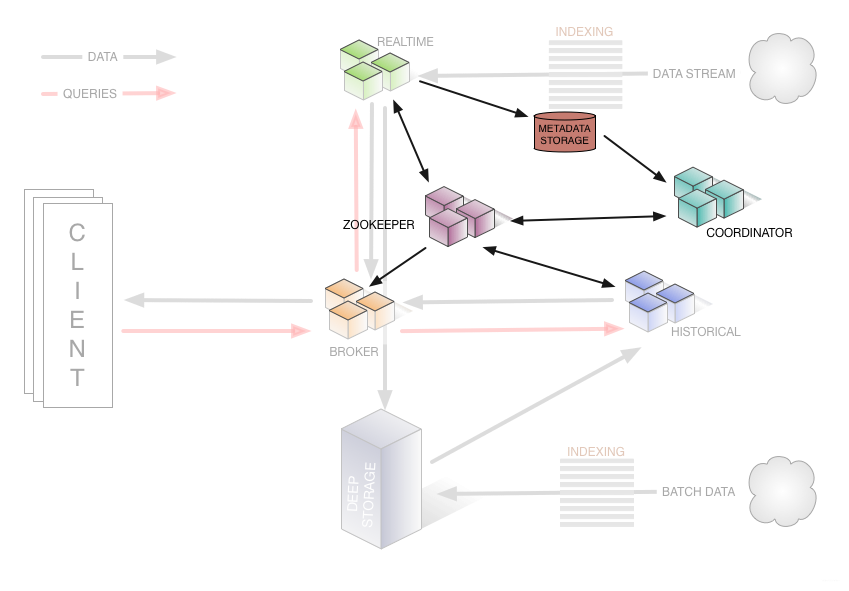
Apache Druid 旧架构图——集群管理
0.13.0 ~ 当前版本(2018~now)
Lambda 架构
从大的架构上看,Druid是一个Lambda架构。
Lambda架构是由 Storm 的作者 Nathan Marz 提出的一个实时大数据处理框架。Lambda 架构设计是为了在处理大规模数据时,同时发挥流处理和批处理的优势:
- 通过批处理提供全面、准确的数据
- 通过流处理提供低延迟的数据
从而达到平衡延迟、吞吐量和容错性的目的,为了满足下游的即席查询,批处理和流处理的结果会进行合并。
Lambda 架构包含三层,Batch Layer、Speed Layer 和 Serving Layer:
-
Batch Layer:批处理层。对离线的历史数据进行预计算,为了下游能够快速查询想要的结果。由于批处理基于完整的历史数据集,准确性可以得到保证。批处理层可以用 Hadoop、Spark 和 Flink 等框架计算
-
Speed Layer:加速处理层。处理实时的增量数据,这一层重点在于低延迟。加速层的数据不如批处理层那样完整和准确,但是可以填补批处理高延迟导致的数据空白。加速层可以用 Storm、Spark streaming 和 Flink 等框架计算
-
Serving Layer:合并层。将历史数据、实时数据合并在一起,输出到数据库或者其他介质,供下游分析
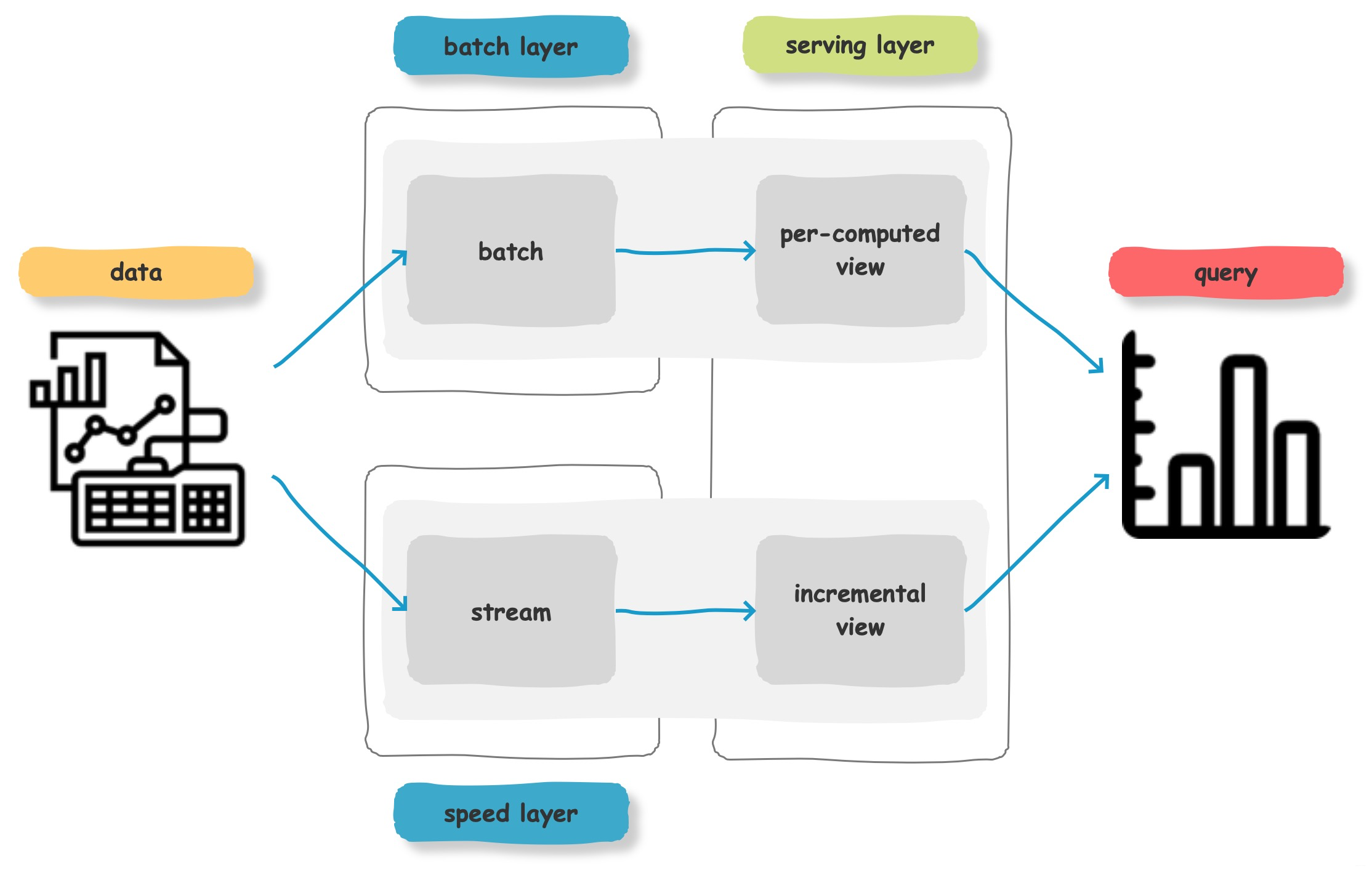
流式数据的链路为:
Row data → Kafka → Streaming processor (Optional, 实时ETL) → Kafka(Optional) → Druid → Application / User
批处理数据的链路为:
Raw data → Kafka(Optional) → HDFS → ETL process(Optional) → Druid → Application / User
数据存储
- Druid中的数据存储在被称为DataSource中,DataSource类似RDBMS中的 Table
- 每个DataSource按照时间划分,每个时间范围称为一个Chunk(比如按天分区,则一个chunk为一天)
- 在Chunk中数据被分为一个或多个Segment
- Segment是数据实际存储结构,Datasource、Chunk只是一个逻辑概念
- Segment是按照时间组织成的Chunk,所以在按照时间查询数据时,效率非常高
- 每个Segment都是一个单独的文件,通常包含几百万行数据
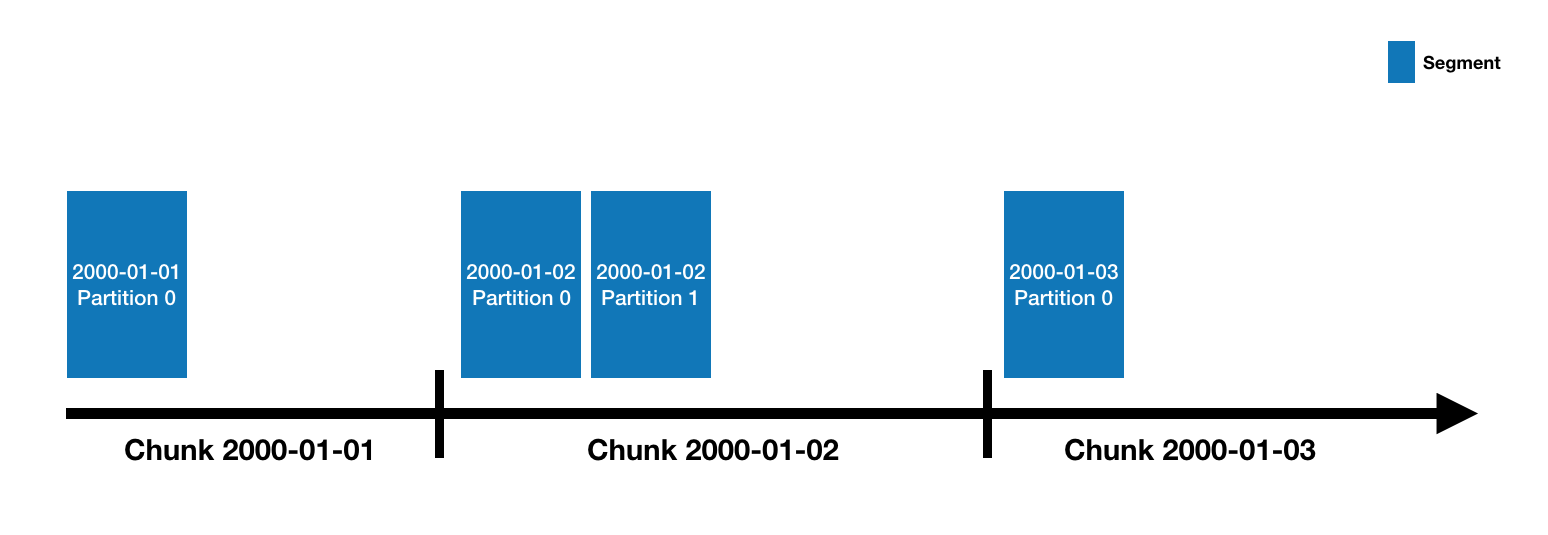
数据分区:
- Druid处理的是事件数据,每条数据都会带有一个时间戳,可以使用时间进行分区
- 上图指定了分区粒度为为天,那么每天的数据都会被单独存储和查询
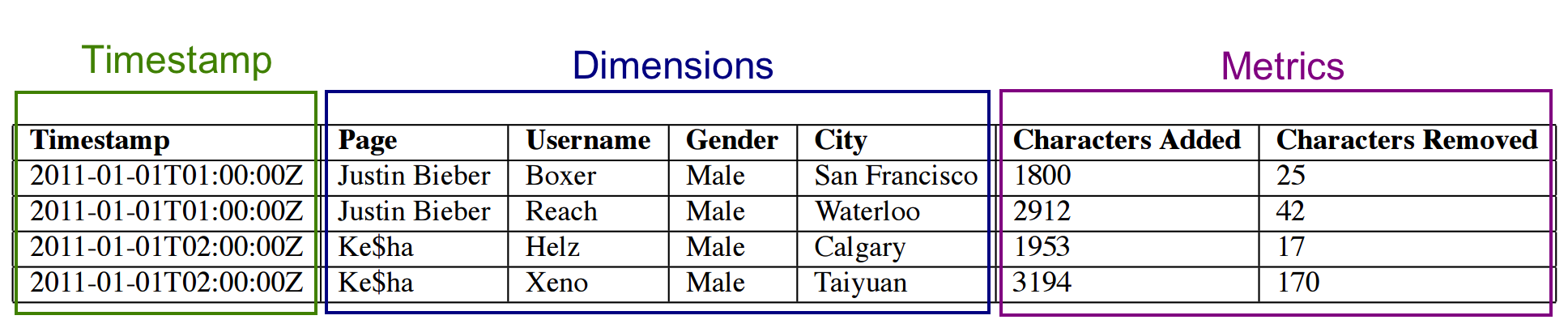
Segment内部存储结构
- Druid采用列式存储,每列数据都是在独立的结构中存储
- Segment中的数据类型主要分为三种
- 时间戳。每一行数据,都必须有一个timestamp,Druid一定会基于时间戳来分片
- 维度列。用来过滤filter或者组合groupby的列,通常是string、float、double、int类型
- 指标列。用来进行聚合计算的列,指定的聚合函数 sum、average 等
MiddleManager节点接受到 ingestion 的任务之后,开始创建Segment:
-
转换成列存储格式
-
用bitmap来建立索引(对所有的dimension列建立索引)
-
使用各种压缩算法:
- 所有的列使用LZ4压缩
- 所有的字符串列采用字典编码/标识以达到最小化存储
- 对位图索引使用位图压缩
Segment创建完成之后,Segment文件就是不可更改的,被写入到深度存储(目的是为了防止MiddleManager节点宕机后,Segment的丢失)。 然后Segment会加载到Historical节点,Historical节点可以直接加载到内存中。
