实时数仓项目搭建及理论
项目背景与需求
项目背景
随着互联网的发展,数据的时效性对企业的精细化运营越来越重要, 商场如战场,在每天产生的海量数据中,如何 能实时有效的挖掘出有价值的信息, 对企业的决策运营策略调整有很大帮助。此外,随着 5G 技术的成熟、广泛应 用, 对于互联网、物联网等数据时效性要求非常高的行业,企业就更需要一套完整成熟的实时数据体系来提高自身 的行业竞争力。
随着数据时效性在企业运营中的重要性日益凸现,例如:
实时推荐;
精准营销;
广告投放效果;
实时物流
实时数仓产生的背景
数据的实时处理能力成为企业提升竞争力的一大因素,最初阶段企业主要采用来一个需求,编写一个实时计算任务的方式来处理实时数据,随着需求的增多,计算任务也相应增多,并且不同任务的开发人员不同,导致开发风格差异化,该阶段的实时数据处理缺乏统一的规划,代码风格差异化严重,在维护成本和开发效率上有很大障碍。
为避免上述问题,人们参照数据仓库的概念和模型来重新规划和设计实时数据处理,在此基础上产生了实时数据仓库(实时数仓)
离线转实时
-
离线数仓分层架构图
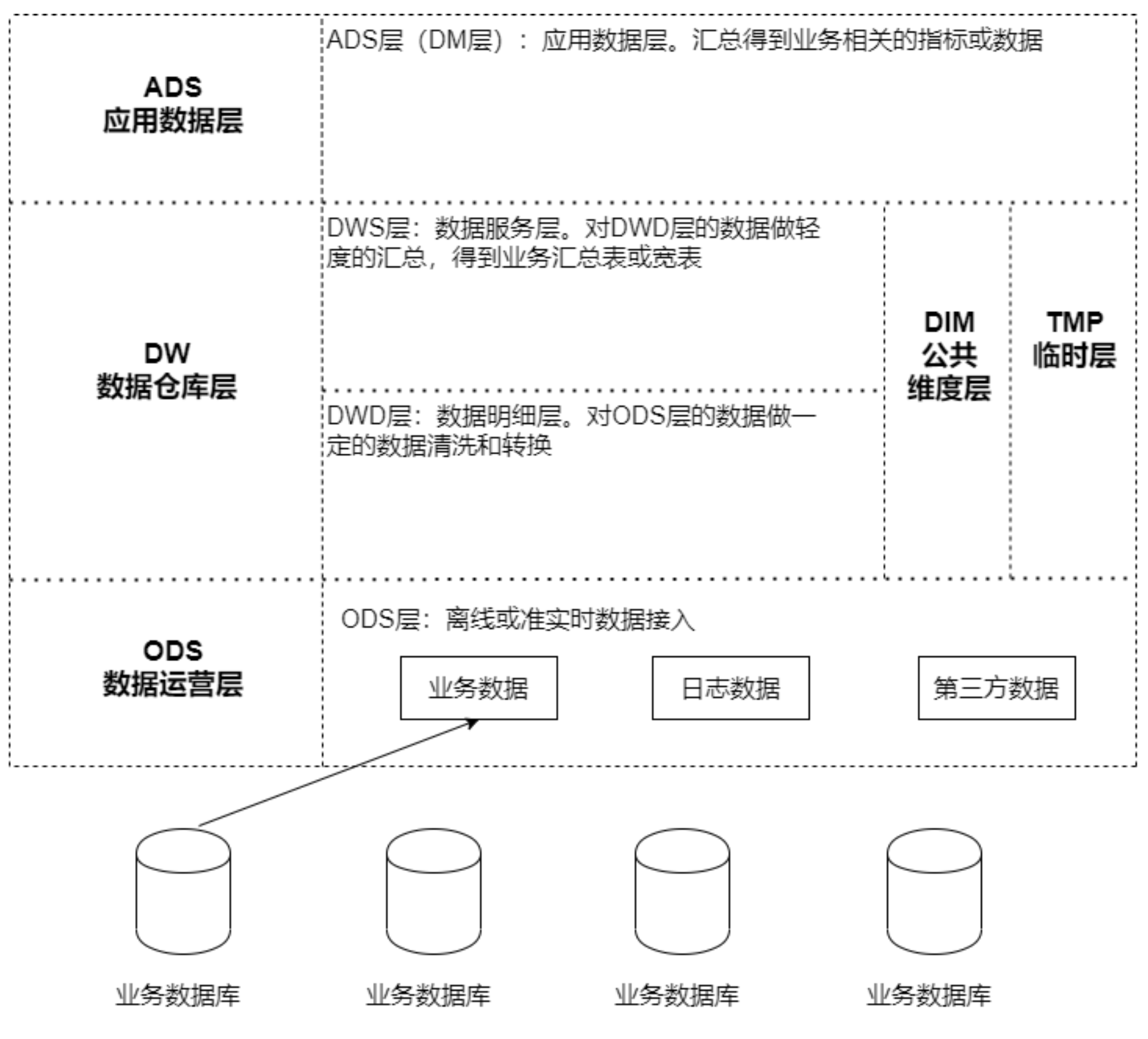
-
实时计算架构
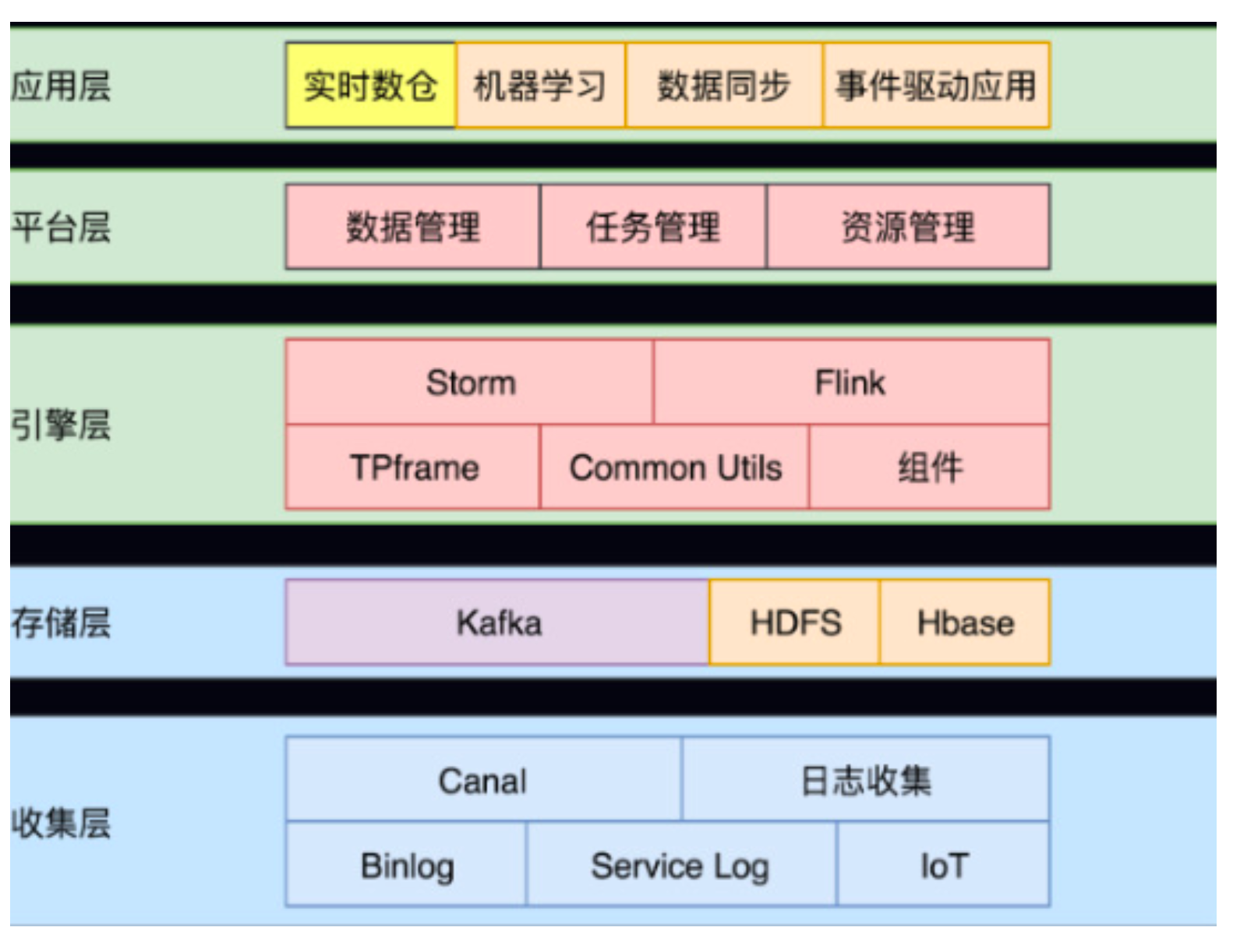
-
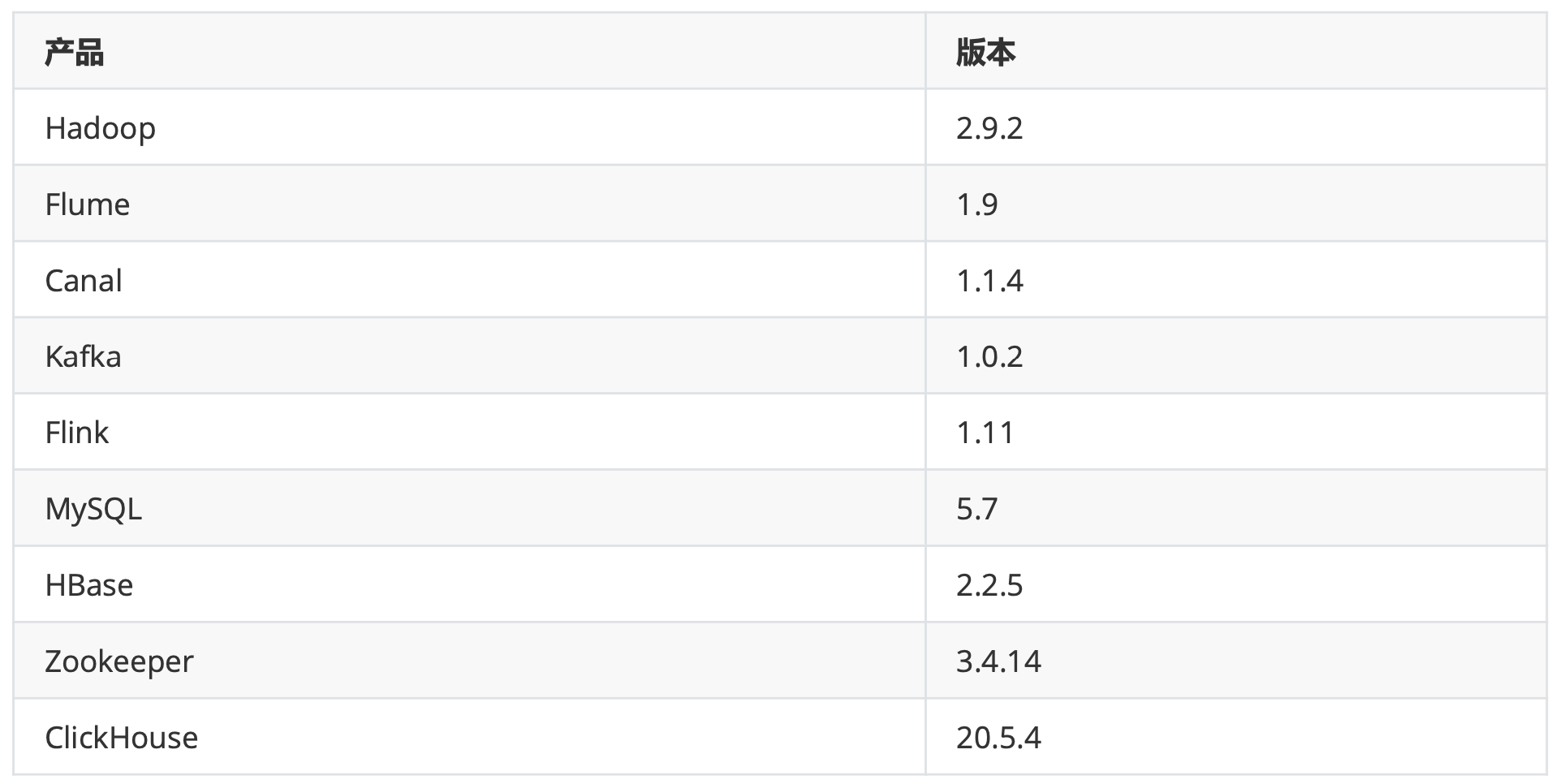
收集层
Binlog(业务日志)、loT(物联网)、后端服务日志(系统日志) 经过日志收集团队和 DB 收集团队的处理,数据将会被收集到 Kafka 中。这些数据不只是参与实时计算,也会参与离 线计算。
-
存储层
- Kafka:实时增量数据
- HDFS:状态数据存储和全量数据存储(持久层)
- HBASE: 维度数据存储
-
引擎层
实时处理框架
-
平台层
数据、任务和资源三个角度去管理—集群资源
-
应用层
底层架构的应用场景
-
-
流量
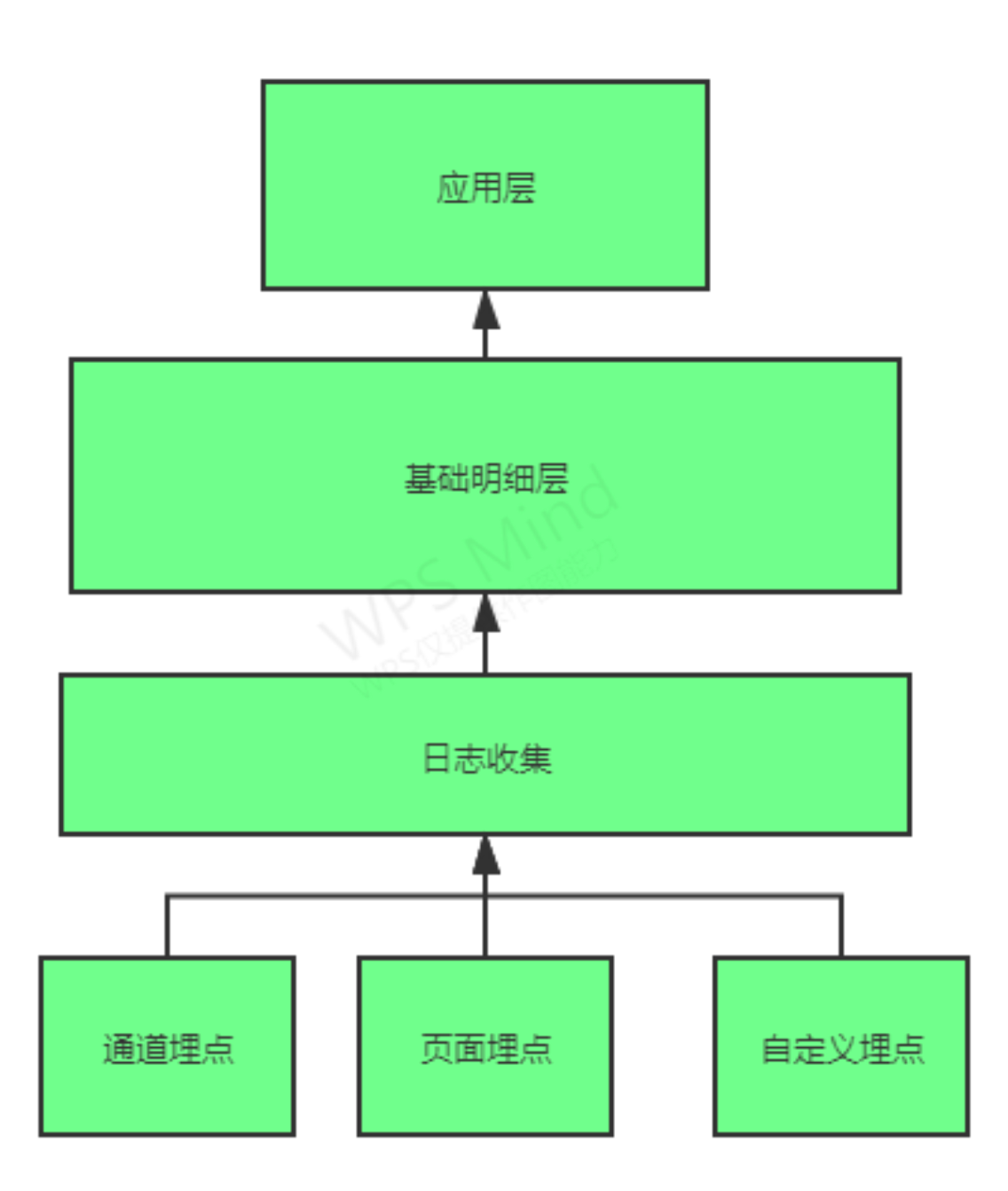
流量数据的产生: 不同通道的埋点和不同页面的埋点产生数据
采集:按照业务维度划分不同的业务通道。
应用: 1、流的方式提供下游业务使用
2、流量方面的分析 -
广告实时效果验证
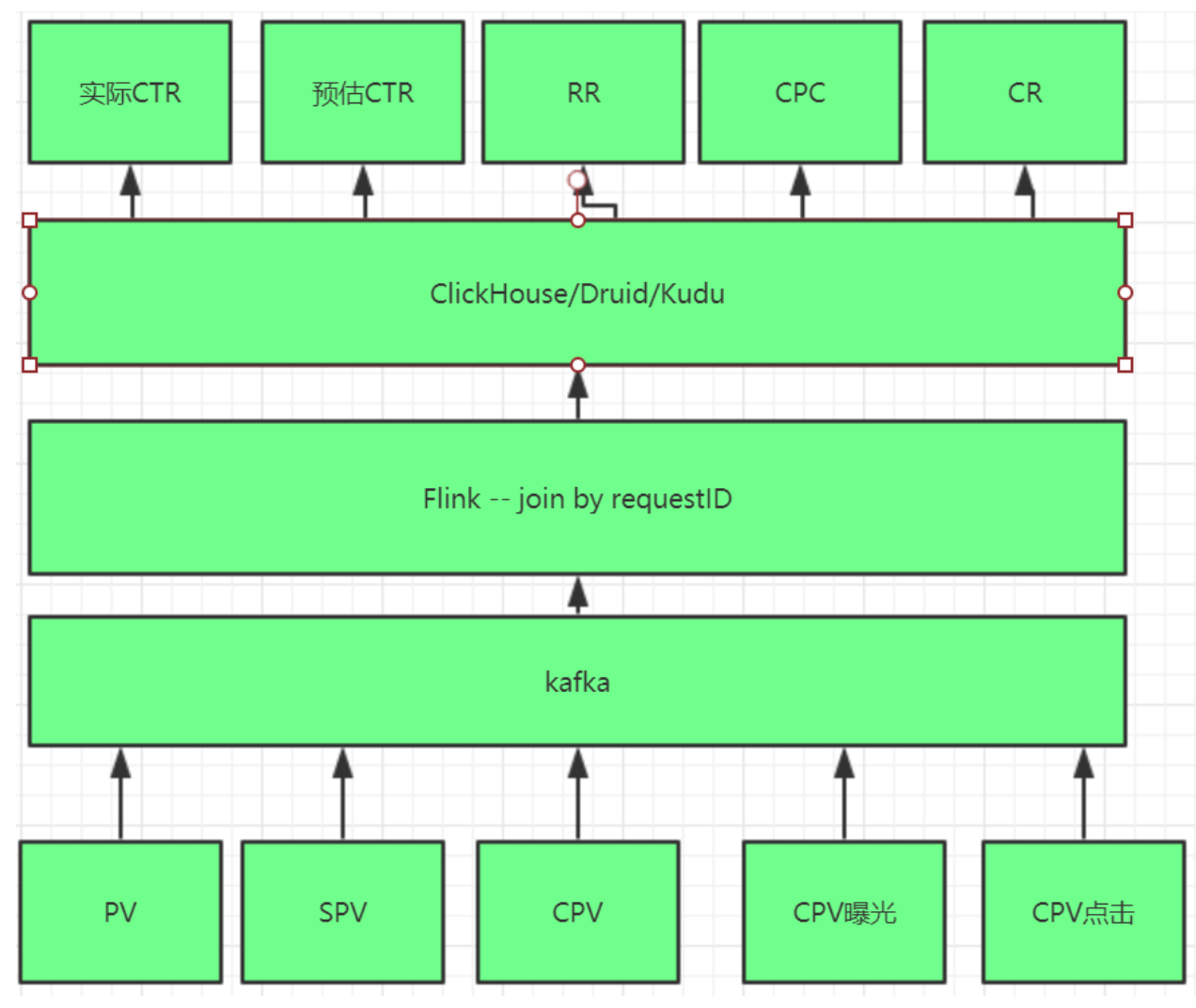
-
重架构
-
CPV(展示广告)
又称富媒体广告,按展示付费,即按投放广告网站的被展示次数计费,网站被打开一次计一次费, 按千次IP计费。(国内CPV广告常见是网页右下角弹窗,例如高仿QQ消息框)
-
CPC与CTR
在现在的广告业 CPC 这个指标很难用来跟效果扯上关系,更多的时候是计费单位了。而 CTR 有的时候 还是会作为效果的工具,大多用来衡量两次投放的不同投放策略、优化策略、创意的好坏。总之这两个指标通常都是 必须提供的基础数据;
-
Reach Rate
广告产生点击动作以后,后面的指标就是到达。点击后到达的比率是一个重要的指标,是否有较高的 到达率是广告效果的重要体现;
-
Conversion Rate
广告后续的转化比率,从到达到转化的比率是用来评估广告效果的一种指标;(漏斗分析)
-
-
到达时间预估
商家、骑手和用户等多维度数据评估
需求分析
日志数据:启动日志、点击日志(广告点击日志)
业务数据:用户下单、提交订单、支付、退款等核心交易数据的分析
广告流量实时统计: 生成动态黑名单
恶意刷单:一旦发现恶意刷单时进行实时告警
基于动态黑名单进行点击行为过滤, 计算每隔5分钟统计最近1小时内各广告的点击量, 计算每天各省的热门广告, 计算每天各广告最近1小时内的点击趋势…
-
订单交易分析
- 每隔5分钟统计最近1小时内的订单交易情况,要求显示城市、省份、交易总金额、订单总数
- 每隔5分钟统计最近1小时各省内交易金额排名前3名的城市,要求显示省份,城市,订单数,交易金额
-
渠道分析
点击来源:从不同的维度分析用户是从哪里点进来的
渠道质量:针对用户进行以下几方面分析:
访问时长、是否产生消费、首次产生消费的金额、收藏、访问页面数(PV) -
风险控制
交易支付异常:当检测到交易异常时进行实时告警
技术选型
数据采集:Flume、Canal
数据存储:MySQL、Kafka、HBase、Redis
数据计算:Flink
OLAP: ClickHouse、Druid 框架、软件尽量不要选择最新的版本,选择半年前左右稳定的版本。
- 系统逻辑架构
Canal同步业务数据
环境准备
Hadoop、HBASE、Flink、ClickHouse、MySQL、Canal、Kafka
初识Canal
-
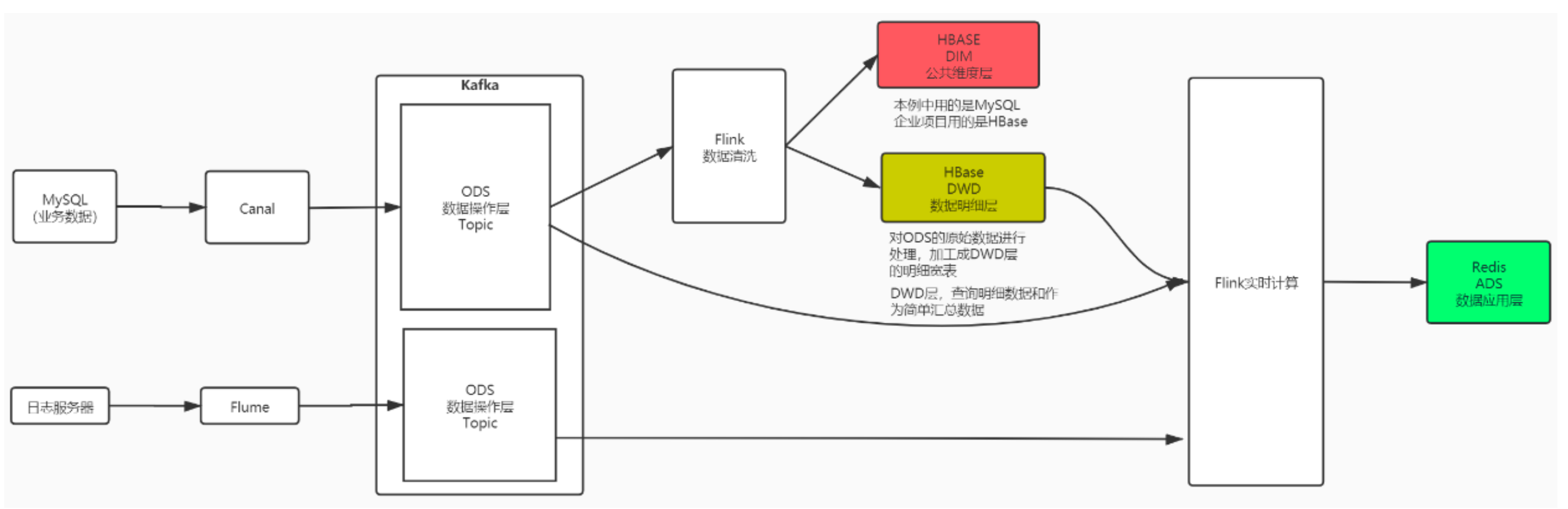
什么是 Canal
Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,Canal主要支持了MySQL 的binlog解析,解析完成后才利用Canal client 用来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基 于Canal)。
-
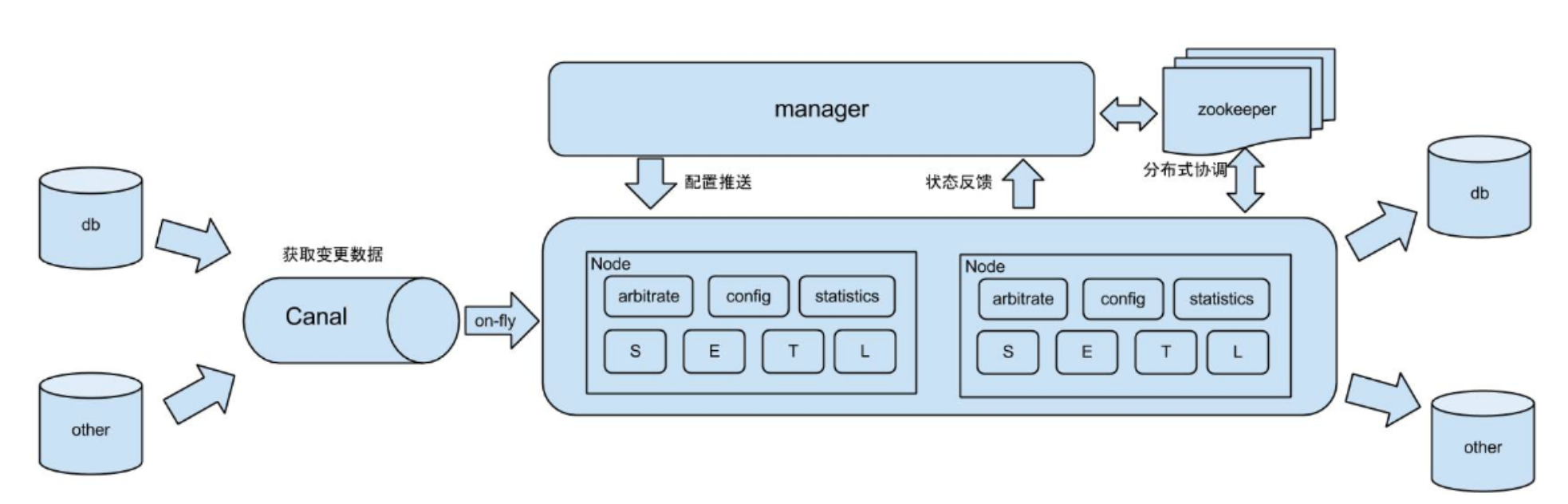
- 原始场景
-
阿里otter中间件的一部分
- 原始场景
-
更新缓存
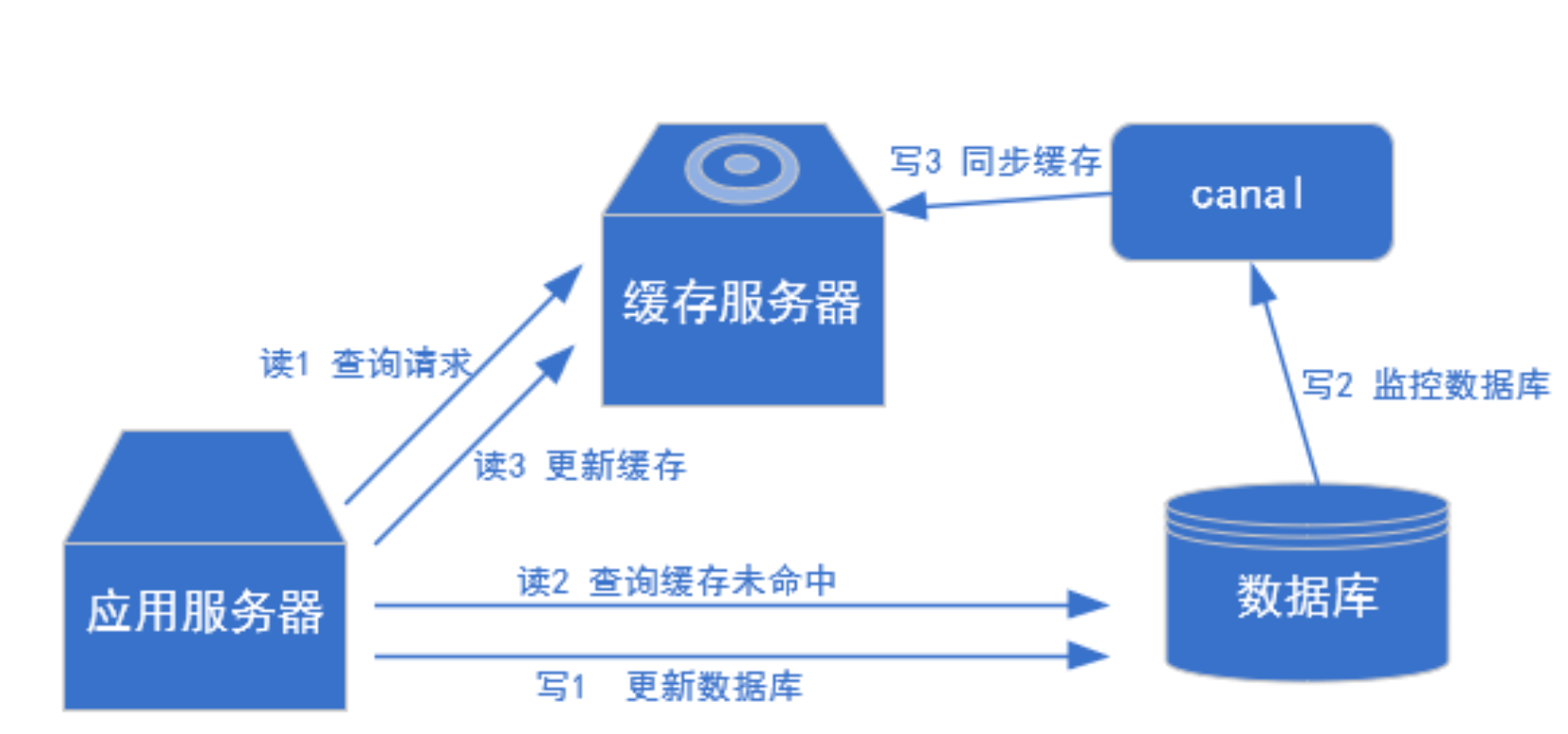
- 用于制作拉链表
-
-
Canal的工作原理
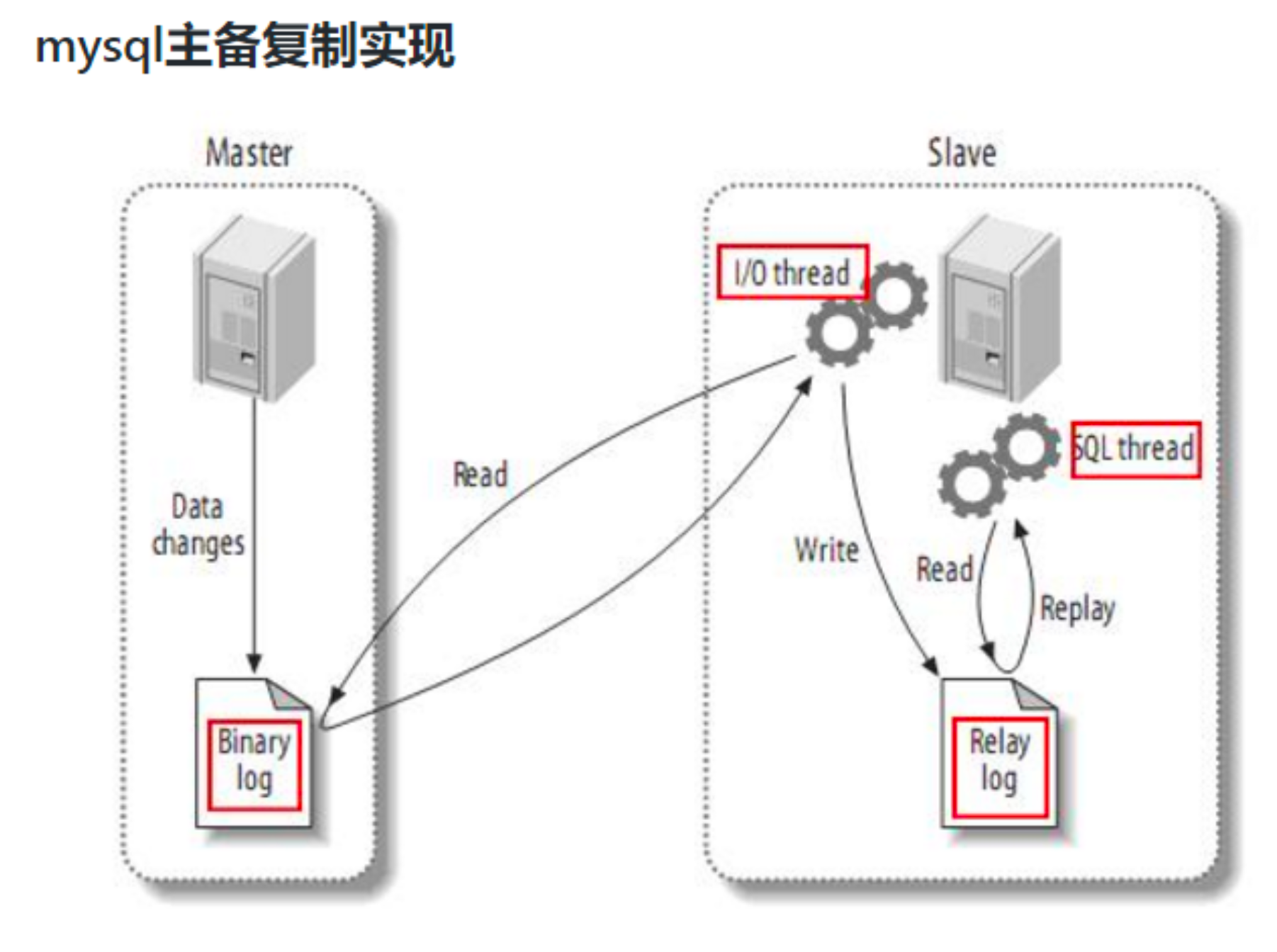
复制过程分成三步:
1) Master主库将改变记录写到二进制日志(binary log)中
2) Slave从库向MySQL master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log);
3) Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。Canal的工作原理很简单,就是把自己伪装成slave,假装从master复制数据。
-
什么是binlog
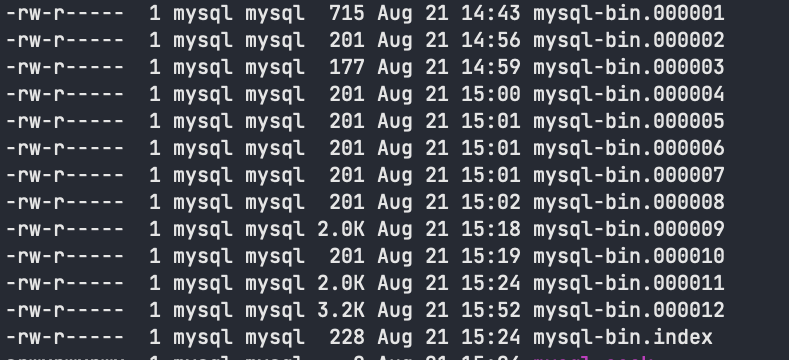
MySQL的二进制日志可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事 件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。 一般来说开启二进制日志大概会有1%的性能损耗。二进制有两个最重要的使用场景:
