ELK(Elasticsearch,Logstash,Kibana)
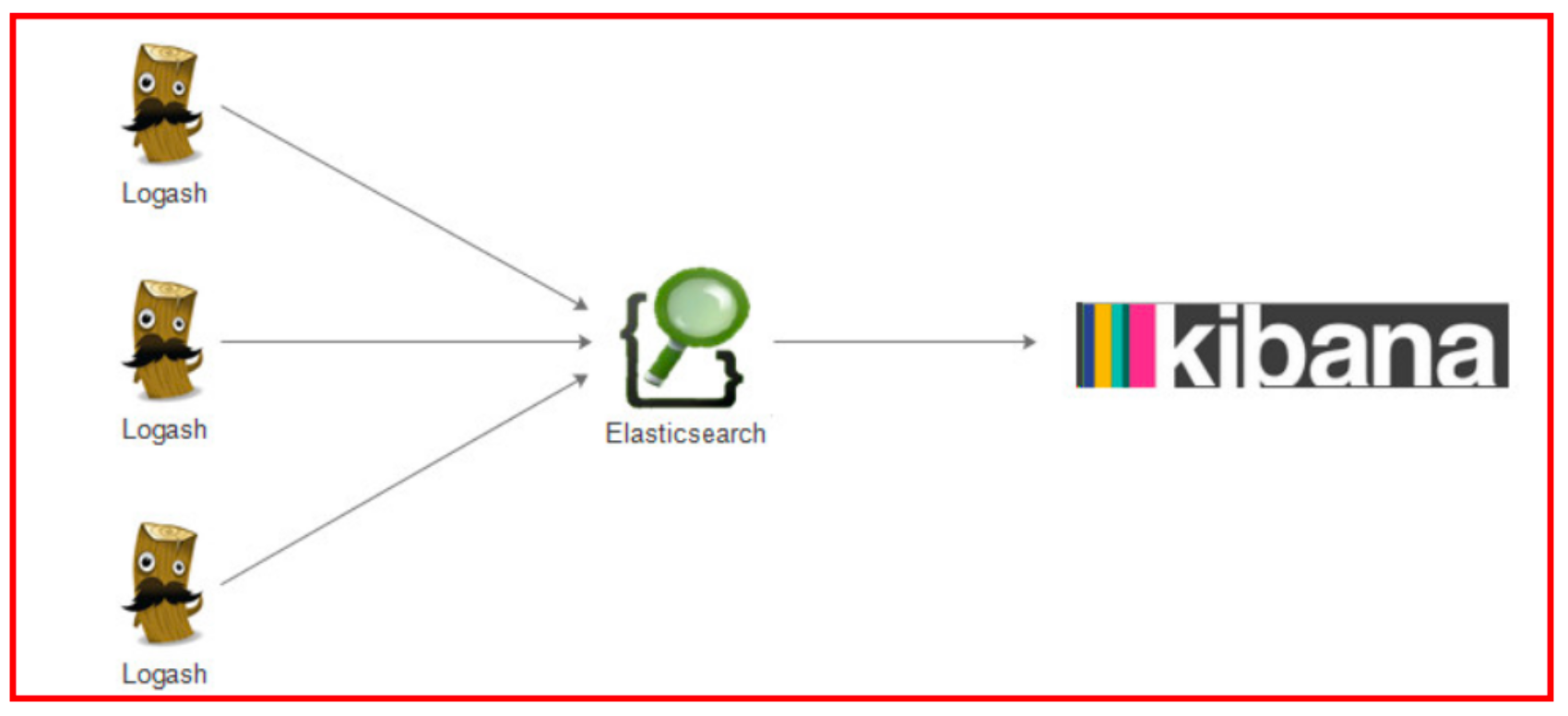
ELK 其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写,Elasticsearch(ES),Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为 ELK 协 议栈。
ELK官网:https://www.elastic.co/
ELK官网文档:https://www.elastic.co/guide/index.html
ELK中文手册:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
ELK中文社区:https://elasticsearch.cn/
ELK API :https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/travelansport-client.html
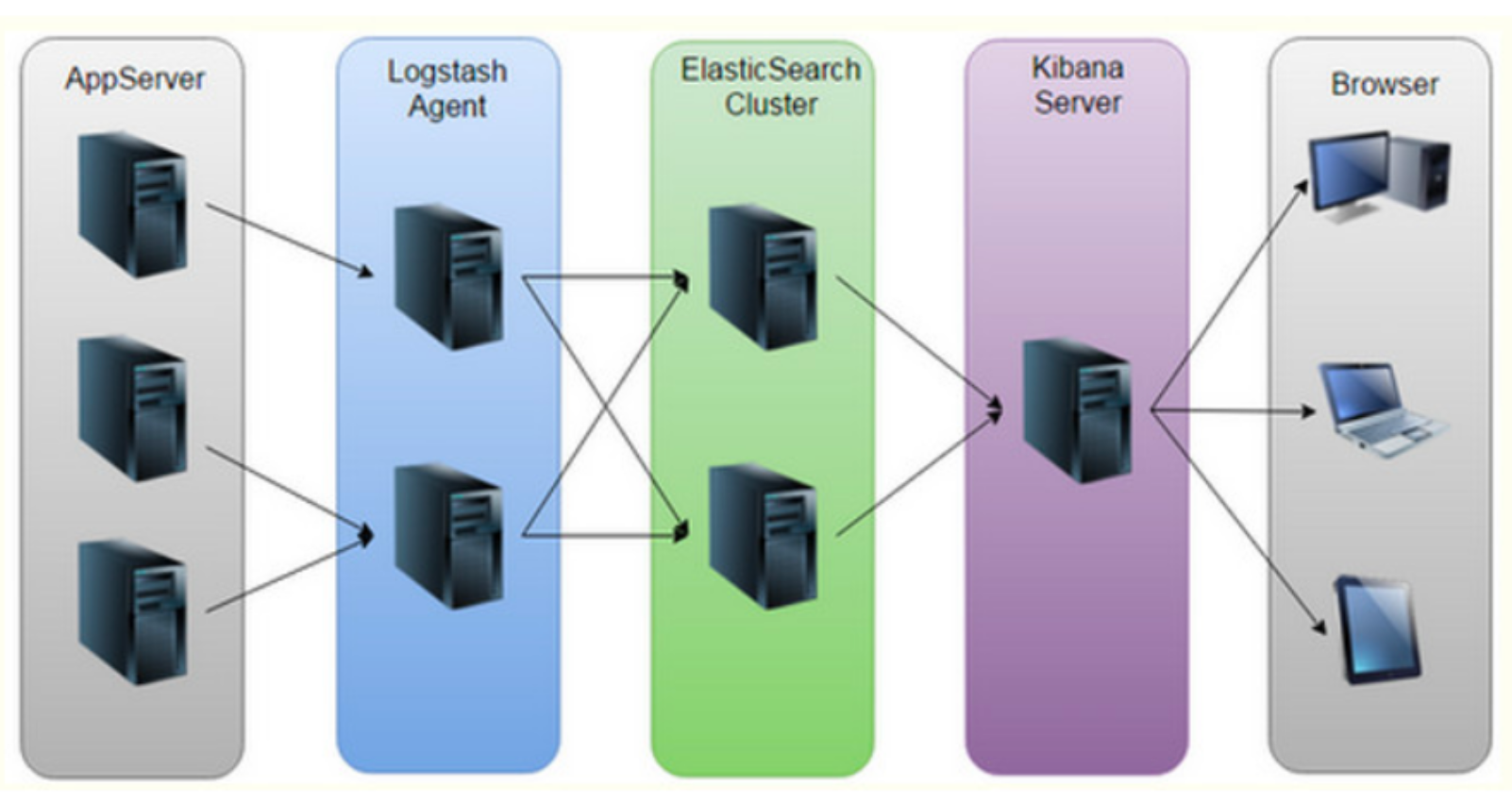
Elk整体架构
Kibana
Kibana 是一款基于 Apache 开源协议,使用 JavaScript 语言编写,为 Elasticsearch 提供分析和可视化的 Web 平
台。它可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度的表图。
Elasticsearch
Elasticsearch 是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在 全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
主要特点
- 实时分析
- 分布式实时文件存储,并将每一个字段都编入索引
- 文档导向,所有的对象全部是文档
- 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)。
- 接口友好,支持 JSON
ES简介
-
什么是ElasticSearch Elasticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本 身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现 所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简 单。
- ElasticSearch使用案例
- 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的 数据,包括13亿文件和1300亿行代码”
- 维基百科:启动以elasticsearch为基础的核心搜索架构
- SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
- 百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定 义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多 个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个 ES节点,每天导入30TB+数据
- 新浪使用ES 分析处理32亿条实时日志
- 阿里使用ES 构建自己的日志采集和分析体系
- ElasticSearch对比Solr
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
Elasticsearch Single-Node Mode部署
Elasticsearch是一个分布式全文搜索引擎,支持单节点模式(Single-Node Mode)和集群模式(Cluster Mode)部署,一 般来说,小公司的业务场景往往使用Single-Node Mode部署即可。先以Single-Node Mode部署感受下ES,后续搭 建分布式集群深入学习。
- 虚拟机环境准备
- 准备一台虚拟机
- 操作系统:CentOS 7.x 64 bit
- 可用内存大小不少于3G
- 客户端连接工具:SecureCRT
- 关闭虚拟机的防火墙
systemctl stop firewalld.service #停止 firewall systemctl disable firewalld.service #禁止firewall开机启动 firewall-cmd --state # 查看防火墙
- 准备一台虚拟机
-
下载安装包
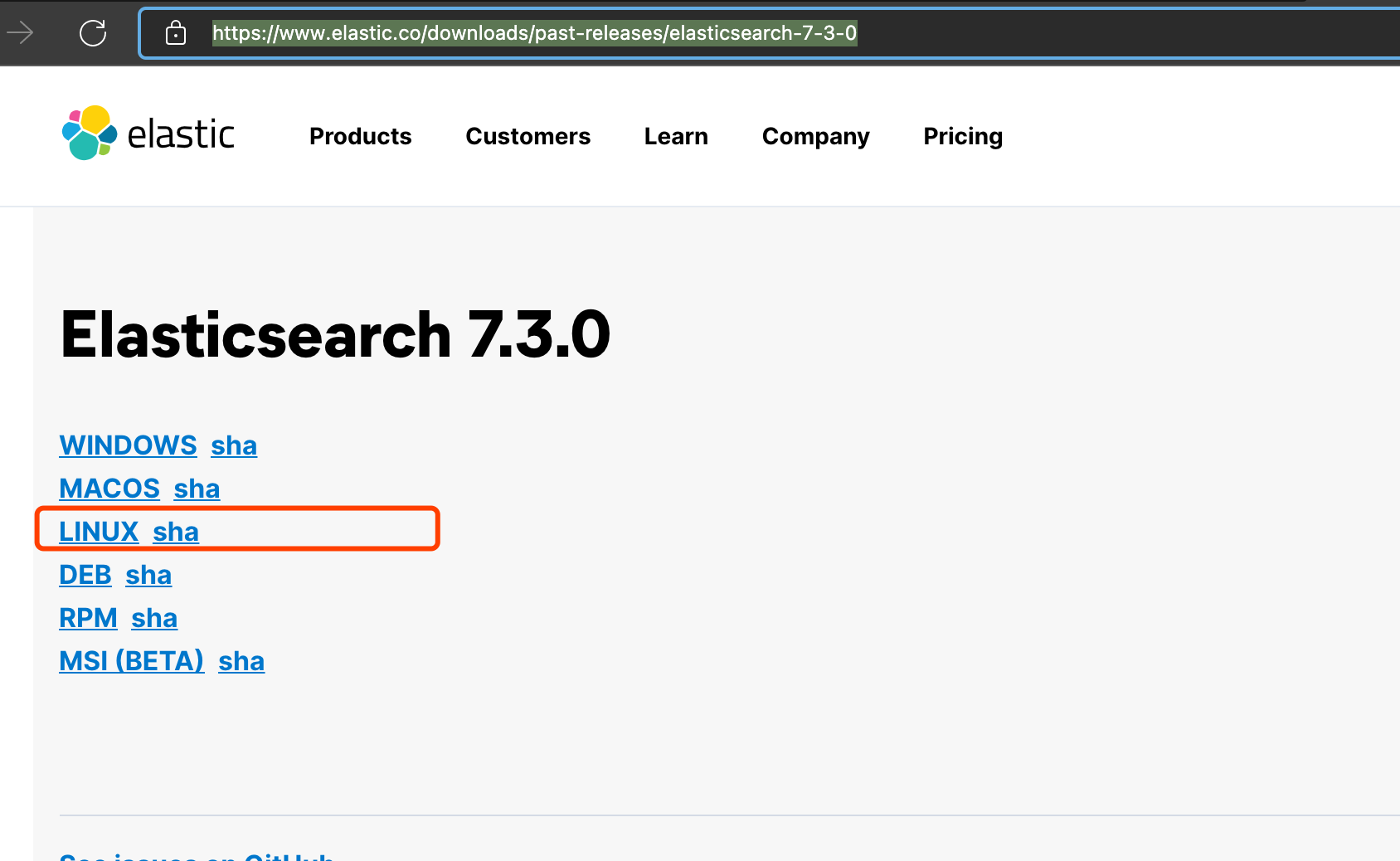 https://www.elastic.co/downloads/past-releases/elasticsearch-7-3-0
https://www.elastic.co/downloads/past-releases/elasticsearch-7-3-01.下载、解压tar.gz文件
wget [https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.4-linux-x86_64.tar.gz](https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.4-linux-x86_64.tar.gz) cd /opt/software tar -zxvf elasticsearch-7.3.0-linux-x86_64.tar.gz -C ../servers cd ../servers/ - 配置Elasticsearch
1.编辑vim config/elasticsearch.yml
- 单机安装请取消注释:node.name: node-1,否则无法正常启动。
- 修改网络和端口,取消注释master节点,单机只保留一个node
vim config/elasticsearch.yml # 修改如下内容,取消注释,根据本机情况修改 node.name: node-1 network.host: centos7-2 # # Set a custom port for HTTP: # http.port: 9200 cluster.initial_master_nodes: ["node-1"]2.按需修改vim config/jvm.options内存设置
vim config/jvm.options # 修改分配内存大小 -Xms2g -Xmx2g根据实际情况修改占用内存,默认都是1G,单机1G内存,启动会占用700m+然后在安装kibana后,基本上无 法运行了,运行了一会就挂了报内存不足。 内存设置超出物理内存,也会无法启动,启动报错。
- 添加es用户,es默认root用户无法启动,需要改为其他用户
useradd estest #修改密码 passwd estest
改变es目录拥有者账号
chown -R estest /opt/servers/elasticsearch/elasticsearch-7.3.04.修改/etc/sysctl.conf
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错修改文件句柄数
vim /etc/sysctl.conf # 末尾添加: vm.max_map_count=655360执行sysctl -p 让其生效
sysctl -p5.修改/etc/security/limits.conf
修改linux系统对文件描述符的限制级别vim /etc/security/limits.conf # 末尾添加: * soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 - 启动es
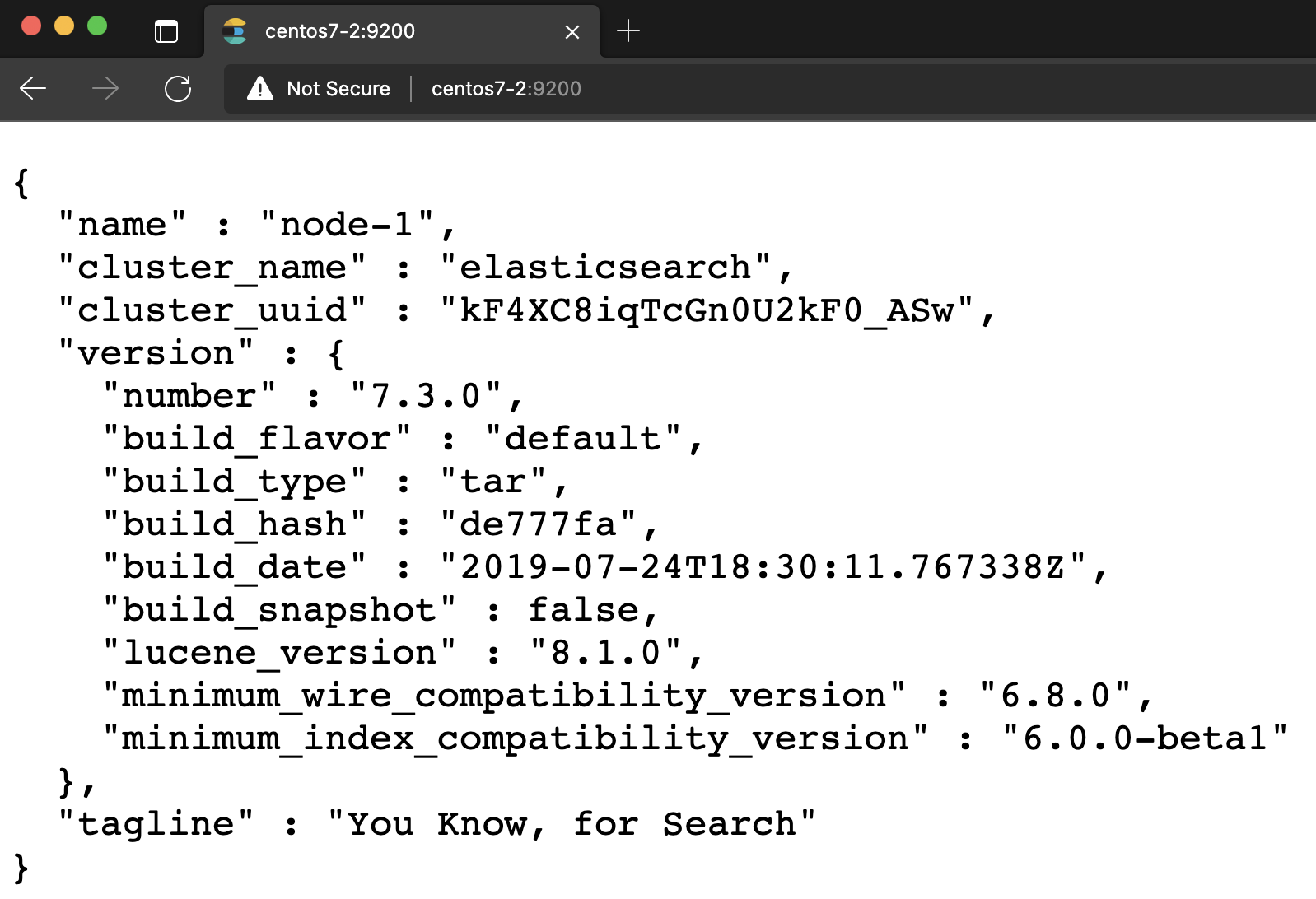
切换刚刚新建的用户su estest cd /opt/servers/elasticsearch-7.3.0/bin/ ./elasticsearch配置完成:浏览器访问测试
http://centos7-2:9200 -
简单使用 创建blog01索引
curl -XPUT http://centos7-2:9200/blog01/?pretty # result { "acknowledged" : true, "shards_acknowledged" : true, "index" : "blog01" }插入文档
curl -XPUT http://centos7-2:9200/blog01/article/1?pretty -d '{"id": "1", "title": "What is lucene"}' -H "Content-Type: application/json" curl -XPUT http://centos7-2:9200/blog01/article/2?pretty -d '{"id": "2", "title": "Apache Spark is a unified analytics engine for large-scale data processing"}' -H "Content-Type: application/json" # results { "_index" : "blog01", "_type" : "article", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 }查询文档
curl -XGET http://centos7-2:9200/blog01/article/1?pretty -H "Content-Type: application/json"更新文档
curl -XPUT http://centos7-2:9200/blog01/article/1?pretty -d '{"id": "1", "title": " What is elasticsearch"}' -H "Content-Type: application/json"搜索文档
curl -XGET "http://centos7-2:9200/blog01/article/_search?q=title:'What'&pretty" -H "Content-Type: application/json" curl -XGET "http://centos7-2:9200/blog01/article/_search?q=title:'is'&pretty" -H "Content-Type: application/json" curl -XGET "http://centos7-2:9200/blog01/article/_search?q=title:'elasticsearch'&pretty" -H "Content-Type: application/json" curl -XGET "http://centos7-2:9200/blog01/article/_search?q=title:'unified'&pretty" -H "Content-Type: application/json"
Elasticsearch核心概念
-
概述 Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅 是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数 据)进行索引、搜索、排序、过滤。
Elasticsearch是基于Lucene的全文检索引擎,本质也是存储和检索数据。ES中的很多概念与MySQL类似 我们可以按 照关系型数据库的经验去理解
- 索引(index)
类似的数据放在一个索引,非类似的数据放不同索引, 一个索引也可以理解成一个关系型数据库。 - 类型(type)
代表document属于index中的哪个类别(type)也有一种说法一种type就像是数据库的表, 比如dept表,user表。
注意ES每个大版本之间区别很大:
ES 5.x中一个index可以有多种type。 ES 6.x中一个index只能有一种type。 ES 7.x以后 要逐渐移除type这个概 念。-
映射(mapping)
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html#_multi_fields_2
mapping定义了每个字段的类型等信息。相当于关系型数据库中的表结构。
常用数据类型:text、keyword、number、array、range、boolean、date、geo_point、ip、nested、 object- Elasticsearch比传统关系型数据库
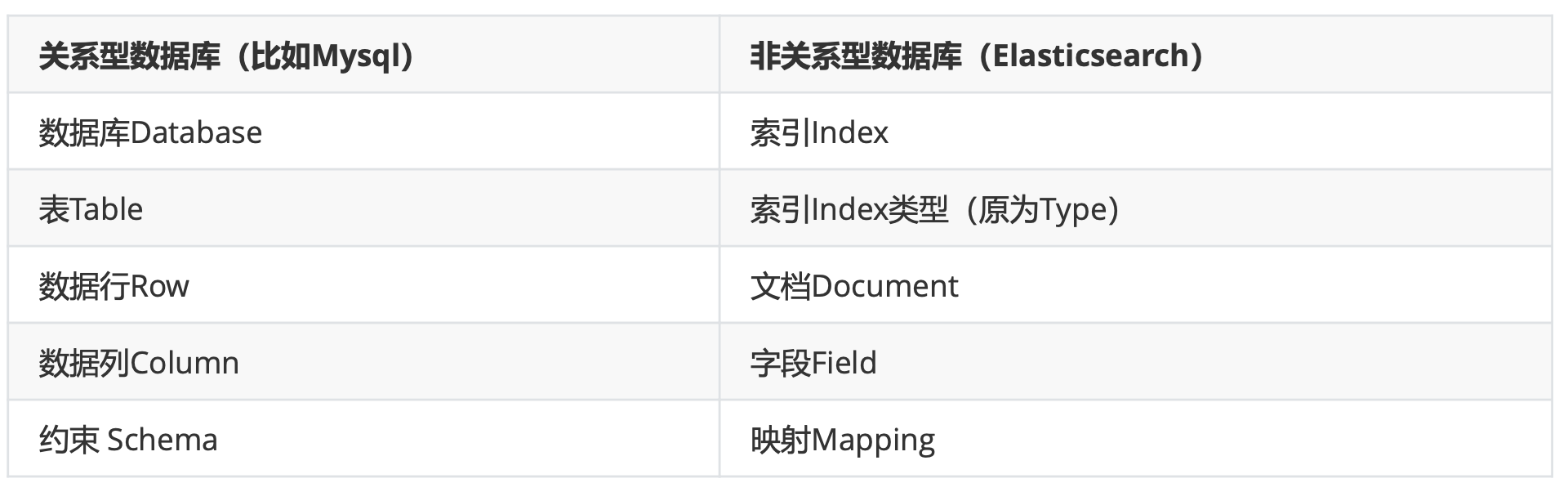
- Elasticsearch比传统关系型数据库
- 索引(index)
-
索引 index 一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
-
类型 type 在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来 定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据 存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为 评论数据定义另一个类型。
高版本ES中逐渐抛弃了type的概念,会有一个默认的type:_doc -
字段Field 相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
-
映射 mapping mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这 些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性 能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
-
文档 document 一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也 可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在 的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被 索引/赋予一个索引的type。 -
接近实时 NRT(near real time) Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
-
cluster
-
集群(Cluster) 一个Elasticsearch集群由多个节点(Node)组成,每个集群都有一个共同的集群名称作为标 识
- 节点(Node)
- 一个Elasticsearch实例即一个Node,一台机器可以有多个实例,正常使用下每个实例都应该会部署在不同的机器上。Elasticsearch的配置文件中可以通过node.master、node.data来设置节点类型。
- node.master:表示节点是否具有成为主节点的资格
- true代表的是有资格竞选主节点
- false代表的是没有资格竞选主节点
- node.data:表示节点是否存储数据
-