同时,metadata store 也会记录下这个新创建的Segment的信息,如结构,尺寸,深度存储的位置等等。Coordinator节点需要这些元数据来协调数据的查找。
索引服务
-
索引服务:数据导入并创建 segments 数据文件的服务
-
索引服务是一个高可用的分布式服务,采用主从结构作为架构模式,索引服务由三大组件构成
- overlord 作为主节点
- middlemanager是从节点
- peon用于运行一个task
索引服务架构图如下图所示:
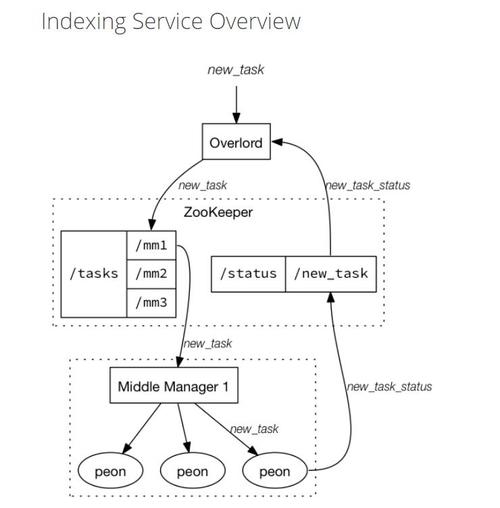
索引服务由三部分组件组成:
-
Overlord组件
- 负责创建task、分发task到middlemanager上运行,为task创建锁以及跟踪task运行状态并反馈给用户
-
MiddleManager组件
- 作为从节点,负责接收主节点分配的任务,然后为每个task启动一个独立的JVM进程来完成具体的任务
-
Peon(劳工)组件
- 由middlemanager启动的一个进程用于运行一个task任务
索引服务架构与 Yarn 的架构类似:
- Overlaod => ResourceManager,负责集群资源管理和任务分配
- MiddleManager => NodeManager,负责接受任务和管理本节点的资源
- Peon => Container,执行节点上具体的任务
Task类型有很多,包括:
-
index hadoop task:Hadoop索引任务,利用Hadoop集群执行MapReduce任务以完成segment数据文件的创建,适合体量比较大的segments数据文件的创建任务
-
index kafka task:用于Kafka数据的实时摄入,通过Kafka索引服务可以在Overlord上配置一个KafkaSupervisor,通过管理Kafka索引任务的创建和生命周期来完成 Kafka 数据的摄取
-
merge task:合并索引任务,将多个segments数据文件按照指定的聚合方法合并为一个segments数据文件
-
kill task : 销毁索引任务,将执行时间范围内的数据从Druid集群的深度存储中删除
索引及压缩机制
Druid的查询时延低性能好的主要是因为采用了五个技术点:
- 数据预聚合
- 列式存储、数据压缩
- Bitmap 索引
- mmap(内存文件映射方式)
- 查询结果的中间缓存
1、数据预聚合
- Druid通过一个roll-up的处理,将原始数据在注入的时候就进行汇总处理
- Roll-up可以压缩我们需要保存的数据量
- Druid会把选定的相同维度的数据进行聚合操作,可减少存储的大小
- Druid可以通过 queryGranularity 来控制注入数据的粒度。 最小的queryGranularity 是 millisecond(毫秒级)
Roll-up聚合前:
| time | AppKey | area | value |
|---|---|---|---|
| 2020-10-05 10:00:00 | areakey1 | Beijing | 1 |
| 2020-10-05 10:30:00 | areakey1 | Beijing | 1 |
| 2020-10-05 11:00:00 | areakey1 | Beijing | 1 |
| 2020-10-05 11:00:00 | areakey2 | Shanghai | 2 |
Roll-up聚合后:
| time | AppKey | area | value |
|---|---|---|---|
| 2020-10-05 | areakey1 | Beijing | 3 |
| 2020-10-05 | areakey2 | Shanghai | 2 |
2、位图索引
Druid在摄入的数据示例:
| Time | AppKey | Area | Value |
|---|---|---|---|
| 2020-10-01 10:00:00 | appkey1 | 深圳 | 1 |
| 2020-10-01 11:00:00 | appkey2 | 北京 | 1 |