其一:MySQL Replication在Master端开启binlog,Mster把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
其二:自然就是数据恢复了,通过使用MySQL binlog工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
配置MySQL的binlog
-
binlog的开启
在MySQL的配置文件(Linux: /etc/my.cnf)下,修改配置
在[mysqld] 区块,设置/添加vim /etc/my.cnf [mysqld] server-id=1 # 配置 MySQL replaction 需要定义,不要和 Canal 的 slaveId 重复 log-bin=mysql-bin # 开启 binlog binlog-format=ROW # 选择 ROW 模式 binlog-do-db=dwshow # dwshow是数据库的名称log-bin=mysql-bin这个表示binlog日志的前缀是mysql-bin ,以后生成的日志文件就是 mysql-bin.123456 的文件后面的数字按顺序生 成。 每次MySQL重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号。
重启MySQL
systemctl restart mysqld ps -ef|grep mysql #MySQL重启之后,到下面路径中看有没有mysql-bin.*****文件 cd /var/lib/mysql-
binlog的分类设置
MySQL binlog的格式有三种,分别是STATEMENT,MIXED,ROW。
1) statement 语句级,binlog会记录每次一执行写操作的语句。 相对row模式节省空间,但是可能产生不一致性,比如:update tt set create_date=now() 如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点: 节省空间
缺点: 有可能造成数据不一致。
2) row 行级, binlog会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间。
3) mixed statement的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题 在某些情况下譬如:
当函数中包含 UUID() 时;
包含 AUTO_INCREMENT 字段的表被更新时;
执行 INSERT DELAYED 语句时;
用 UDF 时;
会按照 ROW的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。
-
-
授权
授权 Canal 链接 MySQL账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant。 在MySQL中执行
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal' ;验证:
mysql> select Host,User from mysql.user; +-----------+---------------+ | Host | User | +-----------+---------------+ | % | canal | | % | druid | | % | hive | | % | root | | 127.0.0.1 | root | | ::1 | root | | bogon | | | bogon | root | | localhost | | | localhost | hive | | localhost | mysql.session | | localhost | mysql.sys | | localhost | root | +-----------+---------------+ 13 rows in set (0.00 sec) mysql> show grants for 'canal'@'%'; +---------------------------------------------------------------------------+ | Grants for canal@% | +---------------------------------------------------------------------------+ | GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' | +---------------------------------------------------------------------------+ 1 row in set (0.01 sec) -
常见的binlog命令
# 是否启用binlog日志 show variables like 'log_bin'; # 查看binlog类型 show global variables like 'binlog_format'; show global variables like '%log%'; # mysql数据存储目录 show variables like '%dir%'; # 查看binlog的目录 show global variables like "%log_bin%"; # 查看当前服务器使用的biglog文件及大小 show binary logs; # 查看最新一个binlog日志文件名称和Position show master status; # 查询binlog 变动信息, 默认取第一个文件 show binlog events; # 指定文件 show binlog events in 'mysql-bin.000012'; # 刷写bin-log,开启新的文件 flush logs;
Canal 安装
下载地址: https://github.com/alibaba/canal/releases
把下载的Canal.deployer-1.1.4.tar.gz拷贝到linux,解压缩(路径可自行调整)
[root@linux123 ~]# mkdir /opt/servers/canal
[root@linux123 mysql]# tar -zxf canal.deployer-1.1.4.tar.gz -C /opt/servers/canal
