SqueezeNet & MobileNet
写在前面:
这篇文章是我阅读SqueezeNet 和 MobileNet 之后的理解总结,写给健忘的自己. 要读这篇文章需要了解熟悉卷积网络,如果还不了解,可以先查看这篇文章CNN卷积神经网络
介绍和起因
- 为了更高效的训练网络, 现有的一些经典CNN网络,比如VGG, GoogleNet, ResNet,虽然在预测上精度很高,但是由于参数比较多,所以要把它们训练好还是很消耗资源和时间的.所以需要一个小的模型.
- 当把模型更新到终端的时候需要传输的数据变少
- 方便把模型迁移到嵌入式芯片中
SqueezeNet(2016)
 标题很好的概括了SqueezeNet的特点,AlexNet级别的精度,参数却小了50倍,整个模型的大小不到0.5MB.
标题很好的概括了SqueezeNet的特点,AlexNet级别的精度,参数却小了50倍,整个模型的大小不到0.5MB.
网络结构
网络结构设计的三个策略
- 把3x3的卷积核替换成1x1. 在卷积滤镜数一样的情况下,使用1x1的卷积核和3x3的相比可以把需要的参数缩小9倍.
- 减少输入到3x3卷积的输入通道数. 一个卷积核是3x3的卷积层需要的参数为(输入通道数)x(滤镜数)x(3x3).所以为了减少参数.不仅可以参照策略1减少卷积核为3x3的卷积层,还可以通过减少输入到3x3卷积的 输入通道数.(现在看不懂没关系,后面会详细解释)
- 延迟下取样,这样卷积网络会拥有更大的激活特征图. 卷积网络输出特征图的大小由输入数据的大小(图片的 长 和 宽),还有卷积的步长(stride)决定.如果 stride > 1,那么输出图约为输入图的大小除以stride(具体大小受padding的策略影响),数据每次变小都会损失一些信息.所以在卷积网络中,前段尽量设置stride=1,stride>1放在网络的靠后阶段,可以保留图片的更多特征,这样可以有效提高预测的精度.
前两个策略的目的在于减小网络大小,第三个策略的目的在于提高精度.
Fire Module <-重点
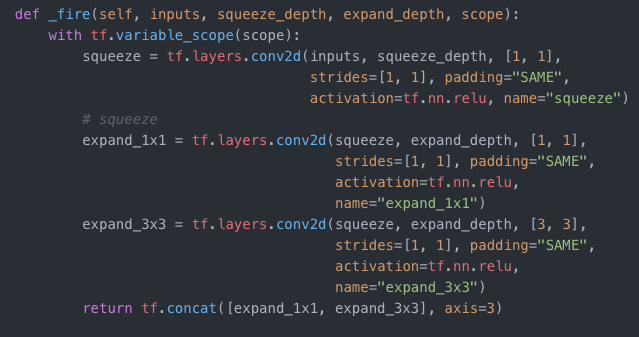
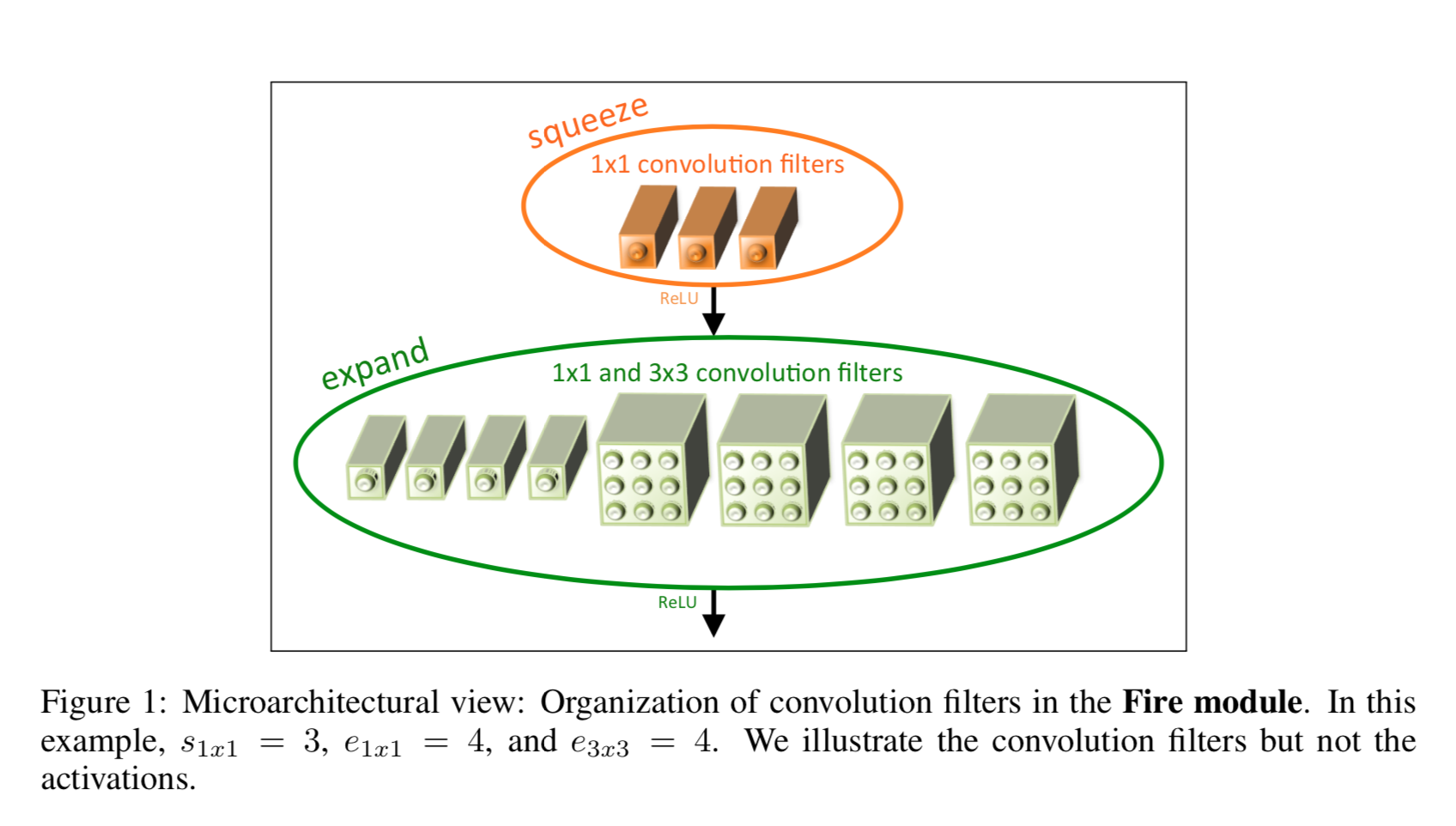 这个结构是squeeze的关键结构.