| 2020-10-01 12:00:00 | appkey2 | 深圳 | 1 |
| 2020-10-01 13:00:00 | appkey2 | 北京 | 1 |
| … … | … … | … … | … … |
| 2020-10-01 23:00:00 | appkey3 | 北京 | 1 |
- 第一列为时间,Appkey和Area都是维度列,Value为指标列
- Druid会在导入阶段自动对数据进行Rollup,将维度相同组合的数据进行聚合处理
- 数据聚合的粒度根据业务需要确定
按天聚合后的数据如下:
| Time | AppKey | Area | Value |
|---|---|---|---|
| 2020-10-01 | appkey1 | 北京 | 10 |
| 2020-10-01 | appkey1 | 深圳 | 20 |
| 2020-10-01 | appkey2 | 北京 | 30 |
| 2020-10-01 | appkey2 | 深圳 | 40 |
| 2020-10-01 | appkey3 | 北京 | 50 |
| 2020-10-01 | appkey3 | 深圳 | 60 |
Druid通过建立位图索引,实现快速数据查找。
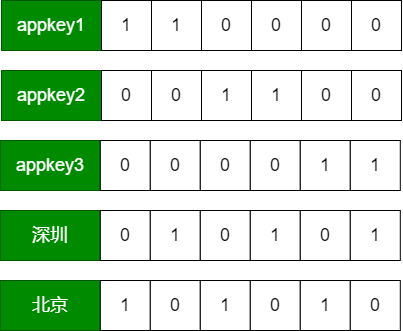
Bitmap 索引主要为了加速查询时有条件过滤的场景。Druid 在生成索引文件的时候,对每个列的每个取值生成对应的 Bitmap 集合。如下图所示:
| Key | ||||||
|---|---|---|---|---|---|---|
| appkey1 | 1 | 1 | 0 | 0 | 0 | 0 |
| appkey2 | 0 | 0 | 1 | 1 | 0 | 0 |
| appkey3 | 0 | 0 | 0 | 0 | 1 | 1 |
| 深圳 | 0 | 1 | 0 | 1 | 0 | 1 |
| 北京 | 1 | 0 | 1 | 0 | 1 | 0 |
- 索引位图可以看作是HashMap<String, Bitmap>
- key就是维度的取值
- value就是该表中对应的行是否有该维度的值
以SQL查询为例:
1)boolean条件查询
select sum(value)
from tab1
where time='2020-10-01'
and appkey in ('appkey1', 'appkey2')
and area='北京'
执行过程分析:
- 根据时间段定位到segment
- Appkey in (‘appkey1’, ‘appkey2’) and area=’北京’ 查到各自的bitmap
- (appkey1 or appkey2) and 北京
- (110000 or 001100) and 101010 = 111100 and 101010 = 101000
- 符合条件的列为:第1行 & 第3行,这几行 sum(value) 的和为 40
2)group by 查询
select area, sum(value)
from tab1
where time='2020-10-01'
and appkey in ('appkey1', 'appkey2')
group by area
该查询与上面的查询不同之处在于将符合条件的列
- appkey1 or appkey2
- 110000 or 001100 = 111100
- 将第1行 到 第4行取出来
- 在内存中做分组聚合。结果为:北京:40、深圳:60
Part 5 Druid实战案例
需求分析
1.1 场景分析
- 数据量大,需要在这些数据中根据业务需要灵活做查询
- 实时性要求高
- 数据实时的推过来,要在秒级对数据进行分析并查询出结果
1.2 数据描述