修改Canal配置
这个文件是canal的基本通用配置,主要关心一下端口号,不改的话默认就是11111
修改内容如下:
# 配置zookeeper地址
canal.zkServers =centos7-1:2181,centos7-3:2181
# tcp, kafka, RocketMQ
canal.serverMode = kafka
# 配置kafka地址
canal.mq.servers =centos7-1:9092,centos7-3:9092
修改conf/example/instance.properties
这个文件是针对要追踪的MySQL的实例配置
修改内容如下:
# 配置MySQL数据库所在的主机 canal.instance.master.address = linux123:3306 # username/password,配置数据库用户和密码 canal.instance.dbUsername =canal canal.instance.dbPassword =canal
# mq config,对应Kafka主题:
canal.mq.topic=test
启动Canal
sh bin/startup.sh
# 关闭Canal
sh bin/stop.sh
-
集群模式
上面的操作是单机模式,也可以将Canal搭建集群模式。 如果要搭建集群模式,可将Canal目录分发给其他虚拟机,然后在各节点中分别启动Canal。 这种Zookeeper为观察者监控的模式,只能实现高可用,而不是负载均衡,即同一时间点只有一个canal-server节点 能够监控某个数据源,只要这个节点能够正常工作,那么其他监控这个数据源的canal-server只能做stand-by,直到 工作节点停掉,其他canal-server节点才能抢占。
Kafka客户端测试
# 1. 启动zookeeper
# 2. 启动kafka
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
# 3. 创建topic
kafka-topics.sh --zookeeper localhost:2181/mykafka --create --topic test --partitions 2 --replication-factor 1
# 4. 消费topic
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
mysql操作
use dwshow;
DROP TABLE IF EXISTS `ad_show`;
CREATE TABLE `ad_show` (
`dt` varchar(10) NOT NULL COMMENT '日期',
`cnt` bigint(20) DEFAULT NULL COMMENT '总点击数据',
`u_cnt` bigint(20) DEFAULT NULL COMMENT '不同用户点击数',
`device_cnt` bigint(20) DEFAULT NULL COMMENT '不同设备点击数',
`ad_action` tinyint(4) NOT NULL COMMENT '用户行为;0 曝光;1 曝光后点击;2 购买',
`hour` tinyint(4) NOT NULL COMMENT '小时',
PRIMARY KEY (`dt`,`hour`,`ad_action`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `ad_show` VALUES ('2020-07-21', '7855924', '5522275', '5512895', '0', '0');
UPDATE `ad_show` set cnt=2048 where dt='2020-07-21';
delete from `ad_show` where dt='2020-07-21';
-
查看kafka消费到的json数据
# drop table { "data": null, "database": "dwshow", "es": 1629532323000, "id": 17, "isDdl": true, "mysqlType": null, "old": null, "pkNames": null, "sql": "DROP TABLE IF EXISTS `ad_show` /* generated by server */", "sqlType": null, "table": "ad_show", "ts": 1629532324169, "type": "ERASE" } # create table { "data": null, "database": "dwshow", "es": 1629532323000, "id": 17, "isDdl": true, "mysqlType": null, "old": null, "pkNames": null, "sql": "CREATE TABLE `ad_show` (\n `dt` varchar(10) NOT NULL COMMENT '??',\n `cnt` bigint(20) DEFAULT NULL COMMENT '?????',\n `u_cnt` bigint(20) DEFAULT NULL COMMENT '???????',\n `device_cnt` bigint(20) DEFAULT NULL COMMENT '???????',\n `ad_action` tinyint(4) NOT NULL COMMENT '?????0 ???1 ??????2 ??',\n `hour` tinyint(4) NOT NULL COMMENT '??',\n PRIMARY KEY (`dt`,`hour`,`ad_action`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8", "sqlType": null, "table": "ad_show", "ts": 1629532324169, "type": "CREATE" } # insert { "data": [{ "dt": "2020-07-21", "cnt": "730766", "u_cnt": "585599", "device_cnt": "613573", "ad_action": "1", "hour": "0" }], "database": "dwshow", "es": 1629532324000, "id": 17, "isDdl": false, "mysqlType": { "dt": "varchar(10)", "cnt": "bigint(20)", "u_cnt": "bigint(20)", "device_cnt": "bigint(20)", "ad_action": "tinyint(4)", "hour": "tinyint(4)" }, "old": null, "pkNames": [ "dt", "ad_action", "hour" ], "sql": "", "sqlType": { "dt": 12, "cnt": -5, "u_cnt": -5, "device_cnt": -5, "ad_action": -6, "hour": -6 }, "table": "ad_show", "ts": 1629532324170, "type": "INSERT" } # update { "data": [{ "dt": "2020-07-21", "cnt": "2048", "u_cnt": "5522275", "device_cnt": "5512895", "ad_action": "0", "hour": "0" }, { "dt": "2020-07-21", "cnt": "2048", "u_cnt": "585599", "device_cnt": "613573", "ad_action": "1", "hour": "0" }, { "dt": "2020-07-21", "cnt": "2048", "u_cnt": "71399", "device_cnt": "63404", "ad_action": "2", "hour": "0" }, { "dt": "2020-07-21", "cnt": "2048", "u_cnt": "17197502", "device_cnt": "17402885", "ad_action": "0", "hour": "2" } ], "database": "dwshow", "es": 1629532324000, "id": 17, "isDdl": false, "mysqlType": { "dt": "varchar(10)", "cnt": "bigint(20)", "u_cnt": "bigint(20)", "device_cnt": "bigint(20)", "ad_action": "tinyint(4)", "hour": "tinyint(4)" }, "old": [{ "cnt": "7855924" }, { "cnt": "730766" }, { "cnt": "90569" }, { "cnt": "26754224" } ], "pkNames": [ "dt", "ad_action", "hour" ], "sql": "", "sqlType": { "dt": 12, "cnt": -5, "u_cnt": -5, "device_cnt": -5, "ad_action": -6, "hour": -6 }, "table": "ad_show", "ts": 1629532324172, "type": "UPDATE" } # delete { "data": [{ "dt": "2020-07-21", "cnt": "2048", "u_cnt": "5522275", "device_cnt": "5512895", "ad_action": "0", "hour": "0" }, { "dt": "2020-07-21", "cnt": "2048", "u_cnt": "585599", "device_cnt": "613573", "ad_action": "1", "hour": "0" }, { "dt": "2020-07-21", "cnt": "2048", "u_cnt": "71399", "device_cnt": "63404", "ad_action": "2", "hour": "0" }, { "dt": "2020-07-21", "cnt": "2048", "u_cnt": "17197502", "device_cnt": "17402885", "ad_action": "0", "hour": "2" } ], "database": "dwshow", "es": 1629532324000, "id": 17, "isDdl": false, "mysqlType": { "dt": "varchar(10)", "cnt": "bigint(20)", "u_cnt": "bigint(20)", "device_cnt": "bigint(20)", "ad_action": "tinyint(4)", "hour": "tinyint(4)" }, "old": null, "pkNames": [ "dt", "ad_action", "hour" ], "sql": "", "sqlType": { "dt": 12, "cnt": -5, "u_cnt": -5, "device_cnt": -5, "ad_action": -6, "hour": -6 }, "table": "ad_show", "ts": 1629532324173, "type": "DELETE" }
ODS层处理
大数据数据仓库的架构
-
离线大数据架构
HDFS存储,hive、mr、spark进行离线计算的传统大数据架构;
-
Lambda架构
在离线大数据架构的基础上增加新链路用于实时数据处理,需要维护离线处理和实时处理两套代码;
-
图层
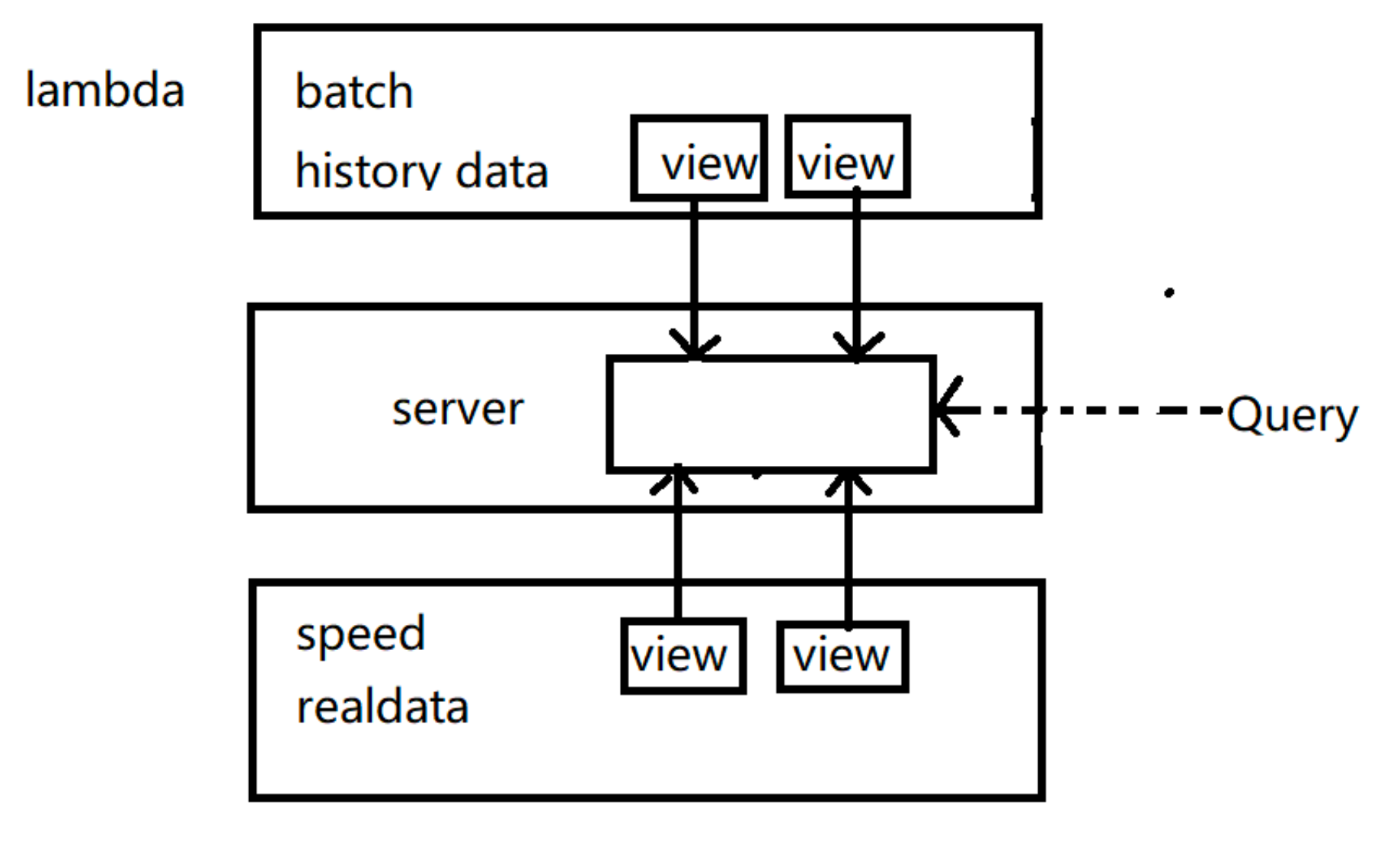
所有进入系统的数据都被分配到批处理层和速度层进行处理。批处理层管理主数据集(一个不可变的,仅可扩展的原始数据集)并预先计算批处理视图。服务层对批处理视图进行索引,以便可以在低延迟的情况下进行点对点查询。速度层只处理最近的数据。任何传入的查询都必须通过合并来自批量视图和实时视图的结果来得到结果。
-
实现
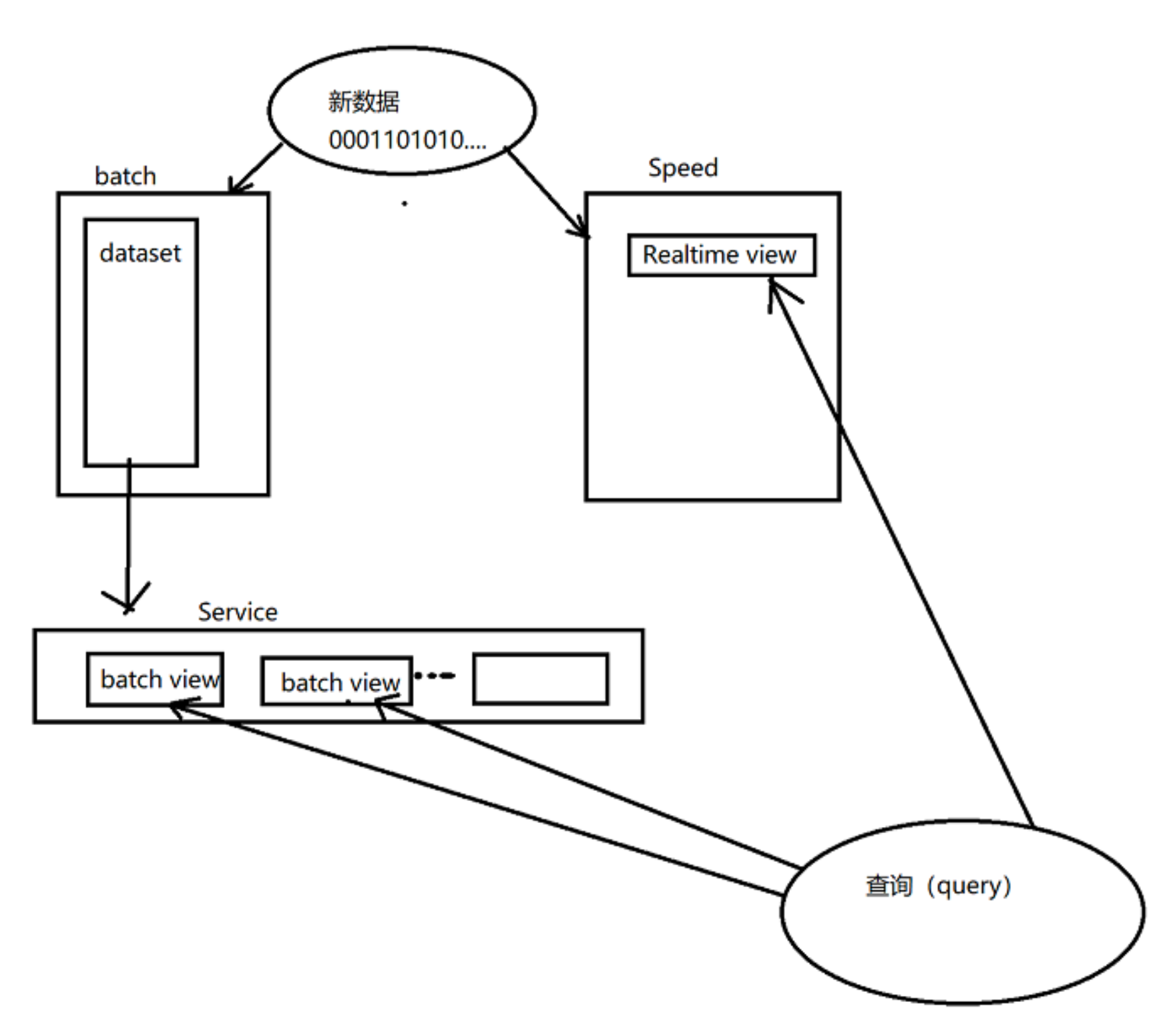
有多种实现Lambda体系结构的方法,因为它对于每个层的底层解决方案都是不可知的。每一层都需要底层实现的特 定功能,这可能有助于做出更好的选择并避免过度的决定:
批处理层:一次写入,批量读取多次
服务层:随机读取,不随机写入; 批量计算和批量写入
速度层:随机读取,随机写入; 增量计算
-
-
**Kappa架构
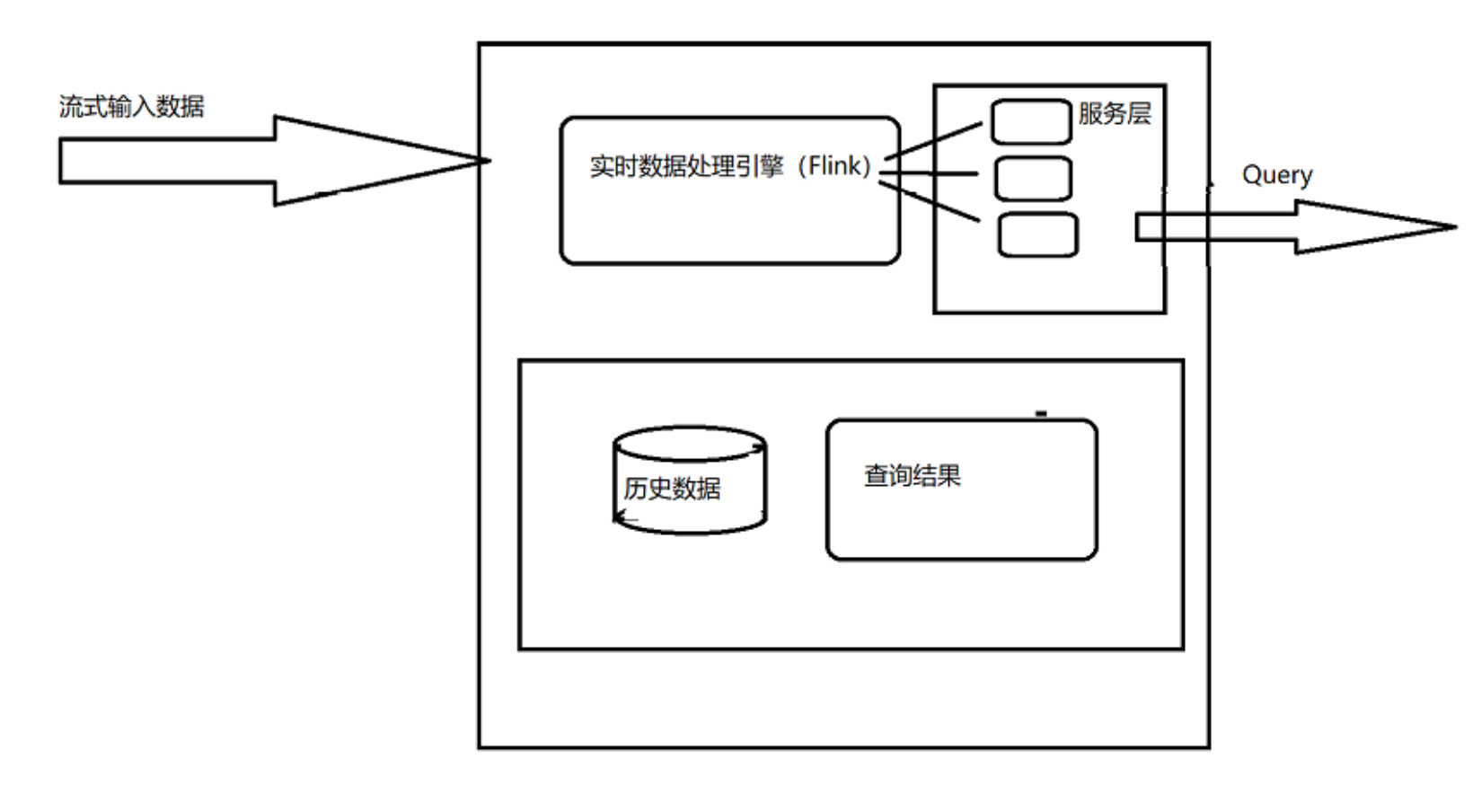
批流合一,离线处理和实时处理整合成一套代码,运维成本小,这就是现今flink之所以火的原 因。Kappa架构已成为数据仓库架构的新趋势。
Kappa 架构是 LinkedIn的Jay Kreps结合实际经验和个人体会,针对Lambda架构进行深度剖析,分析其优缺点并采用的替代方案。 Lambda 架构的一个很明显的问题是需要维护两套分别跑在批处理和实时计算系统上面的代码,而且这两套代码得产 出一模一样的结果。因此对于设计这类系统的人来讲,要面对的问题是:为什么我们不能改进流计算系统让它能处理 这些问题?为什么不能让流系统来解决数据全量处理的问题?流计算天然的分布式特性注定其扩展性比较好,能否加 大并发量来处理海量的历史数据?基于种种问题的考虑,Jay提出了Kappa这种替代方案。Kappa架构 简化了 Lambda架构。
Kappa架构系统是删除了批处理系统的架构。要取代批处理,数据只需通过流式传输系统快速提供
那如何用流计算系统对全量数据进行重新计算,步骤如下:
1、用Kafka或类似的分布式队列保存数据,需要几天数据量就保存几天。
2、当需要全量计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个结果存储中。
3、当新的实例完成后,停止老的流计算实例,并把老的结果删除。 -
计算框架选型
storm/flink等实时计算框架,强烈推荐flink,其『批量合一』的特性及活跃的开源社区,有逐渐替代spark的趋势。
-
数据存储选型
首要考虑查询效率,其次是插入、更新等问题,可选择apache druid,不过在数据更新上存在缺陷,选型时注意该问题频繁更新的数据建议不要采用该方案。当然存储这块需要具体问题具体分析,不同场 景下hbase、redis等都是可选项。
-
实时数仓分层
为更好的统一管理数据,实时数仓可采用离线数仓的数据模型进行分层处理,可以分为实时明 细层写入druid等查询效率高的存储方便下游使用;轻度汇总层对数据进行汇总分析后供下游使用。
-
数据流转方案
实时数仓的数据来源可以为kafka消息队列,这样可以做到队列中的数据即可以写入数据湖或者 数据仓库用于批量分析,也可以实时处理,下游可以写入数据集市供业务使用。
-
数据湖
其实数据湖就是一个集中存储数据库,用于存储所有结构化和非结构化数据。数据湖可用其原生格式存储任何类型的数据,这是没有大小限制。数据湖的开发主要是为了处理大数据量,擅长处理非结构化数据。
我们通常会将所有数据移动到数据湖中不进行转换。数据湖中的每个数据元素都会分配一个唯一的标识符,并对其进行标记,以后可通过查询找到该元素。这样做技术能够方便我们更好的储存数据。 -
数据仓库
数据仓库是位于多个数据库上的大容量存储库。它的作用是存储大量的结构化数据,并能进行频繁和可重复的分析。通常情况下,数据仓库用于汇集来自各种结构化源的数据以进行分析,通常用于商业分析目的。
那么数据湖和数据仓库之间的主要差异是什么呢?在储存方面上,数据湖中数据为非结构化的,所有数据都保持原始形式。存储所有数据,并且仅在分析时再进行转换。数据仓库就是数据通常从事务系统中提取。在将数据加载到数据仓库之前,会对数据进行清理与转换。在数据抓取中数据湖就是捕获半结构化和非结构化数据。而数据仓库则是捕获结构化数据并将其按模式组织。数据湖的目的就是数据湖非常适合深入分析的非结构化数据。数据科学家可能会用具有预测建模和统计分析等功能的高级分析工具。而数据仓库就是数据仓库非常适用于月度报告等操作用途,因为它具
有高度结构化。在架构方面数据湖通常是在存储数据之后定义架构。使用较少的初始工作并提供更大的灵活性。在数据仓库中存储数据之前定义架构。这需要你清理和规范化数据,这意味着架构的灵活性要低不少。
其实数据仓库和数据湖是我们都需要的地方,数据仓库非常适用于业务实践中常见的可重复报告。当我们执行不太直接的分析时,数据湖就很有用。
ODS(Operational Data Store)数据
在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据。在互联 网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据(DB)两类
系统实时监控&可视化
普罗米修斯Prometheus
-
功能
-
在业务层用作埋点系统
Prometheus支持多种语言(Go,java,python,ruby官方提供客户端,其他语言有第三方开源客户端)。我们可 以通过客户端方便的对核心业务进行埋点。如下单流程、添加购物车流程。
-
在应用层用作应用监控系统
一些主流应用可以通过官方或第三方的导出器,来对这些应用做核心指标的收集。如redis,mysql。
-
在系统层用作系统监控
除了常用软件, prometheus也有相关系统层和网络层exporter,用以监控服务器或网 络。
-
集成其他的监控
prometheus还可以通过各exporter,集成其他的监控系统,收集监控数据,如AWS CloudWatch,JMX,Pingdom等等
-
-
环境安装
-
步骤1:安装go 语言环境
由于Prometheus 是用golang开发的,所以首先安装一个go环境
wget [https://storage.googleapis.com/golang/go1.8.3.linux-amd64.tar.gz](https://storage.googleapis.com/golang/go1.8.3.linux-amd64.tar.gz) tar -zxvf go1.8.3.linux-amd64.tar.gz -C /usr/local配置环境变量
vim /etc/profile # go export GO_HOME=/usr/local/go export GOROOT=/usr/local/go export PATH=$PATH:/usr/local/go/bin source /etc/profile验证是否安装成功
# go version go version go1.8.3 linux/amd64 -
步骤2:在监控服务器上安装prometheus
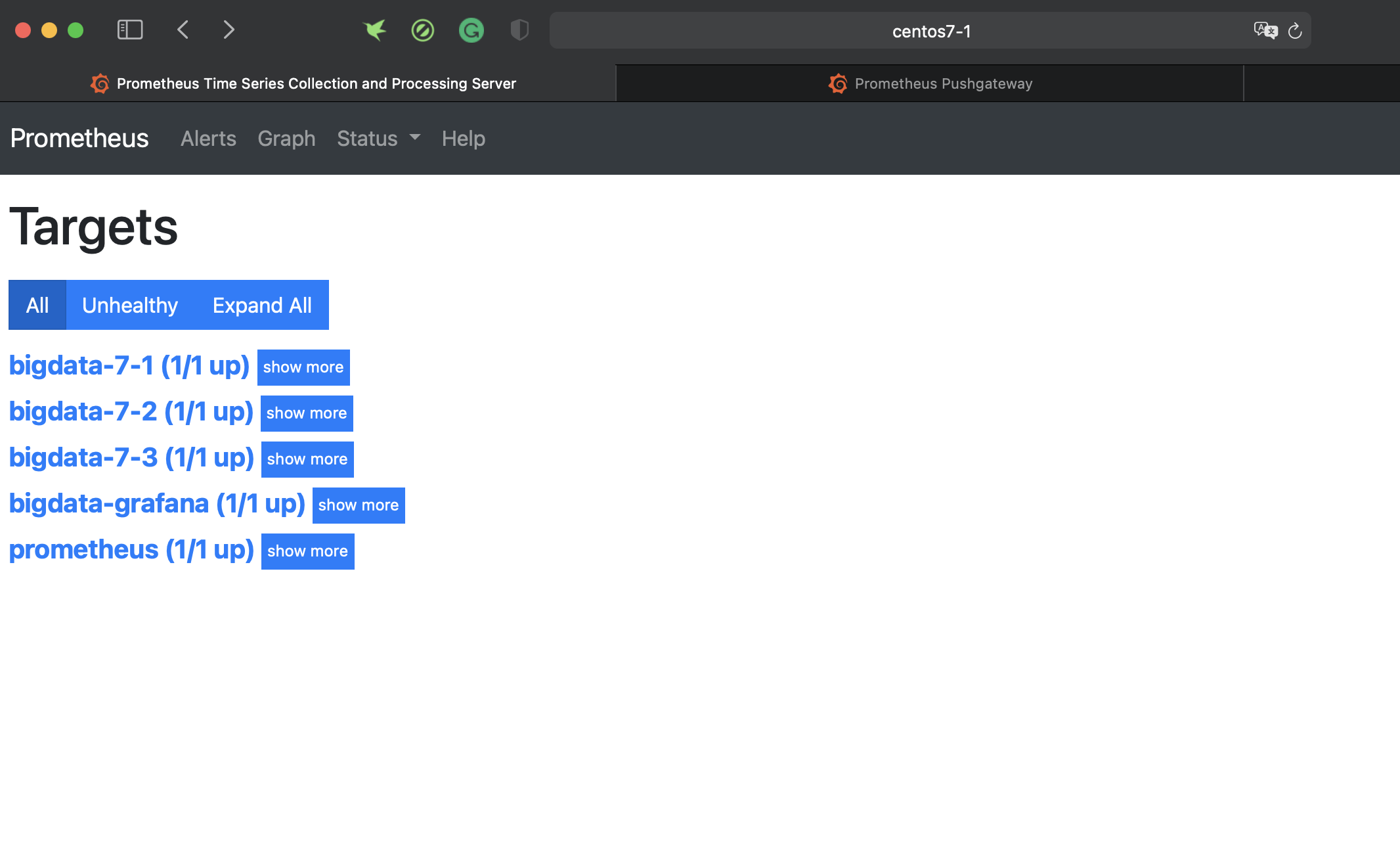
下载版本
https://github.com/prometheus/prometheus/releases/tag/v2.22.1下载后上传到部署的服务器,在服务上执行如下命令解压(root用户,解压到 /root/apps):