如上图所示,fire module由两部分组成,一个是squeeze(1x1)的卷积网络;还有一个expand,它由1x1和3x3卷积层拼接到一起构成.数据传进来先经过squeeze压缩,然后expand展开.这里设置squeeze的滤镜数小于expand层拼接后滤镜数.这就是前面提到的减少输入到3x3卷积层的 输入通道数 的操作方式.Tensorflow的实现代码如下:
这个结构是squeeze的关键结构.如上图所示,fire module由两部分组成,一个是squeeze(1x1)的卷积网络;还有一个expand,它由1x1和3x3卷积层拼接到一起构成.数据传进来先经过squeeze压缩,然后expand展开.这里设置squeeze的滤镜数小于expand层拼接后滤镜数.这就是前面提到的减少输入到3x3卷积层的 输入通道数 的操作方式.Tensorflow的实现代码如下:
整体网络结构
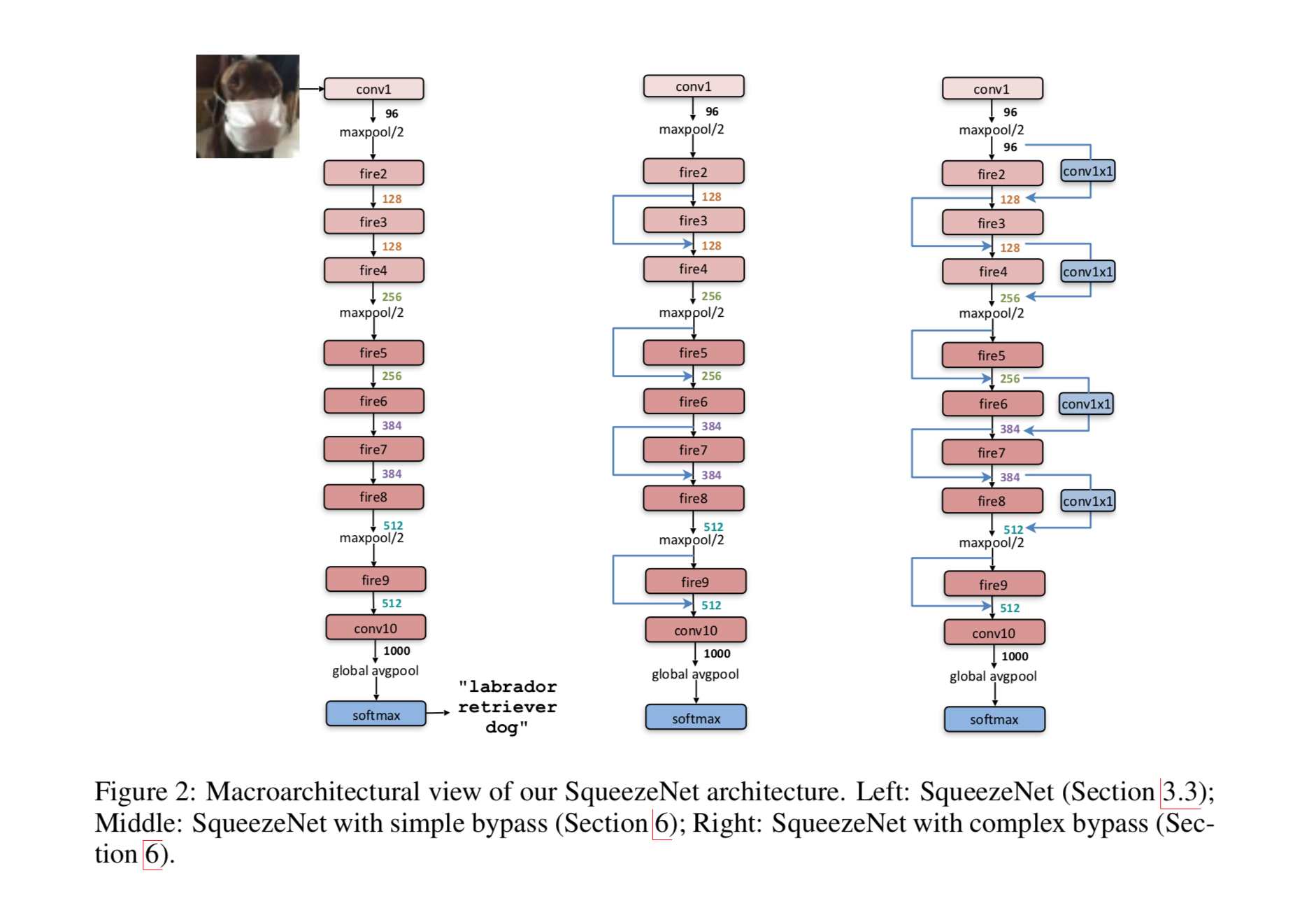 左边是一个朴素的SqueezeNet,中间是加了简单捷径的SqueezeNet,右边是加了复杂捷径的SqueezeNet.关于这个捷径的好处,可以参考resnet的paper.