{"ts":1607499629841,"orderId":"1009388","userId":"807134","orderStatusId":1,"orderStatus":"已支付","payModeId":0,"payMode":"微信","payment":"933.90","products":[{"productId":"102163","productName":"贝合xxx+粉","price":18.7,"productNum":3,"categoryid":"10360","catname1":"厨卫清洁、纸制用品","catname2":"生活日用","catname3":"浴室用品"},{"productId":"100349","productName":"COxxx0C","price":877.8,"productNum":1,"categoryid":"10302","catname1":"母婴、玩具乐器","catname2":"西洋弦乐器","catname3":"吉他"}]}
ts:交易时间
orderId:订单编号
userId:用户id
orderStatusId:订单状态id
orderStatus:订单状态
0-11:未支付,已支付,发货中,已发货,发货失败,已退款,已关单,订单过期,订单已失效,产品已失效,代付拒绝,支付中
payModeId:支付方式id
payMode:支付方式
0-6:微信,支付宝,信用卡,银联,货到付款,现金,其他
payment:支付金额
products:购买商品
备注:一个订单可能包含多个商品,这里是一个嵌套结构
productId:商品id
productName:商品名称
price:单价
productNum:购买数量
categoryid:商品分类id
catname1:商品一级分类名称
catname2:商品二级分类名称
catname3:商品三级分类名称
以上的嵌套的json数据格式,Druid不好处理,需要对数据进行预处理,将数据拉平,处理后的数据格式:
{"ts":1607499629841,"orderId":"1009388","userId":"807134","orderStatusId":1,"orderStatus":"已支付","payModeId":0,"payMode":"微信","payment":"933.90","product":{"productId":"102163","productName":"贝合xxx+粉","price":18.7,"productNum":3,"categoryid":"10360","catname1":"厨卫清洁、纸制用品","catname2":"生活日用","catname3":"浴室用品"}}
{"ts":1607499629841,"orderId":"1009388","userId":"807134","orderStatusId":1,"orderStatus":"已支付","payModeId":0,"payMode":"微信","payment":"933.90","product":{"productId":"100349","productName":"COxxx0C","price":877.8,"productNum":1,"categoryid":"10302","catname1":"母婴、玩具乐器","catname2":"西洋弦乐器","catname3":"吉他"}}
项目实战
2.1 kafka生产者
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import scala.io.BufferedSource
object KafkaProducerForDruid {
def main(args: Array[String]): Unit = {
// 定义 kafka 参数
val brokers = "linux121:9092,linux122:9092,linux123:9092"
val topic = "lagoudruid2"
val prop = new Properties()
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
// KafkaProducer
val producer = new KafkaProducer[String, String](prop)