tar -zvxf prometheus-2.22.1.linux-amd64.tar.gz -C /opt/servers接着要配置一下监控的配置文件:prometheus.yml(ip地址:改成自己的)
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: 'bigdata-7-1' static_configs: - targets: ['centos7-1:9100'] - job_name: 'bigdata-7-2' static_configs: - targets: ['centos7-2:9100'] - job_name: 'bigdata-7-2' static_configs: - targets: ['centos7-3:9100'] - job_name: 'bigdata-grafana' static_configs: - targets: ['centos7-1:9091']配置完成后,只需要运行起来这个软件
# ./prometheuswebUI: http://centos7-1:9090/
-
步骤3:在系统层用作系统监控exporter
以在centos7-1这台主机为例,安装exporter ,这台linux环境是centos,因此用的监控export是
node_exporter- 0.16.0.linux-amd64.tar.gz,首先在官网下载这个文件,然后上传到被监控的主机(作为部署服务的主机上也需要安装 exporter),因此下载并部署后,执行如下命令:tar xvf node_exporter-1.0.1.linux-amd64.tar.gz -C /opt/servers nohup node_exporter-1.0.1.linux-amd64/node_exporter &执行后,我们回到prometheus查看监控目标,可以看到centos7-1主机也显示为蓝色了。
-
步骤4:修改flink配置,开放flink被监控端口
把prometheus的jar包复制到flink的lib目录下
➜ flink-1.11.1 pwd /opt/servers/flink-1.11.1 ➜ flink-1.11.1 cp plugins/metrics-prometheus/flink-metrics-prometheus-1.11.1.jar lib/修改flink-conf.yaml:
➜ pwd /opt/servers/flink-1.11.1/conf ➜ vim flink-conf.yaml在flink-conf.yaml增加如下内容,修改:
metrics.reporter.promgateway.host: centos7-1
centos7-1已安装prometheus,同样也是步骤5中pushgateway机器名字metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter metrics.reporter.promgateway.host: centos7-1 metrics.reporter.promgateway.port: 9091 metrics.reporter.promgateway.jobName: myJob metrics.reporter.promgateway.randomJobNameSuffix: true metrics.reporter.promgateway.deleteOnShutdown: false同步上面的配置到flink集群的所有机器
-
步骤5:增加pushgateway
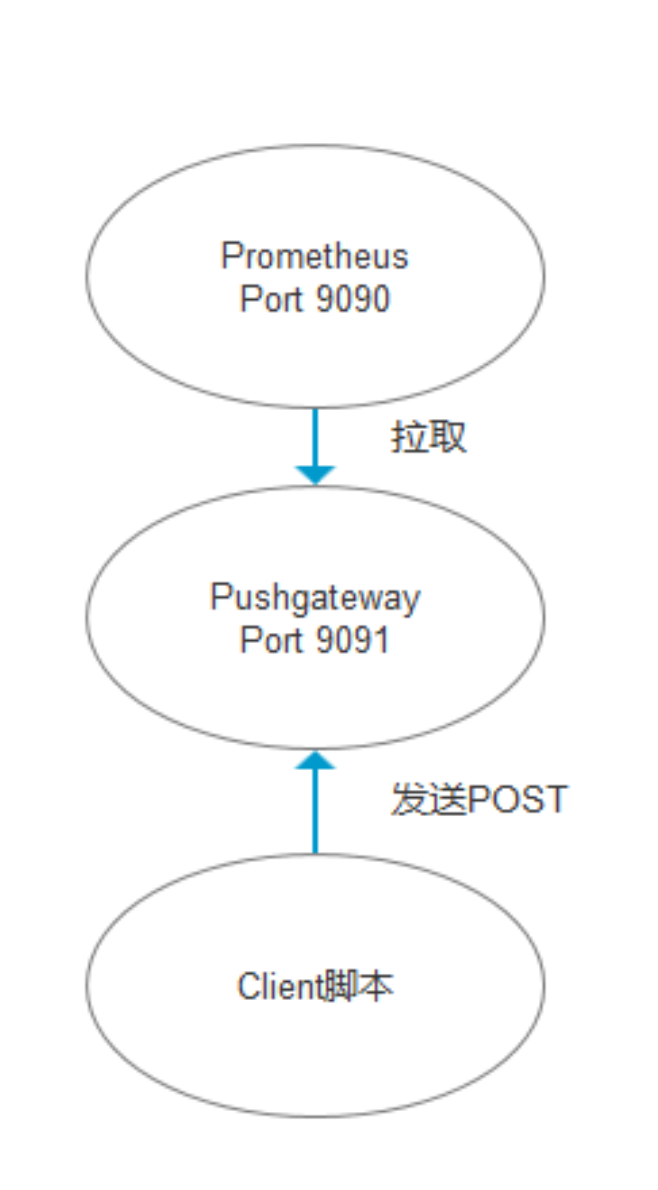
Pushgateway 是 Prometheus 生态中一个重要工具,使用它的原因主要是:
- Prometheus 采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。
- 在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。
由于以上原因,不得不使用 pushgateway,但在使用之前,有必要了解一下它的一些弊端:
- 将多个节点数据汇总到 pushgateway, 如果 pushgateway 挂了,受影响比多个 target 大。
- Prometheus 拉取状态 up 只针对 pushgateway, 无法做到对每个节点有效。
- Pushgateway 可以持久化推送给它的所有监控数据。
因此,即使你的监控已经下线,prometheus 还会拉取到旧的监控数据,需要手动清理 pushgateway 不要的数据。
下载:https://prometheus.io/download/#pushgateway/
解压出pushgateway 放到prometheus中:
➜ prometheus-2.22.1 pwd /opt/servers/prometheus-2.22.1 ➜ prometheus-2.22.1 ll total 178116 drwxr-xr-x 2 3434 3434 38 Nov 5 2020 console_libraries drwxr-xr-x 2 3434 3434 173 Nov 5 2020 consoles drwxr-xr-x 7 root root 172 Sep 4 17:00 data -rw-r--r-- 1 3434 3434 11357 Nov 5 2020 LICENSE -rw------- 1 root root 21762 Sep 4 18:02 nohup.out -rw-r--r-- 1 3434 3434 3420 Nov 5 2020 NOTICE -rwxr-xr-x 1 3434 3434 87734252 Nov 5 2020 prometheus -rw-r--r-- 1 root root 1259 Sep 4 16:58 prometheus.yml -rwxr-xr-x 1 3434 3434 77801592 Nov 5 2020 promtool -rwxr-xr-x 1 3434 3434 16805601 Oct 1 2020 pushgateway修改配置文件:vi prometheus.yml 增加pushgateway的job到prometheus中:
- job_name: 'bigdata-grafana' static_configs: - targets: [‘centos7-1:9091']-