Node节点组合 主节点+数据节点(master+data) 默认
* 节点既有成为主节点的资格,又存储数据
shell node.master: true node.data: true
* 数据节点(data) 节点,没有成为主节点的资格,不参与选举,只会存储数据
shell node.master: false node.data: true
* 客户端节点(client) 不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡
shell node.master: false node.data: false -
分片 每个索引有1个或多个分片,每个分片存储不同的数据。分片可分为主分片(primary shard)和复制分片 (replica shard),复制分片是主分片的拷贝。默认每个主分片有一个复制分片,每个索引的复制分片的 数量可以动态地调整,复制分片从不与它的主分片在同一个节点上
- 副本
这里指主分片的副本分片(主分片的拷贝)
- 提高恢复能力:当主分片挂掉时,某个复制分片可以变成主分片;
- 提高性能:get 和 search 请求既可以由主分片又可以由复制分片处理;
注意:每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索 引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建 的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点, 你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
-
Elasticsearch 集群部署
-
准备工作
- 创建用户
创建一个es专门的用户(必须),因为es不能用root用户启动
使用root用户在三台机器执行以下命令useradd es mkdir -p /opt/servers/es mkdir -p /opt/servers/es/data mkdir -p /opt/servers/es/logs chown -R es /opt/servers/es passwd es密码:123456
-
为es用户添加sudo权限 三台机器使用root用户执行,然后为es用户添加权限
vim /etc/sudoers # 添加如下内容 es ALL=(ALL) ALL # :wq! 保存退出 -
打开机器限制 三台机器都要设置
- 修改/etc/sysctl.conf
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
修改文件句柄数
vim /etc/sysctl.conf # 末尾添加: vm.max_map_count=655360执行sysctl -p 让其生效
sysctl -p2.修改/etc/security/limits.conf
修改linux系统对文件描述符的限制级别vim /etc/security/limits.conf # 末尾添加: * soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 - 修改/etc/sysctl.conf
- 创建用户
创建一个es专门的用户(必须),因为es不能用root用户启动
-
分布式安装部署 关闭所有的会话,重新连接,一定要记得使用es的用户来连接服务器
- 服务器centos7-1
- 解压安装包
tar -zxvf elasticsearch-7.3.0-linux-x86_64.tar.gz -C ../servers/es cd /opt/servers/es mv elasticsearch-7.3.0/ elasticsearch/ - 修改配置文件 elasticsearch.yml
cd /opt/servers/es/elasticsearch/config vim elasticsearch.yml # 集群名字 cluster.name: myes ## 集群中当前的节点 node.name: centos7-1 ## 数据目录 path.data: /opt/servers/es/data # # 日志目录 path.logs: /opt/servers/es/logs # # 当前主机的ip地址 network.host: centos7-1 http.port: 9200 #初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["centos7-1","centos7-2","centos7-3"] #写入候选主节点的设备地址 discovery.seed_hosts: ["centos7-1", "centos7-2","centos7-3"] # 添加 http.cors.enabled: true http.cors.allow-origin: "*"- 修改配置文件jvm.options
cd /opt/servers/es/elasticsearch/config vi jvm.options # 修改内存 -Xms2g -Xmx2g- 配置文件说明
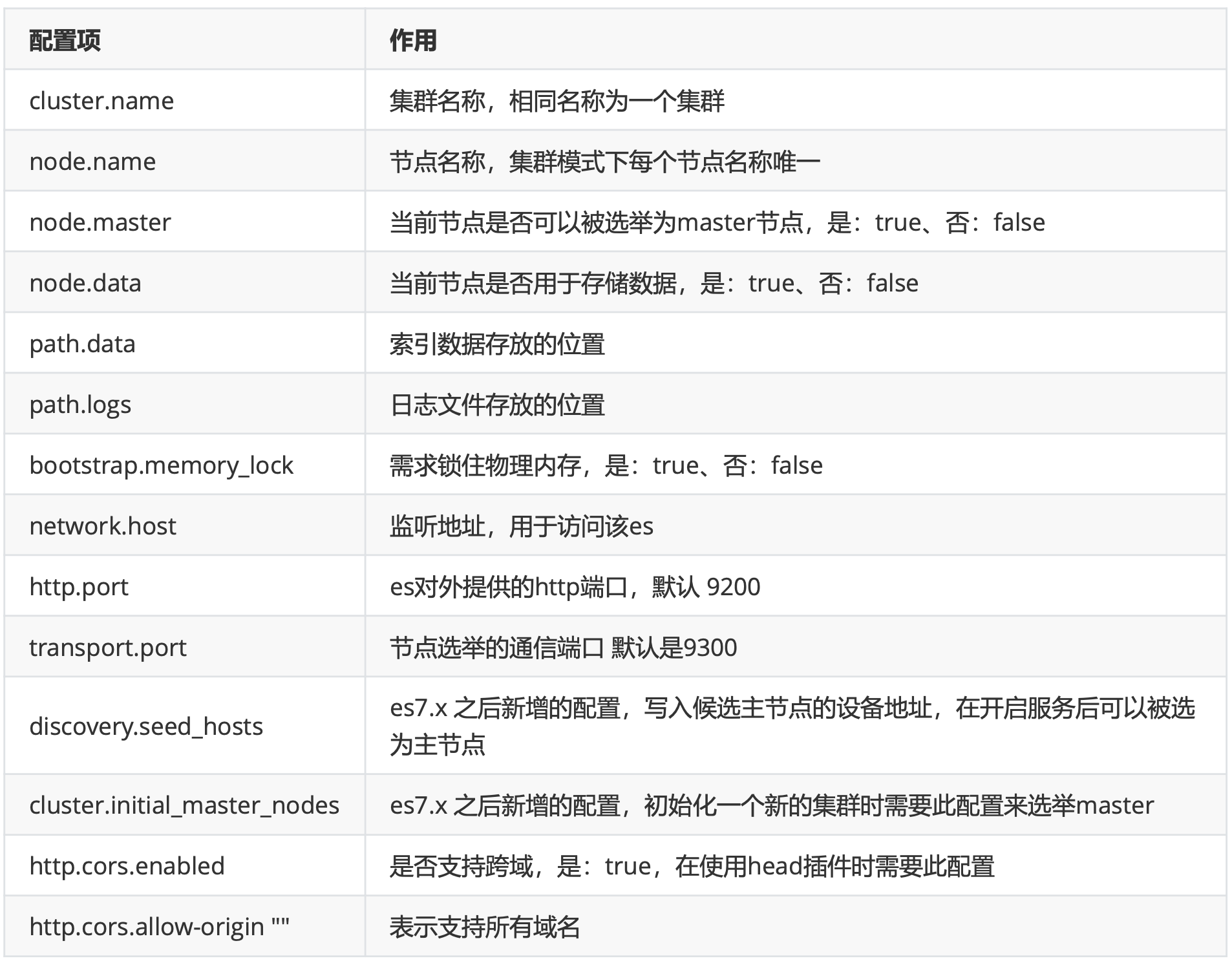
- 解压安装包
-
安装包分发到其他两台机器上 centos7-1服务器执行以下命令
cd /opt/servers/es scp -r elasticsearch/ centos7-2:$PWD scp -r elasticsearch/ centos7-3:$PWD - centos7-2与centos7-3修改配置文件
cd /opt/lagou/servers/es/elasticsearch/config/ vim elasticsearch.yml # 把下面两个属性替换成当前host即可 node.name: centos7-1 network.host: centos7-1 - 启动es服务
后台启动
nohup /opt/servers/es/elasticsearch/bin/elasticsearch >/dev/null 2>&1 &可以在log目录查看启动日志
cd /opt/servers/es/logs vim myes.log -
访问es
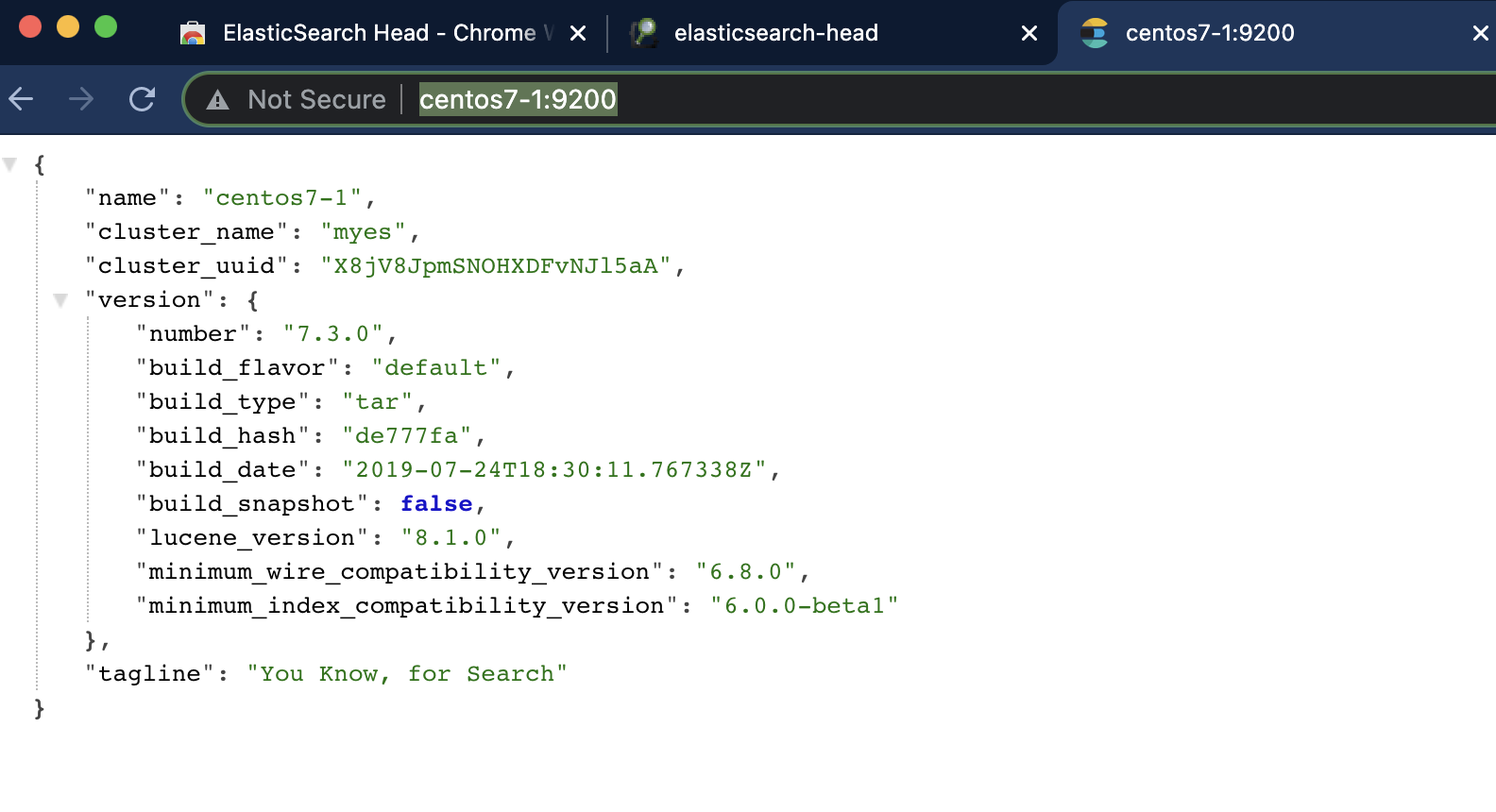 http://centos7-1:9200/
http://centos7-1:9200/
http://centos7-2:9200/
http://centos7-3:9200/三台机器都可以访问
-
安装elasticsearch-head插件
 Chrome插件安装地址
Chrome插件安装地址
https://chrome.google.com/webstore/detail/elasticsearch-head/ffmkiejjmecolpfloofpjologoblkegm/related- 打开插件,替换url即可查看集群信息
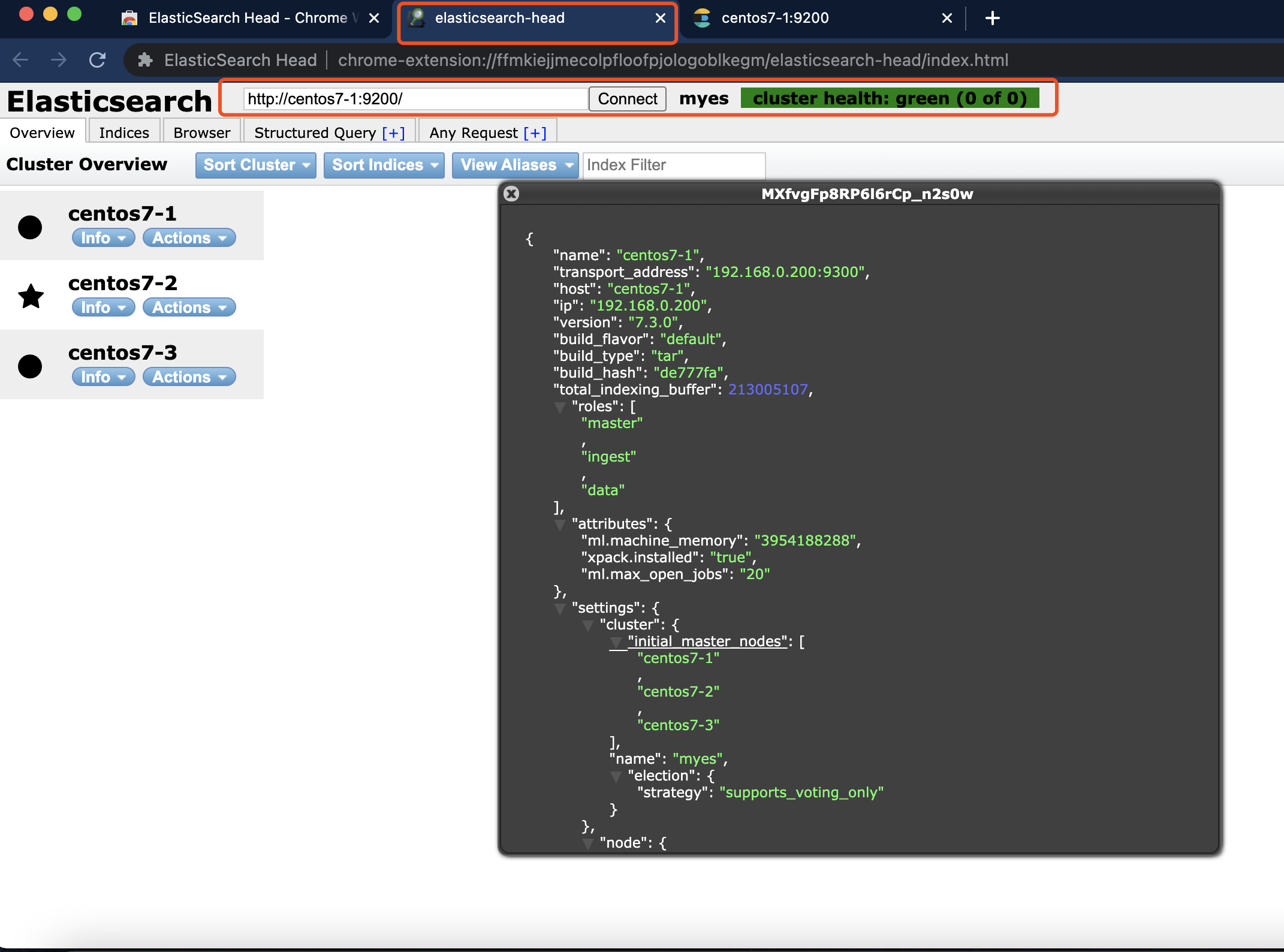
- 打开插件,替换url即可查看集群信息
- 服务器centos7-1
-
安装配置kibana
- 下载和安装
cd /opt/software/ wget [https://artifacts.elastic.co/downloads/kibana/kibana-7.3.0-linux-x86_64.tar.gz](https://artifacts.elastic.co/downloads/kibana/kibana-7.3.0-linux-x86_64.tar.gz) tar -zxvf kibana-7.3.0-linux-x86_64.tar.gz -C ../servers/ cd ../servers/ mv kibana-7.3.0-linux-x86_64/ kibana-7.3.0 # 所有用户可访问 chmod -R 777 /opt/servers/kibana-7.3.0 # 改变kibana目录拥有者账号 chown -R es /opt/servers/kibana-7.3.0修改配置文件
vim /opt/servers/kibana-7.3.0/config/kibana.yml修改端口,访问ip,elasticsearch服务器ip
server.port: 5601 server.host: "centos7-2" # The URLs of the Elasticsearch instances to use for all your queries. elasticsearch.hosts: ["http://centos7-1:9200","http://centos7-2:9200","http://centos7-3:9200"] - 启动kibana
# 切换用户 su es cd /opt/servers/kibana-7.3.0/bin/ ./kibana- http://centos7-2:5601
- http://centos7-2:5601
- kidbana使用页面
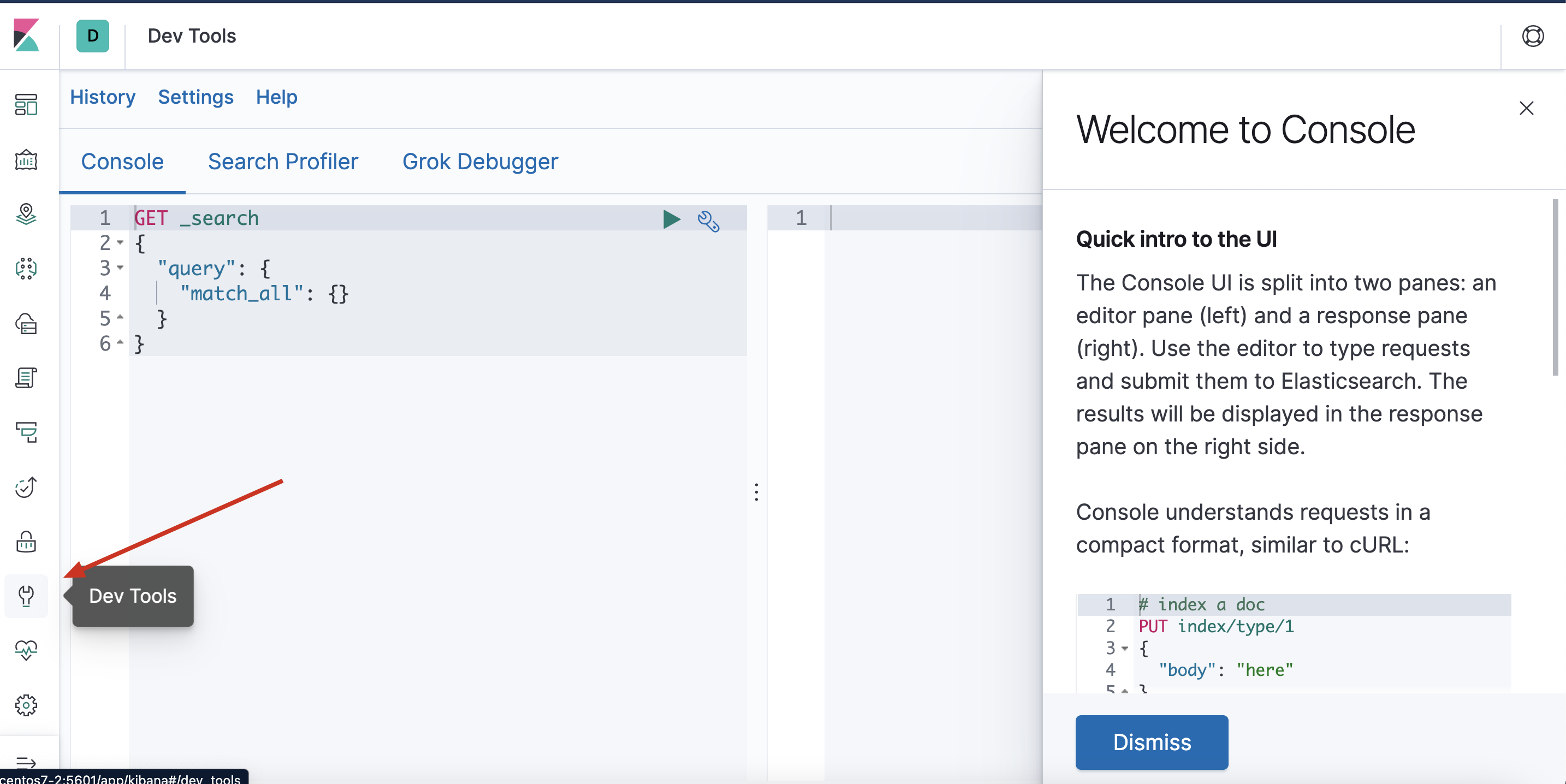 选择左侧的DevTools菜单,即可进入控制台页面
选择左侧的DevTools菜单,即可进入控制台页面
- 下载和安装
管理索引
-
索引操作(创建、查看、删除)
-
创建索引库
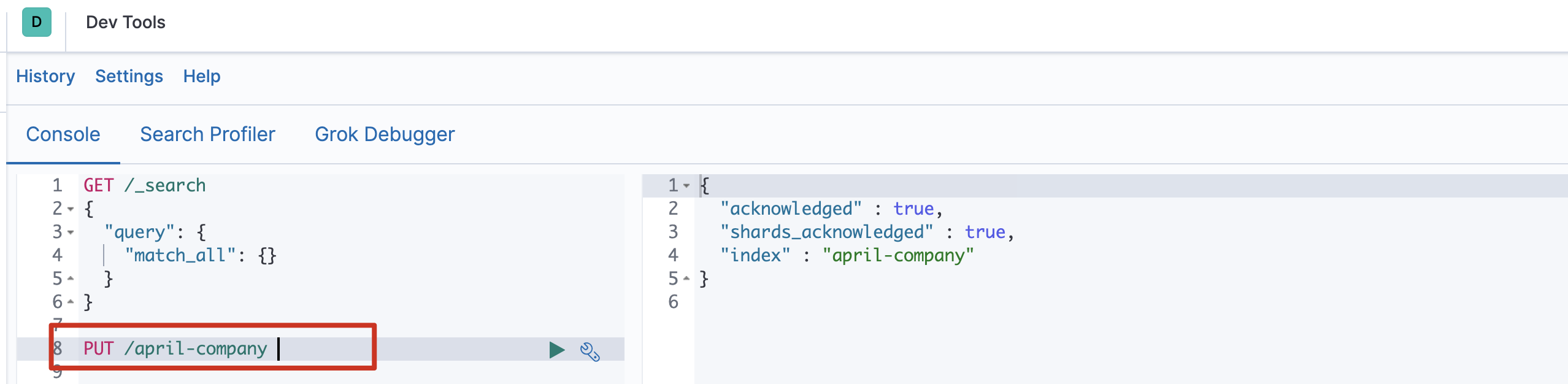 Elasticsearch采用Rest风格API,因此其API就是一次http请求,你可以用任何工具发起http请求
Elasticsearch采用Rest风格API,因此其API就是一次http请求,你可以用任何工具发起http请求PUT /索引名称 { "settings": { "属性名": "属性值" } }settings:就是索引库设置,其中可以定义索引库的各种属性 比如分片数 副本数等,目前我们可以不设置,都走默 认
- 判断索引是否存在
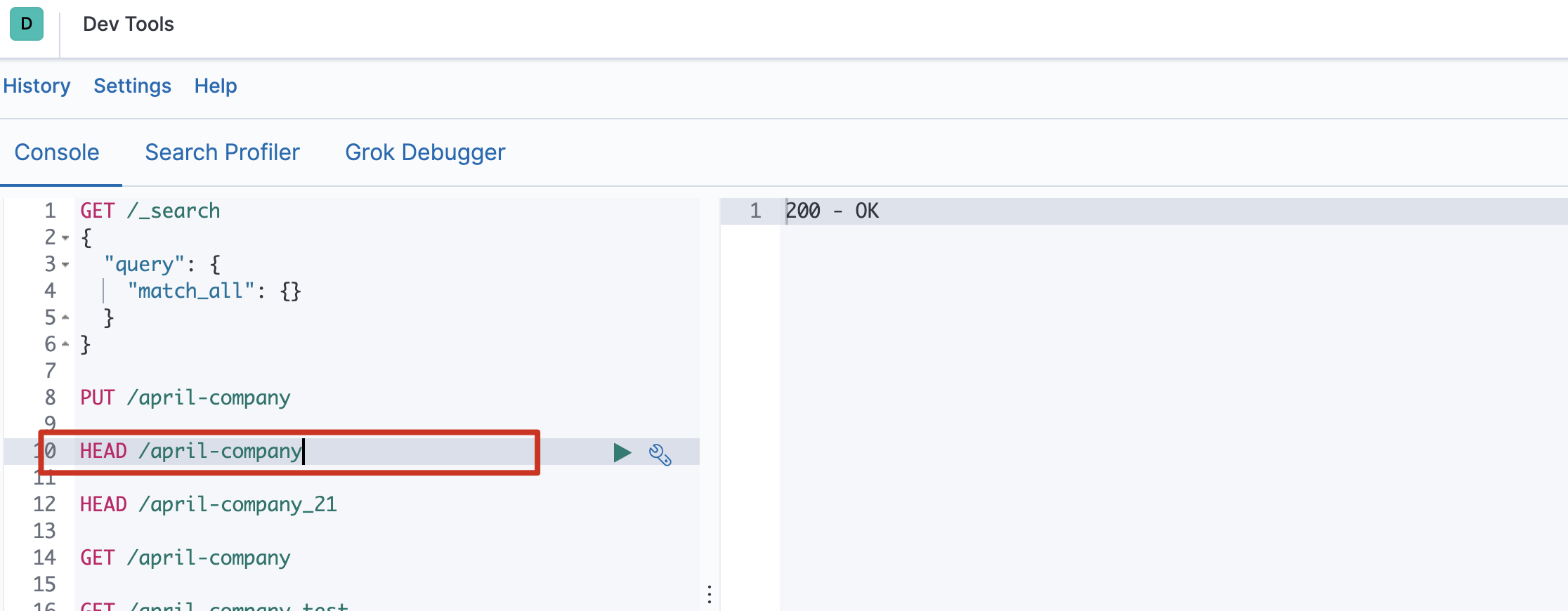
HEAD /索引名称 - 查看索引
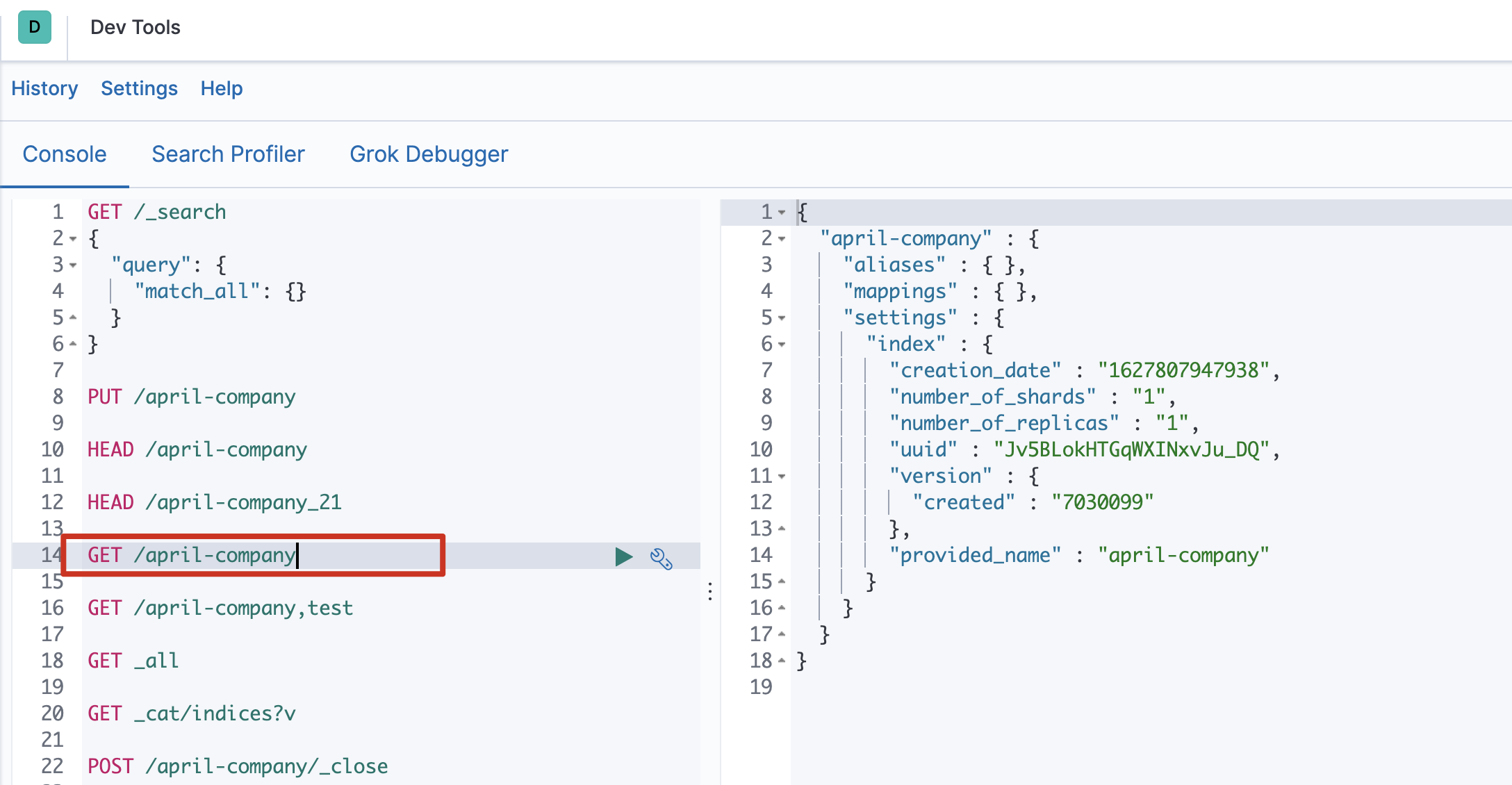 Get请求可以帮我们查看索引的相关属性信息,格式:
Get请求可以帮我们查看索引的相关属性信息,格式:
查看单个索引GET /索引名称- 批量查看索引
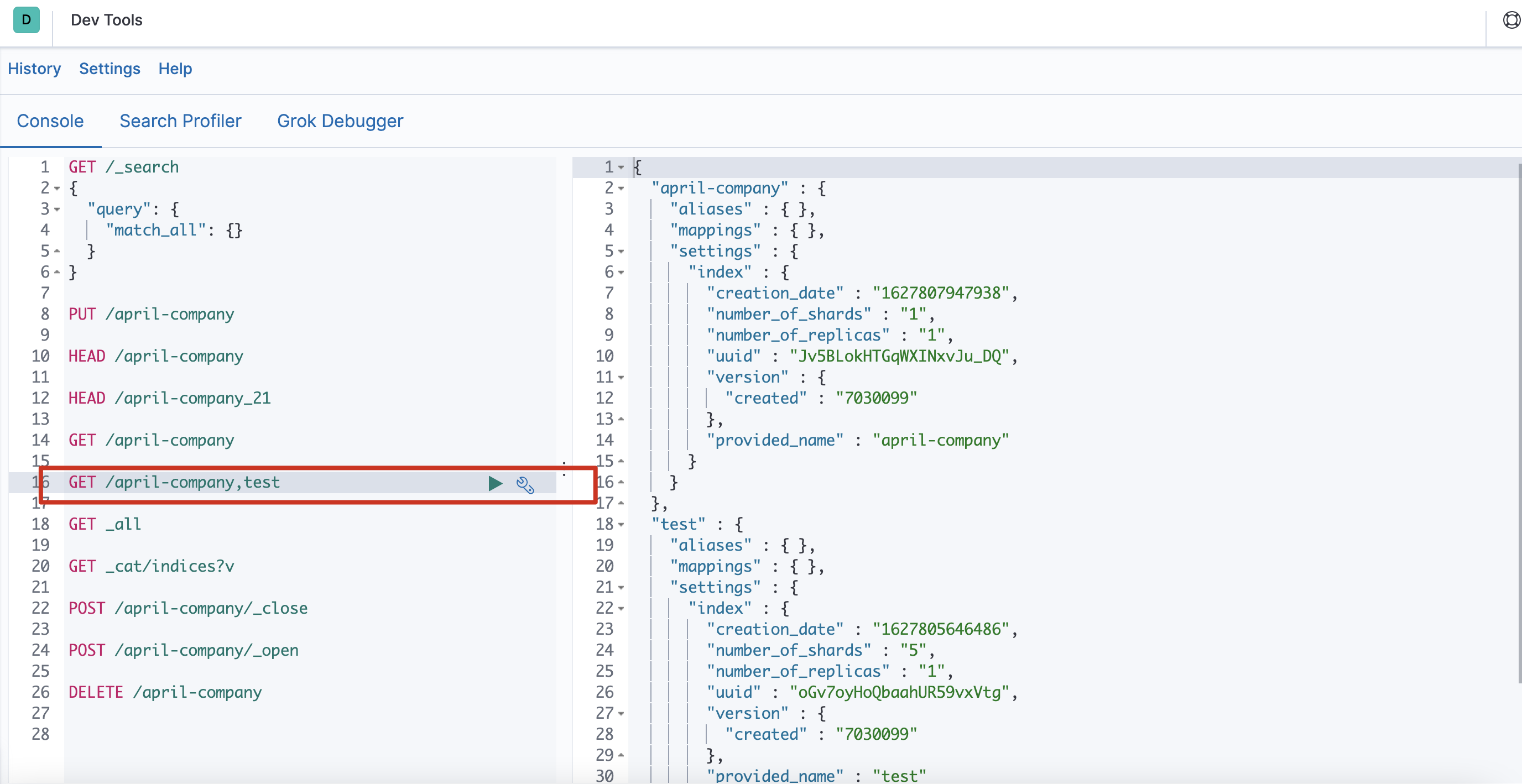
GET /索引名称1,索引名称2,索引名称3,... -
查看所有索引
- 方式一
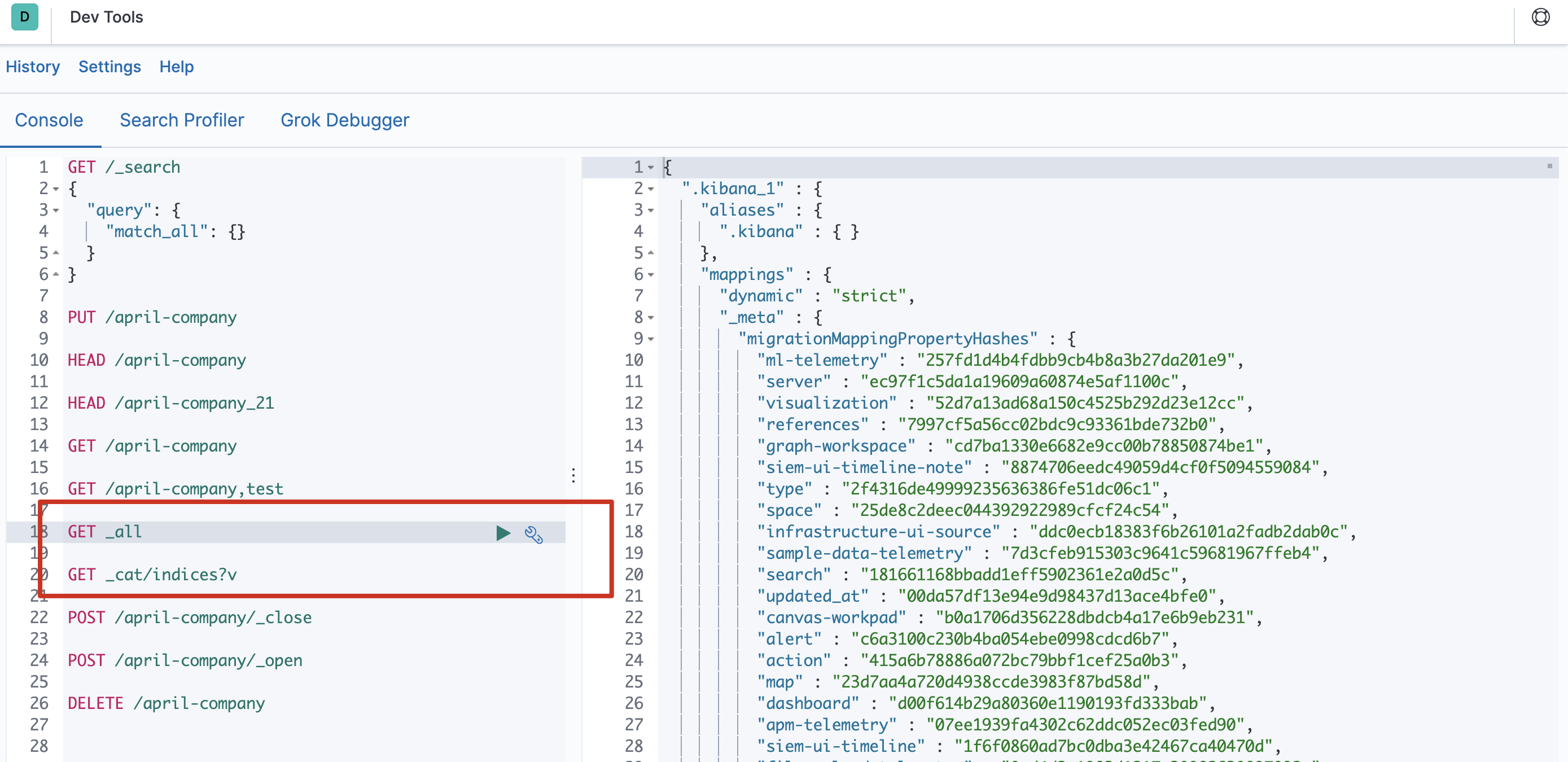
GET _all - 方式二
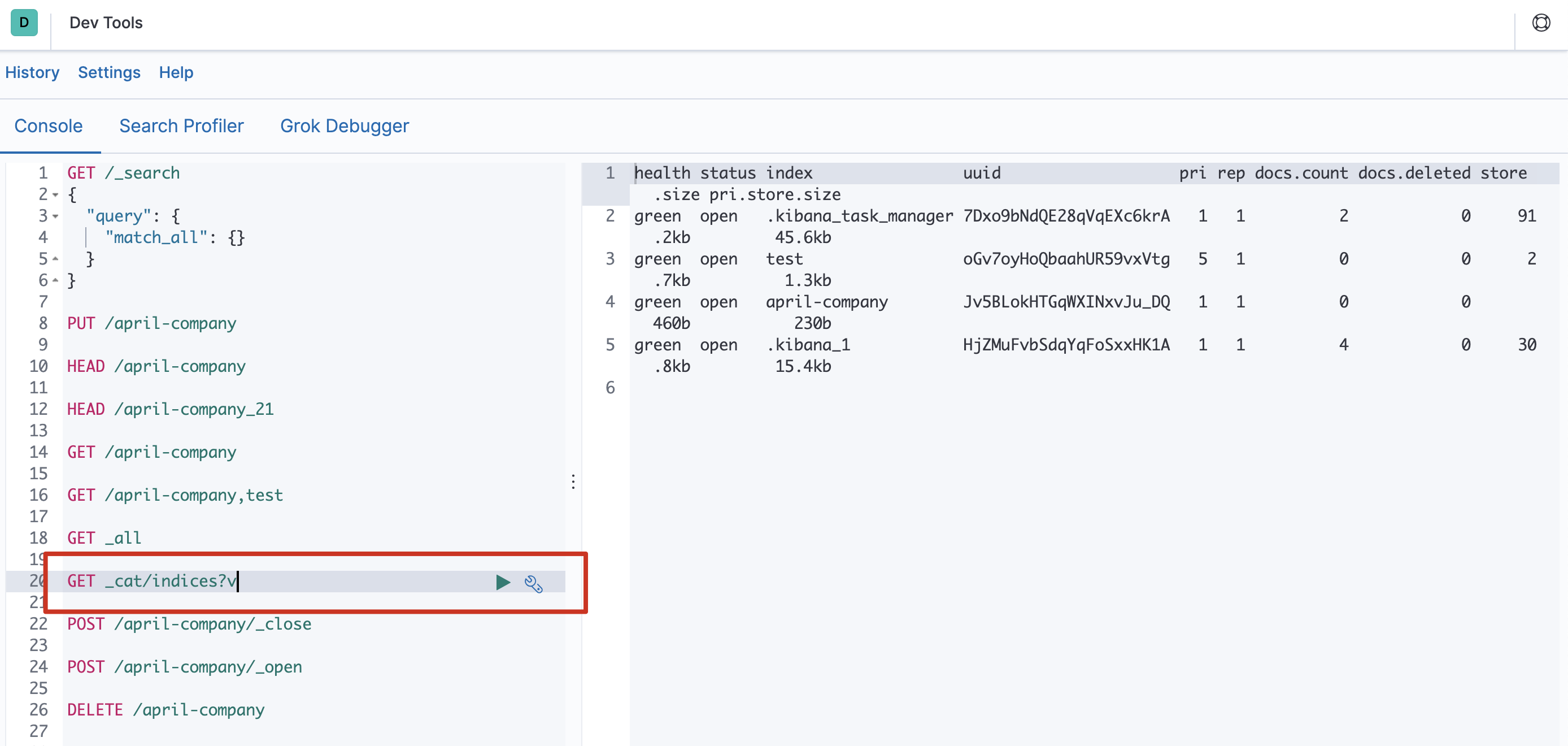
GET /_cat/indices?v绿色:索引的所有分片都正常分配。
黄色:至少有一个副本没有得到正确的分配。
红色:至少有一个主分片没有得到正确的分配。
- 方式一
- 批量查看索引
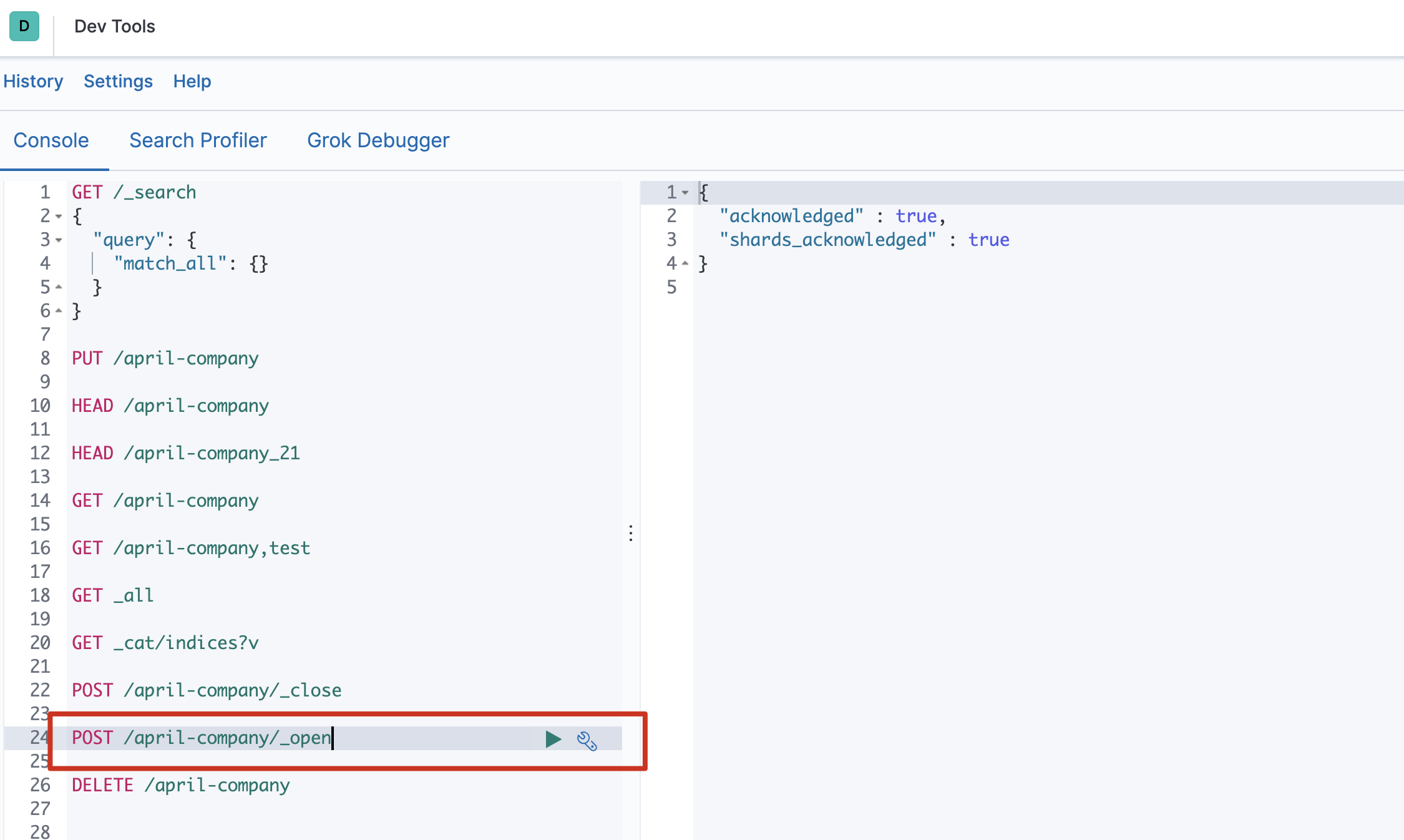
- 打开索引
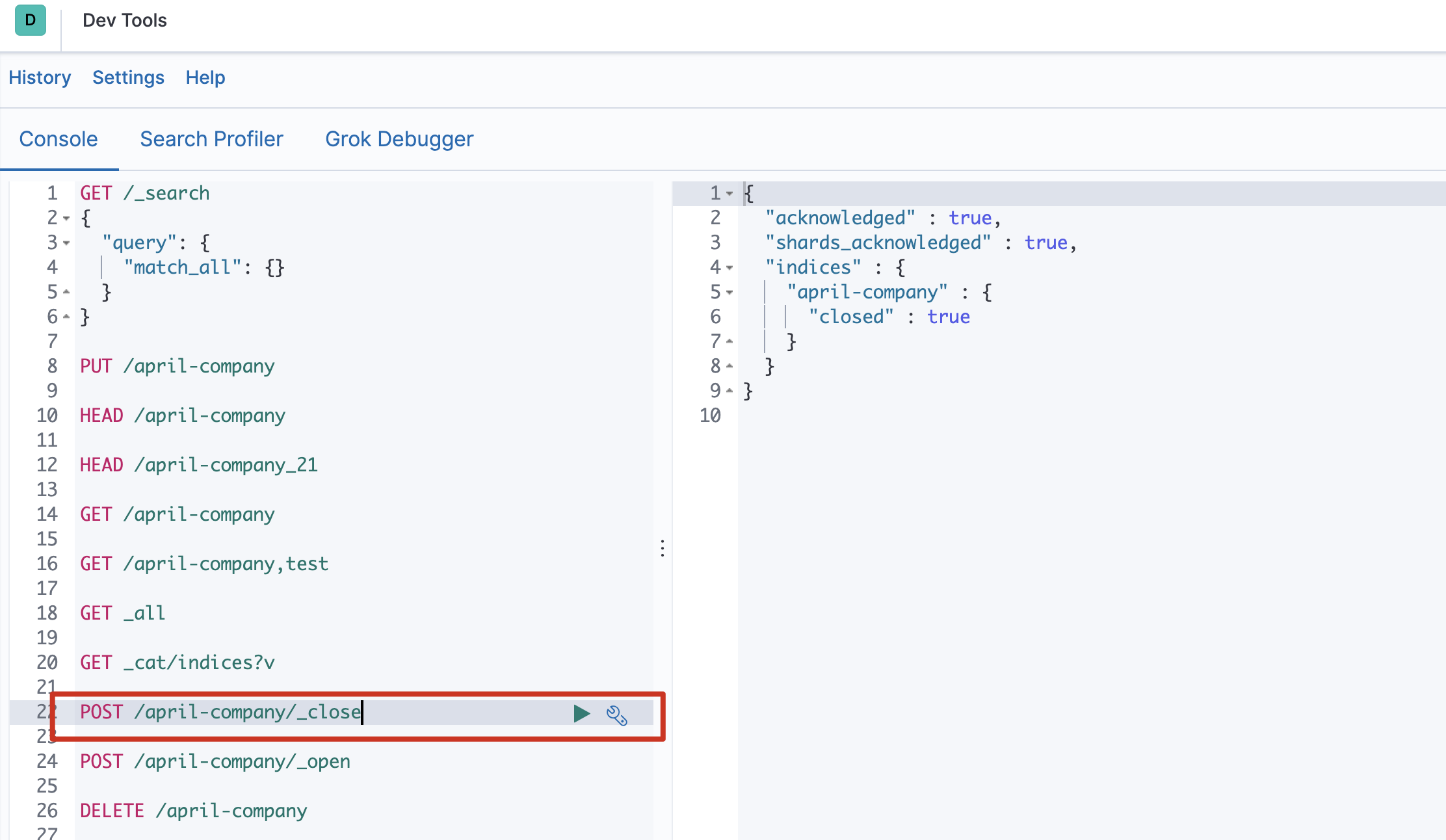
POST /索引名称/_open - 关闭索引
POST /索引名称/_close - 删除索引库
 删除索引使用DELETE请求
删除索引使用DELETE请求
DELETE /索引名称1,索引名称2,索引名称3...
-
-
安装IK分词器
-
安装 使用root用户操作!! 每台机器都要配置。
配置完成之后,需要重启ES服务- 在elasticsearch安装目录的plugins目录下新建 analysis-ik 目录
#新建analysis-ik文件夹 mkdir analysis-ik #切换至 analysis-ik文件夹下 cd analysis-ik #上传资料中的 elasticsearch-analysis-ik-7.3.0.zip #解压 unzip elasticsearch-analysis-ik-7.3.3.zip #解压完成后删除zip rm -rf elasticsearch-analysis-ik-7.3.0.zip #分发到其它节点 cd .. scp -r analysis-ik/ centos7-2:$PWD scp -r analysis-ik/ centos7-3:$PWD - 重启Elasticsearch 和Kibana
#杀死es ps -ef|grep elasticsearch|grep bootstrap |awk '{print $2}' |xargs kill -9 #启动 nohup /opt/servers/es/elasticsearch/bin/elasticsearch >/dev/null 2>&1 & #重启kibana cd /opt/servers/kibana-7.3.0/bin ./kibana
- 在elasticsearch安装目录的plugins目录下新建 analysis-ik 目录
- 测试
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
- ik_max_word (常用) 会将文本做最细粒度的拆分
-
ik_smart 会做最粗粒度的拆分
-
ik_max_word
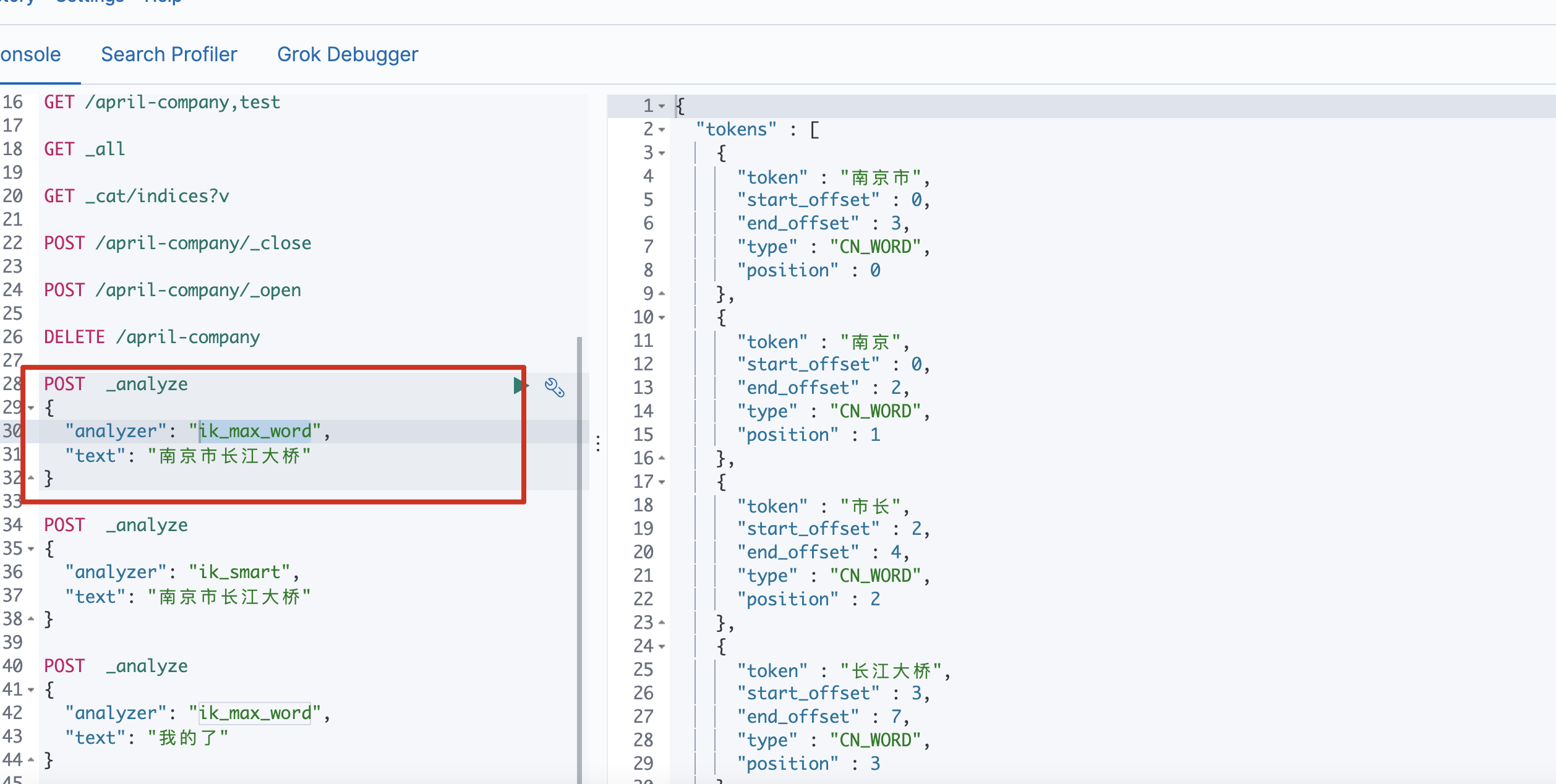 POST _analyze
POST _analyze
{
“analyzer”: “ik_max_word”,
“text”: “南京市长江大桥”
} -
ik_smart
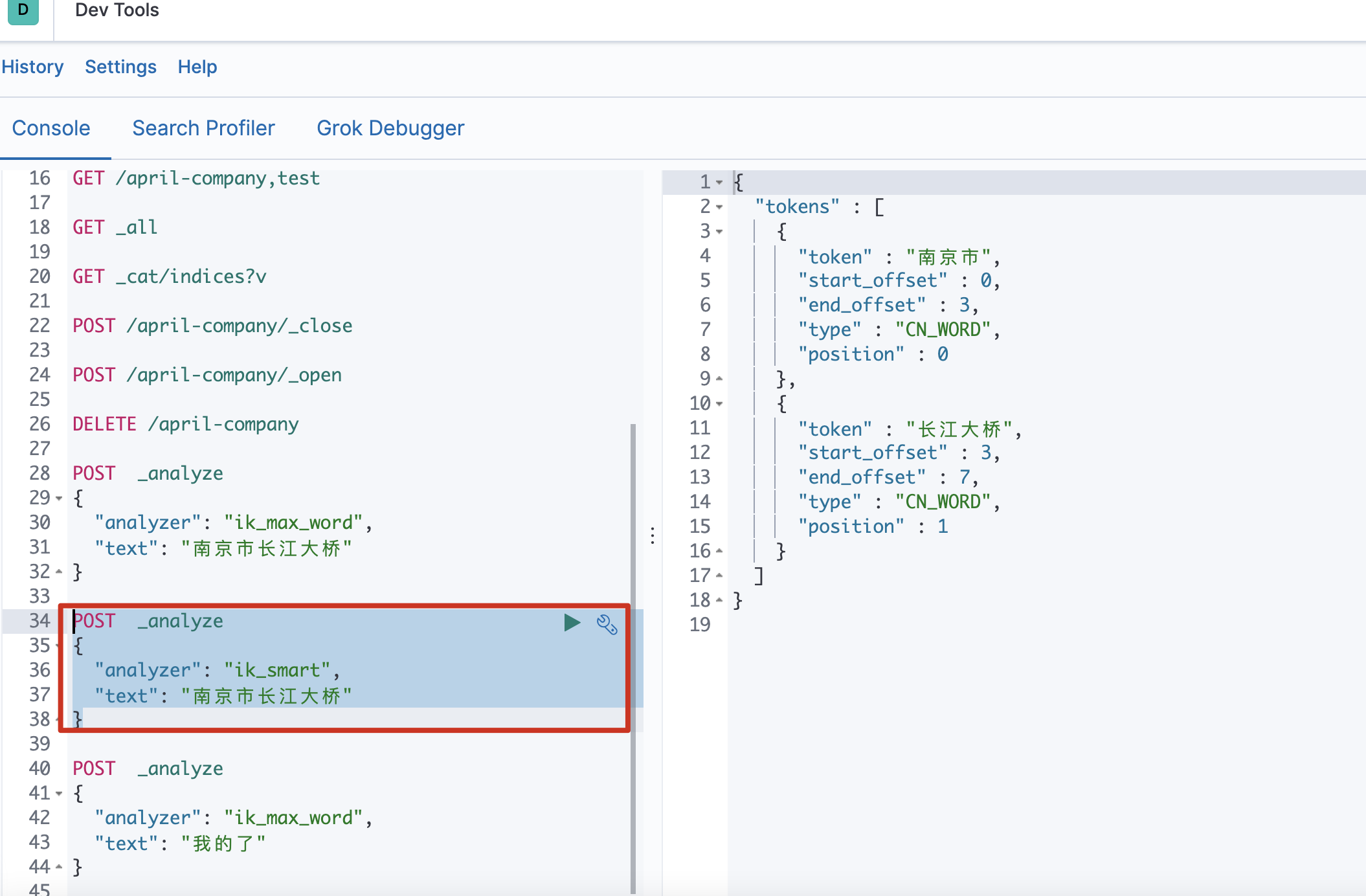 POST _analyze
POST _analyze
{
“analyzer”: “ik_smart”,
“text”: “南京市长江大桥”
} -
如果 如果现在假如江大桥是一个人名,是南京市市长,那么上面的分词显然是不合理的,该怎么办?
使用自定义字典
-
-
词典使用 扩展词:就是不想让哪些词被分开,让他们分成一个词。比如上面的江大桥
停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、an、the、of 等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如 果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。-
远程字典配置 扩展词与停用词集中存储到linux123服务器上,使用web服务器集中管理,避免每个节点维护一份自己的词典
centos7-3部署Tomcat
以下操作使用es用户- 上传tomcat安装包到centos7-3服务器
为了避免权限问题上传到此目录下:/opt/servers/es/
2.解压
tar -zxvf apache-tomcat-8.5.59.tar.gz mv apache-tomcat-8.5.59/ tomcat/3.配置自定义词典文件
- 自定义扩展词库
cd /opt/lagou/servers/es/tomcat/webapps/ROOT vim ext_dict.dic添加:江大桥
- 自定义停用词
vim stop_dict.dic添加:
的 了 啊
- 启动tomcat
cd /opt/servers/es/tomcat/bin ./startup.sh - 配置IK分词器
添加自定义扩展,停用词典
使用root用户修改,或者直接把整个文件夹改为es用户所有!!