如上图SqueezeNet的第一层是一个传统卷积层,后面跟着8个fire module,最后是一个1x1的卷积层,滤镜数为输出的分类数.
左边是一个朴素的SqueezeNet,中间是加了简单捷径的SqueezeNet,右边是加了复杂捷径的SqueezeNet.关于这个捷径的好处,可以参考resnet的paper.
如上图SqueezeNet的第一层是一个传统卷积层,后面跟着8个fire module,最后是一个1x1的卷积层,滤镜数为输出的分类数.
具体参数如下
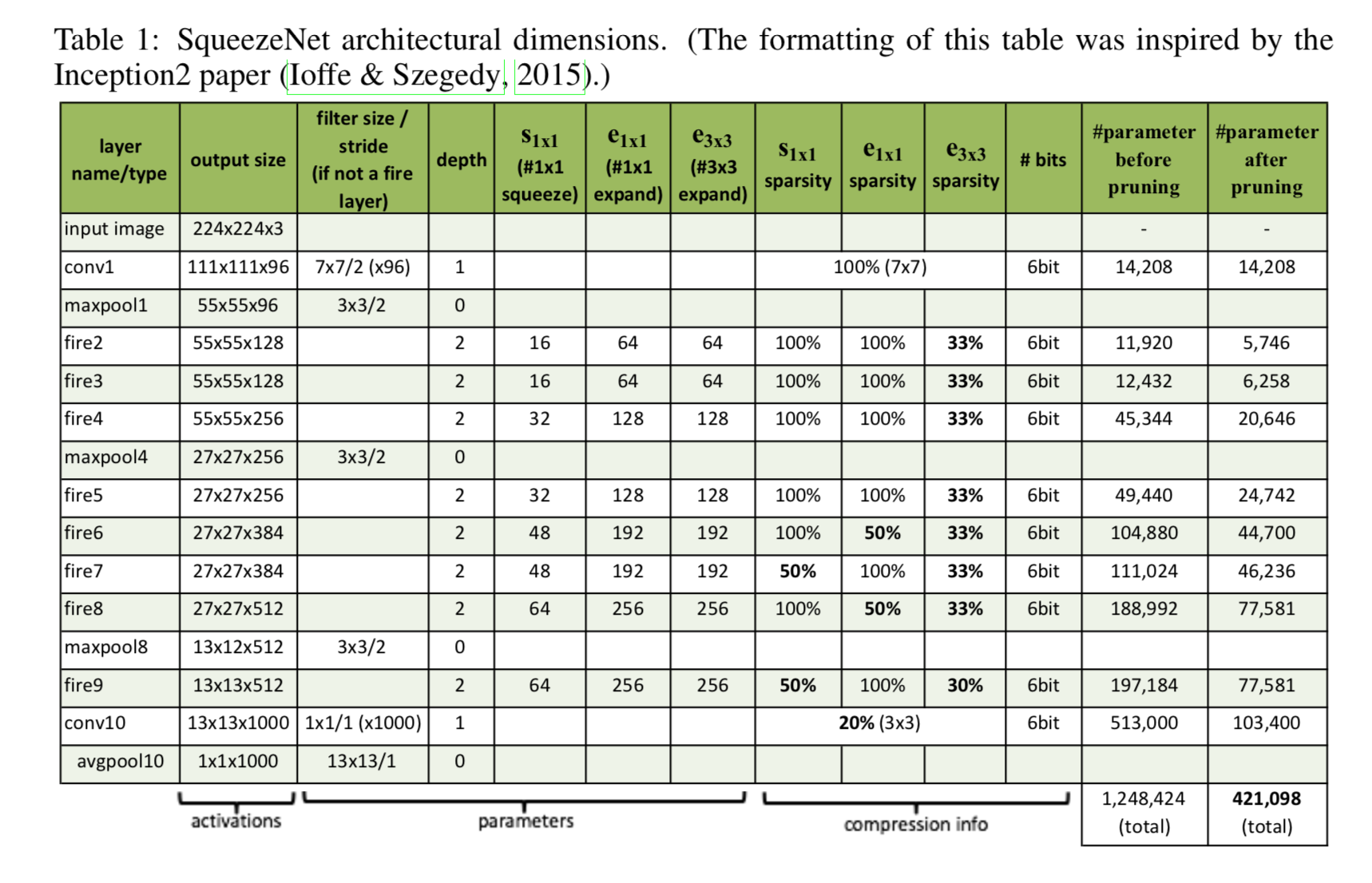
SqueezeNet的表现
采用不同压缩率时的准确率
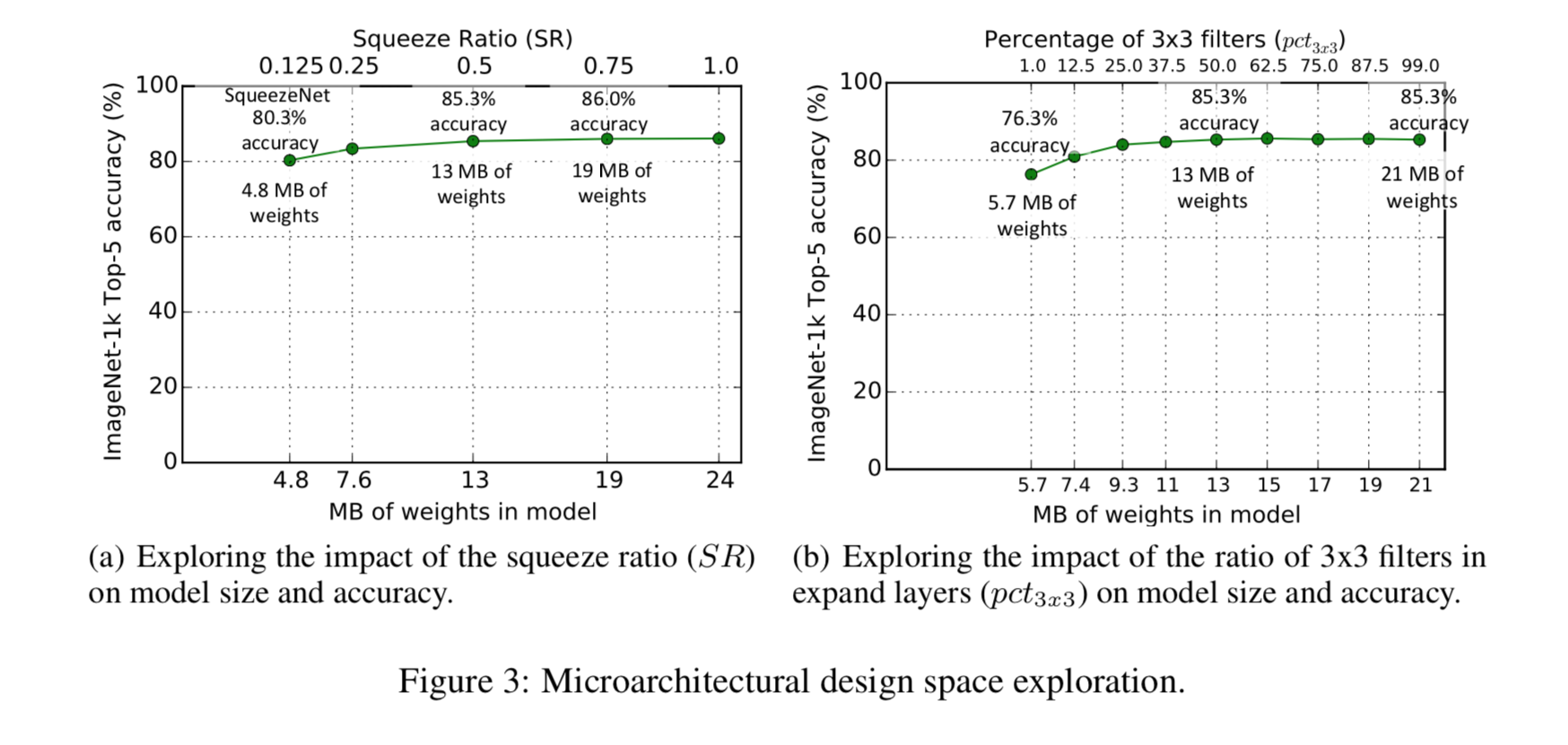 不同网络结构的准确率
不同网络结构的准确率
 补充一下, Top-1 Accuracy 是指网络输出中概率最高的那个刚好是目标标签.Top-5 Accuracy 是指网络输出中概率最高的前5个类别中有一个是目标标签.都是计算预测标签吻合预测标签数占输入数据量的比例.