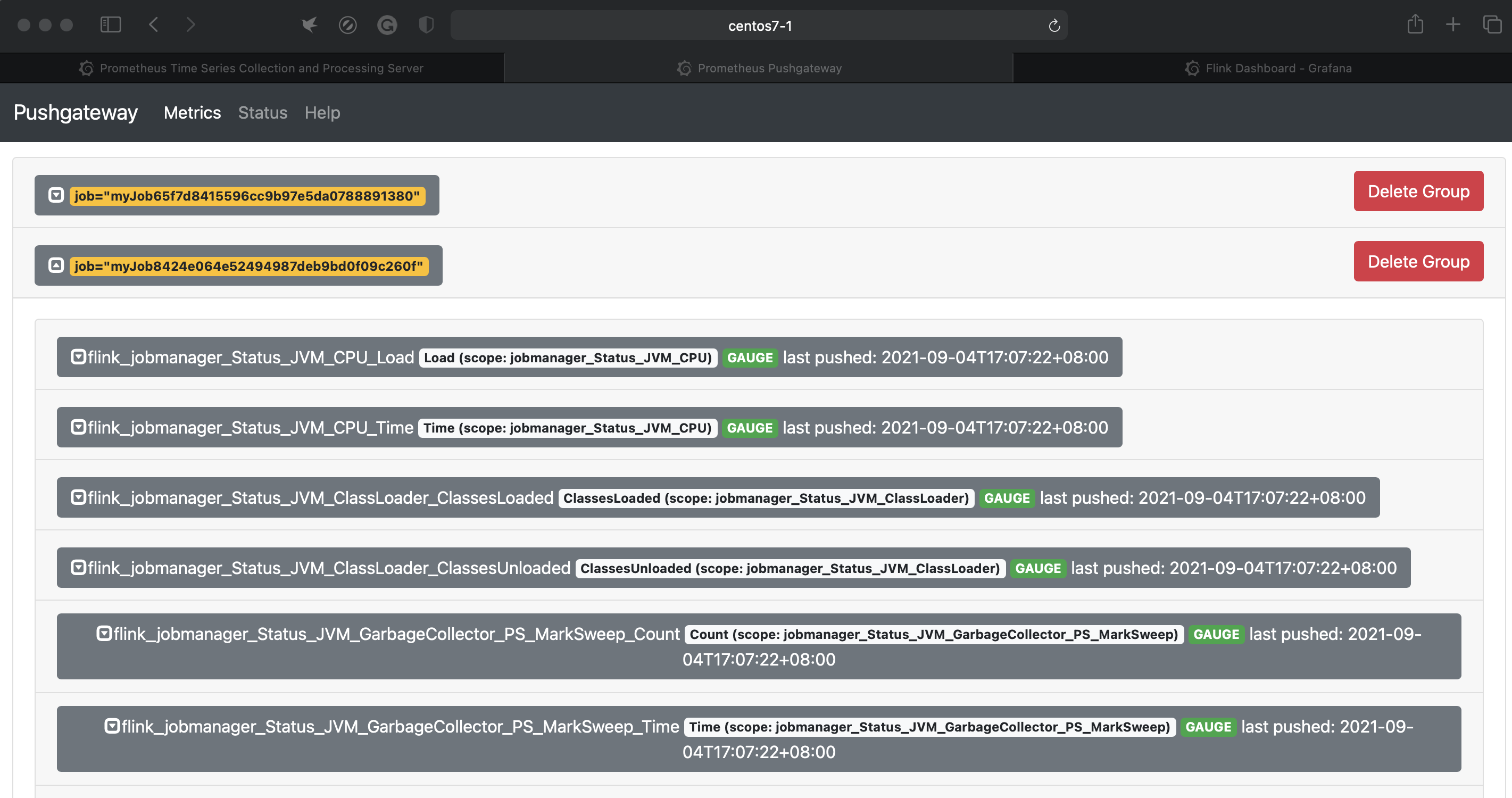
webUI:
配置好之后启动flink集群就可以看到pushgateway的界面有数据
-
步骤6:通过grafana工具监控,可视化效果友好:
下载grafana-7.3.1-1.x86_64.rpm
wget [https://dl.grafana.com/oss/release/grafana-7.3.1-1.x86_64.rpm](https://dl.grafana.com/oss/release/grafana-7.3.1-1.x86_64.rpm) yum install grafana-7.3.1-1.x86_64.rpm ➜ ~ whereis grafana grafana: /etc/grafana /usr/share/grafana # 启动 sudo systemctl start grafana-server # 查看状态 sudo systemctl status grafana-server访问3000端口:centos7-1:3000 (会要求输入账号和密码,初始值为 admin/admin)
-
配置监控项:
-
dashboard模版
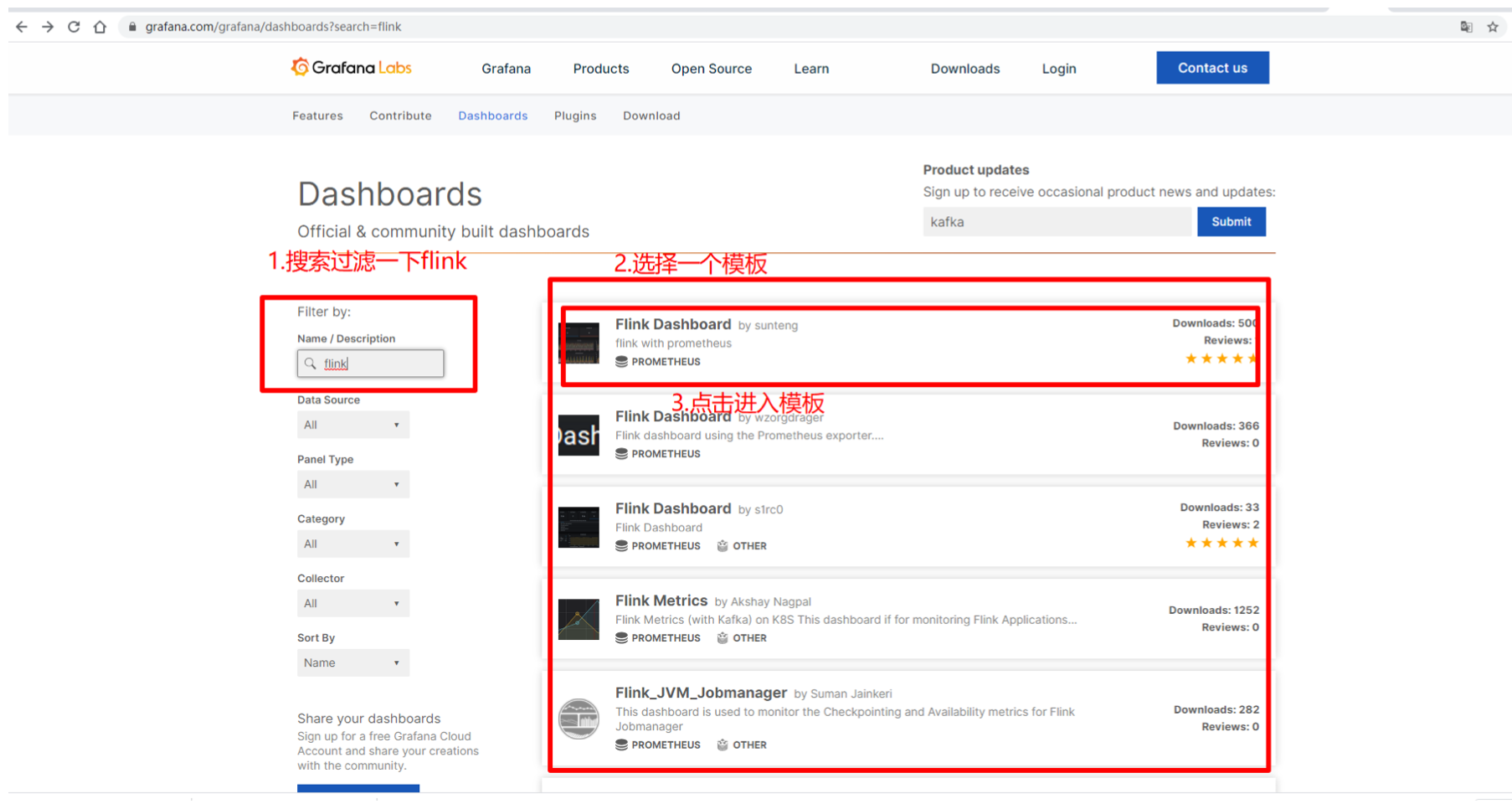
https://grafana.com/grafana/dashboards?search=flink
选择一个flink的模板
-
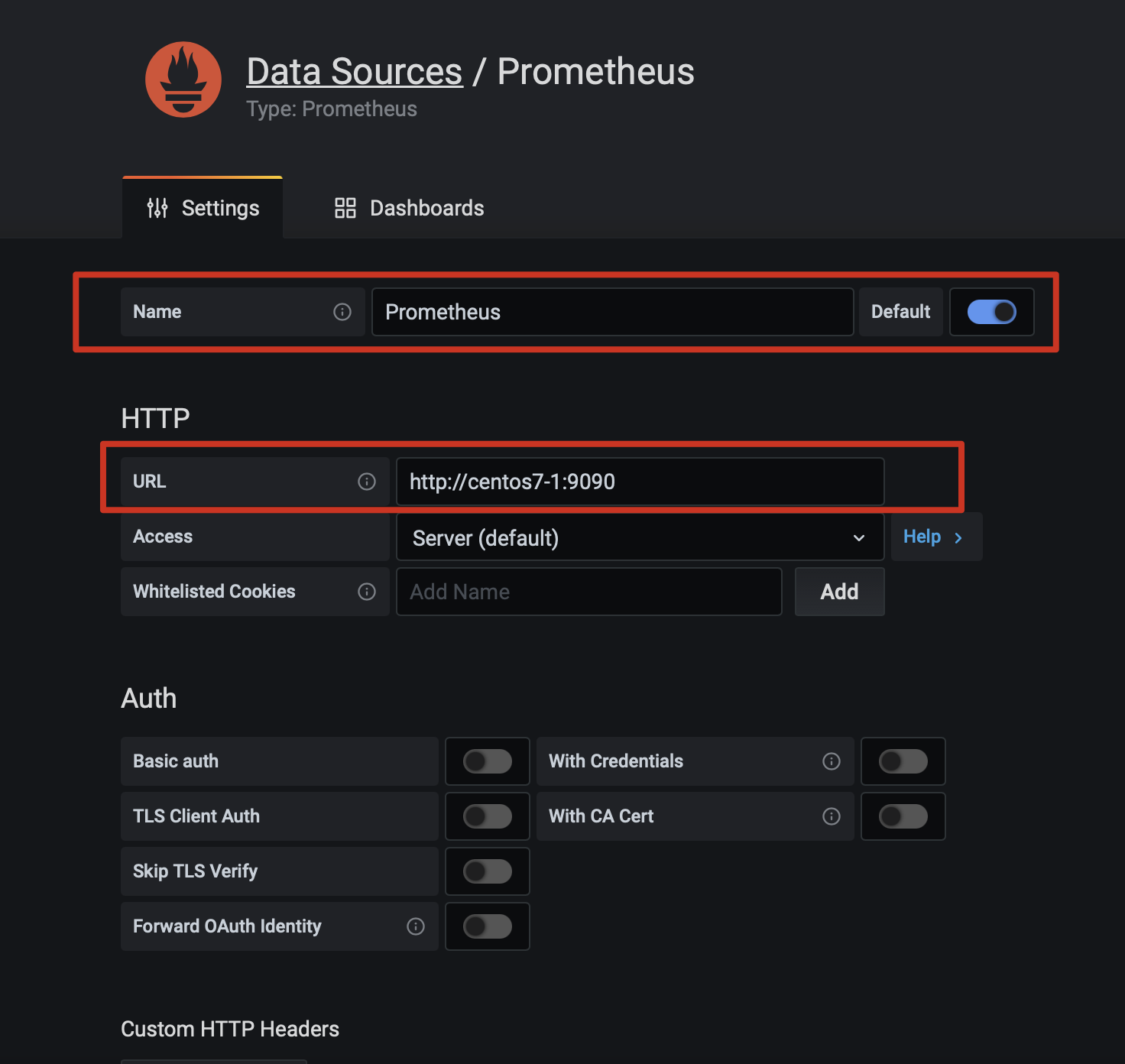
添加datasource
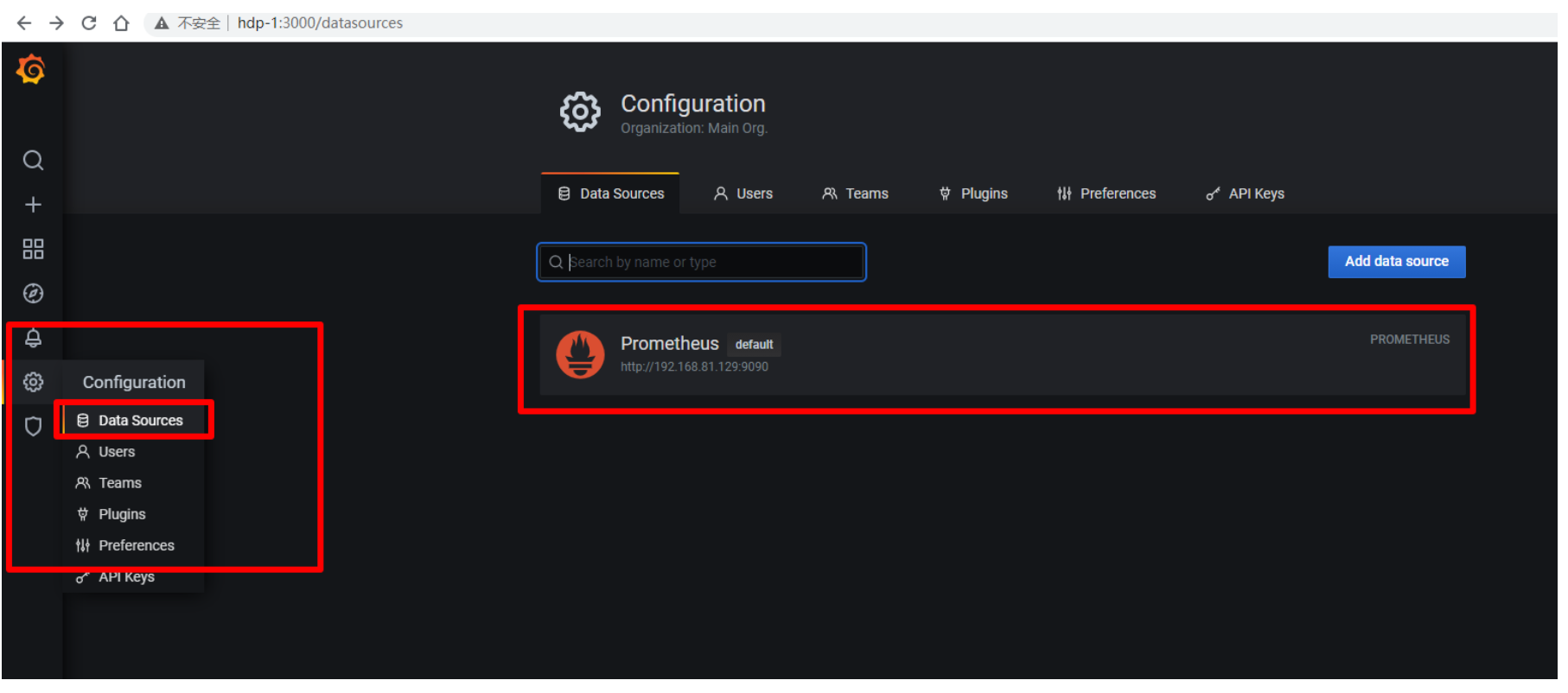
在prometheus页面:选择setting中的dataSource配置数据源:
-
选择import
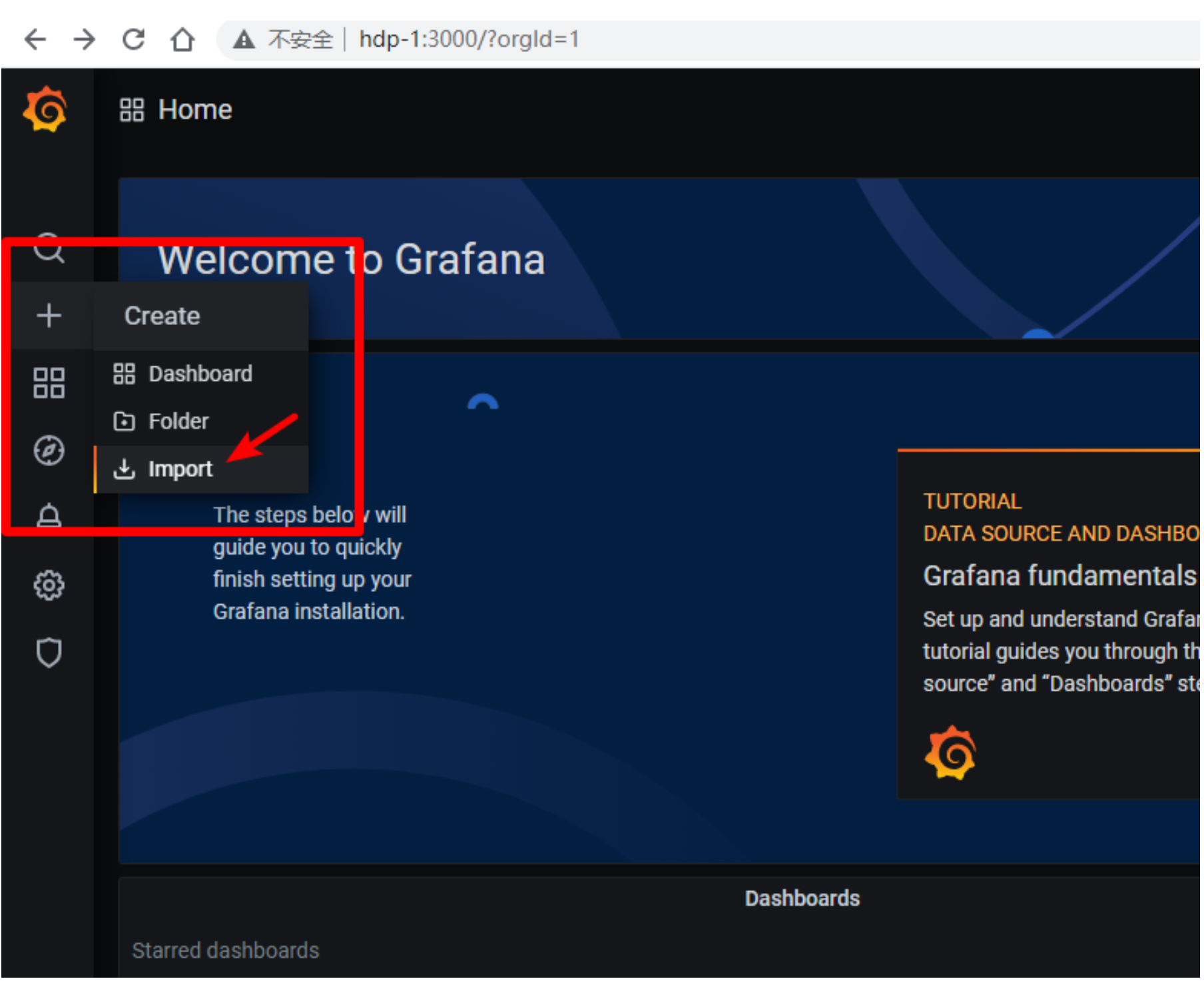
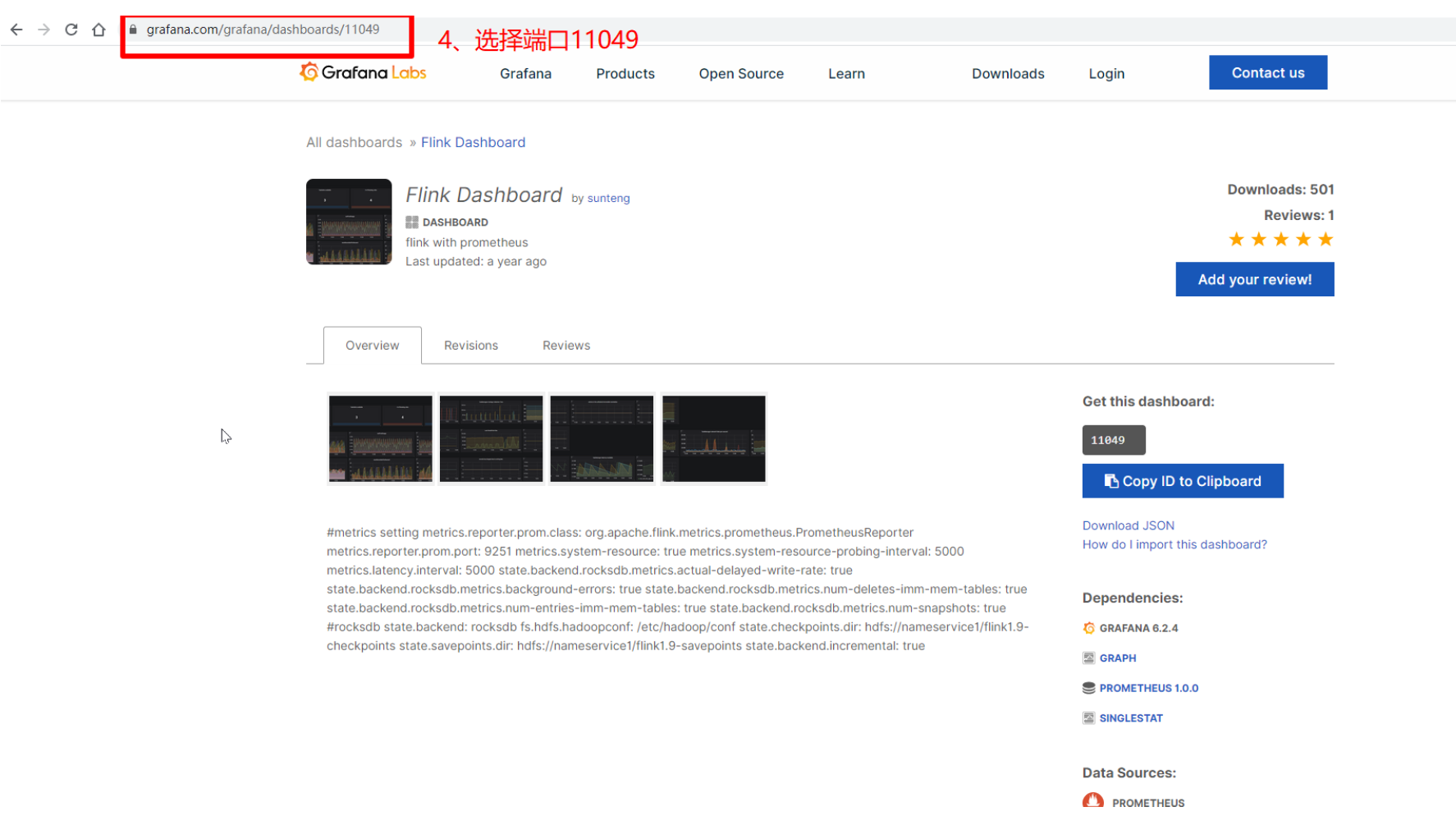
-
填入11049端口,点击load
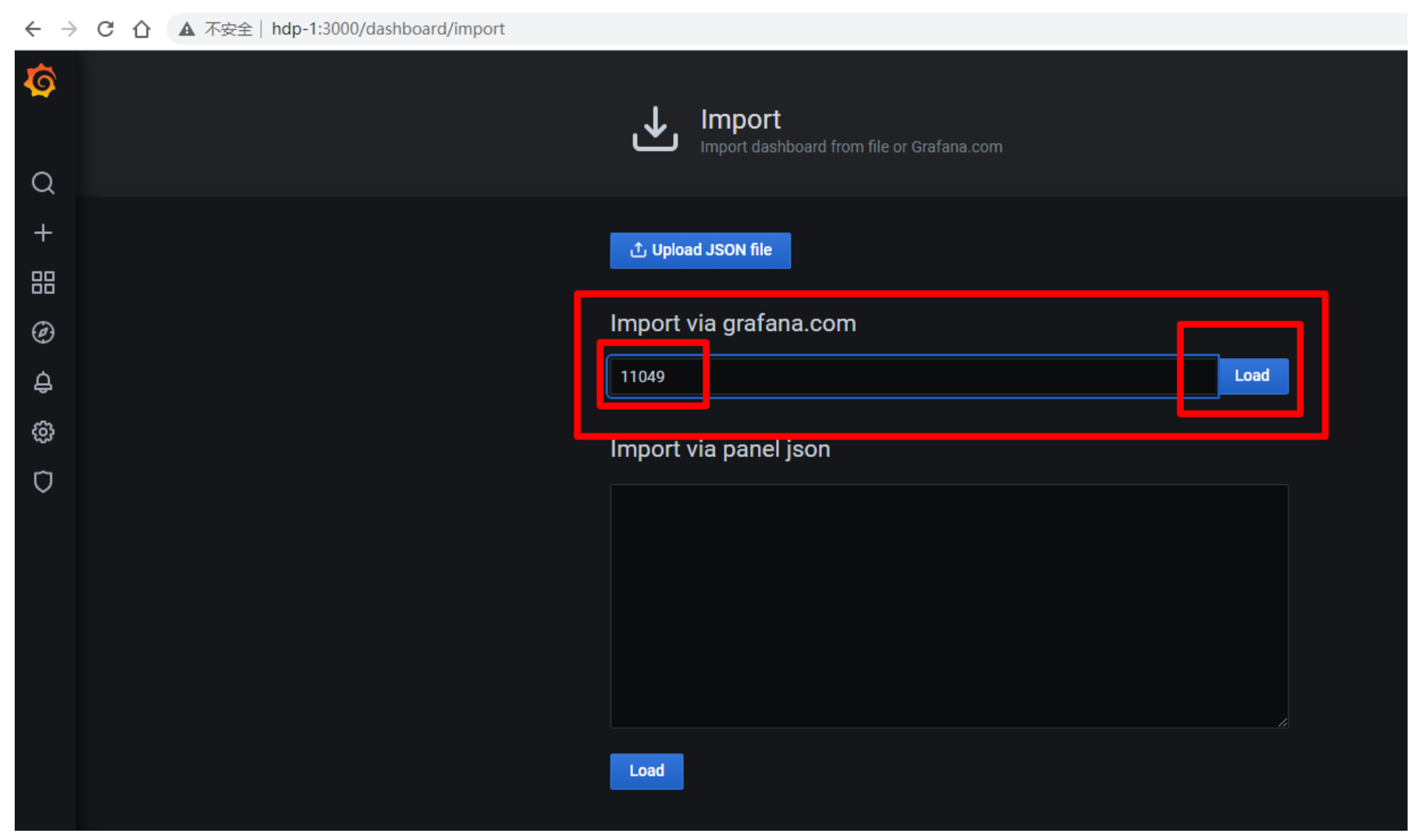
-
import
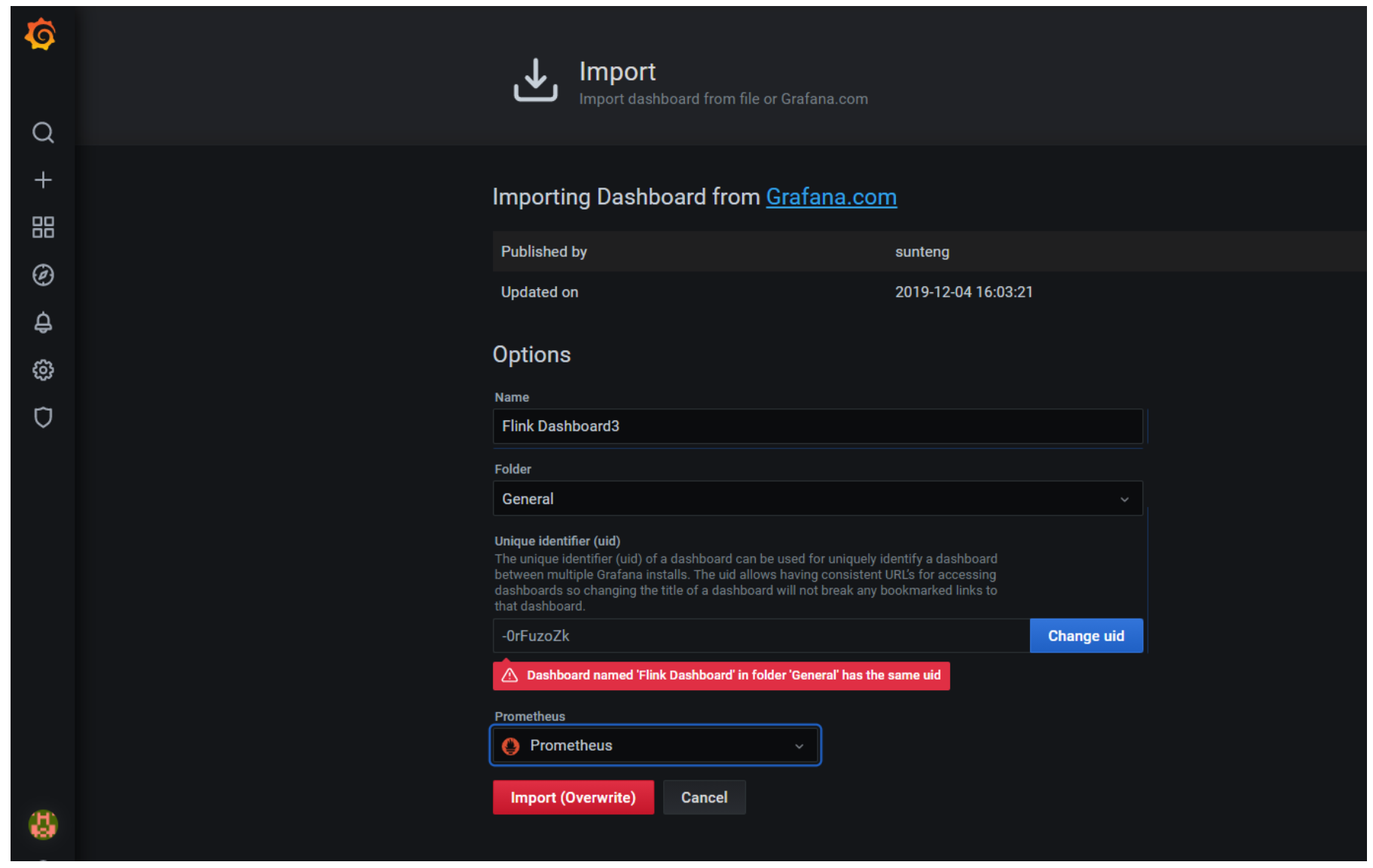
-
查看监控数据
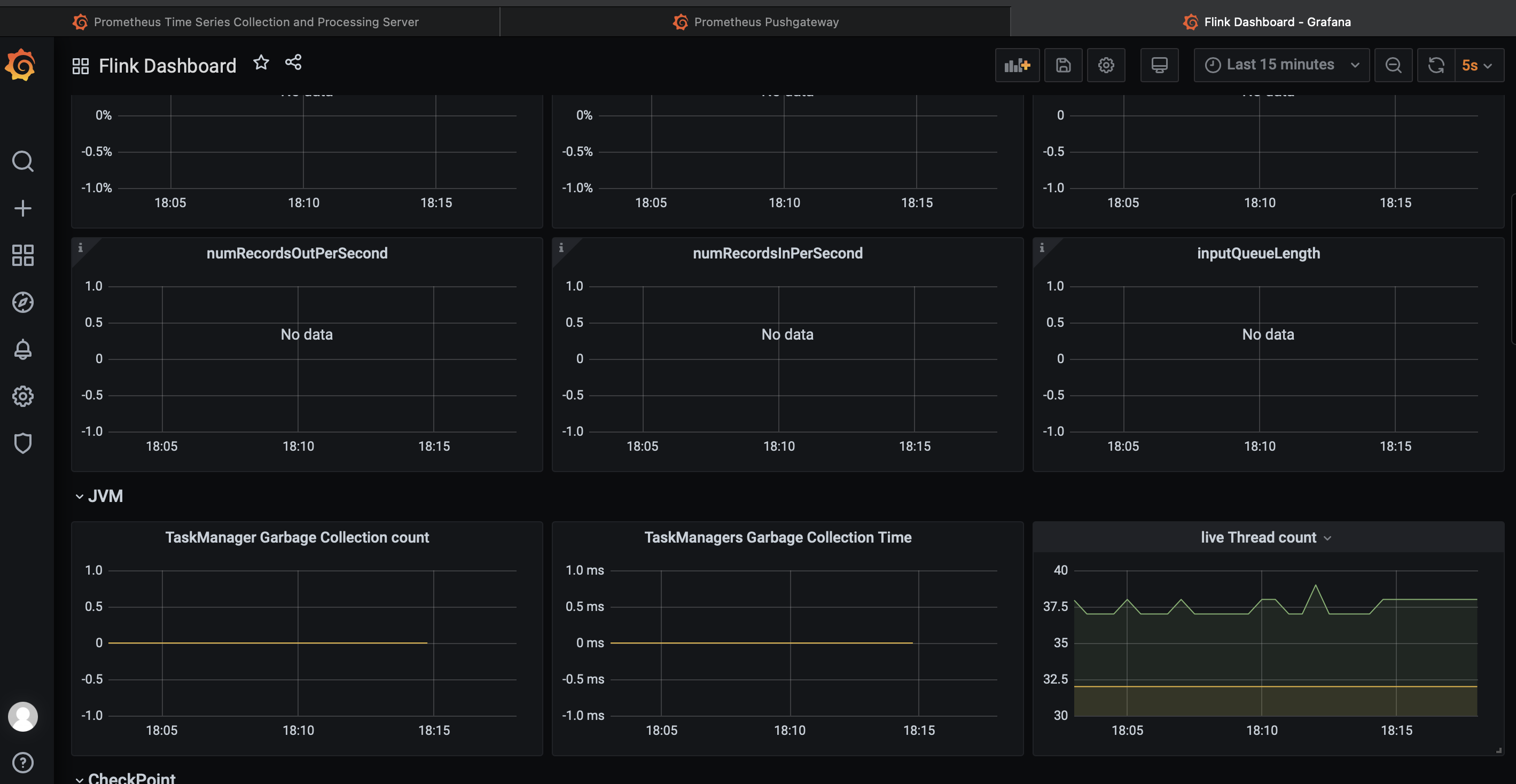
-
-
-
-
redis监控
-
安装插件
新的Redis Data Source for Grafana 插件可以连接到任何Redisdatabase,包括开源Redis、Redis Enterprise和 Redis Enterprise Cloud,并且可以与Grafana 7.0及以后的版本一起使用。如果您已经有了Grafana 7.0,您可以使 用这个grafana-cli命令来安装。
在 /usr/share/grafana/bin下
grafana-cli plugins install redis-datasource # 重启服务 service grafana-server restart -
add datasource
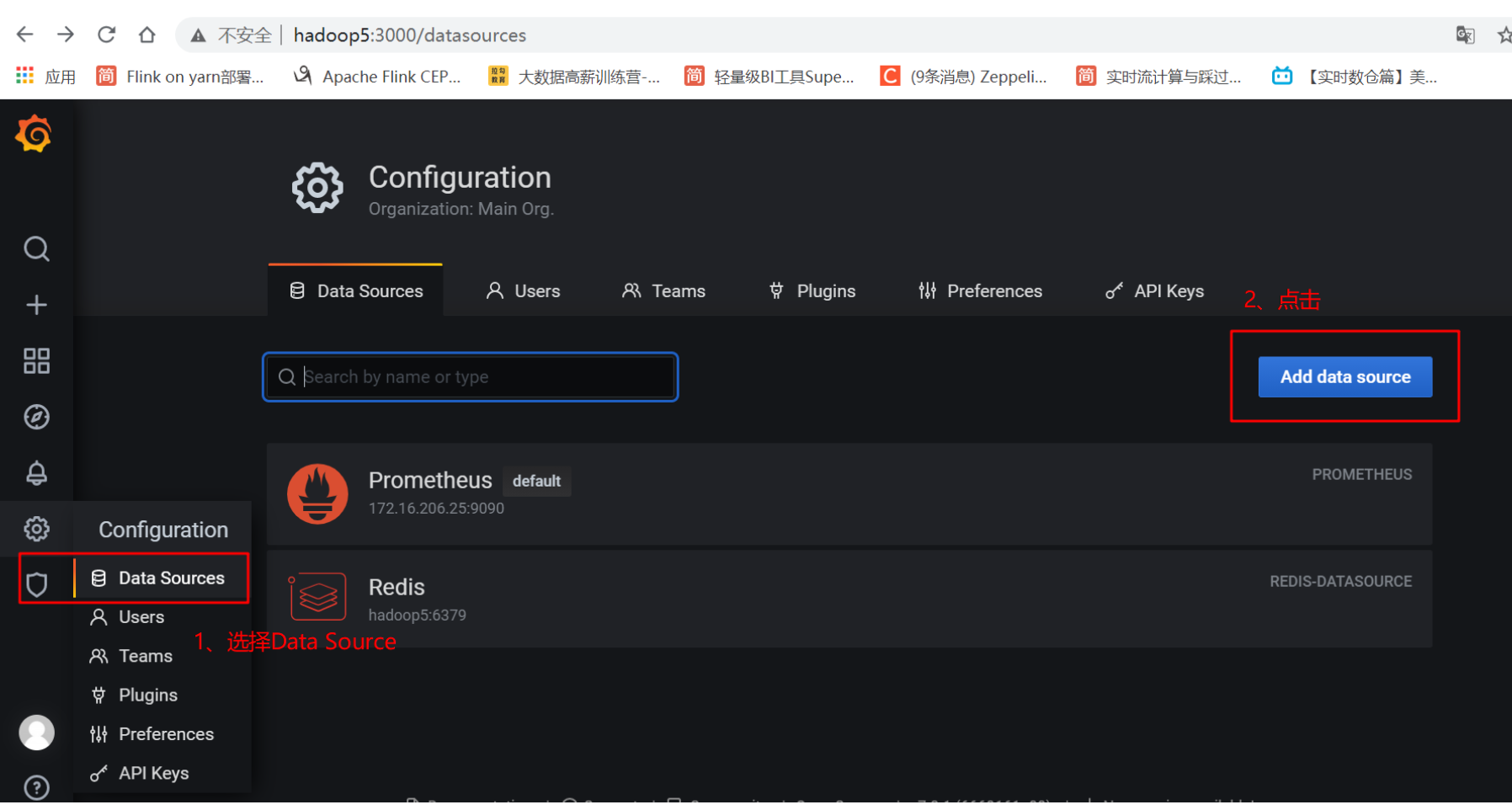
- 找到redis插件
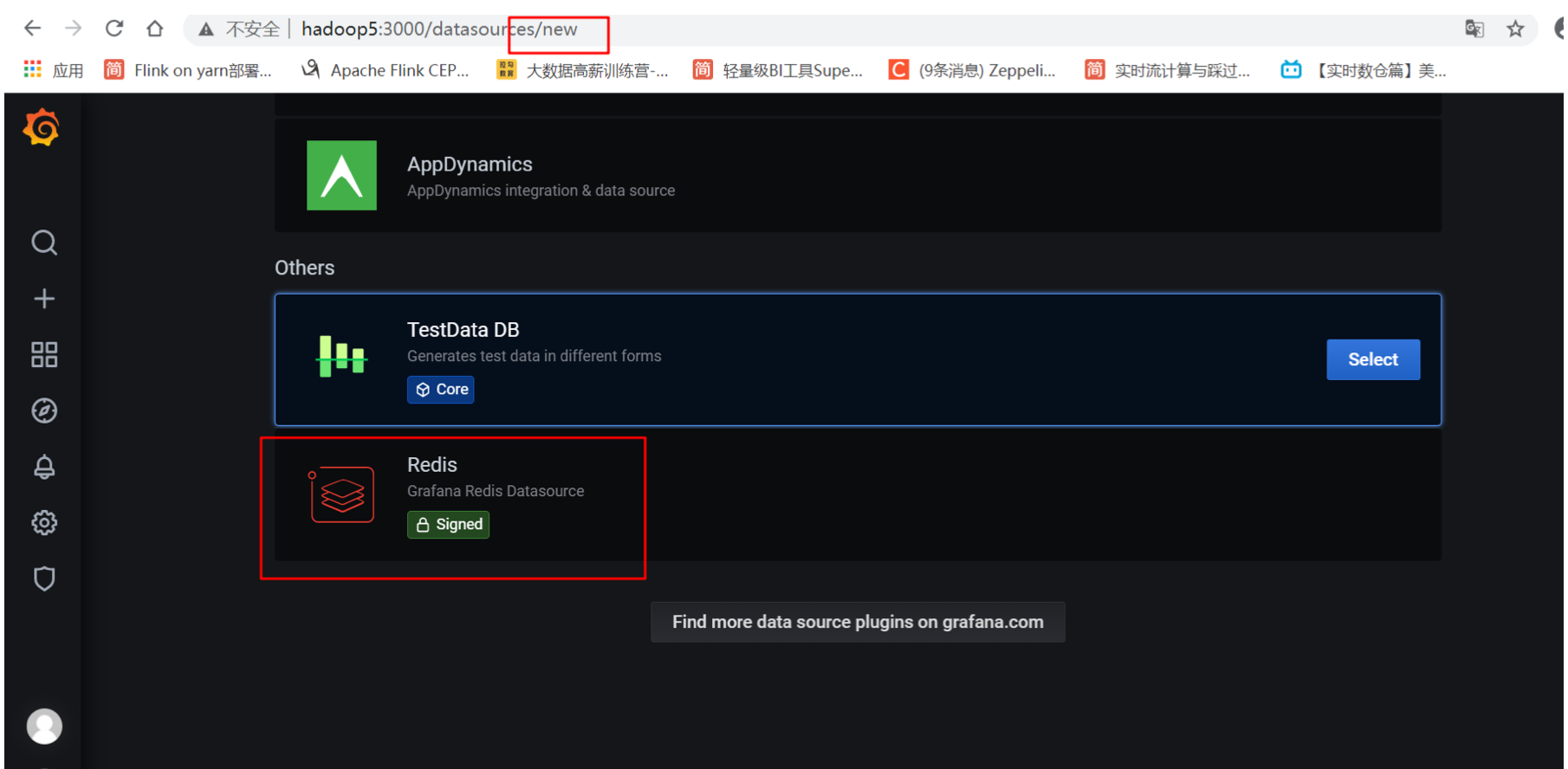
- 找到redis插件
-
选择Dashboard
-
Add new panel
-
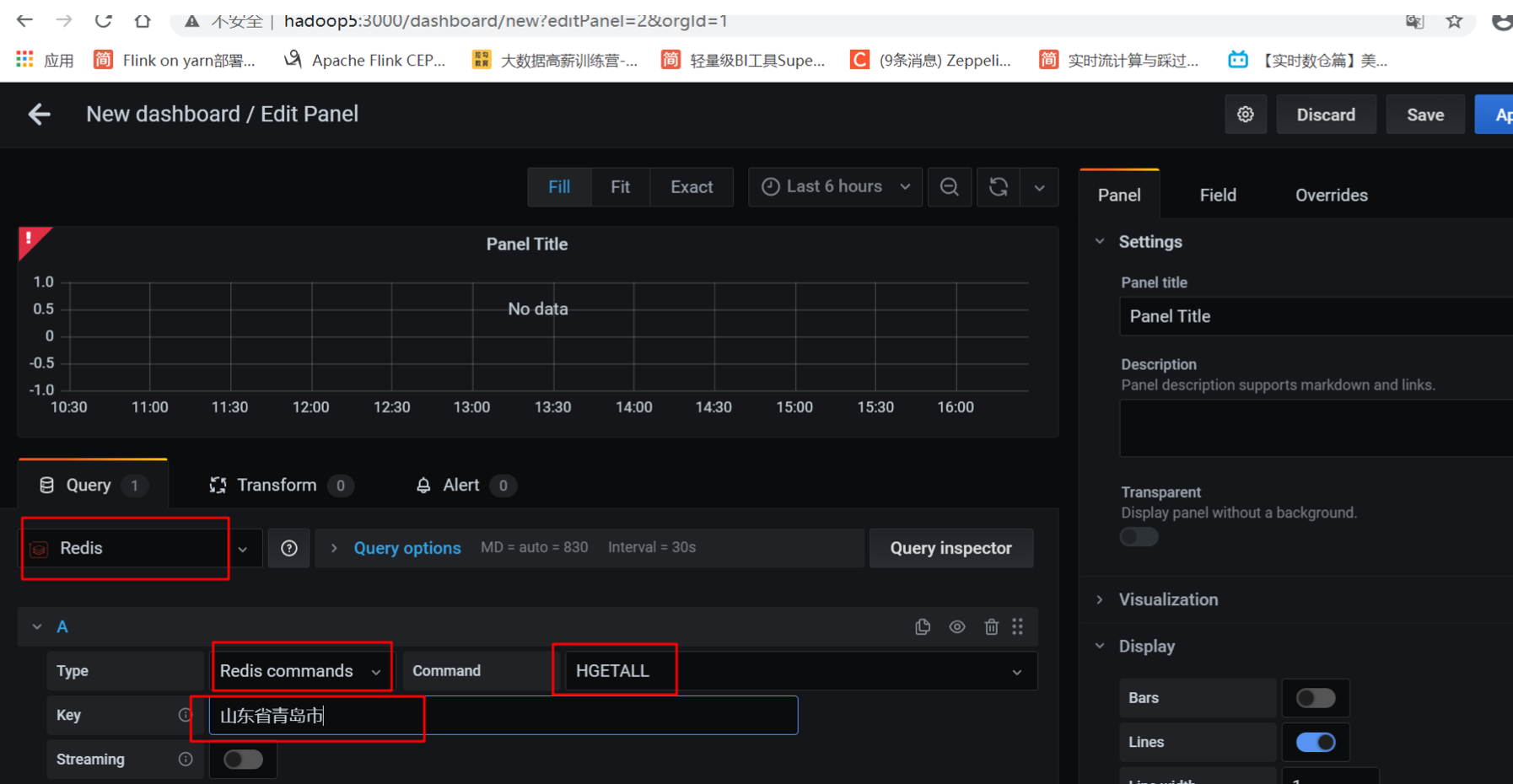
分别选择Redis、Redis commands 、hgetall、 然后填入key:山东省青岛市
-
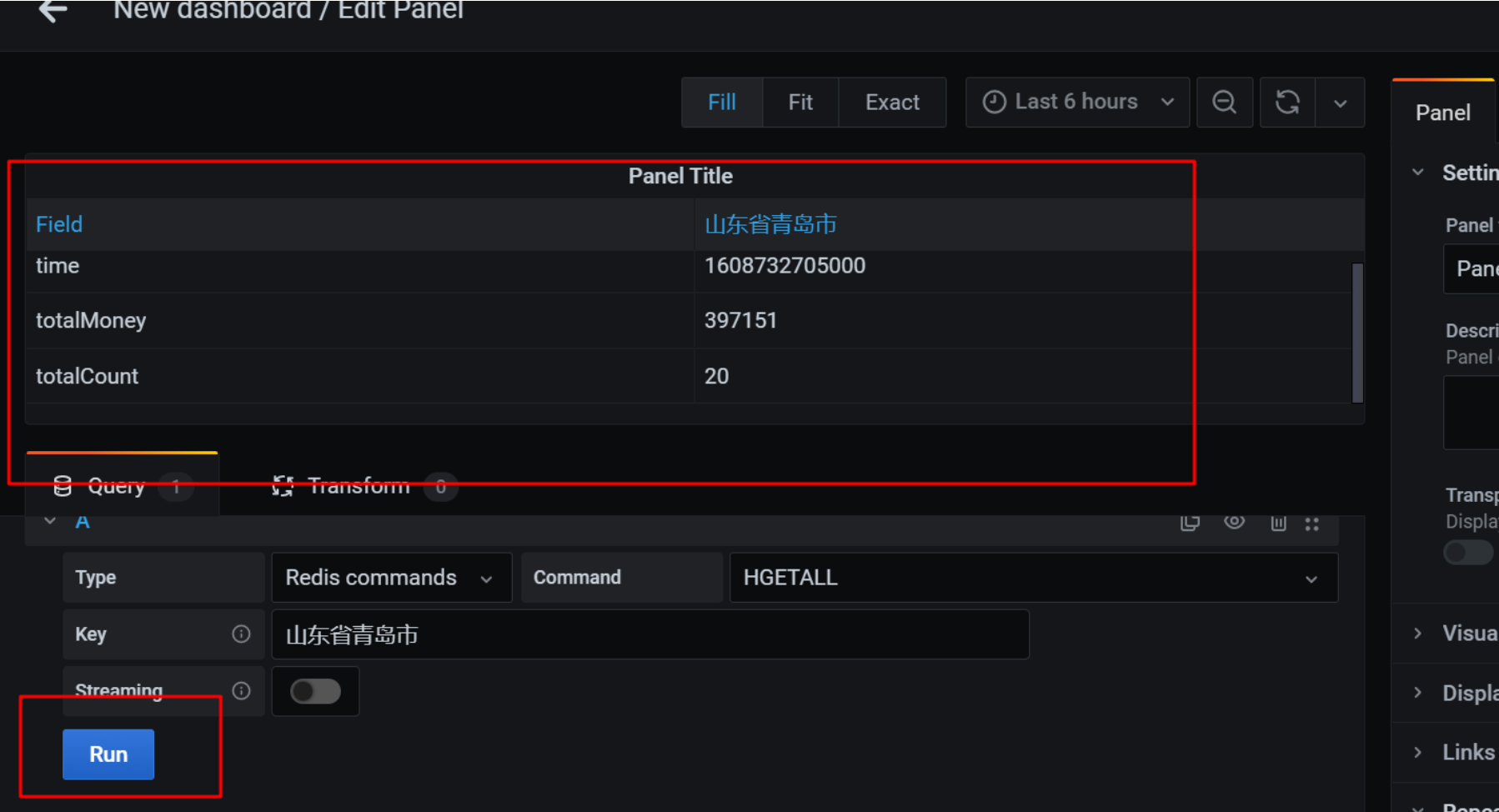
点击run运行,查看结果
-
-
数据质量
数据质量概述
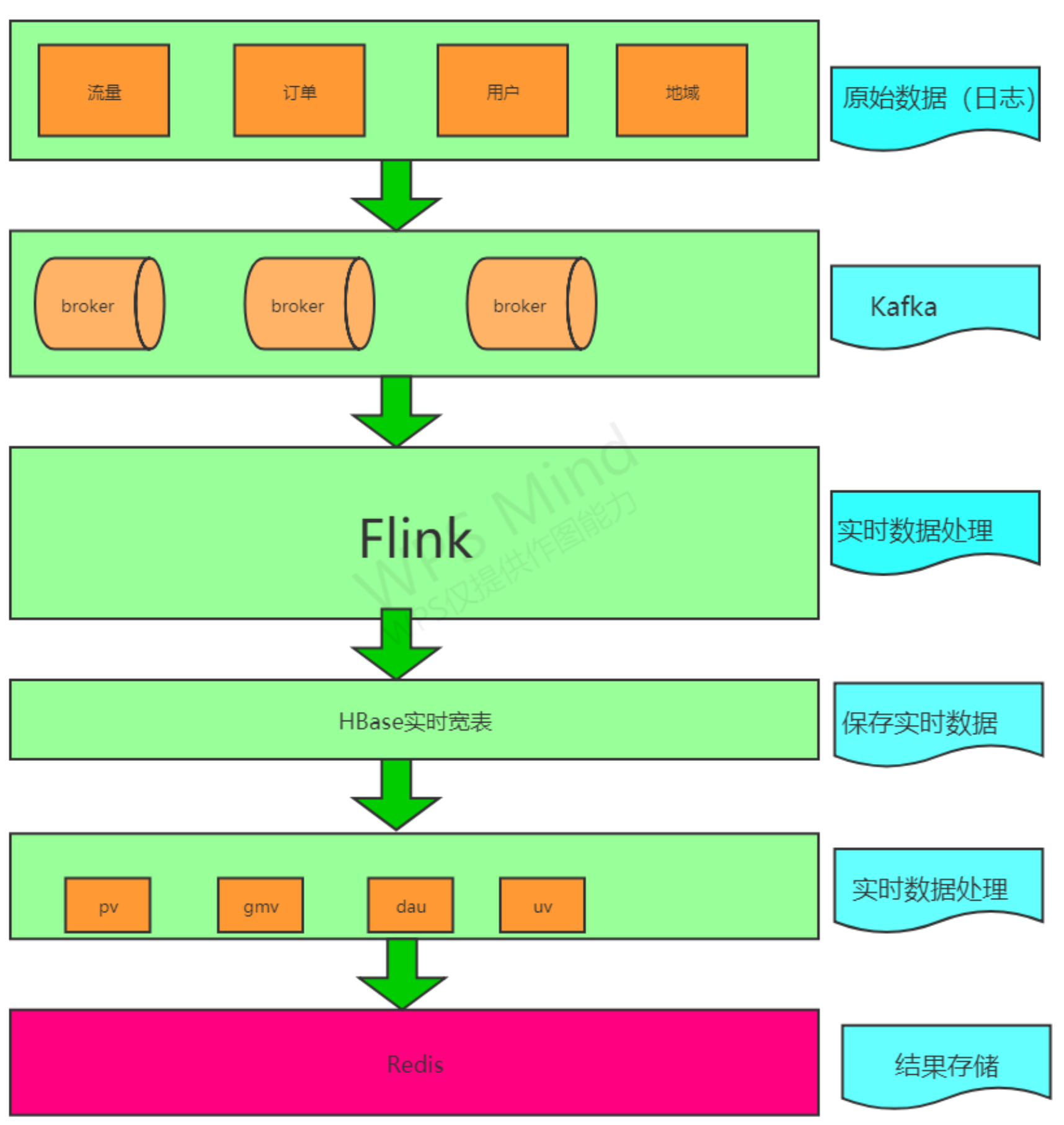
流程图描述了一般的实时数据计算流程,接收日志或者MQ到kafka,用Flink进行处理和计算(指标),将最终计算结 果(指标)存储在redis中,最后查询出redis中的数据给大屏、看板等展示。
但是在整个过程中,不得不思考一下,最后计算出来的存储在redis中指标数据是不是正确的呢?怎么能给用户或者 老板一个信服的理由呢?
比如说:离线的同事说离线昨天的数据订单是1w,实时昨天的数据却是2w,存在这么大的误差,到底是实时计算出 问题了,还是离线出问题了呢?
对于上图中加工的实时宽表数据,可以进行持久化,进行存储。
这样,实时数据也有明细数据,就可以和离线数据进行比对了,到底是日志丢失还是消息没有发送或者计算的业务逻辑有问题,就能够一目了然。
-
UV(Unique visitor)
是指通过互联网访问、浏览这个网页的自然人。访问您网站的一台电脑客户端为一个访客。
00:00-24:00内相同的客户端只被计算一次。 一天内同个访客多次访问仅计算一个UV。 -
IP(Internet Protocol)
独立IP是指访问过某站点的IP总数,以用户的IP地址作为统计依据。00:00-24:00内相同IP 地址之被计算一次。 UV与IP区别: 如:你和你的家人用各自的账号在同一台电脑上登录新浪微博,则IP数+1,UV数+2。由于使用的是同 一台电脑,所以IP不变,但使用的不同账号,所以UV+2
-
PV(Page View)
即页面浏览量或点击量,用户每1次对网站中的每个网页访问均被记录1个PV。用户对同一页面的 多次访问,访问量累计,用以衡量网站用户访问的网页数量
-
VV(Visit View)
用以统计所有访客1天内访问网站的次数。当访客完成所有浏览并最终关掉该网站的所有页面时便 完成了一次访问,同一访客1天内可能有多次访问行为,访问次数累计。 PV与VV区别: 如:你今天10点钟打开了百度,访问了它的三个页面;11点钟又打开了百度,访问了它的两个页面, 则PV数+5,VV数+2. PV是指页面的浏览次数,VV是指你访问网站的次数。
-
DAU(Daily Active User)
DAU(Daily Active User)日活跃用户数量。常用于反映网站、互联网应用或网络游戏的运营情况。DAU通常统计一日 (统计日)之内,登录或使用了某个产品的用户数(去除重复登录的用户),这与流量统计工具里的访客(UV)概 念相似。
-
GMV:Gross Merchandise Volume
GMV:Gross Merchandise Volume,是成交总额(一定时间段内)的意思。多用于电商行业,一般包含拍下未支付订单金额。
Flink双流Join