#三个节点都需修改 cd /opt/servers/es/elasticsearch/plugins/analysis-ik/config vim IKAnalyzer.cfg.xml<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">http://centos7-3:8080/ext_dict.dic</entry> <!--用户可以在这里配置远程扩展停止词字典--> <entry key="remote_ext_stopwords">http://centos7-3:8080/stop_dict.dic</entry> </properties>6.重启服务
#杀死es ps -ef|grep elasticsearch|grep bootstrap |awk '{print $2}' |xargs kill -9 #启动 nohup /opt/servers/es/elasticsearch/bin/elasticsearch >/dev/null 2>&1 & #重启kibana cd /opt/servers/kibana-7.3.0/bin ./kibana - 上传tomcat安装包到centos7-3服务器
-
-
-
映射操作 索引创建之后,等于有了关系型数据库中的database。Elasticsearch7.x取消了索引type类型的设置,不允许指定类型,默认为_doc,但字段仍然是有的,我们需要设置字段的约束信息,叫做字段映射(mapping)
字段的约束包括但不限于:
- 字段的数据类型
- 是否要存储
- 是否要索引
-
分词器
- 创建映射字段
PUT /索引库名/_mapping { "properties": { "字段名": { "type": "数据类型", "index": true, //是否索引,不索引就无法针对这个字段查询 "store": false, //存储,默认不存储,_source:存储了文档的所有字段内容;从_source字段中可以获取所有字段,但是需要自己解析,如果对某个字段指定了存储,在查询时直接指定返回的字段会增加io开销。 "analyzer": "分词器" } } }https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-params.html
字段名:任意填写,下面指定许多属性,例如:
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false
- analyzer:指定分词器
示例
# 创建索引 PUT /lagou-company-index # 创建schema,mapping PUT /lagou-company-index/_mapping/ { "properties": { "name": { "type": "text", "analyzer": "ik_max_word" }, "job": { "type": "text", "analyzer": "ik_max_word" }, "logo": { "type": "keyword", "index": "false" }, "payment": { "type": "float" } } } -
映射属性详解
-
type
 Elasticsearch中支持的数据类型非常丰富
Elasticsearch中支持的数据类型非常丰富
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-types.html- String类型,又分两种:
- text:可分词,不可参与聚合
- keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
- Numerical:数值类型,分两类
- 基本数据类型:long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
* 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
- Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。 - Array:数组类型
* 进行匹配时,任意一个元素满足,都认为满足- 排序时,如果升序则用数组中的最小值来排序,如果降序则用数组中的最大值来排序
- Object:对象
- String类型,又分两种:
-
index index影响字段的索引情况。
* true:字段会被索引,则可以用来进行搜索。默认值就是true
* false:字段不会被索引,不能用来搜索
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。 但是有些字段是我们不希望被索引 的,比如企业的logo图片地址,就需要手动设置index为false。 -
store 是否将数据进行独立存储。 原始的文本会存储在 _source 里面,默认情况下其他提取出来的字段都不是独立存储 的,是从 _source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置store:true即可,获取独立存储的 字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置,默认为false
-
analyzer:指定分词器 一般我们处理中文会选择ik分词器 ik_max_word, ik_smart
-
- 查看映射关系
查看单个索引映射关系
GET /索引名称/_mapping查看所有索引映射关系
GET _mapping示例
# 查看schema GET /lagou-company-index/_mapping # 查看所有schema GET /_mapping - 修改索引映射关系
PUT /索引库名/_mapping { "properties": { "字段名": { "type": "类型", "index": true, "store": true, "analyzer": "分词器" } } }注意:修改映射只能是增加字段操作,做其它更改只能删除索引 重新建立映射
- 一次性创建索引和映射
可以在创建索引库的同时,直接制定索引库中的索引
put /索引库名称 { "settings":{ "索引库属性名":"索引库属性值" }, "mappings":{ "properties":{ "字段名":{ "映射属性名":"映射属性值" } } } }案例
# 创建索引的使用指定mapping PUT /lagou-employee-index { "settings": {}, "mappings": { "properties": { "name": { "type": "text", "analyzer": "ik_max_word" } } } } GET /lagou-employee-index
-
文档增删改查及局部更新 文档,即索引库中的数据,会根据规则创建索引,将来用于搜索。可以类比做数据库中的一行数据。
-
新增文档 新增文档时,涉及到id的创建方式,手动指定或者自动生成。
- 新增文档(手动指定id)
POST /索引名称/_doc/{id} { "field":"value" }示例
POST /lagou-company-index/_doc/1 { "name": "百度", "job": "小度用户运营经理", "payment": "30000", "logo": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm8374.png" } POST /lagou-company-index/_doc/2 { "name": "百度", "job": "小度用户运营经理", "payment": "30000", "logo": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm8374.png", "address": "北京市昌平区" } POST /lagou-company-index/_doc/3 { "name1": "百度", "job1": "小度用户运营经理", "payment1": "30000", "logo1": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm8374.png", "address1": "北京市昌平区" } - 新增文档(自动生成id)
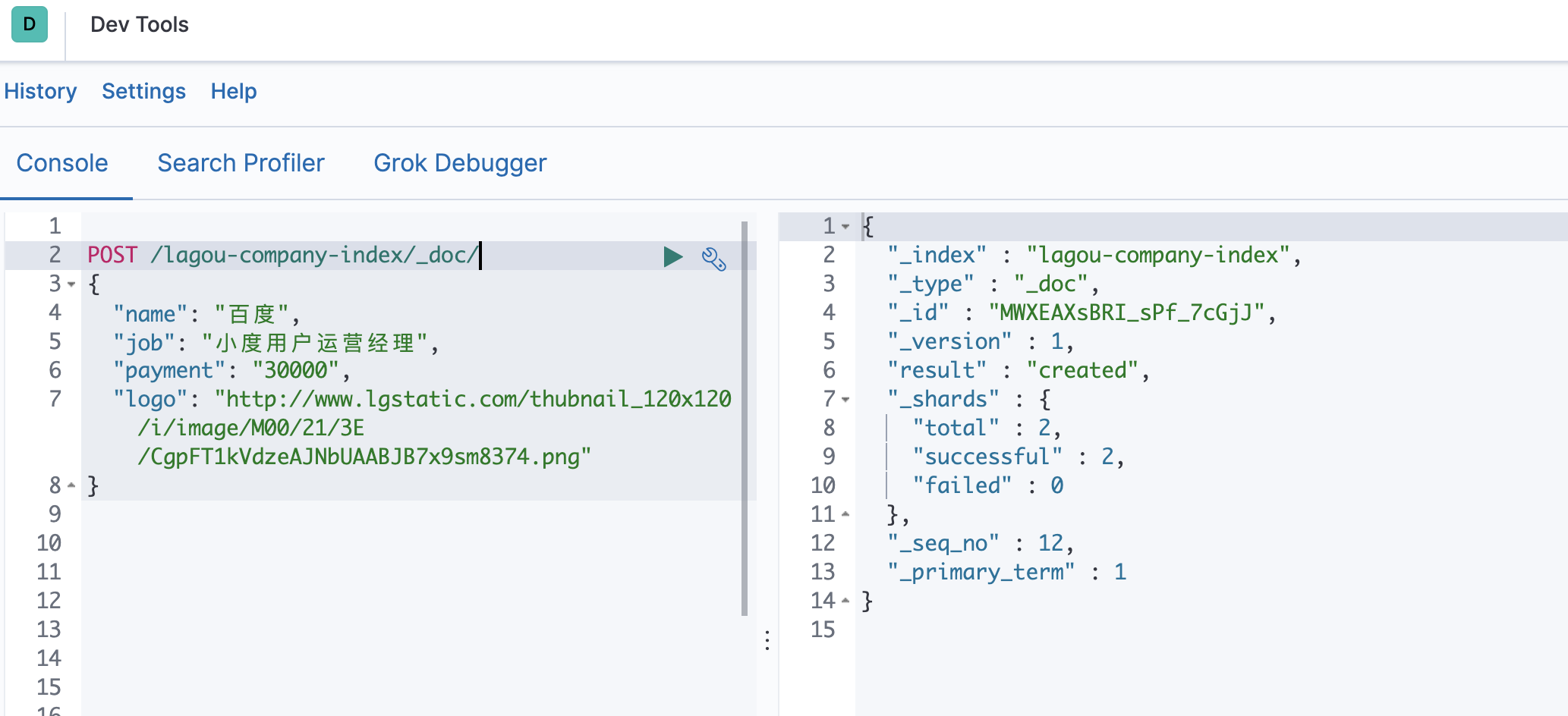
POST /索引名称/_doc { "field":"value" }POST /lagou-company-index/_doc/ { "name": "百度", "job": "小度用户运营经理", "payment": "30000", "logo": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm8374.png" }可以看到结果显示为: created ,代表创建成功。 另外,需要注意的是,在响应结果中有个 _id 字段,这个就 是这条文档数据的 唯一标识 ,这个_id作为唯一标示,这里是Elasticsearch帮我们随机生成的id。
- 新增文档(手动指定id)
- 查看单个文档
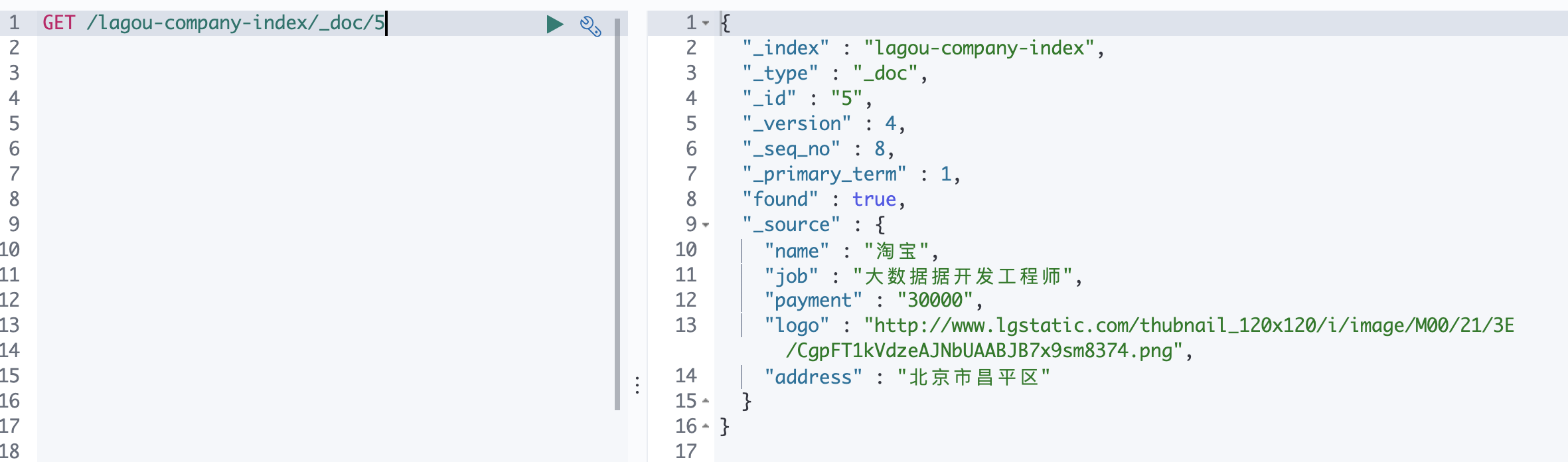
GET /索引名称/_doc/{id} # 示例 GET /lagou-company-index/_doc/1- 文档元数据解读

- 文档元数据解读
- 查看所有文档
POST /索引名称/_search { "query": { "match_all": {} } } #示例 POST /lagou-company-index/_search { "query": { "match_all": {} } } - _source定制返回结果
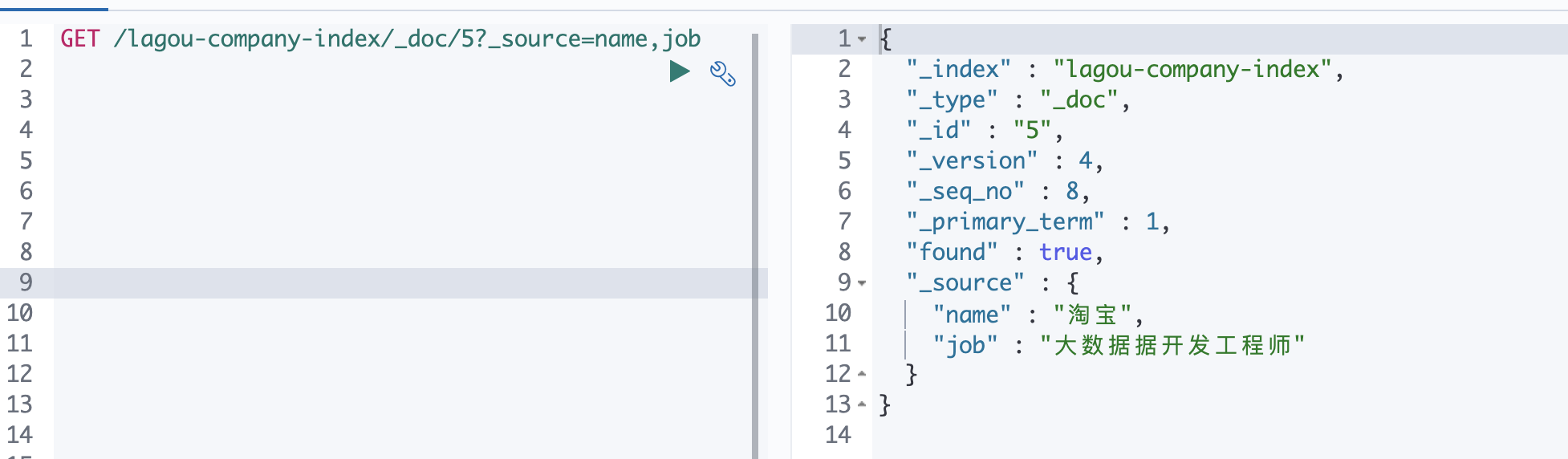 某些业务场景下,我们不需要搜索引擎返回source中的所有字段,可以使用source进行定制,如下,多个字段之间使
某些业务场景下,我们不需要搜索引擎返回source中的所有字段,可以使用source进行定制,如下,多个字段之间使
用逗号分隔GET /lagou-company-index/_doc/1?_source=name,job - 更新文档(全部更新)
把刚才新增的请求方式改为PUT(POST),就是修改了,不过修改必须指定id
- id对应文档存在,则修改
- id对应文档不存在,则新增
比如,我们把使用id为4,不存在,则应该是新增
示例
PUT /lagou-company-index/_doc/5 { "name": "百度", "job": "大数据据开发工程师", "payment": "30000", "logo": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm8374.png", "address": "北京市昌平区" } -
更新文档(局部更新) Elasticsearch可以使用PUT或者POST对文档进行更新(全部更新),如果指定ID的文档已经存在,则执行更新操作。
Elasticsearch执行更新操作的时候,Elasticsearch首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档 不会立即消失,但是你也无法访问,Elasticsearch会在你继续添加更多数据的时候在后台清理已经标记为删除状态的 文档。
- 全部更新,是直接把之前的老数据,标记为删除状态,然后,再添加一条更新的(使用PUT或者POST)
- 局部更新, 只是修改某个字段(使用POST)
POST /索引名/_update/{id} { "doc":{ "field":"value" } }示例
# 局部更新 POST /lagou-company-index/_update/5 { "doc": { "name": "淘宝" } } -
删除文档
- 根据id进行删除
DELETE /索引名/_doc/{id}示例
DELETE /lagou-company-index/_doc/3 - 根据查询条件进行删除
POST /索引库名/_delete_by_query { "query": { "match": { "字段名": "搜索关键字" } } }示例
#查询name字段百度关键字的doc POST /lagou-company-index/_search { "query": { "match": { "name": "百度" } } } #删除name字段百度关键字的doc POST /lagou-company-index/_delete_by_query { "query": { "match": { "name": "百度" } } } - 删除所有文档
POST /索引名/_delete_by_query { "query": { "match_all": {} } }
- 根据id进行删除
-
Query DSL
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/query-dsl.html
Elasticsearch提供了基于JSON的完整查询DSL(Domain Specific Language 特定域的语言)来定义查询。将查询 DSL视为查询的AST(抽象语法树),它由两种子句组成:
- 叶子查询子句 在特定域中寻找特定的值,如 match,term或 range查询。
- 复合查询子句包装其他叶子查询或复合查询,并用于以逻辑方式组合多个查询(例如 bool或 dis_max查询),或更改其行为(例如 constant_score查询)。
我们在使用ElasticSearch的时候,避免不了使用DSL语句去查询,就像使用关系型数据库的时候要学会SQL语法一 样。
- 基本语法
POST /索引库名/_search { "query": { "查询类型": { "查询条件": "查询条件值" } } }这里的query代表一个查询对象,里面可以有不同的查询属性
- 查询类型:
- 例如: match_all , match , term , range 等等
-
查询条件:查询条件会根据类型的不同,写法也有差异,后面详细讲解
- 查询所有(match_all query)
POST /lagou-company-index/_search { "query": { "match_all": {} } }- query :代表查询对象
- match_all :代表查询所有
结果
- took:查询花费时间,单位是毫秒
- time_out:是否超时
- _shards:分片信息
- hits:搜索结果总览对象
- total:搜索到的总条数
- max_score:所有结果中文档得分的最高分
- hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
- _index:索引库
- _type:文档类型
- _id:文档id
- _score:文档得分
- _source:文档的源数据
-
全文搜索(full-text query) 全文搜索能够搜索已分析的文本字段,如电子邮件正文,商品描述等。使用索引期间应用于字段的同一分词器处理查
询字符串。全文搜索的分类很多 几个典型的如下:- 数据准备
PUT /lagou-property { "settings": {}, "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word" }, "images": { "type": "keyword" }, "price": { "type": "float" } } } } POST /lagou-property/_doc/ { "title": "小米电视4A", "images": "http://image.lagou.com/12479122.jpg", "price": 4288 } POST /lagou-property/_doc/ { "title": "小米手机", "images": "http://image.lagou.com/12479122.jpg", "price": 2288 } POST /lagou-property/_doc/ { "title": "华为手机", "images": "http://image.lagou.com/12479122.jpg", "price": 6588 } -
匹配搜索(match query) match
全文查询的标准查询,
* 需要指定字段名,
* 输入文本会进行分词,
比如”hello elasticsearch”会进行拆分为hello和elasticsearch,然后匹配,如果字段中包含hello或者 elasticsearch,或者都包含的结果都会被查询出来,也就是说match是一个部分匹配的模糊查询。查询条件相 对来说比较宽松match queries 接收 text/numerics/dates, 对它们进行分词分析, 再组织成一个boolean查询。可通过operator 指定 bool组合操作(or、and 默认是 or )。
-
or关系 or关系
match 类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系POST /lagou-property/_search { "query": { "match": { "title": "小米电视4A" } } }在上面的案例中,不仅会查询到电视,而且与小米相关的都会查询到,多个词之间是 or 的关系。
POST _analyze { "analyzer": "ik_max_word", "text":"小米电视4A" } -
and关系 某些情况下,我们需要更精确查找,我们希望这个关系变成 and ,可以这样做:
POST /lagou-property/_search { "query": { "match": { "title": { "query": "小米电视4A", "operator": "and" } } } }上面的operator 也可以换成or
-
-
短语搜索(match phrase query) match_phrase是分词的,text也是分词的。match_phrase的分词结果必须在text字段分词中都包含,而且顺序必须 相同,而且必须都是连续的
GET /lagou-property/_search { "query": { "match_phrase": { "title": "小米电视" } } } #下面的代码不能搜索到 GET /lagou-property/_search { "query": { "match_phrase": { "title": "电视小米" } } } GET /lagou-property/_search { "query": { "match_phrase": { "title": "小米4A" } } } -
query_string 查询 该查询与match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
Query String Query提供了无需指定某字段而对文档全文进行匹配查询的一个高级查询,同时也可以指定在哪些字段上进行匹配。
GET /lagou-property/_search { "query": { "match_all": {} } } # 默认 和 指定字段 GET /lagou-property/_search { "query": { "query_string": { "query": "2288" } } } # 不能找到含2288的标题 GET /lagou-property/_search { "query": { "query_string": { "query": "2288", "default_field": "title" } } } # 逻辑查询 OR GET /lagou-property/_search { "query": { "query_string": { "query": "手机 OR 小米", "default_field": "title" } } } # 逻辑查询 AND GET /lagou-property/_search { "query": { "query_string": { "query": "手机 AND 小米", "default_field": "title" } } } # 模糊查询,~1允许错一个字 GET /lagou-property/_search { "query": { "query_string": { "query": "大米~1", "default_field": "title" } } } # 多字段支持,注意数据类型,并列的fields最好是同种数据类型 GET /lagou-property/_search { "query": { "query_string": { "query": "2288", "fields": ["title","price"] } } } -
多字段匹配搜索(multi match query) 如果你需要在多个字段上进行文本搜索,可用multi_match 。multi_match在 match的基础上支持对多个字段进行文本查询。
GET /lagou-property/_search { "query": { "multi_match": { "query": "小米4A", "fields": [ "title", "images" ] } } }
- 数据准备
-
词条级搜索(term-level queries) 可以使用term-level queries根据结构化数据中的精确值查找文档。结构化数据的值包括日期范围、IP地址、价格或产品ID。
与全文查询不同,term-level queries不分析搜索词。相反,词条与存储在字段级别中的术语完全匹配。- 数据准备
PUT /book { "settings": {}, "mappings": { "properties": { "description": { "type": "text", "analyzer": "ik_max_word" }, "name": { "type": "text", "analyzer": "ik_max_word" }, "price": { "type": "float" }, "timestamp": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" } } } } PUT /book/_doc/1 { "name": "lucene", "description": "Lucene Core is a Java library providing powerful indexing and search features, as well as spellchecking, hit highlighting and advanced analysis/tokenization capabilities. The PyLucene sub project provides Python bindings for Lucene Core. ", "price": 100.45, "timestamp": "2020-08-21 19:11:35" } PUT /book/_doc/2 { "name": "solr", "description": "Solr is highly scalable, providing fully fault tolerant distributed indexing, search and analytics. It exposes Lucenes features through easy to use JSON/HTTP interfaces or native clients for Java and other languages.", "price": 320.45, "timestamp": "2020-07-21 17:11:35" } PUT /book/_doc/3 { "name": "Hadoop", "description": "The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.", "price": 620.45, "timestamp": "2020-08-22 19:18:35" } PUT /book/_doc/4 { "name": "ElasticSearch", "description": "Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎, 基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的 企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在 Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显 示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。", "price": 999.99, "timestamp": "2020-08-15 10:11:35" } - 词条搜索(term query)
term 查询用于查询指定字段包含某个词项的文档
POST /book/_search { "query": { "term": { "name": { "value": "solr" } } } } -
词条集合搜索(terms query) terms 查询用于查询指定字段包含某些词项的文档
POST /book/_search { "query": { "terms": { "name": [ "solr", "elasticsearch" ] } } } - 范围搜索(range query)
- gte:大于等于
- gt:大于
- lte:小于等于
- lt:小于
- boost:查询权重:在多条件组合查询时,可以手动控制每个条件的比重
POST /book/_search { "query": { "range": { "price": { "gte": 10, "lte": 200, "boost": 2.0 } } } } POST /book/_search { "query": { "range": { "timestamp": { "gte": "18/08/2020", "lte": "2021", "format": "dd/MM/yyyy||yyyy" } } } } -
不为空搜索(exists query) 查询指定字段值不为空的文档。相当 SQL 中的 column is not null
- 词项前缀搜索(prefix query)
GET /book/_search { "query": { "prefix": { "name": { "value": "el" } } } } -
正则搜索(regexp query) regexp允许使用正则表达式进行term查询.注意regexp如果使用不正确,会给服务器带来很严重的性能压力。比如.* 开头的查询,将会匹配所有的倒排索引中的关键字,这几乎相当于全表扫描,会很慢。因此如果可以的话,最好在使 用正则前,加上匹配的前缀。
GET /book/_search { "query": { "regexp": { "name": "s.*" } } } # 加权重 GET /book/_search { "query": { "regexp": { "name": { "value": "s.*", "boost":1.2 } } } } - 模糊搜索(fuzzy query)
GET /book/_search { "query": { "fuzzy": { "name": "sol" } } } GET /book/_search { "query": { "fuzzy": { "name": "so" } } } # 把模糊的力度调大 GET /book/_search { "query": { "fuzzy": { "name": { "value": "so", "fuzziness": 2 } } } } GET /book/_search { "query": { "fuzzy": { "name": { "value": "sorl", "fuzziness": 0.5 } } } } GET /book/_search { "query": { "fuzzy": { "name": { "value": "sorl", "fuzziness": 2 } } } } - ids搜索(id集合查询)
GET /book/_search { "query": { "ids": { "values": ["1","3"] } } }
- 数据准备
-
复合搜索(compound query)
- 布尔搜索(bool query)
bool 查询用bool操作来组合多个查询子句为一个查询。 可用的关键字:
- must:必须满足
- filter:必须满足,对集合包含/排除的简单检查,计算速度非常快,不参与、不影响评分
- should:或
- must_not:必须不满足,在filter上下文中执行,不参与、不影响评分
# description中必须包含java, # price必须满足大于100小于1000, # name字段可以是lucene或者是solr中的一种即可, # 时间满足。。。。 POST /book/_search { "query": { "bool": { "filter": { "match": { "description": "java" } }, "must": [ { "range": { "price": { "gte": 100, "lte": 1000 } } }, { "bool": { "should": [ { "term": { "name": "lucene" } }, { "term": { "name": "solr" } } ] } } ], "must_not": [ { "range": { "timestamp": { "gte": "18/08/2020", "lte": "2021", "format": "dd/MM/yyyy||yyyy" } } } ] } } }
- 布尔搜索(bool query)
bool 查询用bool操作来组合多个查询子句为一个查询。 可用的关键字:
- Filter DSL
Elasticsearch中的所有的查询都会触发相关度得分的计算。对于那些不需要相关度得分的场景下,Elasticsearch以过 滤器的形式提供了另一种查询功能,过滤器在概念上类似于查询,但是它们有非常快的执行速度,执行速度快主要有 以下两个原因:
- 过滤器不会计算相关度的得分,所以它们在计算上更快一些。
- 过滤器可以被缓存到内存中,这使得在重复的搜索查询上,其要比相应的查询快出许多。
为了理解过滤器,可以将一个查询(像是match_all,match,bool等)和一个过滤器结合起来。我们以范围过滤器 为例,它允许我们通过一个区间的值来过滤文档。这通常被用在数字和日期的过滤上。 下面这个例子使用一个被过 滤的查询,其返回price值是在200到1000之间(闭区间)的书。