补充一下, Top-1 Accuracy 是指网络输出中概率最高的那个刚好是目标标签.Top-5 Accuracy 是指网络输出中概率最高的前5个类别中有一个是目标标签.都是计算预测标签吻合预测标签数占输入数据量的比例.
MobileNet(2017)
网络结构
深度分离卷积(depthwise separable convolution) <-重点
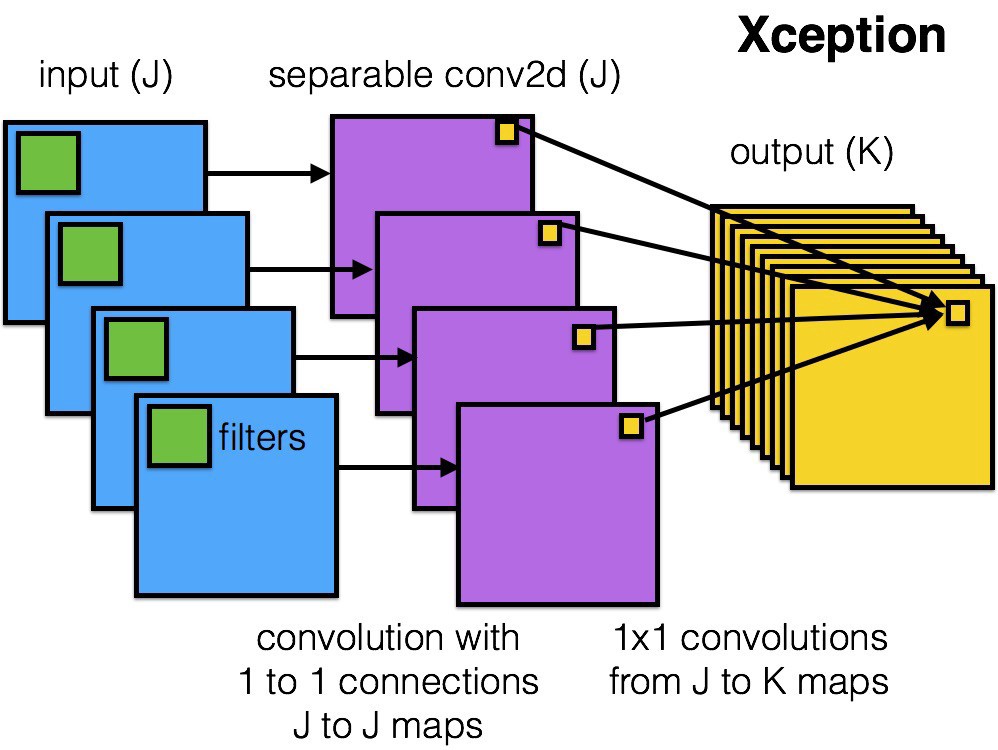 MobileNet是基于 深度分离卷积 搭建.深度分离卷积把标准的卷积过程分成两步来进行计算,先是一个基于深度的卷积,然后是基于点的1x1的卷积.
如上图,深度卷积有跟输入图片深度一样的卷积核(绿色),每个卷积核对输入图(蓝色)中对应的channel进行扫描,然后输出跟输入图深度一样的输出特征图(紫色),这个时候跟正常的卷积计算不同,并没有做加法去叠加不同channel的输出特征图;接下来是用1x1卷积核(黄色)的卷积层对输出特征图进行扫描,最终输出Output.