val source: BufferedSource = scala.io.Source.fromFile("data/lagou_orders1.json")
val iter: Iterator[String] = source.getLines()
iter.foreach{line =>
val msg = new ProducerRecord[String, String](topic, line)
producer.send(msg)
Thread.sleep(10)
}
producer.close()
source.close()
}
}
2.2 启动服务
启动 ZooKeeper、Kafka、Druid、HDFS服务
-- 创建topic
kafka-topics.sh --create --zookeeper linux121:2181,linux122:2181/kafka1.0 --replication-factor 1 --partitions 3 --topic lagoudruid2
2.3 定义数据摄取规范
备注:
- json数据要拉平
- 不用定义Rollup
数据摄取规范:
{
"type": "kafka",
"spec": {
"dataSchema": {
"dataSource": "lagoudruid2",
"timestampSpec": {
"column": "ts",
"format": "millis",
"missingValue": null
},
"dimensionsSpec": {
"dimensions": [],
"dimensionExclusions": [
"ts"
]
},
"metricsSpec": [],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": {
"type": "none"
},
"rollup": false,
"intervals": null
},
"transformSpec": {
"filter": null,
"transforms": []
}
},
"ioConfig": {
"topic": "lagoudruid2",
"inputFormat": {
"type": "json",
"flattenSpec": {
"useFieldDiscovery": true,
"fields": [
{
"type": "path",
"name": "productId",
"expr": "$.product.productId"
},
{
"type": "path",
"name": "productName",
"expr": "$.product.productName"
},
{
"type": "path",
"name": "price",
"expr": "$.product.price"
},
{
"type": "path",
"name": "productNum",
"expr": "$.product.productNum"
},
{
"type": "path",
"name": "categoryid",
"expr": "$.product.categoryid"
},
{
"type": "path",
"name": "catname1",
"expr": "$.product.catname1"
},
{
"type": "path",
"name": "catname2",
"expr": "$.product.catname2"
},
{
"type": "path",
"name": "catname3",
"expr": "$.product.catname3"
}
]
},
"featureSpec": {}
},
"replicas": 1,
"taskCount": 1,
"taskDuration": "PT3600S",
"consumerProperties": {
"bootstrap.servers": "linux121:9092,linux122:9092,linux123:9092"
},
"pollTimeout": 100,
"startDelay": "PT5S",