POST /book/_search { "query": { "bool": { "must": { "match_all": {} }, "filter": { "range": { "price": { "gte": 200, "lte": 1000 } } } } } }分解上面的例子,被过滤的查询包含一个match_all查询(查询部分)和一个过滤器(filter部分)。
可以在查询部分中放入其他查询,在filter部分放入其它过滤器。在上面的应用场景中,由于所有的在这个范围之内 的文档都是平等的(或者说相关度都是一样的),没有一个文档比另一个文档更相关,所以这个时候使用范围过滤器 就非常合适了。通常情况下,要决定是使用过滤器还是使用查询,你就需要问自己是否需要相关度得分。如果相关度 是不重要的,使用过滤器,否则使用查询。查询和过滤器在概念上类似于SELECT WHERE语句。 -
排序 相关性评分排序
默认情况下,返回的结果是按照 相关性 进行排序的——最相关的文档排在最前。 首先看看 sort 参数以及如 何使用它。为了按照相关性来排序,需要将相关性表示为一个数值。在 Elasticsearch 中, 相关性得分 由一个浮点数进行 表示,并在搜索结果中通过 _score 参数返回, 默认排序是 _score 降序,按照相关性评分升序排序如下
POST /book/_search { "query": { "match": { "description": "solr" } } } # 按分数升序 POST /book/_search { "query": { "match": { "description": "solr" } }, "sort": [ { "_score": { "order": "asc" } } ] } # 字段值排序 POST /book/_search { "query": { "match_all": {} } , "sort": [ { "price": { "order": "desc" } } ] } # 多级排序 假定我们想要结合使用 price和 timestamp(时间) 进行查询,并且匹配的结果首先按照价格排序, 然后按照相关性得分排序: POST /book/_search { "query": { "match_all": {} }, "sort": [ { "timestamp": { "order": "desc" } }, { "price": { "order": "desc" } } ] } -
分页 Elasticsearch中实现分页的语法非常简单:
POST /book/_search { "query": { "match_all": {} }, "sort": [ { "price": { "order": "desc" } } ], "size": 2, "from": 0 } POST /book/_search { "query": { "match_all": {} }, "sort": [ { "price": { "order": "desc" } } ], "size": 2, "from": 2 }size:每页显示多少条
from:当前页起始索引, int start = (pageNum - 1) * size -
高亮 Elasticsearch中实现高亮的语法比较简单:
在使用match查询的同时,加上一个highlight属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
POST /book/_search { "query": { "match": { "name": "elasticsearch" } }, "highlight": { "pre_tags": "<font color='pink'>", "post_tags": "</font>", "fields": [ { "name": {} } ] } } # fields内写需要高亮的字段 POST /book/_search { "query": { "query_string": { "query": "elasticsearch" } }, "highlight": { "pre_tags": "<font color='pink'>", "post_tags": "</font>", "fields": [ { "name": {} }, { "description": {} } ] } } -
文档批量操作(bulk 和 mget)
-
mget 批量查询 单条查询 GET /test_index/_doc/1,如果查询多个id的文档一条一条查询,网络开销太大。
GET /_mget { "docs": [ { "_index": "book", "_id": 1 }, { "_index": "book", "_id": 2 } ] } # 或如下写法,同一文档批量操作 GET /book/_mget { "docs": [ { "_id": 1 }, { "_id": 2 } ] } # 使用query POST /book/_search { "query": { "ids": { "values": ["1","2"] } } } -
bulk 批量增删改 Bulk 操作解释将文档的增删改查一些列操作,通过一次请求全都做完。减少网络传输次数。
语法:POST /_bulk {"action": {"metadata"}} {"data"}POST /_bulk {"delete":{"_index":"book","_id":"1"}} {"create":{"_index":"book","_id":"5"}} {"name":"test14","price":100.99} {"update":{"_index":"book","_id":"2"}} {"doc":{"name":"test"}}功能:
- delete:删除一个文档,只要1个json串就可以, 删除的批量操作不需要请求体
- create:相当于强制创建 PUT /index/type/id/_create
- index:普通的put操作,可以是创建文档,也可以是全量替换文档
- update:执行的是局部更新partial update操作
格式:每个json不能换行。相邻json必须换行。
隔离:每个操作互不影响。操作失败的行会返回其失败信息。实际用法:bulk请求一次不要太大,否则一下积压到内存中,性能会下降。所以,一次请求几千个操作、大小在几M 正好。 bulk会将要处理的数据载入内存中,所以数据量是有限的,最佳的数据量不是一个确定的数据,它取决于你 的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。 一般建议是1000-5000个文档,大小建议是5- 15MB,默认不能超过100M,可以在es的配置文件(ES的config下的elasticsearch.yml)中配置。
http.max_content_length: 10mb
-
-
聚合分析
-
聚合介绍
 聚合分析是数据库中重要的功能特性,完成对一个查询的数据集中数据的聚合计算,如:找出某字段(或计算表达式 的结果)的最大值、最小值,计算和、平均值等。Elasticsearch作为搜索引擎兼数据库,同样提供了强大的聚合分析 能力。
聚合分析是数据库中重要的功能特性,完成对一个查询的数据集中数据的聚合计算,如:找出某字段(或计算表达式 的结果)的最大值、最小值,计算和、平均值等。Elasticsearch作为搜索引擎兼数据库,同样提供了强大的聚合分析 能力。对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合 metric 而关系型数据库中除了有聚合 函数外,还可以对查询出的数据进行分组group by,再在组上进行指标聚合。在 ES 中group by 称为分桶,桶聚合 bucketing
Elasticsearch聚合分析语法 在查询请求体中以aggregations节点按如下语法定义聚合分析
aggregations 也可简写为 aggs
-
指标聚合 max min sum avg value_count
# 查询所有书中最贵的 # size : 0, 指查看结果 POST /book/_search { "size": 0, "aggs": { "max_price": { "max": { "field": "price" } } } } # 文档计数count # 统计price大于100的文档数量 POST /book/_count { "query": { "range": { "price": { "gte": 100 } } } } #统计条数(value_count统计某个字段有值的数量) POST /book/_search { "size": 0, "aggs": { "book_nums": { "value_count": { "field": "_id" } } } } POST /book/_search?size=0 { "aggs": { "book_nums": { "value_count": { "field": "_id" } } } } # cardinality值去重计数 基数, count distinct POST /book/_search?size=0 { "aggs": { "_id_count": { "cardinality": { "field": "_id" } }, "price_count": { "cardinality": { "field": "price" } } } } # stats 统计 count max min avg sum 5个值 POST /book/_search { "size": 0, "aggs": { "price_stats": { "stats": { "field": "price" } } } } # Extended stats # 高级统计,比stats多4个统计结果: 平方和、方差、标准差、平均值加/减两个标准差的区间 POST /book/_search { "size": 0, "aggs": { "price_stats": { "extended_stats": { "field": "price" } } } } # Percentiles 占比百分位对应的值统计 POST /book/_search?size=0 { "aggs": { "price_percentiles": { "percentiles": { "field": "price" } } } } # 指定分位值 POST /book/_search?size=0 { "aggs": { "price_percentiles": { "percentiles": { "field": "price", "percents": [ 75, 95, 99 ] } } } } #Percentiles rank 统计值小于等于指定值的文档占比 #统计price小于100,200的文档的占比 POST /book/_search?size=0 { "aggs": { "gge_perc_rank": { "percentile_ranks": { "field": "price", "values": [ 100, 200 ] } } } } -
桶聚合 Bucket Aggregations,桶聚合。
它执行的是对文档分组的操作(与sql中的group by类似),把满足相关特性的文档分到一个桶里,即桶分,输出结 果往往是一个个包含多个文档的桶(一个桶就是一个group)
bucket:一个数据分组
metric:对一个数据分组执行的统计POST /book/_search?size=0 { "aggs": { "group_by_price": { "range": { "field": "price", "ranges": [ { "from": 0, "to": 200 }, { "from": 200, "to": 400 }, { "from": 400, "to": 1000 } ] }, "aggs": { "average_price": { "avg": { "field": "price" } } } } } } # 实现having 效果 POST /book/_search?size=0 { "aggs": { "group_by_price": { "range": { "field": "price", "ranges": [ { "from": 0, "to": 200 }, { "from": 200, "to": 400 }, { "from": 400, "to": 1000 } ] }, "aggs": { "average_price": { "avg": { "field": "price" } }, "having":{ "bucket_selector": { "buckets_path": { "avg_price":"average_price" }, "script": { "source": "params.avg_price >= 200" } } } } } } }
-
Java API操作ES
官网说明
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.3/java-rest-overview.html
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.3/java-rest-high.html
- 准备工作
导入pom
<dependencies> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.3.0</version> <exclusions> <exclusion> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>7.3.0</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId> <version>6.14.3</version> <scope>test</scope> </dependency> </dependencies>resource目录下创建:log4j2.xml
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{yyyy-mm-dd HH:mm:ss} [%t] %-5p %c{1}:%L - %msg%n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers> </Configuration> - 创建Client
import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; public class JESDemo { RestHighLevelClient client; @Before public void init(){ RestHighLevelClient highLevelClient = new RestHighLevelClient(RestClient.builder( new HttpHost("centos7-1", 9200, "http"), new HttpHost("centos7-2", 9200, "http"), new HttpHost("centos7-3", 9200, "http") )); client = highLevelClient; } @After public void destory() { if (client != null) { try { client.close(); } catch (IOException e) { e.printStackTrace(); } } } } - 创建索引
//创建索引 @Test public void createIndex() { CreateIndexRequest es_test = new CreateIndexRequest("es_test"); try { CreateIndexResponse response = client.indices().create(es_test, RequestOptions.DEFAULT); System.out.println(response.isAcknowledged()); } catch (IOException e) { e.printStackTrace(); } } @Test public void createIndexWithMeta() { CreateIndexRequest es_test = new CreateIndexRequest("es_test"); String source = "{\n" + " \"mappings\": {\n" + " \"properties\": {\n" + " \"name\": {\n" + " \"type\": \"text\",\n" + " \"analyzer\": \"ik_max_word\"\n" + " },\n" + " \"job\": {\n" + " \"type\": \"text\",\n" + " \"analyzer\": \"ik_max_word\"\n" + " },\n" + " \"logo\": {\n" + " \"type\": \"keyword\",\n" + " \"index\": \"false\"\n" + " },\n" + " \"payment\": {\n" + " \"type\": \"float\"\n" + " }\n" + " }\n" + " }\n" + "}"; es_test.source(source, XContentType.JSON); try { CreateIndexResponse response = client.indices().create(es_test, RequestOptions.DEFAULT); System.out.println(response.isAcknowledged()); } catch (IOException e) { e.printStackTrace(); } } - 删除索引
//remove索引 @Test public void deleteIndex(){ DeleteIndexRequest es_test_d = new DeleteIndexRequest("es_test"); AcknowledgedResponse response = null; try { response = client.indices().delete(es_test_d, RequestOptions.DEFAULT); System.out.println(response.isAcknowledged()); } catch (IOException e) { e.printStackTrace(); } } - 添加数据
// Documents @Test public void addDoc() { IndexRequest indexRequest = new IndexRequest(indexName); String source = "{\n" + " \"name\": \"腾讯\",\n" + " \"job\": \"大数据开发工程师\",\n" + " \"payment\": \"100000\",\n" + " \"logo\": \"http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm8374.png\",\n" + " \"address\": \"北京市昌平区\"\n" + "}"; indexRequest.source(source, XContentType.JSON); try { IndexResponse response = client.index(indexRequest, RequestOptions.DEFAULT); System.out.println(response.toString()); } catch (IOException e) { e.printStackTrace(); } } - 根据id查数据
@Test public void getDoc() { GetRequest getRequest = new GetRequest(indexName); getRequest.id("NmUsDHsBRI_sPf_7QWii"); try { GetResponse response = client.get(getRequest, RequestOptions.DEFAULT); System.out.println(response.toString()); } catch (IOException e) { e.printStackTrace(); } } - 查询所有
@Test public void getAllDoc() { SearchRequest searchRequest = new SearchRequest(); searchRequest.indices(indexName); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // do your search logic here sourceBuilder.query(QueryBuilders.matchAllQuery()); // set page sourceBuilder.from(1); sourceBuilder.size(2); searchRequest.source(sourceBuilder); try { SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT); System.out.println(response.toString()); } catch (IOException e) { e.printStackTrace(); } } - termQuery
//termquery @Test public void termQuery(){ SearchRequest searchRequest = new SearchRequest(); searchRequest.indices(indexName); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // do your search logic here // sourceBuilder.query(QueryBuilders.termQuery("name","百度")); sourceBuilder.query(QueryBuilders.termQuery("job","开发")); // ///////////////// searchRequest.source(sourceBuilder); try { SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT); System.out.println(response.toString()); } catch (IOException e) { e.printStackTrace(); } } - 返回结果过滤
@Test public void searchWithLimit(){ SearchRequest searchRequest = new SearchRequest(); searchRequest.indices(indexName); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // do your search logic here sourceBuilder.query(QueryBuilders.matchAllQuery()); // Just return the includes field in _source // 只返回需要的字段 String[] includes = new String[]{"name", "job"}; String[] excludes = new String[]{}; sourceBuilder.fetchSource(includes, excludes); // ///////////////// searchRequest.source(sourceBuilder); try { SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT); System.out.println(response.toString()); } catch (IOException e) { e.printStackTrace(); } } - 结果排序
// sort results @Test public void sortResults() { SearchRequest searchRequest = new SearchRequest(); searchRequest.indices(indexName); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // do your search logic here sourceBuilder.query(QueryBuilders.matchAllQuery()); // 对结果进行排序 sourceBuilder.sort("payment", SortOrder.DESC); String[] includes = new String[]{"job", "payment"}; String[] excludes = new String[]{}; sourceBuilder.fetchSource(includes, excludes); searchRequest.source(sourceBuilder); try { SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT); System.out.println(response.toString()); } catch (IOException e) { e.printStackTrace(); } } - 聚合分析
//聚合分析 //按照name分组,对组内计算一个sum的payment @Test public void groupByResults() { SearchRequest searchRequest = new SearchRequest(); searchRequest.indices(indexName); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // do your search logic here // group by name, sum(payment) TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms("name_group").field("name") .subAggregation(AggregationBuilders.sum("sum_payment").field("payment")); sourceBuilder.aggregation(aggregationBuilder); searchRequest.source(sourceBuilder); try { SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT); System.out.println(response.toString()); } catch (IOException e) { e.printStackTrace(); } // 用来分组的字段最好是keyword类型,不可分词,遇到下面这个报错也可以解决 /** * Elasticsearch exception [type=illegal_argument_exception, reason=Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead. * */ // resolution /** * PUT /es_test/_mapping { "properties": { "name": { "type": "text", "analyzer": "ik_max_word", "fielddata": true } } } */ // 不过这个结果不太理想,百、度、百度 都是一个分组 // The result /** * "aggregations":{"sterms#name_group":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"度","doc_count":2,"sum#sum_payment":{"value":60000.0}},{"key":"百","doc_count":2,"sum#sum_payment":{"value":60000.0}},{"key":"百度","doc_count":2,"sum#sum_payment":{"value":60000.0}},{"key":"腾讯","doc_count":1,"sum#sum_payment":{"value":100000.0}}]}}} */ }
Elasticsearch之原理剖析
-
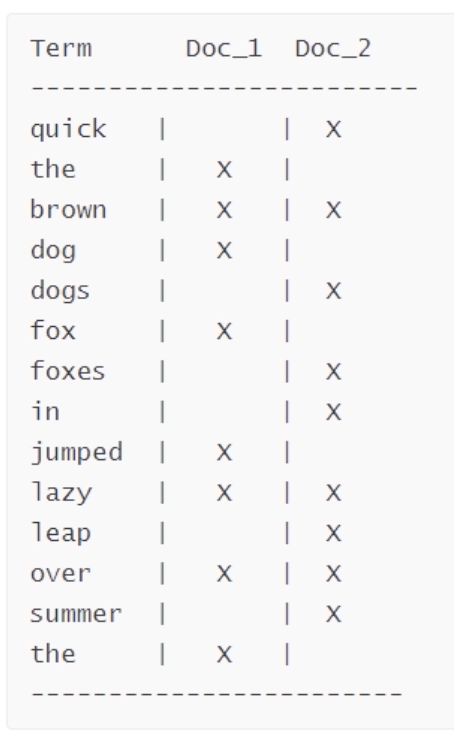
倒排索引
 Elasticsearch 使用一种称为倒排索引的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列 表构成,对于其中每个词,有一个包含它的文档列表。
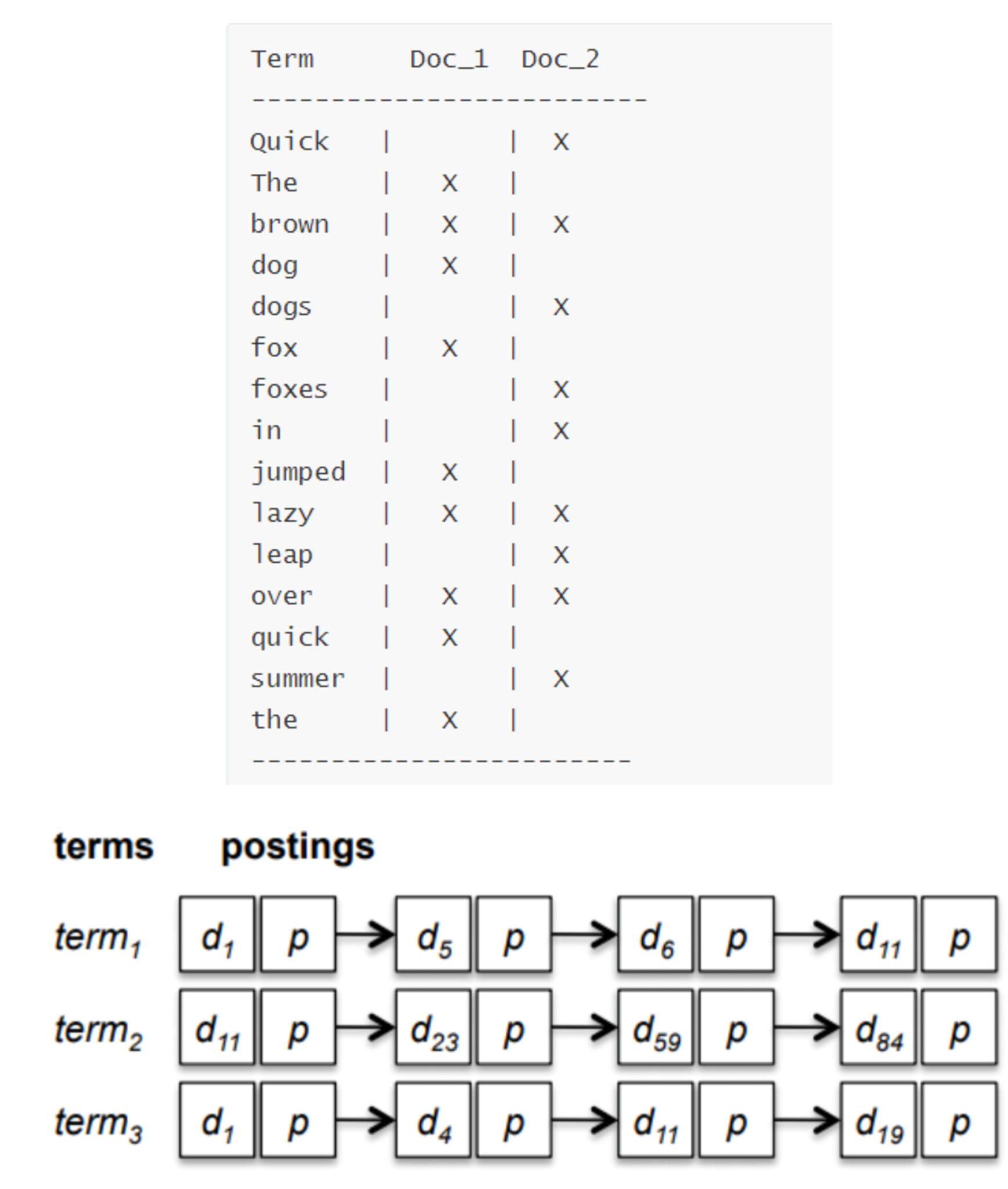
Elasticsearch 使用一种称为倒排索引的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列 表构成,对于其中每个词,有一个包含它的文档列表。例如,假设我们有两个文档,每个文档是如下内容:
1. The quick brown fox jumped over the lazy dog 2. Quick brown foxes leap over lazy dogs in summer要创建倒排索引,首先要将每个文档内容拆分成单独的词,创建一个包含所有不重复词条的排序列表,然后列出每个
词条出现在哪个文档。结果如上所示.现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
Term Doc_1 Doc_2 ------------------------- brown | X | X quick | X | ------------------------ Total | 2 | 1两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法,那 么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
-
读写流程解析
-
创建文档 向ES中添加一个文档对象,由于ES是分布式集群并且底层设计为一个索引有众多shard(分片),所以添加文档时需要 确定该文档属于哪个分片,确定的规则为:
shard = hash(routing) % number_of_primary_shards- routing是一个可变值,默认是文档的_id,也可以设置成一个自定义的值。
- routing通过hash函数生成一个数字,然后这个数字再除以number_of_primary_shards(主分片的数量)后得 到余数 。这个分布在0到number_of_primary_shards - 1之间的余数,就是我们所寻求的文档所在分片的位置。
- 写文档流程
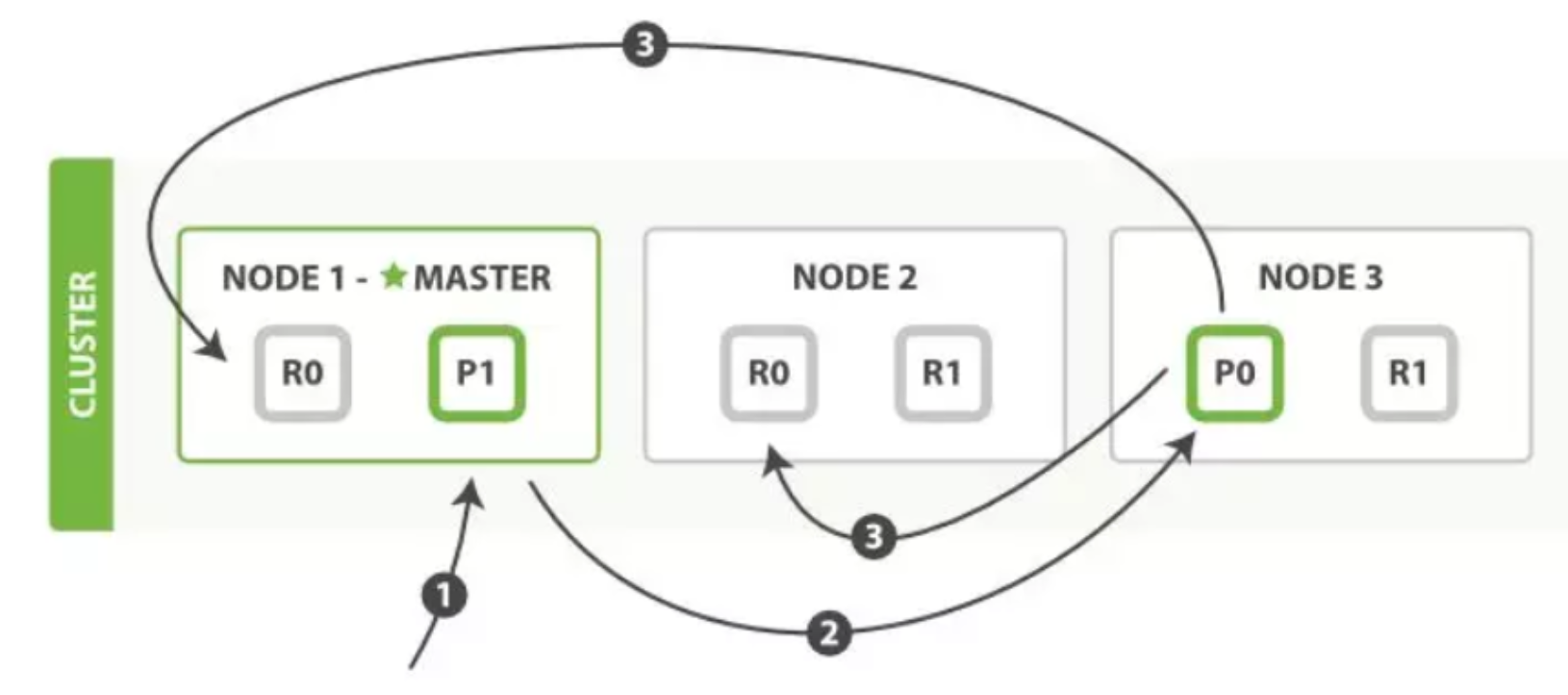 以官网的例子进行分析,从图中能看出一个集群由三个节点组成,有两个分片,两个副本。
以官网的例子进行分析,从图中能看出一个集群由三个节点组成,有两个分片,两个副本。
写操作必须在主分片上面完成之后,才能被复制到其他节点作为分片副本,新建、索引和删除请求都是写操作。- 客户端向master发送写入请求,该节点作为协调节点;
- 根据文档的_id确定分片,图中请求文档属于分片0,协调节点请求转到节点的主分片;
- 在节点3上执行请求,成功之后,节点3根据副本数将请求并行转到副本分片对应节点,一旦副本分片执行完 成,都向节点3报告成功,节点3将向协调节点报告成功,协调节点再向客户端报告成功。
客户端收到成功响应时,则变更操作是安全的。
-
读文档流程 一个搜索请求必须询问请求的索引中所有分片的某个副本来进行匹配。假设一个索引有5个主分片,每个主分片有一 个副本分片,共10分片,一次搜索请求会由5个分片来共同完成,他们可能是主分片,也可能是副分片。也就是说, 一次搜索请求只会命中所有分片副本中的一个。
一次检索流程主要分为两个阶段:- Query阶段
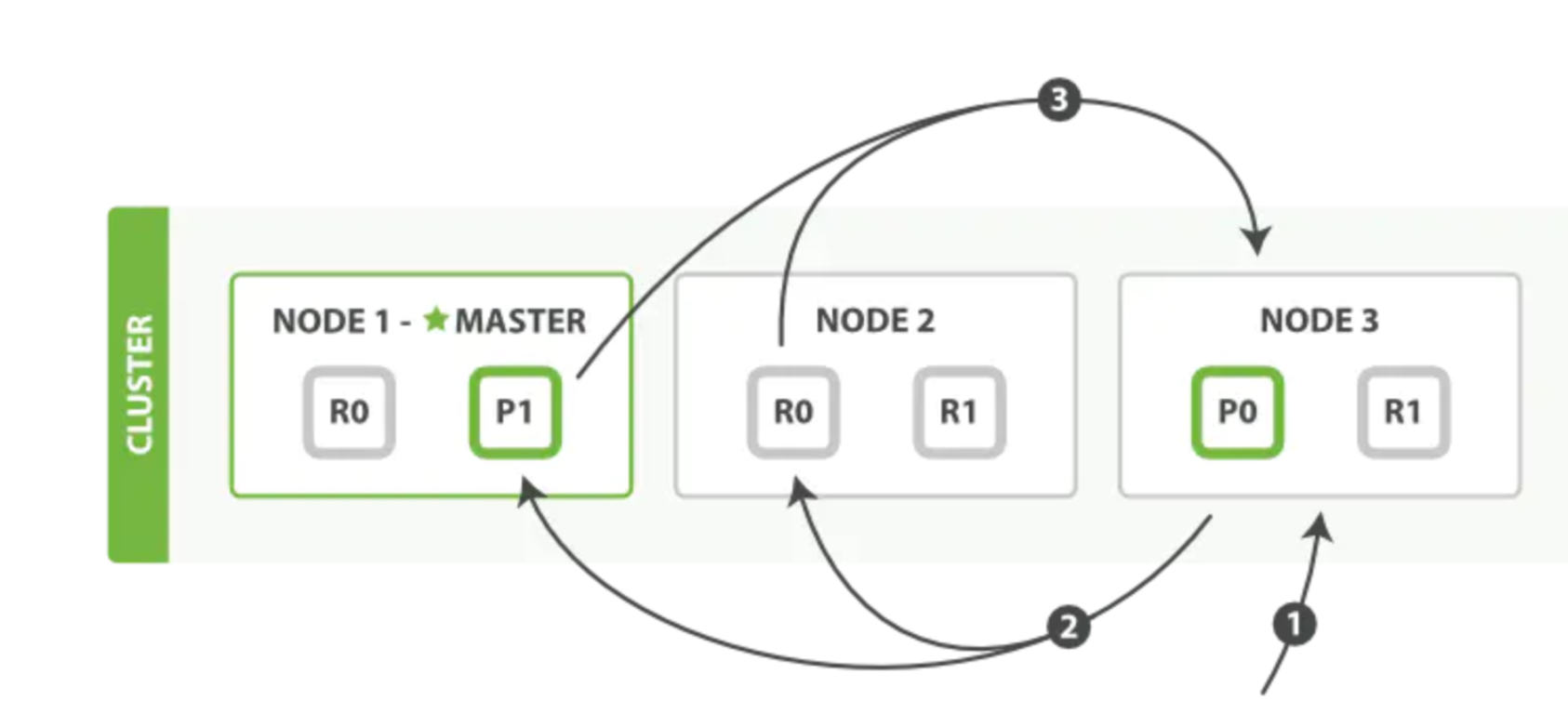
- 客户端发送search请求到NODE3。
- NODE3将查询请求转发到索引的每个主分片或副分片中。
- 每个分片在本地执行查询,并使用本地的Term/Docuemnt Frequency信息进行打分,添加结果到大小为from+size的本地优先队列中。
- 每个分片返回各自优先队列中所有文档的ID和排序值给协调节点,协调节点合并这些值到自己的优先队列中,产生一个全局排序后的列表。
- Fetch阶段
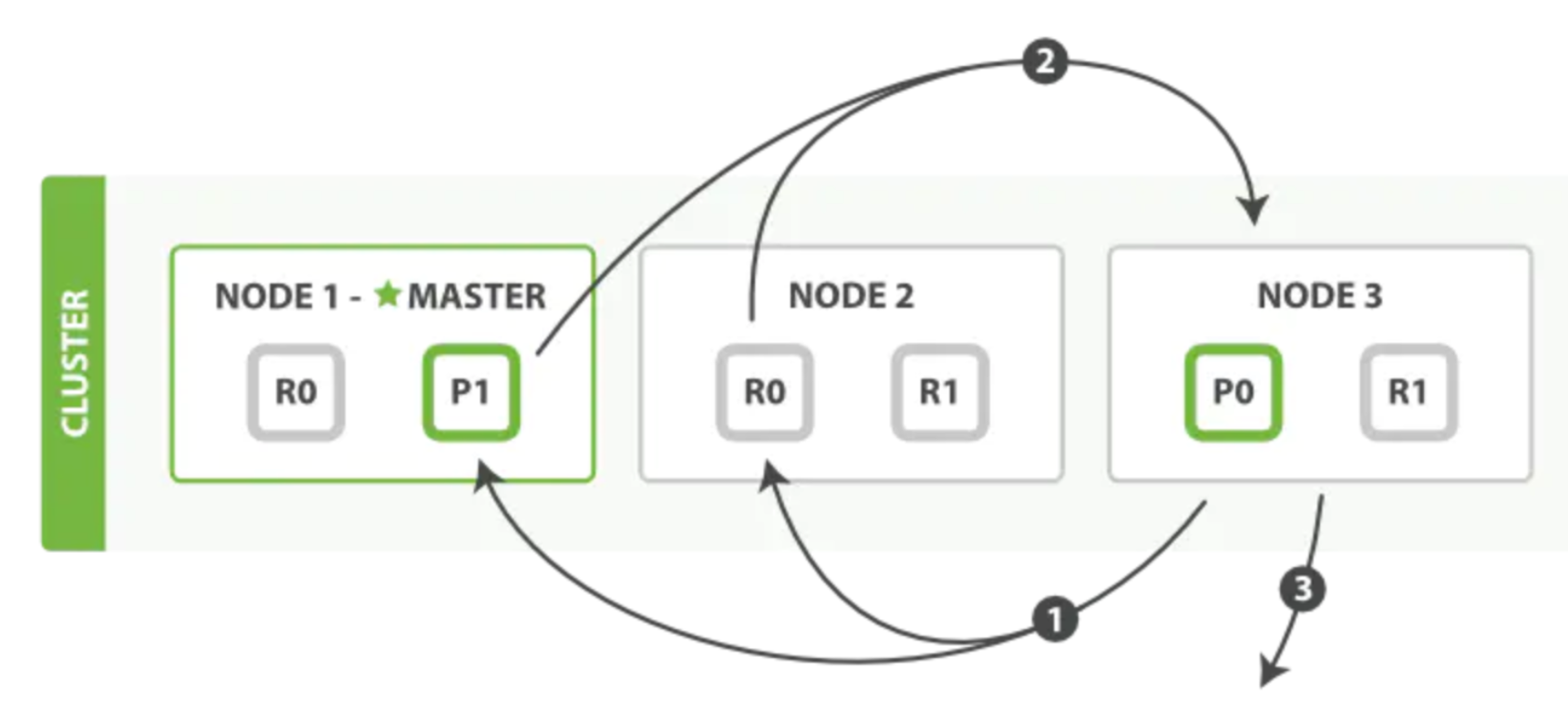
- 协调节点向相关NODE发送GET请求。
- 分片所在节点向协调节点返回数据。
- 协调节点等待所有文档被取得,然后返回给客户端。
分片所在节点在返回文档数据时,处理有可能出现的 _source字段和高亮参数
- Query阶段
-
-
索引文档写入和近实时搜索原理
-
基本概念
-
Segments in Lucene
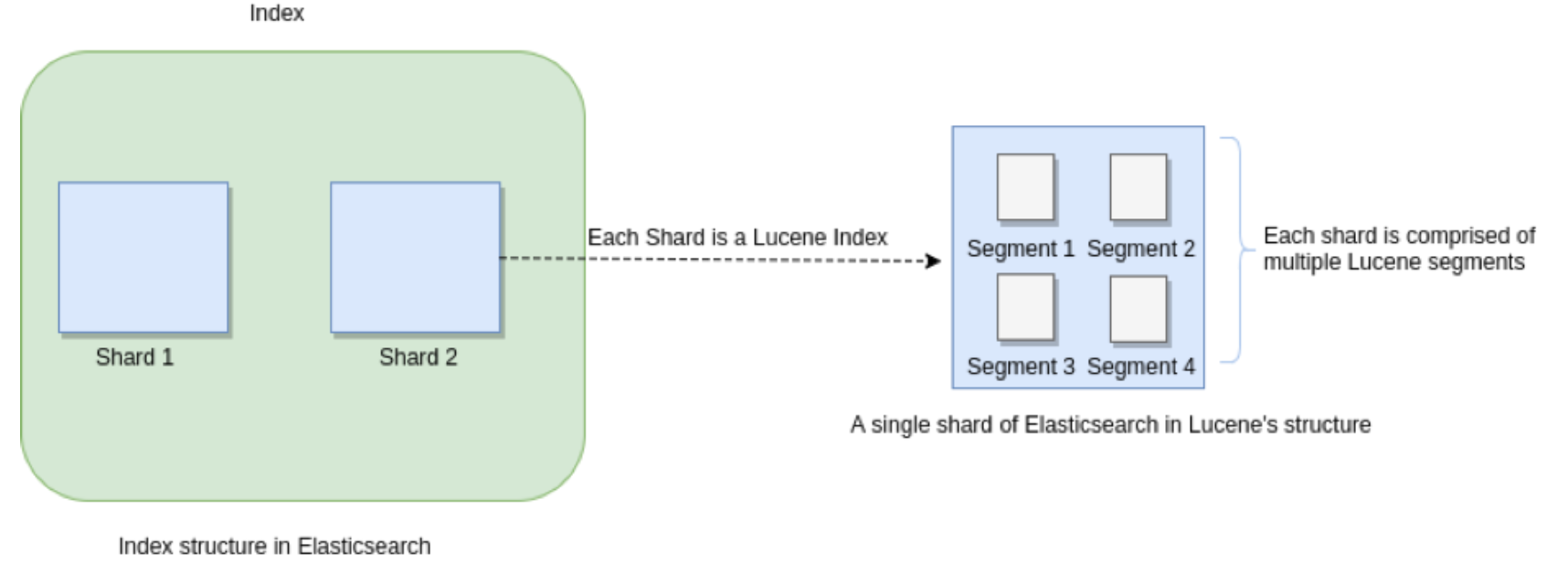 众所周知,Elasticsearch 存储的基本单元是 , ES 中一个 Index 可能分为多个 shard, 事实上每个 shard 都 是一个 Lucence 的 Index,并且每个 Lucence Index 由多个 Segment 组成, 每个 Segment 事实上是一些倒排索引 的集合, 每次创建一个新的 Document , 都会归属于一个新的 Segment, 而不会去修改原来的 Segment 。且每次 的文档删除操作,会仅仅标记 Segment 中该文档为删除状态, 而不会真正的立马物理删除, 所以说 ES 的 index 可 以理解为一个抽象的概念。
众所周知,Elasticsearch 存储的基本单元是 , ES 中一个 Index 可能分为多个 shard, 事实上每个 shard 都 是一个 Lucence 的 Index,并且每个 Lucence Index 由多个 Segment 组成, 每个 Segment 事实上是一些倒排索引 的集合, 每次创建一个新的 Document , 都会归属于一个新的 Segment, 而不会去修改原来的 Segment 。且每次 的文档删除操作,会仅仅标记 Segment 中该文档为删除状态, 而不会真正的立马物理删除, 所以说 ES 的 index 可 以理解为一个抽象的概念。 -
Translog-Hbase WAL(Write Ahead Log:预写入日志)
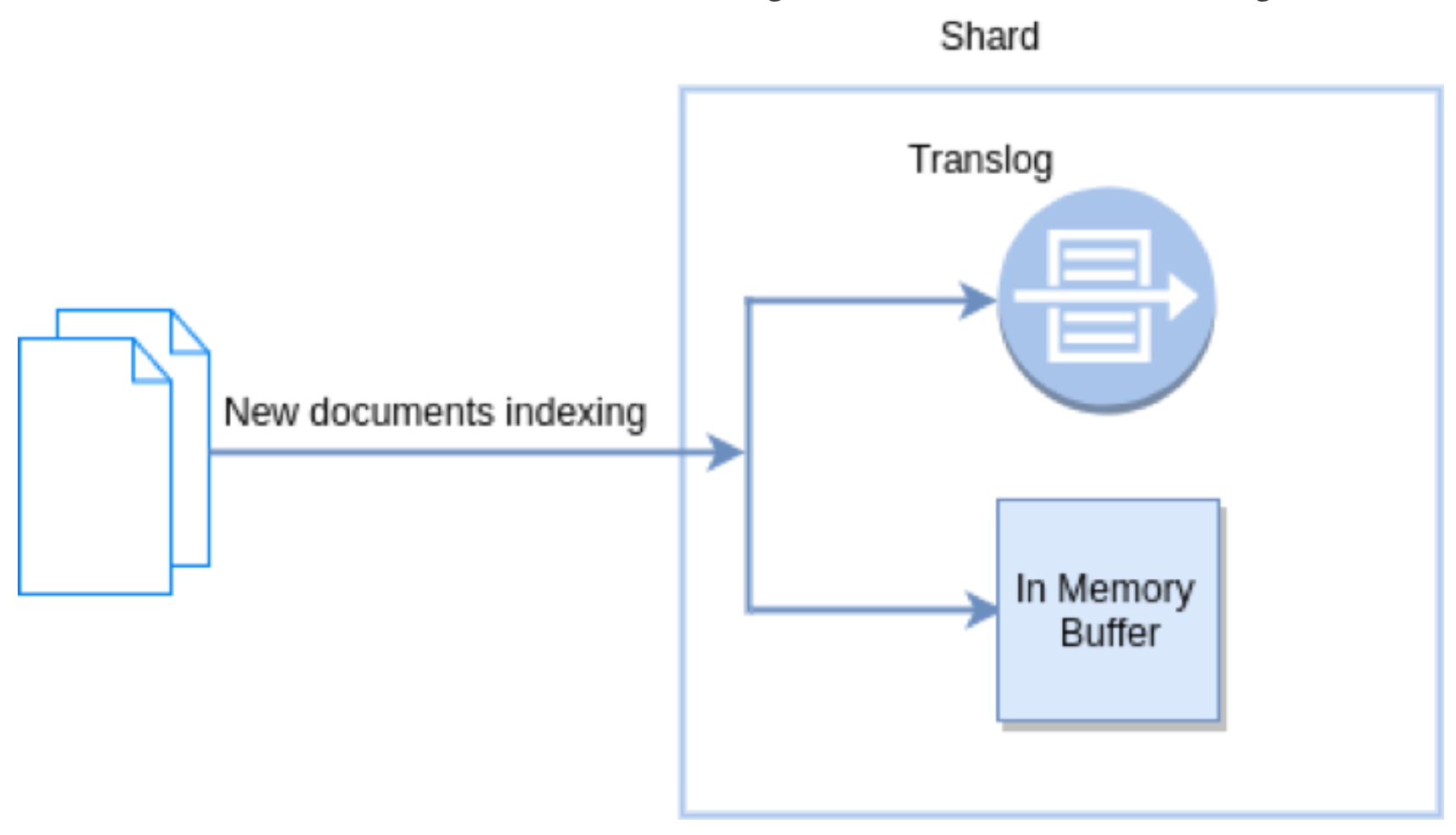 新文档被索引意味着文档会被首先写入内存 buffer 和 translog 文件。每个 shard 都对应一个 translog 文件
新文档被索引意味着文档会被首先写入内存 buffer 和 translog 文件。每个 shard 都对应一个 translog 文件 -
Refresh in Elasticsearch
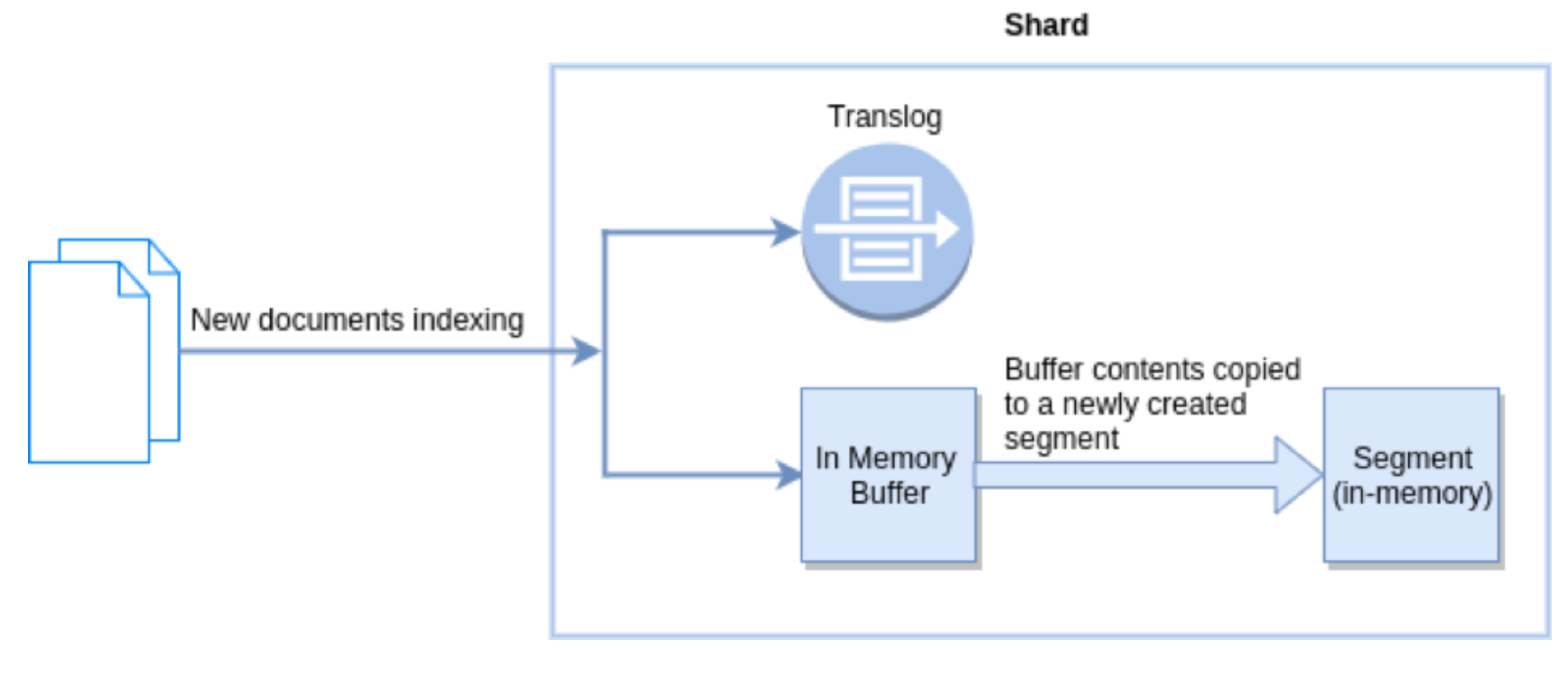 在 Elasticsearch 中, 操作默认每秒执行一次, 意味着将内存 buffer 的数据写入到一个新的 Segment 中,这个时候索引变成了可被检索的。写入新Segment后 会清空内存buffer。
在 Elasticsearch 中, 操作默认每秒执行一次, 意味着将内存 buffer 的数据写入到一个新的 Segment 中,这个时候索引变成了可被检索的。写入新Segment后 会清空内存buffer。 -
Flush in Elasticsearch
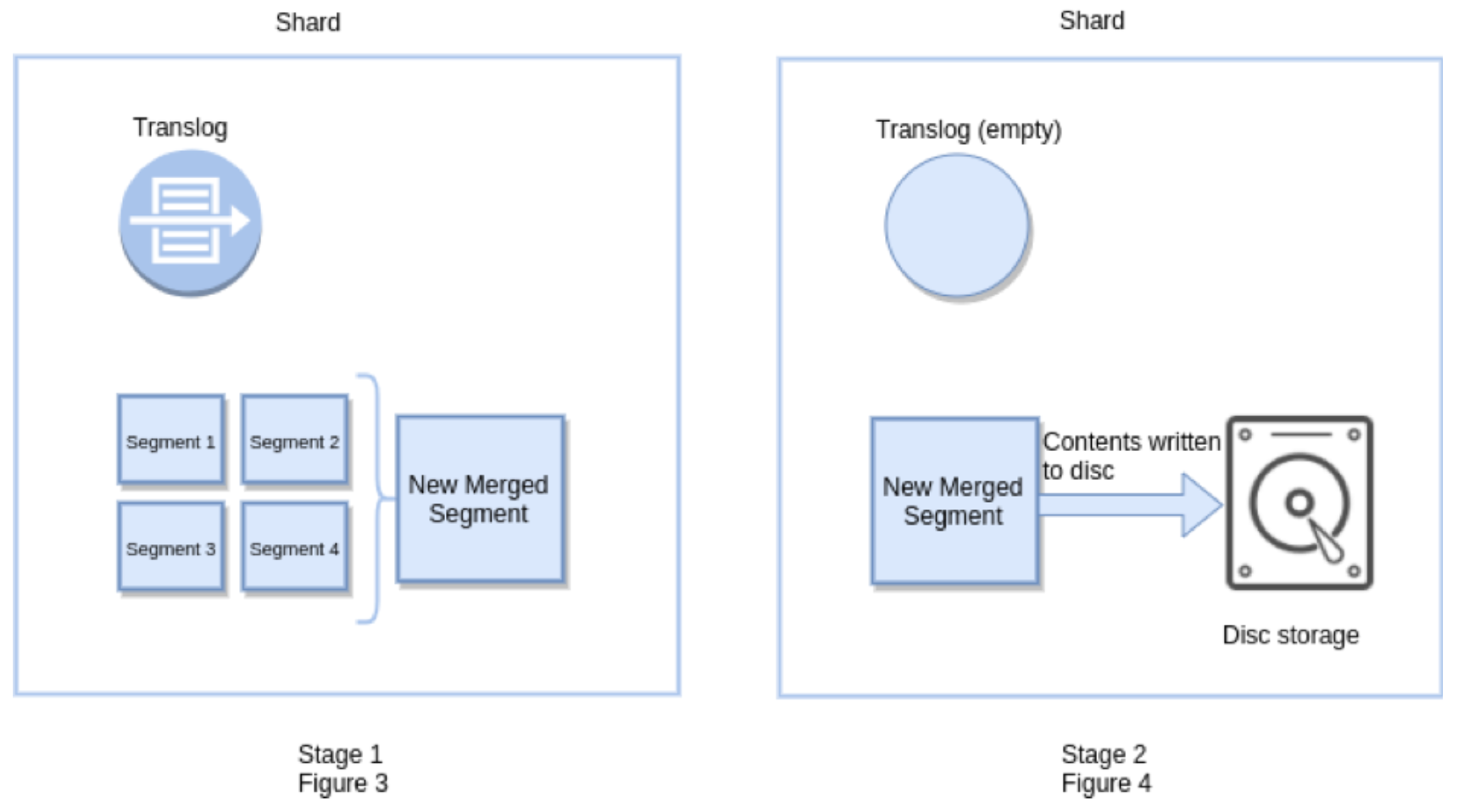 Flush 操作意味着将内存 buffer 的数据全都写入新的 Segments 中, 并将内存中所有的 Segments 全部刷盘, 并 且清空 translog 日志的过程。
Flush 操作意味着将内存 buffer 的数据全都写入新的 Segments 中, 并将内存中所有的 Segments 全部刷盘, 并 且清空 translog 日志的过程。
-
-
近实时搜索
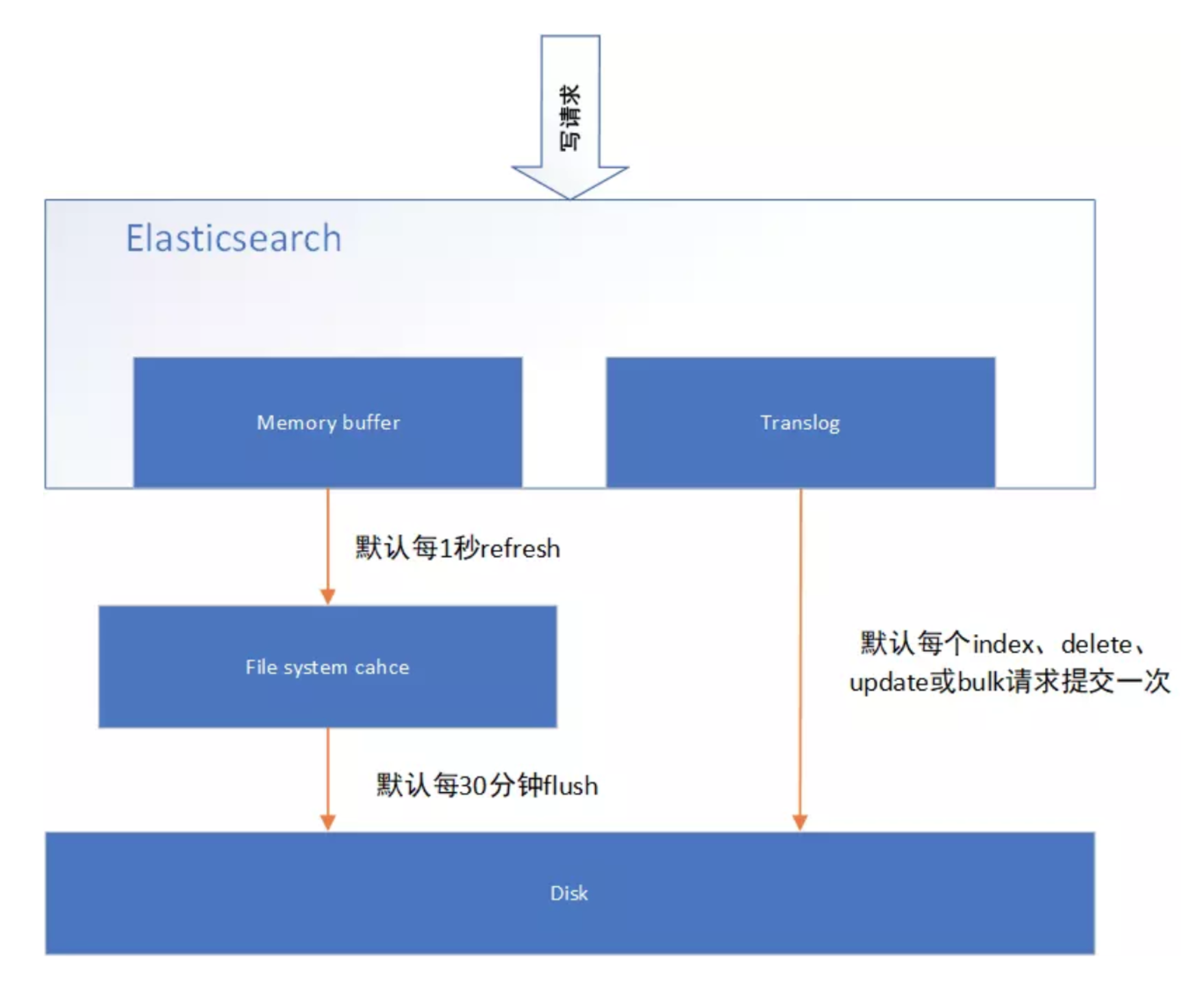 es 写操作流程,当一个写请求发送到 es 后,es 将数据写入 memory buffer 中,并添加事务日志( translog )。 如果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操作也就是随机 写入了。硬盘随机写入的效率相当低,会严重降低es的性能。
es 写操作流程,当一个写请求发送到 es 后,es 将数据写入 memory buffer 中,并添加事务日志( translog )。 如果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操作也就是随机 写入了。硬盘随机写入的效率相当低,会严重降低es的性能。
因此 es 在设计时在 和硬盘间加入了 Linux 的高速缓存( )来提高 es 的写效 率。
当写请求发送到 es 后,es 将数据暂时写入 memory buffer 中,此时写入的数据还不能被查询到。默认设置下,es 每1秒钟将 memory buffer 中的数据 refresh 到 Linux 的 File system cache ,并清空 memory buffer ,此时 写入的数据就可以被查询到了。-
refresh API 在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。
默认情况下每个分片会每秒自动刷新一次。 这就是为什么我们说 Elasticsearch 是 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可 见。
这些行为可能会对新用户造成困惑: 他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是 用 refresh API 执行一次手动刷新:1. POST /_refresh 2. POST /my_blogs/_refresh 3. PUT /my_blogs/_doc/1?refresh {"test": "test"} PUT /test/_doc/2?refresh=true {"test": "test"}- 刷新(Refresh)所有的索引。
- 只刷新(Refresh) blogs 索引
- 只刷新文档
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而 不是近实时搜索, 可以通过设置 refresh_interval , 降低每个索引的刷新频率
PUT /my_logs { "settings": { "refresh_interval": "30s" } }refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关 闭自动刷新,待开始使用该索引时,再把它们调回来:
PUT /my_logs/_settings { "refresh_interval": -1 } PUT /my_logs/_settings { "refresh_interval": "1s" }
-
-
持久化变更(flush) 即使通过每秒刷新(refresh)实现了近实时搜索,仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提
交之间发生变化的文档怎么办?我们也不希望丢失掉这些数据。
Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。通过 translog ,整个流程看起来是上面这样:- 一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog
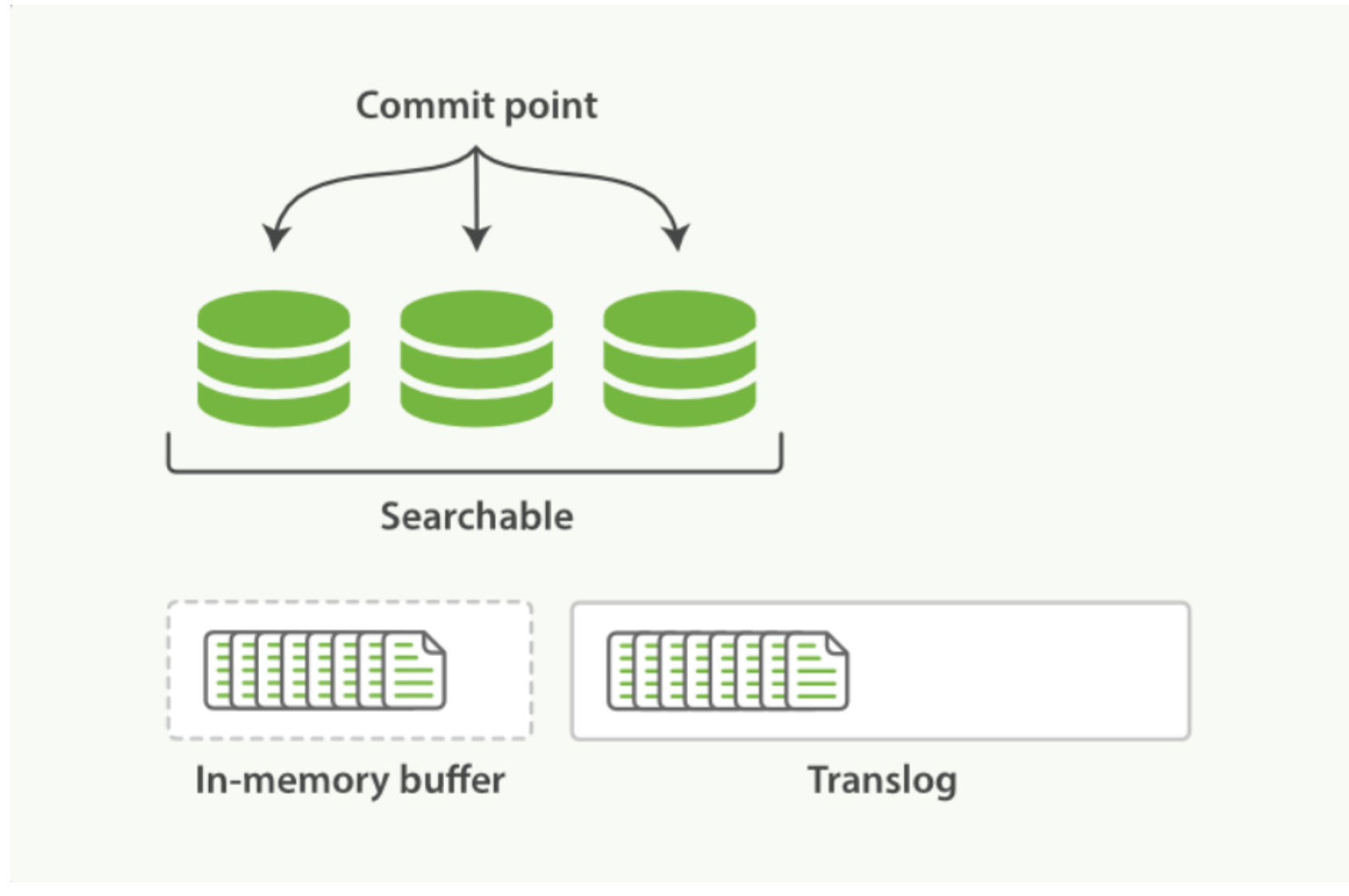 刷新(refresh)使分片处于 下图描述的状态,分片每秒被刷新(refresh)一次:
刷新(refresh)使分片处于 下图描述的状态,分片每秒被刷新(refresh)一次:
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行 fsync 操作。
- 这个段被打开,使其可被搜索。
-
内存缓冲区被清空。
- 刷新(refresh)完成后, 缓存被清空但是事务日志不会
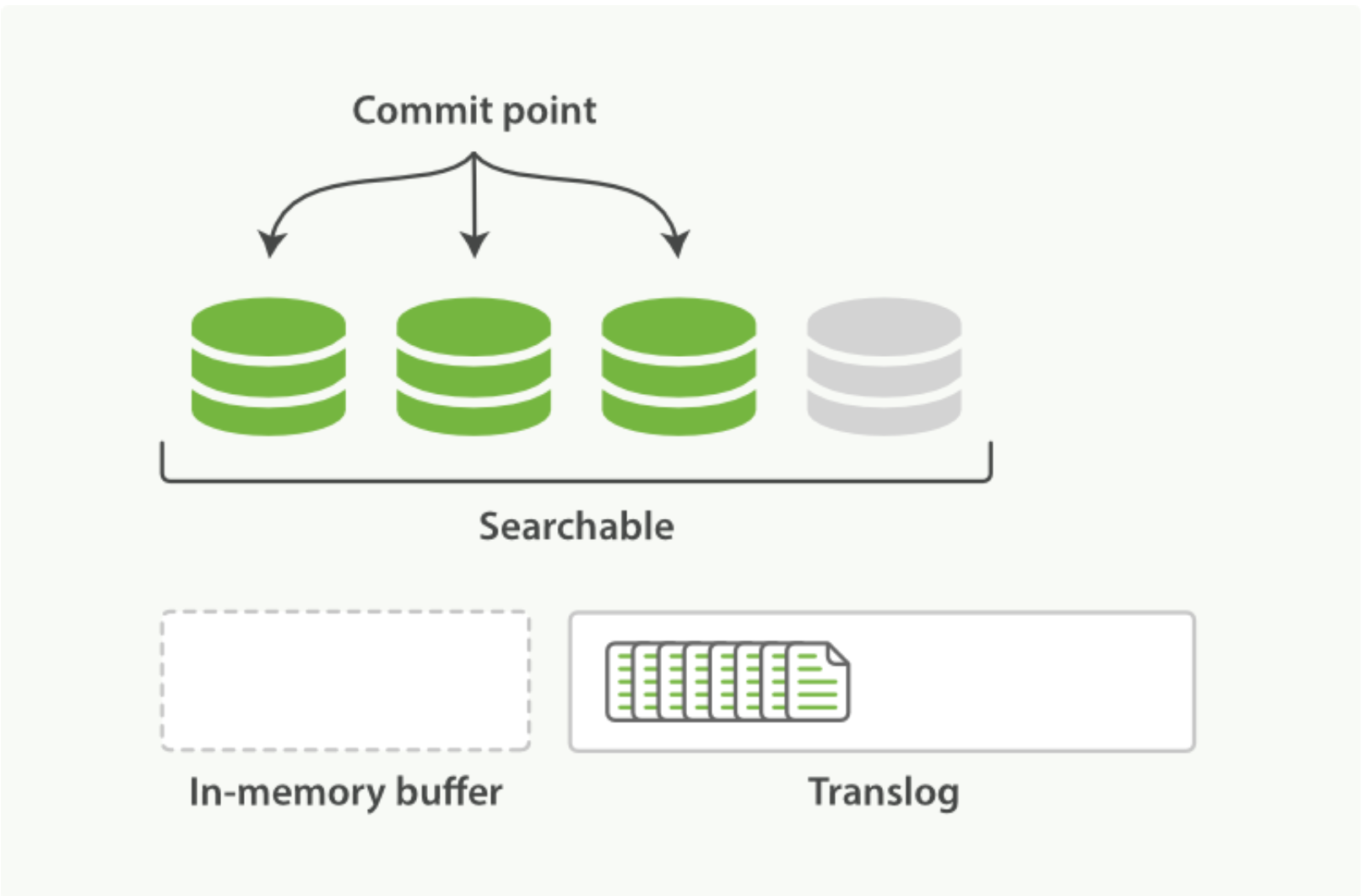
- 刷新(refresh)完成后, 缓存被清空但是事务日志不会
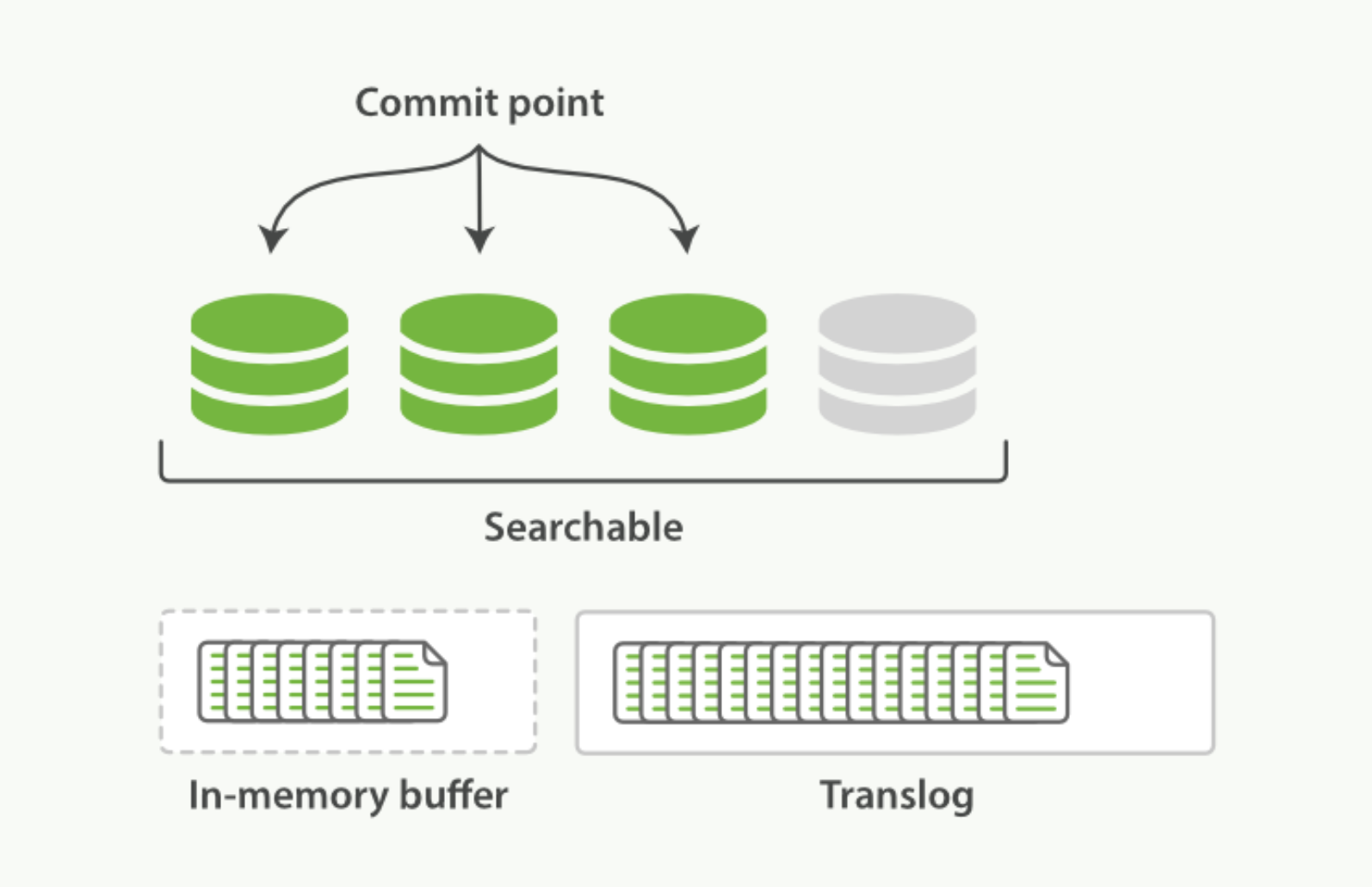
-
这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志, 事务日志不断积累文档
- 每隔一段时间,例如 translog 变得越来越大,索引被刷新(flush);一个新的 translog 被创建,并且一个全量提交被执行
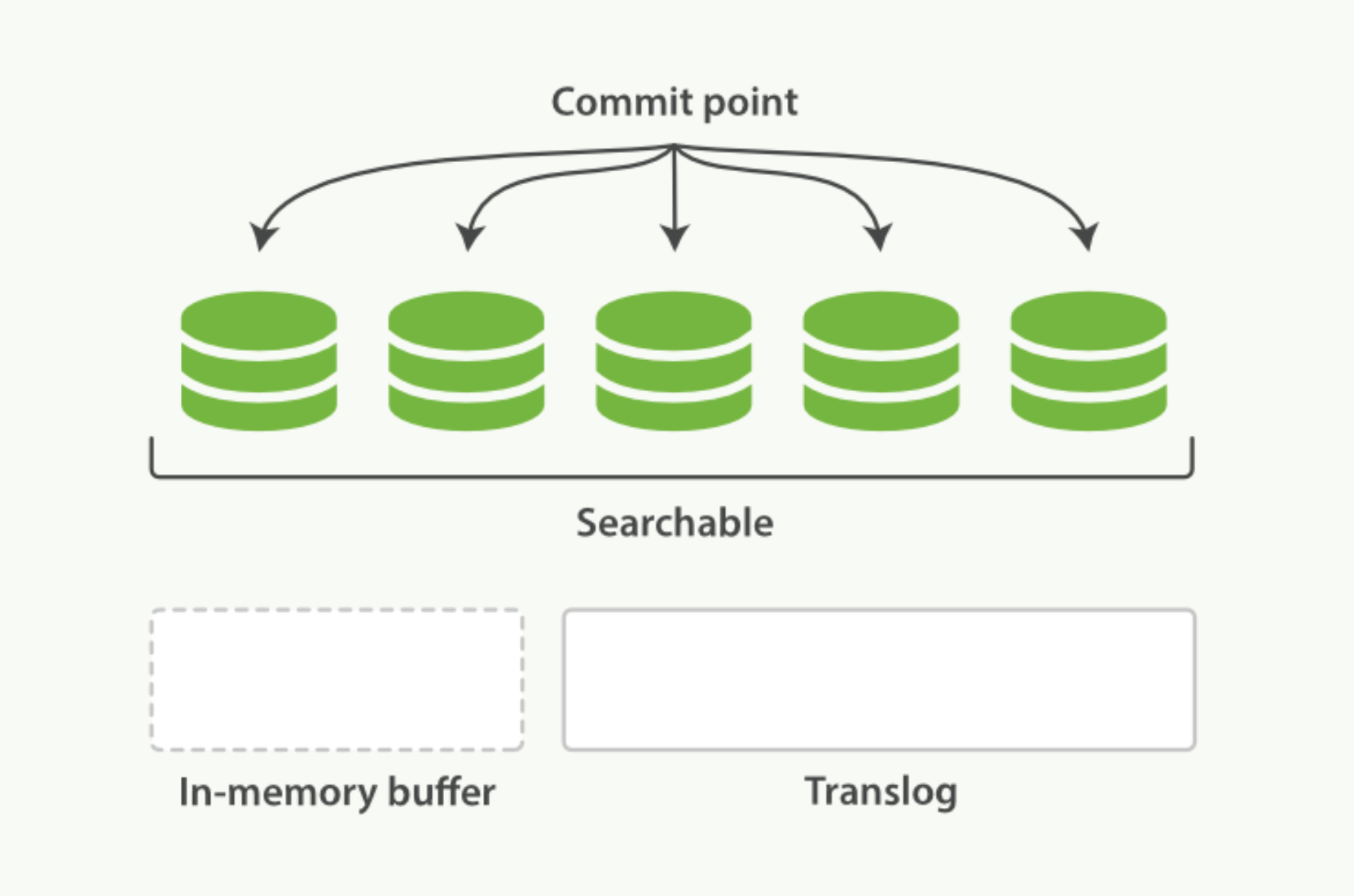
- 所有在内存缓冲区的文档都被写入一个新的段(segment)。
- 缓冲区被清空。
- 一个提交点被写入硬盘。
- 文件系统缓存通过 fsync 被刷新(flush)。 老的 translog 被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化记录。当 Elasticsearch 启动的时候, 它会从磁盘中使用最 后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时 CRUD 。当你试着通过 ID 查询、更新、删除一个文档,它会在尝试从相应的段中检索之 前, 首先检查 translog 任何最近的变更。这意味着它总是能够实时地获取到文档的最新版本。 -
flush API 这个执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 flush 。 分片每 30 分钟被自动刷新
(flush),或者在 translog 太大(512M)的时候也会刷新。flush API 可以 被用来执行一个手工的刷新(flush):
POST /blogs/_flush POST /_flush?wait_for_ongoin- 刷新(flush) blogs 索引。
- 刷新(flush)所有的索引并且等待所有刷新在返回后完成。 我们很少需要自己手动执行一个的 flush 操作;
通常情况下,自动刷新就足够了。
这就是说,在重启节点或关闭索引之前执行 flush有益于你的索引。当 Elasticsearch 尝试恢复或重新打开一个索引, 它需要重放 translog 中所有的操作,所以如果日志越短,恢复越快。
Translog 有多安全? translog 的目的是保证操作不会丢失。
这引出了这个问题: Translog 有多安全? 在文件 被 fsync 到磁盘前,被写入的文件在重启之后就会丢失。这个过程在主分片和复制分片都会发生。最终, 基 本上,这意味着在整个请求被 fsync 到主分片和复制分片的 translog 之前,你的客户端不会得到一个 200 OK 响应。 在每次写请求后都执行一个 fsync 会带来一些性能损失,尽管实践表明这种损失相对较小(特别是 bulk 导入,它在一次请求中平摊了大量文档的开销)。
但是对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的 fsync 还是比较有益的。比如, 写入的数据被缓存到内存中,再每 5 秒执行一次 fsync 。
这个行为可以通过设置 durability 参数为 async 来启用:PUT /my_index/_settings { "index.translog.durability": "async", "index.translog.sync_interval": "5s" }这个选项可以针对索引单独设置,并且可以动态进行修改。如果你决定使用异步 translog 的话,你需要 保证 在发生 crash 时,丢失掉 sync_interval 时间段的数据也无所谓。请在决定前知晓这个特性。
如果你不确定这个行为的后果,最好是使用默认的参数( "index.translog.durability": "request" )来避免数据丢失。
- 一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog
-
-
索引文档存储段合并
-
段合并机制 由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和 CPU 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越 多,搜索也就越慢。
Elasticsearch 通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的 段。段合并的时候会将那些旧的已删除文档 从文件系统中清除。 被删除的文档(或被更新文档的旧版本)不会被拷 贝到新的大段中。
-
启动段合并在进行索引和搜索时会自动进行
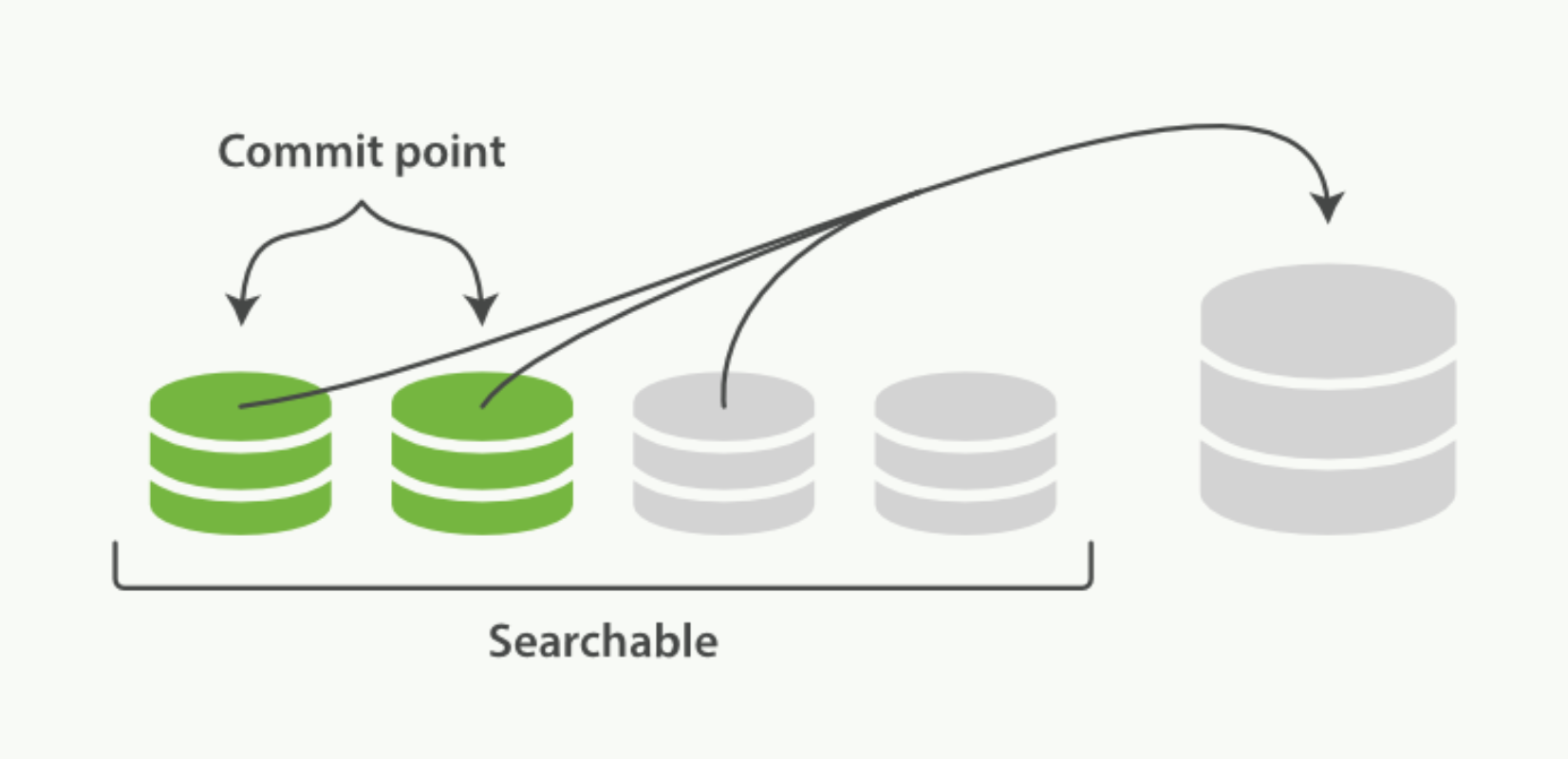 1、 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
1、 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
2、 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。 两个提交了的段和一个未提交的段正在被合并到一个更大的段 - 合并完成时的活动
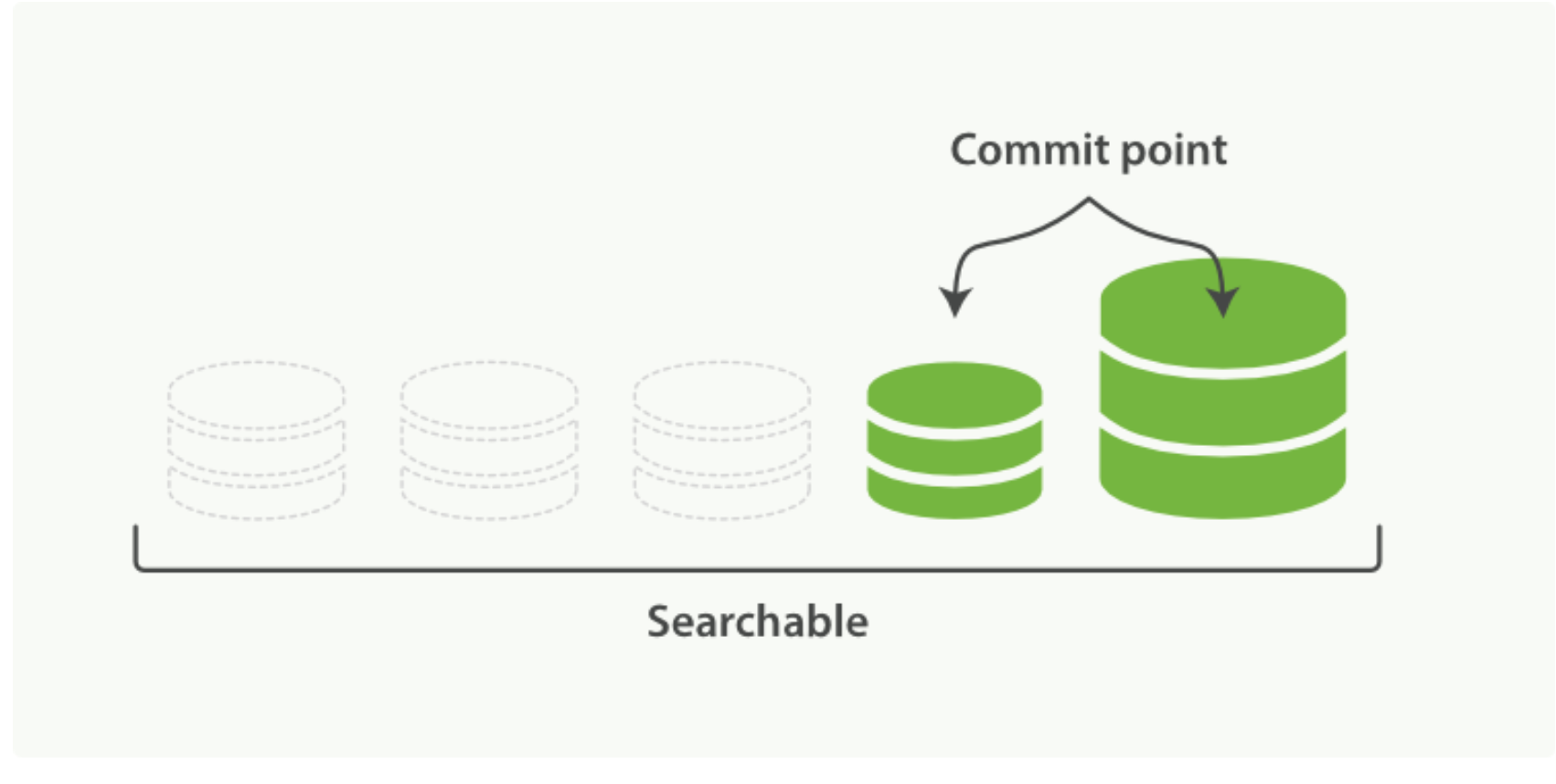
- 新的段被刷新(flush)到了磁盘。 写入一个包含新段且排除旧的和较小的段的新提交点。
- 新的段被打开用来搜索。
- 老的段被删除。
-
资源约束 合并大的段需要消耗大量的 I/O 和 CPU 资源,如果任其发展会影响搜索性能。Elasticsearch 在默认情况下会对合并 流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。默认情况下,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器 来说,这个限速是明显过低的。对于 ELK Stack 应用,建议可以适当调大到 100MB或者更高。
PUT /_cluster/settings { "persistent" : { "indices.store.throttle.max_bytes_per_sec" : "100mb" } }用于控制归并线程的数目,推荐设置为cpu核心数的一半。 如果觉得自己磁盘性能跟不上,可以降低配置,免得IO情况瓶颈。
index.merge.scheduler.max_thread_count
-
- 归并策略 policy
归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条: index.merge.policy.floor_segment 默认 2MB,小于这个大小的 segment,优先被归并。 index.merge.policy.max_merge_at_once 默认一次最多归并 10 个 segment index.merge.policy.max_merge_at_once_explicit 默认 optimize 时一次最多归并 30 个 segment。 index.merge.policy.max_merged_segment 默认 5 GB,大于这个大小的 segment,不用参与归并。optimize 除外。 -
optimize API optimize API 大可看做是 强制合并 API。它会将一个分片强制合并到 max_num_segments 参数指定大小的段数 目。 这样做的意图是减少段的数量(通常减少到一个),来提升搜索性能。 在特定情况下,使用 optimize API 颇 有益处。例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中。 老的索引实质上是只读的;它们 也并不太可能会发生变化。在这种情况下,使用 optimize 优化老的索引,将每一个分片合并为一个单独的段就很有 用了;这样既可以节省资源,也可以使搜索更加快速:
POST /Logstash-2014-10/_optimize?max_num_segments=1 forceMergeRequest.maxNumSegments(1)
-
-
存储文件详解
 通过ES-HEAD插件可以查看到一个索引的分片信息,图中一个绿色方块就代表一个分片Shard; ES使用Lucene来处理shard级别的索引和查询,因此数据目录中的文件由Elasticsearch和Lucene共同编写。
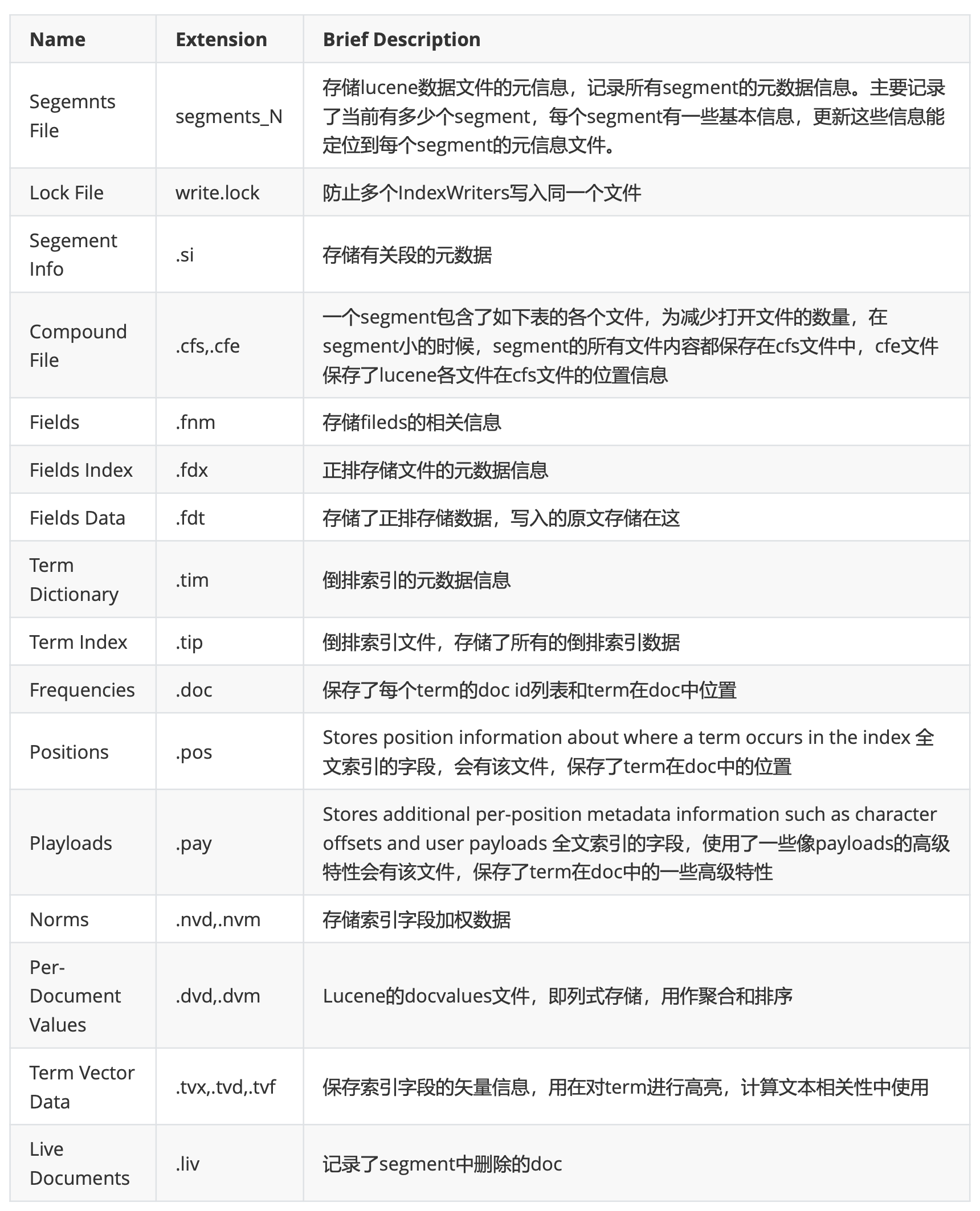
通过ES-HEAD插件可以查看到一个索引的分片信息,图中一个绿色方块就代表一个分片Shard; ES使用Lucene来处理shard级别的索引和查询,因此数据目录中的文件由Elasticsearch和Lucene共同编写。
Lucene负责编写和维护Lucene索引文件,而Elasticsearch在Lucene之上编写与功能相关的元数据,例如字段映射, 索引设置和其他集群元数据,用户和支持功能由Elasticsearch提供。进入ES集群数据存储目录
/opt/servers/es/data/nodes/0/indices补充:indices目录下存储当前节点持有的所有索引的数据(指定分片)。
进入 指定索引目录cd LhzaS2xsQh225hONW447sA-
-
-
文件说明
-
-
Elasticsearch中的数据结构
-
倒排索引详解
 倒排索引是全文检索的根基,理解了倒排索引之后才能算是入门了全文检索领域。倒排索引的的概念很简单,也很好 理解。Elasticsearch/Lucene是如何实现这个结构的呢?
倒排索引是全文检索的根基,理解了倒排索引之后才能算是入门了全文检索领域。倒排索引的的概念很简单,也很好 理解。Elasticsearch/Lucene是如何实现这个结构的呢?倒排索引由两部分组成,所有独立的词列表称为索引,词对应的一系列表统称为倒排表。 —— 来自《信息检索》
- 索引表,叫Terms Dictionary,是由于一系列的Term组成的。
-
倒排表,称Postings List,即是由所有的Term对应的Postings组成的。
-
如何存储一个倒排索引数据?选择哪种数据结构?
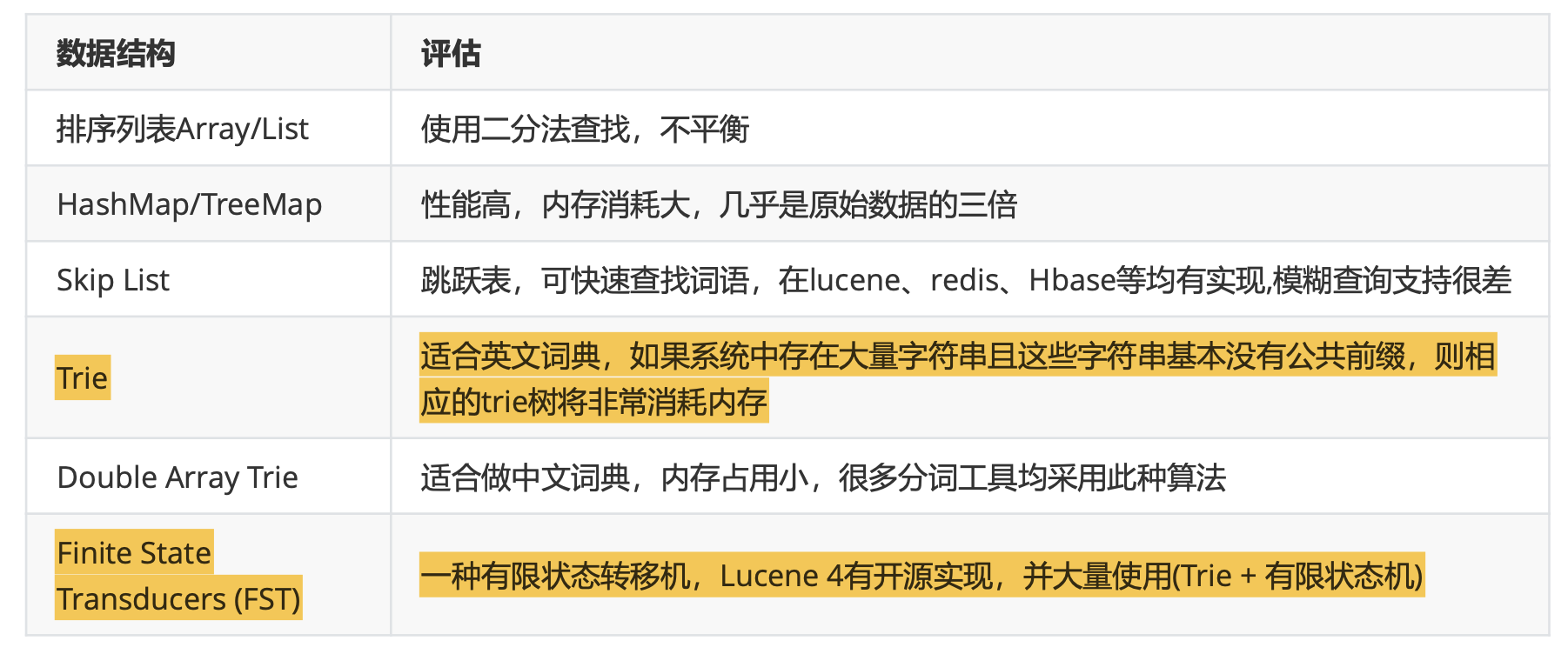 全文搜索引擎通常是需要存储大量的文本,不仅是Postings可能会是非常巨大,同样Dictionary的大小极可能也是非 常庞大。真正的搜索引擎的倒排索引实现都极其复杂,因为它直接影响了搜索性能和功能
全文搜索引擎通常是需要存储大量的文本,不仅是Postings可能会是非常巨大,同样Dictionary的大小极可能也是非 常庞大。真正的搜索引擎的倒排索引实现都极其复杂,因为它直接影响了搜索性能和功能
Lucene的实现非常高级,它的关键特性是能够将整个倒排索引序列化存储在磁盘上,同时它必须是能够满足快速读 写的需求。Lucene为了极致的搜索体验,引用多种数据结构和算法。倒排索引变得高效又复杂给我们带来一次研读 和剖析的机会。 - Lucene索引文件分析
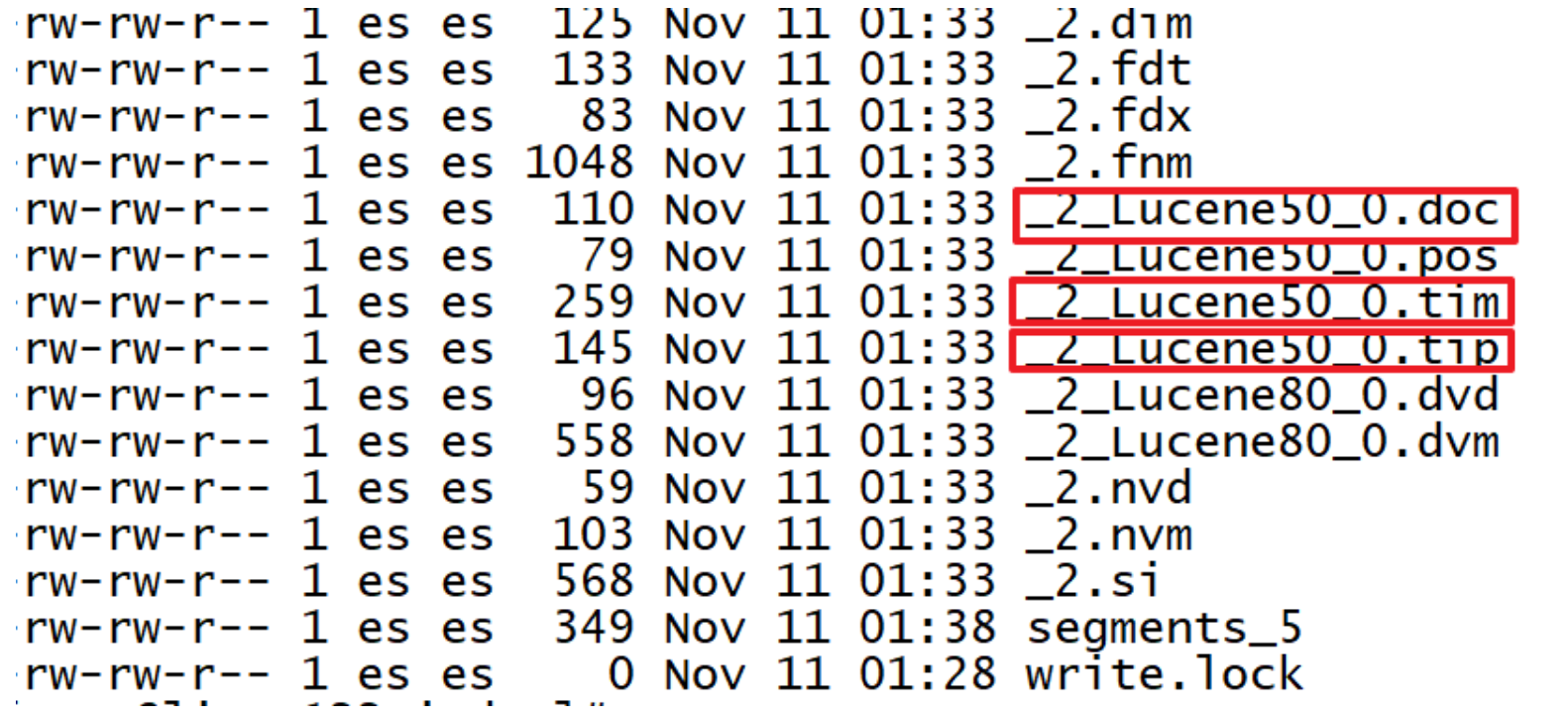 Lucene将索引文件拆分为了多个文件,此处仅讨论倒排索引部分。
Lucene将索引文件拆分为了多个文件,此处仅讨论倒排索引部分。
- tip: Lucene把用于存储Term的索引文件叫Terms Index,它的后缀是 .tip ;
- doc: 把Postings信息分别存储在 .doc ,分别记录Postings的DocId信息和Term的词频信息。
-
tim: Terms Dictionary的文件后缀称为 .tim ,它是Term与Postings的关系纽带,存储了Term和其对应的 Postings文件指针。
-
Term Dictionary
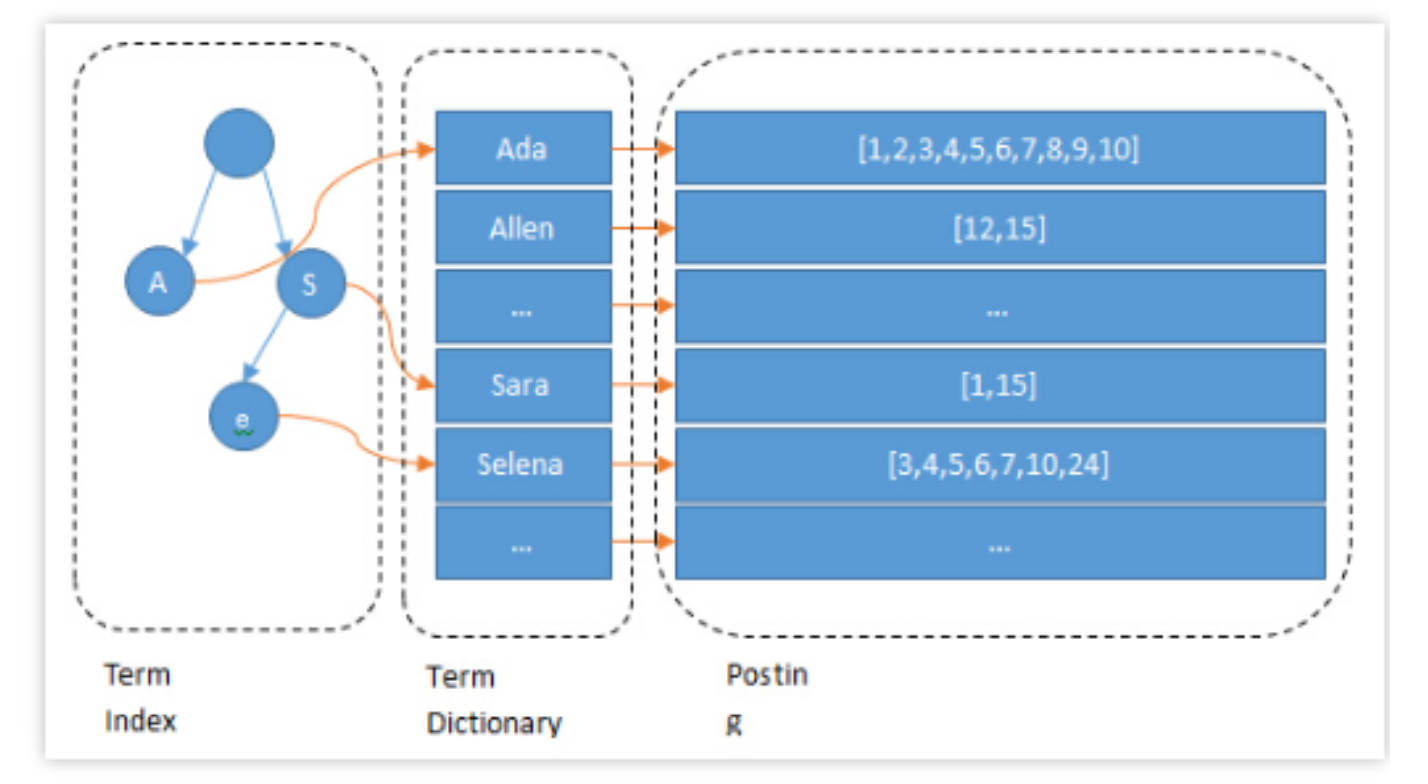 把Term按字典序排列,然后用二分法查找Term (存在磁盘)
把Term按字典序排列,然后用二分法查找Term (存在磁盘)
在Lucene,Terms Dictionary被存储在.tim文件上。当一个Segment的文档数量越来越多的同时Dictionary的词汇 也会越来越多,那查询效率必然也会慢慢变低。如果有一个很好的结构也为Dictionary建构一个索引,将Dictionary 的索引进一步压缩,这就是后来的Terms Index(.tip)。 -
Term Index 是Term Dictionary的索引,存Term的前缀,和与该前缀对应的Term Dictionary中的第一个Term的 block的位置,找到这个第一个Term后会再往后顺序查找,直到找到目标Term。(存在内存)
总结:- 通过Terms Index(.tip)可以快速地在Terms Dictionary(.tim)中找到你的想要的Term,以及它对应的Postings文
件指针(指向doc)。 - Terms Index实际上是一个或者多个 FST 组成的,Segment上每个字段都有自己的一个FST(FSTIndex)记录
在 .tip 上。(FST类似一种TRIE树)
- 通过Terms Index(.tip)可以快速地在Terms Dictionary(.tim)中找到你的想要的Term,以及它对应的Postings文
-
- Trie
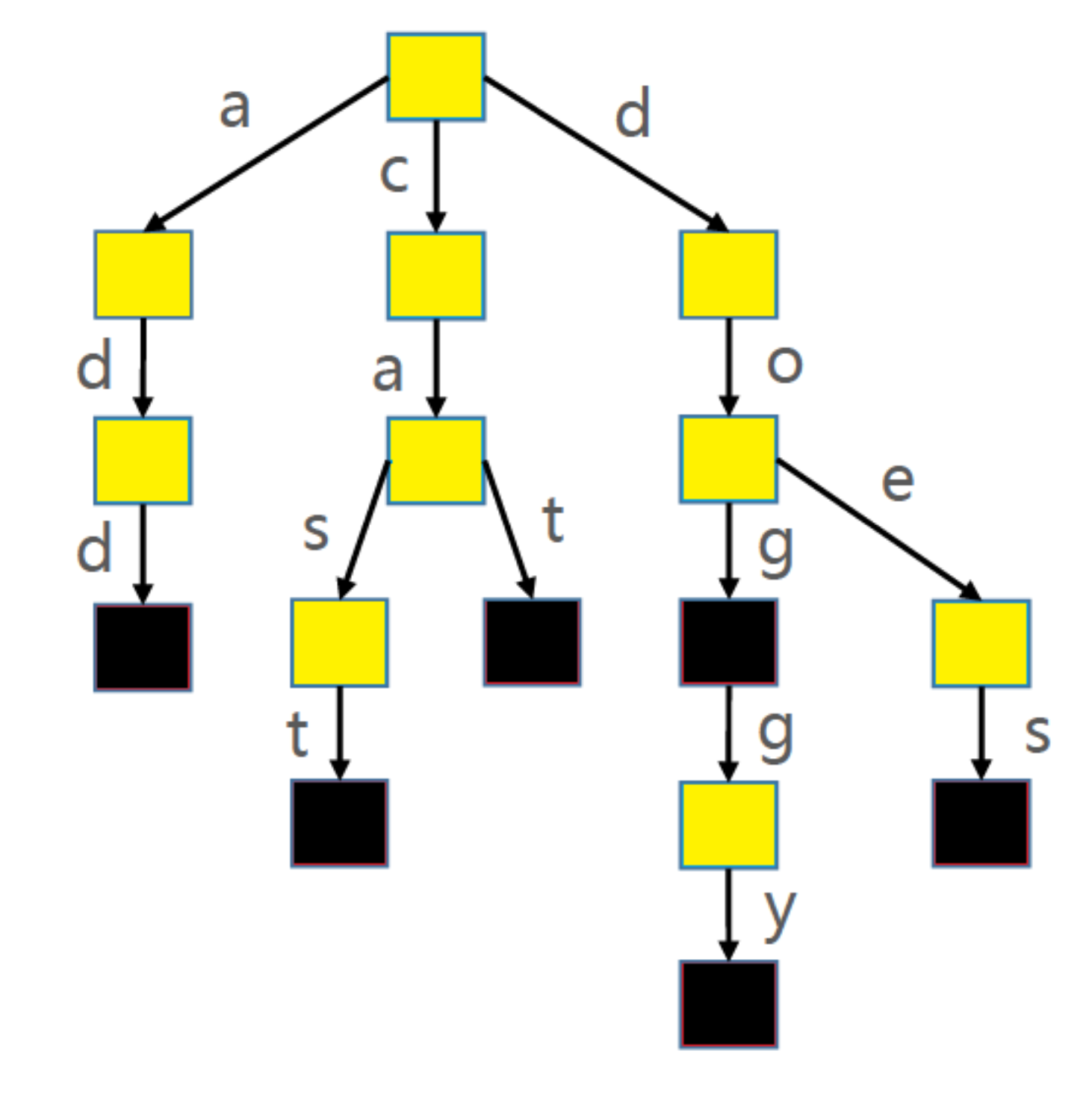 Trie 被称作做字典树、前缀树(Prefix Tree)、单词查找树
Trie 被称作做字典树、前缀树(Prefix Tree)、单词查找树
- Trie 搜索字符串的效率主要跟字符串的长度有关(O(len(单词)))
使用 Trie 存储 cat->1、dog->2、doggy->3、does->4、cast->5、add->6 六个单词映射
Trie时间复杂度:O(len(key))
- FST FST,不但能共享前缀还能共享后缀。不但能判断查找的key是否存在,还能给出响应的输入output。 它在时间复杂 度和空间复杂度上都做了最大程度的优化,使得Lucene能够将Term Index完全加载到内存,快速的定位Term找到 响应的output(posting倒排列表)。
-
-
SkipList应用 假设某个索引字段中有sex,address字段,检索条件为:sex=’female’ and address=’北京’,
- 给定查询过滤条件 sex=’female’的过程就是先从 term index 找到 femal 在 term dictionary 的大概位置, 再从 term dictionary 里精确地找到 female 这个 term,然后得到一个 posting list 或者一个指向 posting list 位置的指针。
- 查询 address=’北京’ 的过程类似的。得到一个 posting list 或者一个指向 posting list 位置的指针
需要计算出 sex=’female’ and address=’北京’ 就是把两个 posting list 做一个“与”的合并。
ES中使用 skip list 数据结构。同时遍历 sex和 address 的 posting list,互相 skip!!- 有序集合计算交集
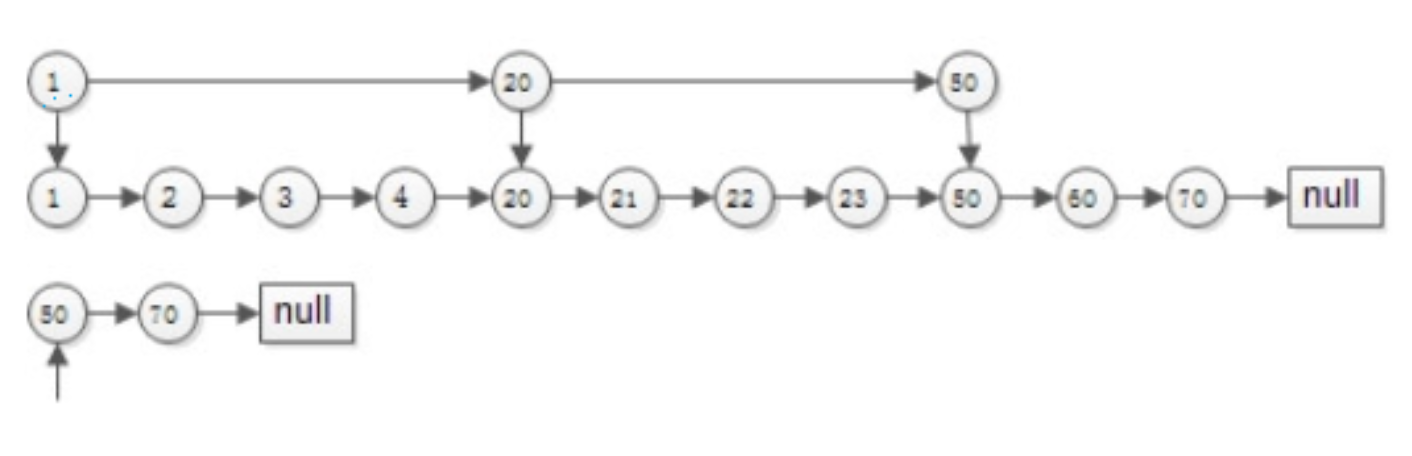
#有序集合 list1:{1,2,3,4,20,21,22,23,50,60,70} list2:{50,70}拉链法
两个指针指向首元素,比较元素的大小:- 如果相同,放入结果集,随意移动一个指针
- 否则,移动值较小的一个指针,直到队尾
这种方法的优势是:
- 集合中的元素最多被比较一次,时间复杂度为O(n)
- 多个有序集合可以同时进行
-
跳表SkipList
 有序链表集合求交集,跳表是最常用的数据结构,它可以将有序集合求交集的复杂度由O(n)降至O(log(n))
有序链表集合求交集,跳表是最常用的数据结构,它可以将有序集合求交集的复杂度由O(n)降至O(log(n))
如果使用拉链法,会发现每个元素都要被比对但是其中有很多其实是无效比对,时间复杂度为O(n),所谓跳表可以把 时间复杂度优化至O(logn),就是因为使用跳表可以跳过很多无效比对!! -
跳表实现
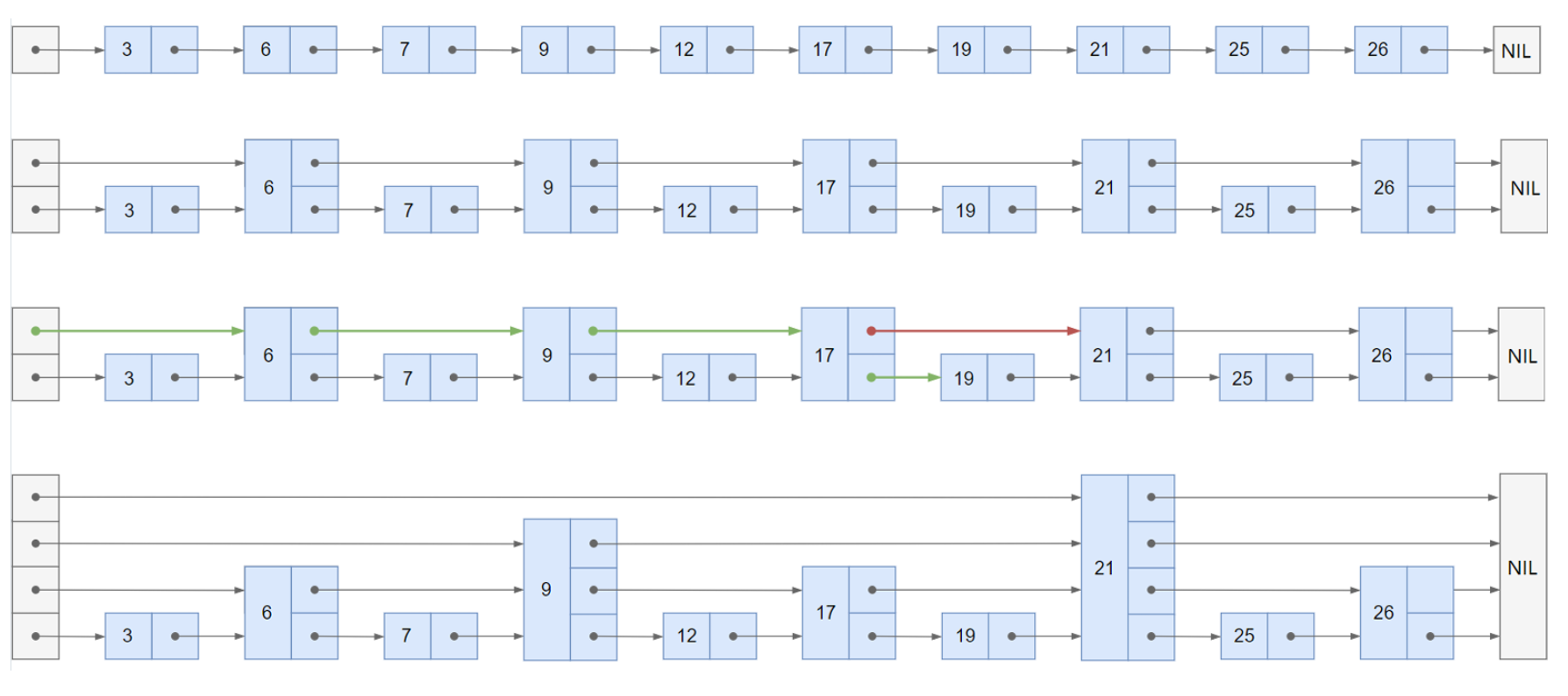
- 搜索过程
- 从顶层链表的首元素开始,从左往右搜索,直至找到一个大于或等于目标的元素,或者到达当前层链表的尾部
- 如果该元素等于目标元素,则表明该元素已被找到
- 如果该元素大于目标元素或已到达链表的尾部,则退回到当前层的前一个元素,然后转入下一层进行搜索
-
添加元素
 随机决定新添加元素的层数(抛硬币)
随机决定新添加元素的层数(抛硬币) - 删除元素

- 搜索过程
-
-
并发冲突处理机制剖析
- 并发冲突
在电商场景下,工作流程为:
- 读取商品信息,包括库存数量
- 用户下单购买
- 更新商品信息,将库存数减一
如果是多线程操作,就可能有多个线程并发的去执行上述的3步骤流程,假如此时有两个人都来读取商品数据,两个 线程并发的服务于两个人,同时在进行商品库存数据的修改。假设库存为100件 正确的情况:线程A将库存-1,设置 为99件,线程B接着读取99件,再-1,变为98件。如果A,B线程都读取的为100件,A处理完之后修改为99件,B处理 完之后再次修改为99件,此时结果就出错了。
-
解决方案
-
悲观锁
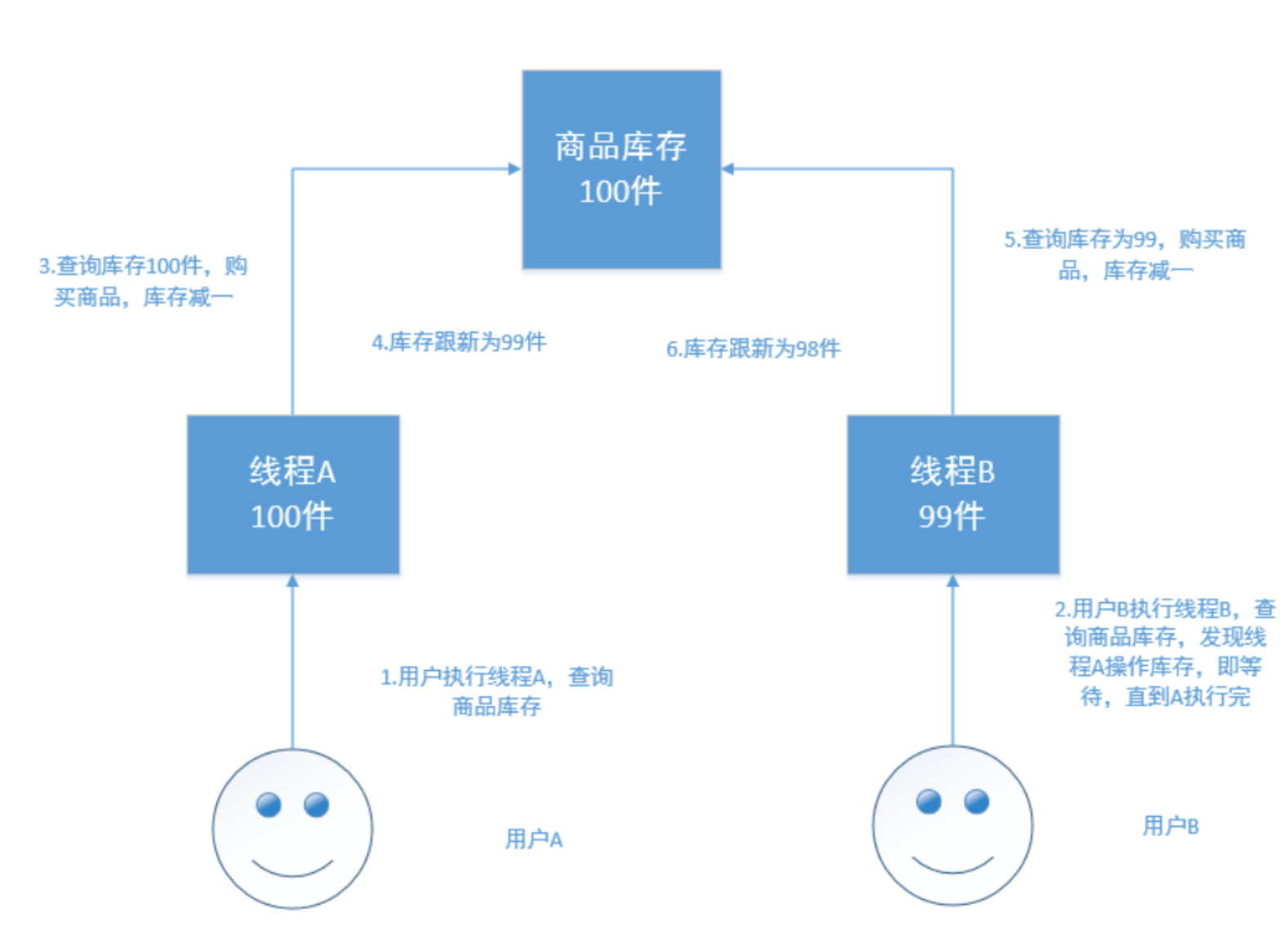 顾名思义,就是很悲观,每次去拿数据的时候都认为被人会修改,所以每次拿数据的时候都会加锁,以防别人修改,直到操作完成后,才会被别人执行。常见的关系型数据库,就用到了很多这样的机制,如行锁,表锁,写锁,都是在操作之前加锁。
顾名思义,就是很悲观,每次去拿数据的时候都认为被人会修改,所以每次拿数据的时候都会加锁,以防别人修改,直到操作完成后,才会被别人执行。常见的关系型数据库,就用到了很多这样的机制,如行锁,表锁,写锁,都是在操作之前加锁。悲观锁的优点:方便,直接加锁,对外透明,不需要额外的操作。
悲观锁的缺点:并发能力低,同一时间只能有一个操作。 -
乐观锁
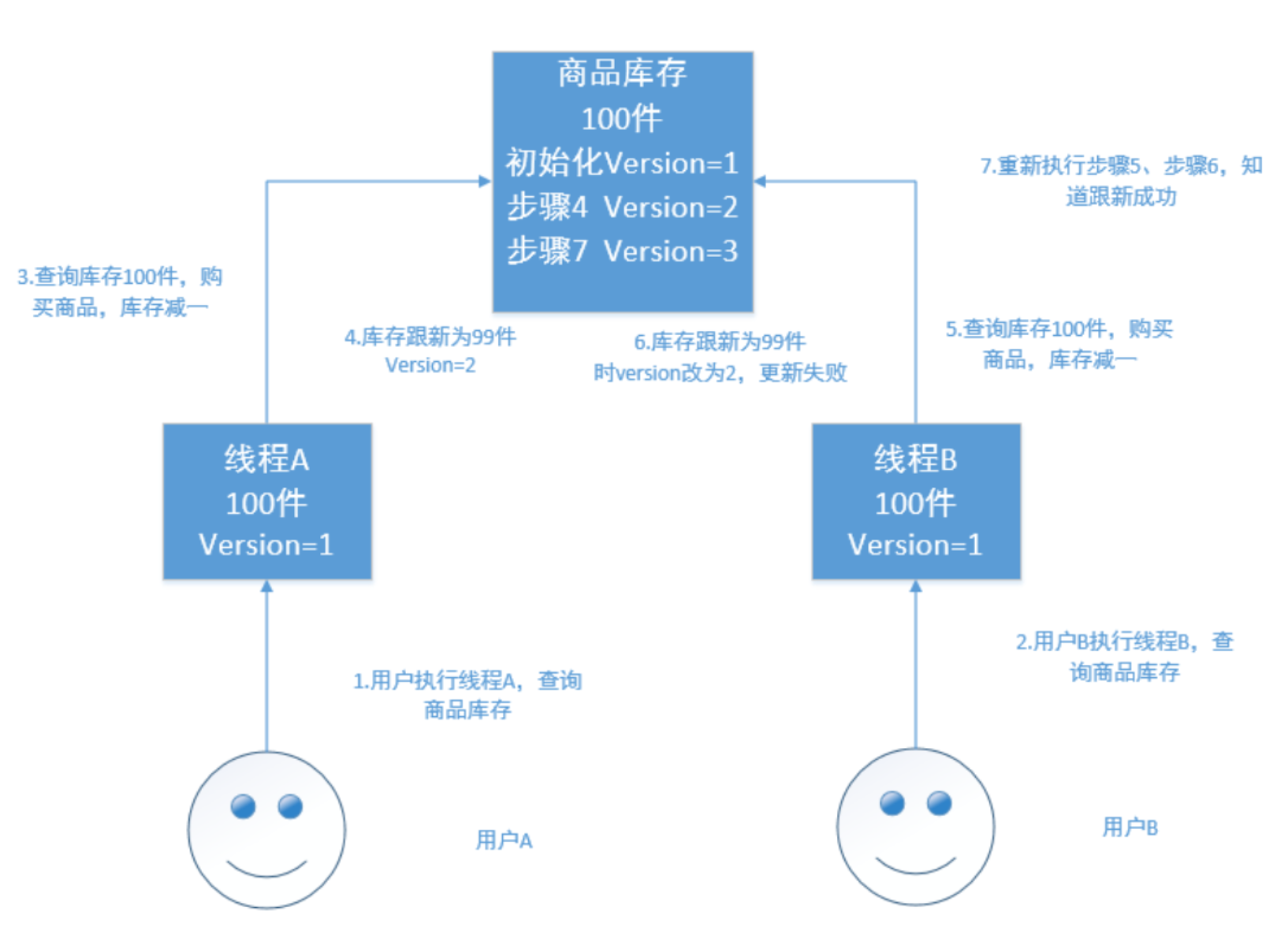 乐观锁不加锁,每个线程都可以任意操作。比如每条文档中有一个version字段,新建文档后为1,修改一次累加,线 程A,B同时读取到数据,version=1,A处理完之后库存为99,在写入es的时候会跟es中的版本号比较,都是1,则写 入成功,version=2,B处理完之后也为99,存入es时与es中的数据的版本号version=2相比,明显不同,此时不会用 99去更新,而是重新读取最新的数据,再减一,变为98,执行上述操作写入。
乐观锁不加锁,每个线程都可以任意操作。比如每条文档中有一个version字段,新建文档后为1,修改一次累加,线 程A,B同时读取到数据,version=1,A处理完之后库存为99,在写入es的时候会跟es中的版本号比较,都是1,则写 入成功,version=2,B处理完之后也为99,存入es时与es中的数据的版本号version=2相比,明显不同,此时不会用 99去更新,而是重新读取最新的数据,再减一,变为98,执行上述操作写入。 -
Elasticsearch的乐观锁 Elasticsearch的后台都是多线程异步的,多个请求之间是乱序的,可能后修改的先到,先修改的后到。
Elasticsearch的多线程异步并发修改是基于自己的_version版本号进行乐观锁并发控制的。 在后修改的先到时,比较版本号,版本号相同修改可以成功,而当先修改的后到时,也会比较一下_version版本号,如
果不相等就再次读取新的数据修改。这样结果会就会保存为一个正确状态 删除操作也会对这条数据的版本号加1
在删除一个document之后,可以从一个侧面证明,它不是立即物理删除掉的,因为它的一些版本号等信息还是保留 着的。先删除一条document,再重新创建这条document,其实会在delete version基础之上,再把version号加1 -
es的乐观锁并发控制示例