深度卷积层负责提取输入图的特征,而1x1卷积则负责整合深度卷积层提取的特征. 这种结构跟正常的卷积比既能减少运算量又能减少参数量.
MobileNet是基于 深度分离卷积 搭建.深度分离卷积把标准的卷积过程分成两步来进行计算,先是一个基于深度的卷积,然后是基于点的1x1的卷积.
如上图,深度卷积有跟输入图片深度一样的卷积核(绿色),每个卷积核对输入图(蓝色)中对应的channel进行扫描,然后输出跟输入图深度一样的输出特征图(紫色),这个时候跟正常的卷积计算不同,并没有做加法去叠加不同channel的输出特征图;接下来是用1x1卷积核(黄色)的卷积层对输出特征图进行扫描,最终输出Output.
深度卷积层负责提取输入图的特征,而1x1卷积则负责整合深度卷积层提取的特征. 这种结构跟正常的卷积比既能减少运算量又能减少参数量.
- DK 代表卷积核大小
- DF 代表输出特征图的大小
- M 代表输入channel的数量
- N 代表输出卷积filter的数量
正常卷积需要的参数量为:
DK x DK x M x N
而深度分离卷积只需要:
G = DK x DK x M x 1 + 1 x 1 x M x N = M x (DK x DK + N)
所以深度分离卷积需要的参数和正常卷积的比例为:DK x DK x N/(DK x DK + N)
N>=1, D>=1, 故:深度分离卷积的参数 <= 正常卷积参数
计算量:
正常卷积层的计算量为:
DK x DK x M x N x DF x DF
而深度分离卷积的计算量为:
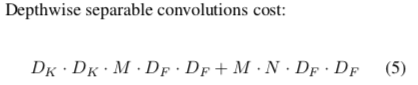
所以正常卷积和深度分离卷积的计算量比例如下:
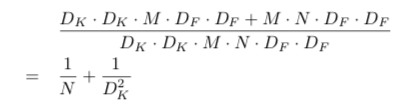
MobileNet使用DK=3, 而N一般是比较大的数(32以上),所以深度分离卷积层的计算量大约是普通卷积层约的8到9分之一,然而准确率只是减小一点点.
网络组成
所有网络层后面都跟着一个 BatchNorm 和一个 ReLU 非线性激活函数,除了最后的全链接层(它的数据会喂入softmax层来用于分类预测).BatchNorm加在深度分离卷积的位置见下图