"period": "PT30S",
"useEarliestOffset": true,
"completionTimeout": "PT1800S",
"lateMessageRejectionPeriod": null,
"earlyMessageRejectionPeriod": null,
"lateMessageRejectionStartDateTime": null,
"stream": "lagoudruid2",
"useEarliestSequenceNumber": true
},
"tuningConfig": {
"type": "kafka",
"maxRowsInMemory": 1000000,
"maxBytesInMemory": 0,
"maxRowsPerSegment": 5000000,
"maxTotalRows": null,
"intermediatePersistPeriod": "PT10M",
"basePersistDirectory": "/opt/lagou/servers/druid-0.19.0/var/tmp/druid-realtime-persist6578707047959911548",
"maxPendingPersists": 0,
"indexSpec": {
"bitmap": {
"type": "roaring",
"compressRunOnSerialization": true
},
"dimensionCompression": "lz4",
"metricCompression": "lz4",
"longEncoding": "longs",
"segmentLoader": null
},
"indexSpecForIntermediatePersists": {
"bitmap": {
"type": "roaring",
"compressRunOnSerialization": true
},
"dimensionCompression": "lz4",
"metricCompression": "lz4",
"longEncoding": "longs",
"segmentLoader": null
},
"buildV9Directly": true,
"reportParseExceptions": false,
"handoffConditionTimeout": 0,
"resetOffsetAutomatically": false,
"segmentWriteOutMediumFactory": null,
"workerThreads": null,
"chatThreads": null,
"chatRetries": 8,
"httpTimeout": "PT10S",
"shutdownTimeout": "PT80S",
"offsetFetchPeriod": "PT30S",
"intermediateHandoffPeriod": "P2147483647D",
"logParseExceptions": false,
"maxParseExceptions": 2147483647,
"maxSavedParseExceptions": 0,
"skipSequenceNumberAvailabilityCheck": false,
"repartitionTransitionDuration": "PT120S"
}
},
"dataSchema": {
"dataSource": "lagoudruid2",
"timestampSpec": {
"column": "ts",
"format": "millis",
"missingValue": null
},
"dimensionsSpec": {
"dimensions": [],
"dimensionExclusions": [
"ts"
]
},
"metricsSpec": [],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": {
"type": "none"
},
"rollup": false,
"intervals": null
},
"transformSpec": {
"filter": null,
"transforms": []
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsInMemory": 1000000,
"maxBytesInMemory": 0,
"maxRowsPerSegment": 5000000,
"maxTotalRows": null,
"intermediatePersistPeriod": "PT10M",
"basePersistDirectory": "/opt/lagou/servers/druid-0.19.0/var/tmp/druid-realtime-persist6578707047959911548",
"maxPendingPersists": 0,
"indexSpec": {
"bitmap": {
"type": "roaring",
"compressRunOnSerialization": true
},
"dimensionCompression": "lz4",
"metricCompression": "lz4",
"longEncoding": "longs",
"segmentLoader": null
},
"indexSpecForIntermediatePersists": {
"bitmap": {
"type": "roaring",
"compressRunOnSerialization": true
},
"dimensionCompression": "lz4",
"metricCompression": "lz4",
"longEncoding": "longs",
"segmentLoader": null
},
"buildV9Directly": true,
"reportParseExceptions": false,
"handoffConditionTimeout": 0,
"resetOffsetAutomatically": false,
"segmentWriteOutMediumFactory": null,
"workerThreads": null,
"chatThreads": null,
"chatRetries": 8,
"httpTimeout": "PT10S",
"shutdownTimeout": "PT80S",
"offsetFetchPeriod": "PT30S",
"intermediateHandoffPeriod": "P2147483647D",
"logParseExceptions": false,
"maxParseExceptions": 2147483647,
"maxSavedParseExceptions": 0,
"skipSequenceNumberAvailabilityCheck": false,
"repartitionTransitionDuration": "PT120S"
},
"ioConfig": {
"topic": "lagoudruid2",
"inputFormat": {
"type": "json",
"flattenSpec": {
"useFieldDiscovery": true,
"fields": [
{
"type": "path",
"name": "productId",
"expr": "$.product.productId"
},
{
"type": "path",
"name": "productName",
"expr": "$.product.productName"
},
{
"type": "path",
"name": "price",
"expr": "$.product.price"
},
{
"type": "path",
"name": "productNum",
"expr": "$.product.productNum"
},
{
"type": "path",
"name": "categoryid",
"expr": "$.product.categoryid"
},
{
"type": "path",
"name": "catname1",
"expr": "$.product.catname1"
},
{
"type": "path",
"name": "catname2",
"expr": "$.product.catname2"
},
{
"type": "path",
"name": "catname3",
"expr": "$.product.catname3"
}
]
},
"featureSpec": {}
},
"replicas": 1,
"taskCount": 1,
"taskDuration": "PT3600S",
"consumerProperties": {
"bootstrap.servers": "linux121:9092,linux122:9092,linux123:9092"
},
"pollTimeout": 100,
"startDelay": "PT5S",
"period": "PT30S",
"useEarliestOffset": true,
"completionTimeout": "PT1800S",
"lateMessageRejectionPeriod": null,
"earlyMessageRejectionPeriod": null,
"lateMessageRejectionStartDateTime": null,
"stream": "lagoudruid2",
"useEarliestSequenceNumber": true
},
"context": null,
"suspended": false
}
2.4 查询计算
-- 查记录总数
select count(*) as recordcount
from lagoudruid2
-- 查订单总数
select count(distinct orderId) as orderscount
from lagoudruid2
-- 查有多少用户数
select count(distinct userId) as usercount
from lagoudruid2
-- 统计各种订单状态的订单数
select orderStatus, count(*)
from (
select orderId, orderStatus
from lagoudruid2
group by orderId, orderStatus
)
group by orderStatus
-- 统计各种支付方式的订单数
select payMode, count(1)
from (
select orderId, payMode
from lagoudruid2
group by orderId, payMode
)
group by payMode
-- 订单金额最大的前10名
select orderId, payment, count(1) as productcount, sum(productNum) as products
from lagoudruid2
group by orderId, payment
order by payment desc limit 10
-- 计算每秒订单总金额
select timesec, round(sum(payment)/10000, 2)
from (
select date_trunc('second', __time) as timesec, orderId, payment
from lagoudruid2
group by date_trunc('second', __time), orderId, payment
)
group by timesec
SQL参考:https://druid.apache.org/docs/0.19.0/querying/sql.html#data-types
2.5 Druid案例小结
- 在配置摄入源时要设置为True从流的开始进行消费数据,否则在数据源中可能查不到数据
- Druid的join能力非常有限,分组或者聚合多的场景推荐使用
- sql支持能力也非常受限
- 数据的分区组织只有时间序列一种方式