# 创建测试索引 PUT /test_index { "settings": {}, "mappings": { "properties": { "test_field":{ "type": "keyword" } } } } # 插入一条数据 PUT /test_index/_doc/4 { "test_field": "test" } # 客户端1 GET /test_index/_doc/4 #返回结果 { "_index" : "test_index", "_type" : "_doc", "_id" : "4", "_version" : 4, "_seq_no" : 3, "_primary_term" : 1, "found" : true, "_source" : { "test_field" : "test" } } # 客户端2 GET /test_index/_doc/4 #返回结果 { "_index" : "test_index", "_type" : "_doc", "_id" : "4", "_version" : 4, "_seq_no" : 3, "_primary_term" : 1, "found" : true, "_source" : { "test_field" : "test" } } # 客户端1,更新,带上查询到的序列号3 PUT /test_index/_doc/4?if_seq_no=3&if_primary_term=1 { "test_field": "client1 chenged" } # 结果 { "_index" : "test_index", "_type" : "_doc", "_id" : "4", "_version" : 5, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 4, "_primary_term" : 1 } # 客户端2,更新,带上查询到的序列号3 PUT /test_index/_doc/4?if_seq_no=3&if_primary_term=1 { "test_field": "client2 chenged" } # 结果版本冲突 { "error": { "root_cause": [ { "type": "version_conflict_engine_exception", "reason": "[4]: version conflict, required seqNo [3], primary term [1]. current document has seqNo [4] and primary term [1]", "index_uuid": "H-vL4W8XSh20-GJsjC8gDw", "shard": "0", "index": "test_index" } ], "type": "version_conflict_engine_exception", "reason": "[4]: version conflict, required seqNo [3], primary term [1]. current document has seqNo [4] and primary term [1]", "index_uuid": "H-vL4W8XSh20-GJsjC8gDw", "shard": "0", "index": "test_index" }, "status": 409 }其中一个客户端,先更新了一下这个数据, 同时带上数据的版本号,确保说,es中的数据的版本号,跟客户端 中的数据的版本号(_seq_no)是相同的,才能修改
-
- 并发冲突
在电商场景下,工作流程为:
-
分布式数据一致性 在分布式环境下,一致性指的是多个数据副本是否能保持一致的特性。 在一致性的条件下,系统在执行数据更新操 作之后能够从一致性状态转移到另一个一致性状态。 对系统的一个数据更新成功之后,如果所有用户都能够读取到 最新的值,该系统就被认为具有强一致性。
-
ES5.0以前的一致性 consistency,one(primary shard),all(all shard),quorum(default)
我们在发送任何一个增删改操作的时候,比如PUT /index/indextype/id,都可以带上一个consistency参数,指 明我们想要的写一致性是什么? PUT /index/indextype/id?consistency=quorum- one:要求我们这个写操作,只要有一个primary shard是active状态,就可以执行。
- all:要求我们这个写操作,必 须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作。
- quorum:默认值,要求所有的 shard中,必须是法定数的shard都是活跃的,可用的,才可以执行这个写操作。
- quorum机制
写之前必须确保法定数shard可用
(1)公式:int((primary shard + number_of_replicas) / 2) + 1 当number_of_replicas > 1时才生效。比如: 1个primary shard,3个replica。那么 quorum=((1 + 3) / 2) + 1 = 3,要求1个primary shard+2个replica shard=4个shard中必须有3个shard是要处于active状态,若这时候只有两台机器的话,会出现什么情况?
最多只有2个shard是活跃的,不满足基数quorum=3的条件
- timeout机制
quorum不齐全时,会wait(等待)1分钟
默认1分钟,可以设置timeout手动去调,默认单位毫秒。 等待期间,期望活跃的shard数量可以增加,最后无法满足shard数量就会timeout,我们其实可以在写操作的时候,加一个 timeout参数,比如说PUT /index/_doc/id?timeout=30s,这个就是说自己去设定quorum不齐全的时候,ES的 timeout时长。默认是毫秒,加个s代表秒
-
ElasticSearch5.0以及以后的版本 从ES5.0后,原先执行put 带 consistency=all / quorum 参数的,都报错了,提示语法错误。
原因是consistency检查是在Put之前做的。然而,虽然检查的时候,shard满足quorum,但是真正从primary shard 写到replica之前,仍会出现shard挂掉,但Update Api会返回succeed。因此,这个检查并不能保证replica成功写 入,甚至这个primary shard是否能成功写入也未必能保证。因此,修改了语法,用了 下面的 wait_for_active_shards,因为这个更能清楚表述,而没有歧义。
PUT /test_index/_doc/1?wait_for_active_shards=2&timeout=10s { "name":"xiao mi" }
-
-
DocValues机制
-
为什么要有 Doc Values
 ElasticSearch 之所以搜索这么快速,归功于它的 倒排索引 的设计,然而它也不是万能的,倒排索引的检索性能是 非常快的,但是在字段值排序时却不是理想的结构。上面是一个简单的 倒排索引 的结构
ElasticSearch 之所以搜索这么快速,归功于它的 倒排索引 的设计,然而它也不是万能的,倒排索引的检索性能是 非常快的,但是在字段值排序时却不是理想的结构。上面是一个简单的 倒排索引 的结构如上表便可以看出,他只有词对应的 doc ,但是并不知道每一个 doc 中的内容,那么如果想要排序的话每一个 doc 都去获取一次文档内容岂不非常耗时? DocValues 的出现使得这个问题迎刃而解。
字段的 doc_values 属性有两个值, true、false。默认为 true ,即开启。
当 doc_values 为 fasle 时,无法基于该字段排序、聚合、在脚本中访问字段值。
当 doc_values 为 true 时,ES 会增加一个相应的正排索引,这增加的磁盘占用,也会导致索引数据速度慢一些举例:
DELETE /person PUT /person { "mappings": { "properties": { "name": { "type": "keyword", "doc_values": true }, "age": { "type": "integer", "doc_values": false } } } } POST _bulk { "index" : { "_index" : "person", "_id" : "1" } } { "name" : "明明", "age": 22 } { "index" : { "_index" : "person", "_id" : "2" } } { "name" : "丽丽", "age": 18 } { "index" : { "_index" : "person", "_id" : "3" } } { "name" : "媛媛", "age": 19 } POST /person/_search { "query": { "match_all": {} }, "sort": [ { "name": { "order": "desc" } } ] } POST /person/_search { "query": { "match_all": {} }, "size": 0, "aggs": { "max_age": { "max": { "field": "age" } } } } # 报错,不能被搜索 { "error": { "root_cause": [ { "type": "illegal_argument_exception", "reason": "Can't load fielddata on [age] because fielddata is unsupported on fields of type [integer]. Use doc values instead." } ], ... } } -
Doc Values 是什么
 Docvalues 通过转置倒排索引和正排索引两者间的关系来解决这个问题。倒排索引将词项映射到包含它们的文档,
Docvalues 通过转置倒排索引和正排索引两者间的关系来解决这个问题。倒排索引将词项映射到包含它们的文档,
Docvalues 将文档映射到它们包含的词项当数据被转置之后,想要收集到每个文档行,获取所有的词项就非常简单了。所以搜索使用倒排索引查找文档,聚合 操作收集和聚合 DocValues 里的数据,这就是 ElasticSearch 。
-
深入理解 ElasticSearch Doc Values DocValues 是在索引时与倒排索引同时生成。也就是说 和 一样,基于 生成并且是 不可变的。同时 DocValues 和 倒排索引 一样序列化到磁盘,这样对性能和扩展性有很大帮助。
DocValues 通过序列化把数据结构持久化到磁盘,我们可以充分利用操作系统的内存,而不是 JVM 的 Heap 。 当
workingset 远小于系统的可用内存,系统会自动将 DocValues 保存在内存中,使得其读写十分高速; 不过,当 其远大于可用内存时,操作系统会自动把 DocValues 写入磁盘。很显然,这样性能会比在内存中差很多,但是它的 大小就不再局限于服务器的内存了。 -
Doc Values 压缩
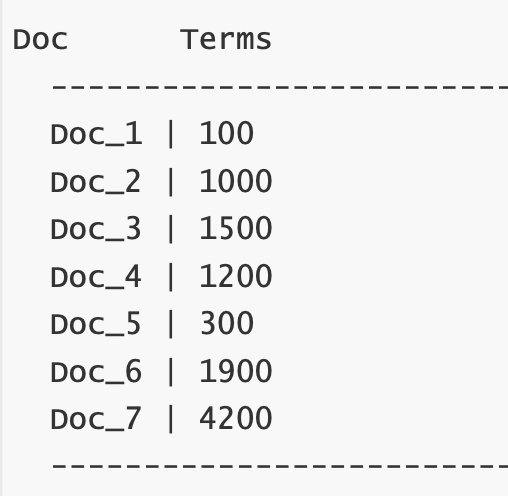 从广义来说, DocValues 本质上是一个序列化的 列式存储,这个结构非常适用于聚合、排序、脚本等操作。而且, 这种存储方式也非常便于压缩,特别是数字类型。这样可以减少磁盘空间并且提高访问速度。来看上面这组数字类型 的 DocValues
从广义来说, DocValues 本质上是一个序列化的 列式存储,这个结构非常适用于聚合、排序、脚本等操作。而且, 这种存储方式也非常便于压缩,特别是数字类型。这样可以减少磁盘空间并且提高访问速度。来看上面这组数字类型 的 DocValues你会注意到这里每个数字都是 100 的倍数, DocValues 会检测一个段里面的所有数值,并使用一个 最大公约数 , 方便做进一步的数据压缩。我们可以对每个数字都除以 100,然后得到: [1,10,15,12,3,19,42] 。现在这些数字 变小了,只需要很少的位就可以存储下,也减少了磁盘存放的大小。
DocValues 在压缩过程中使用如下技巧。它会按依次检测以下压缩模式:- 如果所有的数值各不相同(或缺失),设置一个标记并记录这些值
- 如果这些值小于 256,将使用一个简单的编码表
- 如果这些值大于 256,检测是否存在一个最大公约数
- 如果没有存在最大公约数,从最小的数值开始,统一计算偏移量进行编码
当然如果存储 String 类型,其一样可以通过顺序表对 String 类型进行数字编码,然后再用数字类型构建 DocValues 。
-
禁用 Doc Values DocValues 默认对所有字段启用,除了 analyzed strings 。也就是说所有的数字、地理坐标、日期、IP 和不分析
( not_analyzed )字符类型都会默认开启。
analyzed strings 暂时还不能使用 DocValues ,是因为经过分析以后的文本会生成大量的 Token ,这样非常影响性能。
虽然 DocValues 非常好用,但是如果你存储的数据确实不需要这个特性,就不如禁用他,这样不仅节省磁盘空间, 也许会提升索引的速度。
要禁用 DocValues ,在字段的映射(mapping)设置 doc_values:false 即可。例如,这里我们创建了一个新的 索引,字段 “session_id” 禁用了 DocValues :DELETE /my_index PUT my_index { "mappings": { "properties": { "session_id": { "type": "keyword", "doc_values": false } } } }通过设置 doc_values:false ,这个字段将不能被用于聚合、排序以及脚本操作
-
Logstash
Logstash 是一个具有实时渠道能力的数据收集引擎。使用 JRuby 语言编写。其作者是世界著名的运维工程师乔丹西
塞 (JordanSissel)。
主要特点
- 几乎可以访问任何数据
- 可以和多种外部应用结合
- 支持弹性扩展
它由三个主要部分组成
- Shipper-发送日志数据
- Broker-收集数据,缺省内置 Redis
- Indexer-数据写入
官网
https://www.elastic.co/guide/en/logstash/current/index.html
介绍
| Logstash就是一个具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这 根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。 是一个input | filter | output 的数据流。 |
安装Logstash
# 下载
wget [https://artifacts.elastic.co/downloads/logstash/logstash-7.3.0.tar.gz](https://artifacts.elastic.co/downloads/logstash/logstash-7.3.0.tar.gz)
#解压即可
tar -zxvf logstash-7.3.0.tar.gz
Input插件
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
-
stdin标准输入和stdout标准输出 使用标准的输入与输出组件,实现将我们的数据从控制台输入,从控制台输出
cd $LOGSTASHHOME/bin # 控制台输入, 使用rubydebug解码输出 ./logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}' # 输入到logstash hello logstash { "@timestamp" => 2021-08-08T03:19:18.525Z, "@version" => "1", "message" => "hello logstash", "host" => "centos7-1" } -
监控日志文件变化 Logstash 使用一个名叫 FileWatch 的 Ruby Gem 库来监听文件变化。这个库支持 glob 展开文件路径,而且会记录 一个叫 .sincedb 的数据库文件来跟踪被监听的日志文件的当前读取位置。所以,不要担心 Logstash 会漏过你的数据。
- 编写脚本
cd $LOGSTASHHOME/config vim monitor_file.conf # 写入以下内容 input{ file{ path => "/opt/servers/es/datas/tomcat.log" type => "log" start_position => "beginning" } } output{ stdout{ codec => rubydebug } }补充:start_position => “beginning”或者是”end”
- 检查配置文件是否可用
cd ../bin/ ./logstash -f ../config/monitor_file.conf -t # 配置格式正确 Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash -
启动服务 启动监听
./logstash -f ../config/monitor_file.conf发送数据
新开窗口通过以下命令发送数据echo "hello logstash" >> /opt/servers/es/datas/tomcat.log #接收到的数据 { "type" => "log", "message" => "Oh my god, it work", "host" => "centos7-1", "@timestamp" => 2021-08-08T03:35:46.039Z, "path" => "/opt/servers/es/datas/tomcat.log", "@version" => "1" } - 其它参数说明
Path=>表示监控的文件路径
Type=>给类型打标记,用来区分不同的文件类型。
Start_postion=>从哪里开始记录文 件,默认是从结尾开始标记,要是你从头导入一个文件就把改成”beginning”.
discover_interval=>多久去监听path下 是否有文件,默认是15s
exclude=>排除什么文件
close_older=>一个已经监听中的文件,如果超过这个值的时间内 没有更新内容,就关闭监听它的文件句柄。默认是3600秒,即一个小时。
sincedb_path=>监控库存放位置(默认的 读取文件信息记录在哪个文件中)。默认在:/data/plugins/inputs/file。
sincedb_write_interval=> Logstash 每隔多 久写一次 sincedb 文件,默认是 15 秒。
stat_interval=>Logstash 每隔多久检查一次被监听文件状态(是否有更 新),默认是 1 秒。
- 编写脚本
-
jdbc插件 jdbc插件可以采集某张数据库表当中的数据到Logstash当中来
- 准备数据
use test; CREATE TABLE `user` ( `id` bigint(20) NOT NULL, `user_name` varchar(25) DEFAULT NULL, `gender` varchar(20) DEFAULT NULL, `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `user` VALUES (1, 'zhangsan', 'male', '2020-10-1 00:00:00'); INSERT INTO `user` VALUES (2, 'lisi', 'female', '2020-10-1 00:00:00'); -
编写脚本 本地实际情况修改配置信息,并准备jdbc driver
cd $LOGSTASHHOME/config vim jdbc.conf # 写入以下内容 input { jdbc { jdbc_driver_library => "/opt/servers/es/mysql-connector-java-5.1.49.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://centos7-3:3306/test" jdbc_user => "hive" jdbc_password => "12345678" use_column_value => "true" clean_run => "false" record_last_run => "true" tracking_column => "id" schedule => "* * * * *" last_run_metadata_path => "/opt/servers/es/.Logstash_user_jdbc_last_run" statement => "SELECT * from user where id > :sql_last_value;" } } output { stdout { codec=>rubydebug } } - 启动服务
cd $LOGSTASHHOME/bin # 检查配置文件是否可用 ./logstash -f ../config/jdbc.conf -t # 启动服务 ./logstash -f ../config/jdbc.conf数据库当中添加数据
在我们的数据库当中手动随便插入数据,发现我们的Logstash可以进行收集,并且会记录最后一次获取到数据的位置到/opt/servers/es/.Logstash_user_jdbc_last_run
- 准备数据
-
systlog插件 syslog机制负责记录内核和应用程序产生的日志信息,管理员可以通过查看日志记录,来掌握系统状况
默认系统已经安装了rsyslog.直接启动即可- 编写脚本
cd $LOGSTASHHOME/config vim syslog.conf # 写入以下内容 input{ tcp{ port=> 6789 type=> syslog } udp{ port=> 6789 type=> syslog } } filter{ if [type] == "syslog" { grok { match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" } add_field => [ "received_at", "%{@timestamp}" ] add_field => [ "received_from", "%{host}" ] } date { match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } output{ stdout{ codec => rubydebug } } - 启动服务
cd $LOGSTASHHOME/bin # 检查配置文件是否可用 ./logstash -f ../config/syslog.conf -t # 启动服务 ./logstash -f ../config/syslog.conf - 发送数据
修改系统日志配置文件
sudo vim /etc/rsyslog.conf添加一行以下配置
*.* @@centos7-1:6789重启系统日志服务
sudo systemctl restart rsyslog随意执行一个命令即可看到文件被收集了
例如执行以下命令sudo systemctl status firewalld.service
- 编写脚本
filter插件
Logstash之所以强悍的主要原因是filter插件;通过过滤器的各种组合可以得到我们想要的结构化数据。
grok正则表达式是Logstash非常重要的一个环节;可以通过grok非常方便的将数据拆分和索引
语法格式:
(?<name>pattern)
?<name>表示要取出里面的值,pattern就是正则表达式
-
收集控制台输入数据,采集日期时间出来
- 编写脚本
cd $LOGSTASHHOME/config vim filter.conf # 写入以下内容 input {stdin{}} filter { grok { match => { "message" => "(?<date>\d+\.\d+)\s+" } } } output {stdout{codec => rubydebug}} - 启动服务
cd $LOGSTASHHOME/bin # 检查配置文件是否可用 ./logstash -f ../config/filter.conf -t # 启动服务 ./logstash -f ../config/filter.conf - 控制台输入文字
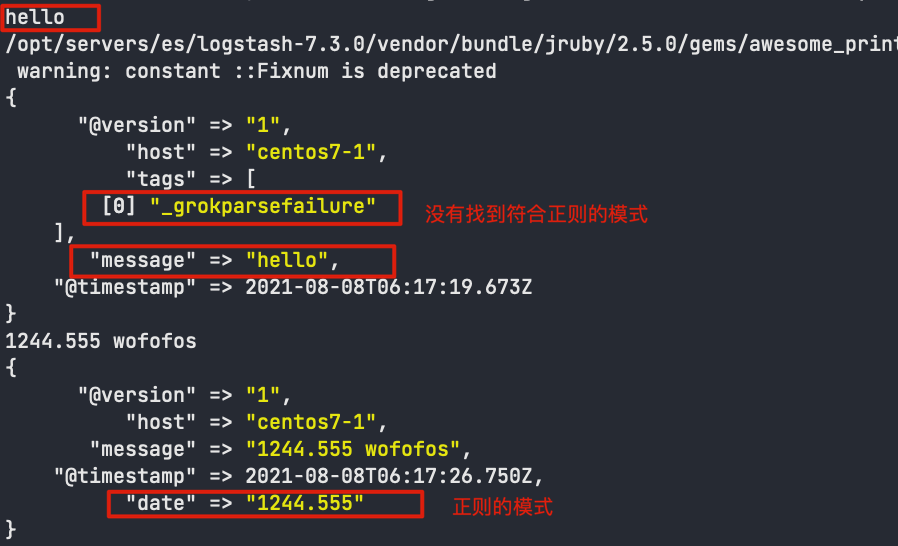
- 编写脚本
-
使用grok收集nginx日志数 nginx一般打印出来的日志格式如下
113.31.119.183 - - [05/Nov/2019:12:59:27 +0800] "GET /phpmyadmin_8c1019c9c0de7a0f/js/messages.php?lang=zh_CN&db=&collation_connection=utf8_unicode_ci&token=6a44d72481633c90bffcfd42f11e25a1 HTTP/1.1" 200 8131 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"这种日志是非格式化的,通常,我们获取到日志后,还要使用mapreduce 或者spark 做一下清洗操作, 就是将非格式化日志编程格式化日志; 在清洗的时候,如果日志的数据量比较大,那么也是需要花费一定的时间的;
所以可以使用Logstash 的grok 功能,将nginx 的非格式化数据采集成格式化数据:- 在线安装grok插件
cd $LOGSTASHHOME vim Gemfile #source 'https://rubygems.org' # 将这个镜像源注释掉 source "https://gems.ruby-china.com/" # 配置成中国的这个镜像源在线安装
cd $LOGSTASHHOME/bin ./logstash-plugin install logstash-filter-grok - 开发Logstash的配置文件
cd $LOGSTASHHOME/config vim monitor_nginx.conf # 写入以下内容 input {stdin{}} filter { grok { match => { "message" => "%{IPORHOST:clientip} \- \- \[%{HTTPDATE:time_local}\] \"(?:%{WORD:method} %{NOTSPACE:request}( ?:HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS:http_referer} %{QS:agent}" } } } output {stdout{codec => rubydebug}} - 启动服务
cd $LOGSTASHHOME/bin # 检查配置文件是否可用 ./logstash -f ../config/monitor_nginx.conf -t # 启动服务 ./logstash -f ../config/monitor_nginx.conf - 从控制台输入nginx日志文件数据
# nginx样例数据 113.31.119.183 - - [05/Nov/2019:12:59:27 +0800] "GET /phpmyadmin_8c1019c9c0de7a0f/js/messages.php?lang=zh_CN&db=&collation_connection=utf8_unicode_ci&token=6a44d72481633c90bffcfd42f11e25a1 HTTP/1.1" 200 8131 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
- 在线安装grok插件
Output插件
-
标准输出到控制台 将收集的数据直接打印到控制台
./bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}' -
将采集数据保存到file文件中 Logstash也可以将收集到的数据写入到文件当中去永久保存
- 配置文件
cd $LOGSTASHHOME/config vim output_file.conf # 写入以下内容 input {stdin{}} output { file { path => "/opt/servers/es/datas/%{+YYYY-MM-dd}-%{host}.txt" codec => line { format => "%{message}" } flush_interval => 0 } } - 启动服务
cd $LOGSTASHHOME/bin # 检查配置文件是否可用 ./logstash -f ../config/output_file.conf -t # 启动服务 ./logstash -f ../config/output_file.conf查看文件写入的内容
cd /opt/servers/es/datas
- 配置文件
-
将采集数据保存到elasticsearch
- 配置文件
cd $LOGSTASHHOME/config vim output_es.conf # 写入以下内容 input {stdin{}} output { elasticsearch { hosts => ["centos7-1:9200"] index => "logstash-%{+YYYY.MM.dd}" } }这个index是保存到elasticsearch上的索引名称,如何命名特别重要,因为我们很可能后续根据某些需求做查询,所 以最好带时间
- 启动服务
cd $LOGSTASHHOME/bin # 检查配置文件是否可用 ./logstash -f ../config/output_es.conf -t # 启动服务 ./logstash -f ../config/output_es.conf
- 配置文件
日志分析平台实战
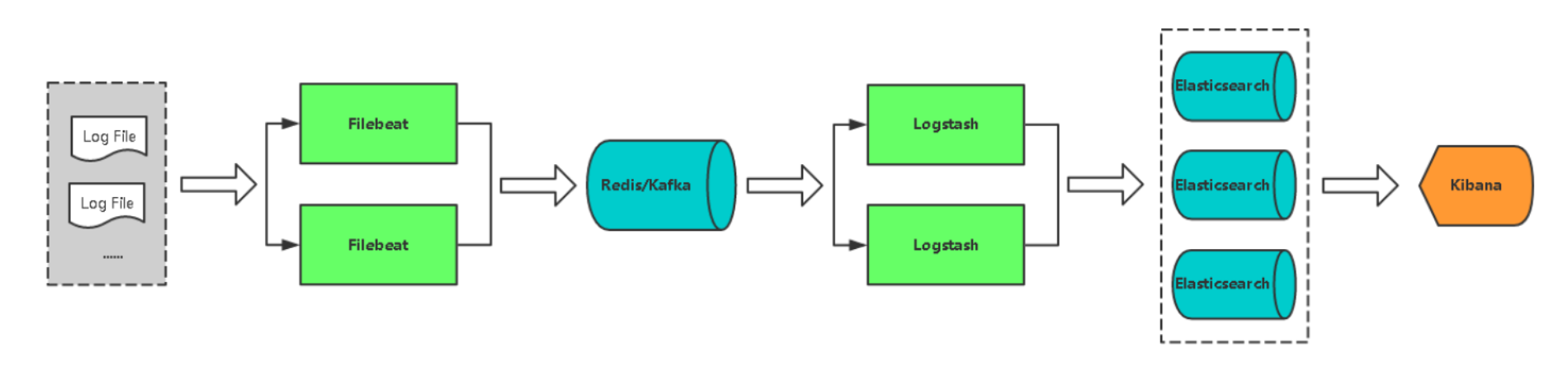
日志分析平台架构图
Nginx安装
1、安装git工具,安装wget下载工具
yum install wget git -y
yum install gcc-c++ -y
2 、下载nginx源码包
cd /usr/local/src
wget http://nginx.org/download/nginx-1.17.8.tar.gz
tar -zxvf nginx-1.17.8.tar.gz
cd nginx-1.17.8
yum install gcc zlib zlib-devel openssl openssl-devel pcre pcre-devel -y
3、进入到nginx的源码目录下(编译nginx)
cd /usr/local/src/nginx-1.17.8
./configure
make && make install
4、启动Nginx
Nginx配置文件路径:/usr/local/nginx/conf
cd /usr/local/nginx/
#启动nginx
/usr/local/nginx/sbin/nginx
如果报错端口被占用,修改Nginx的默认端口
cd /usr/local/nginx/conf
vim nginx.conf
# 把默认端口修改为8080或者8888
server{
listen 8080;
...
5、验证nginx是否启动
ps -ef | grep nginx
查找nginx的访问日志
cd /usr/local/nginx/logs
tail -f access.log
浏览器访问nginx
http://192.168.0.200:8080
6、修改日志格式为JSON格式
调整nginx产生的日志为json格式,减少Logstash的开销(虽然使用正则可以方便提取出字段,但是效率不高)
log_format json '{ "@timestamp": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"request_uri": "$request_uri", '
'"request_method": "$request_method", '
'"http_referrer": "$http_referer", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent"}';
添加到nginx.conf中
重启nginx,验证日志格式
/usr/local/nginx/sbin/nginx -s reload
Filebeat
Filebeat主要是为了解决Logstash工具比较消耗资源比较重的问题,因为Logstash是Java语言编写,所以官方推出了一些轻量级的采集工具,推出了Beats系列,其中使用比较广泛的是Filebeat。
官方地址
https://www.elastic.co/guide/en/beats/filebeat/7.3/index.html
- Filebeat与Logstash区别
- Logstash是运行在jvm,资源消耗比较大,启动一个Logstash就需要消耗500M左右的内存(这就是为什么 Logstash启动特别慢的原因),而filebeat只需要10来M内存资源。
- 常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat发送Kafka集群, Logstash消费kafka数据,Logstash根据配置文件进行过滤。然后将过滤之后的文件输送到elasticsearch 中,通过kibana去展示。
-
Filebeat安装 1、centos7-3下载Filebeat
cd /opt/servers/ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.0-linux-x86_64.tar.gz2、解压
tar -zxvf filebeat-7.3.0-linux-x86_64.tar.gz mv filebeat-7.3.0-linux-x86_64 filebeat/ cd filebeat3、修改配置文件
vim filebeat.yml
filebeat.inputs: - type: log paths: - /usr/local/nginx/logs/access.log fields: app: www type: nginx-access fields_under_root: true - type: log paths: - /usr/local/nginx/logs/error.log fields: app: www type: nginx-error fields_under_root: true output.kafka: hosts: ["centos7-3:9092"] topic: "nginx_access_log"收集nginx的access与error日志发送到Kafka中。
验证
- 启动zk
- kafka
- 创建topic
- 启动filebeat
./filebeat -e -c filebeat.yml启动控制台消费者
bin/kafka-console-consumer.sh --bootstrap-server centos7-3:9092 --topic nginx_access_log --from-beginning
Logstash读取Kafka
Kafka Input
https://www.elastic.co/guide/en/logstash/7.3/plugins-inputs-kafka.html
- Logstash配置文件
input { kafka { bootstrap_servers => "centos7-1:9092,centos7-2:9092,centos7-3:9092" topics => ["nginx_access_log"] codec => "json" } } filter { if [app] == "www" { if [type] == "nginx-access" { json { source => "message" remove_field => ["message"] } geoip { source => "remote_addr" target => "geoip" database => "/opt/servers/es/datas/GeoLite2-City.mmdb" add_field => ["[geoip][coordinates]", "%{[geoip][longitude]}"] add_field => ["[geoip][coordinates]", "%{[geoip][latitude]}"] } mutate { convert => ["[geoip][coordinates]", "float"] } } } } output { elasticsearch { hosts => ["http://centos7-1:9200","http://centos7-2:9200","http://centos7-3:9200"] index => "logstash-%{type}-%{+YYYY.MM.dd}" } stdout{codec => rubydebug } } - 启动logstash任务
bin/logstash -f config/logstash_kafka_es.conf
Kibana可视化
-
快速入门
-
添加样例数据
-
添加航班数据
-
es-head查看索引
-
进入仪表盘页面
-
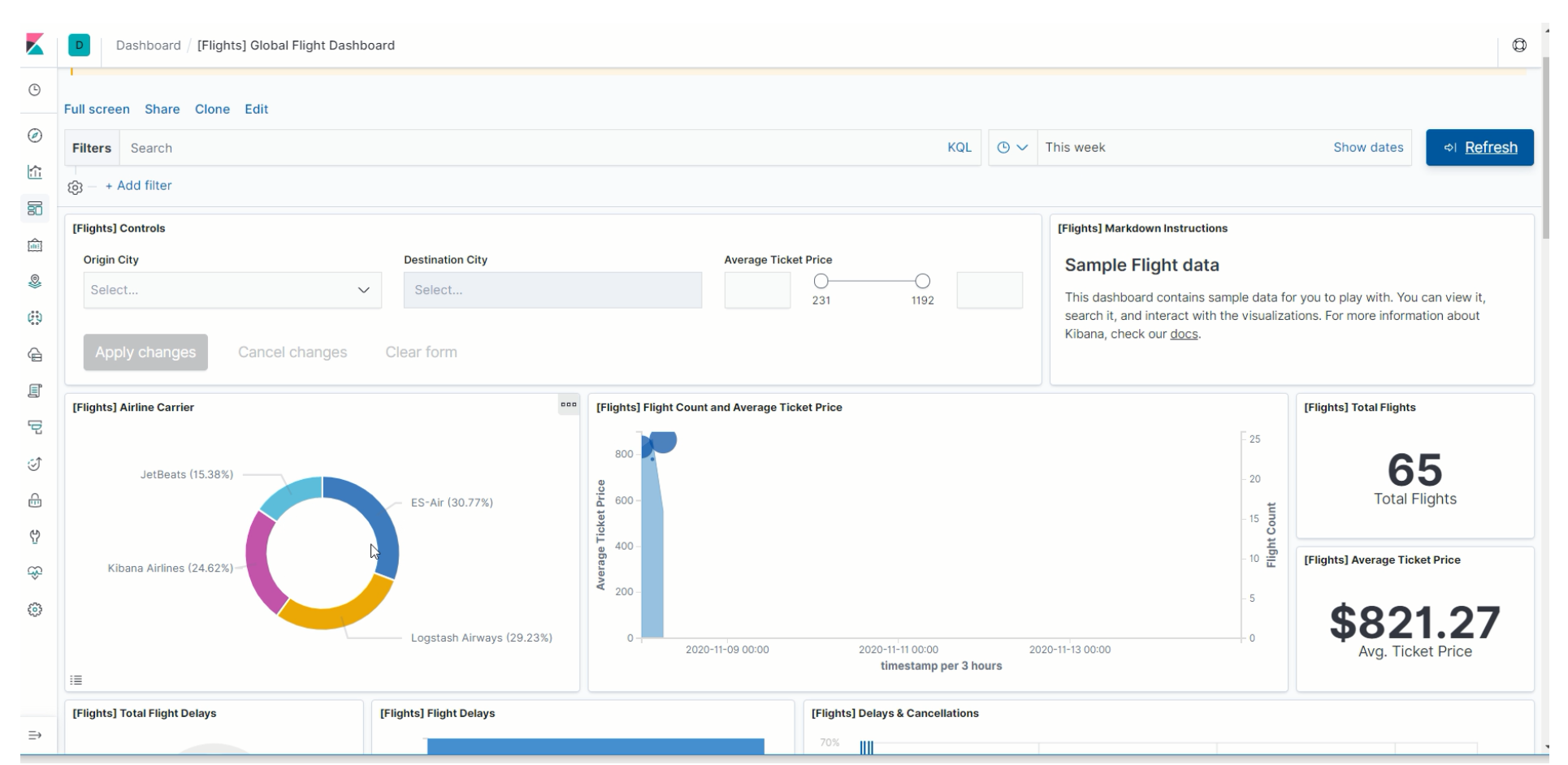
航班数据的相关图表
-
进入管理页面
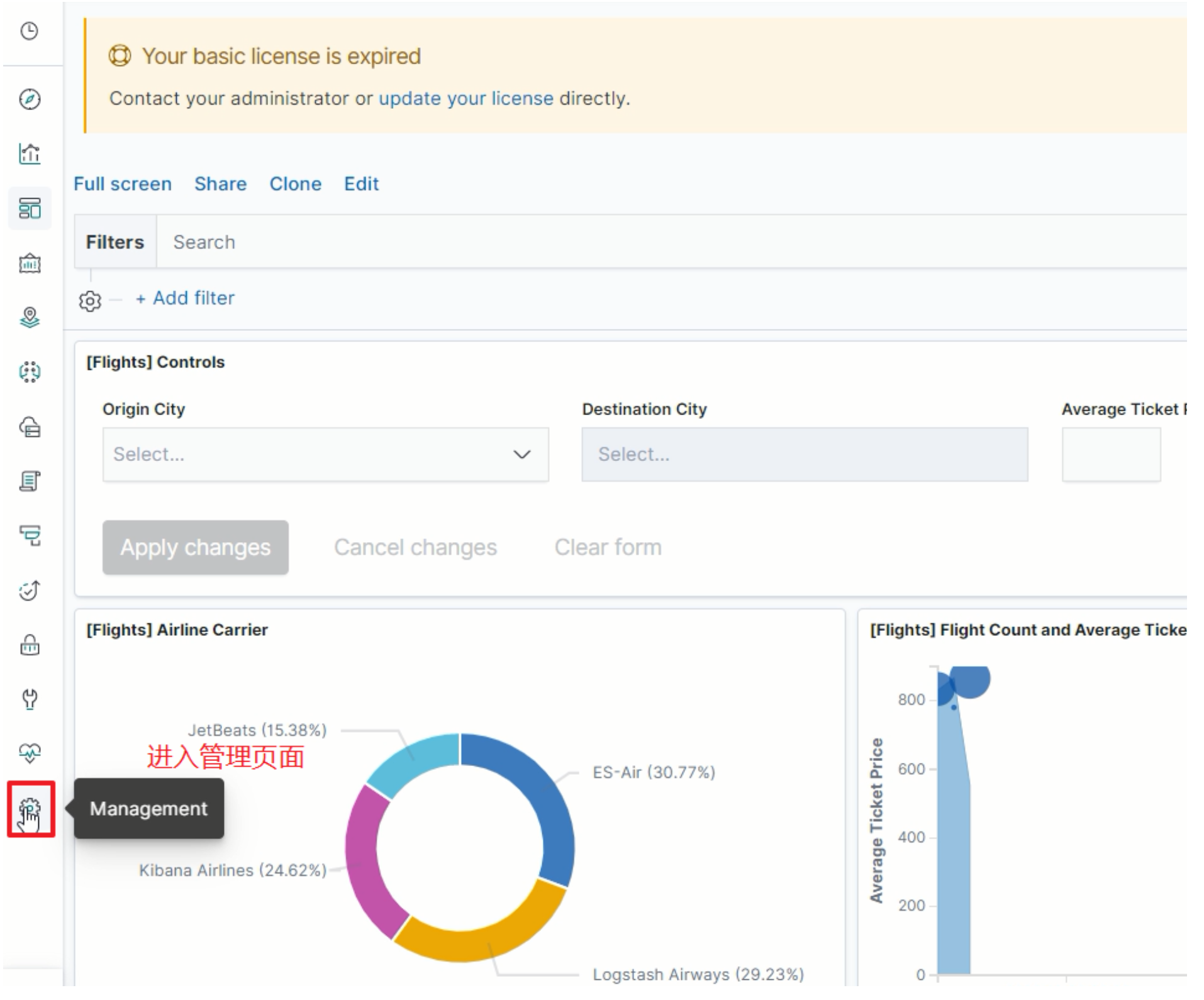
-
进入索引规则配置页面
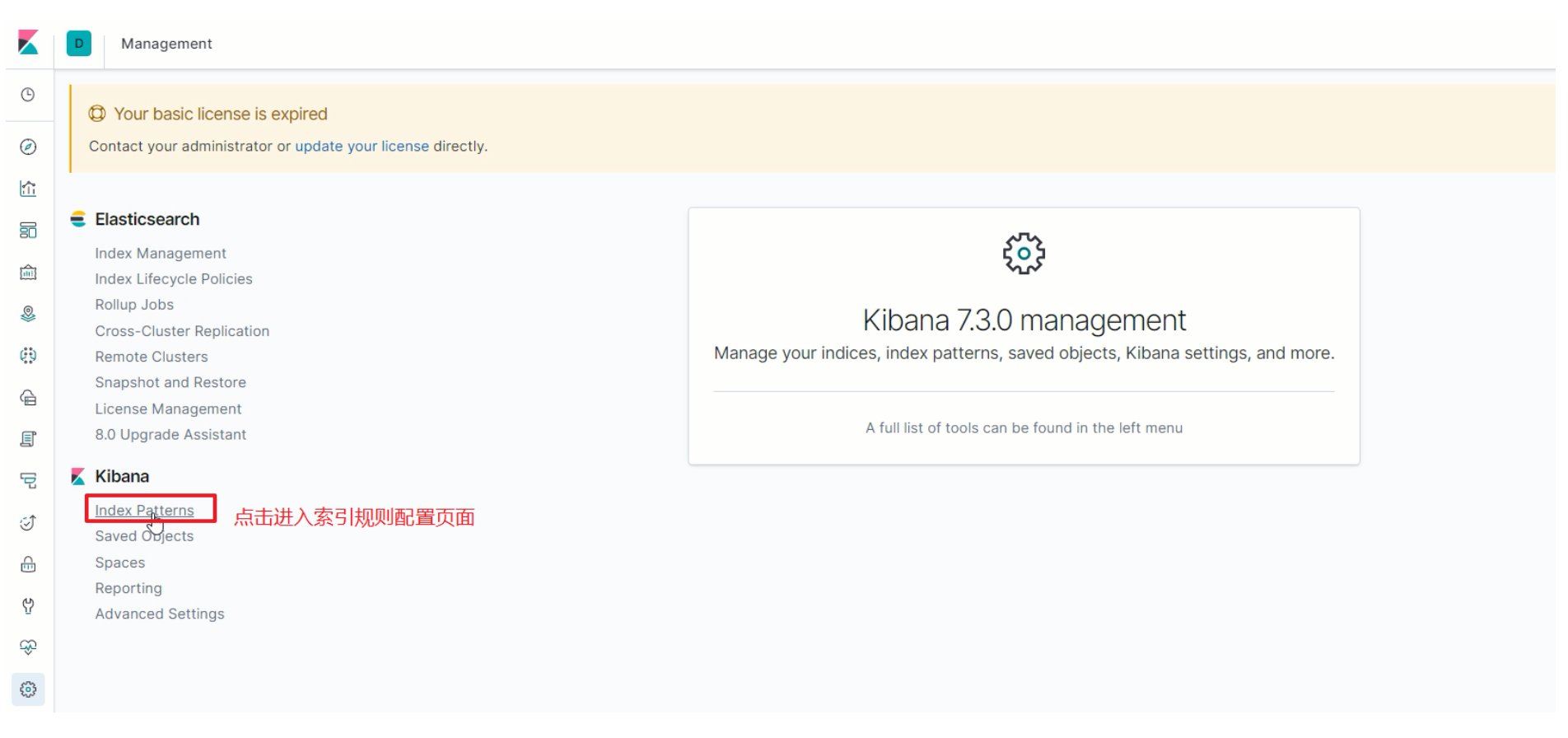
-
创建新的索引规则
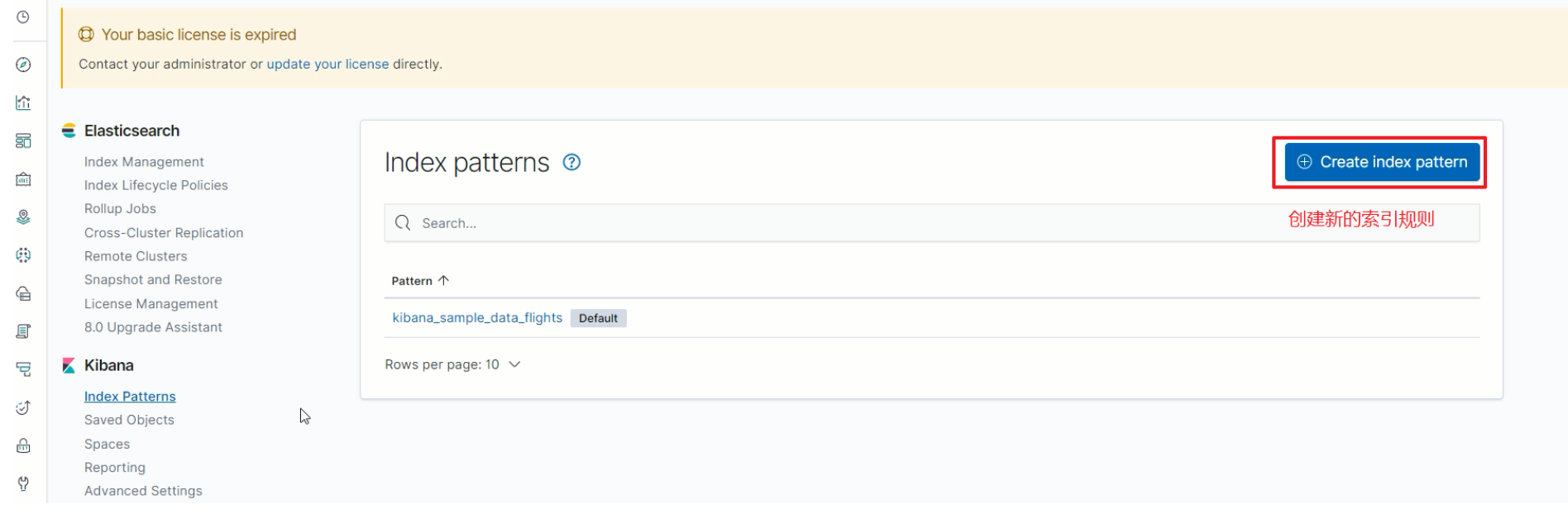
-
匹配到ES中的索引
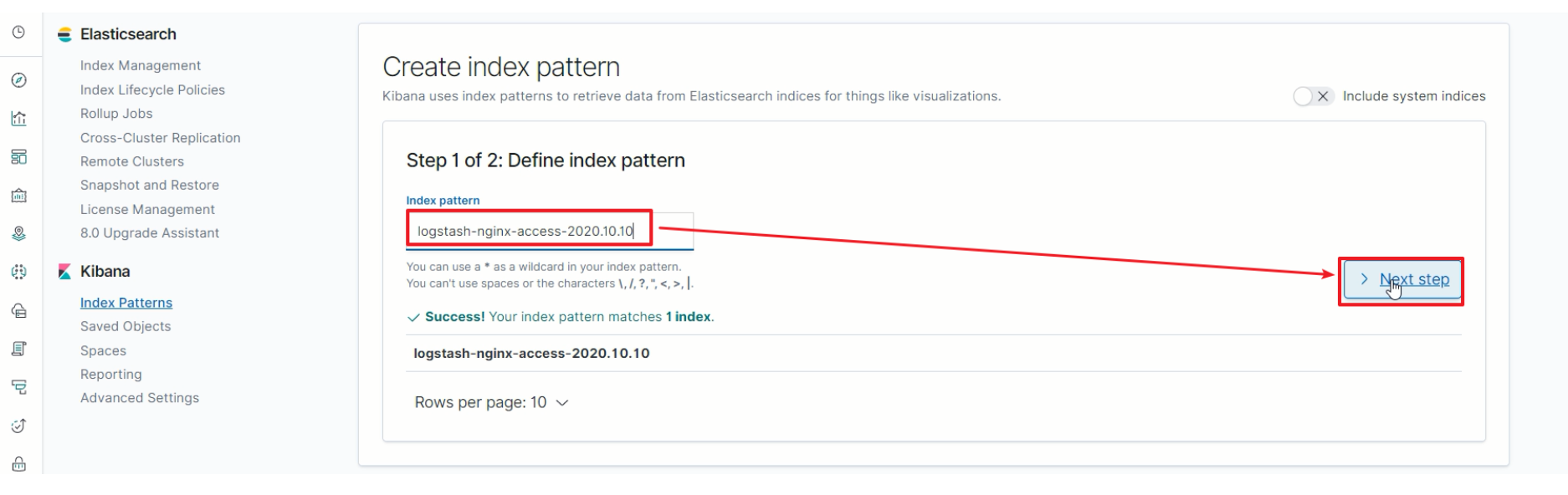
-
展示该索引的所有字段信息
-
探索分析数据
-
创建图表
-
-
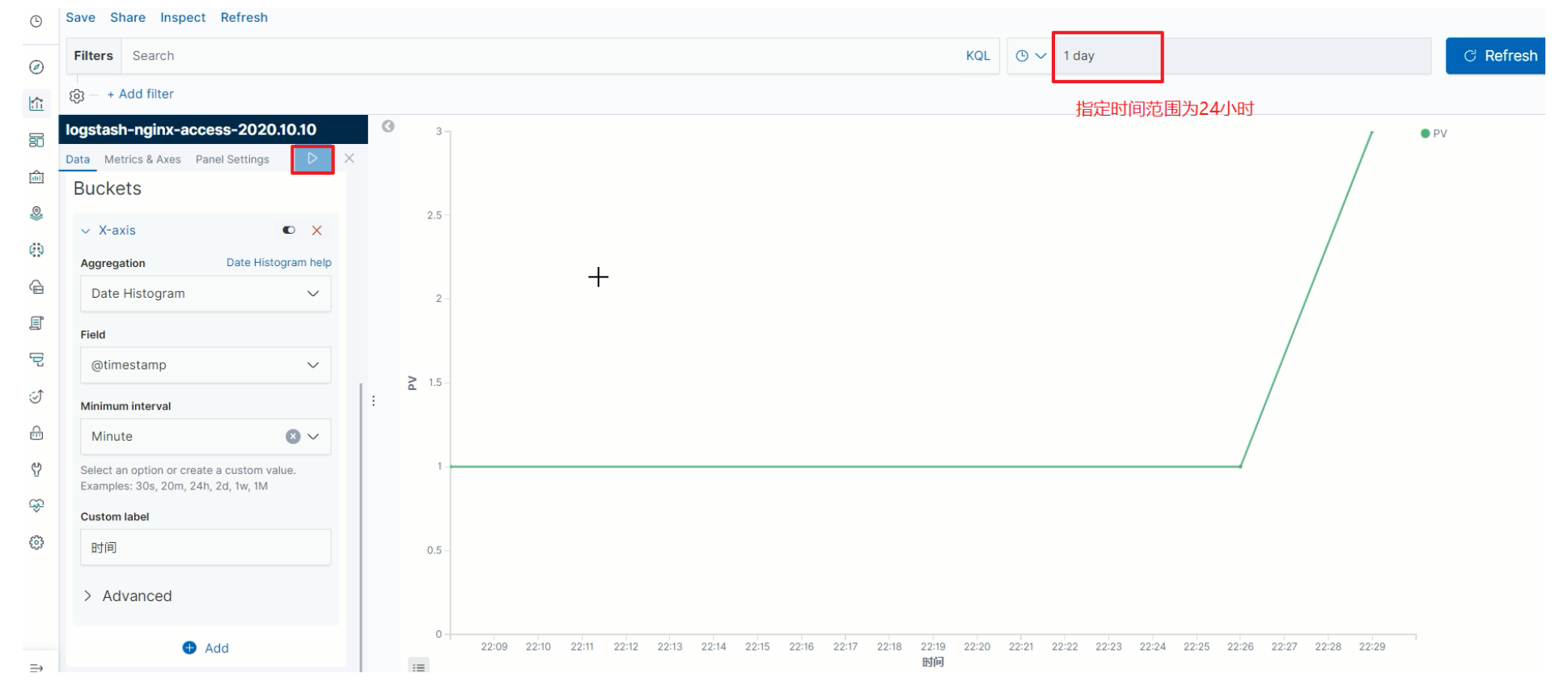
PV
-
选择趋势图
-
指定Y轴
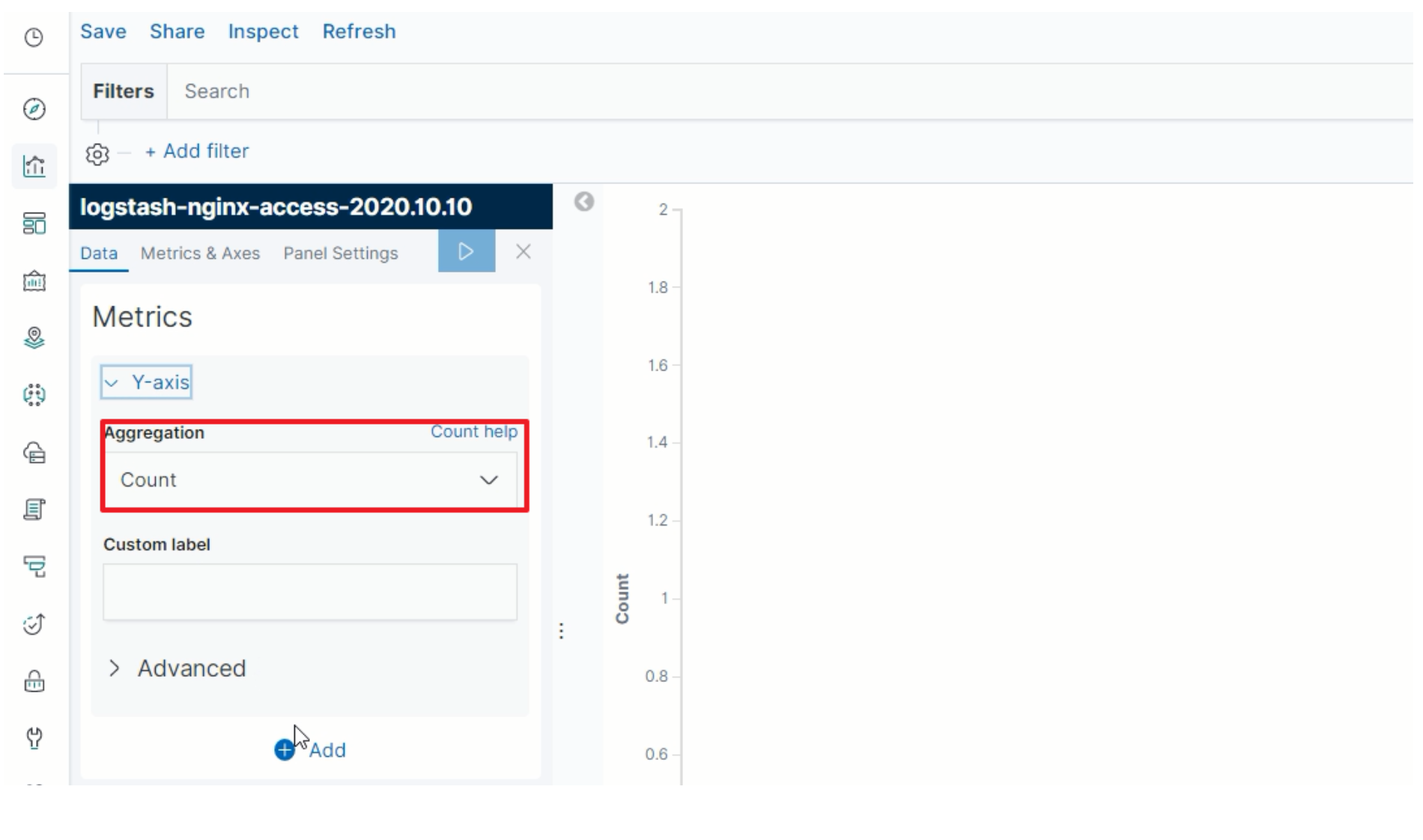
-
指定X轴
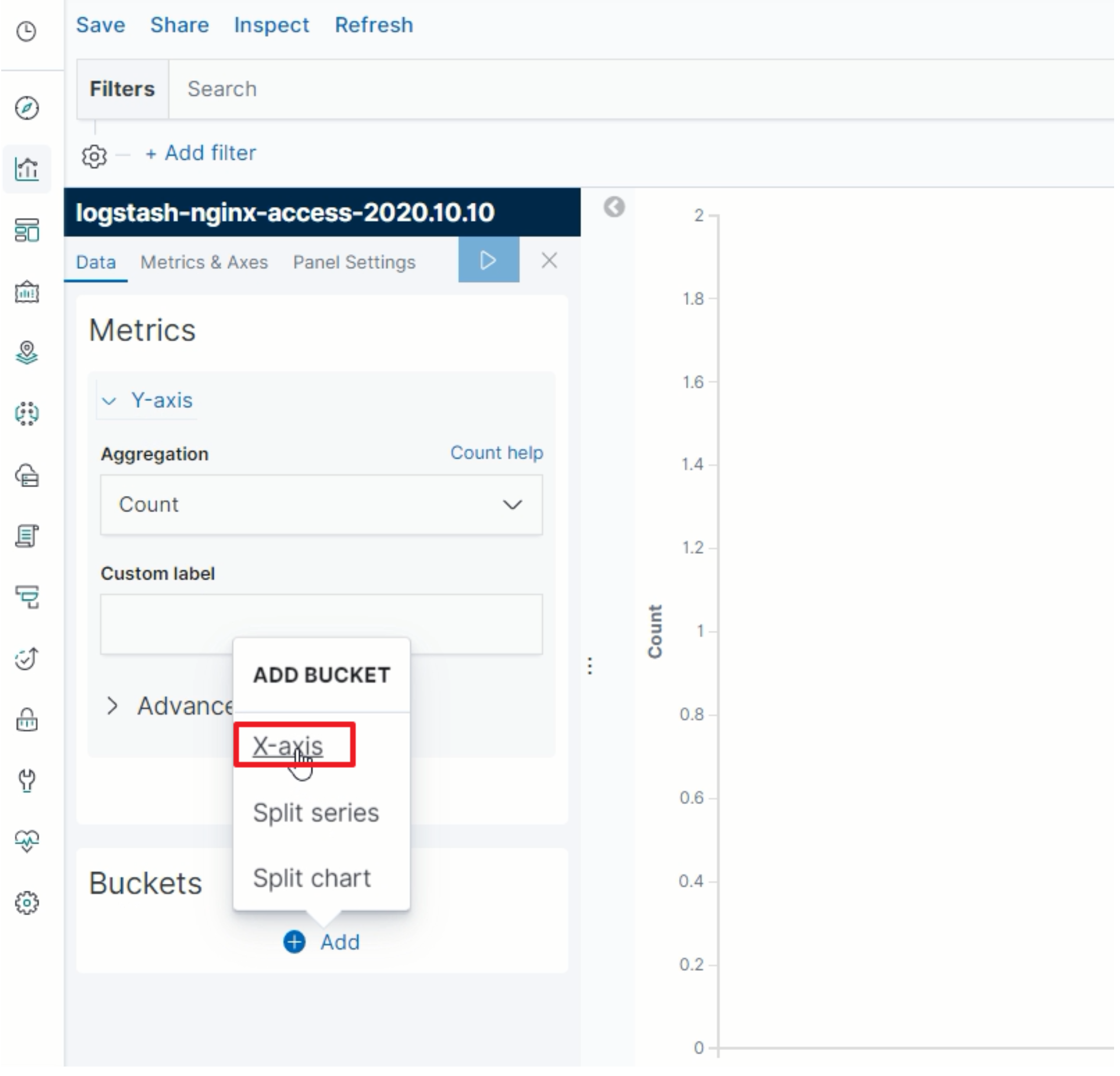
-
指定X轴为时间属性
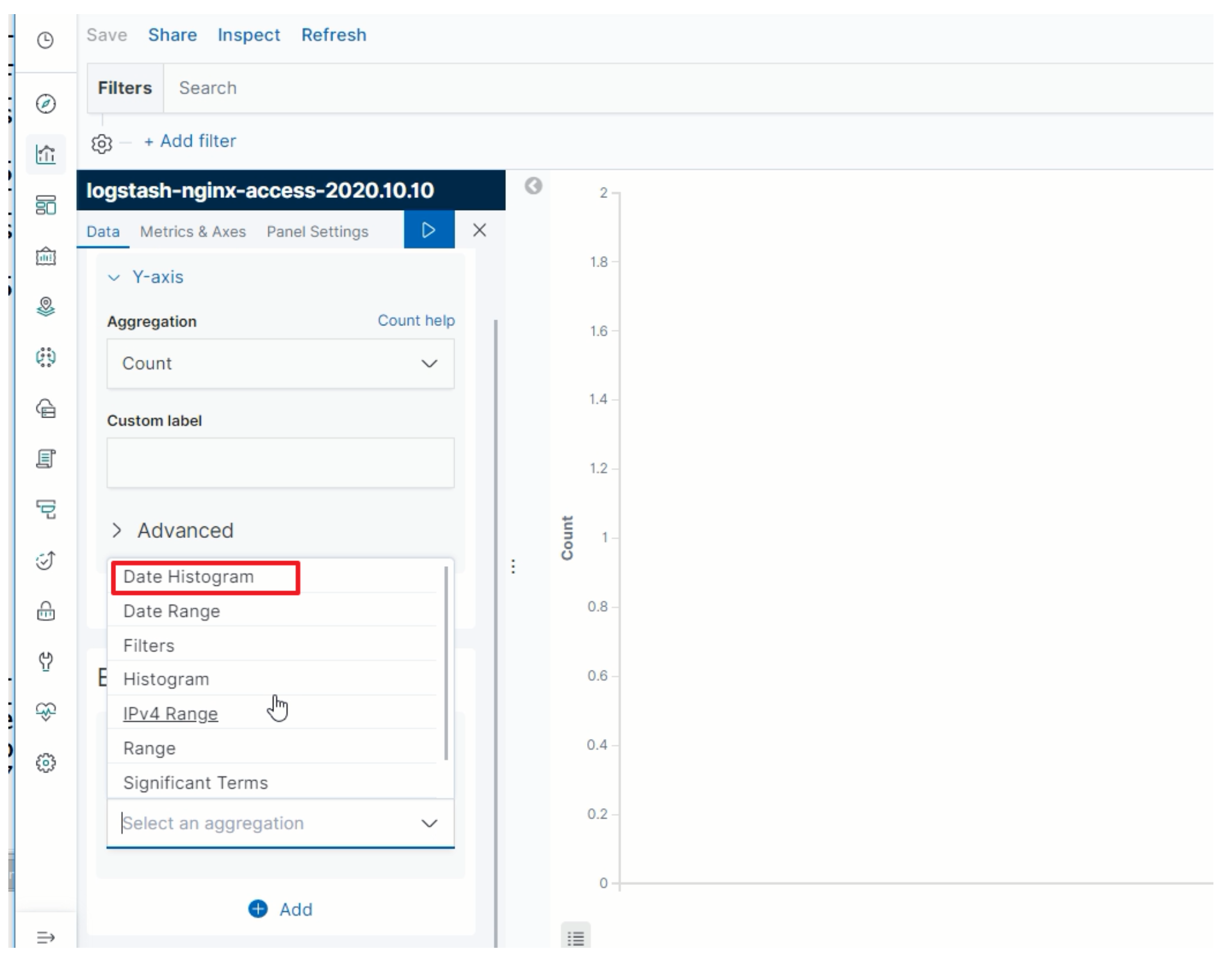
-
选择时间周期为分钟级别
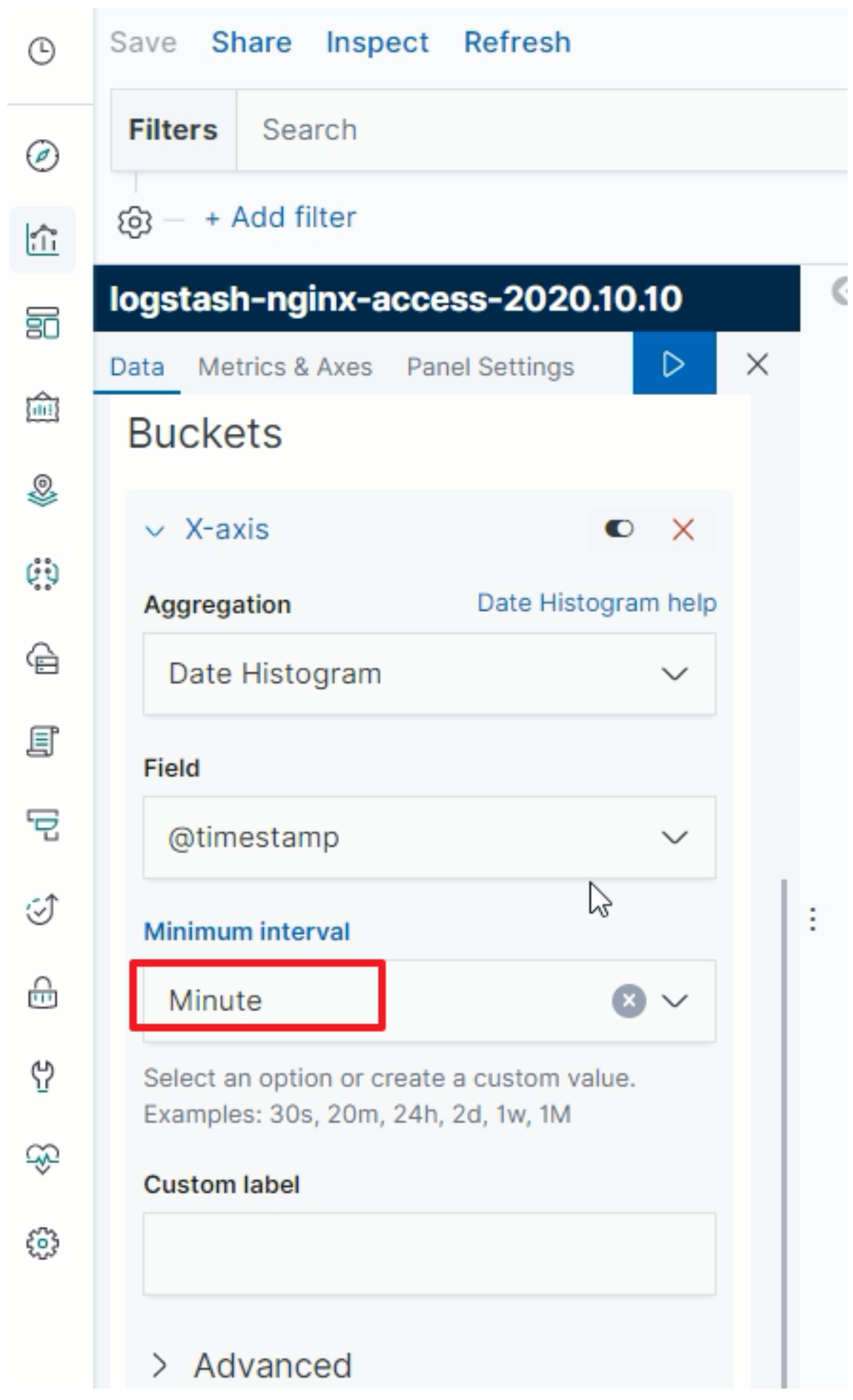
-
点击保存当前图表
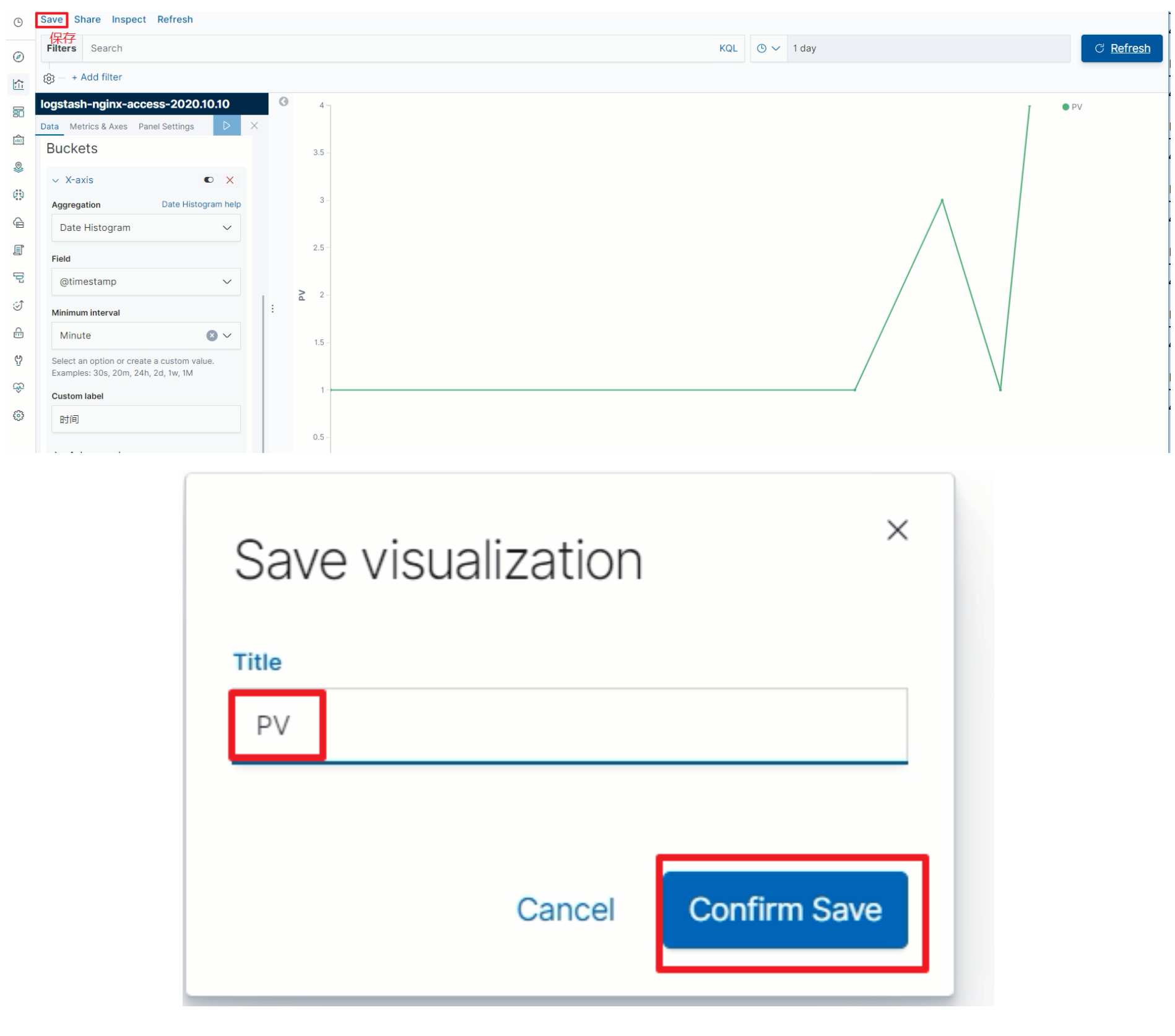
-
-
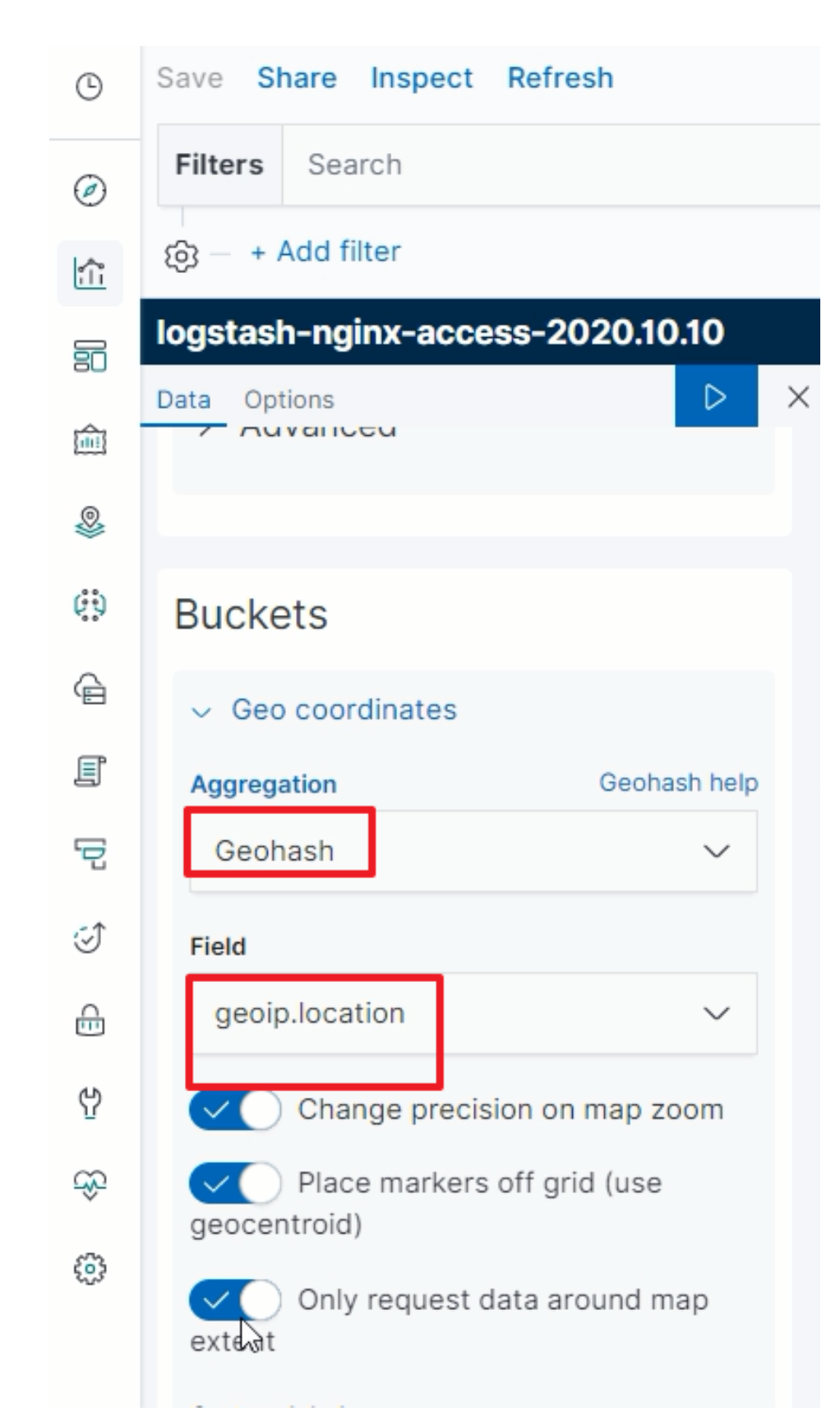
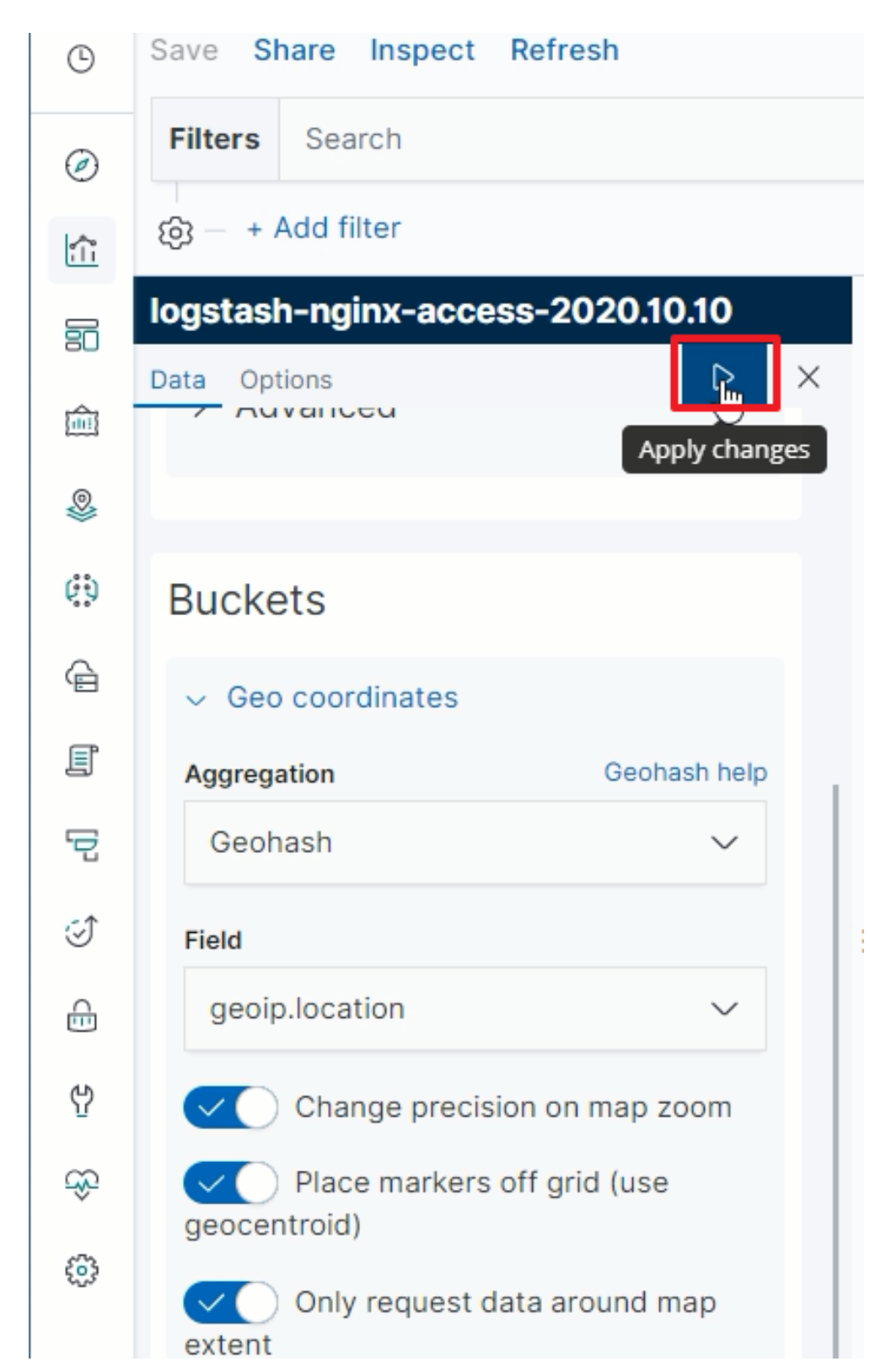
IP地理位置分布
-
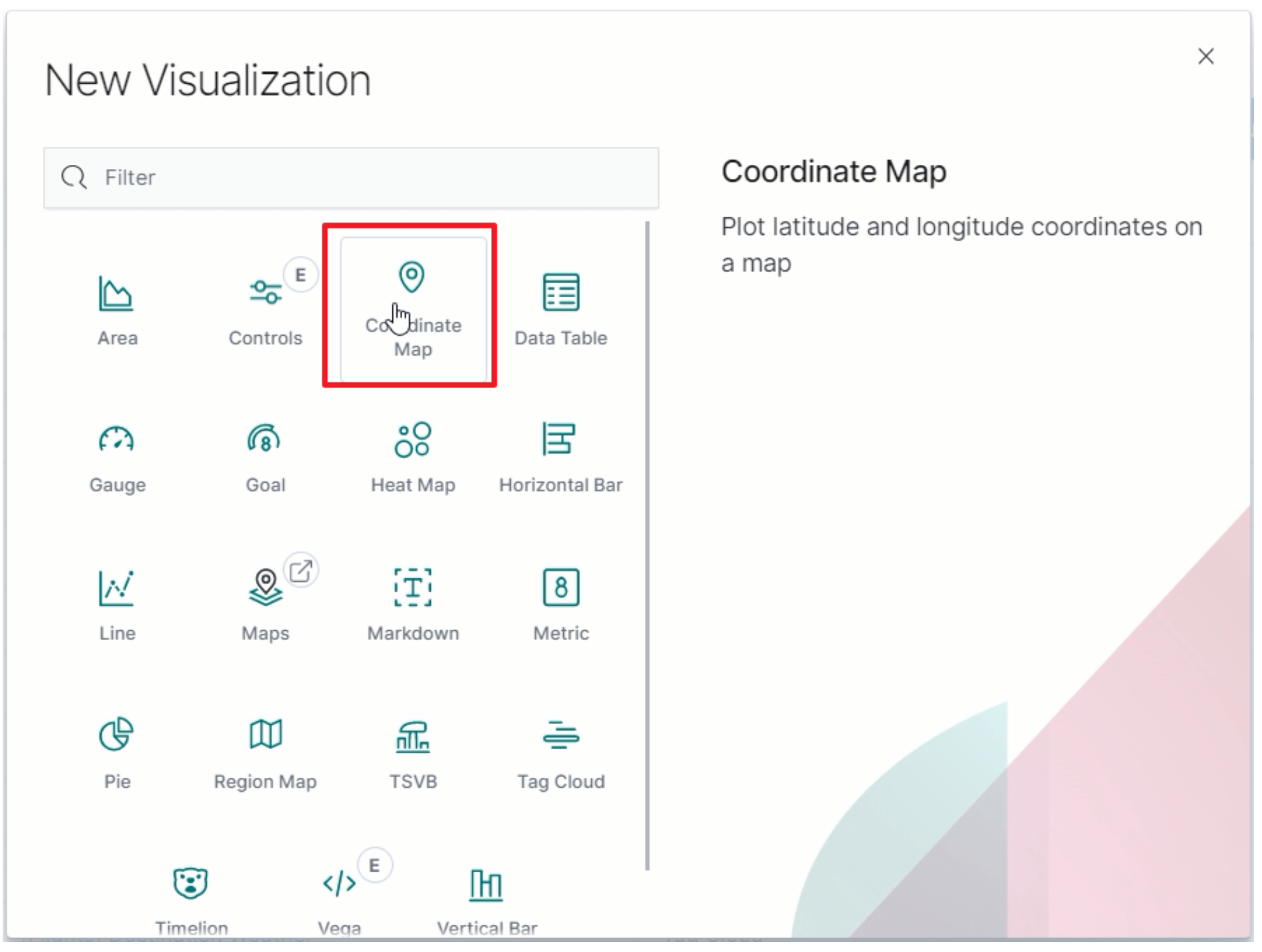
选择图表:Coordinate Map
-
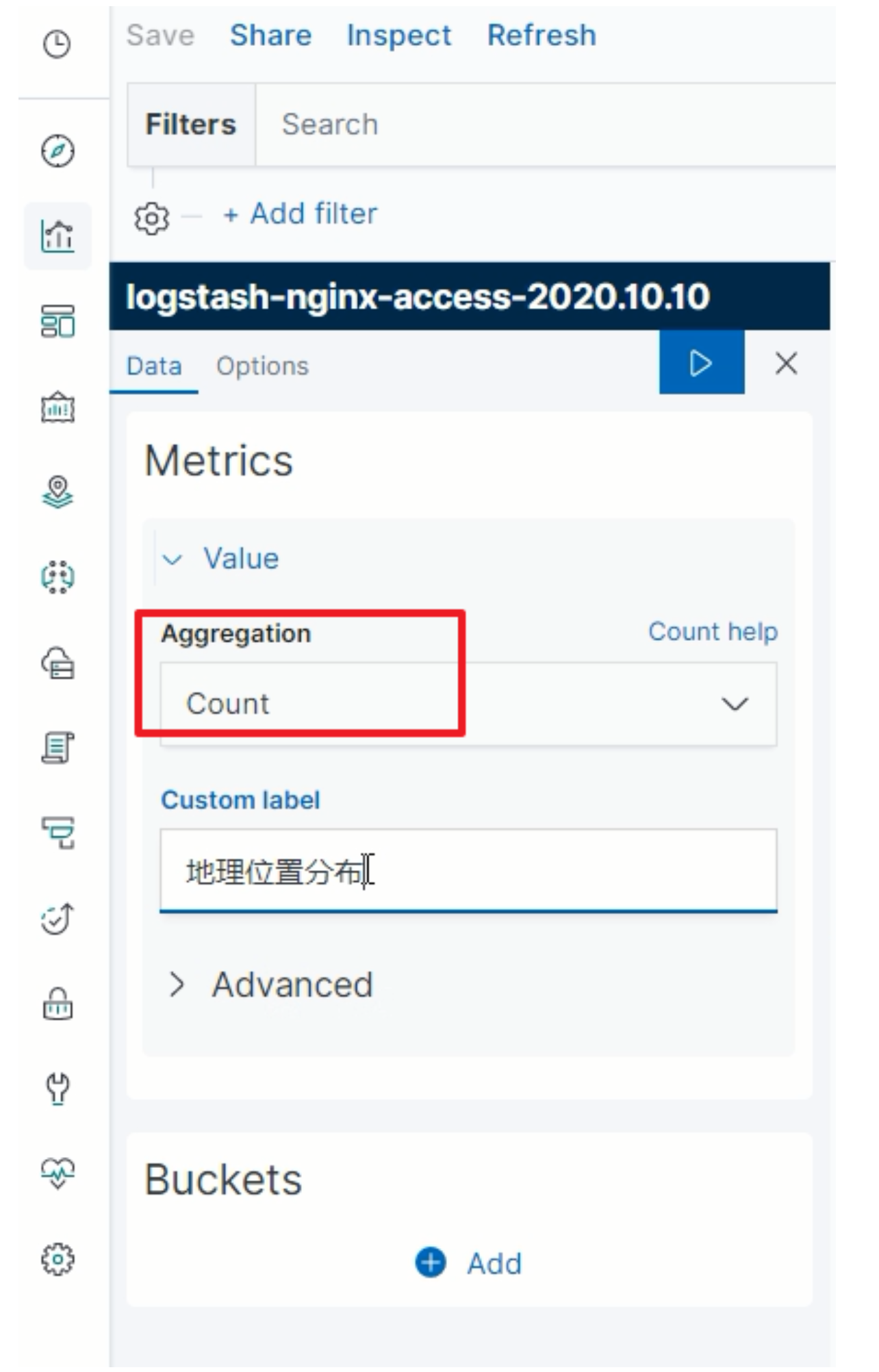
指定聚合统计规则
-
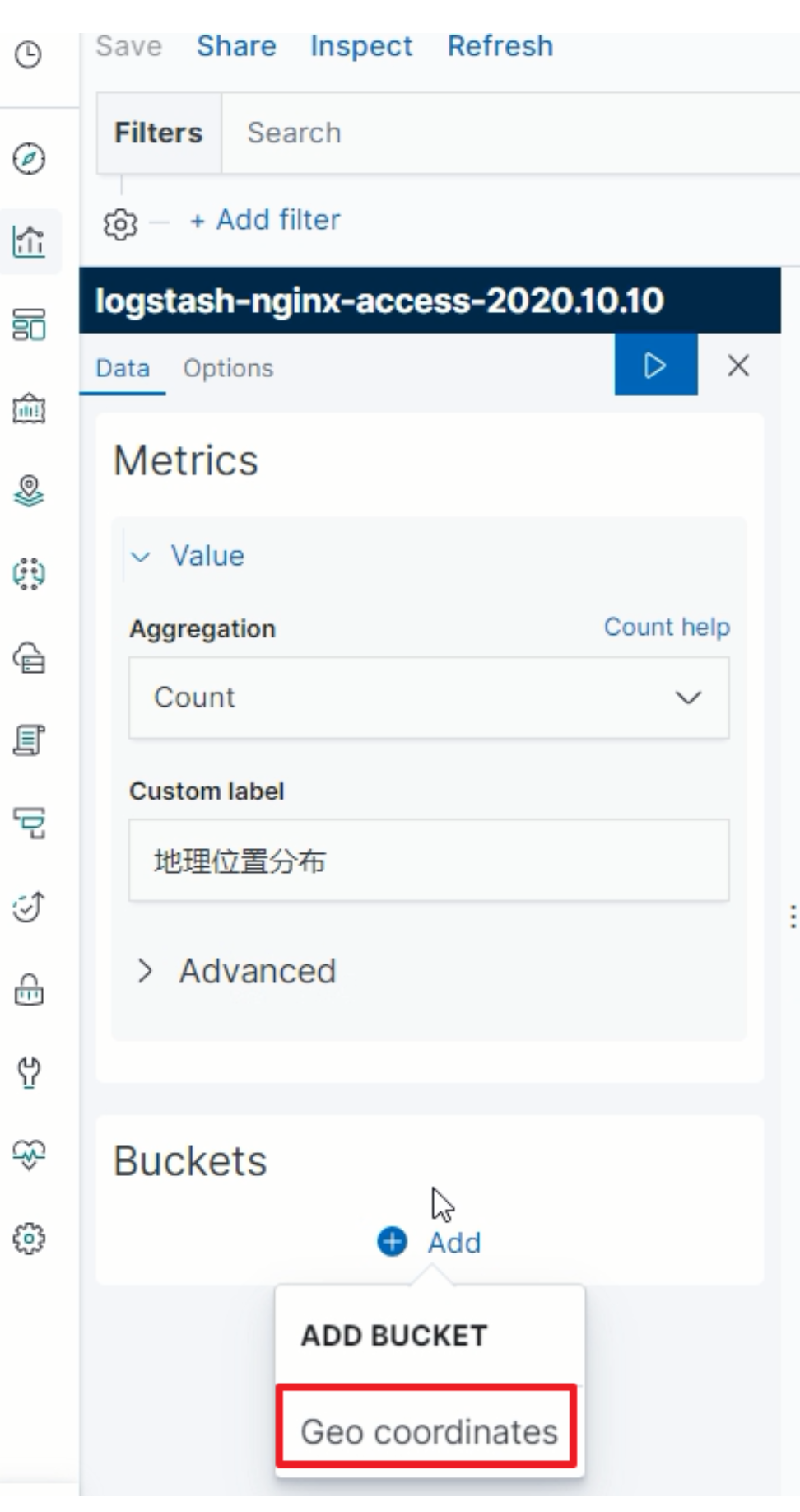
指定GEO规则
-
-
-
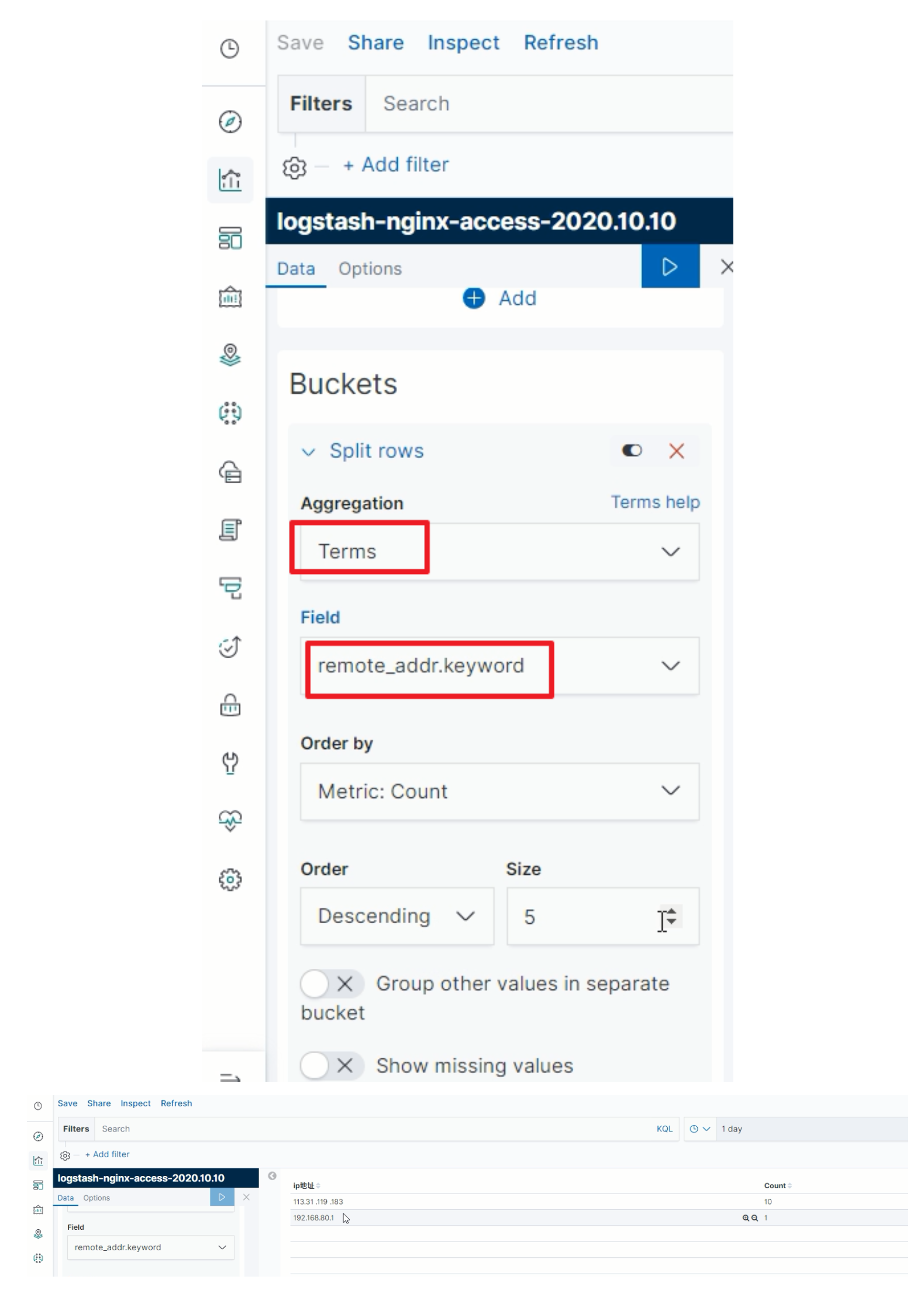
TOPN
-
选择图表
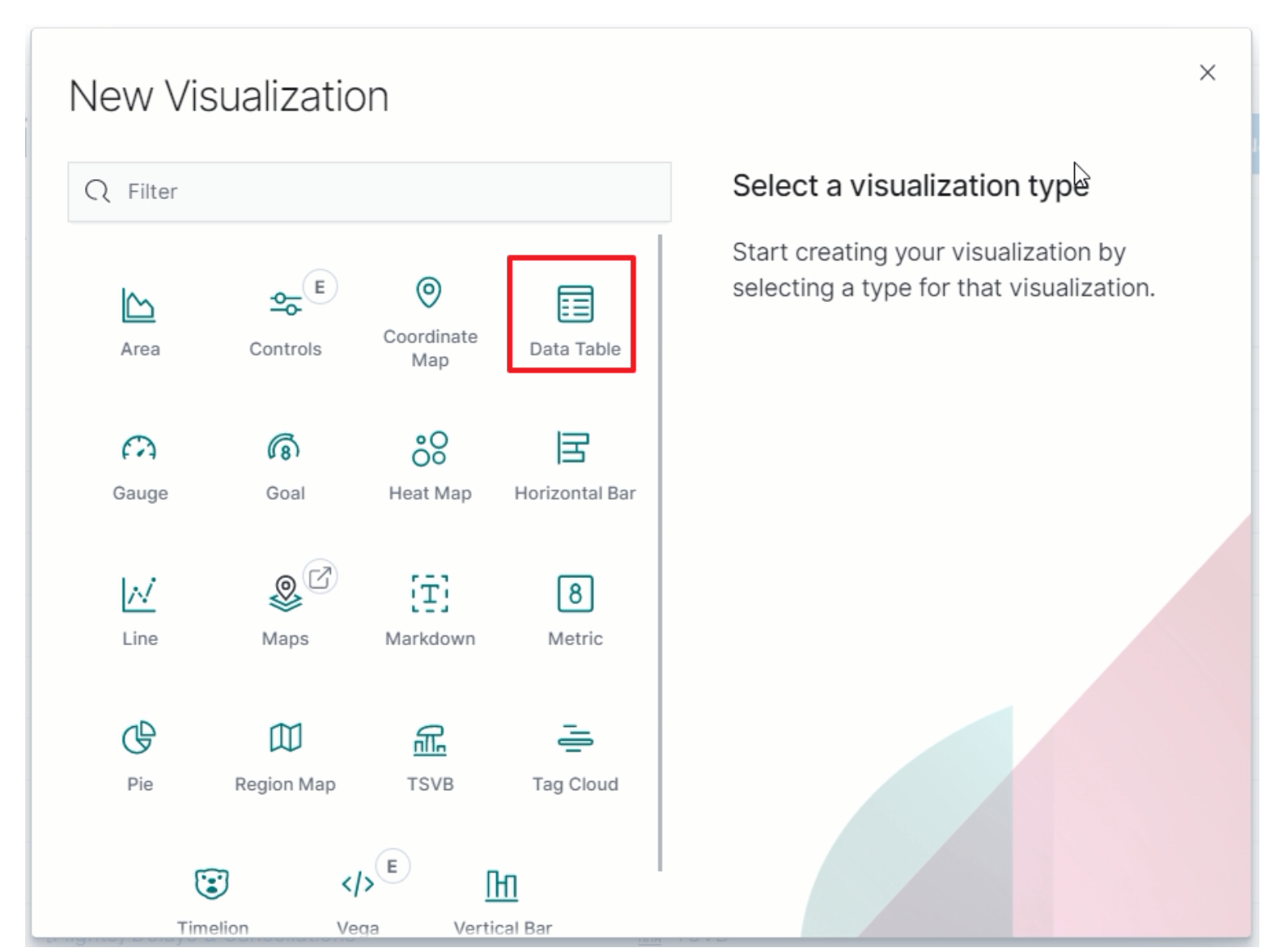
-
指定分组规则
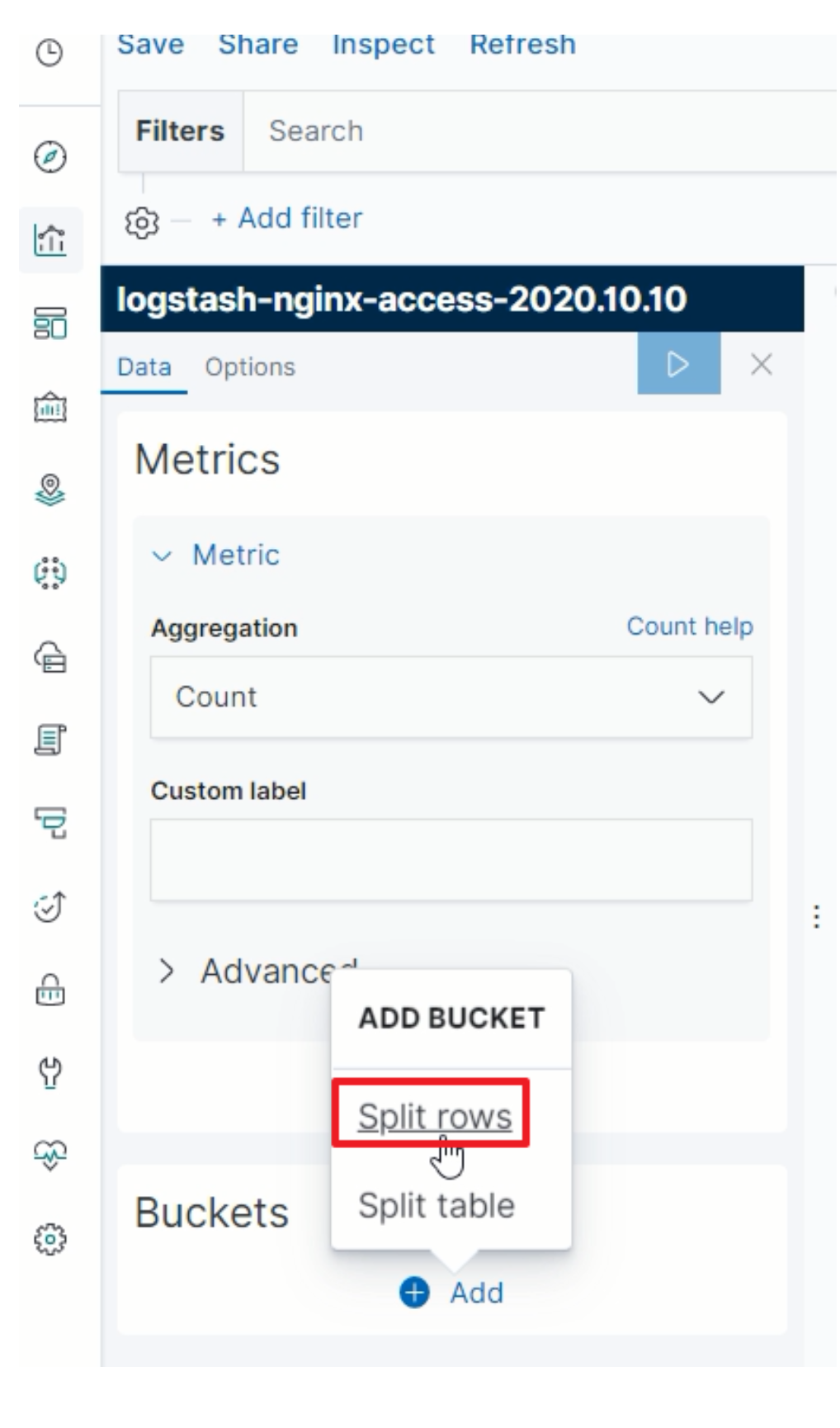
-
-
Dashboard
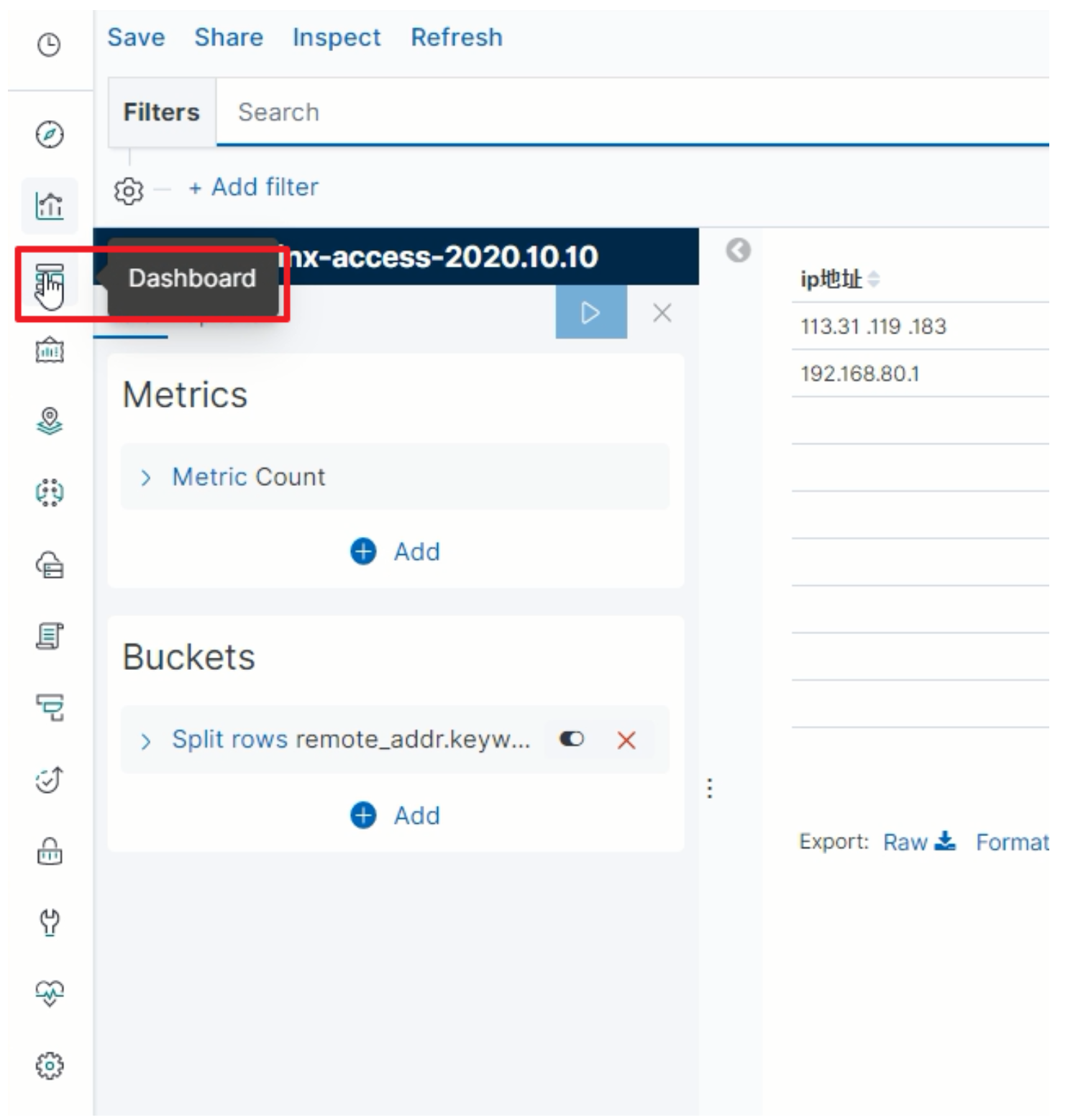
-
创建仪表盘
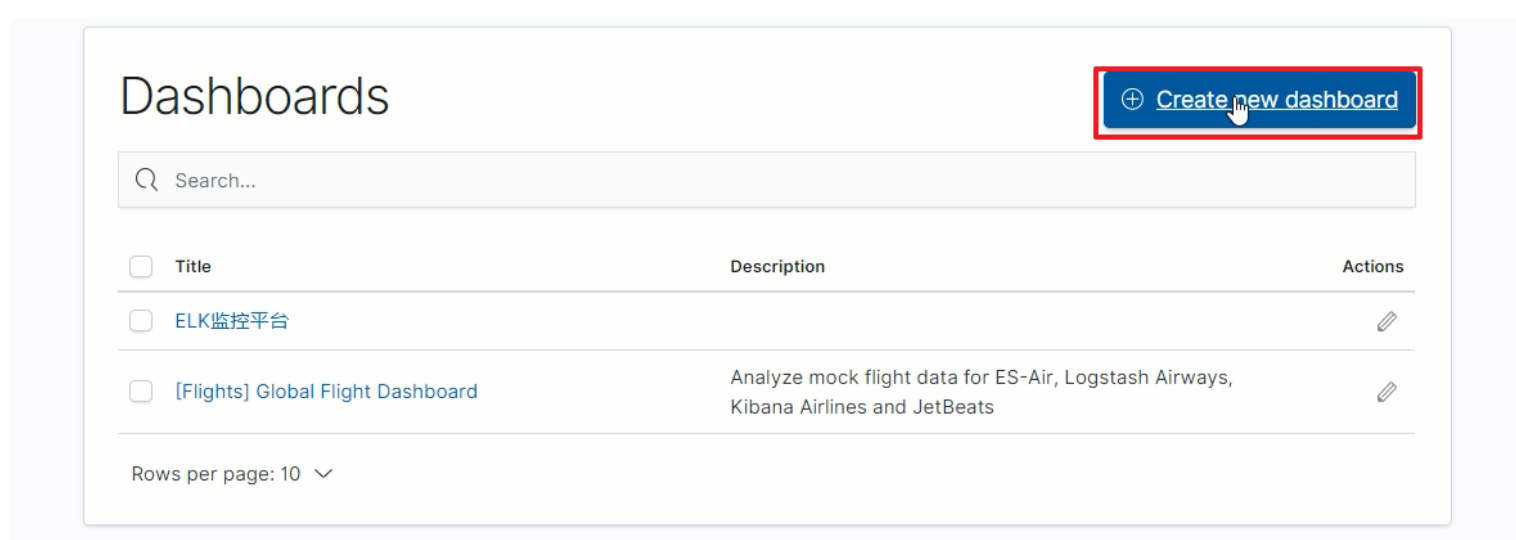
-
添加图表
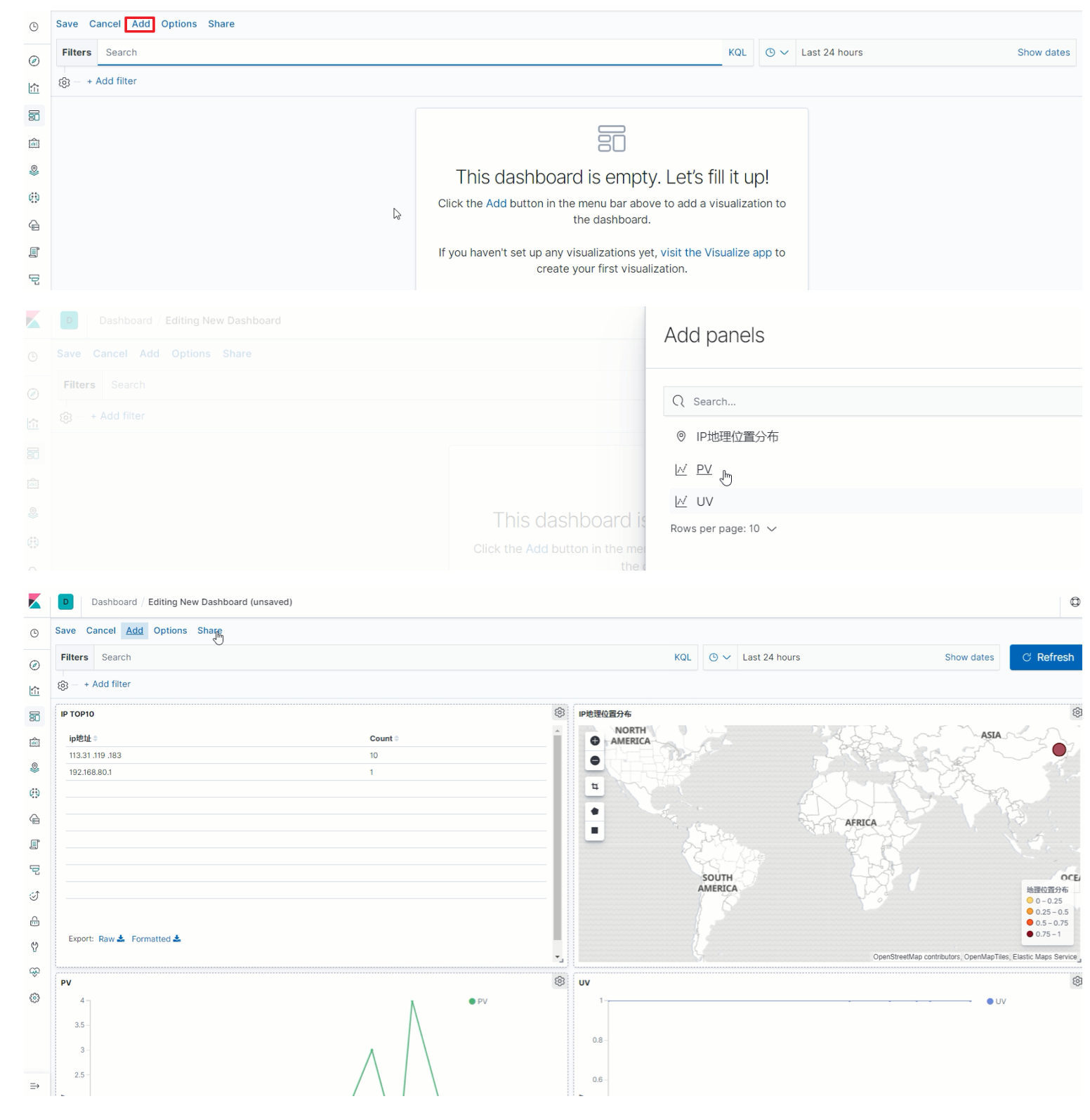
-
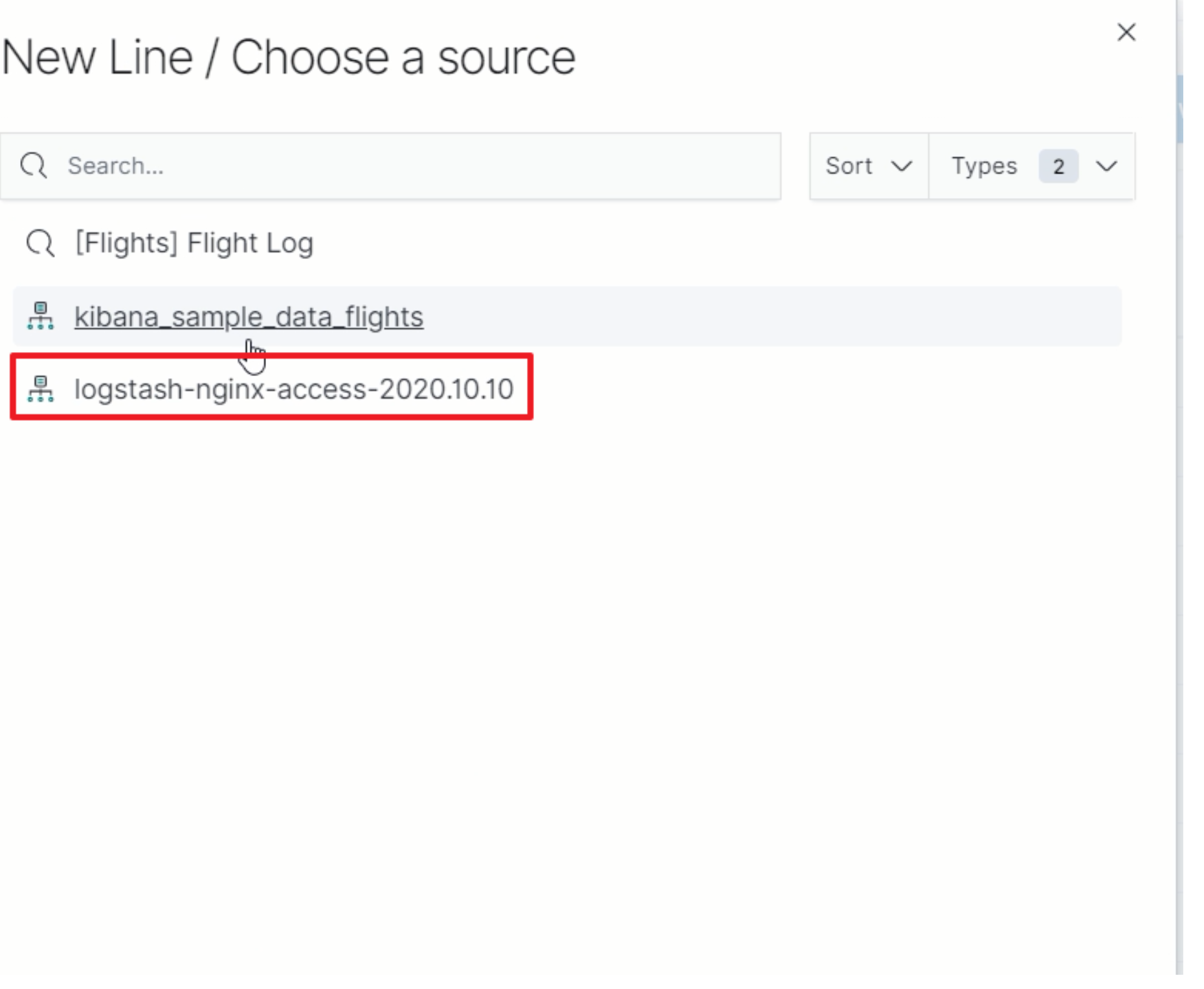
ES集群规划与调优
ES集群规划
-
我们需要多大规模的集群 需要从以下两个方面考虑:
- 当前的数据量有多大?数据增长情况如何?
- 你的机器配置如何?cpu、多大内存、多大硬盘容量?
推算的依据: Elasticsearch JVM heap 最大可以设置32G 。 30G heap 大概能处理的数据量 10 T。如果内存很大如 128G,可在一台机器上运行多个ES节点实例。
备注:集群规划满足当前数据规模+适量增长规模即可,后续可按需扩展。
两类应用场景:
A. 用于构建业务搜索功能模块,且多是垂直领域的搜索。数据量级几千万到数十亿级别。一般2-4台机器的规模。 B. 用于大规模数据的实时OLAP(联机处理分析),经典的如ELK Stack,数据规模可能达到千亿或更多。几十到上百节 点的规模。
-
集群中的节点角色如何分配 节点角色: Master
node.master: true
节点可以作为主节点DataNode
node.data: true
默认是数据节点
Coordinate node
协调节点,一个节点只作为接收请求、转发请求到其他节点、汇总各个节点返回数据等功能的节 点,就叫协调节点,如果仅担任协调节点,将上两个配置设为false。 说明:一个节点可以充当一个或多个角色,默 认三个角色都有节点角色如何分配: A. 小规模集群,不需严格区分。 B. 中大规模集群(十个以上节点),应考虑单独的角色充当。特别并发查询量大,查询的合并量大,可以增加独立的协调 节点。角色分开的好处是分工分开,不互影响。如不会因协调角色负载过高而影响数据节点的能力。 -
索引应该设置多少个分片 说明:分片数指定后不可变,除非重建索引。
分片设置的可参考原则:
ElasticSearch推荐的最大JVM堆空间是30~32G, 所以把你的分片最大容量限制为30GB, 然后再对分片数量做合理估 算. 在开始阶段, 一个好的方案是根据你的节点数量按照1.5~3倍的原则来创建分片. 例如,如果你有3个节点, 则推荐你 创建的分片数最多不超过9(3x3)个。当性能下降时,增加节点,ES会平衡分片的放置。 对于基于日期的索引需求, 并 且对索引数据的搜索场景非常少. 也许这些索引量将达到成百上千, 但每个索引的数据量只有1GB甚至更小. 对于这种 类似场景, 建议只需要为索引分配1个分片。如日志管理就是一个日期的索引需求,日期索引会很多,但每个索引存放 的日志数据量就很少。
-
分片应该设置几个副本 副本设置基本原则: 为保证高可用,副本数设置为2即可。要求集群至少要有3个节点,来分开存放主分片、副本。 如发现并发量大时,查询性能会下降,可增加副本数,来提升并发查询能力。 注意:新增副本时主节点会自动协 调,然后拷贝数据到新增的副本节点,副本数是可以随时调整的!
PUT /my_temp_index/_settings { "number_of_replicas": 1 }
-
ES集群调优策略
拉勾ELK日志平台中Elasticsearch实例节点数不到10个,考虑到资金投入、当前及未来一定时间内数据的增量情况等,研发和运维团队在竭尽所能的通过调优方式保证Elasticsearch正常高效运转。
-
Index(写)调优 拉勾网的职位数据和简历数据,首先都是进入MySQL集群的,从MySQL的原始表里面抽取并存储到ES 的Index,而 MySQL的原始数据也是经常在变化的,所以快速写入Elasticsearch、以保持Elasticsearch和MySQL的数据及时同步 也是很重要的。
- 副本数置0
如果是集群首次灌入数据,可以将副本数设置为0,写入完毕再调整回去,这样副本分片只需要拷贝,节省了索引过程。
PUT /my_temp_index/_settings { "number_of_replicas": 0 } -
自动生成doc ID 通过Elasticsearch写入流程可以看出,如果写入doc时如果外部指定了id,则Elasticsearch会先尝试读取原来doc
的版本号,以判断是否需要更新。这会涉及一次读取磁盘的操作,通过自动生成doc ID可以避免这个环节。 - 合理设置mappings
- 将不需要建立索引的字段index属性设置为not_analyzed或no。对字段不分词,或者不索引,可以减少很多运 算操作,降低CPU占用。 尤其是binary类型,默认情况下占用CPU非常高,而这种类型进行分词通常没有什么意义。
- 减少字段内容长度,如果原始数据的大段内容无须全部建立 索引,则可以尽量减少不必要的内容。
- 使用不同的分析器(analyzer),不同的分词器在索引过程中 运算复杂度也有较大的差异。
-
调整_source字段 source 字段用于存储doc原始数据,对于部分不需要存储的字段,可以通过includes excludes过滤,或者将source禁用,一般用于索引和数据分离,这样可以降低1/O的压力,不过实际场景中大多不会禁用_source。
- 对analyzed的字段禁用norms
Norms用于在搜索时计算doc的评分,如果不需要评分,则可以将其禁用:
"title": { "type": "string", "norms": { "enabled": false } -
调整索引的刷新间隔 该参数缺省是1s,强制ES每秒创建一个新segment,从而保证新写入的数据近实时的可见、可被搜索到。比如该参数被调整为30s,降低了刷新的次数,把刷新操作消耗的系统资源释放出来给index操作使用。
PUT /my_index/_settings { "index" : { "refresh_interval": "30s" } }这种方案以牺牲可见性的方式,提高了index操作的性能。
- 批处理
 批处理把多个index操作请求合并到一个batch中去处理,和mysql的jdbc的bacth有类似之处。
批处理把多个index操作请求合并到一个batch中去处理,和mysql的jdbc的bacth有类似之处。
比如每批1000个documents是一个性能比较好的size。每批中多少document条数合适,受很多因素影响而不同
- 副本数置0
如果是集群首次灌入数据,可以将副本数设置为0,写入完毕再调整回去,这样副本分片只需要拷贝,节省了索引过程。
-
Search(读)调优 在存储的Document条数超过10亿条后,如何进行搜索调优。
-
数据分组
 ES用来存储日志,日志的索引管理方式一般基于日期的,基于天、周、月、年建索引。
ES用来存储日志,日志的索引管理方式一般基于日期的,基于天、周、月、年建索引。
当搜索单天的数据,只需要查询一个索引的shards就可以。当需要查询多天的数据时,需要查询多个索引的 shards。这种方案其实和数据库的分表、分库、分区查询方案相比,思路类似,小数据范围查询而不是大海捞针。 - 使用Filter替代Query
在搜索时候使用Query,需要为Document的相关度打分。使用Filter,没有打分环节处理,做的事情更少,而且filter理论上更快一些。
如果搜索不需要打分,可以直接使用filter查询。如果部分搜索需要打分,建议使用’bool’查询。这种方式可以把打分 的查询和不打分的查询组合在一起使用,如:GET /_search { "query": { "bool": { "must": { "term": { "user": "kimchy" } }, "filter": { "term": { "tag": "tech" } } } } } - ID字段定义为keyword 一般情况,如果ID字段不会被用作Range 类型搜索字段,都可以定义成keyword类型。这是因为keyword会被优化,以便进行terms查询。Integers等数字类的mapping类型,会被优化来进行range类型搜索。 将integers改成keyword类型之后,搜索性能大约能提升30%。
-