- Join大体分类只有两种:Window Join和Interval Join。Window Join又可以根据Window的类型细分出3种: Tumbling Window Join、Sliding Window Join、Session Widnow Join。
- Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join 操作;
- interval join也是利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清理;
- 目前Stream join的结果是数据的笛卡尔积;
- 日常使用中的一些问题,数据延迟、window序列化相关。
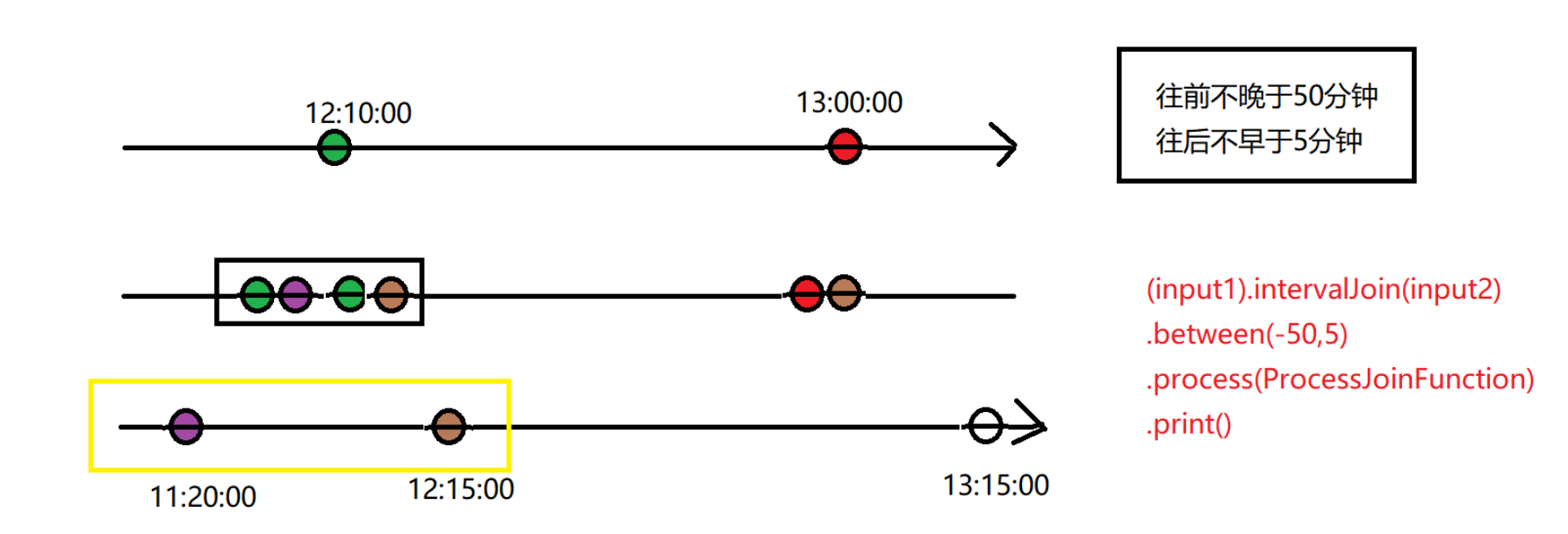
基于时间的双流join
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
object TimeJoin {
case class UserClickLog(userId: String, eventTime: String, eventType: String, pageId:
String)
case class UserBrowseLog(userId: String, eventTime: String, productId: String, productPrice: String)
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val clickStream = env.fromElements(
UserClickLog("user_1", "1500", "click", "page_1"),
UserClickLog("user_1", "2000", "click", "page_1")
)
.assignAscendingTimestamps(_.eventTime.toLong*1000)
.keyBy(_.userId)
val browseStream = env.fromElements(
UserBrowseLog("user_1", "1000", "product_1", "10"),
UserBrowseLog("user_1", "1500", "product_1", "10"),
UserBrowseLog("user_1", "1501", "product_1", "10"),
UserBrowseLog("user_1", "1502", "product_1", "10")
)
.assignAscendingTimestamps(_.eventTime.toLong*1000)
.keyBy(_.userId)
clickStream.intervalJoin(browseStream)
.between(Time.minutes(-10),Time.seconds(0))
.process(new IntervalJoinFunc)
.print()
env.execute()
}
class IntervalJoinFunc extends ProcessJoinFunction[UserClickLog, UserBrowseLog, String] {
override def processElement(left: UserClickLog, right: UserBrowseLog, ctx: ProcessJoinFunction[UserClickLog, UserBrowseLog, String]#Context, out: Collector[String]): Unit = {
val str = s"${left} ==> ${right}"
out.collect(str)
}
}
}
基于window的双流join
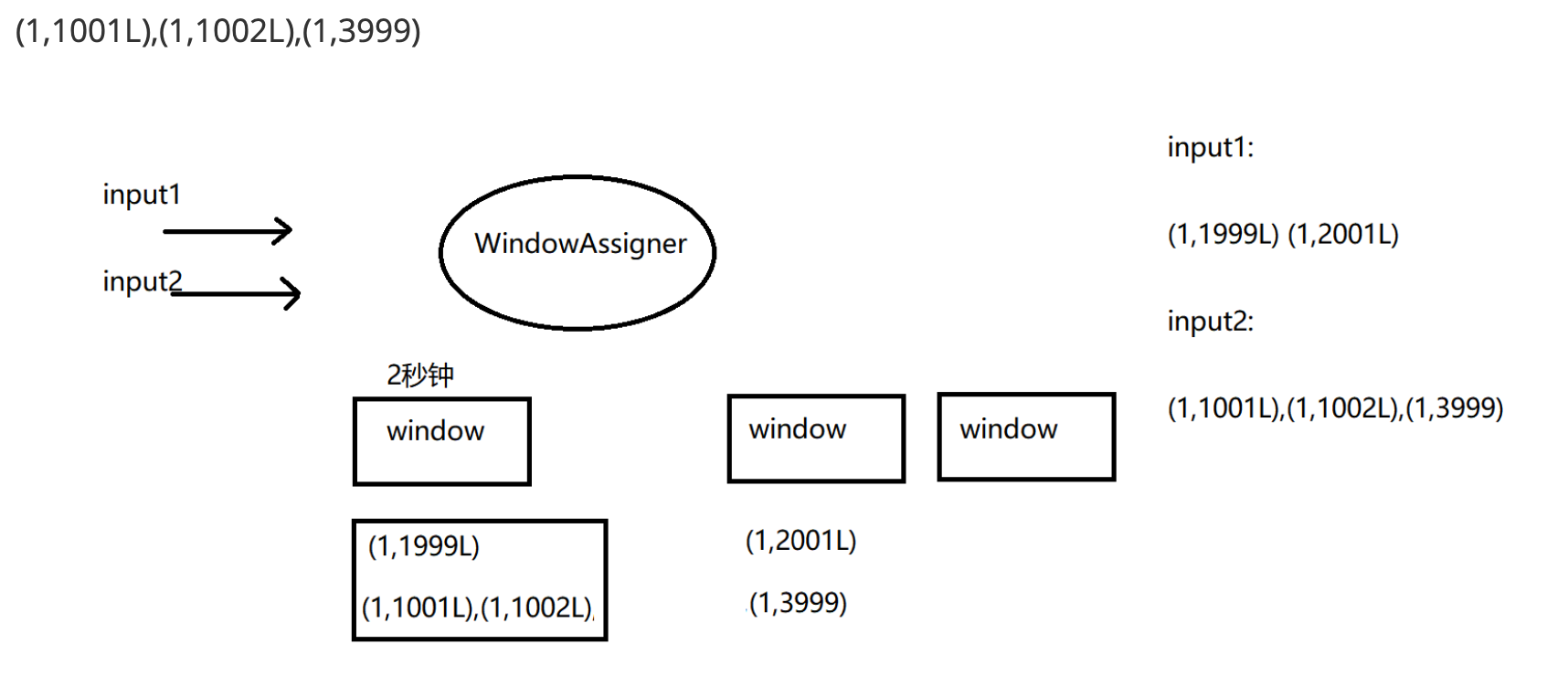
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
/**
* 根据时间窗口去join,跟intervalJoin相比,更加以窗口window为中心
*/
object WindowJoin {
case class UserClickLog(userId: String, eventTime: String, eventType: String, pageId:
String)
case class UserBrowseLog(userId: String, eventTime: String, productId: String, productPrice: String)
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val input1Stream: DataStream[(Int, Long)] = env.fromElements((1, 1999L), (1,
2000L),(1, 2001L)).assignAscendingTimestamps(_._2)
val input2Stream: DataStream[(Int, Long)] = env.fromElements((1, 1000L),(1, 1001L), (1, 1002L), (1, 1500L),(1,
3999L),(1, 4000L)).assignAscendingTimestamps(_._2)
input1Stream.join(input2Stream)
.where(k => k._1) //left key
.equalTo(k=>k._1) //right key
.window(TumblingEventTimeWindows.of(Time.seconds(2))) //window
.apply{(e1, e2) => e1 + "...." + e2} //
.print()
/**
* (1,1999)....(1,1000)
* (1,1999)....(1,1001)
* (1,1999)....(1,1002)
* (1,1999)....(1,1500)
* (1,2000)....(1,3999)
* (1,2001)....(1,3999)
*/
// .window(TumblingEventTimeWindows.of(Time.seconds(2)))
// 滚动窗口,默认开始偏移量是0,所以从0~1999是一个窗口,2000~3999 是一个窗口
env.execute()
}
}