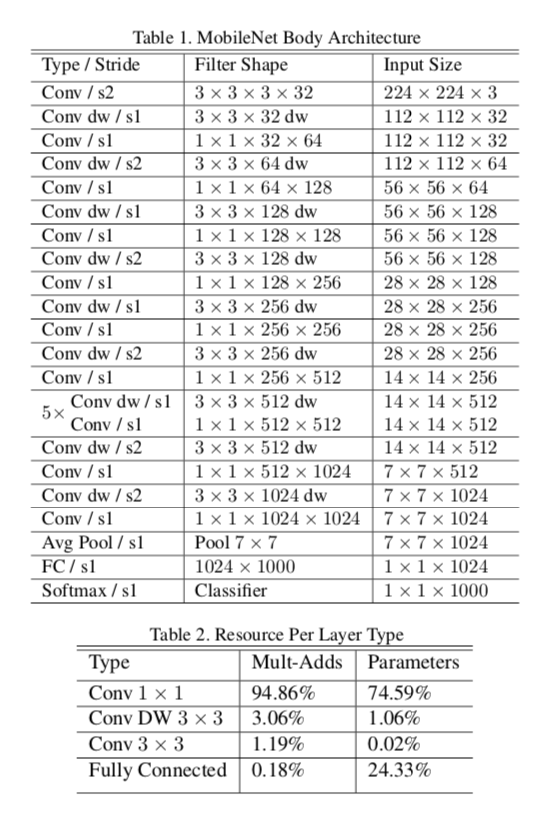
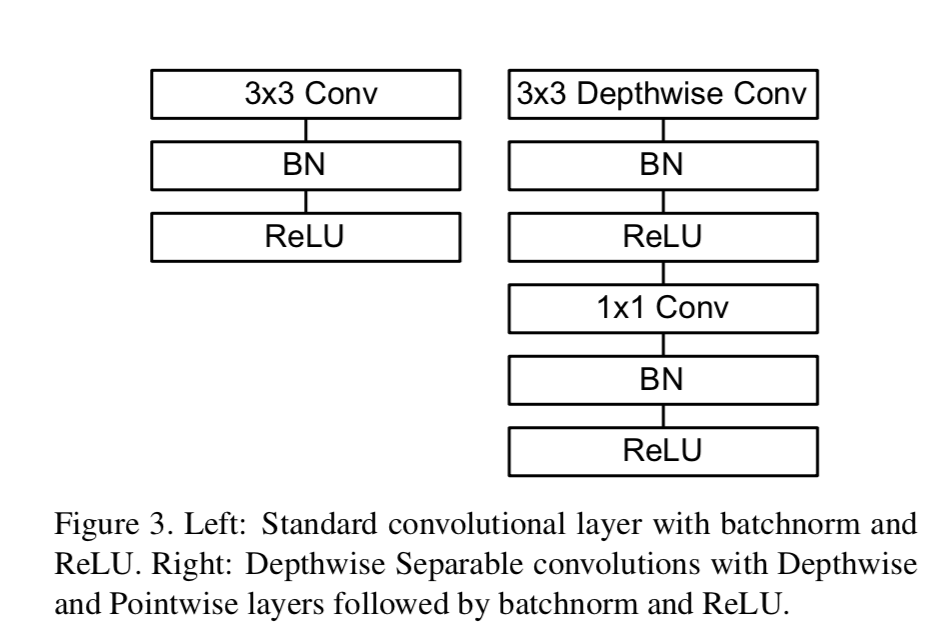 下取样的(stride>1)的操作是在基于深度的卷积层.在数据喂入全链接层之前有一个全局平局池化层.加上基于深度的卷积和基于点的卷积,MobileNet总共有28层.
下取样的(stride>1)的操作是在基于深度的卷积层.在数据喂入全链接层之前有一个全局平局池化层.加上基于深度的卷积和基于点的卷积,MobileNet总共有28层.
深度因子: 给模型瘦身
虽然MobileNet已经够小了,不过在有些应用场景中仍然需要更小更快的模型.所以有了深度因子 α. 假设对一个深度分离网络使用深度因子 α,那么它的输入channel M 变成 αM,它的输出 channel N 变成 αN.
加了深度因子α之后整个网络的计算量变化如下
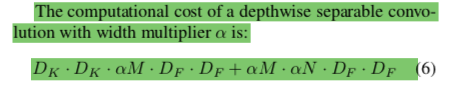
0< α <=1, 使用深度因子之后整体的计算量和参数量大约小了 α2倍.
分辨率因子: 缩小输入
通过把输入图片的大小缩小,也可以有效的减少计算量.所以这里定义了一个分辨率因子 ρ,把输入图的缩小 ρ 倍之后,后面网络中每一层的计算量也会随之变小.再把前面说的深度因子 α 考虑进来的话,深度分离卷积的计算量可以表示为:

0< ρ <=1,所以引入分辨率因子 ρ 之后,可以把计算量缩小
ρ2 倍.
MobileNet 的表现
 在模型大小相当的情况下,MobileNet精度比SqueezeNet高一些,而运算量却小了20几倍.其他Mobile的表现及比较请查看论文详情.
在模型大小相当的情况下,MobileNet精度比SqueezeNet高一些,而运算量却小了20几倍.其他Mobile的表现及比较请查看论文详情.
reference:
SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications